论文题目:Lightweight cross-modal transformer for RGB-D salient object detection(用于RGB-D突出物体检测的轻型跨模态变压器)
期刊:Computer Vision and Image Understanding (计算机视觉与图像理解)
摘要:最近,基于transformer的RGB-D显著物体检测(SOD)模型将性能提升到了一个新的水平。然而,它们的代价是消耗大量的资源,包括内存和功率,从而阻碍了它们的实际应用。为了解决这种情况,本文将介绍一种用于RGB-D SOD的新型轻型跨模变压器(LCT)。具体而言,LCT将首先采用中级特征融合结构,以轻量级Transformer为骨干,降低其参数和计算成本。然后,在变压器的帮助下,通过有效地从多模态输入图像中捕获跨模态和跨层次的互补信息来补偿性能下降。为此,将设计一个具有轻量级通道交叉注意块(LCCAB)的跨模态增强和融合模块(CEFM),以有效捕获跨模态互补信息,但成本更低。设计了一个双向多级特征交互模块(Bi-MFIM),该模块具有轻量级的空间交叉注意块(LSCAB),用于捕获交叉层次的互补上下文信息。利用CEFM和Bi-MFIM,可以很好地补偿由于参数缩减而导致的性能下降,从而提高性能。通过这样做,我们提出的模型只有2.8M参数,7.6G FLOPs,运行速度为66 FPS。此外,在多个基准数据集上的实验结果表明,我们提出的模型可以获得与其他模型相当甚至更好的结果。
代码地址:https://github.com/nexiakele/lightweight-cross-modalTransformer-LCT-for-RGB-D-SOD上发布。
轻量级跨模态Transformer:让RGB-D显著性检测飞起来
引言
想象一下,你正在开发一个智能机器人,需要让它快速识别场景中最重要的物体。RGB-D相机可以提供彩色和深度信息,但如何让模型既快又准地处理这些数据呢?今天要介绍的这篇来自西安电子科技大学和谢菲尔德大学的CVIU 2024论文,提出了一个令人惊艳的解决方案------轻量级跨模态Transformer(LCT)。
背景:Transformer的双刃剑
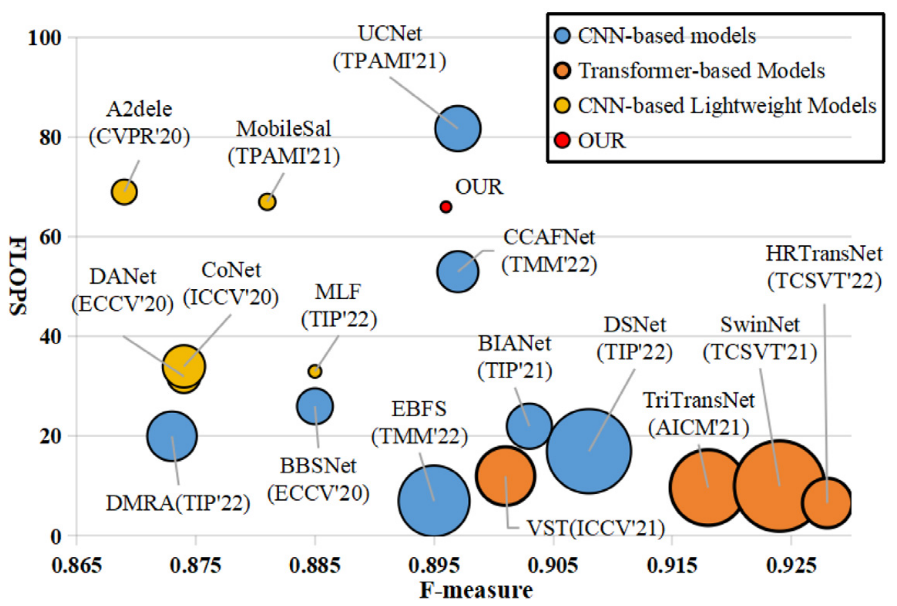
近年来,Transformer在RGB-D显著性目标检测(SOD)领域大放异彩,性能远超传统CNN模型。但这一切都是有代价的:
- 📊 SwinNet:199.2M参数,124.7G FLOPs
- 📊 TriTransNet:139.6M参数,293.9G FLOPs
- 🐌 运行速度:仅10 FPS左右
这样的模型在移动设备或车载计算机上根本无法实时运行!更糟的是,现有的轻量级RGB-D SOD模型几乎都基于CNN,Transformer的轻量级方案还是一片空白。
核心挑战:如何在减参的同时保持性能?
论文团队面临一个两难问题:
- ❌ 简单减少参数 → 性能大幅下降
- ❌ 保持性能 → 参数和计算量居高不下
他们的洞察是:性能下降可以通过更有效地捕获跨模态和跨层级互补信息来补偿。
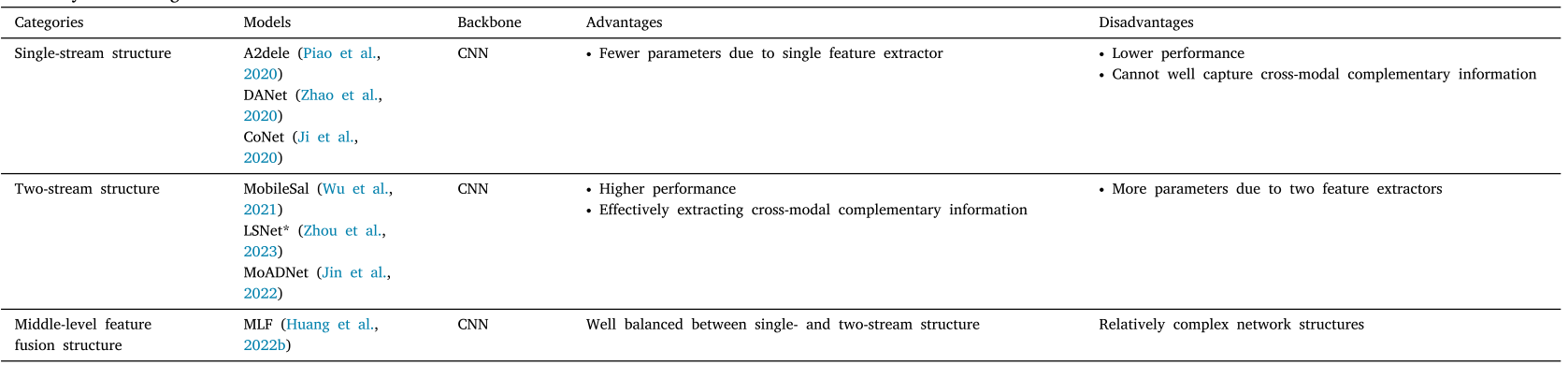
创新方案一:巧妙的结构设计
1. 中间层特征融合结构
传统双流结构需要两个大型特征提取器,而LCT采用了更聪明的策略:
传统双流:
RGB图像 → 大型提取器 → 5层特征 ⎤
⎦→ 多次融合 → 输出
深度图像 → 大型提取器 → 5层特征 ⎦
LCT中间层融合:
RGB图像 → 小型提取器 → 3层特征 ⎤
⎦→ 第3层融合 → 共享提取器 → 4-5层特征 → 输出
深度图像 → 小型提取器 → 3层特征 ⎦优势:
- ✅ 只需要两个小型提取器 + 一个共享提取器
- ✅ 只在一个层级进行跨模态融合
- ✅ 参数量大幅减少
2. 轻量级骨干网络
采用MobileViT作为特征提取器,这是一个专为移动设备设计的高效Transformer。论文还验证了LightViT和EfficientFormer等其他轻量级Transformer的兼容性。
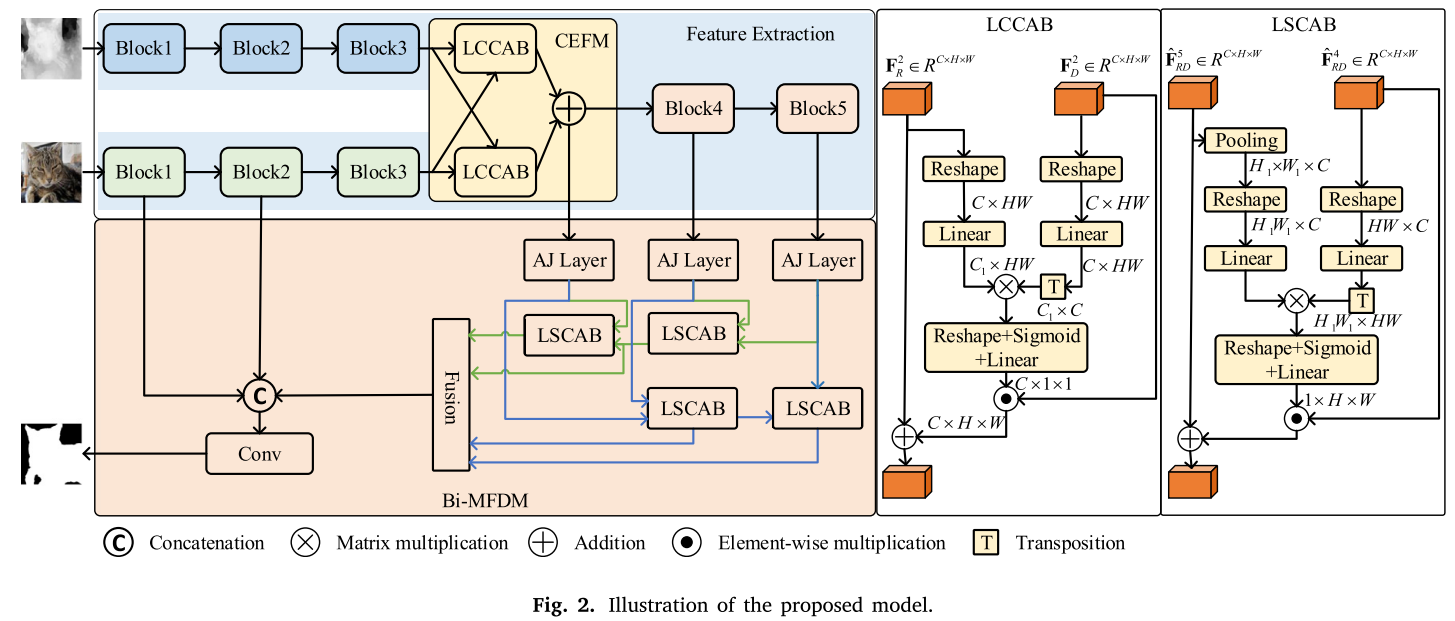
创新方案二:跨模态增强与融合模块(CEFM)
这是论文最精彩的部分之一!传统方法直接融合RGB和深度特征,但这会引入大量冗余信息。CEFM采用**"先增强,再融合"**的策略:
工作流程
-
双向增强:
- RGB特征从深度特征中"吸取"互补信息
- 深度特征从RGB特征中"吸取"互补信息
-
融合增强特征:
- 将两个增强后的特征相加
- 互补信息得到强化,冗余信息被抑制
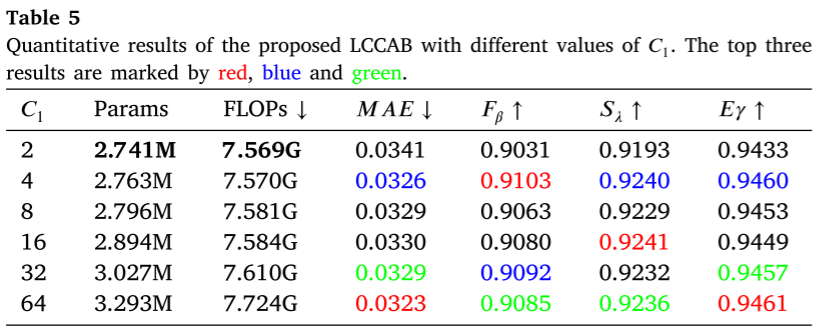
轻量级通道交叉注意力块(LCCAB)
传统交叉注意力在空间维度计算,成本很高。LCCAB巧妙地在通道维度计算注意力:
# 伪代码示意
Q_c = Linear(Reshape(F_RGB)) # C1 × HW
K_c = Linear(Reshape(F_Depth)) # C × HW
# 通道维度的注意力
weights = Sigmoid(Linear(Q_c @ K_c.T / sqrt(C))) # C × 1 × 1
# 增强RGB特征
F_RGB_enhanced = F_RGB + weights * F_Depth计算成本对比:
- 标准交叉注意力:C·HW(3C + HW) ≈ 14.7M(C=64, H=W=56)
- LCCAB:C·HW(2C₁ + C) + C₁C² ≈ 0.25M(C₁=4)
- 节省98%计算量!
创新方案三:双向多层级特征交互模块(Bi-MFIM)
现有方法通常密集聚合多层特征,但这会引入冗余信息。Bi-MFIM采用双向交互策略:
双向设计理念
从高到低方向:
- 高层特征(语义丰富)从低层特征提取细节信息
- 第5层 → 从第4层学习 → 从第3层学习
从低到高方向:
- 低层特征(细节丰富)从高层特征提取语义信息
- 第3层 → 从第4层学习 → 从第5层学习
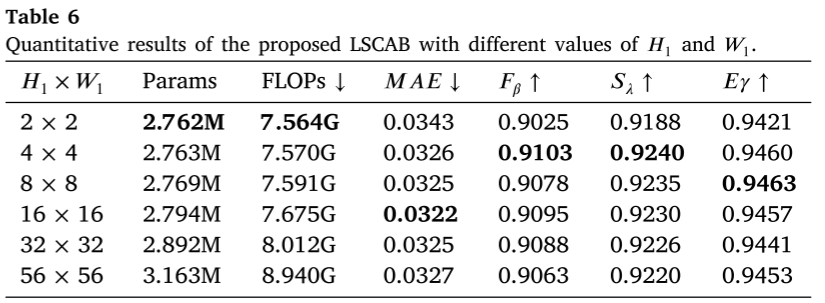
轻量级空间交叉注意力块(LSCAB)
为了降低空间注意力的计算成本,LSCAB使用pooling降低查询特征的空间分辨率:
# 伪代码示意
Q_s = Linear(Reshape(Pooling(F_high))) # H1W1 × C (H1=4)
K_s = Linear(Reshape(F_low)) # HW × C (H=56)
# 空间注意力权重
weights = Reshape(Sigmoid(Linear(Q_s @ K_s.T / sqrt(C)))) # 1 × H × W
# 特征增强
F_enhanced = F_high + weights * F_low计算成本对比:
- 标准交叉注意力:C·HW(3C + 2HW) ≈ 26.2M
- LSCAB:C²(H₁W₁ + HW) + (C+1)(H₁W₁HW) ≈ 0.7M
- 节省97%计算量!
实验结果
模型效率令人惊叹
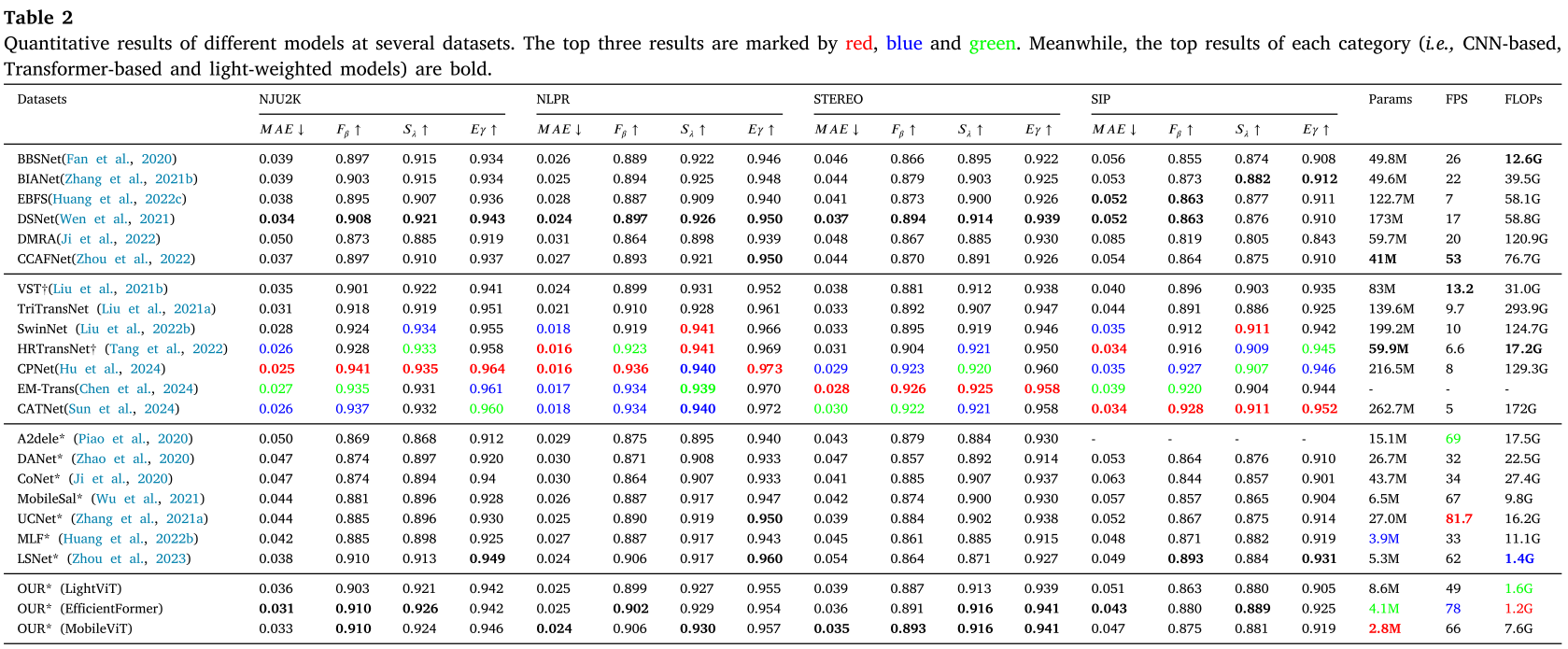
| 模型 | 参数量 | FLOPs | 速度 |
|---|---|---|---|
| SwinNet | 199.2M | 124.7G | 10 FPS |
| TriTransNet | 139.6M | 293.9G | 9.7 FPS |
| LCT | 2.8M | 7.6G | 66 FPS |
- 📉 参数量仅为SwinNet的1.4%
- 📉 FLOPs仅为SwinNet的4.5%
- 🚀 速度是SwinNet的6.6倍
性能不输重量级模型
在NJU2K数据集上:
- F-measure: 0.910(超越VST的0.901)
- MAE: 0.033(优于大多数CNN模型)
- 与重量级Transformer模型性能相当
在其他三个数据集(NLPR、STEREO、SIP)上也取得了竞争性甚至更优的结果!
可视化结果

论文展示的定性结果非常convincing:
- ✅ 小目标检测准确
- ✅ 大目标边界清晰
- ✅ 复杂背景下鲁棒
- ✅ 多目标场景表现优异
消融实验:每个模块都至关重要
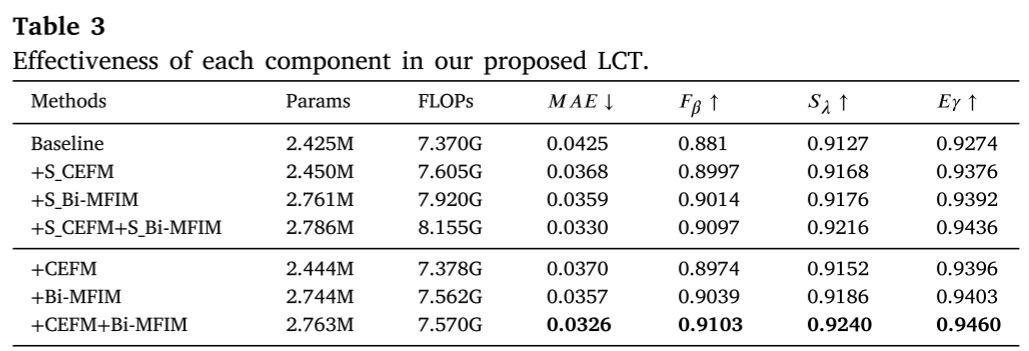
CEFM的贡献
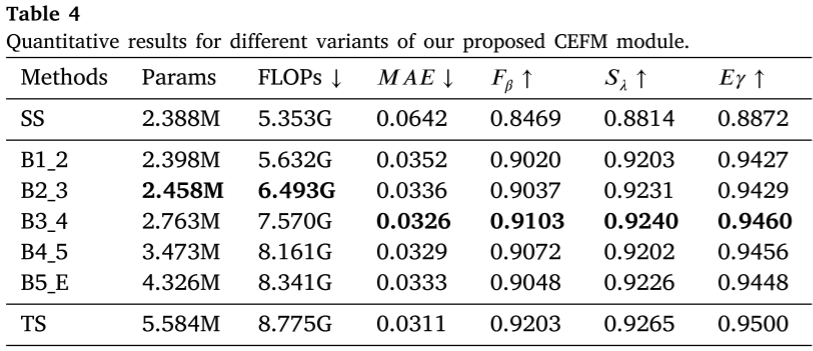
| 配置 | F-measure | MAE |
|---|---|---|
| Baseline | 0.881 | 0.0425 |
| + CEFM | 0.897 | 0.0370 |
| 改进 | +1.6% | -13% |
Bi-MFIM的贡献
| 配置 | F-measure | MAE |
|---|---|---|
| Baseline | 0.881 | 0.0425 |
| + Bi-MFIM | 0.904 | 0.0357 |
| 改进 | +2.3% | -16% |
两者结合效果最佳
| 配置 | F-measure | MAE |
|---|---|---|
| Baseline | 0.881 | 0.0425 |
| + CEFM + Bi-MFIM | 0.910 | 0.0326 |
| 改进 | +2.9% | -23% |
融合位置的选择
论文测试了在不同层级进行跨模态融合的效果,发现在第3层融合(中间层)达到最佳平衡:
- 太早融合(第1-2层):性能不足
- 太晚融合(第4-5层):参数增多但性能提升有限
- 第3层融合:性能与效率的最佳平衡点
技术亮点总结
1. 设计哲学的转变
- ❌ 传统思路:密集融合、大力出奇迹
- ✅ LCT思路:精准交互、事半功倍
2. 注意力机制的创新
-
LCCAB :通道维度注意力,节省98%计算
-
LSCAB :降维空间注意力,节省97%计算
3. 架构设计的智慧
- 中间层融合:参数最优点
- 双向交互:互补信息最大化
局限性与未来工作
论文诚实地指出了当前的局限:
-
计算复杂度仍有优化空间
- 虽然参数少,但FLOPs相对其他轻量级模型仍较高
- 某些耗时操作(如concatenation)影响速度
-
未来改进方向
- 进一步简化网络结构
- 减少耗时操作
- 探索更高效的注意力机制
实践启示
这篇论文给我们的启示:
-
减参不一定牺牲性能
- 关键在于如何更有效地利用信息
- 精心设计的轻量模块可以弥补参数减少
-
注意力机制的维度选择很重要
- 通道注意力 vs 空间注意力
- 根据特征图尺寸灵活选择
-
交互胜过聚合
- 双向特征交互比单向聚合更有效
- 先增强再融合比直接融合更好
-
中间层融合是个好策略
- 在轻量级模型设计中值得考虑
- 兼顾低层细节和高层语义
结语
这篇论文为RGB-D显著性检测领域带来了一股清流------不是所有问题都需要用更大的模型来解决。通过巧妙的结构设计和高效的模块,LCT实现了:
- 🎯 2.8M参数:业界最小
- ⚡ 66 FPS:实时运行
- 🏆 竞争性能:媲美重量级模型
这不仅是技术上的创新,更是设计理念的突破。对于需要在资源受限设备上部署RGB-D视觉算法的场景(如移动机器人、智能手机、车载系统),LCT提供了一个极具实用价值的解决方案。
关键启发:有时候,"少即是多"------用更少的参数做更多的事,关键在于找到信息利用的最优策略。
如果你对轻量级深度学习模型设计感兴趣,这篇论文绝对值得深入研究!