Mind to Hand : Purposeful Robotic Control via Embodied Reasoning
原文链接:https://arxiv.org/pdf/2512.08580
目录
[Mind to Hand: Purposeful Robotic Control via Embodied Reasoning](#Mind to Hand: Purposeful Robotic Control via Embodied Reasoning)
[空间动作分词器 (Spatial Action Tokenizer) ------ 核心创新点](#空间动作分词器 (Spatial Action Tokenizer) —— 核心创新点)
[Stage 1: 持续VLM预训练 (Continued VLM Pre-training)](#Stage 1: 持续VLM预训练 (Continued VLM Pre-training))
[Stage 2: 跨机身混合训练 (Co-training on Cross-Embodiment Data)](#Stage 2: 跨机身混合训练 (Co-training on Cross-Embodiment Data))
[Stage 3: 目标机身推理训练 (Target-Embodiment Action Training)](#Stage 3: 目标机身推理训练 (Target-Embodiment Action Training))
五.长程任务判定:子任务完成度预测 (Subtask Completeness)
[(2)training recipe技术分析](#(2)training recipe技术分析)
[GRPO 原理解析](#GRPO 原理解析)
[RL 数据工程 (Data Selection for RL)](#RL 数据工程 (Data Selection for RL))
[奖励函数设计 (Reward Engineering) ------ 核心干货](#奖励函数设计 (Reward Engineering) —— 核心干货)
[七.实验分析、长程任务鲁棒性与机器人Scaling Laws](#七.实验分析、长程任务鲁棒性与机器人Scaling Laws)
核心实验洞察 (Performance Deep Dive)
[训练阶段的现象:语义 vs. 动作](#训练阶段的现象:语义 vs. 动作)
[机器人Scaling Laws](#机器人Scaling Laws)
一.背景
通用的机器人操作模型VLA往往面临一个核心矛盾:Web级数据的推理能力与物理世界精准操作之间的鸿沟。像RT-2这样的模型虽然具备语义理解,但在长程任务规划和动作可解释性上存在短板。
突破:mind to hand**(从心到手)**
不仅仅是一个将图像映射到动作的策略网络
而是将具身推理 与动作生成深度解耦又联合优化的系统
后面我从模型架构,数据准备,预训练,后训练,实验分析,总结等几个方面讲解,并指出每个部分的优劣势
二.相关概念
- ++Action Tokenization++:++将连续的、复杂的动作空间(比如控制++ ++机械臂++ ++每个关节的精确++ ++力矩++ ++),转换成一系列离散的、基本的"动作单元"或"动作词"++
Binning (分桶):最简单的离散化,将连续动作空间(如-1到1)切分为256个桶。缺点是对于高维机器人,token序列过长,推理慢。
ACT / VQ-VAE:通过聚类或量化学习动作的离散表示。
Lumo-1的创新 :结合了AWE (Action Waypoint Extraction) 和 K-means 的空间动作分词器,专注于末端执行器(End-Effector, EE)的增量空间(Delta Space)。
- ++GRPO (Group Relative Policy++ ++Optimization++ ++)++
++源自DeepSeekMath等大语言模型++ ++强化学习++ ++算法。++
核心逻辑:不依赖额外的Critic模型(Value function),而是通过对同一个Prompt生成一组输出(Group),计算组内相对优势(Advantage),从而优化Policy。
在Lumo-1中:用于解决"推理文本"与"实际物理动作"不对齐的问题。
三.核心架构设计
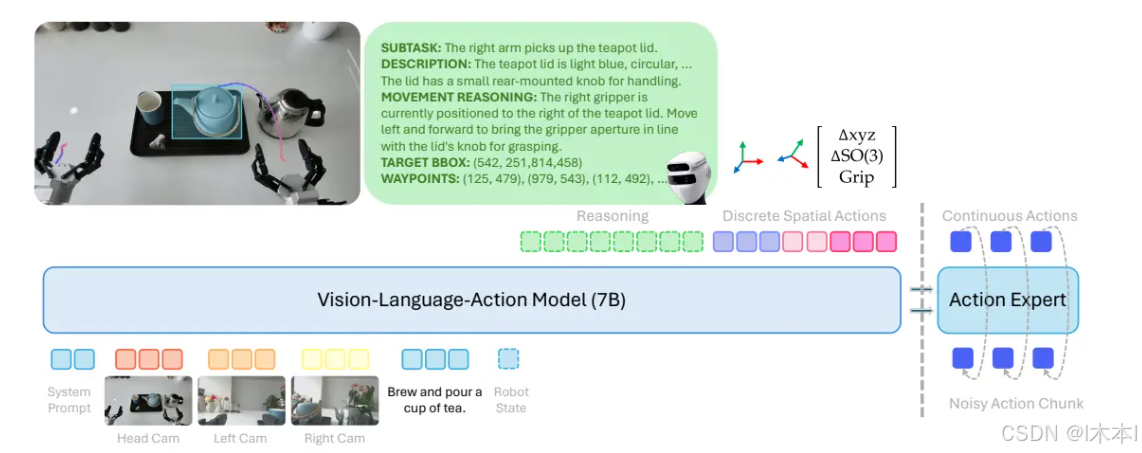
骨干网络:backbone
基座:Qwen2.5-VL-7B
-
输入模态:
-
文本指令(Instruction)。
-
机器人本体状态(robot state)。
-
视觉观测(多视角图像,Head/Wrist Cameras)。
-
-
输出:文本Token(用于推理链CoT)+ 离散动作Token(用于粗粒度规划)。
空间动作分词器 (Spatial Action Tokenizer) ------ 核心创新点
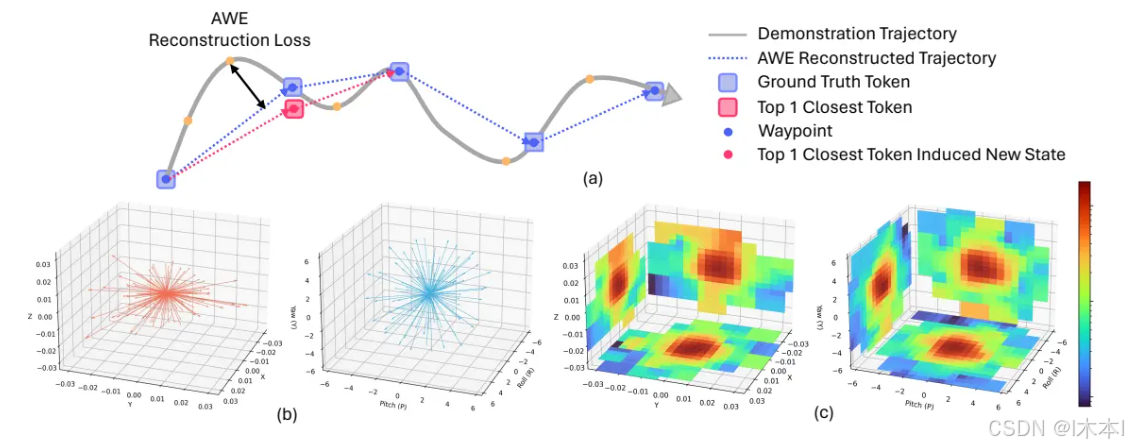
是高效处理跨机器人的关键,传统的关节空间表示由于自由度不同难以通用
核心思路:
EE-Space Delta (末端增量空间)
模型预测的是末端执行器(手)在笛卡尔空间中的相对位移和旋转变化
这种表示法对机器人本体构型不敏感
轨迹压缩 (AWE, Action Waypoint Extraction)
不预测每一步,预测关键点
K-means 聚类
在海量机器人数据上,对相对位移和旋转变化分别进行K-means聚类。构建Motion Token Library(动作词表)。
Token 结构
一个动作帧被压缩为8个Token 的固定序列: [躯干位置,躯干旋转, 左臂位置, 左臂旋转, 左手夹爪, 右臂位置, 右臂旋转, 右手夹爪]
动作专家 (Action Expert)
技术选型:Flow Matching
-
工作流:
-
VLM骨干网络处理视觉和文本,输出KV Cache(上下文向量)。
-
Action Expert 接收 VLM 的 KV Cache 作为条件输入(Conditioning)。
-
Action Expert 生成连续的动作向量场(Vector Field)。
-
-
Why? Driess et al. (2025) 指出,直接微调VLM输出连续值会导致训练不稳定。将连续动作生成剥离给专门的Expert网络,既保留了VLM的通用推理能力,又保证了控制精度。
(1)架构优势劣势分析
核心优势
-
通用性与迁移性 :通过空间动作分词器在Delta EE空间操作,Lumo-1可以利用不同构型机器人的数据进行Co-training,而不需要重新训练特定机器人的Head。
-
长程推理能力:将推理(Reasoning)显式地作为Token生成的一部分(CoT),模型在执行动作前会先生成"Subtask Reasoning"、"Visual Grounding"等文本。这比单纯的动作克隆(BC)更鲁棒。
-
推理效率:
-
离散Token预测时,采用了特定的8-token结构,压缩率高。
-
连续动作生成时,Flow Matching通常比Diffusion收敛更快,推理步数更少。
-
潜在挑战
-
逆运动学 (IK) 依赖:由于模型输出的是EE(末端)位姿,控制机器人需要高性能的IK解算器将EE转换为Joint控制信号。如果IK解算存在多解或奇异点,可能导致动作抖动。
-
Token解压缩误差:K-means聚类是有损压缩。如果聚类中心不够密集,可能导致微小的操作精度丢失(虽然通过Flow Expert进行了补偿)。
-
推理延迟:虽然Flow Matching快,但串联一个7B参数的VLM加上Expert网络,在端侧实时控制(如30Hz闭环)对算力(Orin/RTX 4090)要求极高
四.训练pipeline和数据工程(recipe)
Lumo-1的训练并不是简单地将所有数据混合在一起进行一次性微调,而是采用了Curriculum Learning(课程学习)的思想---一种模仿人类学习过程的机器学习范式
Stage 1: 持续VLM预训练 (Continued VLM Pre-training)
-
目标:注入"空间几何感知"与"具身规划"能力,但尚未涉及具体机器人的控制信号。
-
核心动作:让模型学会"看懂"物理世界,而非仅仅是识别物体类
- 热身性质 :大约13.7B个token ,此阶段仅训练了7000步( 128 H100 GPUs),相比后续阶段较短。其目的是在不破坏VLM原有语义能力的前提下,align其视觉编码器对物理几何特征的敏感度。
Stage 2: 跨机身混合训练 (Co-training on Cross-Embodiment Data)
-
目标:学习通用的物理交互规律(Physics Priors)和动作预测能力。
-
核心动作:利用海量异构机器人数据(Agile X, Genie等),结合动作分词器,学习"手眼协调"。
- 计算量最大的阶段,模型"看过"了约**2000亿(200B)**个Token。核心挑战在于如何处理来源杂乱、质量参差不齐的异构机器人数据。
算法上采用了混合策略(保持模型对指令理解) ,数据清洗上轨迹去重(减少无效样本训练) ,轨迹镜像(解决人类操作员右利手的问题)
训练70000步( 128 H100 GPUs)
Stage 3: 目标机身推理训练 (Target-Embodiment Action Training)
-
目标:适配Astribot S1硬件特性,并注入结构化推理(Reasoning)逻辑。
-
核心动作:在Astribot S1的高质量数据上微调,强化"三思而后行"的思维链(CoT)。
Lumo-1区别于传统VLA的最显著特征。在针对Astribot S1的微调中,模型不再是简单的输入指令输出动作,而是被强制要求"Think before Act"。
推理-动作范式
推理链(Reasoning Trace)包含四个层级:
-
抽象概念推理 (Abstract Concept):
-
指令:"把高热量饮料拿给我"。
-
推理:"高热量饮料指的是红色的可乐罐。"
-
-
子任务规划 (Subtask):
- 推理:"现在的任务是抓取可乐,下一步应该移动右臂去接近它。"
-
视觉描述 (Visual Description):
- 推理:"可乐罐位于桌子右侧,红色,目前没有被遮挡。"
-
运动推理 (Movement Reasoning):
- 推理:"右臂需要向左前方移动,调整夹爪角度以对齐可乐罐的把手。"
五.长程任务判定:子任务完成度预测 (Subtask Completeness)
在执行如"做饭"这种长程任务时,传统VLA常遇到的问题是:不知道自己做完了没有,或者在相似状态下死循环(例如门开了一半,是继续开还是关?)。
Lumo-1的创新解法:
-
输入变更 :
[Flat Instruction, Last Executed Subtask] -
逻辑 :模型不仅预测下一个子任务,还会先预测**"上一个子任务是否已完成"**。
-
效果:如果上一步是"打开微波炉门",模型只有在判断门已经完全打开(Completeness = True)后,才会生成"放入食物"的子任务。这极大地提升了状态机的稳定性。
(2)training recipe技术分析
核心亮点 (Key Takeaways)
-
数据 质量优于数量:通过去重和镜像增强,Astribot证明了处理好的数据比单纯堆砌Raw Data更有效。
-
VLM与Robot能力的平衡:在Stage 2中显式混入VLM数据是防止模型变"傻"(丧失语义理解)的关键。
-
显式推理监督:Stage 3证明了,仅仅做BC(行为克隆)是不够的,强制模型输出推理过程(Reasoning Trace)可以作为一种强的正则化手段,帮助模型对齐视觉特征和动作意图。
潜在风险点 (Risks)
-
推理延迟累积 :Full Reasoning模式生成的文本Token数量可能多达几百个,这将显著增加推理时间(Time-to-Action)。在需要高频响应的动态场景(如接球)中可能不适用。
-
Prompt依赖:模型的表现高度依赖系统Prompt的引导。如果Prompt设计不当,可能会导致推理幻觉(Hallucination)。
六.强化学习与推理-动作一致性对齐
经过Stage 3的训练,Lumo-1已经能够针对指令生成"推理链"和"动作Token"。但在实际测试中,Astribot团队观察到了两个主要问题:
-
推理幻觉 (Unreasonable Reasoning):文本推理内容逻辑错误。例如,指令是"拿苹果",推理文本却识别成了"拿橘子",或者Bounding Box预测偏离目标。
-
脑手不一 (Misalignment):推理文本完全正确(例如:"向左移动"),但生成的动作Token却是向右的。
这是因为SFT本质上是行为克隆(Behavior Cloning) ,模型只是在模仿训练数据的分布,而没有真正理解"推理导致动作"的因果关系。为了闭环(Close the loop),必须引入强化学习。
最通俗的解释就是,让模型去做练习题(mind与hand对齐),对了奖励,错了惩罚
没有选择PPO算法(在VLA(7B参数)场景下,PPO需要维护一个与策略网络同样巨大的Value Network(Critic),显存开销极大),选择了GRPO (Group Relative Policy Optimization) ,是DeepSeek-Math等模型采用的高效算法。GRPO摒弃了Critic网络,而是通过**"组内相对优势"** 来估计Baseline。简单来说就是自己跟自己比。
GRPO 原理解析
-
工作流:
-
对于同一个输入(图像+指令),让当前策略采样生成G组不同的输出
-
计算每一组输出的奖励
-
计算组内平均奖励和标准差
-
计算优势函数
-
-
优势:
-
显存节省:无需加载额外的Critic模型。
-
相对更稳:通过组内对比,自然形成了一个动态的Baseline。
-
优化目标函数
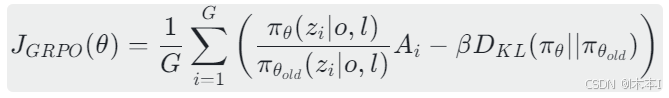
其中 β 是KL散度的惩罚系数,用于约束策略更新不要偏离旧策略太远,防止崩塌。
RL 数据工程 (Data Selection for RL)
RL训练对数据质量极其敏感。Astribot团队采取了以下策略:
-
关键帧加权 (Keyframe Sampling):在采样数据时,赋予"子任务完成时刻"附近的帧更高的权重。这些时刻通常包含抓取或放置的关键动作,Reward信号最强。
-
文本增强 (Text Augmentation):随机修改指令中的非关键部分,防止模型过拟合特定的句式。
-
动态过滤 (Efficiency Filtering):
-
在训练前,先用当前模型跑一遍推断。
-
剔除太简单的样本(Reward方差极小,大家都做对了)。
-
剔除太难的样本(所有尝试都得0分,无法提供梯度)。
-
只保留那些**"有成功也有失败"**的样本,提供最大的学习信息量。
-
奖励函数设计 (Reward Engineering) ------ 核心干货
由于Lumo-1是多模态输出**(文本+坐标+动作)** ,Reward设计必须是混合型的。

·视觉感知奖励 (Visual Reward)
·轨迹一致性奖励 (Waypoint Reward)
·文本一致性奖励 (Consistency Reward)
·动作执行奖励 (Action Reward)
·格式奖励 (Format Reward)
效果验证:净胜率 (NSR)
为了验证RL的有效性,Astribot提出了 NSR (Net Superiority Rate) 指标,用于对比 RL模型 vs Stage 3模型。
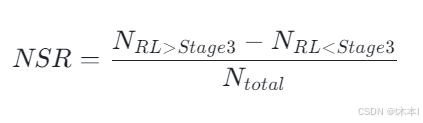
实验结果(Full Reasoning Mode):
-
Waypoint NSR : +22.43% (轨迹规划能力大幅提升)
-
Action NSR : +23.33% (最终动作执行更准)
-
Bbox NSR: +5.05% (视觉感知微涨)
结论 :RL阶段带来的最大收益不在于感知(感知主要靠Pre-training),而在于规划与执行的一致性。模型学会了更好地利用自己的推理结果来指导动作。
(3)RL部分技术总结
-
GRPO是VLA微调的首选:在显存受限和模型巨大的情况下,放弃Critic网络,利用Group Sampling是高效且有效的。
-
Reward必须多维:单一的Action Loss不足以训练推理能力。必须引入VLM-as-a-Judge和中间过程(Bbox/Waypoint)的监督信号。
-
DTW的重要性(轨迹一致性奖励中):在衡量轨迹相似度时,DTW比MSE更适合处理时序上的弹性变化。
-
探索与利用:高Temperature + 严格的Format Reward,是在保证输出结构合规的前提下,最大化探索解空间的有效手段。
七.实验分析、长程任务鲁棒性与机器人Scaling Laws
实验设计涵盖了大概下面四个方面
-
Unseen Environments:训练没见过的背景/光照/桌台。
-
Unseen Objects:训练没见过的物体(测试几何泛化)。
-
Unseen Instructions:训练没见过的复杂指令(测试语义推理)。
-
Long-Horizon Tasks:涉及多步骤、显式记忆和状态管理的长任务。
核心实验洞察 (Performance Deep Dive)
训练阶段的现象:语义 vs. 动作
-
现象 :在Stage 2(跨机身Co-training)结束后,模型在动作执行准确率 上大幅提升(Unseen Env成功率从86%涨到92%),但在语义理解(Instruction Following)上反而下降了。
-
原因分析 :Stage 2引入了海量机器人轨迹数据,尽管混入了5%的VLM数据,但在高强度的"动作回归"训练下,VLM原有的通用语义空间被压缩,导致对"高热量饮料"、"吃竹子的动物"等抽象概念理解能力退化。
-
Stage 3的救赎:Lumo-1通过Stage 3(Reasoning Training)完美解决了这个问题。通过强制输出Reasoning Trace,模型重新连接了Visual Grounding和Abstract Semantics。
数据证明:Stage 3模型在Unseen Instructions上的成功率比Stage 2提升了近20个百分点,且动作精度未下降。
长程任务实测
在"泡茶"、"折叠毛巾"、"微波炉热饭"等任务中,Lumo-1展示了其架构中**"子任务完成度预测(Subtask Completeness Prediction)"**的价值。
解决"死循环"Bug
在长程任务中,视觉观测往往具有欺骗性。例如:
-
场景:微波炉门开了一半。
-
歧义:此时是应该继续"开门"?还是已经开够了,该"放食物"?
-
Lumo-1表现:
无Completeness预测的模型:容易在"开门"动作上死循环,因为视觉上门还可以开得更大。
Lumo-1:利用输入的History Context(上一帧子任务状态),准确判断当前子任务已结束,强制切换到下一状态。
灵巧操作 (Dexterous Manipulation)
在"整理文具(Organize Stationery)"任务中,需要精确控制手腕旋转(Wrist Rotation)将笔插入笔筒。Lumo-1展现了极高的微操能力,这归功于:
-
Action Expert (Flow Matching):生成了平滑且连续的旋转轨迹。
-
RL Fine-tuning:通过Waypoint Reward微调,修正了SFT阶段常见的"手腕转动角度不足"的问题。
机器人Scaling Laws
在LLM领域,我们信奉Scaling Laws(大力出奇迹),但在机器人领域,高质量数据极其昂贵,Blind Scaling(盲目扩展)是不可行的。
Astribot团队采用了Data-Constrained Scaling Law (数据受限扩展定律) Muennighoff et al., 2023 来建模。
数学模型
在固定模型参数量(7B)的前提下,LossL(D)与数据量 D 的关系为:
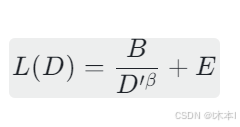

实验结论与行动指南
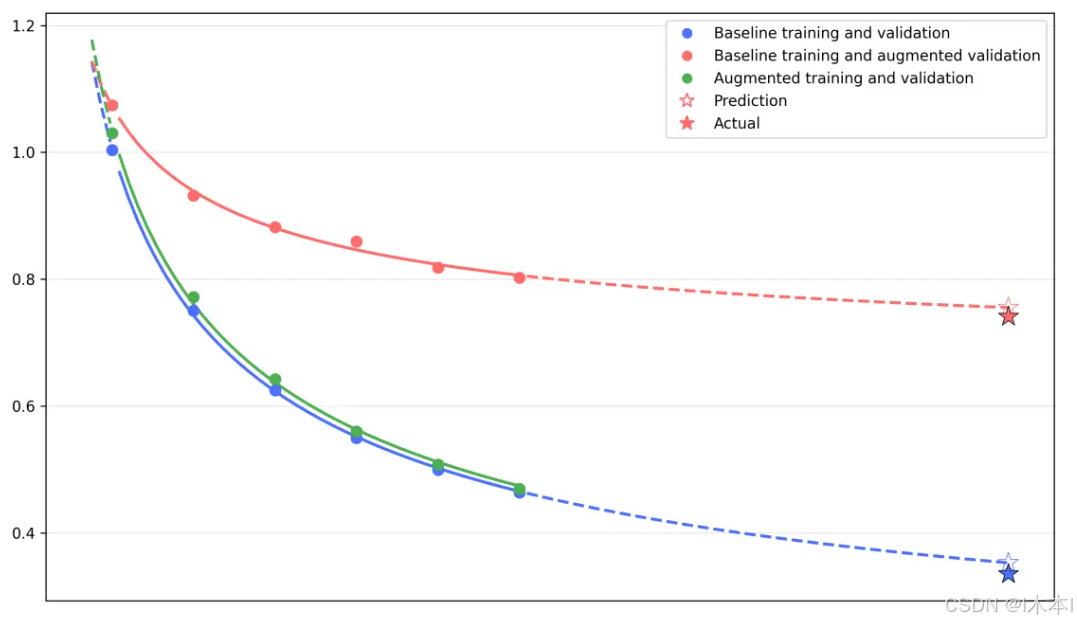
通过对比不同数据配置下的验证集Loss曲线(图16),得出了三条铁律:
-
数据重复收益递减极快 :简单地将同样的机器人轨迹跑很多个Epoch(红色曲线),Loss下降很快就会停滞(Saturation)。这意味着过拟合发生得比LLM更早。
-
增强(Augmentation)等于数据扩容:
-
Astribot在训练中引入了激进的增强策略:视觉增强 (光照、视角变换)+ 文本增强 (指令改写)+ Prompt增强。
-
实验显示,Augmented Training(绿色曲线) 能够显著延缓Loss的饱和,这就好比人为地增加了 U_D(唯一数据量)。
-
-
Scaling Law 在机器人领域成立 :实际观测的Loss点与公式预测高度拟合。这意味着我们可以预估:如果要将成功率提升10%,需要采集多少新数据,或者需要做多少倍的数据增强。
(4)实验部分技术总结分析
基于上述定律,未来的数据采集策略应调整为:
-
不要死磕单一场景:在一个场景下采集1000条数据,不如在10个场景下各采集100条。
-
计算换数据:在训练Pipeline中,加大Data Augmentation的算力投入(甚至使用GenAI生成合成数据),其性价比高于物理采集。
-
Diversity > Quantity:Stage 2引入的跨机身数据,其核心价值在于提供了极高的Diversity(多样性),从而打破了特定机器人的过拟合。
具身智能模型训练的物理规律:
-
推理是泛化的催化剂:没有Reasoning,VLA只是一个机械的轨迹回放器;有了Reasoning,它才能应对Unseen指令。
-
Flow Matching是灵巧操作的基石:离散Token负责决策,连续Flow负责微操,这种解耦是必要的。
-
数据策略必须科学化:利用Scaling Laws指导数据采集预算,通过多样性和增强技术来最大化数据效率。
八,全文总结及建议
Lumo-1的核心贡献在于验证了一条通往通用机器人的路径:
-
统一语言:用离散Token打通视觉、语言和动作。
-
显式思考:用CoT强迫机器人理解物理世界,而非死记硬背。
-
分层控制:大模型做规划(Mind),专家网络做执行(Hand),RL做对齐。
对于技术团队而言。未来的竞争将不再是"谁的模型结构更复杂",而是"谁能采集到更高质量的推理数据(Reasoning Data)"以及"谁能更高效地完成Sim-to-Real的RL闭环"。
关于局限与风险
-
推理延迟:视频里有2倍速,有4倍速,应该是开启了不同的推理模式,实际上Lumo-1基于7B模型,Full Reasoning模式下需要先生成数百个文本Token,再生成动作Token,最后还要过一遍Flow Matching网络。这一过程在端侧(即使是Orin X)很难做到30Hz实时响应。
-
缺失触觉:Lumo-1是纯视觉(Vision-Only)模型,在"盲插"、"精密装配"或"处理软体形变"任务中,缺乏力觉/触觉反馈会导致失败。
-
对标定与IK强依赖:模型输出的是EE(末端)位姿,严重依赖逆运动学(IK)解算器和手眼标定精度。如果机器人的IK求解存在奇异点,或者摄像头发生微小位移(标定失效),模型性能必定下跌。而像pi0这种输出关节角度的模型反而有一定鲁棒性。
-
开环执行:Lumo-1一次预测约1.33秒的轨迹(Action Chunk)。在这1.33秒内,动作是开环执行的,如果在执行Chunk的过程中环境发生了突变(如被人撞了一下),机器人无法即时修正,必须等这1.33秒执行完才能重新规划。
-
动作空间分词器能不能直接用:K-means聚类中心是基于Astribot的数据分布生成的,除此之外,关于stage3的内容难以复现,其中视频demo推测是针对性的通过stage3调整。