作者:来自 Elastic Nathan_Reese

Kibana 地图 教程 "构建地图,用于按国家或地区对比指标" 使用 Elasticsearch 的 DSL 查询 来创建地图。最近新增的 ES|QL 函数 LOOKUP JOIN( 8.18 )和 ST_GEOTILE( 9.2 )使得可以使用 ES|QL 重新创建该教程中的地图。
下面是使用 ES|QL 重新创建该教程地图的步骤。随后,这些步骤还超出了原始教程的能力范围,并按国家人口对分级设色图层进行归一化处理。
前提条件
- 如果你还没有 Kibana,请使用我们的 免费试用 进行设置。
- 本教程需要 web logs 示例数据集。
- 你必须具备创建地图和创建索引的正确权限。
步骤 1:创建 地图
- 前往 Dashboards。
- 点击 Create dashboard。
- 将时间范围设置为 Last 7 days。
- 点击 Add 按钮并选择 New panel,最后点击 Maps。
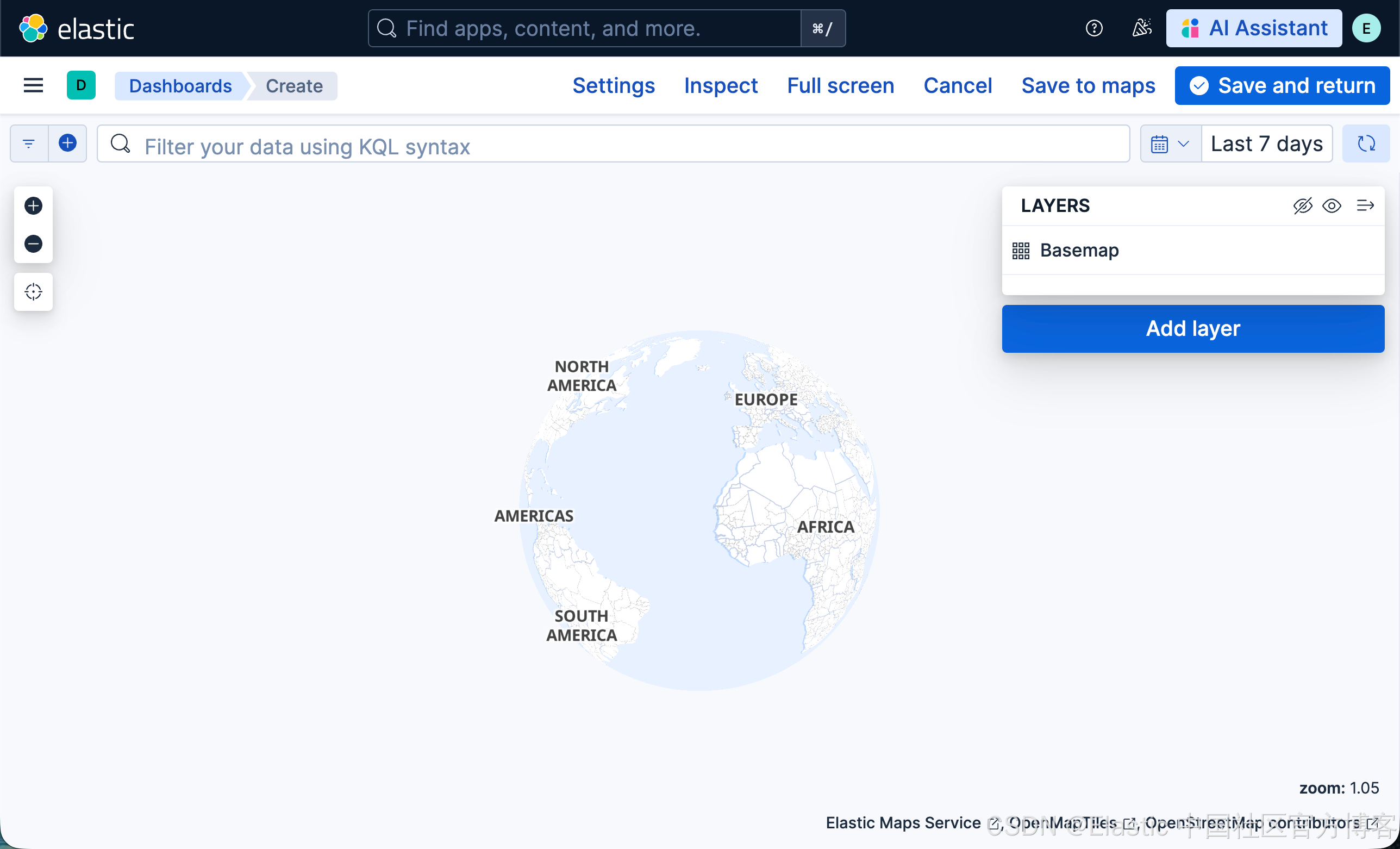
步骤 2. 添加一个 choropleth 图层
你将添加的第一个图层是一个 choropleth 图层,用于按 web 日志流量为世界各国着色。较深的颜色表示 web 日志流量较多的国家,较浅的颜色表示流量较少的国家。
索引世界国家
- 下载世界国家 GeoJSON 文件
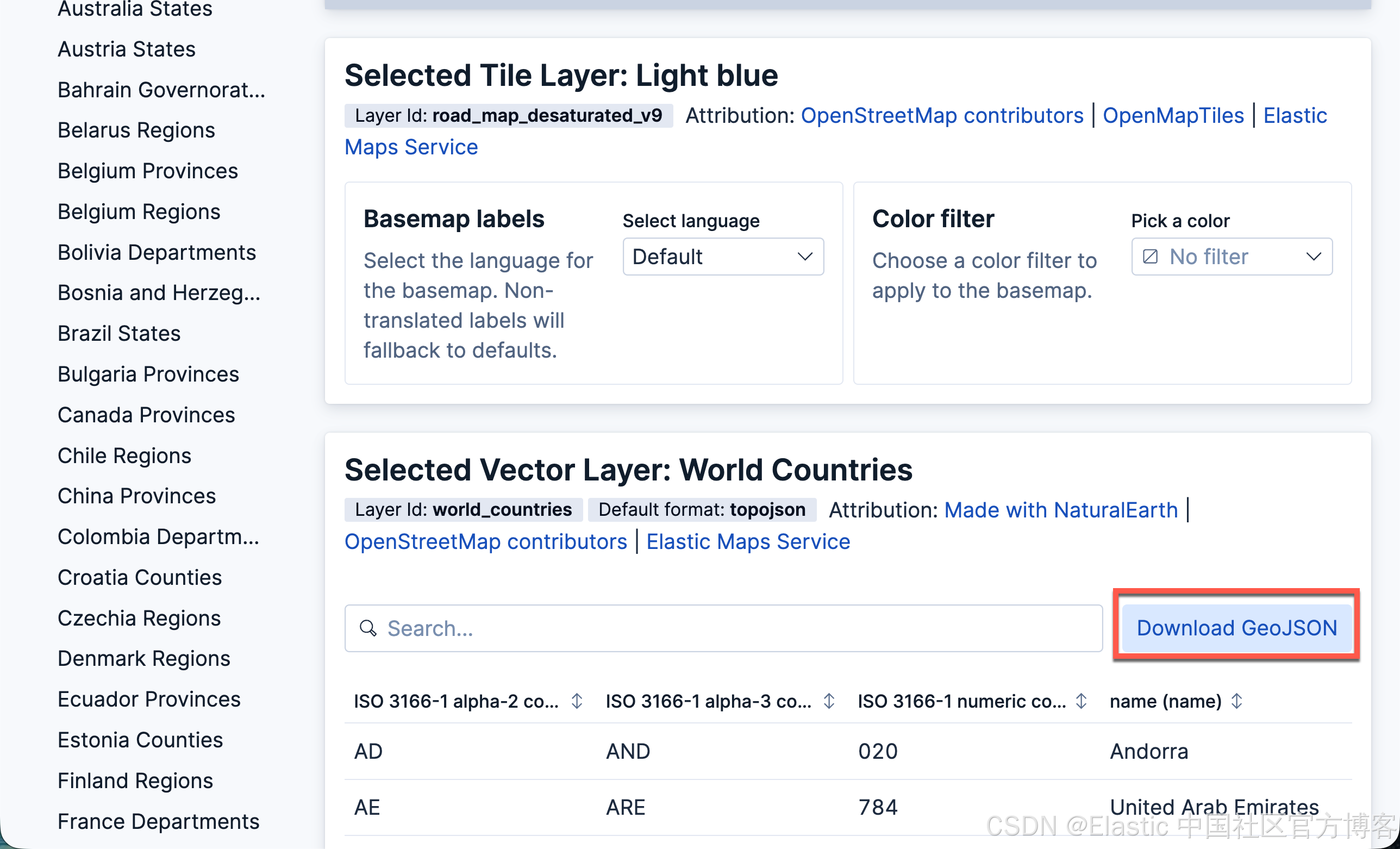
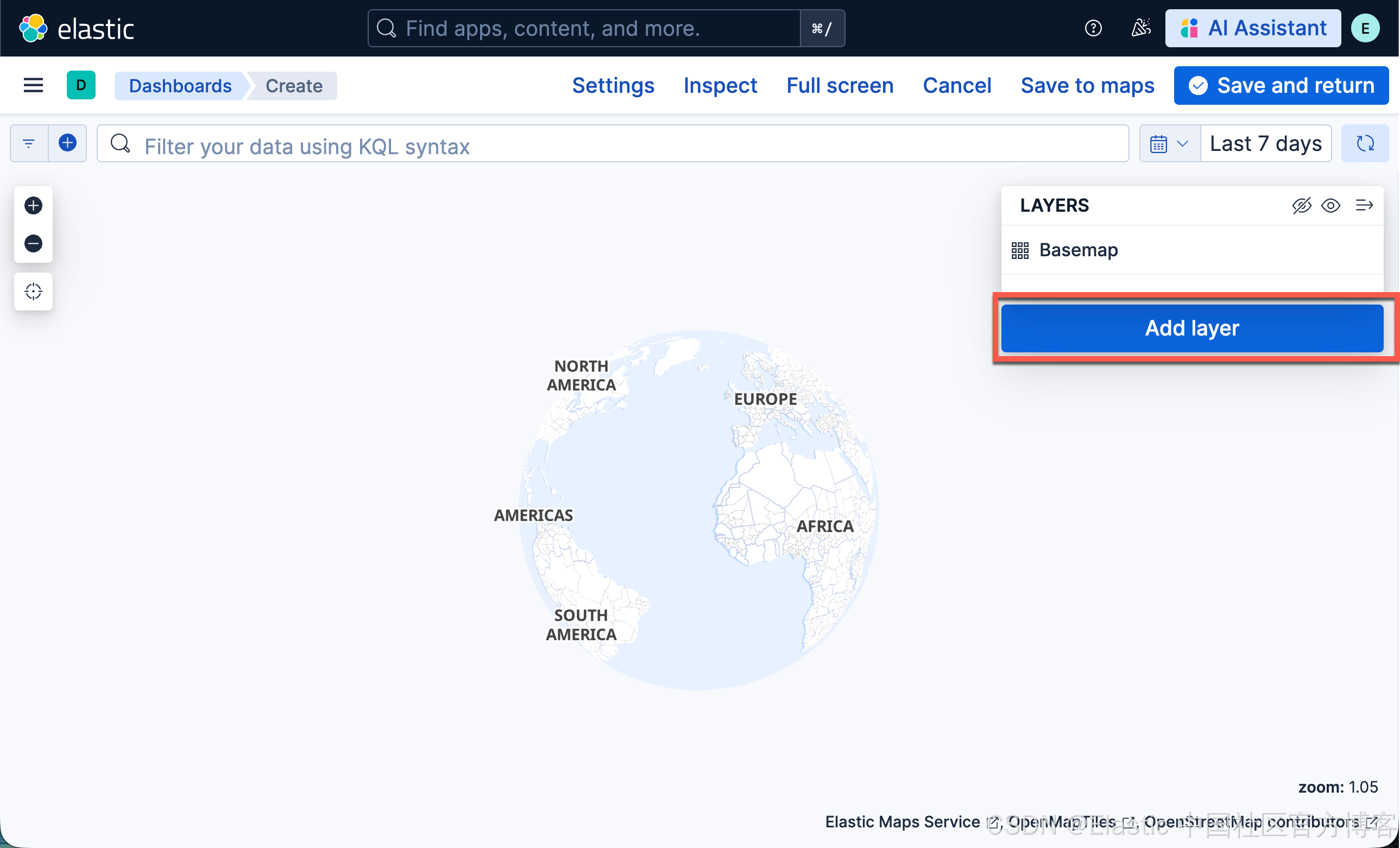
- 在 Kibana maps 中,点击 Add layer
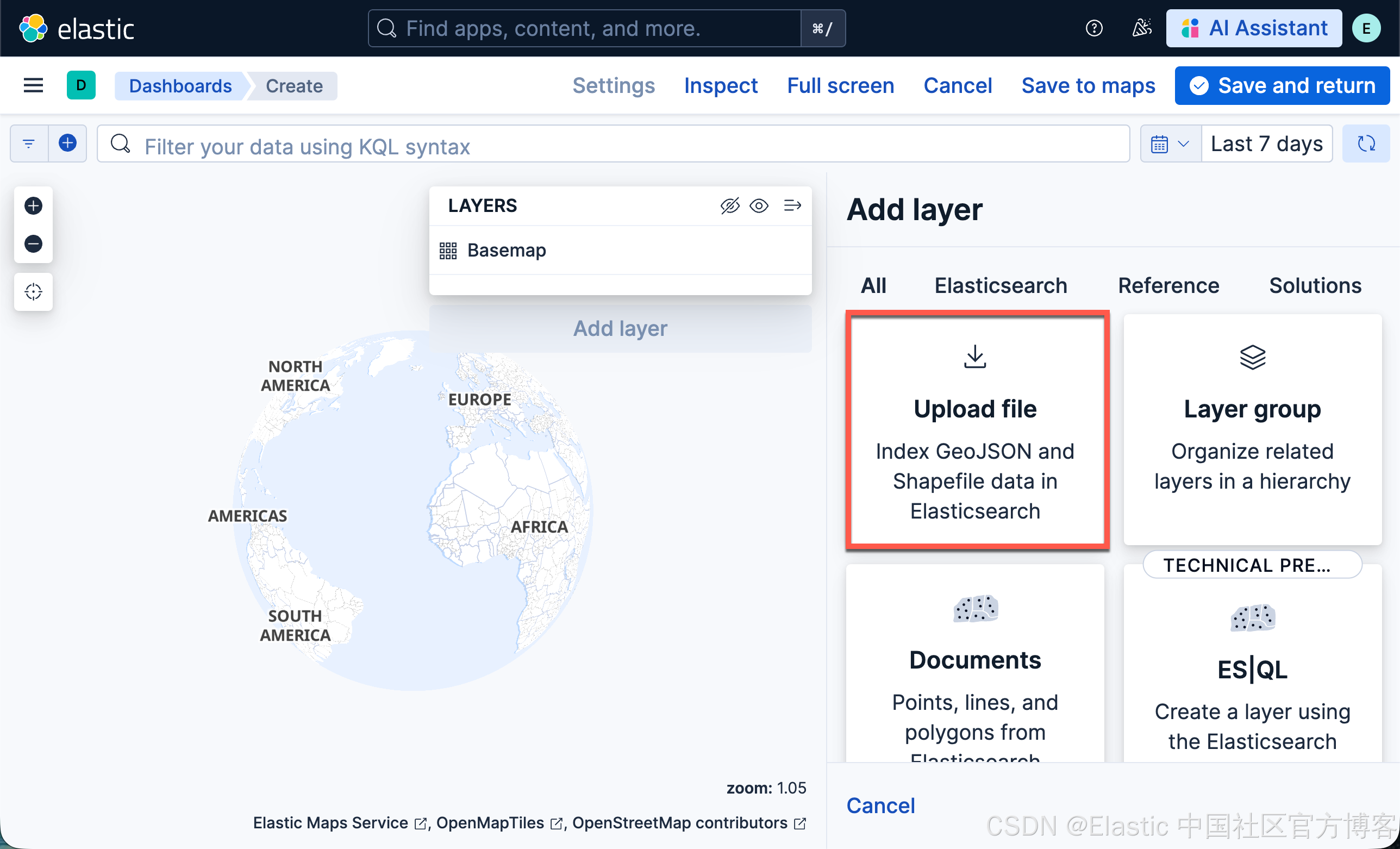
- 选择 Upload file
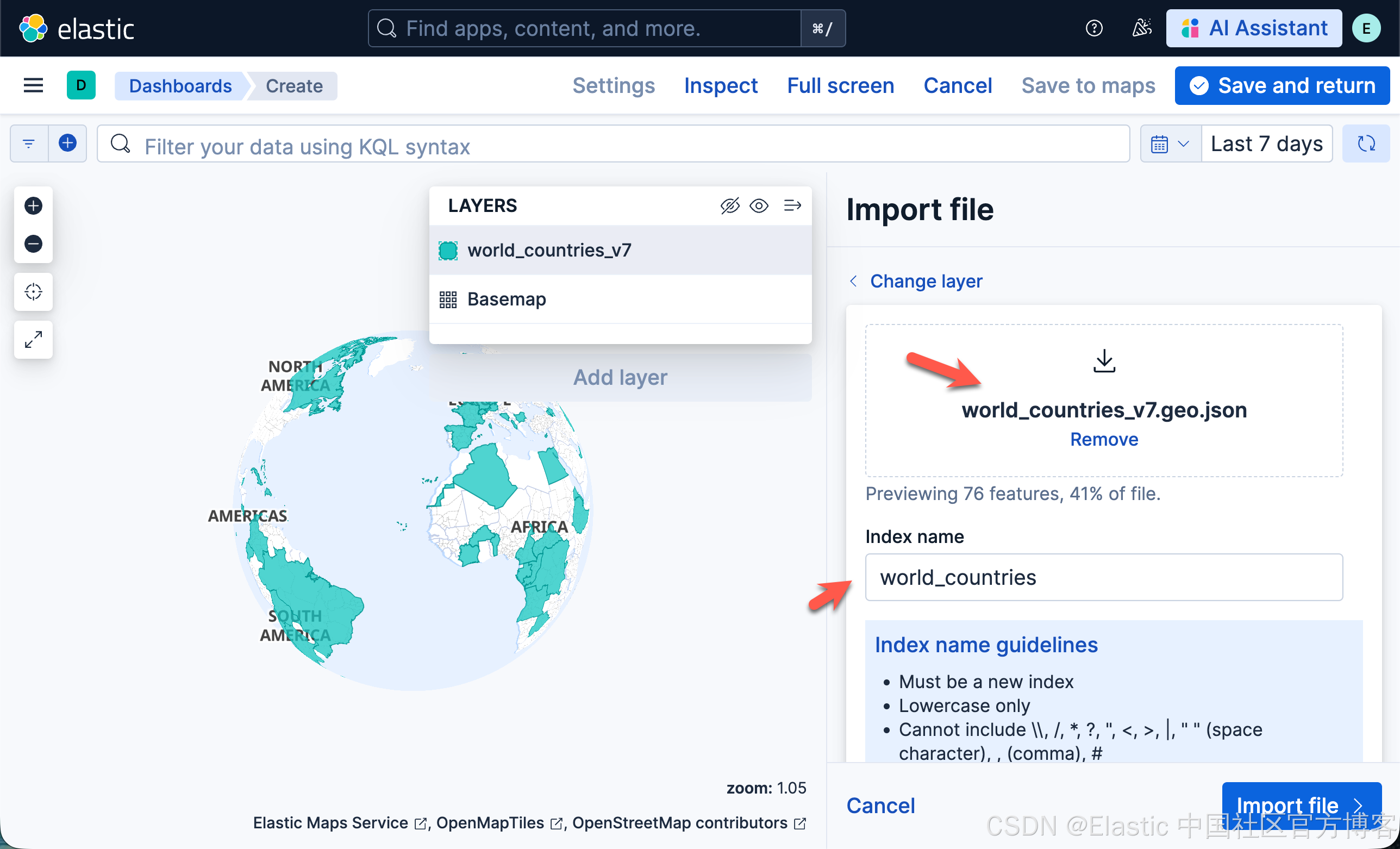
- 在文件选择器中选择世界国家 GeoJSON 文件
- 将 Index name 设置为 world_countries
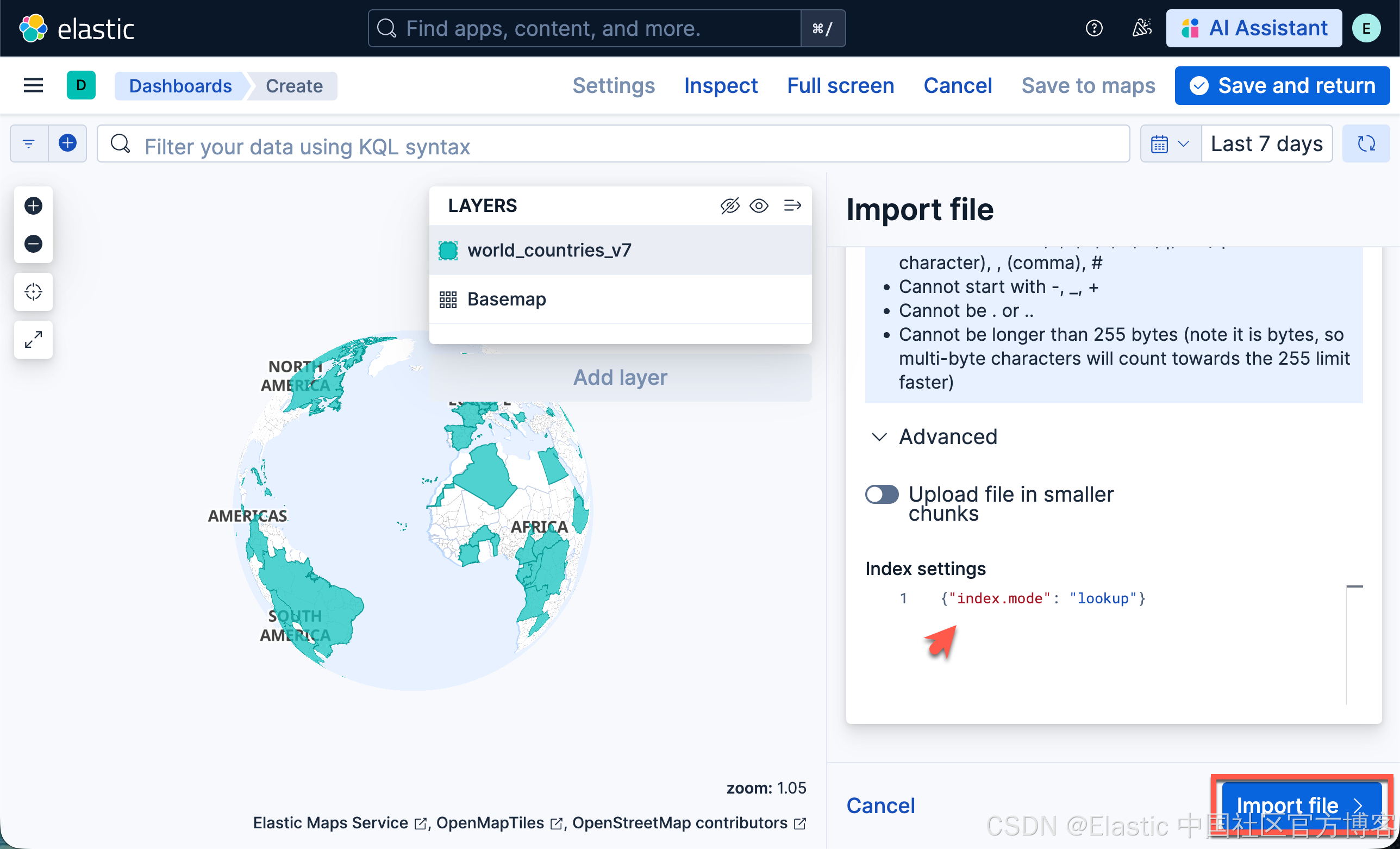
- 打开 Advanced 部分
- 将 Index settings 设置为 { "index.mode": "lookup" }。
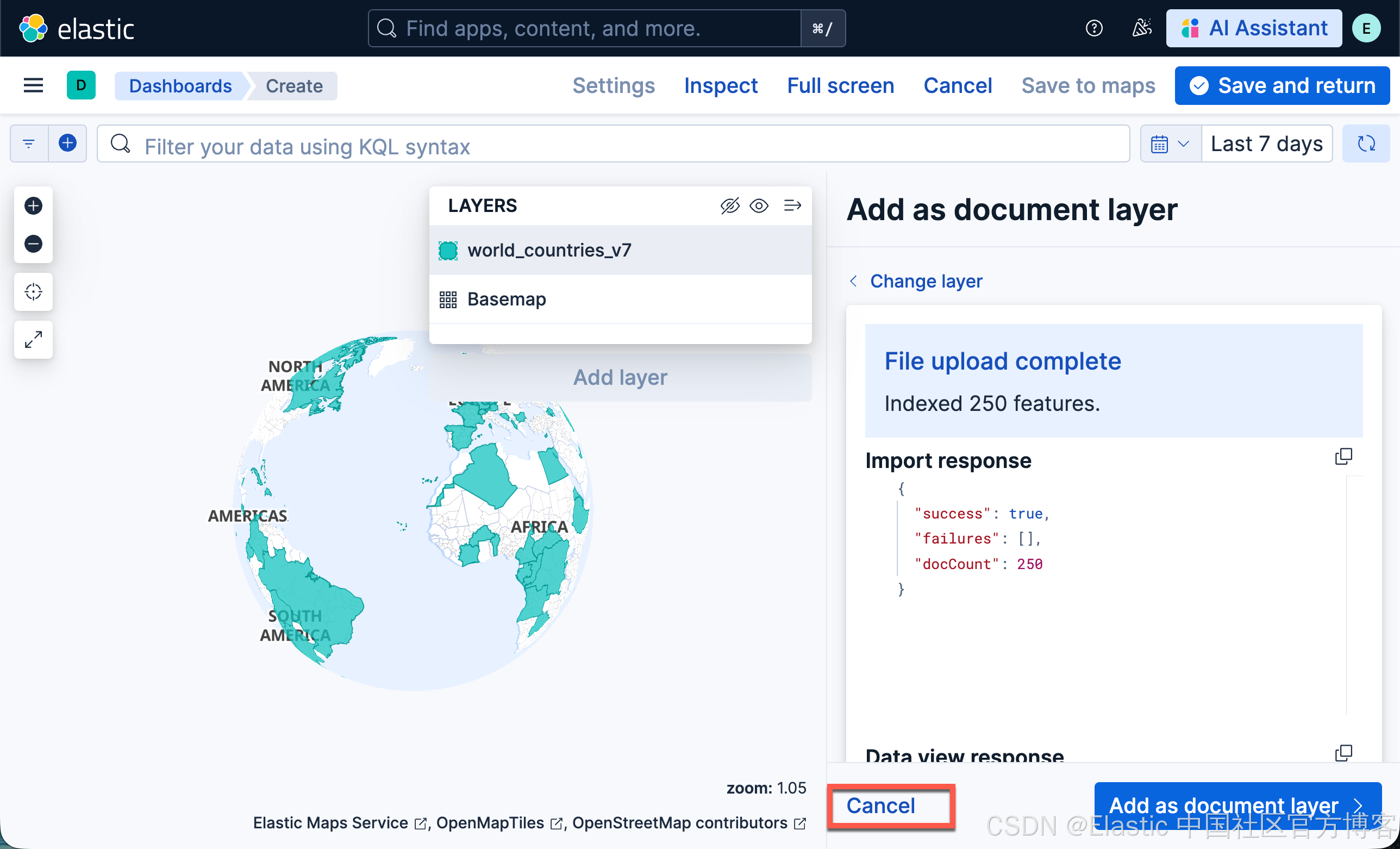
添加 choropleth 图层
- 点击 Add layer
- 选择 ES|QL
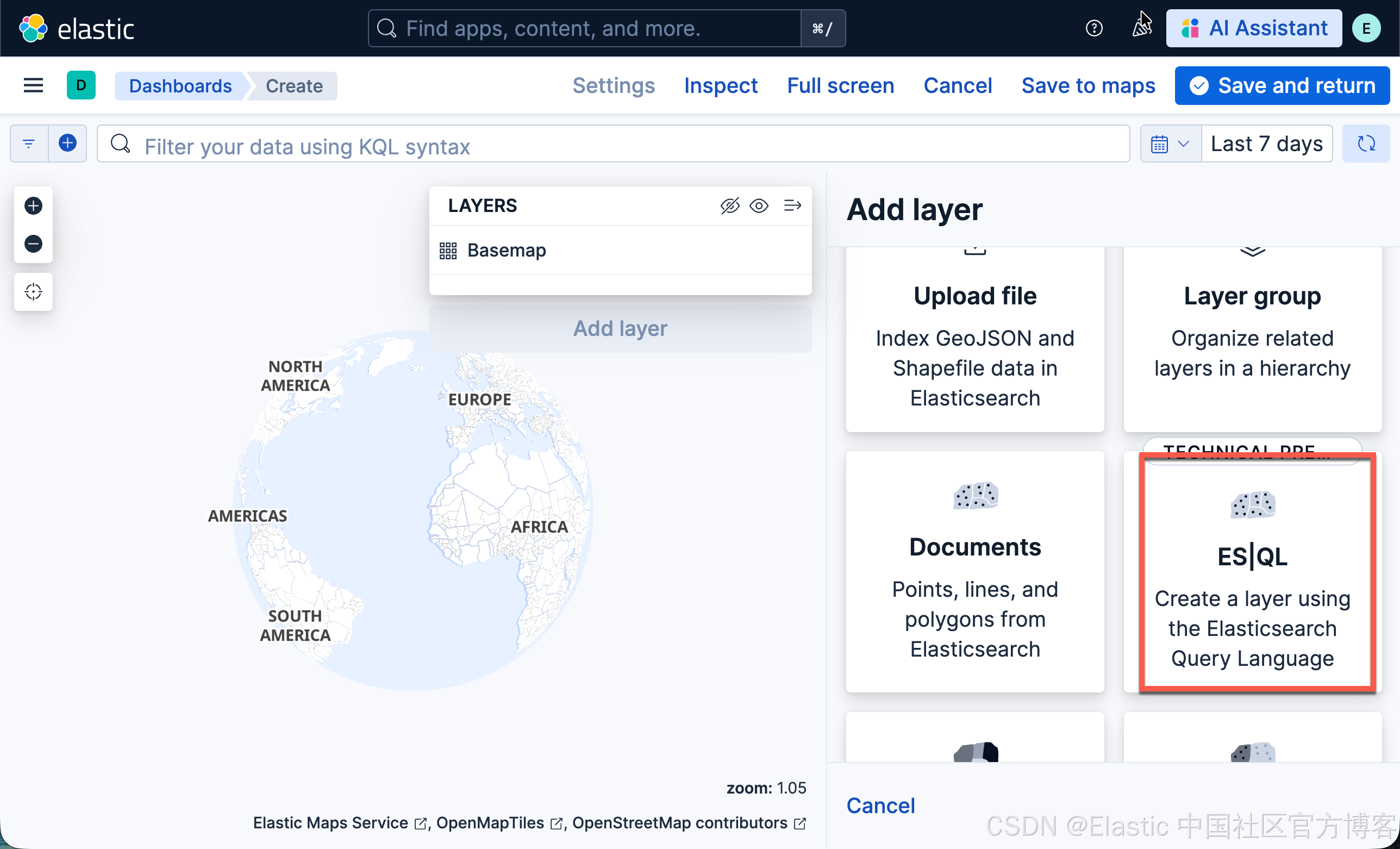
-
将 ES|QL statement 设置为
FROM kibana_sample_data_logs
| STATS count = COUNT() BY geo.dest
| RENAME geo.dest AS iso2.keyword
| LOOKUP JOIN world_countries ON iso2.keyword
| RENAME iso2.keyword AS geo.dest
| KEEP count, geometry, geo.dest
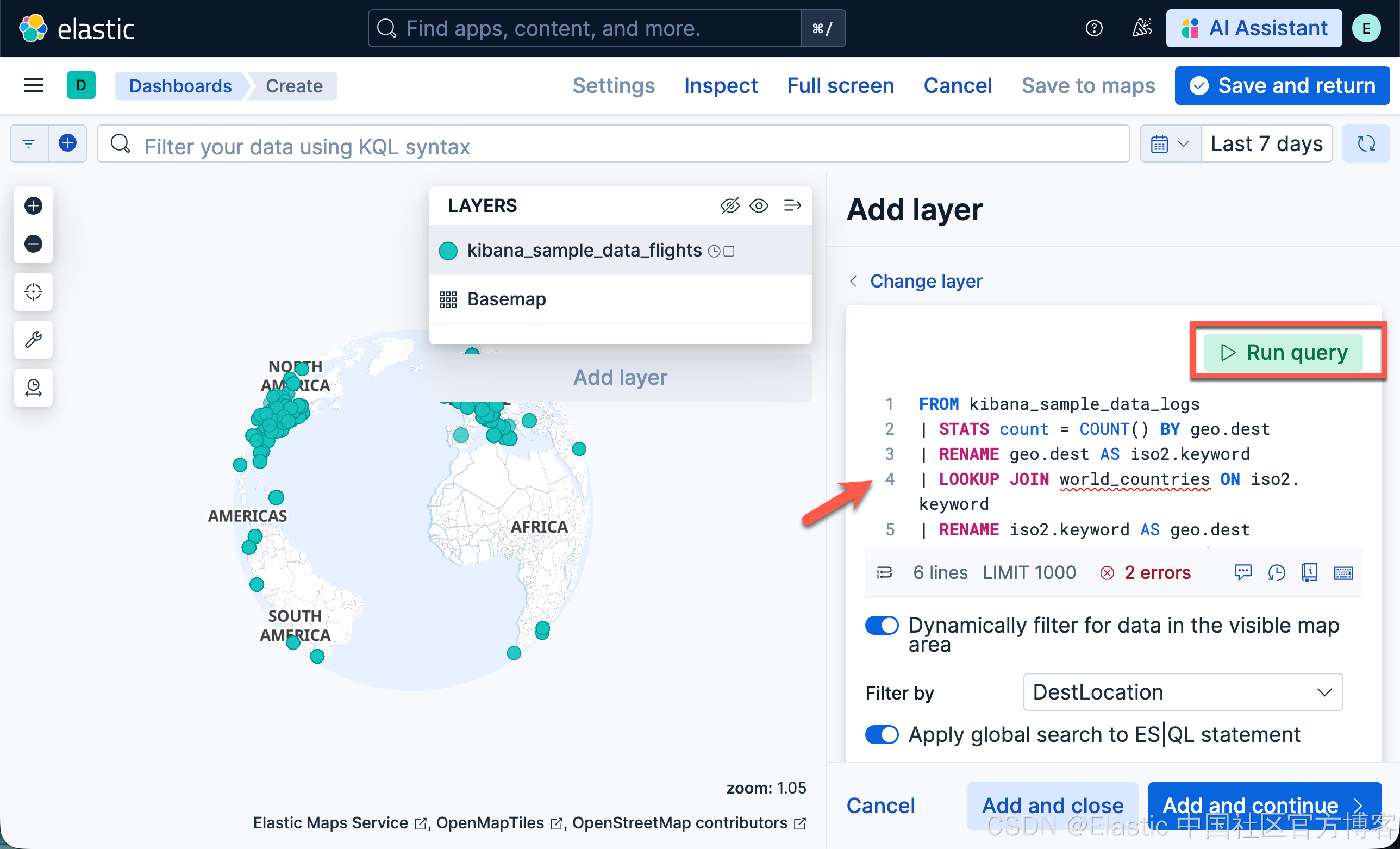
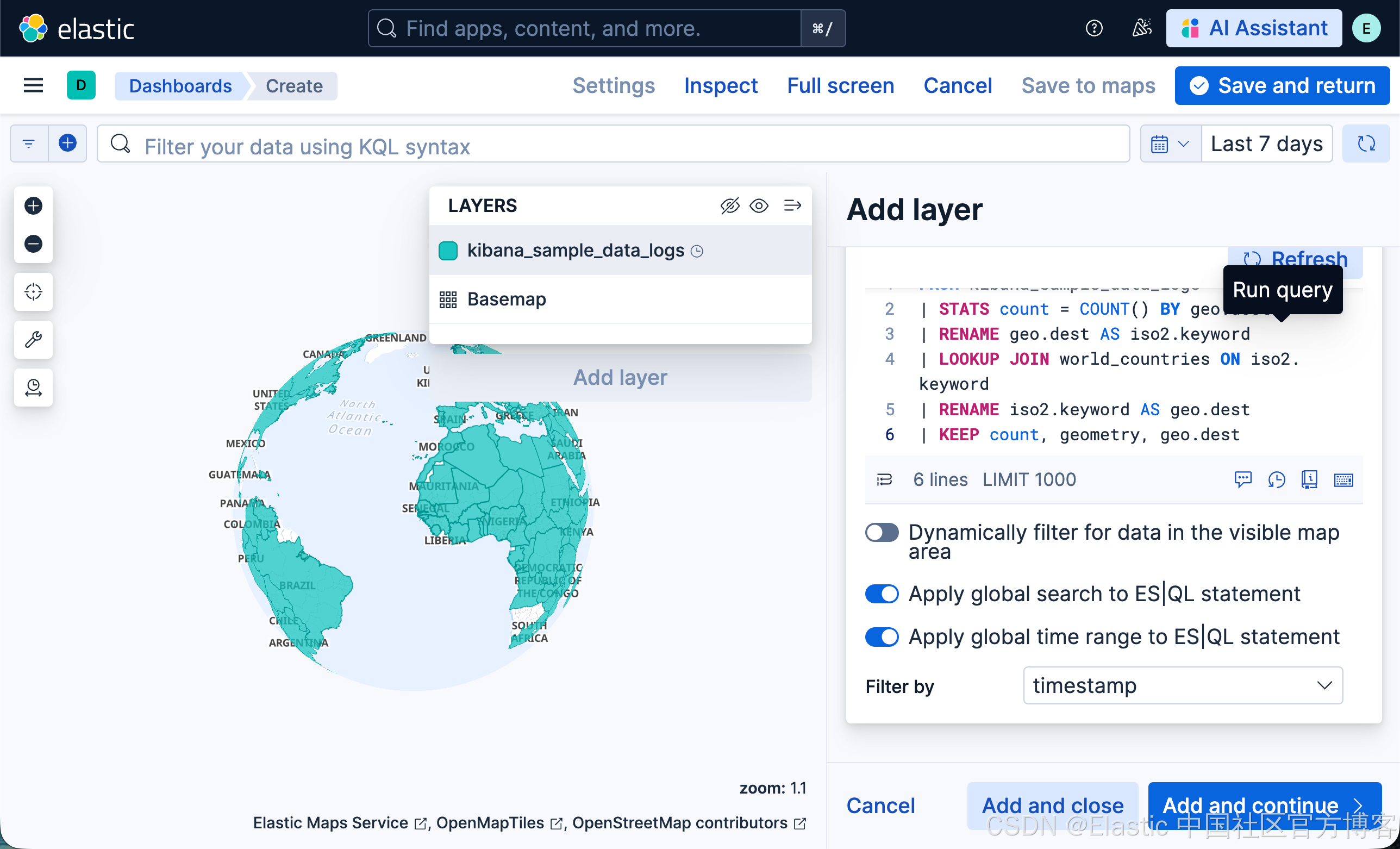
- 点击 Add and continue
- 在 Layer settings 中,设置:
- 将 Name 设置为 Total Requests by Destination。
- 将 Opacity 设置为 50%。
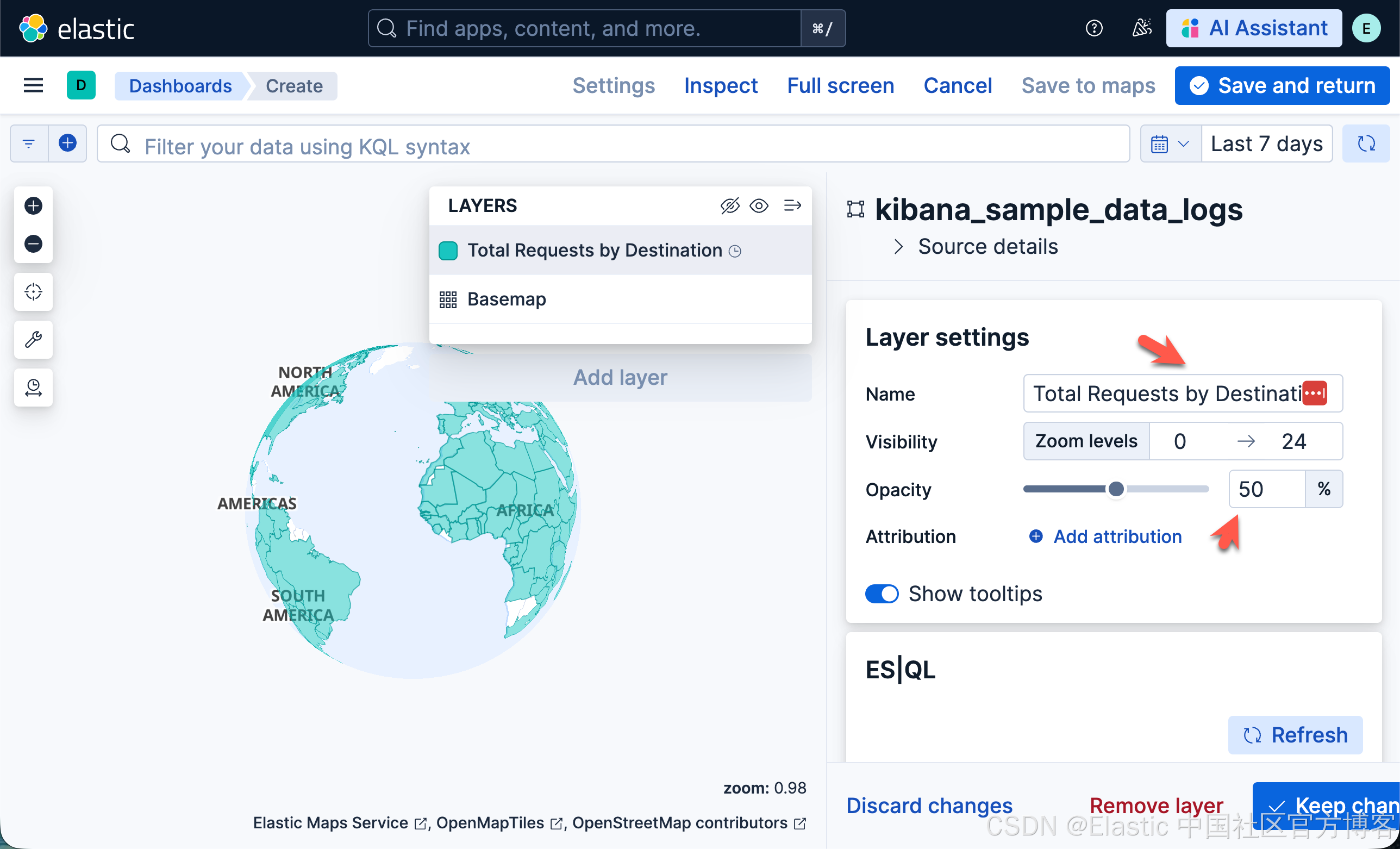
- 在 Layer style 中
- 将 Fill color 设置为 By value by count。选择 "grey to black" 颜色渐变。
- 将 Border color 设置为 "white"。4.
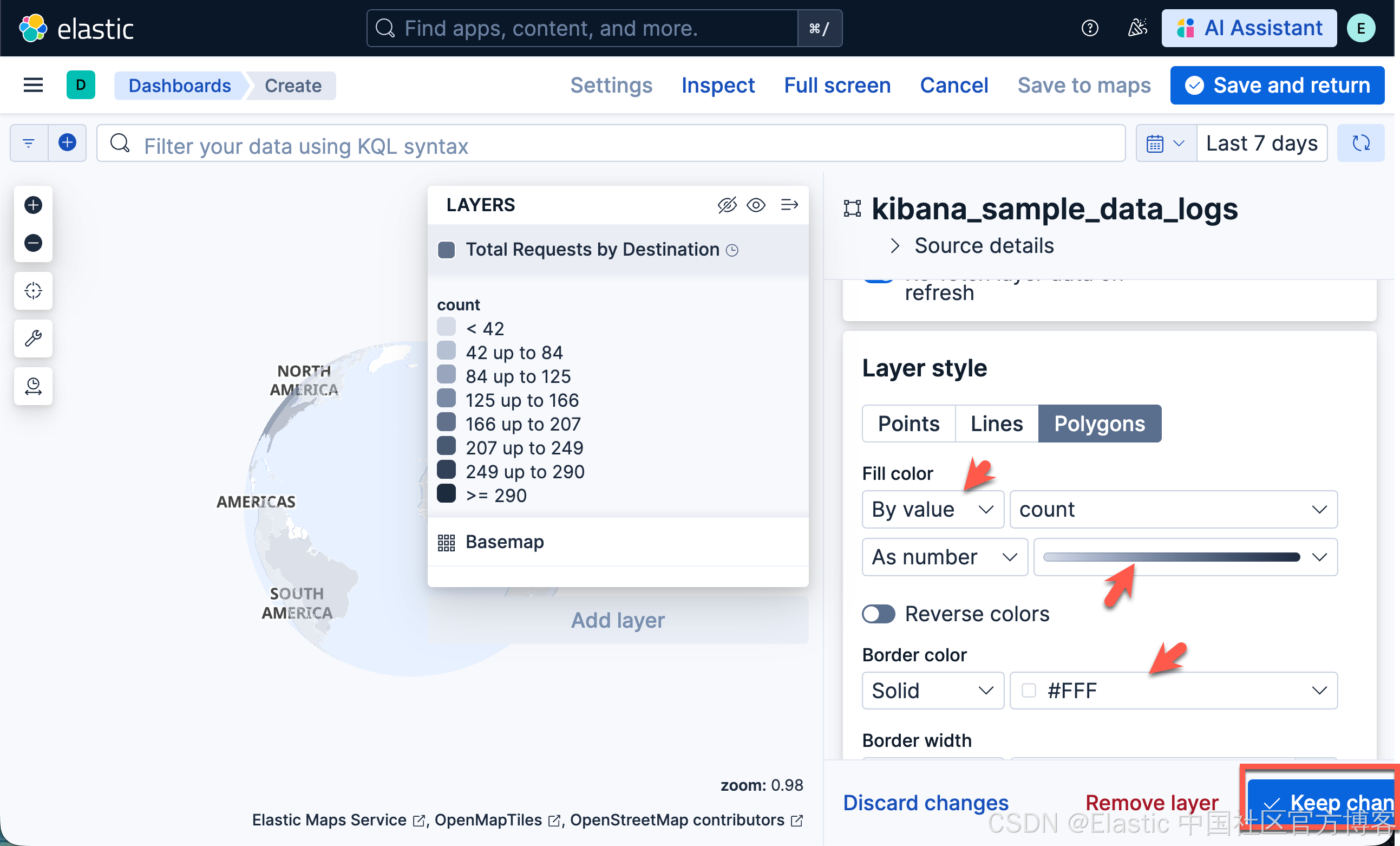
- 点击 Keep changes。你的地图现在应该看起来像
步骤 3. 为 Elasticsearch 数据添加图层
为了避免一次向用户展示过多数据,你将为 Elasticsearch 数据添加两个图层。第一个图层在用户放大地图时显示单个文档。第二个图层在用户缩小地图时显示聚合数据。
为单个文档添加图层
此图层将 web 日志文档显示为点。
该图层仅在用户放大时可见。
- 点击 Add layer
- 选择 ES|QL
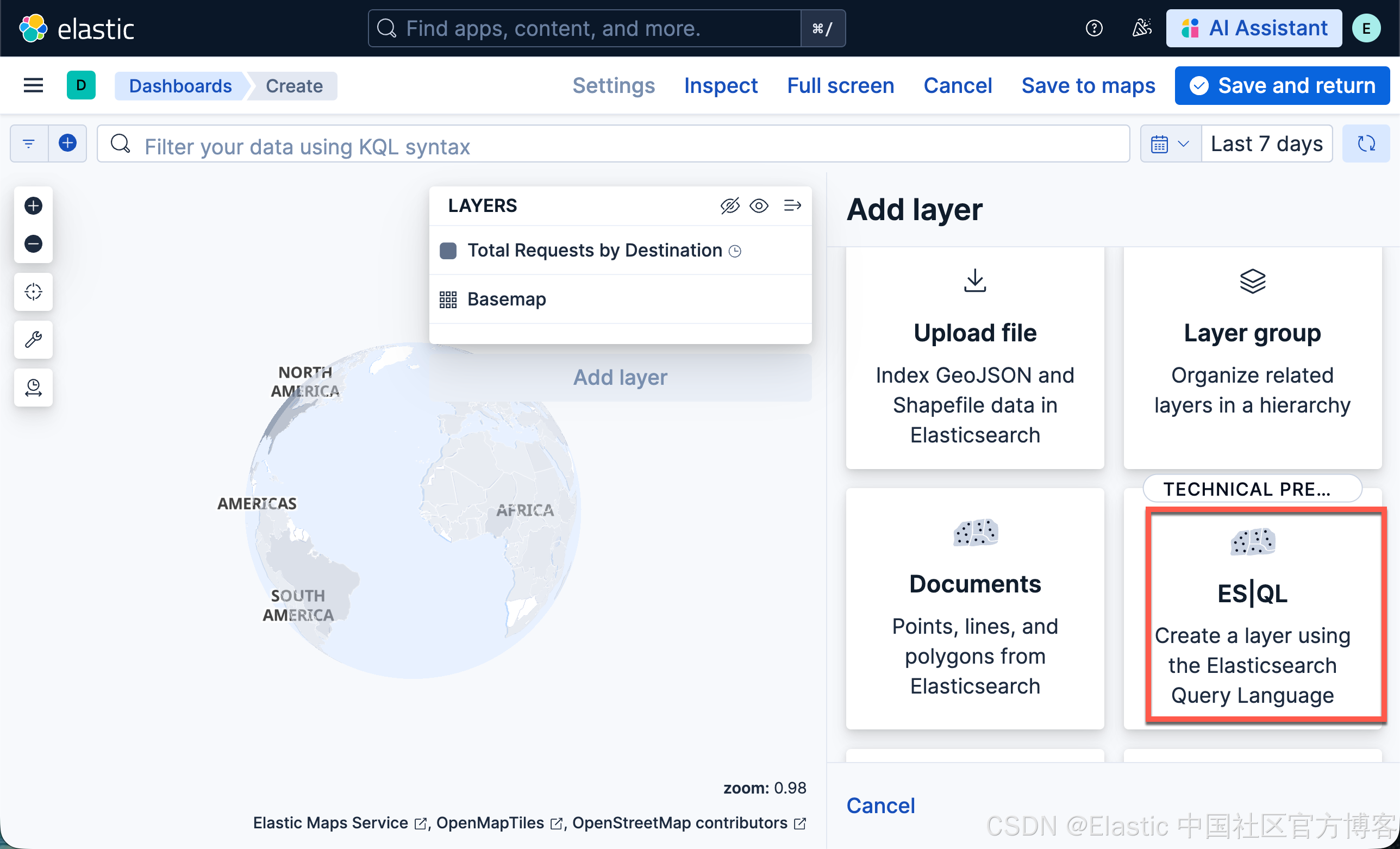
-
将 ES|QL statement 设置为
FROM kibana_sample_data_logs
| KEEP geo.coordinates, agent, bytes, clientip,
host, machine.os, request, response, timestamp
| LIMIT 10000 -
在 ES|QL 编辑器中点击 Run query
-
点击 Add and continue
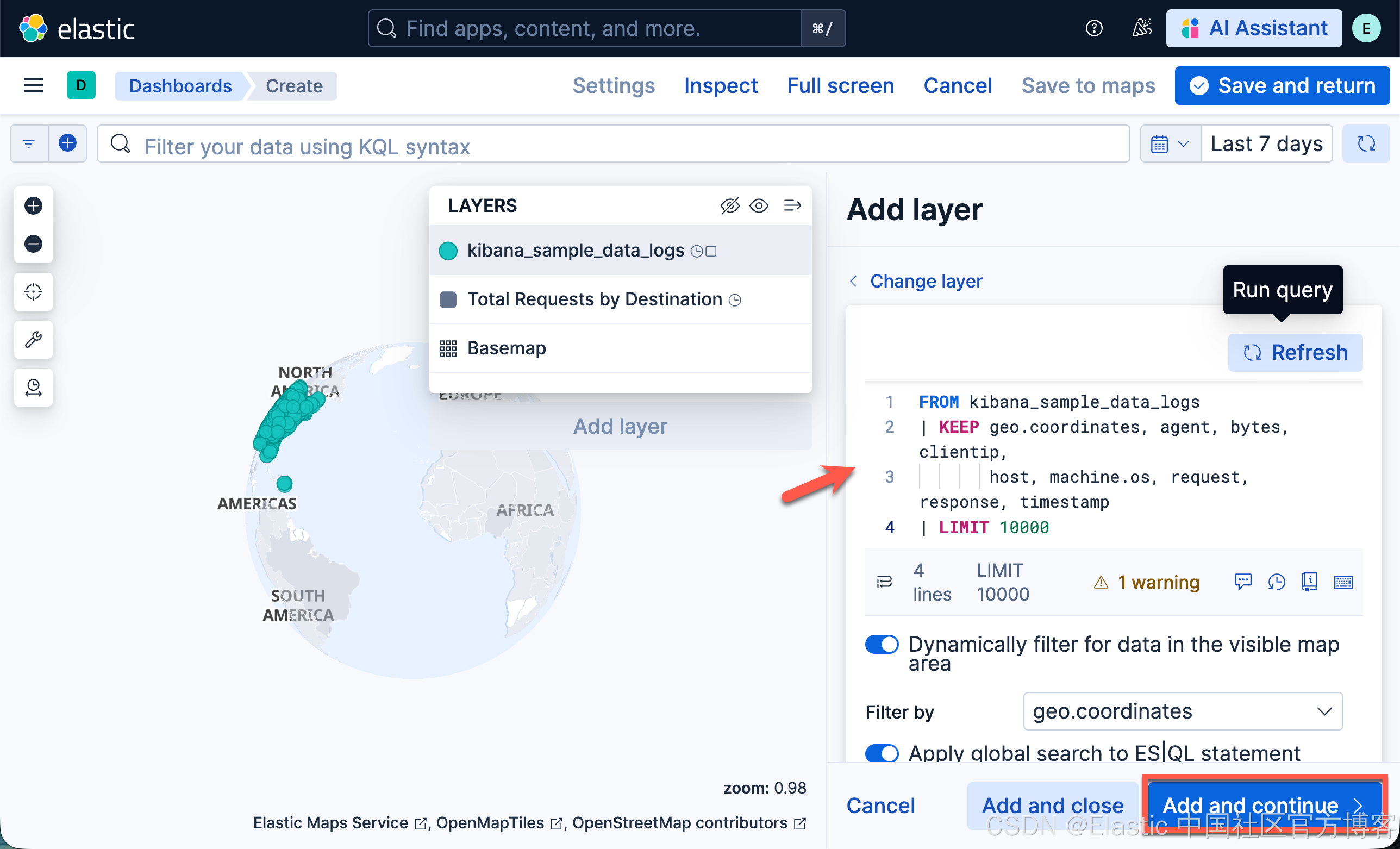
- 在 Layer settings 中,设置:
- 将 Name 设置为 Actual Requests。
- 将 Visibility 设置为范围 9, 24。
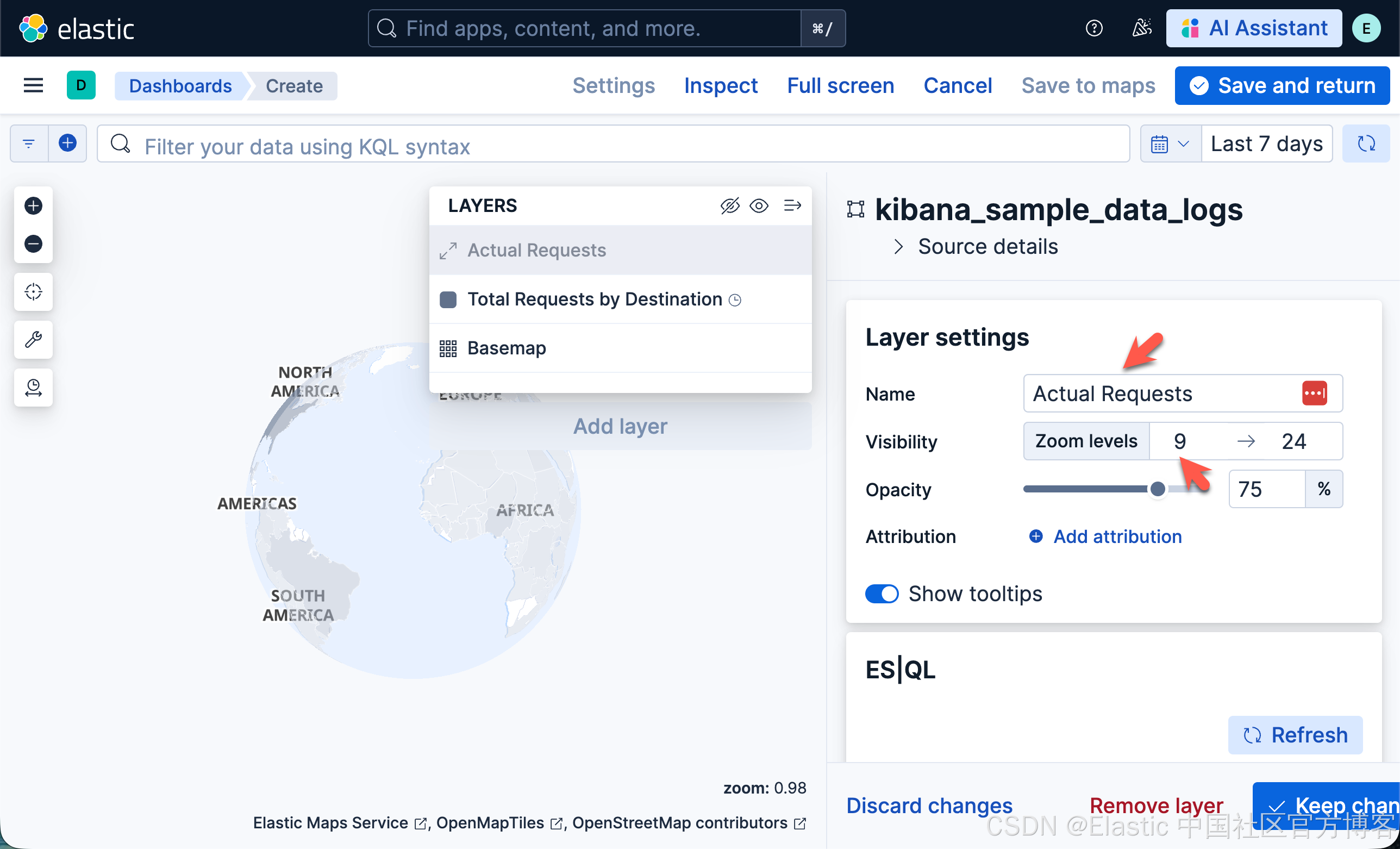
- 在 Layer style 中,设置:
- 将 Fill color 设置为 #2200FF。
- 将 Border width 设置为 0。
- 点击 Keep changes。你的地图现在应该看起来像
为聚合数据添加图层
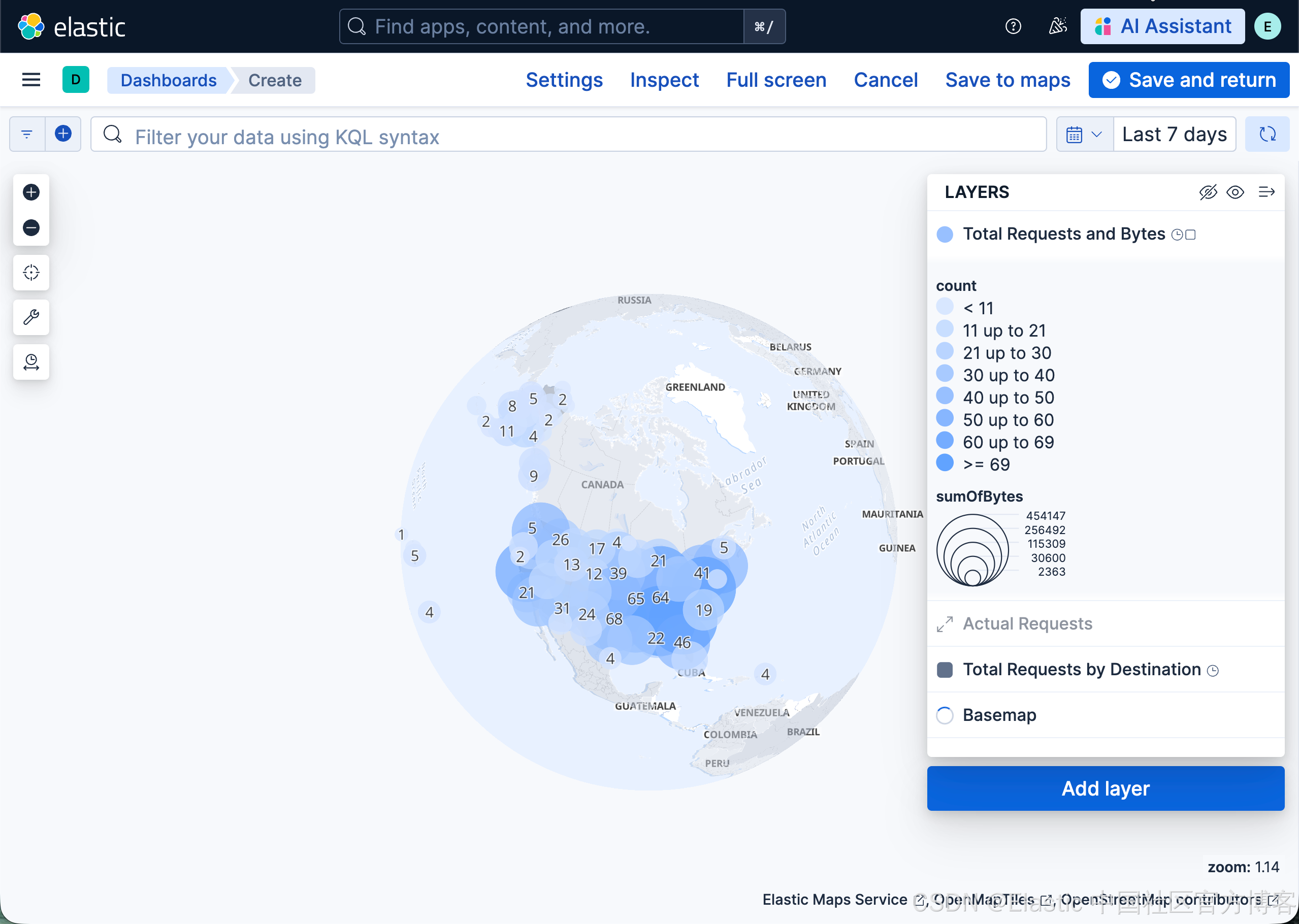
你将创建一个聚合数据图层,并仅在地图缩小时显示。较深的颜色表示 web 日志流量更多的网格,较浅的颜色表示流量较少的网格。较大的圆表示传输总字节更多的网格,较小的圆表示字节较少的网格。
- 点击 Add layer
- 选择 ES|QL
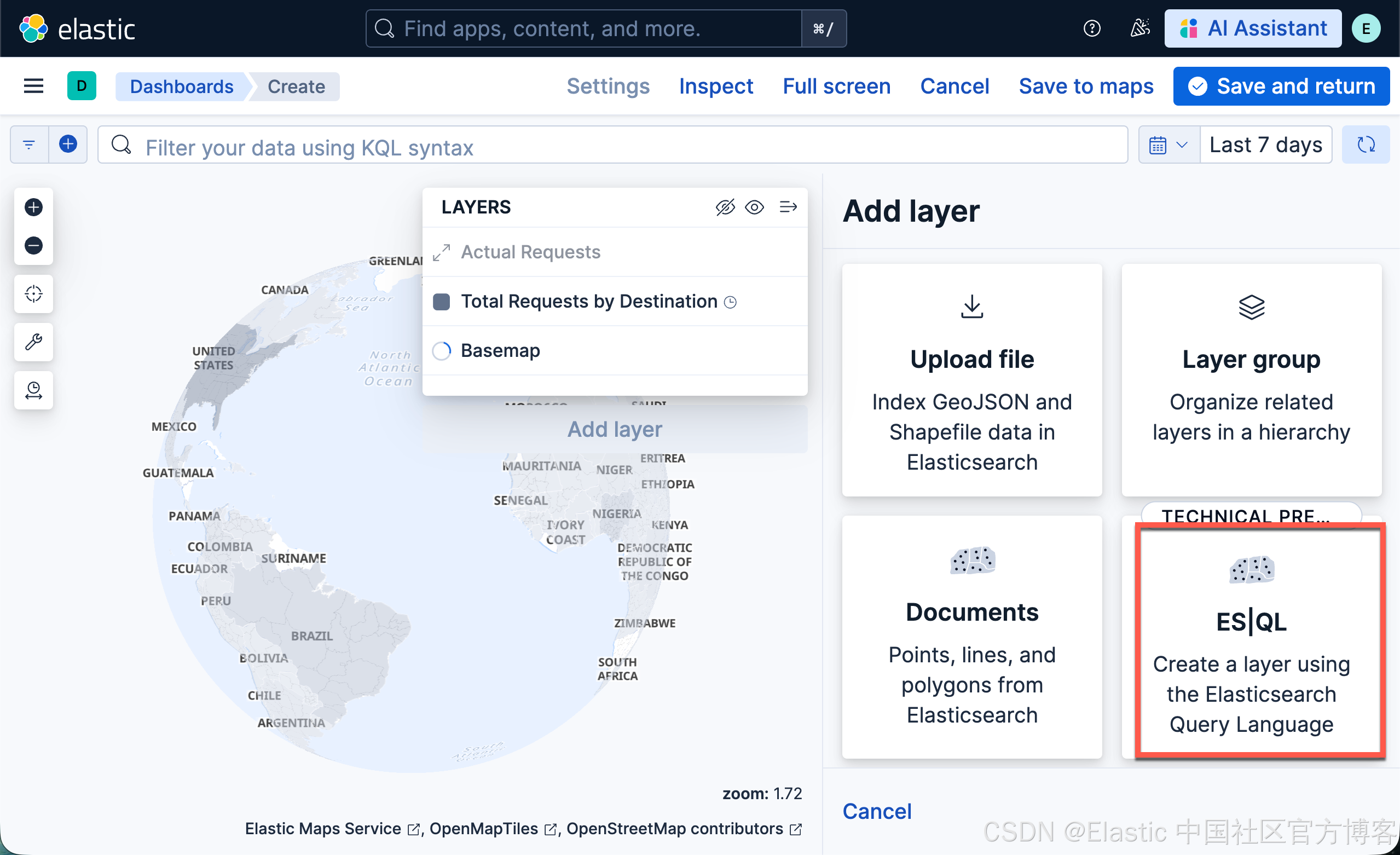
-
将 ES|QL statement 设置为
FROM kibana_sample_data_logs
| EVAL geotile = ST_GEOTILE(geo.coordinates, 6)
| STATS count = COUNT(geotile),
sumOfBytes = SUM(bytes),
centroid = ST_CENTROID_AGG(geo.coordinates) BY geotile
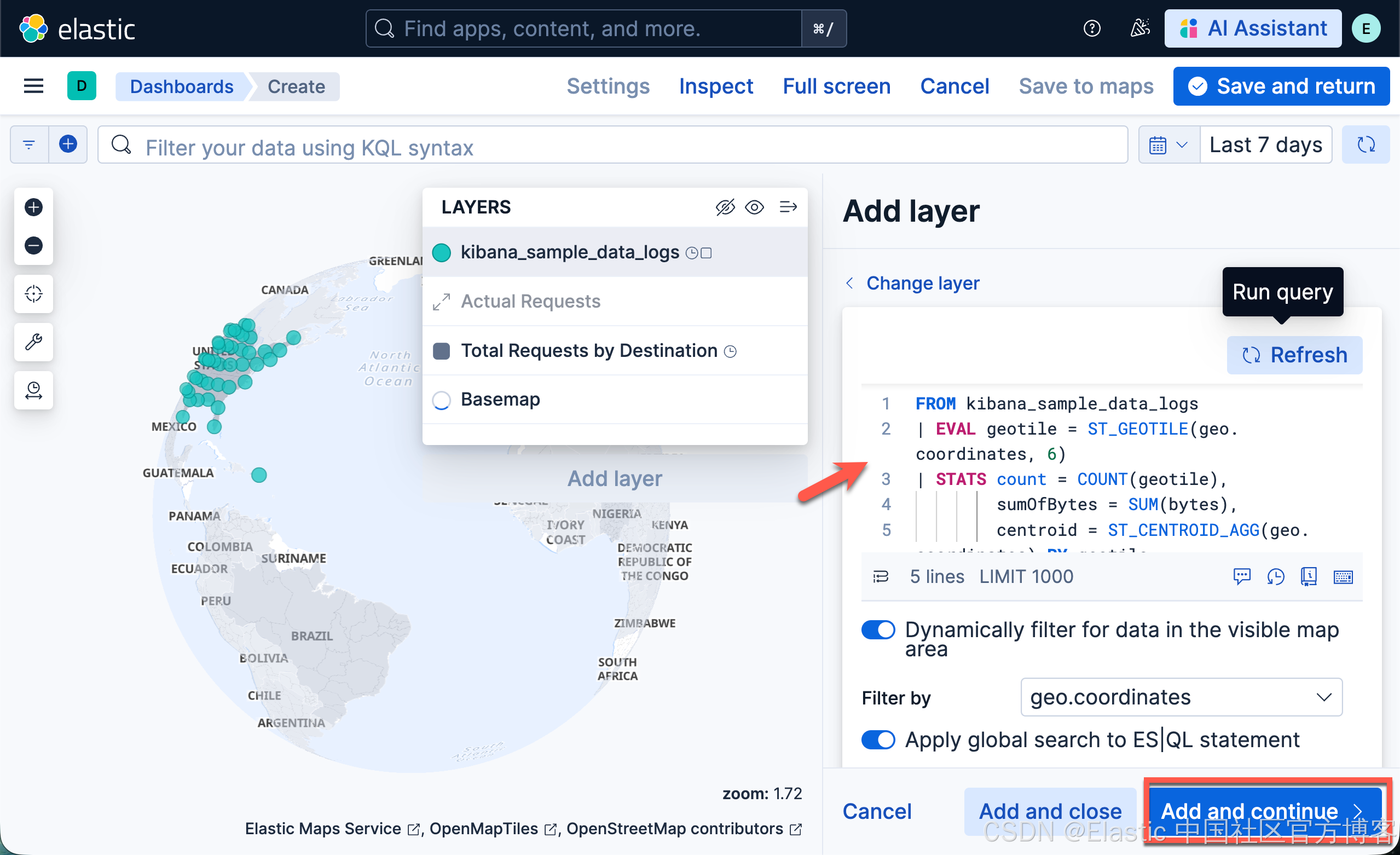
- 在 ES|QL 编辑器中点击 Run query
- 点击 Add 并继续
- 在 Layer settings 中,设置:
- 将 Name 设置为 Total Requests and Bytes。
- 将 Visibility 设置为范围 0, 9。
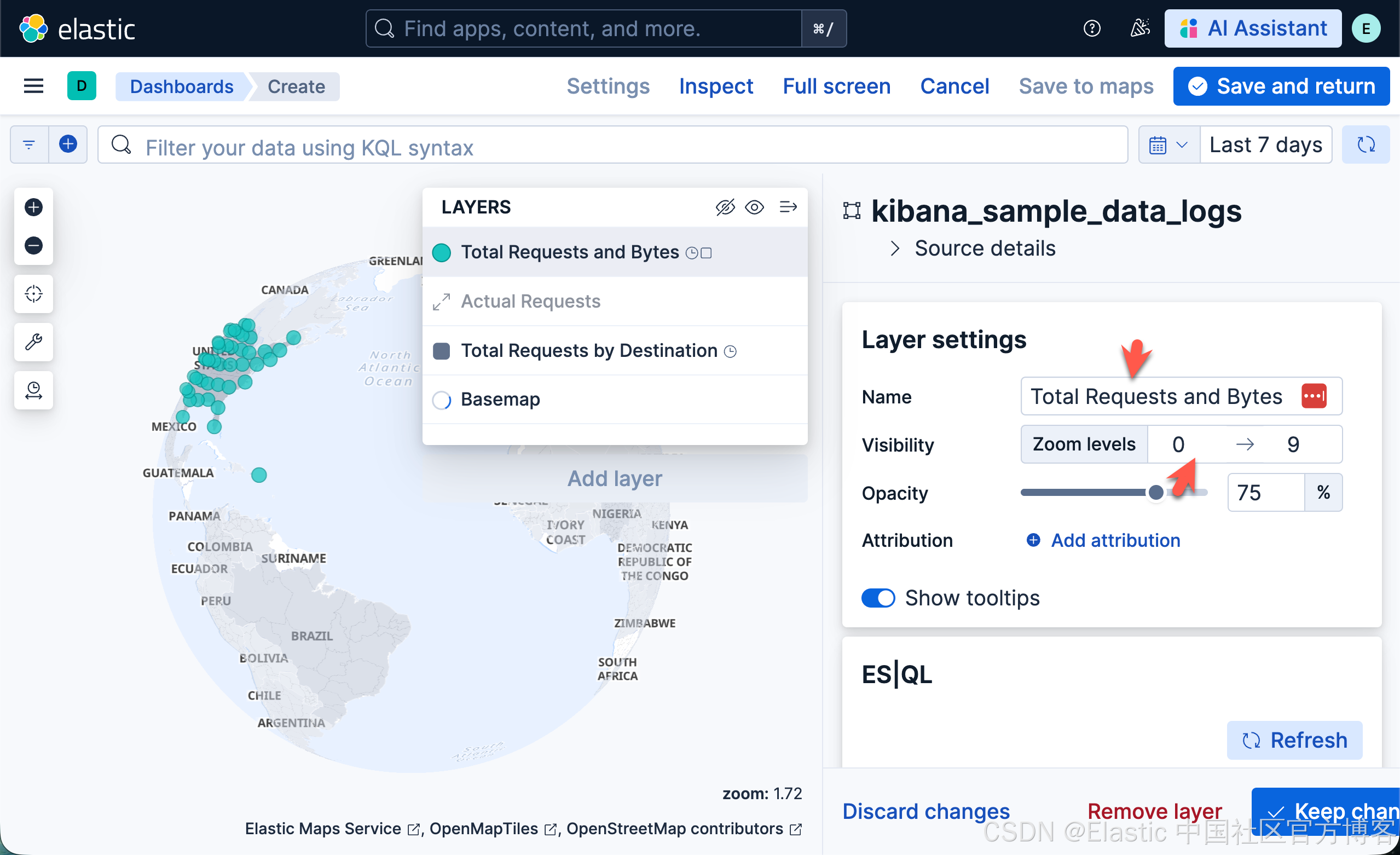
- 在 Layer style 中,设置:
- 将 Fill color 设置为 By value by count
- 将 Border width 设置为 0。
- 将 Symbol size 设置为 By value by sumOfBytes。将最小尺寸设置为 7,最大尺寸设置为 25。
- 将 Label 设置为 By value by count
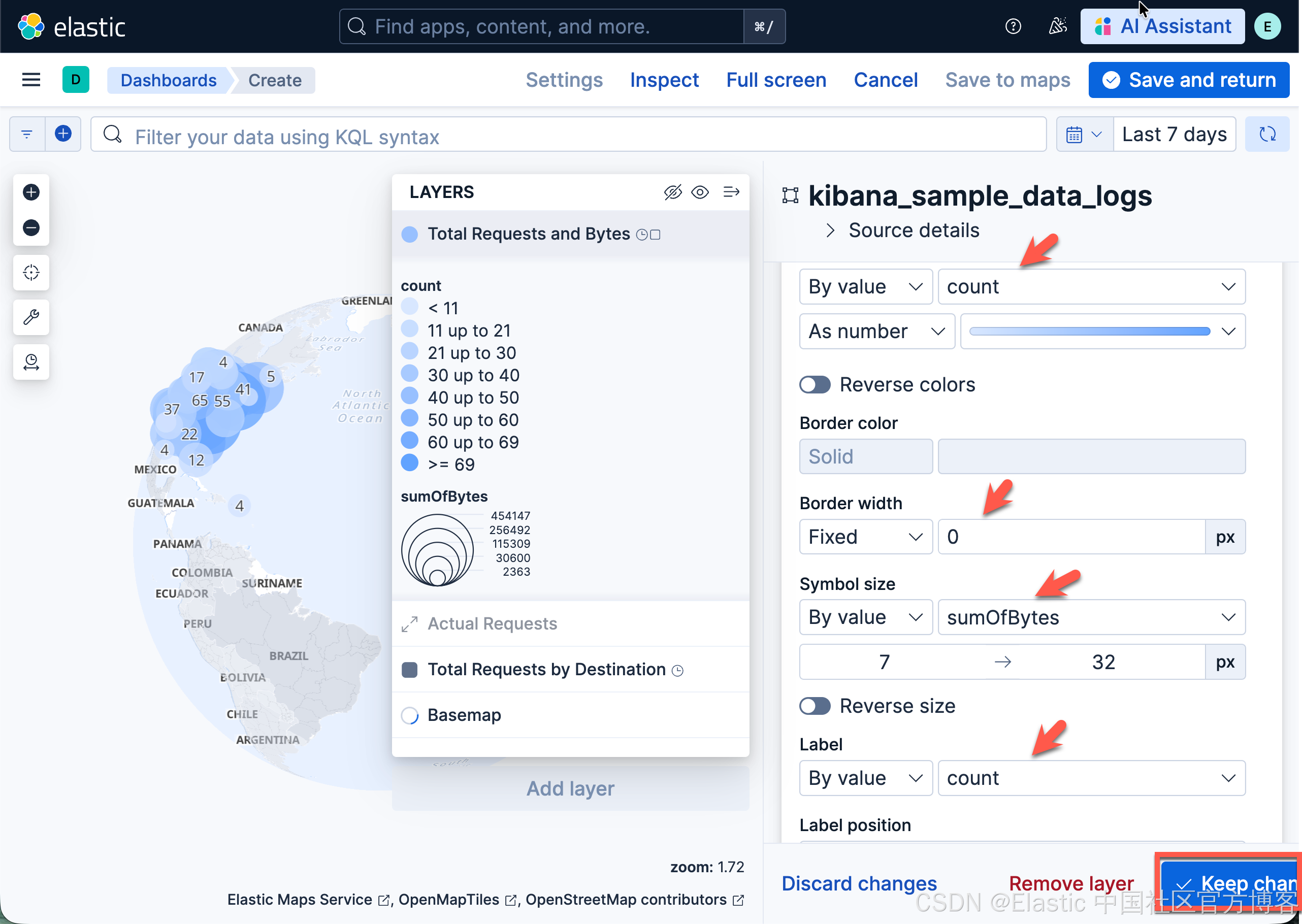
- 点击 Keep changes。你的地图现在应该看起来像
步骤 4. 按国家人口标准化 choropleth 图层
第 2 步创建的 choropleth 图层按 web 日志流量为世界各国着色。由于各国人口不同,直接比较各国的计数并不公平。人口较多的国家可能有更多的 web 流量,而人口较少的国家流量较少。相反,你希望按人口调整后的 web 日志流量为世界各国着色。
ES|QL 可以通过考虑每个国家的总人口来对 web 日志计数进行标准化。我们将可视化每 100,000 人的 web 日志计数,而不是原始计数。现在,我们可以比较各国的标准化计数。
索引世界国家人口
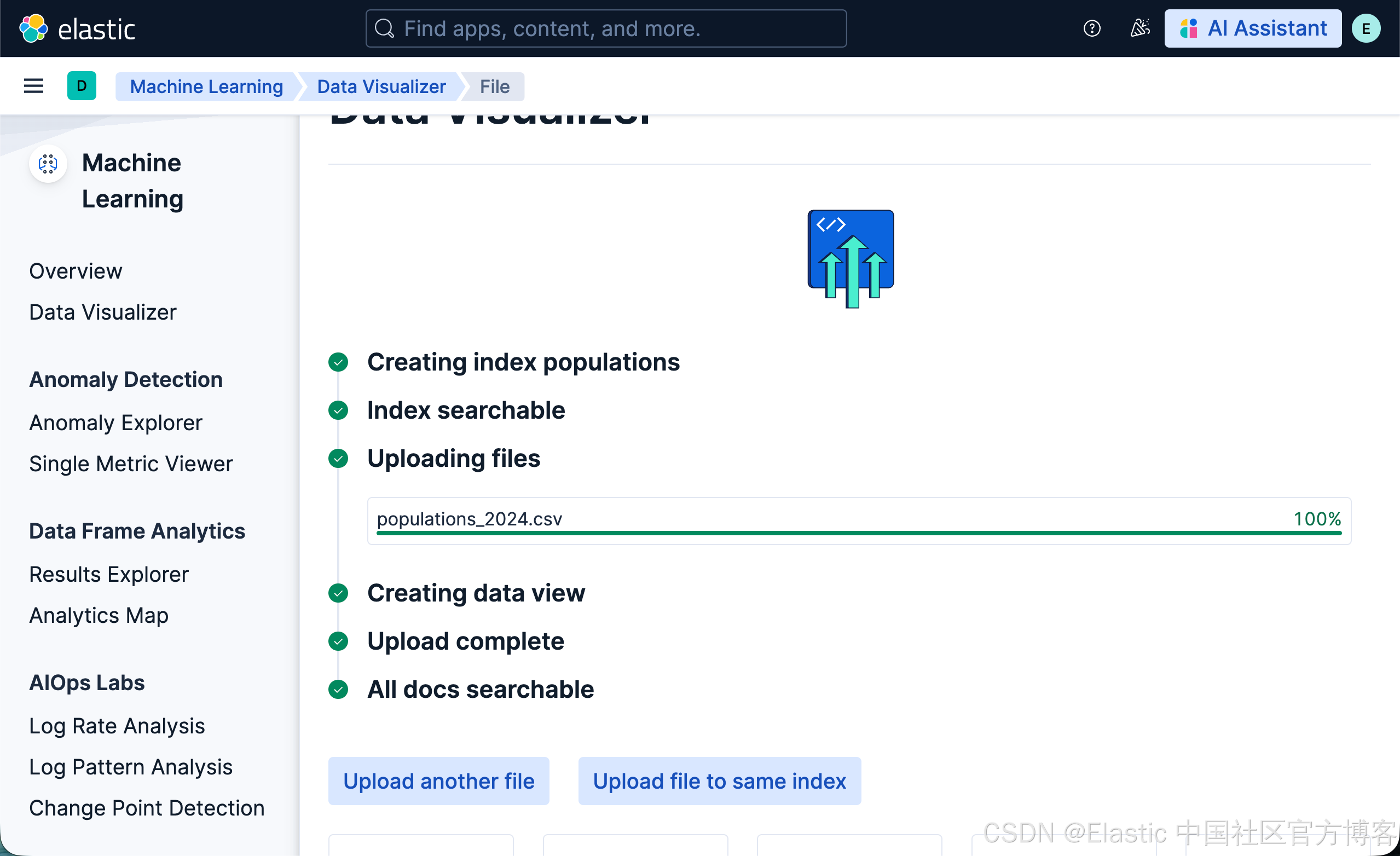
- 下载 populations_2024.csv文件。该文件来源于 World Bank Group。 下载完毕后,我们必须重新命名文件后缀为 .csv 而不是 .txt。
- 在 Kibana 中,通过全局搜索字段进入 File upload。
- 在文件选择器中选择 populations_2024.csv
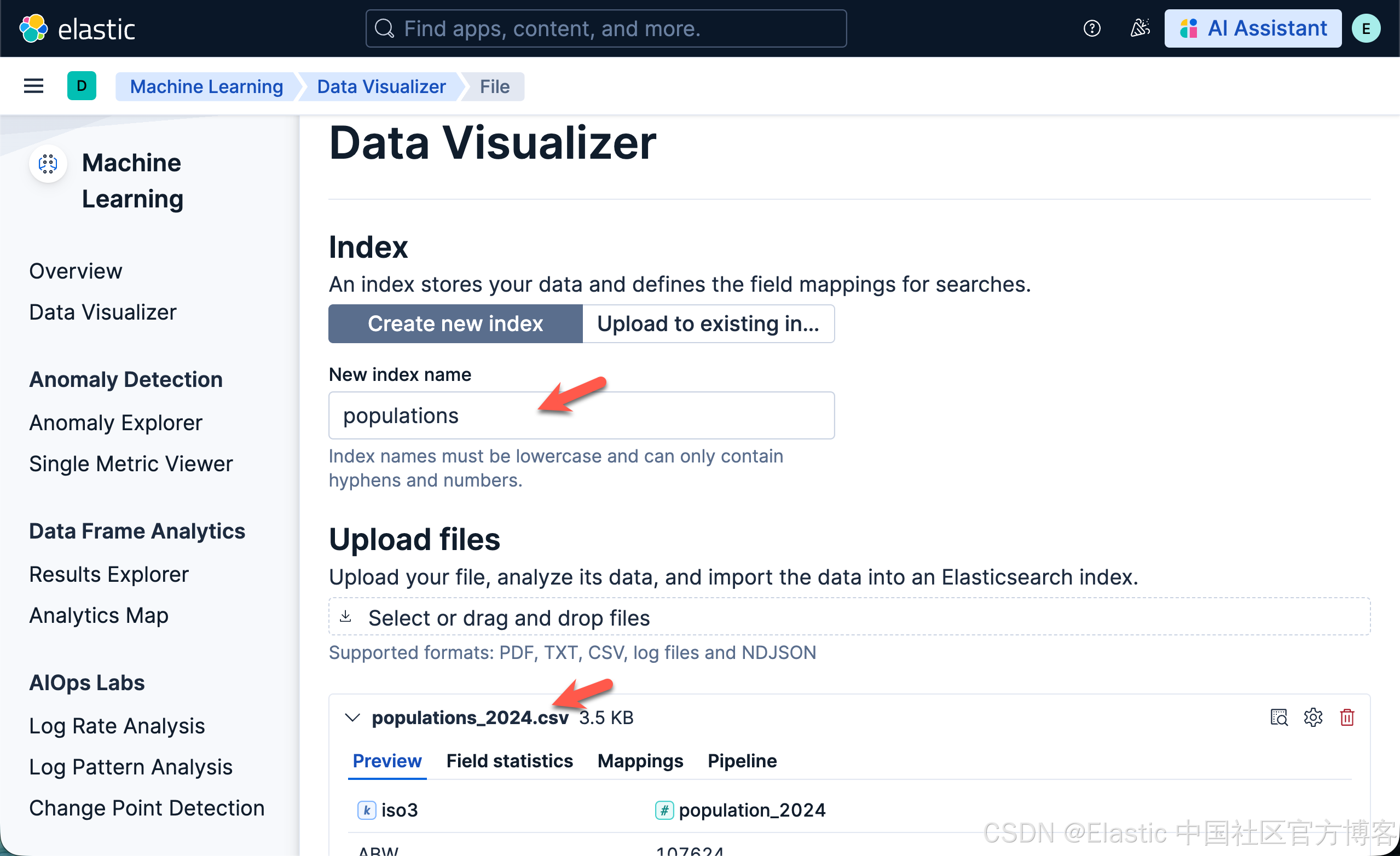
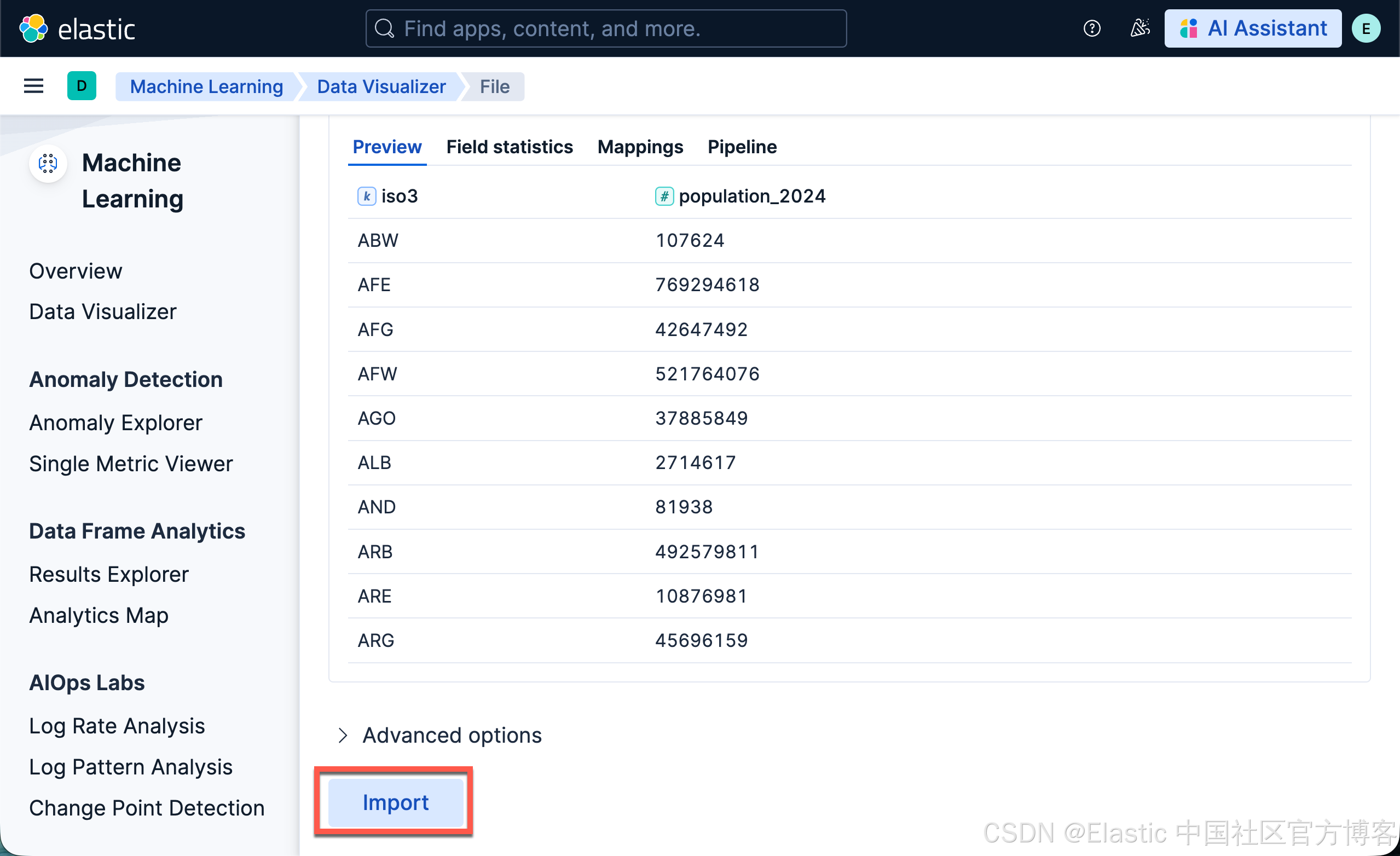
- 将 New index name 设置为 populations
- 点击 Import
向 world_countries 索引添加人口字段
使用 enrich processor 将人口数据添加到世界国家集合中。
-
通过导航菜单或全局搜索字段进入 Developer tools。
-
创建一个 match enrichment policy
PUT /_enrich/policy/population_lookup
{
"match": {
"indices": "populations",
"match_field": "iso3",
"enrich_fields": [ "population_2024"]
}
} -
要初始化该策略,运行:
POST /_enrich/policy/population_lookup/_execute
-
要创建一个 ingest pipeline,运行:
PUT _ingest/pipeline/add_population_to_world_countries
{
"processors": [
{
"enrich": {
"field": "iso3",
"policy_name": "population_lookup",
"target_field": "population",
"ignore_missing": true,
"ignore_failure": true
}
}
]
} -
要向 world_countries 添加人口数据,运行:
POST world_countries/_update_by_query?pipeline=add_population_to_world_countries
-
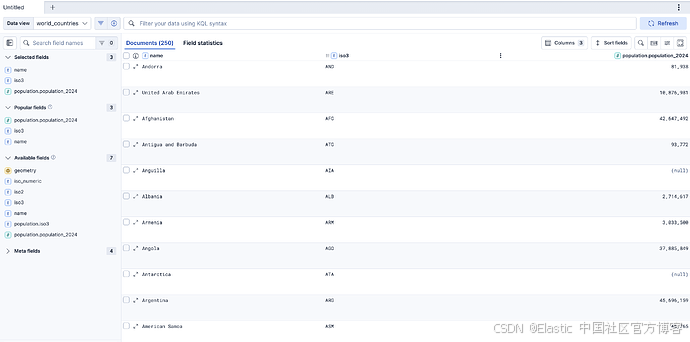
在 Discover 中查看 world_countries 索引。每一行现在都包含 population.population_2024 列。
在 ES|QL statement 中按人口标准化计数
-
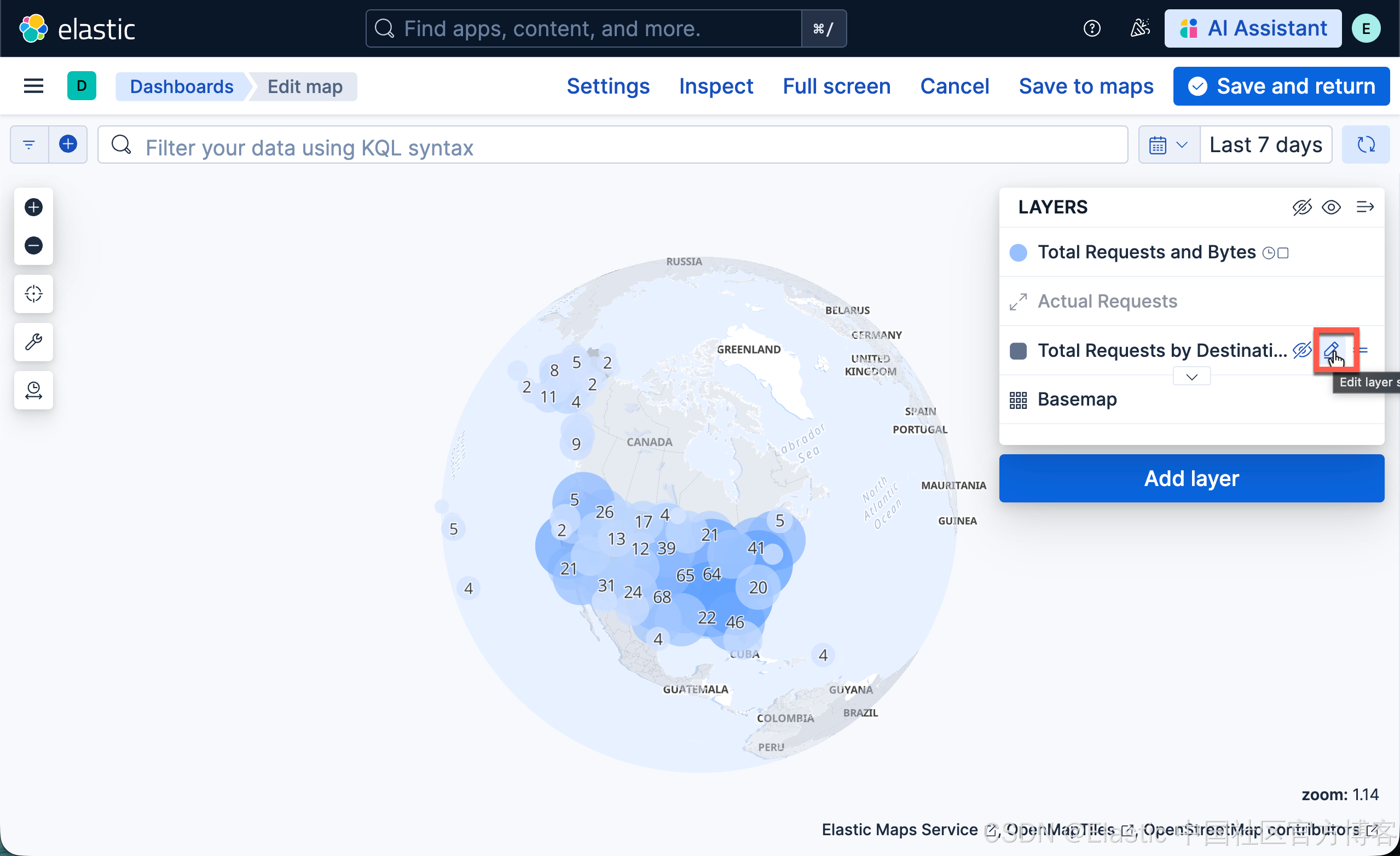
点击 Total Requests by Destination 图层的 edit 按钮。
-
将 ES|QL statement 替换为
FROM kibana_sample_data_logs
| STATS count = COUNT() BY geo.dest
| RENAME geo.dest AS iso2.keyword
| LOOKUP JOIN world_countries ON iso2.keyword
| RENAME iso2.keyword AS geo.dest
| KEEP count, geometry, geo.dest, population.population_2024
| EVAL normalized_count = TO_DOUBLE(count) / population.population_2024 * 100000
- 在 ES|QL 编辑器中点击 Run query
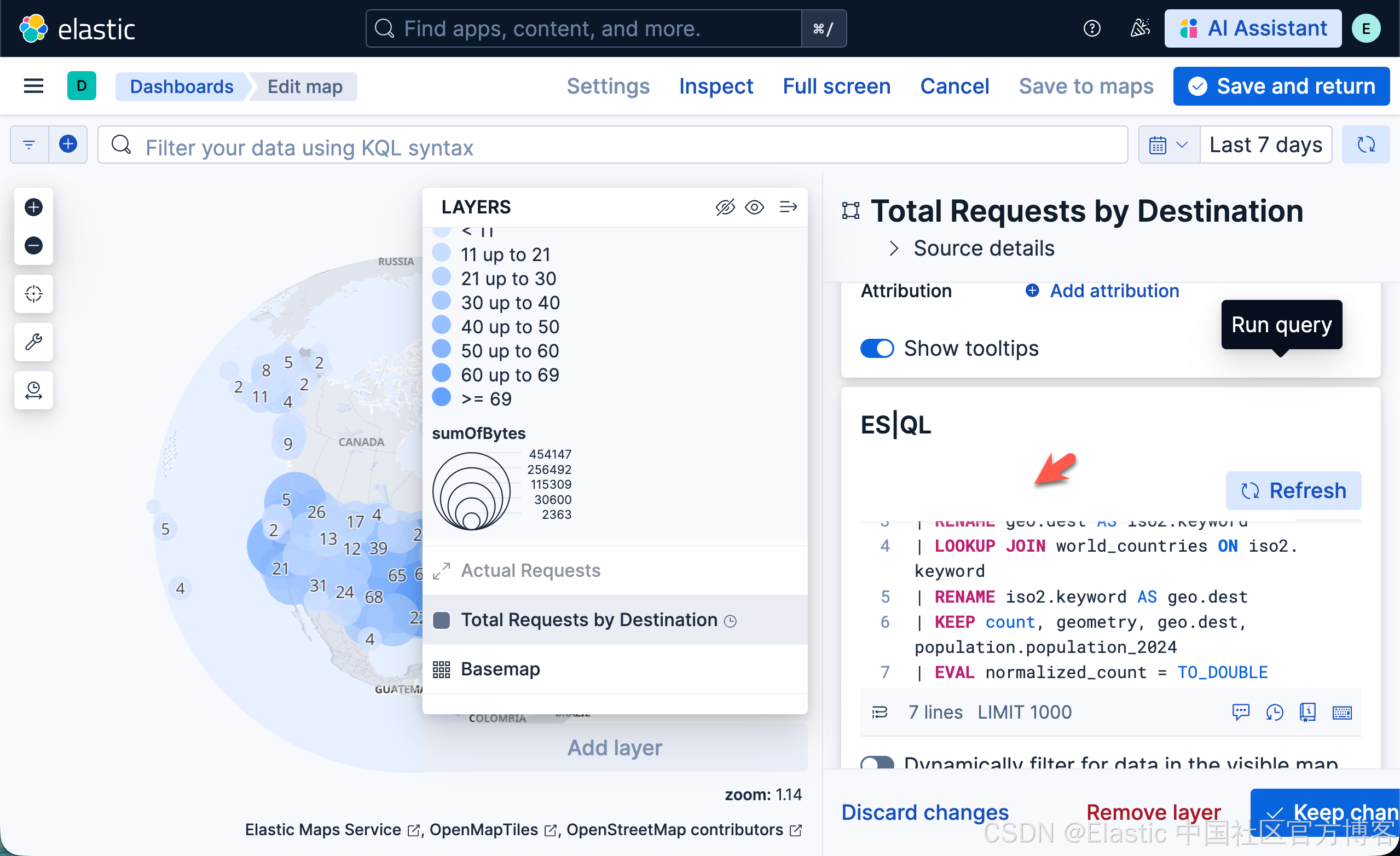
- 在 Layer style 中将 Fill color 设置为 By value by normalized_count。
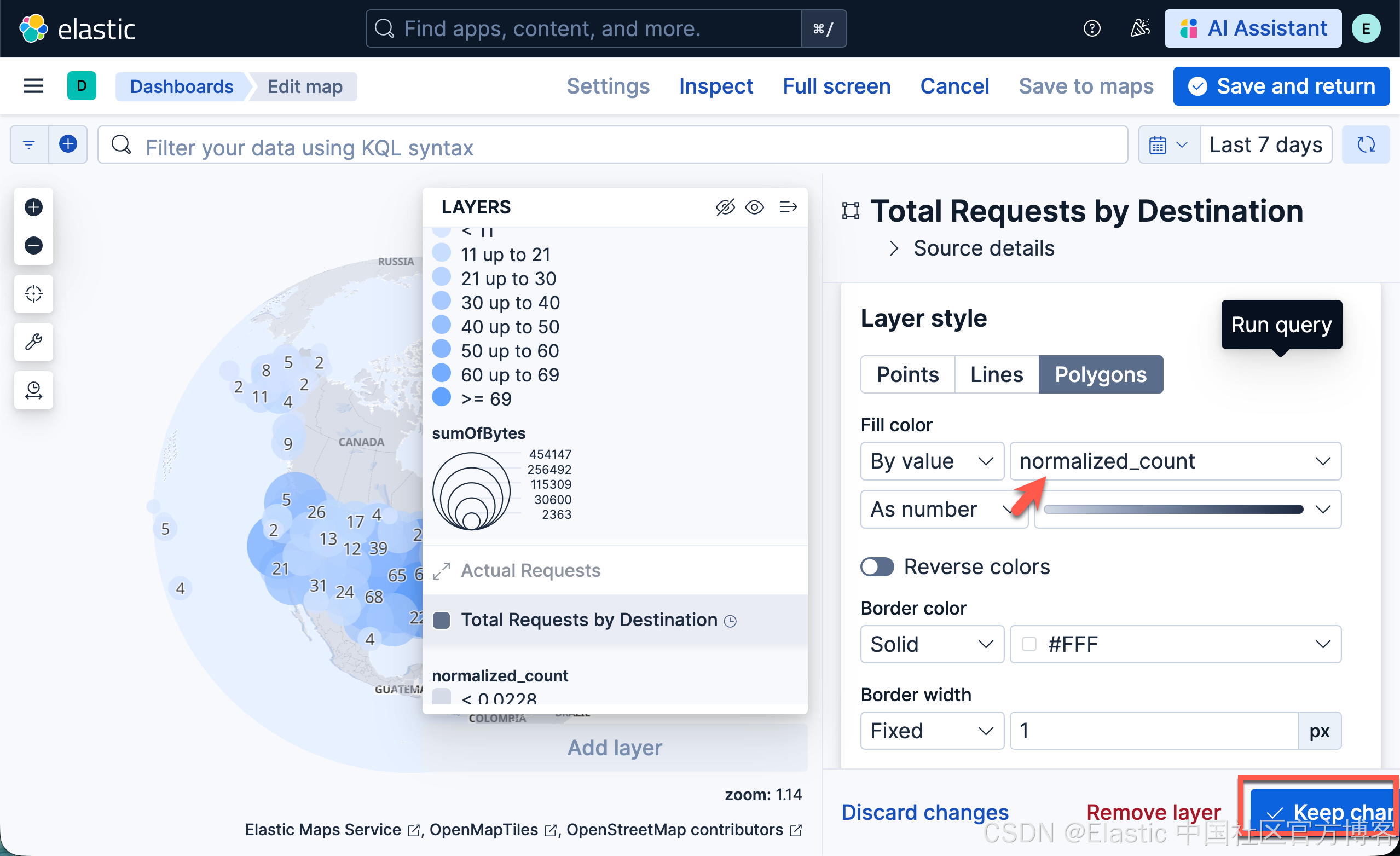
- 点击 Keep changes。
注意:你可能已经猜到,为什么不使用 lookup 设置导入 populations CSV 来对地图查询执行第二次 LOOKUP JOIN。那是可行的!但要注意,每增加一次 join 都会有性能开销。