代码github:https://github.com/OpenDriveLab/TCP
叠甲:本人半年前才接触机器学习,而且纯纯混子,本文是在各位ai老师帮助下写出来的,可能存在诸多错误,看看就行
目录如果你和我一样连接的远程服务器,无法可视化界面,可以使用下面的方法:
[附录 遇到的各种问题](#附录 遇到的各种问题)
[A. ModuleNotFoundError: No module named 'carla'](#A. ModuleNotFoundError: No module named 'carla')
[B tensorboard分析训练日志](#B tensorboard分析训练日志)
[C 效果差的问题](#C 效果差的问题)
[① 图像增强](#① 图像增强)
[② weight_decay](#② weight_decay)
[③ 过拟合,修改loss权重](#③ 过拟合,修改loss权重)
[④ 学习率](#④ 学习率)
[⑤ 更新目标点的距离](#⑤ 更新目标点的距离)
[D 轨迹&车辆数据可视化](#D 轨迹&车辆数据可视化)
[F. 报错AttributeError: 'NoneType' object has no attribute 'cancel'](#F. 报错AttributeError: 'NoneType' object has no attribute 'cancel')
[G. 发牢骚](#G. 发牢骚)
[H. 保存的图像为纯黑](#H. 保存的图像为纯黑)
[I. 关闭carla特效](#I. 关闭carla特效)
[J. 转向时撞到盲区自行车](#J. 转向时撞到盲区自行车)
[K. 结果](#K. 结果)
一、安装carla
安装carla 0.9.10.1:
bash
mkdir carla
cd carla
# 官方README提供的wget地址是下面这两个,但是我并连不上:
wget https://carla-releases.s3.eu-west-3.amazonaws.com/Linux/CARLA_0.9.10.1.tar.gz
wget https://carla-releases.s3.eu-west-3.amazonaws.com/Linux/AdditionalMaps_0.9.10.1.tar.gz
# gpt给了这个地址,我这里能连上:
wget https://s3.us-east-005.backblazeb2.com/carla-releases/Linux/CARLA_0.9.10.1.tar.gz
wget https://s3.us-east-005.backblazeb2.com/carla-releases/Linux/AdditionalMaps_0.9.10.1.tar.gz
tar -xf CARLA_0.9.10.1.tar.gz
tar -xf AdditionalMaps_0.9.10.1.tar.gz
rm CARLA_0.9.10.1.tar.gz
rm AdditionalMaps_0.9.10.1.tar.gz
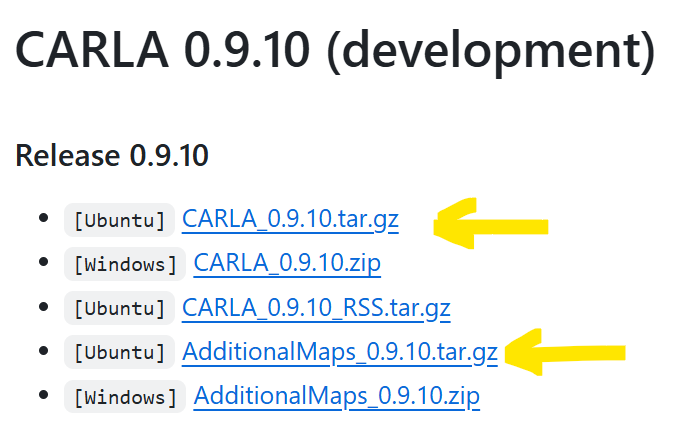
cd ..如果wget链接还进不去直接去官网Releases · carla-simulator/carla下这两个:
二、克隆TCP
bash
git clone https://github.com/OpenDriveLab/TCP.git
# (这里地址不是github教程中写的OpenPerceptionX,地址已经搬家了,如果你用旧的指令会clone到一个只有README的文件)
cd TCP
conda env create -f environment.yml --name TCP
conda activate TCP
export PYTHONPATH=$PYTHONPATH:PATH_TO_TCP # (把PATH_TO_TCP改为TCP文件根目录)三、下载数据集
共115G,github提供了三种下载方式:
Datasets at Hugging Face
Google 云端硬盘
百度网盘(提取码8174)
(使用huggingface下载的话,需要使用下面的命令将三个文件合成一个)
bash
cat tcp_carla_data_part_* > tcp_carla_data.zip
(只有huggingface下载的数据集需要执行这个指令!!)也可以直接终端挂到后台下:(huggingface,需要上面的命令合并)
bash
wget -c https://hf-mirror.com/datasets/craigwu/tcp_carla_data/resolve/main/tcp_carla_data_part_aa
wget -c https://hf-mirror.com/datasets/craigwu/tcp_carla_data/resolve/main/tcp_carla_data_part_ab
wget -c https://hf-mirror.com/datasets/craigwu/tcp_carla_data/resolve/main/tcp_carla_data_part_ac将下载后的文件解压到TCP根目录,即TCP路径下将有一个tcp_carla_data文件,其中是town等文件。放到其他路径也可以,但是要修改/TCP/config.py,把root_dir_all = "tcp_carla_data"改成自己的数据集路径。
四、训练
(训练前可以先看一下附录C,按需修改)
不需要carla。直接训练:
bash
cd PATH/TO/TCP
python TCP/train.py --gpus NUM_OF_GPUS如果报错No module named 'carla',看附录A。
默认训练60epochs。但我跑了这几次感觉其实十几轮就够了,保守一点可以25或者30轮(具体根据日志分析,日志分析详见附录B)。如果想修改epochs,找到/TCP/TCP/train.py文件,修改157行--epochs的default:
python
parser.add_argument('--epochs', type=int, default=60, help='Number of train epochs.')默认保存最低val_loss的两个ckpt,并保存最新一轮。如果需要修改,在/TCP/TCP/train.py中:
python
checkpoint_callback = ModelCheckpoint(save_weights_only=False, mode="min", monitor="val_loss", save_top_k=2, save_last=True,
dirpath=args.logdir, filename="best_{epoch:02d}-{val_loss:.3f}")训练结果默认保存到TCP/log/TCP下,分析训练日志的方法详见附录B。
五、启动Carla
开一个终端,cd到carla根目录下, 执行:
python
./CarlaUE4.sh --world-port=2000 -opengl
或(如果使用-quality-level=Low出现rgb摄像机图像黑屏的问题,详见附录H)
./CarlaUE4.sh --world-port=2000 -quality-level=Low -opengl
如果你和我一样连接的远程服务器,无法可视化界面,可以使用下面的方法:
cd到carla目录下,执行:
python
SDL_VIDEODRIVER=offscreen SDL_HINT_CUDA_DEVICE=0 ./CarlaUE4.sh -opengl -carla-rpc-port=2000
或(使用-quality-level=Low时,如果你查看保存的rgb摄像头图像发现有黑屏,详见附录H)
SDL_VIDEODRIVER=offscreen ./CarlaUE4.sh -opengl -quality-level=Low -carla-rpc-port=2000此时终端会卡在这里:

新开一个终端,输入命令:
bash
ss -tulpn | grep 2000 # 端口保持一致应能看到类似下图输出,说明CARLA已经启动完成:

之后评估的时候通过自动保存到TCP/data/results_TCP的相机和bev画面进行分析
六、数据生成
如果不满意官方提供的数据集,可以自己采数据。
修改TCP/leaderboard/scripts/data_collection.sh中的:
carla路径CARLA_ROOT、城镇地图ROUTES、场景文件SCENARIOS、保存路径SAVE_PATH。
启动carla,然后执行:
python
sh leaderboard/scripts/data_collection.sh七、评估
修改/TCP/leaderboard/scripts/run_evaluation.sh中的:
carla路径CARLA_ROOT、模型路径PATH_TO_MODEL_CKPT(在TCP/log/TCP下)、保存路径SAVE_PATH、路线ROUTES、场景文件SCENARIOS。
REPETITIONS表示一条路线重复评估几次,默认为3。
启动carla,在另一个终端下cd到TCP路径下:
bash
sh leaderboard/scripts/run_evaluation.sh评估时的画面会自动保存到TCP/data/results_TCP下面。但是默认图上没有规划轨迹,如果需要画上轨迹,详见附录D。
如果遇到AttributeError: 'NoneType' object has no attribute 'cancel'看附录F。
附录 遇到的各种问题
(附录很乱,遇到问题就顺着往后写了)
A. ModuleNotFoundError: No module named 'carla'
(一般来说只要改了CARLA_ROOT就不会出现这个问题)
首先cd到下载carla的路径下,输入命令:
bash
ls PythonAPI/carla/dist应当会显示几个.egg文件,例如:
bash
carla-0.9.10-py2.7-linux-x86_64.egg carla-0.9.10-py3.7-linux-x86_64.egg选择py3.7的这个egg。将其路径添加到PYTHONPATH中:
bash
export PYTHONPATH=$PYTHONPATH:/home/..../carla/PythonAPI/carla/dist/carla-0.9.10-py3.7-linux-x86_64.egg:/home/..../carla/PythonAPI/carla测试一下:
bash
python - << 'EOF'
import carla
print("carla imported OK")
EOFB tensorboard分析训练日志
日志默认保存到TCP/log/TCP/lightning_logs下面。想可视化分析各个loss,步骤如下:
(我这里是windows下使用VSCODE的SSH远程连接的服务器,如果是ubuntu系统本地训练的话也是类似)
首先VSCODE安装tensorboard,然后执行:
bash
tensorboard --logdir=/...改成自己的路径.../log/TCP/lightning_logs --port=6006 --bind_all
本地windows下打开控制台,执行:
bash
ssh -L 6006:localhost:6006 用户名@地址
然后找个浏览器打开地址http://localhost:6006,即可看到训练数据了
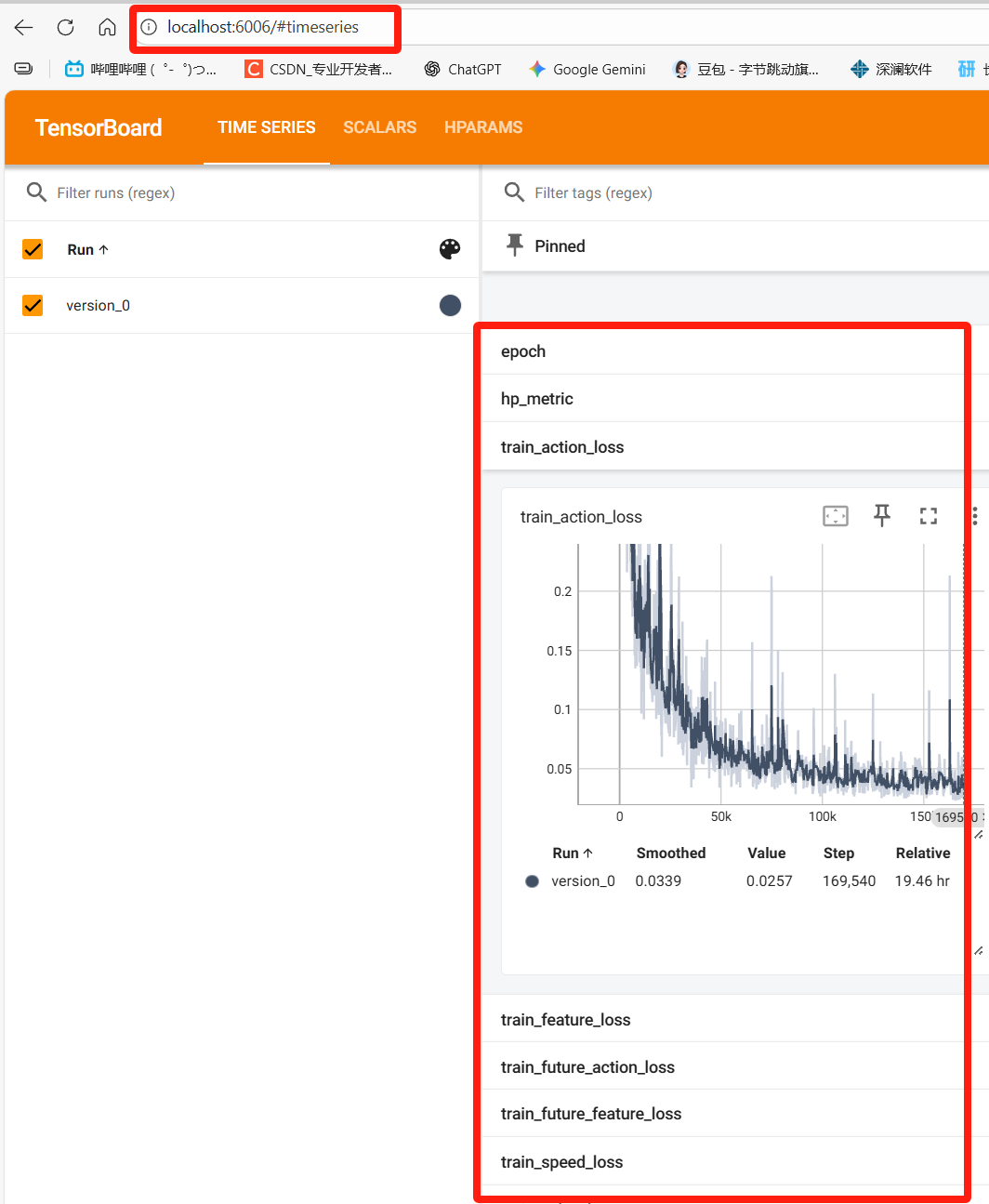
C 效果差的问题
模型评估出来效果简直是一坨啊,论文效果一半都没有。
依照附录B的方法分析日志,我这里发现训练损失很低,但是评估损失直接起飞,应当是过拟合了。
① 图像增强
TCP/TCP/data.py中有图像增强的操作,但默认是关闭的
bash
if self.img_aug:
data['front_img'] = self._im_transform(augmenter(self._batch_read_number).augment_image(np.array(
Image.open(self.root+self.front_img[index][0]))))
else:
data['front_img'] = self._im_transform(np.array(
Image.open(self.root+self.front_img[index][0])))我懒得,直接把self.img_aug强制为True了:
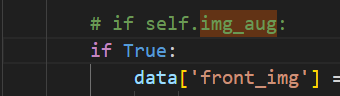
而具体的augmenter配置在TCP/TCP/augment.py里面,可以按需修改。我这里直接在TCP/TCP/augment.py里增加gemini给写的函数:
python
def strong_constant(image_iteration):
"""
Fixed augmentation strategy for autonomous driving.
Optimized for traffic light recognition and robust feature learning.
"""
# 固定的增强概率和参数
frequency_factor = 0.5 # 50%的图像会被增强
color_factor = 1.0 # 完全启用通道独立增强
# 调整后的参数 - 更适合自动驾驶任务
dropout_factor = 0.15 # 降低dropout强度,避免丢失关键信息
blur_factor = 1.0 # 保持模糊范围
add_factor = 20 # 降低亮度变化范围(从30降到20)
multiply_factor_pos = 1.3 # 降低亮度乘法上限(从1.5降到1.3)
multiply_factor_neg = 0.7 # 提高亮度乘法下限(从0.5升到0.7)
contrast_factor_pos = 1.3 # 降低对比度上限(从1.5降到1.3)
contrast_factor_neg = 0.7 # 提高对比度下限(从0.5升到0.7)
augmenter = iaa.Sequential([
# 1. 模糊:模拟运动模糊或对焦不准
iaa.Sometimes(frequency_factor, iaa.GaussianBlur((0, 1.5))),
# 2. 噪声:降低强度以保护细节信息(从0.05*255降到0.02*255)
iaa.Sometimes(frequency_factor, iaa.AdditiveGaussianNoise(
loc=0, scale=(0.0, 0.02*255), per_channel=0.5)),
# 3. 随机挖空:模拟遮挡,强迫模型关注关键特征
iaa.Sometimes(frequency_factor, iaa.CoarseDropout(
(0.0, 0.1), size_percent=(0.02, 0.1), per_channel=0.5)),
# 4. 像素丢失:降低强度
iaa.Sometimes(frequency_factor, iaa.Dropout(
(0.0, dropout_factor), per_channel=0.5)),
# 5. 亮度调整:适度变化
iaa.Sometimes(frequency_factor, iaa.Add(
(-add_factor, add_factor), per_channel=0.5)),
# 6. 亮度乘法:缩小范围避免过暗或过亮
iaa.Sometimes(frequency_factor, iaa.Multiply(
(multiply_factor_neg, multiply_factor_pos), per_channel=0.5)),
# 7. 对比度:缩小范围以保护视觉质量
iaa.Sometimes(frequency_factor, iaa.contrast.LinearContrast(
(contrast_factor_neg, contrast_factor_pos), per_channel=0.5)),
# 8. 灰度化:进一步降低概率以保护颜色信息(从10%降到5%)
iaa.Sometimes(0.05, iaa.Grayscale((0.0, 1.0))),
],
random_order=True
)
return augmenter然后在data.py中修改:
python
# from TCP.augment import hard as augmenter # 修改为下面这行
from TCP.augment import strong_constant as augmenter② weight_decay
在TCP/TCP/train.py中可以找到:
bash
optimizer = optim.Adam(self.parameters(), lr=self.lr, weight_decay=1e-7)weight_decay=1e-7跟没有一样,我先调到weight_decay=1e-4试试。
③ 过拟合,修改loss权重
我这里大部分loss都还好,主要是action相关的两个loss直接飘飞了:
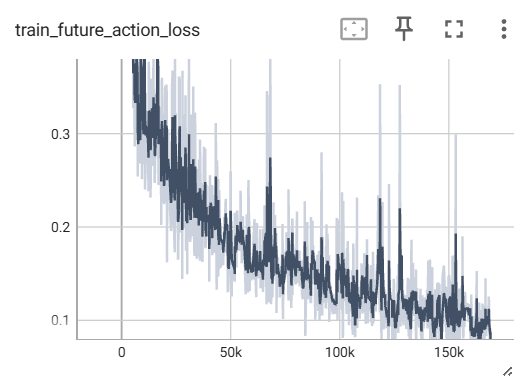
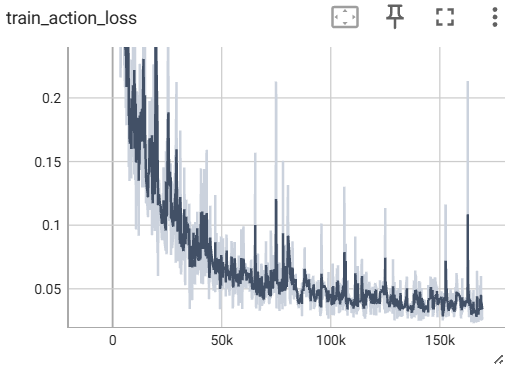
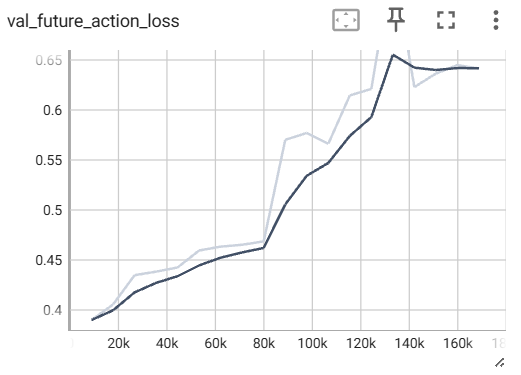
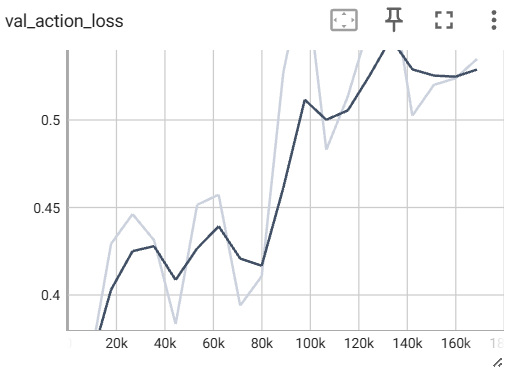
这俩val太离谱了,我修改一下权重。
原来在TCP/TCP/train.py的training_step()函数中,loss定义为:
python
loss = action_loss + speed_loss + value_loss + feature_loss + wp_loss+ future_feature_loss + future_action_loss现在降低两个action的权重:
python
loss = 0.5 * action_loss + speed_loss + value_loss + feature_loss + wp_loss+ future_feature_loss + 0.5 * future_action_loss④ 学习率
虽然和学习率没什么关系,但不知道应该写到哪,先扔到这吧
TCP/TCP/config.py中有配置学习率:
python
lr = 1e-4 # learning rate但实际使用的学习率的值好像是TCP/TCP/train.py的这个:
python
parser.add_argument('--lr', type=float, default=0.0001, help='Learning rate.')⑤ 更新目标点的距离
如果按照前4个修改了以后效果仍然是一坨的话,适当修改tcp_agent.py中的这个值↓但这个值只影响评估,不影响训练:
bash
self._route_planner = RoutePlanner(4.0, 50.0)4.0表示目标点与车辆的最近距离。可以结合D的可视化,看看目标点的距离是否合适。
(4.0太近了,经常到路口了说要变道,比如下图。我调成了15)

然后突然变右边去了:

但是调太远,遇到大弯道又会直接跑到其他车道上去↓(也可能是没训练好)

D 轨迹&车辆数据可视化
评估时,BEV和摄像机图会默认保存到TCP/data/results_TCP下面,但没有规划轨迹,也看不到车辆信息。
让gemini搓了一个代码,勉强能用吧。
能显示轨迹以及命令,红色的点是仿真器下发的target point,左上角增加了导航命令以及控制命令,左下角增加了速度和位置信息。
用下面的代码整个替换掉TCP/leaderboard/team_code/tcp_agent.py里的代码:
(这段代码中⑤目标点更新距离、J转向减速我都改过,记得再改一遍)


python
import os
import json
import datetime
import pathlib
import time
import cv2
import carla
from collections import deque
import math
from collections import OrderedDict
import torch
import numpy as np
from PIL import Image
from torchvision import transforms as T
from leaderboard.autoagents import autonomous_agent
from TCP.model import TCP
from TCP.config import GlobalConfig
from team_code.planner import RoutePlanner
SAVE_PATH = os.environ.get('SAVE_PATH', None)
from TCP.LAW_carla import LAW # 新增
# ================= 可视化配置 =================
VIS_CONFIG = {
# 预测轨迹:亮黄色
'PRED_COLOR': (0, 255, 255),
# 导航目标点:红色
'TARGET_COLOR': (0, 0, 255),
'TEXT_COLOR': (255, 255, 255),
'TEXT_BG_COLOR': (0, 0, 0),
'RGB_WIDTH': 900,
'RGB_HEIGHT': 256,
'RGB_FOV': 100.0,
# 相机位置
'CAM_X': -1.5,
'CAM_Z': 1.6,
'BEV_WIDTH': 512,
'BEV_HEIGHT': 512,
'BEV_FOV_M': 40.0,
'RGB_POINT_RADIUS': 5,
'BEV_POINT_RADIUS': 6,
'TARGET_POINT_RADIUS': 8,
'LINE_WIDTH': 3,
}
# 导航命令映射
CMD_MAP = {
1: 'Left',
2: 'Right',
3: 'Straight',
4: 'Follow',
5: 'Change Left',
6: 'Change Right'
}
# ============================================
def get_entry_point():
return 'TCPAgent'
class TCPAgent(autonomous_agent.AutonomousAgent):
def setup(self, path_to_conf_file):
self.track = autonomous_agent.Track.SENSORS
self.alpha = 0.3
self.status = 0
self.steer_step = 0
self.last_moving_status = 0
self.last_moving_step = -1
self.last_steers = deque()
self.config_path = path_to_conf_file
self.step = -1
self.wall_start = time.time()
self.initialized = False
self.config = GlobalConfig()
# self.net = TCP(self.config)
self.net = LAW(
self.config,
hidden_channel = self.config.hidden_channel,
num_heads = self.config.num_heads,
dim_feedforward = self.config.dim_feedforward,
dropout = self.config.dropout
)
ckpt = torch.load(path_to_conf_file)
ckpt = ckpt["state_dict"]
new_state_dict = OrderedDict()
for key, value in ckpt.items():
new_key = key.replace("model.","")
new_state_dict[new_key] = value
self.net.load_state_dict(new_state_dict, strict = False)
self.net.cuda()
self.net.eval()
self.takeover = False
self.stop_time = 0
self.takeover_time = 0
self.save_path = None
self._im_transform = T.Compose([T.ToTensor(), T.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225])])
self.last_steers = deque()
if SAVE_PATH is not None:
now = datetime.datetime.now()
string = pathlib.Path(os.environ['ROUTES']).stem + '_'
string += '_'.join(map(lambda x: '%02d' % x, (now.month, now.day, now.hour, now.minute, now.second)))
print (string)
self.save_path = pathlib.Path(os.environ['SAVE_PATH']) / string
self.save_path.mkdir(parents=True, exist_ok=False)
(self.save_path / 'rgb').mkdir()
(self.save_path / 'meta').mkdir()
(self.save_path / 'bev').mkdir()
# 新增
if hasattr(self, 'net') and hasattr(self.net, 'prev_feat_list'):
self.net.prev_feat_list = None
def _init(self):
print("===============")
self._route_planner = RoutePlanner(10.0, 50.0)
self._route_planner.set_route(self._global_plan, True)
self.initialized = True
if hasattr(self.net, 'prev_feat_list'):
self.net.prev_feat_list = None
def _get_position(self, tick_data):
gps = tick_data['gps']
gps = (gps - self._route_planner.mean) * self._route_planner.scale
return gps
def sensors(self):
return [
{
'type': 'sensor.camera.rgb',
'x': -1.5, 'y': 0.0, 'z':2.0,
'roll': 0.0, 'pitch': 0.0, 'yaw': 0.0,
'width': 900, 'height': 256, 'fov': 100,
'id': 'rgb',
# ============ 新增:强制关闭 Epic 模式特效 ============
'iso': '100', # 锁定 ISO,防止忽明忽暗
'shutter_speed': '200.0', # 锁定快门速度
'fstop': '8.0', # 锁定光圈
'gamma': '2.2', # 显式指定 Gamma,防止黑屏或过白
'motion_blur_intensity': '0.0', # 彻底关闭动态模糊!
'motion_blur_max_distortion': '0.0',
'motion_blur_min_object_screen_size': '0.05',
'lens_circle_falloff': '0.0', # 关闭暗角
'lens_circle_multiplier': '0.0',
'chromatic_aberration_intensity': '0.0', # 关闭色差
'chromatic_aberration_offset': '0.0',
# ===================================================
},
{
'type': 'sensor.camera.rgb',
'x': 0.0, 'y': 0.0, 'z': 50.0,
'roll': 0.0, 'pitch': -90.0, 'yaw': 0.0,
'width': 512, 'height': 512, 'fov': 5 * 10.0,
'id': 'bev'
},
{
'type': 'sensor.other.imu',
'x': 0.0, 'y': 0.0, 'z': 0.0,
'roll': 0.0, 'pitch': 0.0, 'yaw': 0.0,
'sensor_tick': 0.05,
'id': 'imu'
},
{
'type': 'sensor.other.gnss',
'x': 0.0, 'y': 0.0, 'z': 0.0,
'roll': 0.0, 'pitch': 0.0, 'yaw': 0.0,
'sensor_tick': 0.01,
'id': 'gps'
},
{
'type': 'sensor.speedometer',
'reading_frequency': 20,
'id': 'speed'
}
]
def tick(self, input_data):
self.step += 1
rgb = cv2.cvtColor(input_data['rgb'][1][:, :, :3], cv2.COLOR_BGR2RGB)
bev = cv2.cvtColor(input_data['bev'][1][:, :, :3], cv2.COLOR_BGR2RGB)
gps = input_data['gps'][1][:2]
speed = input_data['speed'][1]['speed']
compass = input_data['imu'][1][-1]
if (math.isnan(compass) == True):
compass = 0.0
result = {
'rgb': rgb,
'gps': gps,
'speed': speed,
'compass': compass,
'bev': bev
}
pos = self._get_position(result)
result['gps'] = pos
next_wp, next_cmd = self._route_planner.run_step(pos)
result['next_command'] = next_cmd.value
theta = compass + np.pi/2
R = np.array([
[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]
])
local_command_point = np.array([next_wp[0]-pos[0], next_wp[1]-pos[1]])
local_command_point = R.T.dot(local_command_point)
result['target_point'] = tuple(local_command_point)
result['R_global_to_ego'] = R.T
return result
@torch.no_grad()
def run_step(self, input_data, timestamp):
if not self.initialized:
self._init()
tick_data = self.tick(input_data)
if self.step < self.config.seq_len:
rgb = self._im_transform(tick_data['rgb']).unsqueeze(0)
control = carla.VehicleControl()
control.steer = 0.0
control.throttle = 0.0
control.brake = 0.0
return control
gt_velocity = torch.FloatTensor([tick_data['speed']]).to('cuda', dtype=torch.float32)
command = tick_data['next_command']
if command < 0: command = 4
command -= 1
cmd_one_hot = [0] * 6
cmd_one_hot[command] = 1
cmd_one_hot = torch.tensor(cmd_one_hot).view(1, 6).to('cuda', dtype=torch.float32)
speed = torch.FloatTensor([float(tick_data['speed'])]).view(1,1).to('cuda', dtype=torch.float32)
speed = speed / 12
rgb = self._im_transform(tick_data['rgb']).unsqueeze(0).to('cuda', dtype=torch.float32)
tick_data['target_point'] = [torch.FloatTensor([tick_data['target_point'][0]]),
torch.FloatTensor([tick_data['target_point'][1]])]
target_point = torch.stack(tick_data['target_point'], dim=1).to('cuda', dtype=torch.float32)
state = torch.cat([speed, target_point, cmd_one_hot], 1)
pred = self.net(rgb, state, target_point)
steer_ctrl, throttle_ctrl, brake_ctrl, metadata = self.net.process_action(pred, tick_data['next_command'], gt_velocity, target_point)
steer_traj, throttle_traj, brake_traj, metadata_traj = self.net.control_pid(pred['pred_wp'], gt_velocity, target_point)
if brake_traj < 0.05: brake_traj = 0.0
if throttle_traj > brake_traj: brake_traj = 0.0
self.pid_metadata = metadata_traj
control = carla.VehicleControl()
if self.status == 0:
self.alpha = 0.3
self.pid_metadata['agent'] = 'traj'
control.steer = np.clip(self.alpha*steer_ctrl + (1-self.alpha)*steer_traj, -1, 1)
control.throttle = np.clip(self.alpha*throttle_ctrl + (1-self.alpha)*throttle_traj, 0, 0.75)
control.brake = np.clip(self.alpha*brake_ctrl + (1-self.alpha)*brake_traj, 0, 1)
else:
self.alpha = 0.3
self.pid_metadata['agent'] = 'ctrl'
control.steer = np.clip(self.alpha*steer_traj + (1-self.alpha)*steer_ctrl, -1, 1)
control.throttle = np.clip(self.alpha*throttle_traj + (1-self.alpha)*throttle_ctrl, 0, 0.75)
control.brake = np.clip(self.alpha*brake_traj + (1-self.alpha)*brake_ctrl, 0, 1)
self.pid_metadata['steer_ctrl'] = float(steer_ctrl)
self.pid_metadata['steer_traj'] = float(steer_traj)
self.pid_metadata['throttle_ctrl'] = float(throttle_ctrl)
self.pid_metadata['throttle_traj'] = float(throttle_traj)
self.pid_metadata['brake_ctrl'] = float(brake_ctrl)
self.pid_metadata['brake_traj'] = float(brake_traj)
# ==================== 新增 ====================
# 方向盘|control.steer| > 0.15 (转向时)
if control.steer > 0.15 or control.steer < -0.15:
# 强制限制油门上限 (0.3),降速
control.throttle = np.clip(control.throttle, 0.0, 0.3)
# 如果车速过快,强制加一点刹车
if tick_data['speed'] > 2.0:
control.brake = max(control.brake, 0.3)
# =============================================
if control.brake > 0.5:
control.throttle = float(0)
if len(self.last_steers) >= 20:
self.last_steers.popleft()
self.last_steers.append(abs(float(control.steer)))
num = 0
for s in self.last_steers:
if s > 0.10: num += 1
if num > 10:
self.status = 1
self.steer_step += 1
else:
self.status = 0
self.pid_metadata['status'] = self.status
# ================= 可视化入口 =================
if SAVE_PATH is not None and self.step % 10 == 0:
pred_wp_np = pred['pred_wp'].detach().cpu().numpy()[0]
# 修改这里:传入 control
self.save(tick_data, control, pred_wp_np)
return control
# ================= 坐标映射核心 =================
def _ego_to_rgb_pixel(self, point_ego):
"""
RGB投影:强制前向 > 0,且允许返回屏幕下方的点
"""
x_cam = abs(point_ego[1]) - VIS_CONFIG['CAM_X']
y_cam = point_ego[0]
z_cam = -VIS_CONFIG['CAM_Z']
if x_cam < 0.01: return None
img_w = VIS_CONFIG['RGB_WIDTH']
img_h = VIS_CONFIG['RGB_HEIGHT']
fov = VIS_CONFIG['RGB_FOV']
f_val = img_w / (2.0 * np.tan(np.deg2rad(fov / 2.0)))
u = img_w / 2.0 + f_val * (y_cam / x_cam)
v = img_h / 2.0 - f_val * (z_cam / x_cam)
if 0 <= int(u) < img_w:
return (int(u), int(v))
return None
def _ego_to_bev_pixel(self, point_ego):
img_w = VIS_CONFIG['BEV_WIDTH']
img_h = VIS_CONFIG['BEV_HEIGHT']
fov_m = VIS_CONFIG['BEV_FOV_M']
pixels_per_meter = img_w / fov_m
cx = img_w / 2.0
cy = img_h / 2.0
v = cy + point_ego[1] * pixels_per_meter
u = cx + point_ego[0] * pixels_per_meter
if 0 <= int(u) < img_w and 0 <= int(v) < img_h:
return (int(u), int(v))
return None
def _draw_hud(self, img, cmd_id, control, tick_data):
"""
在图片绘制 HUD 信息:
左上角:导航指令、控制输出
左下角:车速、坐标 (新增)
"""
# ================= 原有逻辑:左上角信息 =================
# 1. 准备文本
cmd_text = CMD_MAP.get(cmd_id, f'Unknown({cmd_id})')
ctrl_text = f"Thr: {control.throttle:.2f} Brk: {control.brake:.2f} Str: {control.steer:.2f}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.6
thickness = 2
# 2. 计算尺寸
(cmd_w, cmd_h), _ = cv2.getTextSize(cmd_text, font, font_scale, thickness)
(ctrl_w, ctrl_h), _ = cv2.getTextSize(ctrl_text, font, font_scale, thickness)
max_w = max(cmd_w, ctrl_w)
total_h = cmd_h + ctrl_h + 15
# 3. 绘制左上角背景
x_start, y_start = 10, 10
padding = 5
cv2.rectangle(img,
(x_start - padding, y_start - padding),
(x_start + max_w + padding, y_start + total_h + padding * 2),
VIS_CONFIG['TEXT_BG_COLOR'], -1)
# 4. 绘制左上角文字
y_line1 = y_start + cmd_h
cv2.putText(img, cmd_text, (x_start, y_line1), font, font_scale, VIS_CONFIG['TEXT_COLOR'], thickness)
y_line2 = y_line1 + ctrl_h + 10
cv2.putText(img, ctrl_text, (x_start, y_line2), font, font_scale, (255, 255, 0), thickness)
# ================= 新增逻辑:左下角信息 =================
# 获取图像高度
h_img, w_img = img.shape[:2]
# 1. 准备数据
gps_x = tick_data['gps'][1]
gps_y = tick_data['gps'][0] * -1.0
spd_text = f"Speed: {tick_data['speed']:.1f} m/s"
loc_text = f"Loc: x={gps_x:.1f}, y={gps_y:.1f}"
# 2. 计算尺寸
(spd_w, spd_h), _ = cv2.getTextSize(spd_text, font, font_scale, thickness)
(loc_w, loc_h), _ = cv2.getTextSize(loc_text, font, font_scale, thickness)
max_w_bot = max(spd_w, loc_w)
# total_h_bot = spd_h + loc_h + 15
# 3. 计算左下角起始坐标 (Y轴是从上往下的,所以底部是大数值)
# 留出 10 像素的底部边距
y_bot_margin = 10
# loc_text 的基线位置
y_loc_line = h_img - y_bot_margin
# spd_text 的基线位置 (在 loc 上方)
y_spd_line = y_loc_line - loc_h - 10
# 背景框的左上角 Y 坐标
y_bg_start = y_spd_line - spd_h - padding
# 4. 绘制左下角背景
cv2.rectangle(img,
(x_start - padding, y_bg_start),
(x_start + max_w_bot + padding, h_img - y_bot_margin + padding),
VIS_CONFIG['TEXT_BG_COLOR'], -1)
# 5. 绘制左下角文字
# 绘制速度 (绿色,表示状态)
cv2.putText(img, spd_text, (x_start, y_spd_line), font, font_scale, (0, 255, 0), thickness)
# 绘制坐标 (白色)
cv2.putText(img, loc_text, (x_start, y_loc_line), font, font_scale, VIS_CONFIG['TEXT_COLOR'], thickness)
def save(self, tick_data, control, pred_wp=None):
frame = self.step // 10
cmd_id = tick_data['next_command']
# --- 1. 获取 Target Point ---
tp_raw = tick_data['target_point']
if isinstance(tp_raw, (list, tuple)) and len(tp_raw) == 2:
tp_x = float(tp_raw[0])
tp_y = float(tp_raw[1])
vis_target_point = np.array([tp_x, tp_y])
else:
vis_target_point = None
# --- 2. 预处理:插入原点 ---
origin = np.array([[0.0, 0.0]])
if pred_wp is not None:
pred_wp = np.concatenate((origin, pred_wp), axis=0)
# --- 3. RGB 绘制 ---
rgb_cv = cv2.cvtColor(tick_data['rgb'], cv2.COLOR_RGB2BGR)
if pred_wp is not None:
pts = []
for p in pred_wp:
uv = self._ego_to_rgb_pixel(p)
if uv: pts.append(uv)
for i in range(len(pts)-1):
cv2.line(rgb_cv, pts[i], pts[i+1], VIS_CONFIG['PRED_COLOR'], VIS_CONFIG['LINE_WIDTH'])
for pt in pts:
if 0 <= pt[1] < VIS_CONFIG['RGB_HEIGHT']:
cv2.circle(rgb_cv, pt, VIS_CONFIG['RGB_POINT_RADIUS'], VIS_CONFIG['PRED_COLOR'], -1)
if vis_target_point is not None:
uv = self._ego_to_rgb_pixel(vis_target_point)
if uv and 0 <= uv[1] < VIS_CONFIG['RGB_HEIGHT']:
cv2.circle(rgb_cv, uv, VIS_CONFIG['TARGET_POINT_RADIUS'], VIS_CONFIG['TARGET_COLOR'], -1)
# [修改点 1] 传入 tick_data
self._draw_hud(rgb_cv, cmd_id, control, tick_data)
cv2.imwrite(str(self.save_path / 'rgb' / ('%04d.png' % frame)), rgb_cv)
# --- 4. BEV 绘制 ---
bev_cv = cv2.cvtColor(tick_data['bev'], cv2.COLOR_RGB2BGR)
if pred_wp is not None:
pts = []
for p in pred_wp:
uv = self._ego_to_bev_pixel(p)
if uv: pts.append(uv)
for i in range(len(pts)-1):
cv2.line(bev_cv, pts[i], pts[i+1], VIS_CONFIG['PRED_COLOR'], VIS_CONFIG['LINE_WIDTH'])
for pt in pts:
cv2.circle(bev_cv, pt, VIS_CONFIG['BEV_POINT_RADIUS'], VIS_CONFIG['PRED_COLOR'], -1)
if vis_target_point is not None:
uv = self._ego_to_bev_pixel(vis_target_point)
if uv:
cv2.circle(bev_cv, uv, VIS_CONFIG['TARGET_POINT_RADIUS'], VIS_CONFIG['TARGET_COLOR'], -1)
# [修改点 2] 传入 tick_data
self._draw_hud(bev_cv, cmd_id, control, tick_data)
cv2.imwrite(str(self.save_path / 'bev' / ('%04d.png' % frame)), bev_cv)
outfile = open(self.save_path / 'meta' / ('%04d.json' % frame), 'w')
json.dump(self.pid_metadata, outfile, indent=4)
outfile.close()
def destroy(self):
del self.net
torch.cuda.empty_cache()如果想看地图路线,把run_evaluation.sh的DEBUG_CHALLENGE改成1即可
F. 报错AttributeError: 'NoneType' object has no attribute 'cancel'
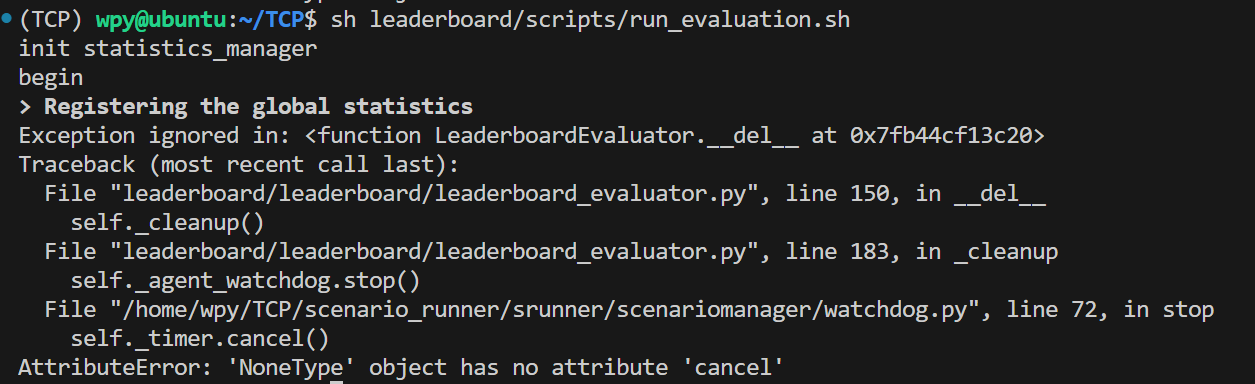
问题找了一年,改了一堆代码,最后发现是因为上一次评估完以后忘了删除生成的results_TCP.json文件,脚本认为所有任务都已经完成,就直接退出了,此时watchdog还没初始化,所以直接报错。
G. 发牢骚
这种自行车卡到这,不走也不刷新掉,车也不敢走,直接超时,无语住了。

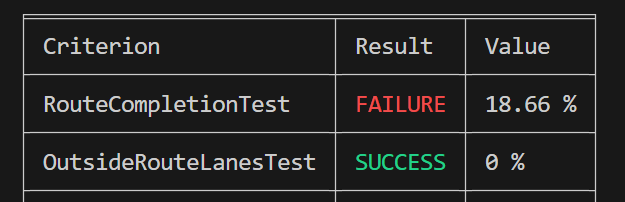
这什么啊,纯纯追尾啊,还算我碰撞啊,每次都得整点新活啊:








因为压线被创更是日常了:




H. 保存的图像为纯黑
经常冒出来这种图,刚开始以为是保存的时候出的问题,后来发现碰撞大部分都发生在黑图的时间段,才反应过来应该是传感器输入的就是黑的。(gemini说是因为我使用SDL_VIDEODRIVER=offscreen,渲染管线断了才出现的黑屏)
最后发现应该是因为我开的-quality-level=Low,OpenGL渲染抽风了。只需要去掉-quality-level=Low即可。
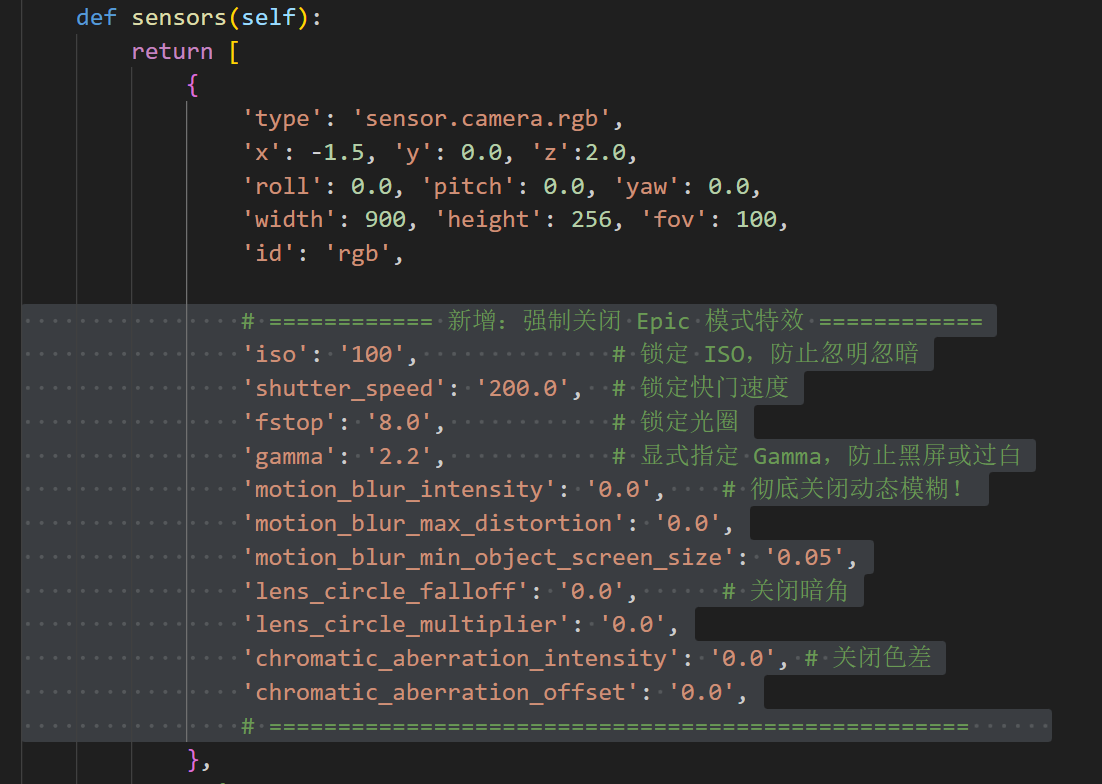
I. 关闭carla特效
如果没用-quality-level=Low,可以在TCP/leaderboard/team_code/tcp_agent.py的sensors函数中增加下面这段代码:
python
# ============ 新增:强制关闭 Epic 模式特效 ============
'iso': '100', # 锁定 ISO,防止忽明忽暗
'shutter_speed': '200.0', # 锁定快门速度
'fstop': '8.0', # 锁定光圈
'gamma': '2.2', # 显式指定 Gamma,防止黑屏或过白
'motion_blur_intensity': '0.0', # 彻底关闭动态模糊!
'motion_blur_max_distortion': '0.0',
'motion_blur_min_object_screen_size': '0.05',
'lens_circle_falloff': '0.0', # 关闭暗角
'lens_circle_multiplier': '0.0',
'chromatic_aberration_intensity': '0.0', # 关闭色差
'chromatic_aberration_offset': '0.0',
# =================================================== 
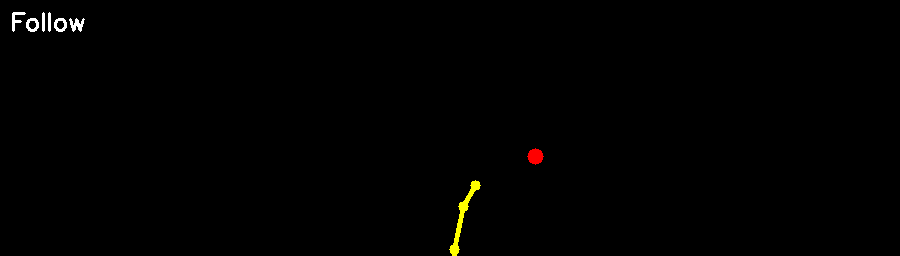
J. 转向时撞到盲区自行车
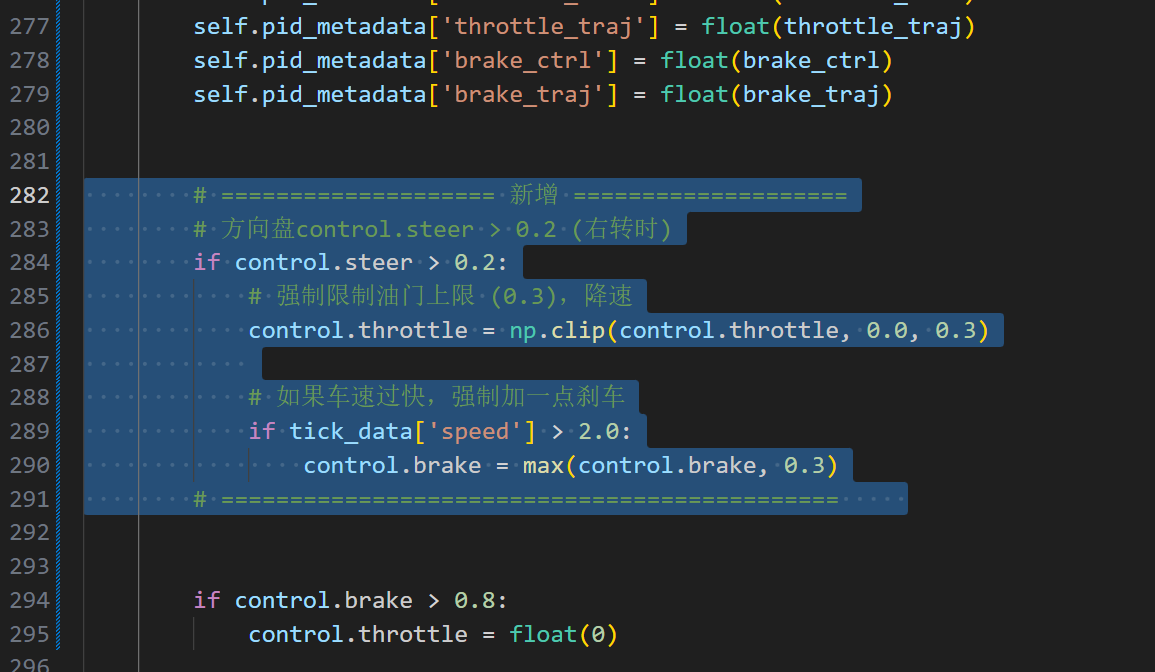
调到现在,一多半碰撞都是右转时盲区冒出来的自行车。我这里强制转向时减速,不知道有没有用。
在TCP/leaderboard/team_code/tcp_agent.py中run_step函数的self.pid_metadata'brake_traj' = float(brake_traj)这一行下面加入代码:
python
# ==================== 新增 ====================
# 方向盘|control.steer| > 0.15 (转向时)
if control.steer > 0.15 or control.steer < -0.15:
# 强制限制油门上限 (0.3),降速
control.throttle = np.clip(control.throttle, 0.0, 0.3)
# 如果车速过快,强制加一点刹车
if tick_data['speed'] > 2.0:
control.brake = max(control.brake, 0.3)
# ============================================= 
K. 结果
1、第一次,完全按照官方的代码,克隆下来直接开跑,然后被评估结果吓昏。基本前5轮两个val_action的loss就开始反弹了
2、第二次,增加了附录C中的①和②,基本在7-10epoch开始反弹
3、第三次,增加了附录3③、附录3④、附录3⑤,并把train.py中的学习率减半(我是双卡,先减半试试),最后val_action_loss在14epoch达到最低0.37。
我也不知道哪个修改作用更大一点,莫得时间慢慢试了,赶紧下一个任务了
感觉完全没必要跑60轮,最多30,基本20以内
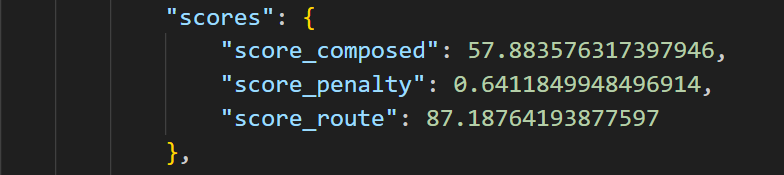

4、本来要训练LAW了,结果眼拙跑到TCP下面训练了,那就看看结果吧
结果竟然比上一次好了不少???这真是同一个模型吗。因为我这次用单卡训练?(黄第一次 蓝第二次)
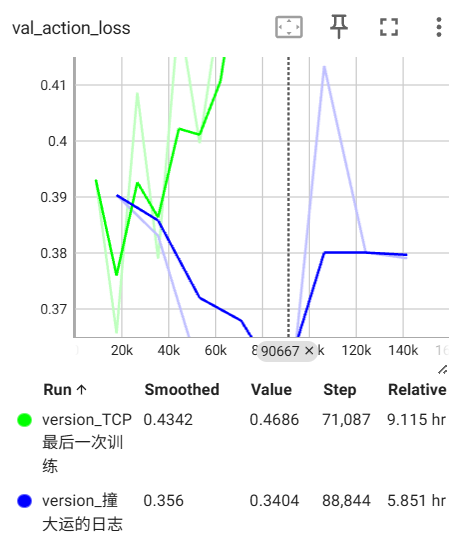
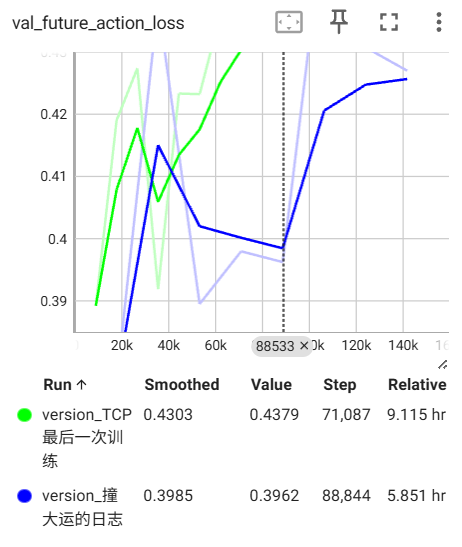
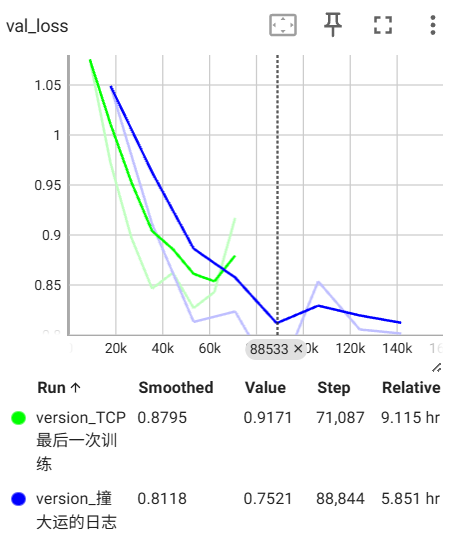
这次的配置是:
bash
train.py:
# weight_decay=1e-4
optimizer = optim.Adam(self.parameters(), lr=self.lr, weight_decay=1e-4)
# 30个epoch将学习率减半(可以调成10次就减半?因为我还没训练过30次以上,懒得试了)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 30, 0.5)
# 训练25epochs,多了浪费
parser.add_argument('--epochs', type=int, default=25, help='Number of train epochs.')
# 学习率5e-5,比官方的1e-4减半
parser.add_argument('--lr', type=float, default=0.00005, help='Learning rate.')
# batch size = 32,+单卡训练
parser.add_argument('--batch_size', type=int, default=32, help='Batch size')
# 将action_loss和future_action_loss的权重减半
loss = 0.5 * action_loss + speed_loss + value_loss + feature_loss + wp_loss+ future_feature_loss + 0.5 * future_action_loss # 修改累了,就这样吧