多模态生成强化学习框架 DanceGRPO + FLUX 在昇腾 NPU 上的部署与对齐实践
------从环境搭建到端到端精度验证的完整实战指南
近年来,随着文生图模型加速演进,"小而美"的后训练模型正成为行业趋势。Flux 系列模型凭借高效生成质量受到广泛关注,而 DanceGRPO 作为专为生成式 AI 设计的 RL(强化学习)框架,通过引入高质量奖励模型与 GRPO 策略,在 Flux 等模型上可取得显著的生成效果提升。
本文基于昇腾 NPU,深入解析 DanceGRPO + FLUX 这一组合的部署方法、关键代码改动点、精度对齐流程、常见问题及训练踩坑,让你从 0 到 1 完整跑通全链路,开始!
1. 项目背景:为什么选择 DanceGRPO + FLUX
在传统 Diffusion 文生图训练中,模型越大、训练越复杂,成本越高。然而 DanceGRPO 的理念是:
用小尺寸模型,通过强化学习,获得更好的图像生成能力。
结合 Flux 的轻量结构,能够在以下方面获益:
- 推理速度快
- 单卡即可微调或 RL 训练
- 模型对 Prompt 的理解更准确
- 图像质量明显提升(尤其是在结构性与美学评分上)
当这些组件部署在昇腾 NPU 上后,能够进一步利用 NPU 的算力优势,在更低成本下完成推理与训练任务。
2. 环境配置与依赖版本
以下版本组合在昇腾环境中:
| 依赖软件 | 版本 |
|---|---|
| NPU 驱动 | 商发版本 |
| NPU 固件 | 商发版本 |
| CANN | 8.2.RC1.B080 |
| Python | 3.10 |
| PyTorch | 2.1.0 |
| torch-npu | 2.1.0 |
| torchvision | 0.21.0 |
| transformers | 4.53.0 |
**PS:Flux 模型依赖 transformers/**safetensors,为避免动态 Shape 和 FlashAttn 相关模块报错,需要按照本文后续说明进行部分裁剪与适配。
3. 模型部署流程
3.1 拉取 DanceGRPO 仓库
暂时无法在飞书文档外展示此内容
3.2 下载所需权重
下载以下模型:
- FLUX
- HPS(Reward model)
- OpenClip
3.3 必要依赖裁剪(解决不能懒加载导致的 ImportError)
由于 DanceGRPO 默认加载所有三方库,会导致一些 FlashAttn 或未适配库的报错,因此建议:
① 注释掉 Mojchi 相关逻辑(用不到)
路径:DanceGRPO/fastvideo/models/mochi_hf/modeling_mochi.py
② 注释 FlashAttn 依赖
路径:flash_attn_no_pad.py 将 FlashAttn 导入与核心逻辑注释掉,只保留 return。
暂时无法在飞书文档外展示此内容
3.4 环境初始化
暂时无法在飞书文档外展示此内容
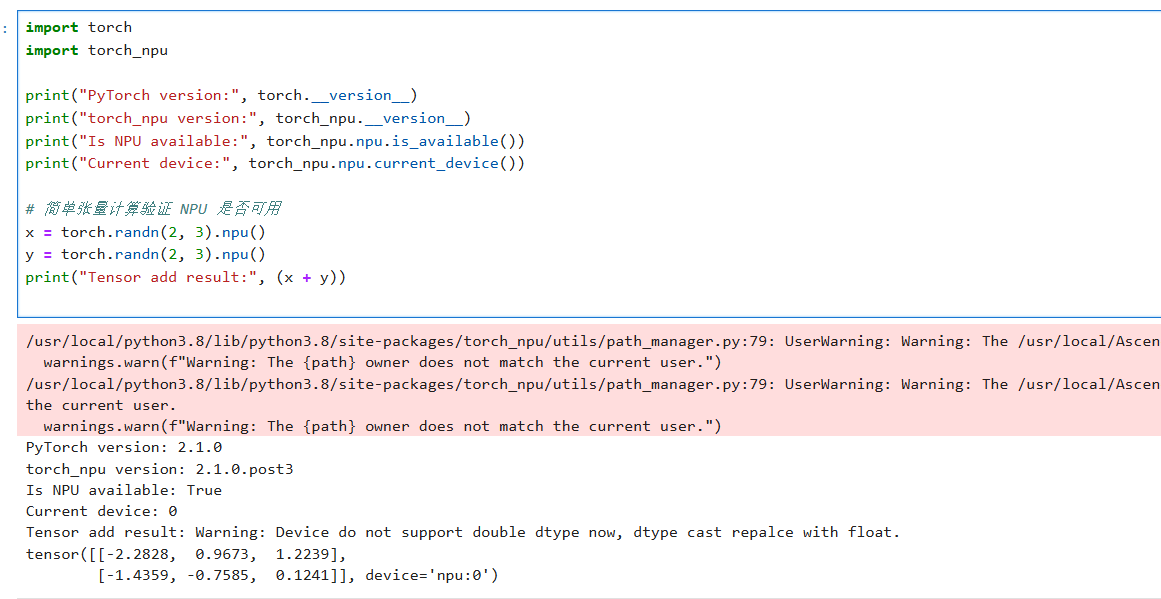
3.5 适配 torch_npu(关键步骤)
修改 preprocess_flux_embedding.py
暂时无法在飞书文档外展示此内容
修改 train_grpo_flux.py
同样引入:
暂时无法在飞书文档外展示此内容
3.6 启动训练(Flux + GRPO)
暂时无法在飞书文档外展示此内容
执行后会自动进入三阶段循环: 推理 → Reward → GRPO 更新。
4. 精度对齐:为什么 RL 训练对齐比普通训练更难?
强化学习(GRPO)与常规模型训练不同:
- 不是单一模型前向
- 包含 推理模型、奖励模型、训练模型 多个组件
- 输入存在随机性(noise、perms、input_latents)
- 多阶段的输出彼此影响
因此需要单独验证:
- 推理阶段对齐(生成图片一致性)
- Reward 阶段对齐(奖励分数一致性)
- 训练阶段 loss 对齐(趋势即可,并非绝对一致)
下面详细介绍如何让 GPU/NPU 全链路可对齐。
5. 随机性固定:GRPO 场景最核心的工作
随机性主要来自:
- prev_sample (扩散初始 noise)
- input_latents
- perms(时间步随机打乱)
- 数据加载 shuffle
- CPU/GPU/NPU 的不同随机源
因此必须进行 强随机性固定。
5.1 方法 A:严格固定(GPU 生成 → NPU 加载)
此方式"最准确",但操作繁琐。
核心思路: GPU 运行时把所有随机变量 dump 到文件中 → NPU 加载同样的值。
如:
prev_sample 固定
暂时无法在飞书文档外展示此内容
NPU 端加载:
暂时无法在飞书文档外展示此内容
input_latents 固定
暂时无法在飞书文档外展示此内容
perms 固定
暂时无法在飞书文档外展示此内容
5.2 方法 B:使用 CPU 固定随机性(推荐方案)
CPU 端随机数在 GPU/NPU 上结果一致,因此:
prev_sample 在 CPU 生成 noise
暂时无法在飞书文档外展示此内容
input_latents 固定
暂时无法在飞书文档外展示此内容
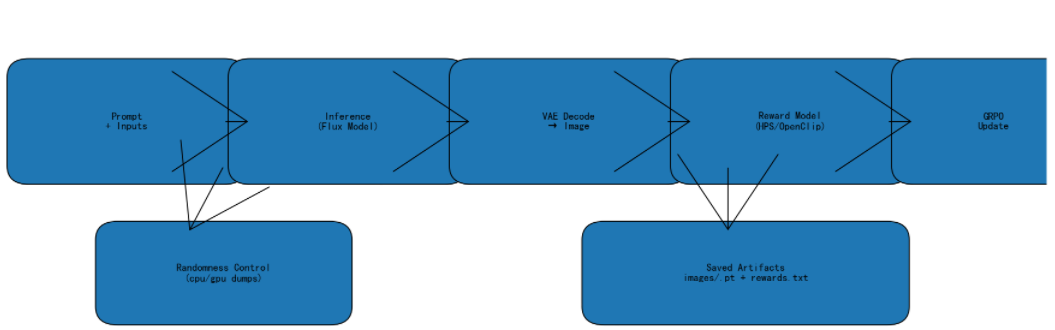
6. 推理流程对齐:关键就是图片一致性
推理阶段每步会生成 12 张图片(num_generations=12),保存方法如下:
暂时无法在飞书文档外展示此内容
GPU 与 NPU 保存同名同序号的图片,即可逐对比对。
如果随机性固定成功:
- 文本理解保持一致
- 图片结构高度一致(几乎一致)
- 细节纹理小部分误差属于预期范围
如出现花图,则说明 前处理、Rope、Attn、VAE 等环节存在不一致。
7. Reward Model 对齐:多步循环验证
对齐方法:
- 在 GPU 上将用于 Reward 的 image/text 保存为 .pt
- 在 NPU 上加载
- 对比 reward 输出
Reward 对齐代码已在供稿中,此处不再重复。
实测误差约:
≈0.015%(完全符合 RL 训练要求)
如何"逐步对齐"的:
暂时无法在飞书文档外展示此内容
8. 端到端对齐
对齐标准:
- 推理图像一致(主观)
- Reward scores:误差 < 5%(前 200 步)
- Loss:趋势一致即可
- 下游推理效果无明显偏移
对齐步骤如下:
- 加载相同预训练模型
- 按前文固定随机性
- 保存关键阶段:
- 推理图片
- Reward 值
- Loss
- 对比推理效果(最重要)
- 如出现花图 → 优先检查:Rope、Attention、norm、VAE decode
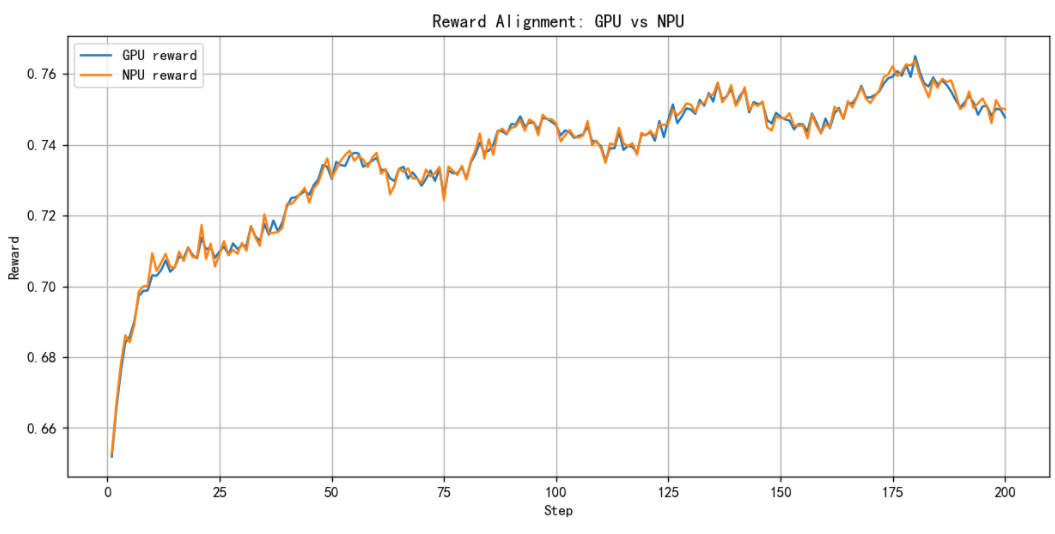
GPU 与 NPU 在前 200 步的 Reward 曲线对齐结果。可以看到两者趋势一致,误差保持在约 0.015% 范围内,满足 GRPO 强化学习对奖励信号的一致性要求。
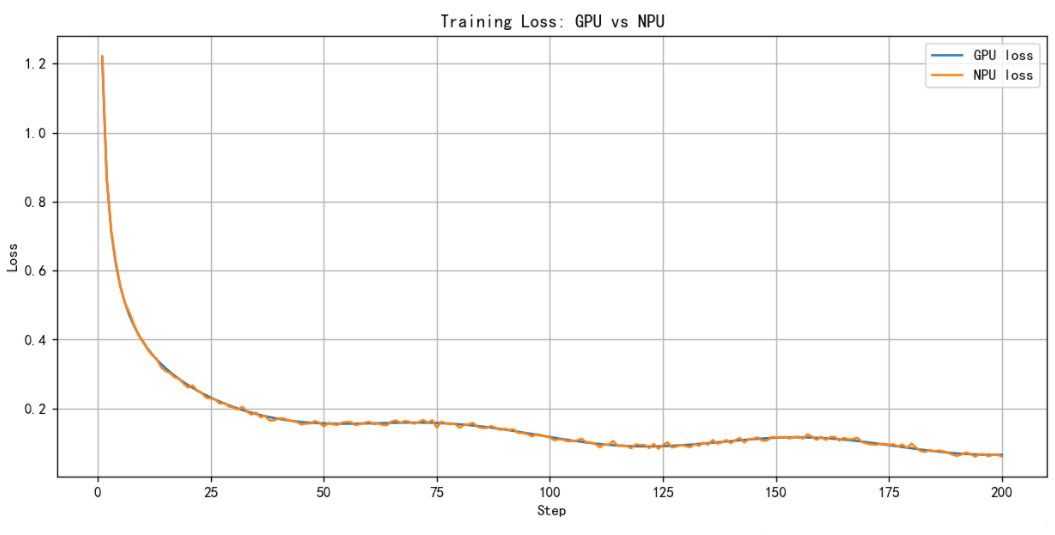
GPU 与 NPU 训练 Loss 曲线对比。尽管 Loss 数值不是强化学习中的主指标,但整体收敛趋势保持一致,表明两端训练稳定性相当。
9. 常见问题
问题:Diffusers 中 RoPE 不支持 complex128(NPU 不兼容)
解决方法:
修改:
lib/python3.10/site-packages/diffusers/models/embeddings.py 1250 行:
暂时无法在飞书文档外展示此内容
10. 总结
我们围绕 Flux + DanceGRPO 在昇腾 NPU 上的部署,从环境搭建、模型修改、随机性固定、推理与 reward 对齐,到最终端到端验证。
核心要点:
- DanceGRPO 强化学习涉及多个模块,必须逐阶段对齐
- 随机性固定是最关键的工作
- Reward 对齐与推理图片一致性是最终指标
- FLUX 需要对 transformers 和部分 diffusers 进行适配
- 中途如出现"花图",从 Rope → Attn → VAE 逐项排查即可
注明:昇腾PAE案例库对本文写作亦有帮助。