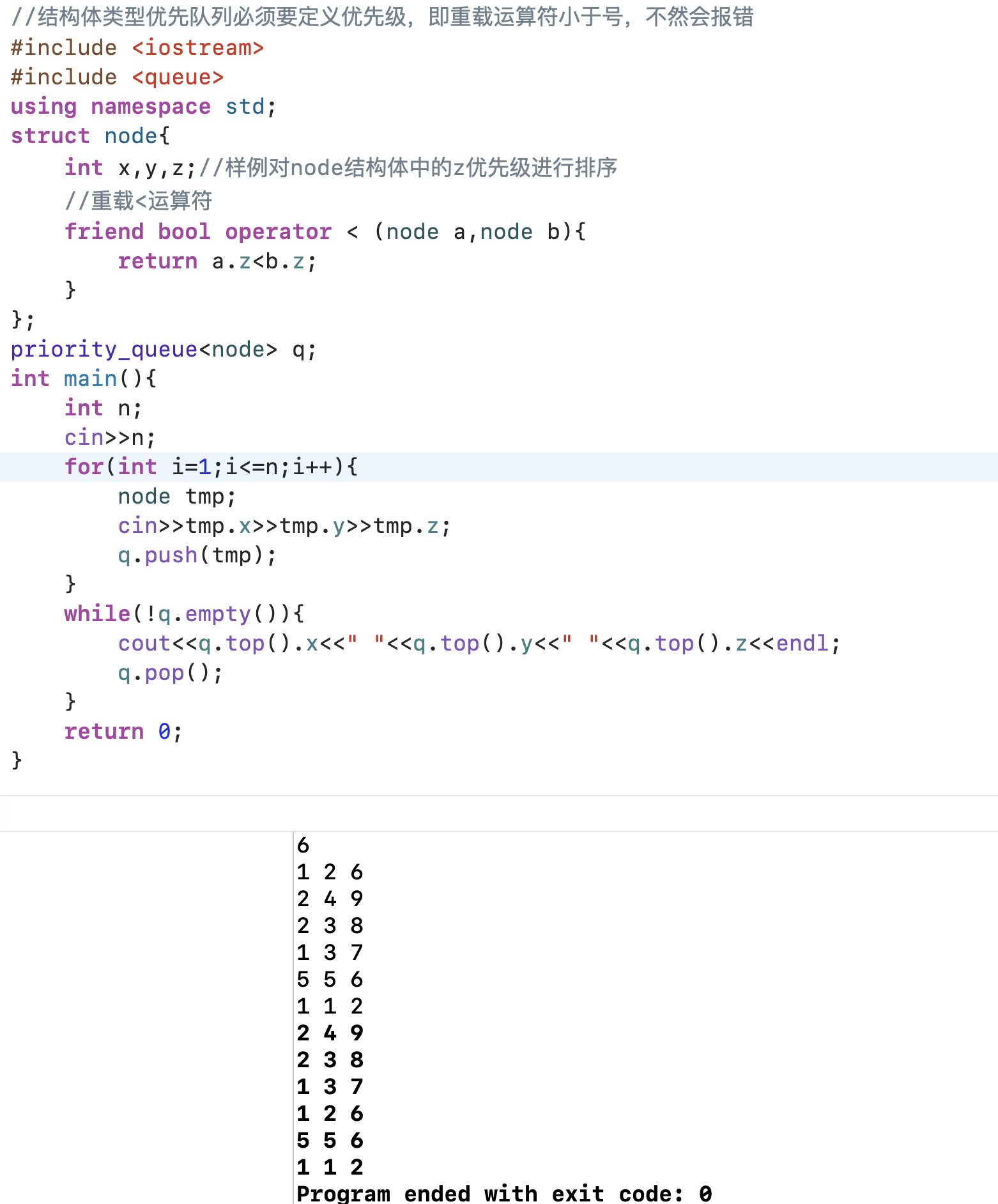
写这部分代码引起的一些思考并总结
一、 优先队列的底层逻辑 (Worldview)
1. 核心矛盾:为什么用 < 却是"大根堆"?
std::priority_queue 的行为逻辑与其命名看似矛盾,实则遵循了 STL 的一致性设计。
-
默认属性 :
priority_queue= Max Heap (大根堆)。 -
默认判据 :
std::less(即调用operator<)。 -
判定流程:
-
队列内部比较
a和b。 -
调用
a < b。 -
若返回 True ,判定
b比a强 (在默认的大根堆语境下,数值大的被视为"强")。 -
结果 :强者 (
b) 上浮至堆顶。
-
2. 代码
cpp
// 代码逻辑
friend bool operator<(node a,node b){
return a.z<b.z;
}解析 :遵循默认逻辑。z 越大,< 比较时在右侧越显"强",因此 z 最大的在堆顶。
二、 优先队列的三种实战写法 (Friend 友元版)
统一使用 Friend (友元) 写法,该写法无 this 指针干扰,逻辑对称,不易出错。
方案 1:大根堆 (默认流)
-
场景:贪心求最大值、常规逻辑。
-
效果:大的先出 (9 -> 8 -> 1)。
cpp
struct node{
int z;
// 逻辑:a.z < b.z 为真 -> b 强 -> b 在顶
friend bool operator<(node a,node b){
return a.z<b.z;
}
};
// 声明:使用默认的大根堆机制
priority_queue<node> q;方案 2:小根堆 (竞赛黑科技流)
-
场景:Dijkstra 最短路、Prim、Huffman 树。
-
原理 :逻辑欺骗。通过反转布尔值,让队列误以为"数值小"的才是"强者"。
-
效果:小的先出 (1 -> 2 -> 9)。
cpp
struct node{
int z;
// 逻辑反转:若 a.z > b.z,返回 true (告诉队列 b 比 a "强")
// 结果:z 值小的会被判定为"强",放在堆顶
friend bool operator<(node a,node b){
return a.z>b.z; // <--- 重点:小于号里写大于逻辑
}
};
// 声明:无需修改队列定义,直接用
priority_queue<node> q;方案 3:小根堆 (工程正统流 ------ 配合 greater)
-
场景:工程代码、团队协作、需要显式语义。
-
原理 :替换裁判 。将比较器从默认的
less替换为greater。 -
要求 :结构体必须重载
operator>。
cpp
struct node{
int z;
// 逻辑:诚实重载大于号,不欺骗
friend bool operator>(node a,node b){
return a.z>b.z;
}
};
// 声明:显式指定 greater,并填补 vector 占位符
priority_queue<node,vector<node>,greater<node>> q;这份关于 operator< 参数顺序的解释非常硬核且直击痛点,很多教程都没讲透这一点。
把它补充在 "二、 优先队列的三种实战写法" 之后,作为 "三、 核心原理解析:参数顺序与逻辑陷阱" 是最合适的。因为上一章刚教了怎么写代码,这一章紧接着解释"为什么要这么写"以及"写反了会怎样"。
以下是整合后的完整章节内容(可以直接复制替换原来的文章结构):
三、 核心原理解析:参数顺序与逻辑陷阱 (必读)
在重载 friend bool operator<(Type a, Type b) 时,你给参数起名 x 还是 y 无所谓,但参数的位置 决定了谁是比较符号 < 左边的数,谁是右边的数。这是一个极易混淆的基础概念。
1. 核心规则:位置决定身份
当你写 friend bool operator < (Node a, Node b) 时,C++ 编译器遵循以下铁律:
-
第 1 个参数 (
a) :代表 小于号左边 的那个对象 (LHS, Left Hand Side)。 -
第 2 个参数 (
b) :代表 小于号右边 的那个对象 (RHS, Right Hand Side)。
当我们执行逻辑 x < y 时,编译器实际调用的是 operator<(x, y)。
2. 举例演示:张三 vs 李四
假设我们有两个病人,按等级 (level) 排序:
-
张三 (Left) :
level = 10 -
李四 (Right) :
level = 20 -
比较操作 :
张三 < 李四
情况 A:正常写法 (符合直觉)
cpp
friend bool operator < (people a, people b){
// a 是张三(10),b 是李四(20)
return a.level < b.level;
// 逻辑:10 < 20 -> 返回 true
}-
比较结果 :
true(张三比李四"小")。 -
优先队列行为 :
priority_queue判定 B (李四) 比 A (张三) 强。 -
最终效果 :大根堆。强者 (李四 20) 上浮至堆顶。
情况 B:逻辑反转 (参数逻辑写反)
如果你搞混了顺序,或者故意写反:
cpp
friend bool operator < (people a, people b){
// a 依然是张三(10),b 依然是李四(20)
return a.level > b.level; // <--- 逻辑反转!
// 逻辑:10 > 20 -> 返回 false
}-
比较结果 :
false(张三不比李四"小",在队列眼里张三比李四"强")。 -
最终效果 :小根堆。被视为"强"的张三 (10) 上浮至堆顶。
3. 为什么优先队列会受此影响?
std::priority_queue 的底层逻辑非常简单粗暴:
-
它不断调用
operator<(A, B)。 -
如果返回
true:它认为 B 的优先级比 A 高 (B is strict weak ordering greater than A)。 -
动作 :它把 B 往堆顶调整。
结论推导:
-
return a.val < b.val;\\rightarrow 数值大的优先级高 \\rightarrow 大数在顶。 -
return a.val > b.val;\\rightarrow 数值小的优先级高 \\rightarrow 小数在顶。
4. 万能公式
为了符合直觉,永远建议按标准写法来,需要小根堆时再去配合 greater 或修改逻辑,不要乱换参数位置:
cpp
// 标准模版
friend bool operator < (const Node& a, const Node& b) {
return a.属性 < b.属性; // 正常的升序逻辑 -> 对应大根堆
}四、 greater 与 std::sort 的深度用法
std::greater 是一个模板结构体(仿函数),其本质是调用类型的 operator>。
1. std::sort 的默认行为
默认使用 <,执行升序排列。
cpp
vector<int> v={1,5,3};
sort(v.begin(),v.end()); // 结果:1, 3, 52. 使用 greater 改为降序
传入 greater 实例,执行降序排列。
cpp
// 语法:greater<int>() 是构造一个临时对象
sort(v.begin(),v.end(),greater<int>()); // 结果:5, 3, 13. 结构体数组排序 (配合重载 >)
若对自定义结构体使用 greater 排序,结构体内部必须重载 >。
cpp
struct node{
int z;
// sort 降序需要 > 运算符支持
friend bool operator>(node a,node b){
return a.z>b.z;
}
};
vector<node> arr={{1},{5},{3}};
// 自动调用 operator>,实现 z 从大到小
sort(arr.begin(),arr.end(),greater<node>()); // 结果:5, 3, 1对比记忆表:
| 容器/算法 | 使用 greater 的效果 | 记忆口诀 |
|---|---|---|
std::sort |
降序 (Desc) | 大的排前面 |
std::priority_queue |
小根堆 (Min Heap) | 小的(被视为强)在堆顶 |
五、 多关键字排序与自定义仿函数 (进阶)
处理复杂逻辑(如:分数优先,ID 兜底)的两种核心范式。
场景设定
cpp
struct Student{int score,id;};目标:分数(score)高的优先;分数相同,学号(id)小的优先。
写法 A:结构体内部重载 (推荐比赛)
在一个 operator< 中处理所有层级逻辑。
cpp
struct Student{
int score,id;
friend bool operator<(Student a,Student b){
// 第一关键字:分数。分数高的在顶(大根堆逻辑)
// 若分数不相等,直接按分数定胜负
if(a.score!=b.score) return a.score<b.score;
// 第二关键字:学号(仅当分数相等时执行)
// 想要 id 小的在顶,需反转逻辑(小根堆逻辑)
return a.id>b.id;
}
};
priority_queue<Student> q;写法 B:外部仿函数 (工程推荐/解耦)
不修改结构体源码,通过定义外部"裁判类"控制排序。此方法可实现一套数据结构多种排序方式。
cpp
// 纯净数据结构
struct Student{int score,id;};
// 裁判 A:按分数优先
struct CmpScore{
bool operator()(Student a,Student b){
if(a.score!=b.score) return a.score<b.score;
return a.id>b.id;
}
};
// 裁判 B:纯按 ID 小的优先
struct CmpID{
bool operator()(Student a,Student b){
return a.id>b.id; // 小根堆逻辑
}
};
// 声明时传入具体裁判类型
priority_queue<Student,vector<Student>,CmpScore> q1;
priority_queue<Student,vector<Student>,CmpID> q2;六、 速查表 (多条件逻辑映射)
假设 Key1 为主键,Key2 为次键。基于默认 priority_queue (大根堆)。
| 需求模式 | 逻辑方向 | 代码写法 (friend operator <) |
|---|---|---|
| 全大优先 | 大顶 + 大顶 | if(a.k1!=b.k1)return a.k1<b.k1; return a.k2<b.k2; |
| 全小优先 | 小顶 + 小顶 | if(a.k1!=b.k1)return a.k1>b.k1; return a.k2>b.k2; |
| 混合模式 | 大顶 + 小顶 | if(a.k1!=b.k1)return a.k1<b.k1; return a.k2>b.k2; |
心法:
-
想让 大 的在顶:用
<(顺应默认)。 -
想让 小 的在顶:用
>(逻辑反转)。
七、 避坑指南
-
模板与对象的区别 (括号问题)
-
priority_queue需要的是类型 (Type) :priority_queue<..., Cmp>(无括号)。 -
sort需要的是对象实例 (Instance) :sort(..., Cmp())(有括号)。
-
-
greater的依赖性-
使用
greater<T>时,T必须重载operator>。 -
报错
no match for operator>通常是因为只写了<却用了greater。
-
-
引用与 Const
-
Friend (友元函数)写法:
friend bool operator<(node a,node b)(值传递,简单)。 -
Member (成员函数)写法:
bool operator<(const node& a) const(必须加 const,否则 STL 报错)。 -
建议:始终坚持使用 Friend 写法,语法负担最小。
-