专业词汇索引
- agent:我们把在环境中移动的物体叫agent,比如强化学习游戏中的马里奥。
- time step:每一次状态(state后面会讲)移动按照时间步来移动
- state:就是智能体相对于环境所处的状态(这个状态可以是很抽象的状态,最简单的就是地理位置,或者是机器人的此时的动作,想象一下你如果在用强化学习让机器人学会跳舞,那它此时的动作,就可以认为是它的状态。在金融数据中,很多特征融合到一起也能称为此时的状态)
- action:智能体从一个状态移动到另一个状态的动作(比如,迷宫探险,一共有四个方向,上下左右,这就是在迷宫探险中的action)
- state transition:状态转移,就是一个状态转换到另一个状态,s1->a2->s2,智能体从s1采取a2动作,到达了s2。
- policy:就是告诉智能体移动方向的概率,也就是智能体如何移动的策略。属于条件概率,Π(a1|s1)=0,处于s1状态,采取a1方向移动的概率为0
- reward:就是我们自己规定的智能体学习的方式,可以给一些惩罚或者是奖励。
- Trajectories:智能体在按照一定的策略运行下去,如果有终点,则这个路径是有限的,如果没有终点,则这个路径是无限的。Trajectories就是智能体运行的路径
- returns:智能体按照trajectories运行下去,得到的reward的总和。
- state value:智能体按照一个给定的策略所能够得到的平均reward
State Values and Bellman Equation
returns是智能体通过一个路径下,所获得的奖励的总和,通过returns能够知道如果智能体通过这样一个trajectory下,获得的奖励总和,来衡量与其他trajectory的比较,就能够知道哪一条道路更加适合。
State Values
假如一个状态在,前往
获得了立即奖励
,依次下去我们用
来表示所获得的路径奖励,表达式为
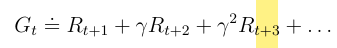
那么我们的State Values就可以用来表示,其计算公式可以用下列来表示
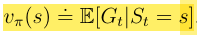
Bellman equation
state value可以写成如下的形式

我们分别来看这两个式子
第一个式子
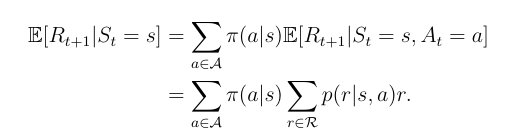
第二个式子
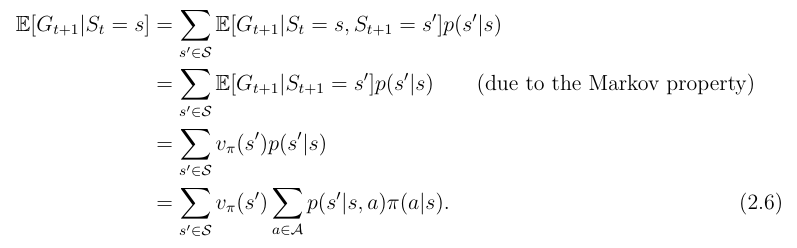
所以两个化简后的式子就可以总和为
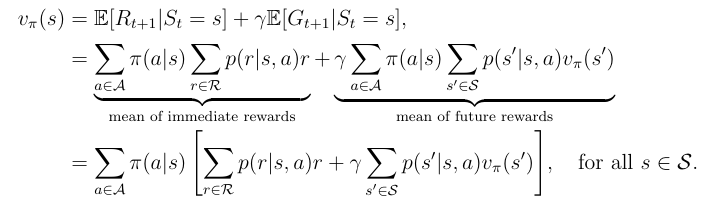
总结为
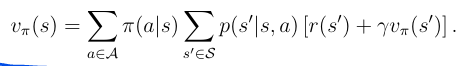
Action value
关于一个动作的价值方程,我们就叫做action value
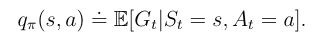
state value的值和action value之间的关系是