该论文是由牛津大学的Visual Geometry Group和Meta完成,VGGT(Visual Geometry Grounded Transformer)是一个开创性的前馈神经网络,专为高效的3D场景重建而设计,能够从一张、几张或数百张图像中直接推断场景的所有关键3D属性,并在不到一秒的时间内完成。与传统方法(如依赖Bundle Adjustment, BA)不同,VGGT采用大型Transformer架构,几乎没有3D诱导偏置,通过多样化的3D标注数据集训练而成。它在单一前向传递中预测相机参数(内参和外参)、深度图、点图和3D点轨迹,通常无需后处理即可优于优化-based的替代方案。该模型参数约1.2亿,支持零样本单视图重建,并能高效扩展到多视图输入。
论文地址:https://arxiv.org/pdf/2503.11651
代码地址:https://github.com/facebookresearch/vggt
Motivation
动机一:传统方法依赖于迭代优化技术(如Bundle Adjustment, BA)来实现相机参数估计、点云重建等任务,但这些方法复杂、计算成本高,通常需要结合机器学习辅助(如特征匹配或单目深度预测)。作者指出,随着神经网络的强大(如大型Transformer模型),可以尝试用前馈网络直接解决3D重建问题,而几乎完全避免几何后处理。这是对现有方法的进一步推进,例如DUST3R和MASt3R只能处理两张图像,需要昂贵的后处理(如全局对齐)来融合多视图结果,而VGGT旨在从单张、少量或数百张图像中一次性预测所有关键3D属性(相机参数、深度图、点图、点跟踪),在不到1秒内完成,且直接输出结果往往优于基于优化的方法。
动机二:构建一个通用骨干网络。VGGT不引入过多3D诱导偏置(如交叉注意力),而是像GPT、CLIP或DINO那样,通过大规模3D标注数据训练一个大型Transformer,使其成为多任务3D基础模型。该模型预测相互关联的3D属性,这有助于提升整体准确性。同时,VGGT的特征可提升下游任务,如非刚性点跟踪和新型视图合成。该方法简化了3D重建流程、提高效率和泛化能力,推动从"几何优化主导"向"神经网络主导"的范式转变。
方法
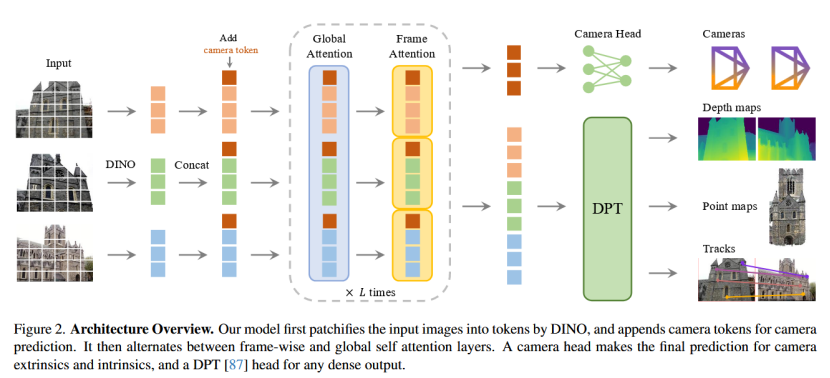
- 问题定义
输入观察同一3D场景的图像序列 ( I i ) i = 1 N (I_i){i=1}^N (Ii)i=1N,其中 I i ∈ R 3 × H × W I_i \in \mathbb{R}^{3 \times H \times W} Ii∈R3×H×W。
VGGT 将该组图像数据映射到对应的一组3D标注,每张图像都有一组对应的3D标注:
f ( ( I i ) i = 1 N ) = ( g i , D i , P i , T i ) i = 1 N f((I_i){i=1}^N) = (g_i, D_i, P_i, T_i)_{i=1}^N f((Ii)i=1N)=(gi,Di,Pi,Ti)i=1N
其中: g i ∈ R 9 g_i \in \mathbb{R}^9 gi∈R9 代表每张图像的相机参数, D i ∈ R H × W D_i \in \mathbb{R}^{H \times W} Di∈RH×W 代表该图像的深度, P i ∈ R 3 × H × W P_i \in \mathbb{R}^{3 \times H \times W} Pi∈R3×H×W 代表点云, T i ∈ R C × H × W T_i \in \mathbb{R}^{C \times H \times W} Ti∈RC×H×W 代表用于点跟踪的C维特征。相机参数使用 q , t , f q, t, f q,t,f 表示: q ∈ R 4 q \in \mathbb{R}^4 q∈R4 表示旋转四元数, t ∈ R 3 t \in \mathbb{R}^3 t∈R3 表示平移向量, f ∈ R 2 f \in \mathbb{R}^2 f∈R2 表示视场角。除了第一帧之外,模型不假设图像顺序,并假设相机的主点位于图像中心。
将图像像素位置(即图像的域)定义为
I i = { 1 , ... , H } × { 1 , ... , W } \mathcal{I}_i = \{1, \dots, H\} \times \{1, \dots, W\} Ii={1,...,H}×{1,...,W}每个像素点的位置 y ∈ I i y \in \mathcal{I}i y∈Ii 都有:一个深度值 D i ( y ) ∈ R + D_i(y) \in \mathbb{R}^+ Di(y)∈R+,一个3D点 P i ( y ) ∈ R 3 P_i(y) \in \mathbb{R}^3 Pi(y)∈R3 与之关联。遵循 DUSt3R 的设置,point maps 是视角不变的,即3D点 P i ( y ) P_i(y) Pi(y) 是在第一个相机 g 1 g_1 g1 的坐标系中定义的,并将其作为世界参考系。
对于关键点跟踪,遵循跟踪任意点(Track Anything)方法。给定查询图像 I q I_q Iq 中的固定查询像素点 y q y_q yq,网络输出由所有图像 I i I_i Ii 中对应的2D点 y i ∈ R 2 y_i \in \mathbb{R}^2 yi∈R2 形成的轨迹:
T ∗ ( y q ) = ( y i ) i = 1 N T^*(y_q) = (y_i){i=1}^N T∗(yq)=(yi)i=1N函数 f f f 不会直接输出轨迹 T ∗ T^* T∗,而是输出C维特征 T i T_i Ti。
除了第一帧图像被选为参考图像之外,其他输入图像的顺序是任意的。网络架构被设计为:除第一帧之外,其他帧都是排列等变的(permutation-equivariant)。
Over-complete Predictions:并非 VGGT 预测的所有量都是独立的。例如:相机参数 g g g 可以从点云图 P P P 中通过求解 Perspective-n-Point (PnP) 问题推断出来,深度图可以通过点云 P P P 和相机参数 g g g 推导出。但在训练期间,会让 VGGT 预测所有属性,以此带来性能提升。在推理过程中,与直接采用专门的点云分支相比,结合独立估计的深度图和相机参数可以产生更准确的3D点。 - 特征骨干
文中设计了一个具有最小3D偏置的架构,避免了复杂的3D偏置(如极线约束或视图特定匹配),而是让模型从充足的3D标注数据中学习。这种数据驱动的范式类似于大型语言模型(如GPT)或视觉模型(如DINO),通过规模化训练实现多任务能力。骨干网络将模型函数实现为一个大型Transformer。输入是多帧图像序列,输出是经过处理的令牌(tokens),用于后续预测头(prediction heads)。
输入预处理:每个输入图像 I I I 先通过 DINO patchify(分块化)处理,得到一组 K K K 个令牌。 K K K 取决于图像分辨率, C C C 是特征维度。DINO 是一个自监督视觉Transformer,用于提取丰富的图像特征。
多帧令牌聚合:所有帧的图像令牌被合并,形成一个全局令牌集合。这允许模型一次性处理任意数量的帧(从1到数百),而无需逐对处理(不同于 DUSt3R 仅限两视图)。
主网络结构:合并后的令牌通过交替帧内和全局自注意力层处理。在标准Transformer基础上进行了轻微调整,引入 Alternating-Attention (AA),让Transformer交替在帧内(within each frame)和全局(globally)焦点上切换,避免纯全局注意力可能带来的问题(如激活值不均或信息过载)。
- 帧内自注意力(frame-wise self-attention):仅关注每个帧内部的令牌,类似于独立处理每张图像,确保帧内特征(如纹理、边缘)得到归一化和强化,类似于单视图深度估计中的局部注意力。
- 全局自注意力(global self-attention):关注所有帧的令牌,允许跨帧信息融合(如匹配对应点或推断相对姿态),捕捉多视图几何关系,但不强制不对称交互。
- 交替方式:层级交替进行帧内和全局注意力,默认 L = 24 L=24 L=24 层(即总48层注意力层,交替叠加),在不同图像间整合信息的同时,归一化每个图像内令牌的激活值。
为什么要AA?
- 如果将所有输入帧的image tokens输入global attention,会导致模型认为不同图像中的相似外观部分来自同一张图片,为了让模型知道哪一个token来自哪一个frame,就需要AA机制;
- 模型本身对frame的输入顺序是不需要感知的,无论使用什么样的输入顺序,重建出来的图还应该是一样的,但如果使用frame index作为先验,则会导致改变frames的输入顺序就可能改变输出;
- 模型在训练阶段如果输入10帧到100帧是可以的,但是如果在推理时需要输入上千帧时,模型在训练的阶段并没有见过,将导致在推理时无法使用灵活的输入长度。
为什么该架构可以减少3D偏置?
在多视图3D重建模型(如DUST3R或类似架构)中,交叉注意力(cross-attention)被视为引入3D诱导偏置(3D inductive bias)的设计选择,主要原因如下:
- 强制视图间的不对称交互
交叉注意力通常将一个视图的查询(query)与另一个视图的键/值(key/value)进行交互,例如在DUST3R的解码器中,先进行自注意力(self-attention,自视图内token交互),然后用交叉注意力让一个视图的token"attend"到另一个视图的特征。这种机制隐含地假设视图之间存在特定的对应关系(如像素匹配或几何对齐),这是一种内置的3D几何偏置。
这种不对称设计鼓励模型优先学习跨视图的对应(如匹配相同3D点的2D投影),类似于传统立体视觉中的极线约束(epipolar geometry)或特征匹配,但以数据驱动方式实现。这使得模型在架构层面就"偏向"3D重建任务,而非从数据中纯净地学习通用表示。 - 引入视图依赖的假设
交叉注意力假设共享视觉内容(如纹理、形状)可以可靠地在3D空间中匹配,从而学习视图不变特征(view-invariant features)。这虽然有助于处理未知相机姿态或内在参数,但也引入了潜在偏差:模型可能过度依赖训练数据中的常见视图重叠或视角变化,如果场景有极小重叠、极端旋转或非刚性变形,注意力机制可能无法有效对齐,导致泛化问题。
与之相比,全局自注意力(如VGGT中的交替注意力)对待所有token平等,不强制这种视图间交叉,而是让模型在全局上下文中自然学习关系。这减少了特定于3D的结构偏置,使架构更通用,类似于大型语言模型(如GPT)中无偏置的自注意力。 - 与最小偏置设计的对比
在VGGT等模型中,作者强调"minimal 3D-inductive biases",并明确避免交叉注意力,只用自注意力(帧内和全局交替)。实验消融显示,使用交叉注意力的变体性能更差(如在ETH3D数据集上整体误差更高),因为它增加了不必要的复杂性和偏置,而非让模型从大量3D标注数据中自由学习。
预测头
相机头: VGGT 模型的预测头部分首先处理相机参数的预测。在处理前,为每个输入图像 I i I_i Ii 的图像令牌 t I i t_I^i tIi 添加一个额外的相机令牌 t i g ∈ R 1 × C ′ t_i^g \in \mathbb{R}^{1 \times C'} tig∈R1×C′ 和四个注册令牌 t i R ∈ R 4 × C ′ t_i^R \in \mathbb{R}^{4 \times C'} tiR∈R4×C′。这些令牌的连接被传入 Alternating-Attention (AA) Transformer,输出精炼后的令牌 ( t ^ I i , t ^ i g , t ^ i R ) i = 1 N (\hat{t}_I^i, \hat{t}_i^g, \hat{t}i^R){i=1}^N (t^Ii,t^ig,t^iR)i=1N。第一帧的相机和注册令牌使用特殊的可学习令牌 t ˉ g , t ˉ R \bar{t}^g, \bar{t}^R tˉg,tˉR,以区分参考帧并在第一相机的坐标系中表示 3D 预测。其他帧使用共享的可学习令牌 t ^ g , t ^ R \hat{t}^g, \hat{t}^R t^g,t^R。输出注册令牌 t ^ i R \hat{t}_i^R t^iR 被丢弃,而 t ^ I i \hat{t}_I^i t^Ii 和 t ^ i G \hat{t}_i^G t^iG 用于预测。坐标系定义为第一相机 g 1 g_1 g1 的坐标系,因此第一相机的外参设置为单位:旋转四元数 q 1 = 0 , 0 , 0 , 1 q_1 = 0,0,0,1 q1=0,0,0,1,平移向量 t 1 = 0 , 0 , 0 t_1 = 0,0,0 t1=0,0,0。特殊令牌帮助 Transformer 识别第一相机。相机预测(Camera Predictions)具体从输出相机令牌种提取,使用四个额外的自注意力层后跟一个线性层,形成相机头。该头预测相机内参和外参。
密集头: 密集预测(Dense Predictions)使用输出图像令牌 t ^ i I \hat{t}_i^I t^iI 来生成密集输出,包括深度图 D i D_i Di、点图 P i P_i Pi 和跟踪特征 T i T_i Ti。这些令牌通过 DPT 层 87 转换为密集特征图,每个 F i F_i Fi 通过一个 3x3 卷积层映射到对应的深度图 D i D_i Di 和点图 P i P_i Pi。DPT 头还输出密集特征 T i ∈ R C × H × W T_i \in \mathbb{R}^{C \times H \times W} Ti∈RC×H×W,作为跟踪头的输入。

跟踪头: 基于 CoTracker2,使用 T 计算查询点 y q y_q yq 的跨帧对应 y i y_i yi,支持无序图像。

训练
端到端多任务损失 L = L c a m e r a + L d e p t h + L p m a p + λ L t r a c k L = L_{camera} + L_{depth} + L_{pmap} + \lambda L_{track} L=Lcamera+Ldepth+Lpmap+λLtrack( λ = 0.05 \lambda = 0.05 λ=0.05)。使用 Huber 损失、不确定性加权 L1+梯度损失、可见性 BCE。坐标归一化: 以第一帧为参考,平均点到原点距离缩放。数据: 混合 Co3Dv2、MegaDepth 等数据集,批次随机 2-24 帧,增强包括颜色抖动、模糊。优化: AdamW,160K 迭代,64 A100 GPU,9 天。推理: 单前馈,0.2s/10 帧。点图可从深度+相机派生(更准)。可结合 BA 精炼。方法强调多任务学习提升互补属性,尽管冗余(如点图可从深度+相机推导),但实验证明有益。
分析
尽管VGGT在效率和准确率上领先,但存在局限。
计算资源高:1.2B参数,训练需9天64 A100 GPU,推理内存随帧数线性增长(200帧40GB),限制边缘设备部署。全局注意力对大量帧内存密集。
场景局限:不支持鱼眼/全景图像,极端旋转或大幅非刚性变形(如动态视频)失败,仅处理轻微运动。
依赖后处理:前向虽优于其他方法,但BA仍提升显著(如AUC@30从85.3到93.5),表明直接预测并非总最优,尤其复杂场景。
数据依赖:需大量3D标注数据,潜在偏差(如合成vs.真实)。不确定性预测虽有,但未充分探索鲁棒性(如噪声、光照变化)。
其他:不处理时序(虽支持无序,但动态任务需微调);注册令牌等设计虽有效,但增加复杂性。