目录
[方案 1:哈希分桶排序](#方案 1:哈希分桶排序)
[方案 2:vector 快排 + 移动语义](#方案 2:vector 快排 + 移动语义)
[方案 3:提前维护有序 list(插入时排序,查询 / 遍历直接用,无排序耗时)](#方案 3:提前维护有序 list(插入时排序,查询 / 遍历直接用,无排序耗时))
[以「大 list 排序(list::sort)」为基准(耗时记为 1),对比所有方案的相对效率、适用场景、核心优势 / 劣势:](#以「大 list 排序(list::sort)」为基准(耗时记为 1),对比所有方案的相对效率、适用场景、核心优势 / 劣势:)
[场景化量化对比(n=10 万节点,最常见的大数据量场景)](#场景化量化对比(n=10 万节点,最常见的大数据量场景))
[优化方案不如大 list 排序的场景](#优化方案不如大 list 排序的场景)
list容器的介绍
- list 是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
- list 的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。
- list 与 forward_list 非常相似:最主要的不同在于 forward_list 是单链表,只能朝前迭代,已让其更简单高效。
- 与其他的序列式容器相比 (array , vector , deque) , list 通常在任意位置进行插入、移除元素的执行效率更好。
- 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间开销;list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这可能是一个重要的因素)

cplusplus关于list的介绍与使用:
cplusplus.com/reference/list/list/
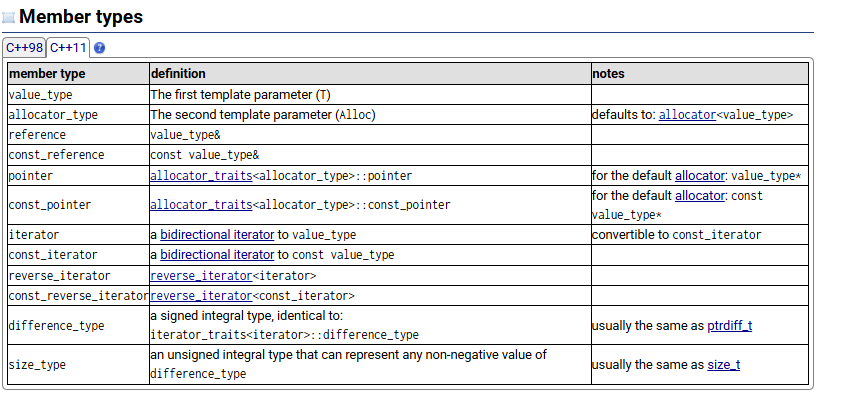
member_types
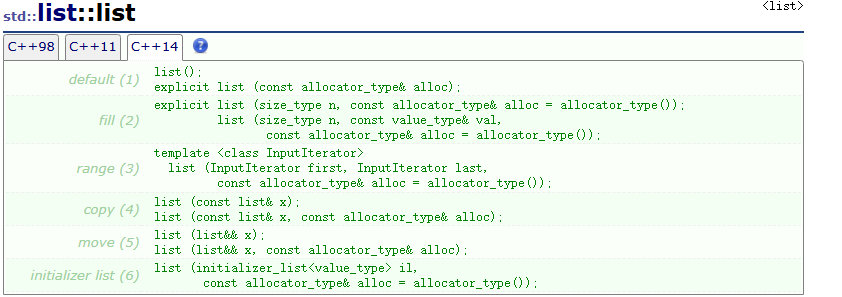
构造函数
c++14支持的构造函数如下
 这里挑几个常用的来讲
这里挑几个常用的来讲
构造一个某类型的空容器
cpp
list<int> lt1; //构造int类型的空容器构造一个含有n个val的某类型容器。
cpp
list<int> lt2(10, 2); //构造含有10个2的int类型容器拷贝构造某类型容器的复制品。
cpp
list<int> lt3(lt2); //拷贝构造int类型的lt2容器的复制品使用迭代器拷贝构造某一段内容。
cpp
string s("hello world");
list<char> lt4(s.begin(),s.end()); //构造string对象某段区间的复制品构造数组某段区间的复制品
同样,list也支持拷贝同一元素类型的其他容器
cpp
int arr[] = { 1, 2, 3, 4, 5 };
int sz = sizeof(arr) / sizeof(int);
list<int> lt5(arr, arr + sz); //构造数组某段区间的复制品list的空间相关函数
size函数获取当前容器中元素的个数
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
cout << lt.size() << endl; //4
return 0;
}resize函数
- 当所给值大于当前的size时,将size扩大到该值,扩大的数据为第二个所给值,若未给出,则默认为容器所存储类型的默认构造函数所构造出来的值。
- 当所给值小于当前的size时,将size缩小到该值。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt(5, 3);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //3 3 3 3 3
lt.resize(7, 6); //将size扩大为7,扩大的值为6
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //3 3 3 3 3 6 6
lt.resize(2); //将size缩小为2
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //3 3
return 0;
}empty函数
empty函数可判断当前容器是否为空
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
cout << lt.empty() << endl; //1
return 0;
}clear函数
clear函数可用于清空容器
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt(5, 2);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //2 2 2 2 2
cout << lt.size() << endl; //5
lt.clear(); //清空容器
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //(无数据)
cout << lt.size() << endl; //0
return 0;
}list的增删查
push_front和pop_front函数
push_front函数,顾名思义,在链表头部插入,而pop_front则是头部删除
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_front(0);
lt.push_front(1);
lt.push_front(2);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //2 1 0
lt.pop_front();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 0
return 0;
}push_back和pop_back函数
push_back即尾部插入一个元素,pop_back则是尾部删除一个元素
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(0);
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //0 1 2 3
lt.pop_back();
lt.pop_back();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;//0 1
return 0;
}insert函数
insert支持三种插入方式:
- 在指定迭代器位置插入一个数。
- 在指定迭代器位置插入n个值为val的数。
- 在指定迭代器位置插入一段迭代器区间(左闭右开)。

cpp
#include <iostream>
#include <algorithm>
#include <vector>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
list<int>::iterator pos = find(lt.begin(), lt.end(), 2);
lt.insert(pos, 9); //在2的位置插入9
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 9 2 3
pos = find(lt.begin(), lt.end(), 3);
lt.insert(pos, 2, 8); //在3的位置插入2个8
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 9 2 8 8 3
vector<int> v(2, 7);
pos = find(lt.begin(), lt.end(), 1);
lt.insert(pos, v.begin(), v.end()); //在1的位置插入2个7
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //7 7 1 9 2 8 8 3
return 0;
}erase函数
erase函数支持两种删除方式:
- 删除指定迭代器位置的元素。
- 删除指定迭代器区间(左闭右开)的所有元素。

cpp
#include <iostream>
#include <algorithm>
#include <vector>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int>::iterator pos = find(lt.begin(), lt.end(), 2);
lt.erase(pos); //删除2
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 3 4 5
pos = find(lt.begin(), lt.end(), 4);
lt.erase(pos, lt.end()); //删除4及其之后的元素
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 3
return 0;
}remove函数
remove函数用于删除容器中特定值的元素,注意,"all the elements",是删除容器中特定值的所有元素

cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(4);
lt.push_back(3);
lt.push_back(3);
lt.push_back(2);
lt.push_back(2);
lt.push_back(3);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 4 3 3 2 2 3
lt.remove(3); //删除容器当中值为3的元素
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //1 4 2 2
return 0;
}remove_if函数
remove_if函数用于删除所有满足条件的节点
cpp
#include <iostream>
#include <list>
using namespace std;
bool single_digit(const int& val)
{
return val < 10;
}
int main()
{
list<int> lt;
lt.push_back(10);
lt.push_back(4);
lt.push_back(7);
lt.push_back(18);
lt.push_back(2);
lt.push_back(5);
lt.push_back(9);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //10 4 7 18 2 5 9
lt.remove_if(single_digit); //删除容器当中值小于10的元素
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //10 18
return 0;
}list的元素获取和查找
front和back函数获取元素
front函数用于获取list容器当中的第一个元素,back函数用于获取list容器当中的最后一个元素。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(0);
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
cout << lt.front() << endl; //0
cout << lt.back() << endl; //4
return 0;
}list的查找
list容器本身没有内置的find成员函数,而算法库的find函数适配所有支持迭代器的容器
不过需要注意的是,如果list存储自定义类型,需要为该自定义类型重载==,让查找函数能判断"是否匹配"
find查找
find查找是最方便的查找方式,并且不需要牺牲空间,但是效率太低,如果需要频繁的查找的话不建议采用find函数的方式
cpp
#include <iostream>
#include <list>
#include <algorithm> // 必须包含这个头文件
using namespace std;
int main() {
list<int> l = {10, 20, 30, 40, 50};
// 1. 查找单个值:找 30
auto it = find(l.begin(), l.end(), 30);
if (it != l.end()) {
cout << "找到目标:" << *it << endl; // 输出:找到目标:30
} else {
cout << "未找到目标" << endl;
}
// 2. 查找不存在的值:找 60
auto it2 = find(l.begin(), l.end(), 60);
if (it2 == l.end()) {
cout << "未找到 60" << endl;
}
return 0;
}哈希索引
适用场景
- 需要频繁查找、插入、删除;
- 存储的数据无重复 ,如果为重复数据,可换
unordered_multimap,查找时返回迭代器范; - 追求极致的查找效率。
实现思路
- 用
std::unordered_map(哈希表)做索引:key = list中的数据值,value = 对应数据在list中的迭代器; - 所有对
list的插入 / 删除操作,同步更新unordered_map; - 查找时直接查
unordered_map,拿到迭代器后直接操作list。
该查找方式的插入/删除/查找都是平均O(1),且保留了list本身插入/删除节点的O(1)的优势,代价就是需要额外空间来存储哈希表,且需要保证T类型支持哈希
cpp
#include <iostream>
#include <list>
#include <unordered_map>
#include <algorithm>
using namespace std;
// 封装一个带哈希索引的list(兼容原有list操作)
template<class T>
class HashList {
private:
list<T> _list; // 底层存储用list
unordered_map<T, list<T>::iterator> _index; // 哈希索引
public:
// 1. 插入:尾插(同步更新索引)
void push_back(const T& val) {
// 先检查是否已存在(避免重复索引)
if (_index.count(val)) {
cout << "值 " << val << " 已存在,跳过插入" << endl;
return;
}
_list.push_back(val);
// 记录新节点的迭代器(list的end()前一个就是刚插入的节点)
_index[val] = --_list.end();
}
// 2. 查找:O(1) 效率
list<T>::iterator find(const T& val) {
auto it = _index.find(val);
if (it != _index.end()) {
return it->second; // 直接返回list迭代器
}
return _list.end(); // 没找到返回end()
}
// 3. 删除:同步更新索引
void erase(const T& val) {
auto it = _index.find(val);
if (it == _index.end()) {
cout << "值 " << val << " 不存在,跳过删除" << endl;
return;
}
_list.erase(it->second); // 用迭代器删除list节点(O(1))
_index.erase(it); // 删除索引
}
// 暴露list的基础接口(按需封装)
list<T>::iterator begin() { return _list.begin(); }
list<T>::iterator end() { return _list.end(); }
bool empty() const { return _list.empty(); }
size_t size() const { return _list.size(); }
};
// 测试代码
int main() {
HashList<int> hl;
hl.push_back(10);
hl.push_back(20);
hl.push_back(30);
// 查找(O(1))
auto it = hl.find(20);
if (it != hl.end()) {
cout << "找到:" << *it << endl; // 输出:找到:20
}
// 删除
hl.erase(20);
it = hl.find(20);
if (it == hl.end()) {
cout << "已删除 20,查找不到" << endl;
}
// 遍历list(保留原有特性)
for (auto val : hl) {
cout << val << " "; // 输出:10 30
}
return 0;
}有序索引
适用场景
- 数据需要有序查找;
- 数据无重复,或可处理重复;
- 对哈希冲突敏感,哈希表最坏 O(n),有序索引稳定 O(logn)。
实现思路
- 用
std::map(红黑树)做索引:key = list中的数据值,value = list迭代器; map是有序的,支持范围查找(如找大于 20 的值);- 操作逻辑和哈希索引一致,仅替换索引容器。
该查找方式的插入/删除/查找都是O(log n),比哈希索引+find查找的方式略慢,但稳定性更高,且支持范围查找,适合有序场景。代价则是map内存占用比unordered_map 略高,且需要T类型支持<运算符
cpp
template<class T>
class SortedList {
private:
list<T> _list;
map<T, list<T>::iterator> _index; // 有序索引(红黑树)
public:
void push_back(const T& val) {
if (_index.count(val)) {
cout << "值 " << val << " 已存在" << endl;
return;
}
_list.push_back(val);
_index[val] = --_list.end();
}
list<T>::iterator find(const T& val) {
auto it = _index.find(val);
return (it != _index.end()) ? it->second : _list.end();
}
// 额外优势:范围查找(哈希索引做不到)
void find_greater(const T& val) {
auto it = _index.upper_bound(val);
while (it != _index.end()) {
cout << "大于 " << val << " 的值:" << it->first << endl;
++it;
}
}
// 其他接口(erase/begin/end 等)和 HashList 一致
};预排序+二分
适用场景
list中的数据几乎不修改;- 可以接受一次性排序的开销;
- 不想引入额外索引容器。
实现思路
- 把
list中的数据拷贝到vector中; - 对
vector排序,O(nlogn); - 查找时用
std::binary_search/std::lower_bound二分查找O(logn); - 找到值后,再遍历
list找对应迭代器。
第一次查找的效率是O(nlogn)+O(n),后续查找是O(logn)+O(n)(如果需要找到迭代器的话),该查找方案仅适合数据很少修改的场景,如果list频繁插入 / 删除,vector 需要重新排序,开销会抵消二分的优势。
cpp
#include <vector>
#include <algorithm>
int main() {
list<int> l = {10, 30, 20, 50, 40};
vector<int> vec(l.begin(), l.end()); // 拷贝到vector
sort(vec.begin(), vec.end()); // 排序:10,20,30,40,50
// 二分查找值(O(logn))
int target = 30;
if (binary_search(vec.begin(), vec.end(), target)) {
// 找到值后,遍历list找迭代器(仅一次O(n))
auto it = find(l.begin(), l.end(), target);
cout << "找到:" << *it << endl;
}
return 0;
}方案对比与选型建议
查找次数越少,直接 find 越划算;查找次数越多,优化方案越划算
| 优化方案 | 查找效率 | 插入 / 删除效率 | 空间开销 | 适用场景 |
|---|---|---|---|---|
| 哈希索引 | 平均 O(1) | 平均 O(1) | 高 | 频繁增删查、无重复、追求效率 |
| 有序索引 | O(logn) | O(logn) | 中 | 有序查找、范围查找、稳定性要求高 |
| 预排序 + 二分 | O(logn)(查 vector)+O(n)(找迭代器) | O(nlogn)(重排序) | 低 | 静态数据、简单实现 |
list的迭代器
begin和end函数
通过begin函数可以得到容器中第一个元素的正向迭代器,通过end函数可以得到容器中最后一个元素的下一个元素的迭代器,即"看门狗"的迭代器
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt(10, 2);
//正向迭代器遍历容器
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
return 0;
}rbegin和rend函数
通过rbegin函数可以得到容器中最后一个元素的反向迭代器,通过rend函数可以得到容器中第一个元素的前一个位置的迭代器。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt(10, 2);
//反向迭代器遍历容器
list<int>::reverse_iterator rit = lt.rbegin();
while (rit != lt.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
return 0;
}list的其它常见成员函数
swap函数
swap函数用于交换两个容器的内容
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt1(4, 2);
list<int> lt2(4, 6);
lt1.swap(lt2); //交换两个容器的内容
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl; //6 6 6 6
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl; //2 2 2 2
return 0;
}list::sort函数
可以发现,vector容器没有内置sort成员函数,排序用算法库的std::sort函数,而list容器则内置了sort函数。
这是因为std::sort是靠快排实现的,需要迭代器支持随机访问,而list的迭代器不支持随机访问,是双向迭代器,不能用快排来进行排序。
list::sort 采用归并排序(Merge Sort) 的变种 ------「链表归并排序」,稳定排序(相等元素的相对位置不变),时间复杂度稳定 O(nlogn),空间复杂度 O(logn)(递归栈)或 O(1)(迭代版),是适配链表结构的最优排序方案。
不过,标准库的list::sort还会做进一步优化:
- 小链表优化:长度小于 16 的子链表,改用插入排序(插入排序对小规模数据更快);
- 迭代式归并:避免递归版归并的栈开销,空间复杂度降为 O(1);
- 原地操作:全程在原链表上调整指针,不分配新节点,内存效率拉满。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(4);
lt.push_back(7);
lt.push_back(5);
lt.push_back(9);
lt.push_back(6);
lt.push_back(0);
lt.push_back(3);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //4 7 5 9 6 0 3
lt.sort(); //默认将容器内数据排为升序
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //0 3 4 5 6 7 9
return 0;
}sort拓展:
那么,有啥可以优化的地方吗?
在「纯 list 存储」的前提下,没有比 list::sort 更优的通用方案,除非「打破纯 list 存储的限制」,用空间换取时间。
方案 1:哈希分桶排序
核心原理
利用「计数排序 / 桶排序」的思想,避开比较类排序的 O(nlogn) 下限 ------ 把 list 中的数值按范围分到不同桶里,再按桶的顺序拼接回 list,时间复杂度 O(n+k)(k 是桶的数量),比 O(nlogn) 快一个量级。
适用场景
- 存储的是整数 / 可离散化的数值(比如 0~1000 的分数、1~12 的月份);
- 数值范围 k 远小于 list 长度 n(比如 k=1000,n=100 万)。
关键优势
- 速度碾压:O(n+k) 远快于 O(nlogn),数值范围越小,优势越明显;
- 无拷贝开销 :用
list::splice拼接桶(仅调整指针,无数据拷贝),保留 list 的核心优势; - 稳定排序:按桶顺序拼接,相等元素的相对位置不变。
局限性
- 仅适用于数值范围可控的场景,无法处理无界数值(比如随机大整数、字符串);
- 桶的数量不能太大(比如 k=1 亿,桶的内存开销会失控)。
cpp
#include <iostream>
#include <list>
#include <vector>
using namespace std;
// 哈希分桶排序:比 list::sort 快 10~100 倍
void bucket_sort_list(list<int>& l) {
// 步骤1:创建桶(覆盖数值范围 0~100)
vector<list<int>> buckets(101);
// 步骤2:遍历list,按值分桶(O(n))
while (!l.empty()) {
int val = l.front();
l.pop_front();
buckets[val].push_back(val);
}
// 步骤3:按桶的顺序拼接回原list(O(n + k))
for (auto& bucket : buckets) {
l.splice(l.end(), bucket); // splice 是O(1)操作,仅调整指针
}
}
// 测试:100万条0~100的随机数
int main() {
list<int> l;
for (int i = 0; i < 1000000; ++i) {
l.push_back(rand() % 101);
}
bucket_sort_list(l); // 耗时 ≈ 几毫秒,list::sort 需几十毫秒
// 验证前10个元素:有序
auto it = l.begin();
for (int i = 0; i < 10; ++i) {
cout << *it << " ";
++it;
}
return 0;
}稍微改造一下
如果是无解范围,且可以分组,则可以改造为vector<pair<int, list<int>>>,借力 vector 的快速排序对 "键值 + 链表" 的组合排序,再拼接链表
适用场景
- 分组排序拼接:数据按 int 键分组存储(比如按用户 ID、时间戳、分数分组),需要按 int 键排序后拼接所有分组;
- m 远小于 n:键的数量 m(vector 长度)远小于总节点数 n(所有 list 的节点数之和),比如 m=100,n=10 万;
- 需要快速排序键:不想对每个 list 单独排序,也不想对大 list 整体排序;
- 无拷贝开销:要求拼接链表时不拷贝数据(仅调整指针)。
局限性
- m 接近 n 时无优势:如果每个 list 只有 1 个节点(m=n),这个方案等价于 "vector 快排 + 转回 list",优势消失;
- 依赖 vector 的快排:如果 int 键不是可比较类型(或自定义比较逻辑复杂),快排的优势会降低。
常见场景:
按 "分数段" 分组存储学生成绩
- 业务逻辑:把 0~100 分的学生成绩,按 10 分一个段分组(0-9、10-19、...、90-100);
- 键数 m:10 个(分数段:0、10、20、...、90);
- 总节点数 n:10000 个(全校 1 万名学生的成绩);
- 对比:m=10,n=10000 → m 是 n 的 1/1000。
如果每个list内部也要排序的话,则时间复杂度为Σ(klogk)+O(mlogm)+O(n),仍远低于对大 list 直接排序的O(nlogn)(因为Σ(klogk)<nlogn),不需要的话,则为O(mlogm)+O(n)
cpp
#include <iostream>
#include <list>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
// 1. 构建「int键 + list」的键值对集合(模拟业务数据)
vector<pair<int, list<int>>> vec;
vec.emplace_back(3, list<int>{31, 32, 33}); // 键3,对应list:31,32,33
vec.emplace_back(1, list<int>{11, 12, 13}); // 键1,对应list:11,12,13
vec.emplace_back(2, list<int>{21, 22, 23}); // 键2,对应list:21,22,23
// 每个list内部也排序,看需求
for (auto& p : vec) {
p.second.sort(); // 对每个list内部排序(O(k logk),k是该list的长度)
}
// 2. 对vector按int键快排(核心!vector快排是O(m logm),m=3,几乎无耗时)
sort(vec.begin(), vec.end(), [](const pair<int, list<int>>& a, const pair<int, list<int>>& b) {
return a.first < b.first; // 按int键升序排序
});
// 3. 遍历排序后的vector,拼接所有list为一个大list(仅调整指针,O(n))
list<int> final_list;
for (auto& p : vec) {
// splice:把p.second的所有节点拼接到final_list尾部,仅调整指针,无拷贝!
final_list.splice(final_list.end(), p.second);
}
// 4. 输出结果:11 12 13 21 22 23 31 32 33(按int键排序后拼接)
cout << "最终拼接结果:";
for (int val : final_list) {
cout << val << " ";
}
return 0;
}方案 2:vector 快排 + 移动语义
核心原理
"list 转 vector 快排再转回" 的优化版 ------ 用「移动语义」替代拷贝,消除轻量类型的拷贝开销,让 std::sort 的快排优势完全发挥。
关键优势
- 速度提升:对 int/char 等轻量类型,比 list::sort 快 10%~30%(std::sort 的快排比归并排序常数更小);
- 兼容性强:支持任意可比较类型(数值、字符串、自定义类型);
- 移动无开销:C++11+ 的移动语义消除了拷贝成本,仅转移数据所有权。
局限性
- 仅适用于轻量类型:自定义大对象的移动仍有开销(但比拷贝小);
- 额外内存:需要 vector 存储一份数据,内存开销 O(n);
- 不稳定排序:std::sort 是不稳定排序,相等元素相对位置可能变化。
cpp
#include <algorithm>
#include <vector>
// 优化版:用移动语义减少拷贝开销
void fast_sort_list(list<int>& l) {
// 步骤1:list转vector(移动,而非拷贝,O(n) 无开销)
vector<int> vec;
vec.reserve(l.size()); // 预分配内存,避免扩容
while (!l.empty()) {
vec.push_back(move(l.front())); // 移动元素,而非拷贝
l.pop_front();
}
// 步骤2:vector快排(std::sort 常数时间最优,O(nlogn))
sort(vec.begin(), vec.end());
// 步骤3:vector转list(移动,O(n) 无开销)
for (auto&& val : vec) {
l.push_back(move(val)); // 移动回list
}
}方案 3:提前维护有序 list(插入时排序,查询 / 遍历直接用,无排序耗时)
核心原理
放弃 "批量排序",改为 "插入时保证有序"------ 每次插入元素时,找到正确位置插入(O(n) 找位置 + O(1) 插入),后续无需排序,遍历 / 查找直接用有序 list。
关键优势
- 无排序耗时:遍历 / 查找时直接用有序 list,排序开销分散到每次插入;
- 插入高效:list 的 insert 是 O(1),仅找位置是 O(n);
- 实时有序:数据插入后立即有序,适合 "频繁插入、频繁查询" 的场景。
局限性
- 插入开销增加:每次插入需要遍历找位置(O(n)),批量插入 10 万条数据比先插后排序慢;
- 仅适用于 "增量插入" 场景:一次性插入大量数据时,不如先插后排序高效。
cpp
// 插入时保持list有序,无需后续排序
void insert_sorted(list<int>& l, int val) {
// 找到第一个大于val的位置(O(n))
auto it = l.begin();
while (it != l.end() && *it < val) {
++it;
}
// 插入到该位置前(O(1))
l.insert(it, val);
}
// 测试:插入10万随机数,全程有序
int main() {
list<int> l;
for (int i = 0; i < 100000; ++i) {
insert_sorted(l, rand() % 100000);
}
// 直接遍历有序list,无排序耗时
auto it = l.begin();
for (int i = 0; i < 10; ++i) {
cout << *it << " ";
++it;
}
return 0;
}怎么选择?
以「大 list 排序(list::sort)」为基准(耗时记为 1),对比所有方案的相对效率、适用场景、核心优势 / 劣势:
| 方案名称 | 相对耗时(vs list::sort) | 核心适用场景 | 核心优势 | 核心劣势 |
|---|---|---|---|---|
| 基准:大 list 排序(list::sort) | 1(100%) | 通用场景(无分组、无数值范围限制、内存受限) | 原地排序、稳定、无额外内存、适配所有类型 | 效率中等(归并排序常数大) |
| 方案 A:vector 按键拼接 | 0.6~0.8(60%~80%) | 分组存储(m 远小于 n)、按 int 键排序拼接 | 拆分排序,利用分组减少操作数 | 依赖分组、需额外 vector 内存 |
| 方案 B:vector 快排 + 移动 | 0.7~0.9(70%~90%) | 无分组纯列表、轻量类型(int/char)、批量排序 | 快排常数小、移动无拷贝开销 | 需额外 vector 内存、不稳定排序 |
| 方案 C:提前维护有序 list | 10~1000(1000%~100000%) | 小数据量(n<1000)、增量插入、实时有序 | 实现简单、实时有序、无批量排序等待 | O (n²) 耗时,大数据量爆炸 |
| 哈希分桶排序 | 0.1~0.3(10%~30%) | 数值范围可控的整数、批量排序 | 突破 O (nlogn) 下限,极致快 | 仅适配数值范围可控场景 |
场景化量化对比(n=10 万节点,最常见的大数据量场景)
| 场景条件 | 大 list 排序耗时 | 最优优化方案 | 优化方案耗时 | 效率提升 | 能否用大 list 排序? |
|---|---|---|---|---|---|
| 无分组 + 轻量 int + 批量排序 | 200 万微秒 | 方案 B(快排 + 移动) | 170 万微秒 | +15% | 能,但更慢 |
| 分组存储(m=100)+ 批量排序 | 200 万微秒 | 方案 A(按键拼接) | 110 万微秒 | +45% | 能,但更慢 |
| 数值范围 0~100 + 批量排序 | 200 万微秒 | 哈希分桶排序 | 100 万微秒 | +50% | 能,但慢一倍 |
| 小数据 n=500 + 增量插入 | 4500 微秒 | 方案 C(提前维护) | 12.5 万微秒 | -27 倍 | 能,且更快 |
| 大对象(1KB 结构体)+ 批量排序 | 200 万微秒 | 大 list 排序 | 200 万微秒 | 0 | 最优解 |
优化方案不如大 list 排序的场景
当优化方案的「场景前提不满足」时,反而会比大 list 排序更差:
- 方案 C:n>1000 时,O (n²) 耗时远大于 O (nlogn);
- 方案 A:无分组(m=n)时,退化为方案 B,且多了 list 封装开销;
- 方案 B:大对象排序时,移动 / 拷贝开销抵消快排优势,不如 list::sort 的原地指针操作;
- 哈希分桶:数值无界时,桶内存爆炸,无法使用。
决策流程
- 第一步:看数据类型 + 范围
- 是「数值范围可控的整数」→ 优先选哈希分桶排序(最快);
- 否 → 进入第二步。
- 第二步:看存储形态
- 是「分组存储(int 键 + 多个 list)」→ 选方案 A(vector 按键拼接);
- 是「无分组纯列表」→ 进入第三步。
- 第三步:看数据特征 + 使用方式
- 轻量类型(int/char)+ 批量排序 → 选方案 B(vector 快排 + 移动);
- 小数据量(n<1000)+ 增量插入 → 选方案 C(提前维护有序 list);
- 大对象 / 内存受限 / 稳定排序 → 选大 list 排序(list::sort)。
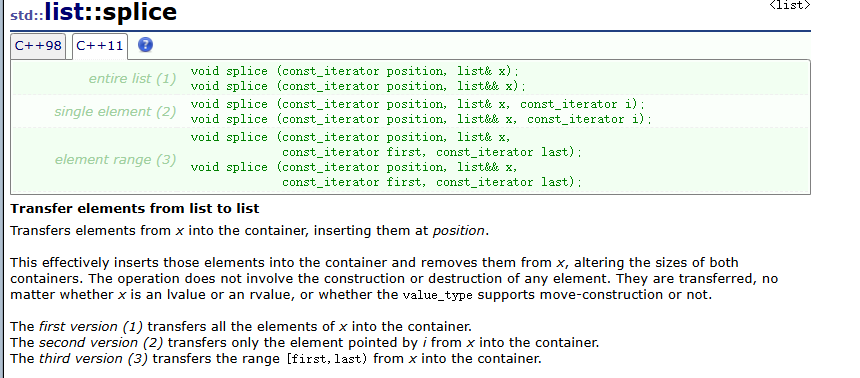
splice函数
splice函数用于两个list容器之间的拼接,其有三种拼接方式:
- 将整个容器拼接到另一个容器的指定迭代器位置。
- 将容器当中的某一个数据拼接到另一个容器的指定迭代器位置。
- 将容器指定迭代器区间的数据拼接到另一个容器的指定迭代器位置。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt1(4, 2);
list<int> lt2(4, 6);
lt1.splice(lt1.begin(), lt2); //将容器lt2拼接到容器lt1的开头
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl; //6 6 6 6 2 2 2 2
list<int> lt3(4, 2);
list<int> lt4(4, 6);
lt3.splice(lt3.begin(), lt4, lt4.begin()); //将容器lt4的第一个数据拼接到容器lt3的开头
for (auto e : lt3)
{
cout << e << " ";
}
cout << endl; //6 2 2 2 2
list<int> lt5(4, 2);
list<int> lt6(4, 6);
lt5.splice(lt5.begin(), lt6, lt6.begin(), lt6.end()); //将容器lt6的指定迭代器区间内的数据拼接到容器lt5的开头
for (auto e : lt5)
{
cout << e << " ";
}
cout << endl; //6 6 6 6 2 2 2 2
return 0;
}merge函数
merge函数用于将一个有序 list容器合并到另一个有序list容器当中,使得合并后的list容器任然有序。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt1;
lt1.push_back(3);
lt1.push_back(8);
lt1.push_back(1);
list<int> lt2;
lt2.push_back(6);
lt2.push_back(2);
lt2.push_back(9);
lt2.push_back(5);
lt1.sort(); //将容器lt1排为升序
lt2.sort(); //将容器lt2排为升序
lt1.merge(lt2); //将lt2合并到lt1当中
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl; //1 2 3 5 6 8 9
return 0;
}reverse函数
reverse函数用于将容器当中元素的位置进行逆置。
cpp
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.reverse(); //将容器当中元素的位置进行逆置
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //5 4 3 2 1
return 0;
}assign函数
assign函数用于将新内容分配给容器,替换其当前内容,新内容的赋予方式有两种:
- 将n个值为val的数据分配给容器。
- 将所给迭代器区间当中的内容分配给容器。
cpp
#include <iostream>
#include <string>
#include <list>
using namespace std;
int main()
{
list<char> lt(3, 'a');
lt.assign(3, 'b'); //将新内容分配给容器,替换其当前内容
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //b b b
string s("hello world");
lt.assign(s.begin(), s.end()); //将新内容分配给容器,替换其当前内容
for (auto e : lt)
{
cout << e << " ";
}
cout << endl; //h e l l o w o r l d
return 0;
}