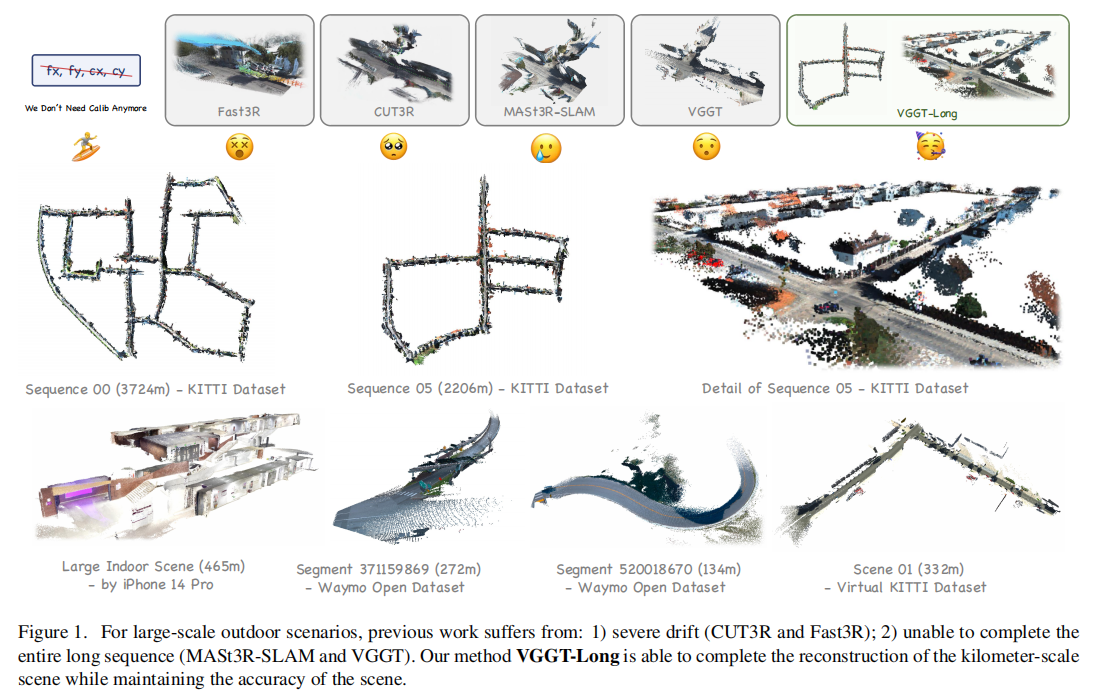
在自动驾驶、机器人导航等关键领域,从单目 RGB 流中感知 3D 环境是核心技术需求。然而,现有 3D 视觉基础模型在处理千米级、无标定的户外长序列时,往往受限于内存瓶颈和累积漂移问题,难以实现精准且稳定的 3D 重建。近期,来自南开大学和南京大学的研究团队提出了 VGGT-Long 框架,通过 "分块 - 对齐 - 闭环" 的极简设计,成功将单目 3D 重建能力拓展至千米级无界户外场景,无需相机标定和深度监督,性能媲美传统标定方法。
代码链接:https://github.com/DengKaiCQ/VGGT-Long
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心挑战
1. 单目 3D 重建的重要性与应用场景
单目 3D 重建技术仅通过单摄像头采集的 RGB 图像序列,即可恢复场景的 3D 结构和相机轨迹,在自动驾驶、无人机测绘、虚拟现实等领域具有不可替代的优势。尤其在自动驾驶场景中,该技术能为车辆提供周围环境的 3D 感知信息,支撑路径规划、障碍物检测等关键决策。
2. 现有方法的局限性
当前 3D 重建方法主要分为两类,但均存在显著短板:
- 传统方法(SfM/SLAM):经典的运动恢复结构(SfM)和同步定位与地图构建(SLAM)方法(如 ORB-SLAM2、LDSO)依赖复杂的多模块流水线,需要已知相机内参,且在纹理缺失或动态场景中鲁棒性不足;部分学习增强型方法(如 PixSfM、DF-SfM)虽结合了深度特征,但仍存在扩展性差或泛化能力弱的问题。
- 基于 Transformer 的基础模型:近年来,以 DUSt3R、MASt3R、CUT3R、VGGT 为代表的端到端基础模型,通过统一的深度学习框架整合相机姿态估计、内参回归和 3D 场景表示,无需手动设计特征,在小尺度场景中表现出优异的重建质量。但这类模型面临两大核心挑战:
- 内存瓶颈:Transformer 的自注意力机制计算量随输入图像数量呈二次增长,即使采用 Flash-Attention 等优化技术,GPU 内存占用仍居高不下。例如,VGGT 在 24GiB RTX 4090 GPU 上仅能处理 60-80 帧图像,面对 KITTI 序列的 4600 帧图像,需 1380-1840GiB 显存,远超现有硬件能力。
- 累积漂移:在长序列中,局部重建误差会不断累积,导致全局一致性下降。CUT3R、Fast3R 等模型即使在数十帧的短序列中也存在严重漂移,而 VGGT 虽局部重建精度高,但无法处理长序列。
3. 研究动机
现有大尺度重建方法(如 MASt3R-SLAM)通过构建复杂的后端优化系统(姿态图优化、光束法平差等)来扩展基础模型的能力,但工程复杂度高,难以适配下游任务。研究团队提出核心疑问:大尺度重建是否必须等同于系统级复杂度?基于此,团队摒弃复杂后端设计,转而通过极简策略解锁 VGGT 模型本身的潜力,提出 VGGT-Long 框架,实现无需标定、内存高效、高精度的千米级单目 3D 重建。
二、核心贡献
论文的核心贡献可概括为三点,既突破了技术瓶颈,又提供了全新的设计思路:
- 首次实现无标定千米级单目 3D 重建:提出首个无需相机标定和深度监督,能稳定处理千米级无界户外场景的单目 3D 重建系统,填补了基础模型在大尺度场景应用中的空白。
- 提出 "分块 - 对齐" 极简流水线:通过重叠分块处理、置信度感知对齐和轻量级闭环优化,解决了基础模型的内存限制问题,在长序列上实现与传统标定方法相当的精度。
- 解决长序列累积漂移问题:证明了 VGGT 可作为大尺度重建系统的稳健前端,无需复杂后端即可通过高效闭环校正,抑制 Sim (3) 漂移累积。
三、相关工作综述
1. 运动恢复结构(SfM)
- 经典 SfM:采用增量式策略(特征检测、匹配、光束法平差),鲁棒性强但依赖手动设计特征,在纹理缺失场景表现不佳。
- 深度学习增强型 SfM:混合框架(如 PixSfM)结合深度特征与经典优化;全可微分框架(如 FlowMap)探索端到端学习,但扩展性差;VGGSfM 通过密集特征和多视图一致性,在真实数据集上超越经典方法。
2. SLAM 与视觉里程计
- 传统 SLAM:依赖手工特征和优化(如 ORB-SLAM3),但扩展性差;
- 学习型 SLAM:将可微分组件融入深度网络(如 DROID-SLAM),但需预标定相机;
- 基础模型 + SLAM:MASt3R-SLAM 基于 MASt3R 构建复杂后端,实现无标定重建,但在长序列中易因特征匹配失败导致跟踪丢失。
3. 基于 Transformer 的 3D 视觉方法
这类方法以端到端方式处理无标定图像对,联合估计相机参数和 3D 几何。从 DUSt3R、MASt3R 到 CUT3R、Fast3R,再到当前 SOTA 的 VGGT,重建质量不断提升,但均受限于计算和内存成本,无法处理长序列。
4. 本文方法的差异化
VGGT-Long 摒弃复杂后端设计,采用 "极简主义" 思路,通过分块处理、置信度感知对齐和高效闭环优化,直接扩展 VGGT 的能力,无需修改模型结构或重新训练,在内存效率、鲁棒性和工程复杂度之间取得了最佳平衡。
四、VGGT-Long 核心方法详解
VGGT-Long 的核心框架遵循 "分块(Chunking)- 分块对齐(Chunk-wise Alignment)- 闭环检测与对齐(Loop Detection & Alignment)- 全局优化(Global Optimization)" 四步流程,既解决内存问题,又保证全局一致性。其整体架构如图 2 所示:
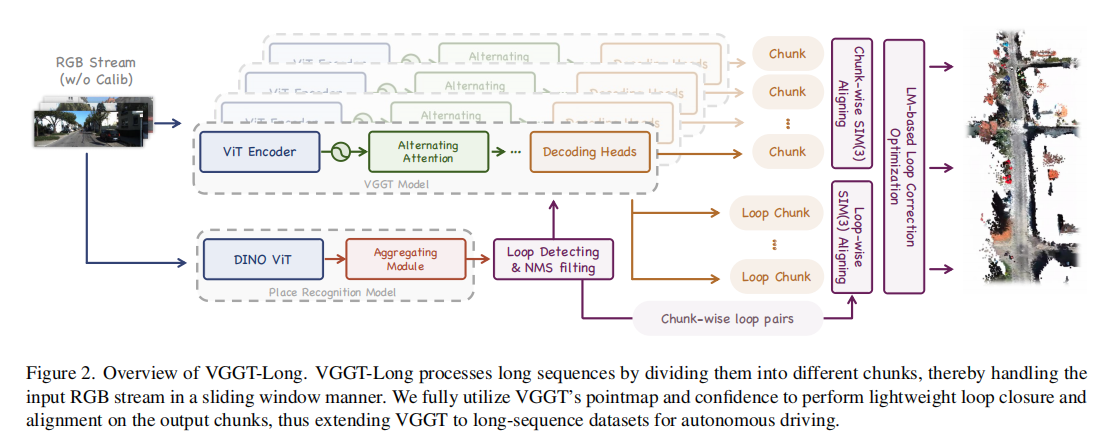
1. 序列分块与局部置信度对齐(Sequence Chunking and Local Aligning with Confidence)
1.1 序列分块策略
给定长度为 的图像序列
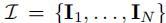 ,将其划分为
,将其划分为 个重叠的分块(Chunk)。设分块大小为
,重叠大小为
,则第
个分块
的帧索引范围为
。分块可视化如图 3 (a) 所示,通过滑动窗口方式处理长序列,每个分块独立输入 VGGT 模型,输出局部一致的相机姿态、3D 点云
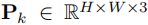 以及对应的置信度图
以及对应的置信度图 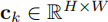 。
。
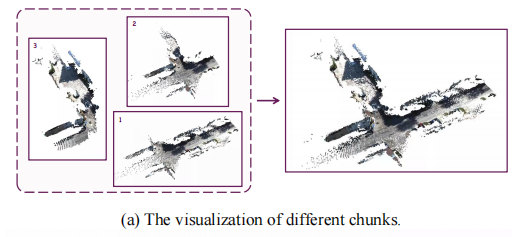
分块参数设置:KITTI 和 Virtual KITTI 数据集采用 L=75 帧,Waymo 数据集采用 L=60 帧(接近 24GiB GPU 的最大容量),确保每个分块能在单 GPU 上高效处理。
1.2 置信度感知的分块对齐
VGGT 输出的置信度图 反映了 3D 点云的可靠性:静态场景(如建筑物、静止车辆)置信度高,动态目标(如行人、车辆)和无纹理区域(如天空、雨天雨滴)置信度低。利用该特性,采用迭代加权最小二乘(IRLS)优化估计相邻分块的相对 Sim (3) 变换,实现稳健对齐。
-
目标函数:最小化对应点在 Sim (3) 变换下的距离,采用 Huber 损失抑制异常值影响:
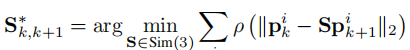
其中 ρ(・) 为 Huber 损失函数,
和
-
迭代加权策略 :每次迭代中,权重
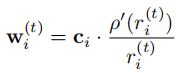
其中
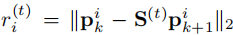 为上一轮迭代的残差。权重设计使得高置信度点贡献更大,低置信度点被抑制。
为上一轮迭代的残差。权重设计使得高置信度点贡献更大,低置信度点被抑制。 -
优化求解:采用加权 Umeyama 算法高效求解 Sim (3) 变换的闭合解。同时设置置信度阈值,直接丢弃置信度低于 0.1× 中位数的点,进一步提升对齐稳健性。
该策略能有效抑制动态目标和无纹理区域对对齐的干扰,如图 4 所示,在高交通流量场景中,VGGT-Long 可过滤高速车辆的影响,而 LiDAR 难以完全排除这类干扰。

2. 闭环检测与闭环对齐(Loop Detection and Loop-wise SIM (3) Aligning)
分块对齐虽能处理局部一致性,但长序列中会累积 Sim (3) 漂移,需通过闭环检测校正全局误差。

2.1 闭环候选检测
- 采用预训练的视觉位置识别(VPR)模型(基于 DINOv2 骨干网络)提取每个图像的全局特征向量
- 通过最近邻搜索寻找余弦相似度高于阈值
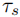 的图像对,且帧索引差
的图像对,且帧索引差  (避免时间上接近的冗余匹配)。
(避免时间上接近的冗余匹配)。 - 应用非极大值抑制(NMS)在局部时间窗口内筛选最强匹配,得到高置信度的图像级闭环候选对
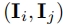 。
。
2.2 闭环中心分块重建
为获得闭环场景的高质量 3D 重建,将闭环候选对 周围的子序列拼接成临时图像批,输入 VGGT 模型生成 "闭环中心分块"(Loop-centric Chunk)。该分块包含同一位置的时间分散视图,基线更宽,能更稳健地恢复场景几何。
2.3 闭环 Sim (3) 变换计算
通过闭环中心分块连接两个远距离分块 和
,计算闭环变换
:

其中 和
分别为
、
到闭环中心分块的变换。该变换为全局优化提供了强几何约束,有效校正累积漂移。
3. 全局 Sim (3) LM 优化(Global SIM (3) LM-based Optimization)
为实现全局一致性,采用 Levenberg-Marquardt(LM)算法对所有分块的 Sim (3) 变换进行全局优化,目标函数包含两类约束:
- 相邻分块的顺序约束(来自分块对齐);
- 非相邻分块的闭环约束(来自闭环对齐)。
优化问题形式化为:
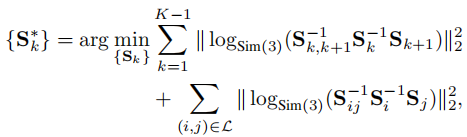
其中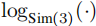 将 Sim (3) 变换映射到其李代数 sim (3) 的 7 维切空间,实现无约束优化。
将 Sim (3) 变换映射到其李代数 sim (3) 的 7 维切空间,实现无约束优化。
全局优化的优势:
- 仅优化分块级 Sim (3) 变换(通常仅几十个变量),计算量小;
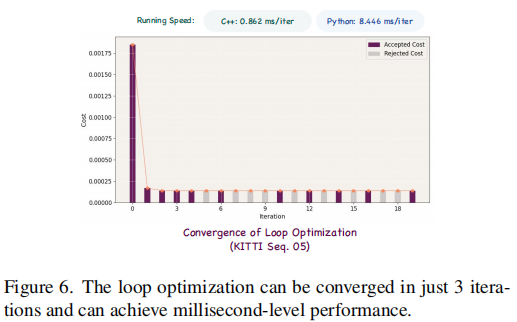
- 收敛速度快,平均 3 次迭代即可收敛,C++ 实现中每次迭代仅需 0.4-1.3ms,Python 实现需 3.5-13ms(如图 6 所示);
- 无需构建复杂因子图,工程实现简洁。
4. 内存管理策略
为处理大规模场景中 CPU 内存不足的问题,采用高效的内存管理方案:
- 分块处理后,将结果存储到磁盘,仅在对齐和优化阶段加载相关分块对;
- 计算完成后立即释放内存,避免内存溢出;
- 最终输出(彩色点云和相机姿态)采用流式写入,绕过 CPU 内存限制。
磁盘 I/O 开销可忽略(每个分块加载 25ms、写入 95ms),不影响整体实时性。
五、实验验证与结果分析
1. 实验设置
- 数据集:选用三大主流数据集,覆盖真实 / 合成、不同场景复杂度和天气条件:
- KITTI Odometry Track:11 个序列,长度 394m-5067m,户外自动驾驶场景;
- Waymo Open Dataset(v1.4.1):10 个 200 帧片段,长度 42m-351m,城市驾驶场景,交通流量变化大;
- Virtual KITTI Dataset(v1.3.1):5 个场景,包含雾、雨、日落等多种天气条件,测试域适应性。
- 硬件环境:Ubuntu 22.04,12 核 Intel Xeon Gold 6128 CPU,67GiB RAM,24GiB RTX 4090 GPU。
- 评价指标:
- 轨迹精度:绝对轨迹误差(ATE RMSE),评估长序列一致性;
- 重建精度:准确性(预测点到 GT 的欧氏距离)、完整性(GT 点到预测点的欧氏距离)、香农距离(两者平均值);
- 预处理:所有方法均通过 ICP 进行粗对齐,过滤低置信度点(Transformer 类方法保留置信度 > 0.75× 平均值的点)。
2. KITTI 数据集结果
2.1 轨迹跟踪性能
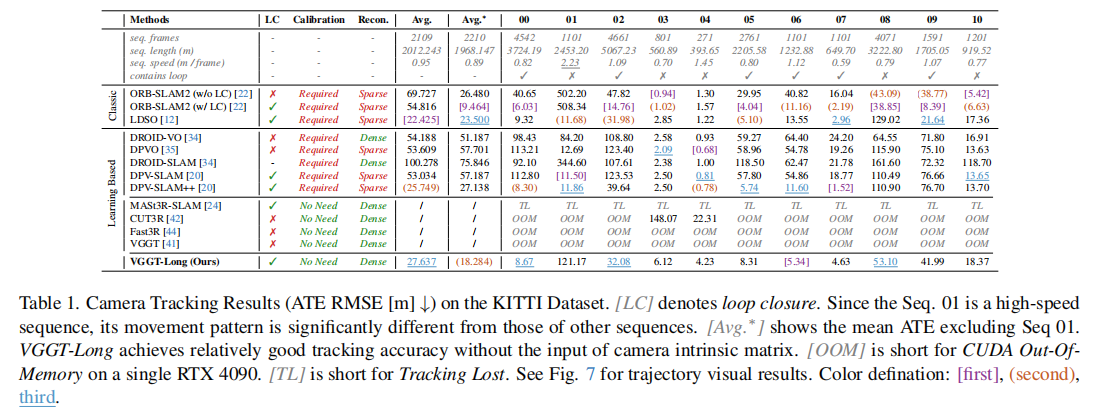
表 1 展示了 11 个 KITTI 序列的 ATE 结果,关键结论如下:
- VGGT-Long 无需相机标定,平均 ATE 为 27.637m(排除 Seq.01 后为 18.284m),优于 DROID-SLAM、DPVO 等学习型方法,与需标定的经典方法(如 LDSO)性能相当;
- 基础模型(CUT3R、Fast3R、VGGT)因内存溢出(OOM)无法完成长序列处理,MASt3R-SLAM 因特征匹配失败导致跟踪丢失(TL);
- 在长序列(如 Seq.00,3724m)中,VGGT-Long 的 ATE 仅为 8.67m,远低于其他无标定方法,验证了其长序列稳定性。
2.2 轨迹可视化
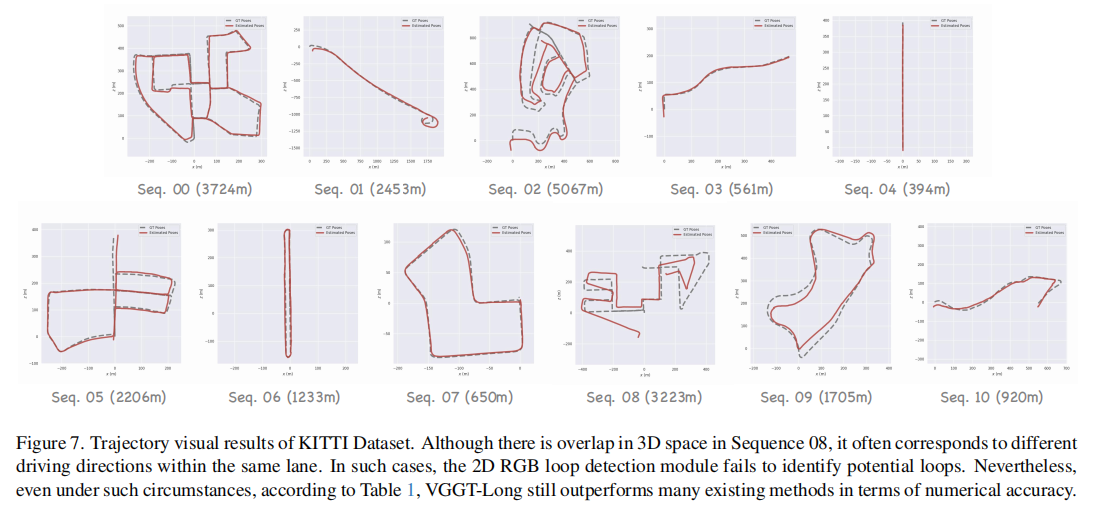
图 7 展示了 KITTI 序列的轨迹可视化结果,可见 VGGT-Long 的轨迹与真实轨迹(GT)贴合度高,即使在 Seq.08 等存在车道方向变化的场景中,仍能保持稳定跟踪,优于其他方法。
3. Waymo 数据集结果
3.1 轨迹跟踪性能
表 2 显示,VGGT-Long 在 10 个 Waymo 片段上的平均 ATE 为 1.996m,显著低于 CUT3R(9.872m)和 MASt3R-SLAM(5.560m),在高交通流量和强视角变化场景中表现尤为突出。
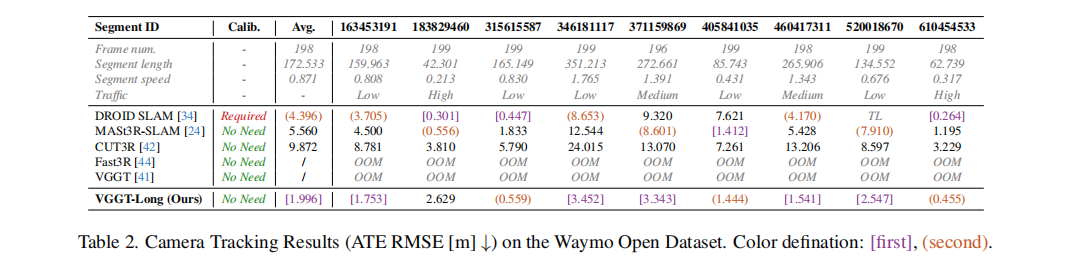
3.2 重建质量评估
表 3 展示了重建指标结果,VGGT-Long 在准确性(平均 1.182m)、完整性(平均 2.860m)和香农距离(平均 2.021m)上均优于其他方法。值得注意的是,LiDAR 采集的 GT 点云因扫描高度限制,无法覆盖天桥等结构(如片段 371159869),而 VGGT-Long 等视觉方法能有效重建这类结构,验证了其场景覆盖能力。
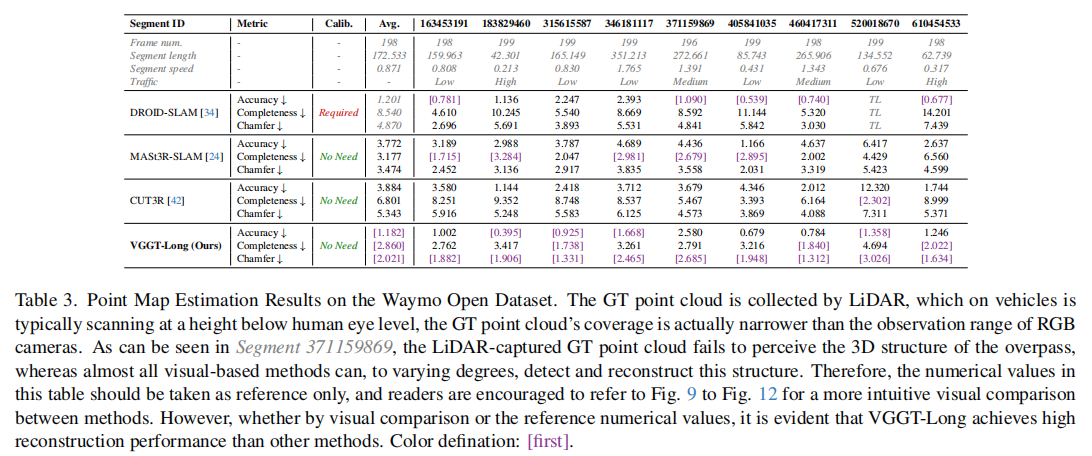
3.3 重建可视化对比
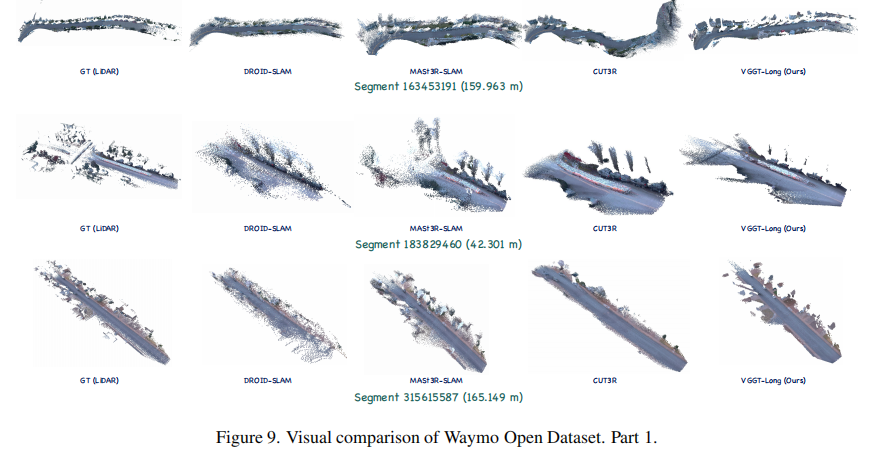
图 9-12 (以图9为例)展示了 Waymo 片段的重建可视化结果,可见 VGGT-Long 生成的点云更密集、准确,能更好地还原建筑物、道路边缘等细节,而 DROID-SLAM、CUT3R 等方法存在点云稀疏或漂移问题。
4. Virtual KITTI 数据集结果
表 4 展示了不同天气条件下的 ATE 结果,VGGT-Long 在雾、雨、日落等所有场景中均保持稳定性能(平均 ATE 为 2.0538m),而 DROID-SLAM 偶尔跟踪失败,CUT3R 存在严重漂移(平均 ATE 为 38.0189m)。这验证了 VGGT-Long 的强鲁棒性,无需域自适应或重新训练即可应对复杂天气。

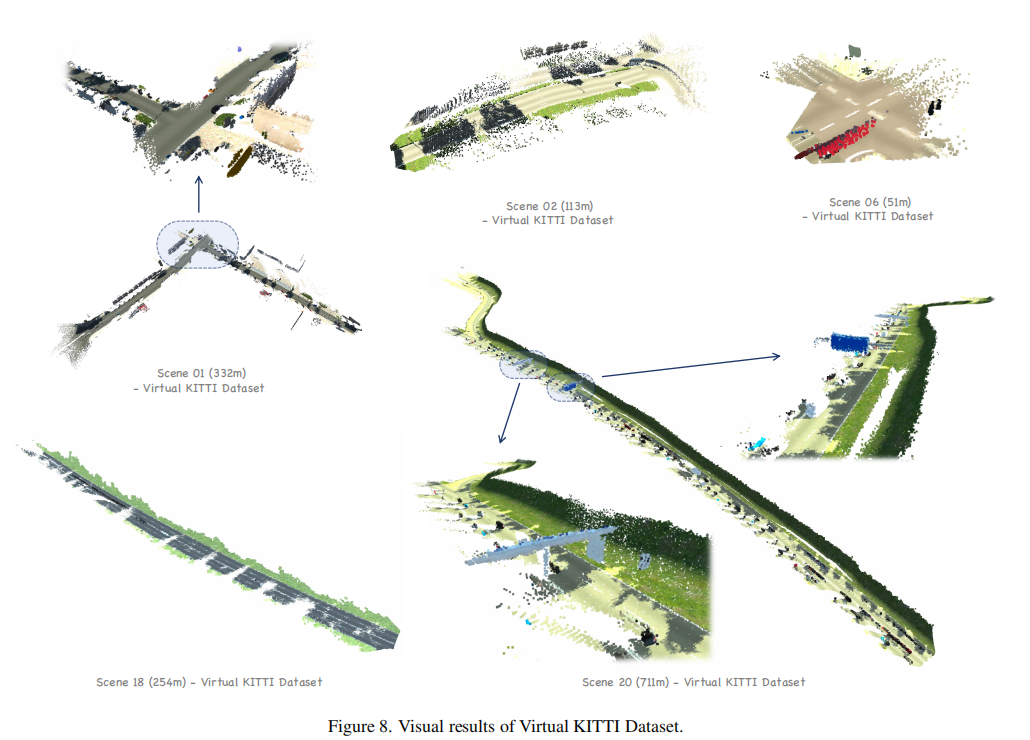
图 8 展示了 Virtual KITTI 场景的重建可视化,VGGT-Long 在不同天气条件下均能生成清晰、一致的 3D 结构。
5. 消融实验与运行时分析
5.1 消融实验
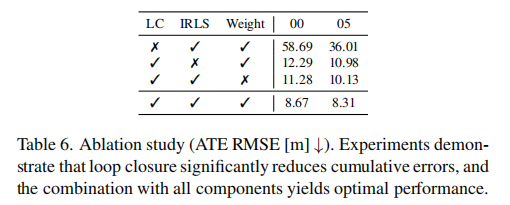
表 6 验证了各核心组件的作用,关键结论如下:
- 闭环检测(LC)是抑制累积漂移的关键:关闭 LC 后,Seq.00 的 ATE 从 8.67m 升至 58.69m;
- 迭代加权最小二乘(IRLS)提升对齐稳健性:关闭 IRLS 后,性能下降 13%;
- 置信度加权(Weight)有效过滤异常点:关闭后性能略有下降;
- 所有组件协同工作时性能最优,验证了 "分块 - 对齐 - 闭环" 设计的合理性。
5.2 运行时分析
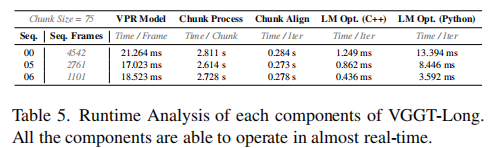
表 5 展示了 VGGT-Long 各组件的运行时间,关键指标如下:
- 分块处理:每块约 2.6-2.8s;
- 分块对齐:每次迭代约 0.27-0.28s;
- LM 优化(C++):每次迭代 0.4-1.3ms;
- 整体运行效率满足近实时需求,千米级序列处理无压力。
六、结论与未来展望
1. 研究结论
VGGT-Long 通过 "分块 - 对齐 - 闭环 - 全局优化" 的极简框架,成功突破了现有 3D 视觉基础模型的内存瓶颈和累积漂移问题,实现了无需相机标定、深度监督或模型重新训练的千米级单目 3D 重建。在 KITTI、Waymo、Virtual KITTI 三大数据集上的实验表明,该方法在轨迹精度、重建质量和鲁棒性上均优于现有方法,且工程复杂度低、运行高效,为自动驾驶等真实场景的大尺度 3D 感知提供了实用解决方案。
2. 未来方向
论文指出未来将继续研究以下方向:
- 提升 3D 基础模型在长户外序列中的准确性和一致性;
- 进一步优化分块策略和闭环检测,适应更复杂的动态场景;
- 探索多模态融合(如融合 IMU 数据),进一步抑制漂移。
七、总结
VGGT-Long 的核心创新在于 "极简主义" 设计思路:不依赖复杂后端,而是通过分块处理解决内存问题,利用置信度感知对齐保证局部精度,通过高效闭环优化校正全局漂移,充分挖掘了 VGGT 基础模型的潜力。该方法不仅在技术上突破了千米级单目 3D 重建的极限,更提供了一种扩展基础模型至大尺度场景的通用思路,对 3D 视觉在自动驾驶、机器人导航等领域的落地具有重要意义。