论文源:https://doi.org/10.1016/j.neucom.2023.127052
期刊名:nuerocomputing 计算机科学二区
注:标题号不对应文内章节号
目录
[1. 论文标题:](#1. 论文标题:)
[2. 关键词(Keywords)](#2. 关键词(Keywords))
[3. 摘要](#3. 摘要)
[5. Scene Graph 定义](#5. Scene Graph 定义)
[6. 场景图生成](#6. 场景图生成)
1. 论文标题:
Scene Graph Generation: A Comprehensive Survey
场景图生成:一篇系统性综述
**2.**关键词(Keywords)
- Scene Graph Generation(场景图生成)
- Visual Relationship Detection(视觉关系检测)
- Object Detection(目标检测)
- Scene Understanding(场景理解)
3. 摘要
近年来,深度学习技术在物体检测领域取得重大突破,并催生了大量场景理解任务。场景图因其强大的语义表征能力和在场景理解中的应用价值,成为研究热点。场景图生成(SGG)是指将图像或视频自动映射为语义结构化场景图的任务,该过程需要对检测到的物体及其关系进行正确标注。本文对近期研究成果进行了全面综述,旨在系统梳理现有视觉关系检测方法,综合阐释 SGG 的机制与策略。最后,文章对当前存在的问题及未来研究方向进行了深入探讨。通过本综述,读者将能更全面地理解当前研究进展。
重点:
SGG:把图像/视频 → 语义结构化场景图
需要:正确识别 物体 + 关系
本文目标:
系统整理视觉关系检测(VRD)方法
从 机制与策略层面解释 SGG
讨论问题与未来方向
4.引言
Scene Understanding 问题的演化可简述为:
- Image Classification → Detection → Segmentation → Panoptic
但这些都只关心:"物体是什么/在哪"
真正对于环境理解需要:
物体间交互、环境和物体的关系
因此出现了:VRD(视觉关系检测)
HOI(人与物体交互)
Scene Graph(场景图),这里的"图"是数据结构意义上的图 = 对象节点 + 属性 + 关系边
是一种:
- 结构化
- 可组合
- 可与语言对齐的表示
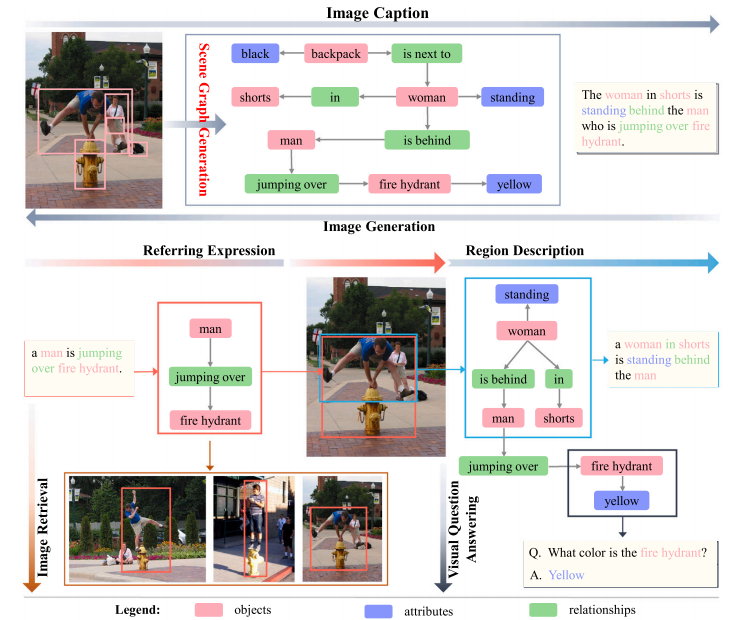
应用驱动(Fig.1)
Image Captioning
VQA
Image Retrieval
Image Generation
Referring Expression
此文贡献:
138 篇 SGG 文献的系统综述
以"特征表示 + 特征精炼"为主线的 2D SGG 分析
覆盖 2D / 时空 / 3D SGG + 数据集与评测
5. Scene Graph 定义
要素:
Object(物体)
Attribute(属性)
Relation(关系)
Triplet 形式:
⟨subject, predicate, object⟩
⟨object, is, attribute⟩
图结构视角:
本质是有向图
实际使用中:
节点 = 带属性的物体
边 = 关系
Scene Graph vs Knowledge Graph
KG:抽象、稳定、跨场景
Scene Graph:图像特定、瞬时、视觉依赖
关键观点:理想的 scene graph 在给定场景下是唯一的
2D / 3D / 时序 Scene Graph
2D:有视角歧义
3D:消除空间歧义
Video:关系随时间变化 → 时空场景图
6. 场景图生成
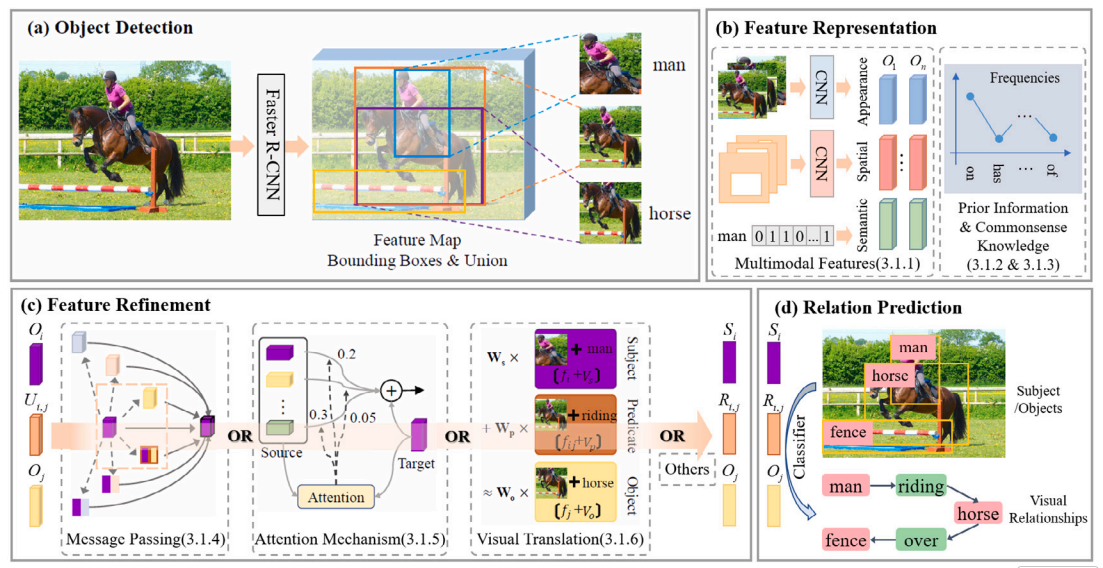
总览:
SGG ≠ 单纯关系分类
核心在于:关系预测之前的特征构造与特征精炼
方法创新 集中在 (b)(c)
(a)(d) 属于前置条件与输出端
(a) Object Detection(前置模块,不是研究重点)
使用 Faster R-CNN / RPN
产生:
subject box
object box
predicate ROI = subject ∪ object
多数工作:
直接用现成 detector
或用 GT box(排除检测误差)
结论:
检测质量重要
但不是 SGG 方法分类依据
(b) Feature Representation(特征表示)
核心问题:
Union box 的 appearance 特征不足以判别关系
关系 = 多信息联合判断
多模态特征:
Appearance:解决"看起来像什么"
Semantic:解决"是什么东西"
Spatial:解决"相对位置"
Context:缩小可行语义空间
Prior Information(先验信息)
Statistical Prior
- 数据集共现频率
Language Prior
- 词向量 / 语义相似度
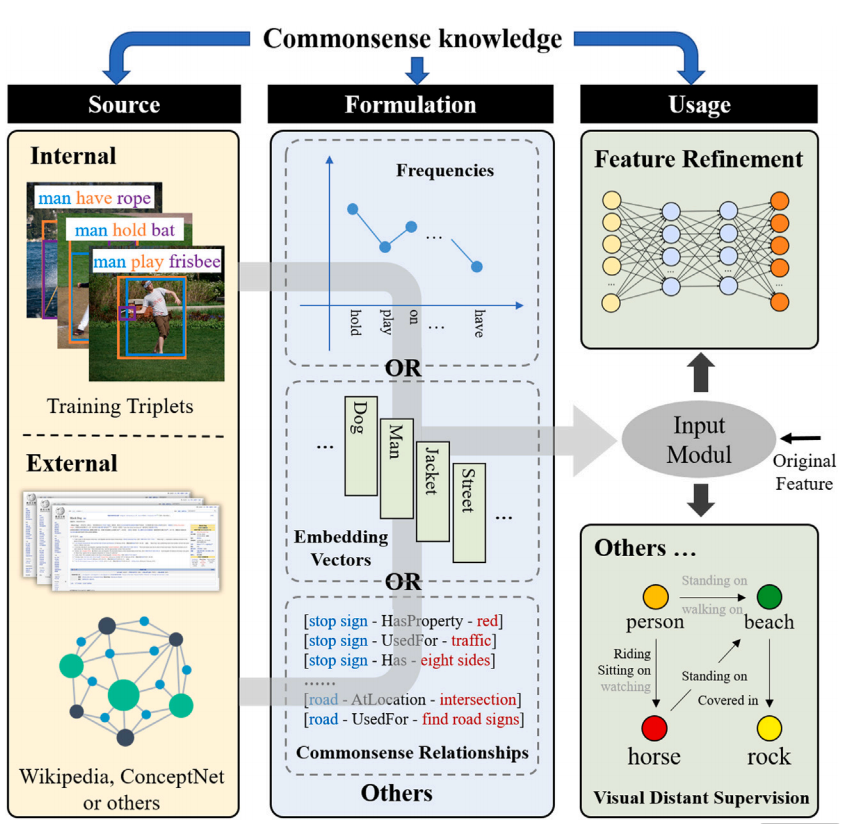
Commonsense Knowledge(常识知识)
Source:知识来源
- 数据集统计 / 外部知识库(ConceptNet, Wiki)
Formulation:建模方式
- 共现矩阵 / 图结构 / 概率约束
Usage:使用位置
- 特征精炼 / 推理阶段 / 训练约束
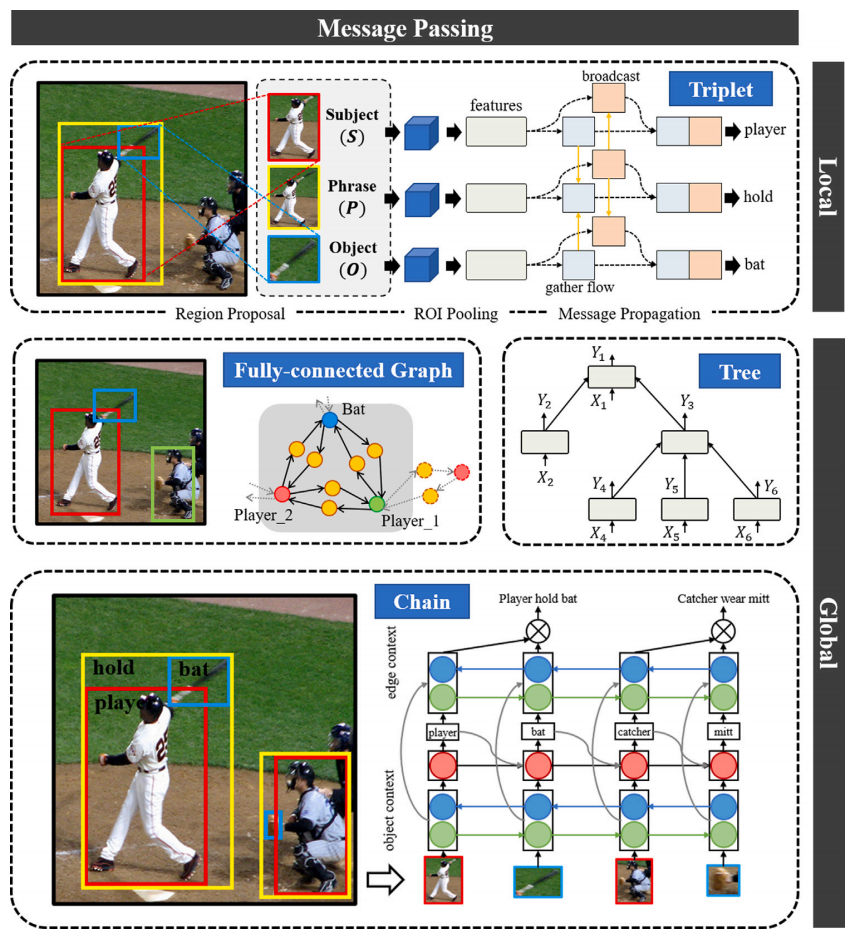
(c) Feature Refinement(特征精炼)
核心部分
总体目标
引入上下文
保证关系预测的结构一致性与语义合理性
Message Passing(消息传递)
核心思想
关系不是孤立的
对象 / 关系之间存在依赖
两级传播
局部(Triplet 内)
- S ↔ P ↔ O
全局(Scene Graph)
- object ↔ object ↔ relation
常见结构
Chain:RNN / LSTM
Tree:TreeLSTM(VCTree)
Graph:GNN / CRF
Attention Mechanism(注意力机制)
作用
选择性利用信息
抑制无关上下文
两类
Self-Attention
- 强化单个对象/关系表征
Context-Aware Attention
- 从图结构中选择关键邻居
Visual Translation Embedding(视觉平移嵌入)
动机
同一 predicate 在不同对象间差异巨大
Zero-shot / long-tail 问题
两种形式
不显式建模 predicate embedding
显式建模 ⟨S, P, O⟩ 共同嵌入
(d) Relation Prediction(关系预测)
使用分类器输出 predicate
生成 ⟨s, r, o⟩ triplets
7.其他内容简述
-
Section 4:数据集汇总
-
Section 5:性能对比与评测指标
-
Section 6:开放问题与未来方向
-
Section 7:总结