《Deep Learning for Time Series Anomaly Detection: A Survey》
用于时序数据异常检测的深度学习综述
1.发布时间
2024年10月
2. 摘要
时序数据的异常检测广泛应用与金融市场、经济学、地球科学、制造业和医疗保健等行业。本综述提供了基于异常检测策略和深度学习模型的分类法,讨论了它们的优点和局限性。该综述包括近年来在各种应用领域的时序数据中深度异常检测的例子。
2. 关键词
异常检测、时间序列分析、异常值检测、时间序列、单变量时间序列、多变量时间序列、深度学习
一、介绍
- 近年来,时间序列异常检测(TSAD)在各种领域的应用越来越广泛,包括城市管理、入侵检测、医疗风险和自然灾害。
- 深度学习异常检测取得了比传统时间序列异常检测任务更高的性能。
- 本文贡献:
- 提出了一种新颖的时序数据深度异常检测模型分类法,将模型大致分为四类:基于预测、基于重构、基于表示和混合方法。
- 提供了截止到2024年时间序列异常检测的最新技术水平的全面回顾
- 汇总了各个领域中使用的主要基准和数据集
- 讨论了时间序列数据中不同类型异常发生的基本原则
- 提供了评估指标以及指标选择的指南
二、背景
时间序列是一系列随时间顺序索引的数据点。通常分为单变量(一维)和多变量(多维)。
2.1 单变量时间序列(UTS)
单变量时间序列是基于随时间变化的单个变量的一系列数据。
2.2 多变量时间序列(MTS)
多变量时间序列表示依赖于时间的多个变量,每个变量都受到过去值和基于其相关性的其他变量(维度)的影响。
2.3 时间序列分解
可以将时间序列 X X X分解为四个部分,每个部分表示其运动的一个特定方面。
- 长期趋势:序列中的长期趋势,如增加、减少或稳定。长期趋势代表一段时间内数据的一般模式,不一定是线性的。
- 季节性变化:根据月份、工作日或持续时间的不同,时间序列可能会表现出季节性模式。季节性总是以固定的频率出现。
- 周期性波动:一个周期被定义为长期趋势和季节变化所定义的基础序列的延伸偏离。与季节性效应不同,周期性效应的开始时间和持续时间各不相同。
- 不规则变化:随机的、不规则的事件。是出去所有其他成分后的剩余部分。
2.4 时间序列中的异常
异常是指对数据总体分布的偏离,如单个观测值(点)或一系列观测值(子序列)大大偏离总体分布。
- 异常的类型 :单变量时间序列和多变量时间序列中的异常可以分为时间异常、中间异常或时间-中间异常。不同的时间异常如下:
- 全局 :是序列中的尖峰,是与序列的其余部分相比具有极值的点。(设定一个阈值,当输出值与实际值的差值大于阈值的时候,就认为是异常)
- 上下文 :与相邻时间点的上下文的偏差,(与全局异常类似,不过阈值是根据其邻居的背景确定的)
- 季节性 :尽管时间序列有正常的形状和趋势,但与总体季节性相比,它们的季节性是不寻常的。(判断两个子序列的差异值是不是大于阈值)
- 趋势 :导致数据向其平均值永久移动并产生时间序列趋势转变的事件。虽然这种异常保持了常态的周期性和季节性,但它极大地改变了其斜率。(判断实际趋势与正常趋势的差异值是不是大于阈值)
- Shapelet :一种具有显著辨识度的时序子序列模式。在这种模式下,某个子序列的时间序列特征或周期与序列中其余部分的常规模式存在显著差异。(判断预期子序列的周期形状与实际子序列的周期形状的差异值是不是大于阈值)
- 动态时间规整(DTW):异常通常可以通过"实际的子序列"与"预期的子序列"之间的距离来表示。动态时间规整作为一种能够实现两条时间序列最优对齐的技术,是衡量这种不相似性(即距离)的一种非常有效的方法。
- 降维技术:如基于领域知识或初步分析选择关键维度的子集,有助于管理随着维度数量增加而增加的计算复杂性。
三、时间序列异常检测方法
3.1 用于时间序列异常检测的深度模型
-
用于时间序列异常检测的深度模型主要分为三类:基于预测的、基于重构的和基于表示的。

-
下表概述了模型的以下方面:时间/空间、学习方案、输入、可解释性、点/子序列异常、随机性、增量和单变量支持。
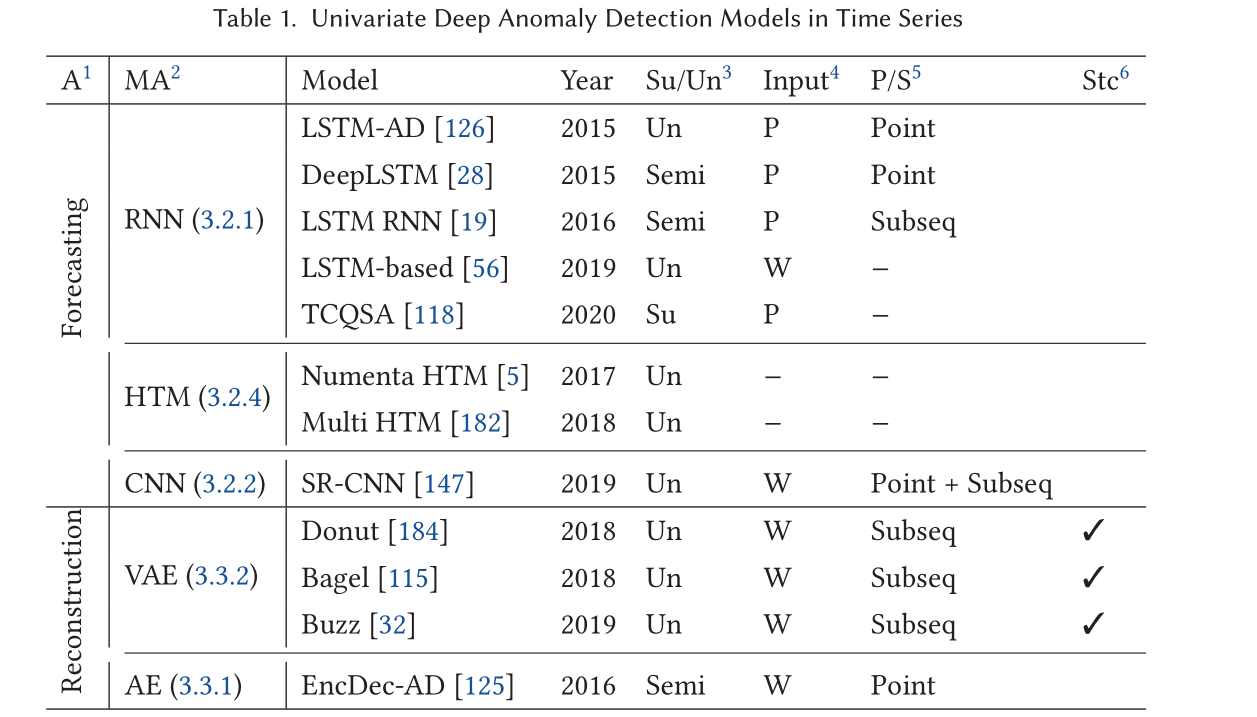
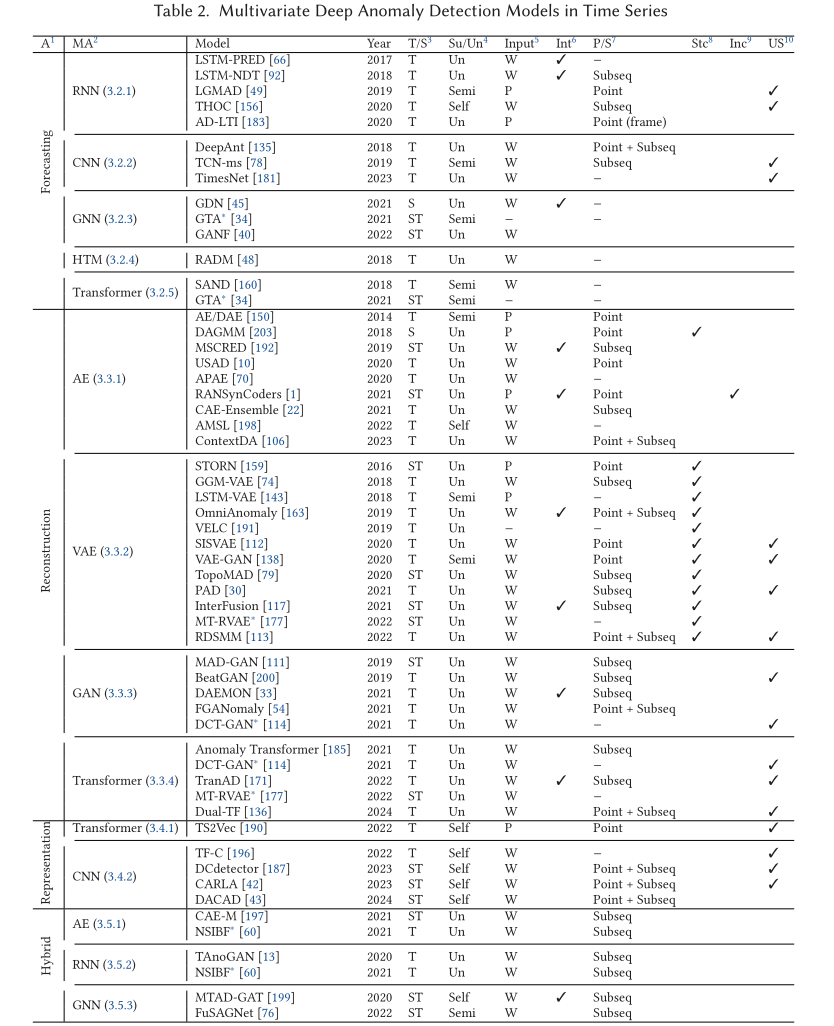
3.1.1 时间/空间
使用UTS作为输入,模型可以捕获时间信息(即模式),而使用MTS作为输入,它可以通过时间和空间依赖性来学习正态性。此外,如果模型输入是一个MTS,其中的空间依赖性被捕获,该模型也可以检测中间异常
3.1.2 学习策略
- 有监督方法: 利用训练集中所有的标签来学习异常与正常数据之间的界限。它能确定一个合适的阈值;当某个时间点的异常评分超过该阈值时,即判定为异常。其局限性在于,现实中异常往往未知或标注不全,导致该方法难以应用。
- 无监督方法: 不使用任何标签,且不区分训练集和测试集。它们完全依赖数据的内在特征,因此灵活性最高,非常适合不需要标签的流式数据应用。但其难点在于模型评估较为困难。由于历史数据天然缺乏标签且异常具有不可预测性,异常检测通常被视为无监督学习问题。
- 半监督方法: 仅利用标注为"正常"的数据进行训练。与需要全标注的有监督方法不同,它通过学习正常模式来识别偏离正常的异常点。
- 自监督方法: 与上述不同,模型从输入数据本身生成伪标签(监督信号),无需显式的人工标注。
3.1.3 输入方式
模型可以将单个数据点(即一个时间步)或一个窗口(即包含历史信息的连续时间步序列)作为输入。根据应用需求,窗口可以按顺序使用(称为滑动窗口),也可以不考虑顺序进行打乱(Shuffled)。
Raw Data → Impute/Norm Clean Data → Sliding Window Subsequences → Model Input Anomaly Score \text{Raw Data} \xrightarrow{\text{Impute/Norm}} \text{Clean Data} \xrightarrow{\text{Sliding Window}} \text{Subsequences} \xrightarrow{\text{Model Input}} \text{Anomaly Score} Raw DataImpute/Norm Clean DataSliding Window SubsequencesModel Input Anomaly Score
3.1.4 可解释性
可解释性是指给出导致观测值异常的原因。
3.1.5 点异常 / 子序列异常
模型可以检测点异常或子序列异常。
- 点异常是指与数据集其余部分相比显得异常的单个点。
- 子序列异常是指连续的观测值表现出异常的协同行为,尽管其中每个观测值本身并不一定是离群点。
3.1.6 随机性
- 确定性模型 (Deterministic models) 可以在不依赖随机性的情况下准确预测未来事件,只要数据齐全,其结果是可预测的,且给定相同输入必产生相同输出。
- 随机模型 (Stochastic models) 能够处理输入中的不确定性。通过引入随机组件作为输入,可以考虑到某种程度的不可预测性或随机性。
3.1.7 增量式
这是一种机器学习范式,每当出现一个或多个新观测值时,模型的知识储备就会随之扩展。它定义了一种动态学习策略,适用于训练数据逐渐产生的场景。增量学习的目标是使模型在适应新数据的同时,保留其过去学到的知识。
3.1.8 不同的输入处理方式
- 分步式:包含一个特征学习模块,其后跟着一个异常评分模块。
- 端到端:将特征学习模块与异常评分模块结合起来,利用神经网络直接学习异常评分。
3.2 基于预测的模型
基于预测的方法利用已学习的模型,根据当前点或近期的窗口数据来预测未来的一个点或一个子序列。为了确定新输入值的异常程度,模型会将预测值与实际观测值进行比较,并将他们之间的偏离程度视为异常值的量化指标。
3.2.1 循环神经网络(RNN)
RNN具有内部记忆,使其能够处理变长的输入序列并保留时间动态特征。循环单元接收输入窗口 X t − w : t − 1 X_{t-w:t-1} Xt−w:t−1并预测下一个时间戳 x ^ t \hat{x}_t x^t。
- LSTM长期记忆网络:LSTM 网络扩展了 RNN,使其记忆能力可达数千步,通过捕捉长期依赖关系实现卓越的预测。LSTM 单元包含细胞(cells)、输入门(input gates)、输出门(output gates)和遗忘门(forget gates)。细胞负责记忆长短不一的时间周期值,而门控则控制信息的流动。
- LSTM的几种应用
- 堆叠式与层次化架构
- 简单模型与集体异常
- 多变量扩展与后处理
- 自动调节与混合模型
- LSTM 与支持向量机的结合
- GRU 架构 :GRU 同样使用门控结构控制信息流,但它没有独立的记忆单元,而是通过更新门(Update gate)和重置门(Reset gate)来整合新输入与旧记忆。
- 解决季节性与历史异常问题
- 多尺度与层次化检测
3.2.2 卷积神经网络(CNN)
-
基础CNN与DeepAnt模型
- 解释:CNN 通过卷积层(滤波器)、池化层(统计摘要)和全连接层来识别数据的层级模式。
- DeepAnt :这是一个基于 CNN 的模型,特点是对数据污染具有鲁棒性(即使训练集中有 5% 的异常也能正常学习),且只需极少的训练数据。它能检测单变量/多变量数据中的点异常、上下文异常和不一致性(Discords)。
-
TCN(时间卷积网络):CNN 的时序进化版
- 解释: 传统 CNN 难以处理序列是因为其设计缺乏时间逻辑。TCN 通过**因果卷积(Causal Convolutions)确保模型不会看到未来的数据,并通过空洞卷积(Dilated Convolutions)**在不显著增加计算量的前提下扩大"感受野"。
-
工业级应用:SR + CNN
- 解释: 微软团队将**谱残差(Spectral Residual, SR)**与 CNN 结合。SR 负责快速提取"看起来奇怪"的候选区域,CNN 负责精细分类。这种方法效率极高,能在超大规模(每分钟数百万条序列)的场景下运行。
-
准周期序列 (QTS) 处理:AQADF
-
解释: 针对像心电图或服务器定期备份任务这类"准周期"数据,AQADF 先用分层聚类进行周期分割,再用 LSTM-CNN 混合模型 (HALCM) 处理。
-
注意力机制: 加入了特征注意力和位置注意力,让模型能精准识别波动细节。
-
-
最新前沿:TimesNet
-
解释: 这是目前学术界非常火的模型。它认为时序数据在 1D 维度下很难看清复杂模式,因此将其转换为 2D 张量。
-
TimesBlock: 通过 2D 卷积捕捉"周期内"和"周期间"的变化。它是全能型选手,在异常检测和预测任务中表现优异。
-
3.2.3 图神经网络(GNN)
-
将多变量序列转化为图结构
-
核心思想: 在多变量异常检测中,每一个维度(即每一个传感器或指标,如 CPU 占用率)被视为图中的一个节点(Node)。
-
边(Edges): 指标之间的相关性被抽象为边。GNN 的优势在于它不仅看单个指标随时间的变化(时间特征),还看指标之间是如何相互影响的(空间特征)。
-
-
消息传递机制 (Message Passing)
-
聚合 (AGGREGATE): 节点 u u u 收集它所有邻居节点的信息。
-
更新 (UPDATE): 节点 u u u 根据自身状态和收集到的邻居信息,更新自己的特征表达(Embedding)。
-
-
典型的 GNN 架构
-
GCN (图卷积网络): 聚合一阶邻居信息。
-
GAT (图注意力网络): 利用注意力机制,为不同的邻居分配不同的权重。例如,CPU 异常时,内存指标的参考权重可能比风扇转速更高。
-
-
代表性模型
-
GDN (Graph Deviation Network): 专门为传感器数据设计。它学习传感器之间的嵌入(Embeddings)来构建图,并预测传感器行为。
-
GANF (图增强归一化流): 将时间序列表示为贝叶斯网络,利用图结构学习条件概率密度。如果某个实例在学习到的分布中密度极低,则判定为异常。
-
3.2.3 分层时序记忆(HTM)
-
HTM 的工作原理
-
生物模拟: HTM 模拟了大脑新皮层(Neocortex)的层级处理逻辑。
-
稀疏空间池化 (Sparse Spatial Pooling): 输入数据 x t x_t xt 首先被编码成一个高度稀疏的二进制向量 a ( x t ) a(x_t) a(xt)。这模仿了大脑神经元的稀疏激活状态(只有少数神经元在工作)。
-
序列记忆 (Sequence Memory): 模型预测下一个可能出现的稀疏状态 π ( x t ) \pi(x_t) π(xt)。
-
-
**异常判定公式 **:预测误差 e r r t err_t errt: e r r t = 1 − π ( x t − 1 ) ⋅ a ( x t ) ∣ a ( x t ) ∣ err_t = 1 - \frac{\pi(x_{t-1}) \cdot a(x_t)}{|a(x_t)|} errt=1−∣a(xt)∣π(xt−1)⋅a(xt)
-
**逻辑:**它计算预测的稀疏向量与实际观测到的向量之间的重叠度。如果重叠度很低,误差就接近 1。
-
异常似然度 (Anomaly Likelihood): 最终不仅看瞬时误差,还要结合历史误差分布来判断当前状态是否真的属于"罕见"异常。
-
-
HTM 的结构特性
- 层级与列: 神经元被组织成"列(Columns)"。高层合并底层的模式,从而识别更复杂的长周期规律。
- 鲁棒性: 对噪声具有极强的容忍度,且能同时学习多种模式。
-
代表性模型与应用
-
Numenta HTM: 即使在极其嘈杂的环境中也能持续适应变化,识别微小异常且误报率低。
-
Multi-HTM & RADM:
- Multi-HTM 适用于单变量并能高效扩展到多变量。
- RADM 是一个实时无监督框架,它将 HTM 与朴素贝叶斯网络 结合。HTM 先处理单个指标,贝叶斯网络再汇总这些指标间的概率关系。这种做法不需要降维(如 PCA),能捕获单指标分析中漏掉的关联异常。
- Multi-HTM 适用于单变量并能高效扩展到多变量。
-
3.2.4 Transformer
-
Transformer 的核心优势
-
并行处理: 与 RNN 必须逐个时间步处理不同,Transformer 同时处理整个序列。
-
自注意力机制 (Self-Attention): 模型根据不同部分的重要性对输入数据赋予不同的权重。
-
长距离依赖: 它能直接连接序列中任意两个点,有效捕捉"上周此时"或"几小时前"的复杂模式。
-
-
关键公式解析 : Q , K , V = softmax ( Q K T d k ) V Q, K, V = \text{softmax} \left( \frac{QK^T}{\sqrt{d_k}} \right) V Q,K,V=softmax(dk QKT)V
-
Q (Query): "我想找什么样的特征"。
-
K (Key): "我这里有什么样的特征"。
-
V (Value): "这些特征具体的值是多少"。
-
d k \sqrt{d_k} dk : 缩放因子,防止数值过大导致梯度消失。
-
-
位置编码 (Positional Encoding) :由于 Transformer 抛弃了递归结构,它无法自动感知时间前后的顺序。因此,必须手动加入位置编码,告诉模型哪个数据点在前,哪个在后。
-
代表性改进模型
-
GTA (Graph Transformer Attention):
- 它将 Transformer 与 图卷积(Graph Convolution) 结合。
- 双向图: 学习多个 IoT 传感器(或服务器指标)之间的关系。
- 多尺度空洞卷积: 融合层级时间上下文。这非常适合处理你的服务器监控数据,因为它能同时看到分钟级和小时级的特征。
-
SAnD:
- 专门针对临床时序数据设计。
- 采用堆叠的编码器结构,利用密集内插嵌入(Dense Interpolation Embedding)来处理复杂的时间顺序。
- 专门针对临床时序数据设计。
-
3.3 基于重构的模型
3.3.1 基于预测 vs. 基于重构
- 预测模型的痛点: 面对快速变化或不可预测的序列(如金融市场或突发的高频网络抖动),预测模型难以看清远期趋势,误差会随着预测步长的增加而迅速累积,导致误报。
- 重构模型的优势: 重构模型在处理当前时刻数据时,可以利用当前及前后的完整上下文信息 。通过重新构建整个数据场景,它能比预测模型更精准地发现偏离。虽然这可能带来轻微的检测延迟,但在追求高精度(Precision)的场景下更受青睐。
3.3.2 重构模型的工作原理
- 特征编码: 将正常数据的滑动窗口映射到低维潜空间(Latent Space)。这就像是对数据进行极致的压缩,只保留最本质的"正常特征"。
- 重构过程: 模型尝试从这个低维表达中重新还原(解压)出原始数据。
- 异常判定逻辑: 由于模型在训练时只见过正常数据,它学会了如何完美还原正常模式。
- 当异常数据进入模型时,模型无法用学到的"正常逻辑"来还原它,从而产生巨大的重构误差(Reconstruction Error)。
- 或者通过重构概率判断:异常点被成功重构的可能性极低。
3.3.3 自编码器AE
自编码器(AE)的工作逻辑:
-
编码(Encoding): 编码器 E n c Enc Enc 将滑动窗口数据 X X X 压缩为低维潜空间表示 Z Z Z(潜变量)。
-
解码(Decoding): 解码器 D e c Dec Dec 尝试从 Z Z Z 还原出原始数据 X ^ \hat{X} X^。
-
异常判定: A S w = ∣ ∣ X − X ^ ∣ ∣ 2 AS_w = ||X - \hat{X}||^2 ASw=∣∣X−X^∣∣2,异常评分(Anomaly Score)即为重构误差。模型在正常数据上训练,无法完美还原异常数据,因此异常点的误差会显著升高。
-
统计与概率增强类
- DAGMM: 将 AE 降维与**高斯混合模型(GMM)**结合。它在潜空间估算样本概率,不仅看误差大小,还看样本在概率分布中的位置。但缺点是缺乏时间序列的先后逻辑。
-
对抗训练与稳健性类
-
USAD(Unsupervised Anomaly Detection): 借鉴了 GAN 的思想,通过两个 AE 进行对抗训练,目的是放大异常点的重构误差,让异常更明显。
-
APAE: 针对对抗攻击(如恶意干扰监控数据)进行了鲁棒性增强,适合安全性要求极高的系统。
-
-
卷积与时间依赖类
-
MSCRED: 使用 ConvLSTM 捕捉时间趋势,并重构"签名矩阵"(代表传感器间的相关性)。它能精准定位异常发生的根因(Root Cause)。
-
CAE-Ensemble: 使用卷积序列到序列(Seq2Seq)结构,具有高并行性,配合 GLU(门控线性单元) 能捕捉周期性规律。
-
-
工业级落地架构
-
RANSysCoders (eBay): 采用多编码器-解码器架构,通过随机特征选择 和多数投票来定位异常。它解决了阈值难定、采样不均等实际工程痛点。
-
AMSL: 结合了自监督学习 和记忆网络(Memory Network)。当正常数据有限时,它通过对数据进行 6 种变换(Self-supervised)来增强模型的泛化能力。
-
3.3.4 变分子编码器
VAE 的本质:
- 概率编码: 编码器不直接输出 latent 变量 Z Z Z,而是输出均值 μ \mu μ 和方差 σ \sigma σ,表示一个高斯分布。
- 采样与重构: 从该分布中采样出一个 Z Z Z,再通过解码器重构。
- 损失函数: 包含两部分:
- 重构误差: 保证还原得像。
- KL 散度: 正则化项,让编码出的分布尽量接近标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1),防止过拟合。
-
经典 KPI 异常检测系列
-
Donut (VAE-based): 专为季节性 KPI 设计。引入了缺失数据注入 和 MCMC 插补,使其能处理监控数据中常见的"数据缺失"问题。但它在捕捉复杂时间依赖上较弱。
-
Bagel (CVAE-based): 针对 Donut 的不足,使用了条件变分自编码器(CVAE),显式引入了时间信息,从而能更好地识别时间轴上的异常。
-
-
随机性与时序融合类(SOTA 级别)
-
OmniAnomaly: 结合了 VAE 和 随机 RNN (如 GRU/LSTM)。它使用 平面正规化流(Planar Normalizing Flow) 来处理非高斯的潜空间分布。这是目前多变量异常检测中非常强悍的模型,推荐在 5070Ti 上优先实验。
-
InterFusion: 采用层级 VAE,同时对"指标间相关性"和"时间依赖"进行建模。它能有效防止模型在训练时由于过拟合已有的异常而失效。
-
-
复杂分布与噪声处理
-
Buzz & SISVAE: 针对非高斯噪声和变动剧烈的序列。通过 Wasserstein 距离或平滑处理,提高模型在嘈杂监控环境下的鲁棒性。
-
Gaussian Mixture VAE: 使用 GMM(高斯混合模型) 代替单一高斯分布作为先验,从而学习数据中的多模态特征(即服务器可能有多种正常的运行状态)。
-
-
跨领域融合(GNN + VAE + Transformer)
-
TopoMAD: 为云系统设计,结合了 GNN (捕捉拓扑空间关系)+ LSTM (捕捉时间)+ VAE(捕捉随机性)。
-
Variational Transformer: 用 Transformer 的自注意力机制代替图结构,在降维的同时捕捉稀疏相关性。
-
3.3.5 生成对抗网络(GAN)
GAN 的"博弈"机制:
- 生成器 (G): 试图学习正常数据的分布,生成看起来像真实数据的"伪造窗口"。
- 判别器 (D): 试图区分输入是"真实的训练数据"还是"生成器造出来的假数据"。
- 对抗损失:
- 这是一个最大最小博弈(Minimax Game)。
- 生成器努力让判别器犯错(降低识破假数据的概率)。
- 判别器努力提高准确度(最大化识别真假的能力)。
-
稳健重构与时间增强 (BeatGAN)
-
核心: 结合了 AE 的重构能力和 GAN 的对抗特性。
-
特色: 引入了**时间规整(Time Warping)**数据增强技术,通过改变时间序列的速度来增加训练集的多样性。这使得模型对服务器指标在时间轴上的小幅度漂移(如某个任务比平时晚了几秒)更具鲁棒性,不会产生误报。
-
-
多重对抗与潜空间对齐 (DAEMON)
-
核心: 这是一个比较复杂的架构。
-
特色: 它不仅重构原始数据,还强制要求隐藏层的向量(Latent Vector)符合一个预设的先验分布。这种双重对抗策略防止了模型去"勉强"重构它从未见过的异常模式,从而让异常分数更高、更准确。
-
-
时序捕获 (MAD-GAN)
-
核心: LSTM + GAN 的组合。
-
特色: 使用 LSTM 作为 G 和 D 的基础单元,专门用来捕捉多变量时序中的时间依赖关系。它同时利用重构误差 (生成器还原得好不好)和判别损失(判别器觉得它像不像真的)来共同判定异常。
-
-
过滤过拟合 (FGANomaly)
-
核心: 引入"过滤器"概念。
-
特色: 在训练前先用伪标签滤掉可能包含异常的样本,并使用自适应权重损失。这解决了"训练集不纯净"的问题,让模型能够更专注地学习"什么是正常行为"。
-
3.3.6 Transformer
-
Anomaly Transformer:关联差异化 (Association Discrepancy)
-
核心思路: 正常的点很容易与周围的点建立"紧密联系"(Series Association),而异常点往往与整体序列脱节。
-
技术创新: 它同时学习先验关联 (基于高斯核,关注邻近点)和系列关联 (基于原始数据的自注意力)。通过一个 MINIMAX(最大最小)策略,模型会故意放大这种关联差异,让异常点在重构时显得格外出挑。
-
-
TranAD:自调节与对抗增强
-
核心思路: 针对那些非常微小的、隐蔽的异常(Subtle anomalies)。
-
技术创新:
- 对抗训练: 类似 GAN,它通过对抗过程故意放大重构误差,让微小异常无所遁形。
- 自调节 (Self-conditioning): 确保特征提取的稳定性。这种架构在处理大规模输入时既稳定又高效,非常契合你 32G 内存 和 5070Ti 的配置。
- 对抗训练: 类似 GAN,它通过对抗过程故意放大重构误差,让微小异常无所遁形。
-
-
混合架构 (DCT-GAN & MT-RVAE)
-
DCT-GAN: 这是一个"全明星"组合。用 Transformer 处理序列,用 GAN 进行重构,用 空洞 CNN (Dilated CNN) 从潜空间提取时间信息。它还融合了多个尺度的生成器,泛化能力极强。
-
MT-RVAE: 结合了 Transformer 的序列建模能力和 VAE 的概率分布建模能力。
-
-
Dual-TF:时域与频域的双重侦测
-
核心思路: 有些异常在时间轴上不明显,但在频率上很诡异(比如周期性的规律突然乱了)。
-
技术创新: 使用两个并行的 Transformer,一个看时间域 ,一个看频率域。这种双域分析能同时精准定位"点异常"和"子序列异常",解决了时频粒度不一致的问题。
-
3.4 基于表示的模型
3.4.1 Transformer
-
核心架构:分层 Transformer
-
多尺度捕捉: TS2Vec 采用了**分层 Transformer(Hierarchical Transformer)**架构。这意味着它不仅能看到当前时刻的细微变化(微观),还能看到整个趋势(宏观)。
-
通用表示学习: 它的目标不是直接检测异常,而是学习一种"通用表示"。一旦模型理解了什么是正常的服务器运行状态,异常检测就变成了顺水推舟的下游任务。
-
-
自监督对比学习 (Contrastive Learning)
- **数据增强 (Augmentation):对同一段时序数据进行两种处理------**时间戳掩码(Timestamp Masking)和随机裁剪(Random Cropping)。
- 正样本对 (Positive Pairs): 同一时间戳在两种不同增强背景下的表示,被定义为"正样本"。模型的目标是让它们的表示尽可能接近。
- 负样本对 (Negative Samples): * 同一序列中不同时间戳的表示。
- 同一批次(Batch)中其他序列在同一时间戳的表示。
- 模型的目标是让这些表示尽可能远离。
3.4.2 卷积神经网络CNN
-
TF-C (时频一致性模型)
-
核心思路: 它认为同一个时间序列在"时间域"和"频率域"的表达应该是一致的。
-
架构: 使用 3 层 1-D ResNets(残差网络)分别作为时间分量和频率分量的编码器。
-
学习机制: 通过"一致性损失",将时域和频域特征拉入同一个潜空间。
-
正负样本: 正样本是原始样本的轻微扰动版,负样本是其他不同的样本。
-
-
DCdetector (双重自注意力检测器)
-
核心思路: 专注于空间(指标间)和时间维度的双重注意力。
-
创新点: 它不使用负样本。它通过最大化正常和异常样本之间的"表示差异(Representation Discrepancy)"来识别微小异常。
-
-
CARLA 与 DACAD (引入人工异常)
-
CARLA: 两阶段框架。第一阶段让模型学习区分"原始样本"和"注入了人工异常的样本";第二阶段利用邻居信息进行分类。正样本选自邻居,负样本是注入的异常。
-
DACAD: 在 CARLA 基础上引入了 TCN(时间卷积网络) 和 领域自适应(Domain Adaptation)。它能让模型在一个环境(如 A 服务器集群)学到的经验,快速迁移到另一个环境(如 B 服务器集群)。
-
3.5 混合模型
3.5.1 自编码器
-
CAE-M (深度卷积自编码记忆网络)
-
核心思路: 同时进行重构(Reconstruction)**和**预测(Prediction)。通过双管齐下的方式,模型既能理解当前的结构,又能把握未来的走向。
-
关键技术:
- MMD 惩罚(Maximum Mean Discrepancy): 这是一个统计学上的约束,强制让模型学到的低维特征符合目标分布。它的最大作用是防过拟合 ,防止模型把训练集里的噪声或隐蔽异常也当成"正常模式"给学进去了。
- 时空建模: 使用双向 LSTM(Bi-LSTM)**和**注意力机制来捕捉时间依赖,同时利用卷积层处理多指标间的空间关联。
- MMD 惩罚(Maximum Mean Discrepancy): 这是一个统计学上的约束,强制让模型学到的低维特征符合目标分布。它的最大作用是防过拟合 ,防止模型把训练集里的噪声或隐蔽异常也当成"正常模式"给学进去了。
-
-
NSIBF (神经系统辨识与贝叶斯过滤)
-
核心思路: 为**信息物理系统(CPS)安全性设计。它不只是给出一个分值,而是利用状态空间模型(State-Space Model)**来跟踪系统"隐藏状态"的不确定性。
-
关键技术:
- 贝叶斯过滤(Bayesian Filtering): 在检测阶段,它通过贝叶斯推断来估算观测值的概率似然度。
- 不确定性跟踪: 它能感知系统运行中的"模糊地带"。如果观测到的传感器数据与系统内部预测的隐藏状态严重不符,就会触发报警。
- 贝叶斯过滤(Bayesian Filtering): 在检测阶段,它通过贝叶斯推断来估算观测值的概率似然度。
-
3.5.2 循环神经网络RNN
模型名称: TAnoGan (Time-series Anomaly Detection with GAN)。
核心架构: 基于 LSTM (长短期记忆网络)的 GAN 架构。
解决痛点: 专门设计用于在训练样本有限的情况下检测时序异常。在现实的服务器监控场景中,虽然原始数据多,但高质量的、带标注的异常样本往往非常稀缺,TAnoGan 正是针对这种"数据贫瘠"的情况。
实验验证: 该方法在 NAB(Numenta Anomaly Benchmark)数据集上进行了测试。NAB 是时序异常检测领域最权威的基准测试集之一,包含了 46 个涵盖不同领域的真实时序数据。
核心结论: 实验证明,通过对抗训练(Adversarial Training),基于 LSTM 的 GAN 在处理复杂时序数据时的表现,要优于单纯的基于 LSTM 的非对抗模型。
3.5.3 图神经网络(GNN)
-
双并行 GAT 模型
- 核心思路: 使用两个并行的图注意力层(GAT) 。
-
第一层负责识别不同指标(维度)之间的联系(例如:流量激增是否导致了负载升高)。
-
第二层负责学习不同时间戳之间的关系(时间序列本身的演变)。
-
技术融合: 该模型同时使用了预测(Forecasting)**和**重构(Reconstruction)。
- 预测模型:预测下一个时间点的值。
- 重构模型:学习整个序列的低维特征表达。
-
- 核心思路: 使用两个并行的图注意力层(GAT) 。
-
最大优势: 可解释性(Interpretability)。它不仅能告诉你发生了异常,还能通过注意力权重告诉你"是哪几个指标的关联出了问题"。
-
FuSAGNet (融合自编码器与图网络)
- 核心思路: 将 稀疏自编码器(SAE)的重构能力 与 GNN 的预测能力 结合。
- 关键技术:
- 传感器嵌入(Sensor Embedding): 引入了之前提到的 GDN 模型,为每个传感器/指标学习一个特征向量。
- 循环单元(Recurrent Units): 在图处理后,使用类似 LSTM/GRU 的单元来捕获时间模式。
- 稀疏特征: 通过学习稀疏的潜空间表示,使模型能更敏锐地察觉那些打破常规行为的复杂异常。
- 关键技术:
- 核心思路: 将 稀疏自编码器(SAE)的重构能力 与 GNN 的预测能力 结合。
3.6 对于时序异常检测的模型选择指导
| 数据/任务特性 | 推荐架构 | 典型应用场景 |
|---|---|---|
| 多维数据且存在复杂依赖 | GNN (GCN, GAT) | IoT 传感器网络、工业系统、多指标联动监控 |
| 长距离时间依赖 | RNN (LSTM, GRU) | 金融分析、预测性维护、医疗监控 |
| 大规模数据且要求扩展性 | Transformer | 网络流量分析、超大规模集群监控 |
| 含噪声的数据 | AE / VAE | 网络流量、CPS 系统、高噪声传感器数据 |
| 高频数据与局部细节 | CNN / TCN | Web 流量、实时监控系统、细微偏离检测 |
| 模式演变与多模态分布 | 混合模型 (Hybrid) | 智能电网、气候监测、工业自动化 |
| 层级与多尺度上下文 | HTM | 极其嘈杂且具有复杂层级模式的数据 |
| 需跨数据集泛化 | 对比学习 (Contrastive) | 工业监测、网络安全、医疗诊断 |
四、数据集
4.1 数据集的分类维度
文章收集了 48 个 知名且高引用的数据集,并从以下 6 个维度进行了刻画:
- 数据性质: 真实的(Real)、合成的(Synthetic)或混合的。
- 实体数量: 数据集中包含多少个独立的序列。
- 变量类型: 单变量(UTS)、多变量(MTS)或两者兼有。
- 维度: 每个实体包含的特征数量(例如服务器指标的个数)。
- 样本总量: 整个数据集的数据点总数。
- 应用领域: 数据所属的行业(如工业、IT、医疗等)。
4.2 常用基准数据集
| 类型 | 常用数据集名称 | 特点/应用领域 |
|---|---|---|
| 多变量 (MTS) | MSL, SMAP, SMD, SWaT, PSM, WADI | 涵盖航天(MSL/SMAP)、服务器(SMD)、水处理(SWaT)等。 |
| 单变量 (UTS) | Yahoo, KPI, NAB, UCR | 涵盖互联网业务(Yahoo/KPI)、通用异常(NAB/UCR)等。 |
五、评估指标
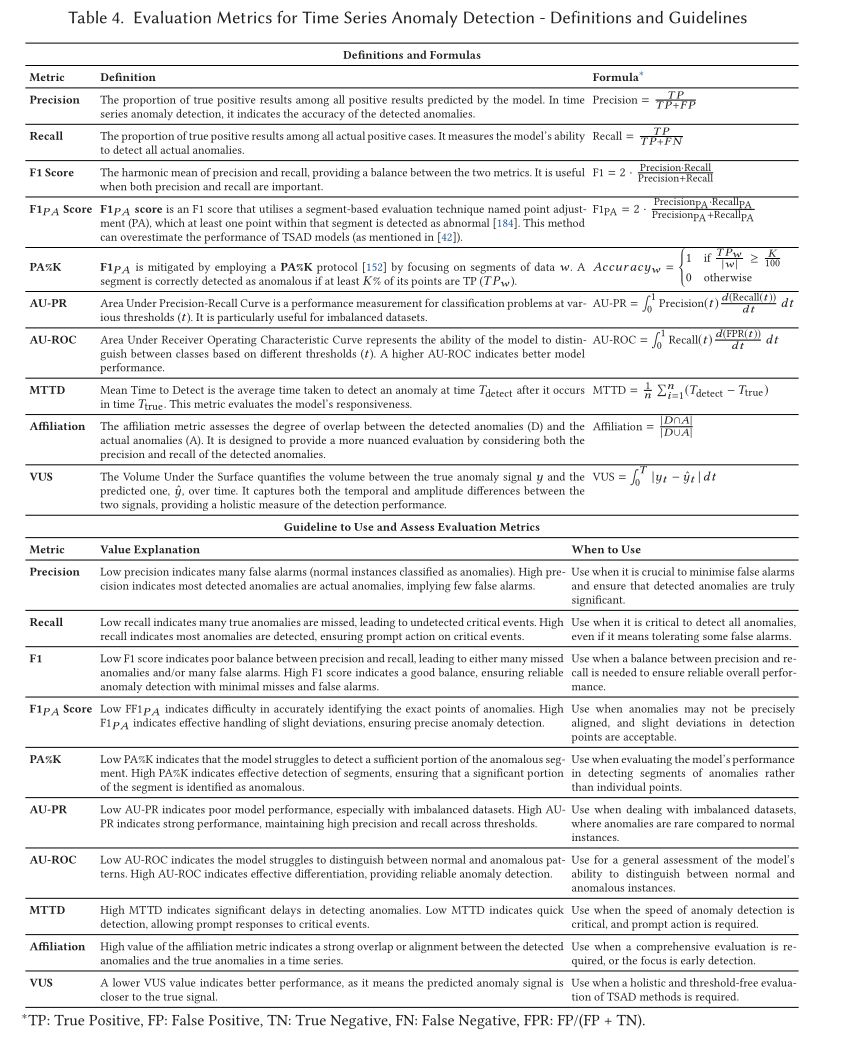
5.1 传统分类指标 (Point-based Metrics)
- Precision (精确率): 模型报出的异常中,有多少是真的。避免"虚警"。
- Recall (召回率): 所有的真实异常中,模型抓住了多少。避免"漏报"。
- F1 Score: 精确率和召回率的调和平均,综合评估。
- AU-ROC / AU-PR: 衡量模型在不同阈值下的整体分类能力,AU-PR 在处理极度不平衡的数据(异常极少)时比 ROC 更有效。
5.2 针对时序调整的指标 (TS-Specific Metrics)
这些指标考虑了异常的"段"特征和时间特性:
- F1PA (F1 Score with Point Adjustment): 一种针对时序的特殊计算方式。如果异常段(Segment)中有一个点被检测到,则认为整段都被正确检测。
- MTTD (Mean Time to Detect,平均检测时间): 衡量模型从异常开始发生到发出警报之间的延迟。在服务器运维中,这个指标直接关系到损失的大小。
- VUS (Volume Under the Surface): 这是一个比较前沿的指标,通过同时改变"检测阈值"和"缓冲区大小(Buffer Size)"来评估模型,对滞后和噪声更具鲁棒性。
5.3 基于关联/位置的指标 (Proximity Metrics)
- Affiliation (关联度指标): 一种新型评估方式。它不要求预测点和真实点完全重合,而是计算预测点与最近真实异常段之间的距离,能更客观地评价模型对异常区域的捕捉能力。
| 指标类型 | 代表性指标 | 关注点 | 建议应用场景 |
|---|---|---|---|
| 基础精度 | Precision, Recall, F1 | 预测的准确性 | 通用评估 Baseline |
| 段检测能力 | F1PA | 只要抓到异常段就算成功 | 工业/服务器告警场景 |
| 检测速度 | MTTD | 预警的及时性 | 实时监控、防患于未然 |
| 鲁棒性评价 | VUS, AU-PR | 对噪声和不平衡的抗性 | 科研论文、模型深度对比 |
| 可容忍度 | Affiliation | 预测位置与真实的距离 | 允许有一定时间滞后的场景 |
六、可解释性指标
6.1 HitRate@P%:根因覆盖率
- 定义: 检查真正的故障原因(Relevant Dimensions)是否出现在模型预测的前 P % P\% P% 优先级名单中。
- 逻辑: 这种指标类似于推荐系统。如果 P = 10 P=10 P=10,即模型给出的前 10% 疑似原因里包含了真实原因,就算"击中"。它奖励模型能够找全所有真因。
- 公式意义: HitRate@P% = 前 P % 中的真因数 总真因数 \text{HitRate@P\%} = \frac{\text{前 } P\% \text{ 中的真因数}}{\text{总真因数}} HitRate@P%=总真因数前 P% 中的真因数。
6.2 IPS (Interpretation Score):解释得分
- 定义: 这是 HitRate@K 的进阶版,不仅看是否击中,还考虑了段(Segment)级别的精确度。
- 逻辑: 它对每个异常段计算 Top-k 的击中率,然后取全局平均。它量化了模型精准定位最相关因素的能力。
6.3 RC-top-k (Relevant Causes top-k):关键原因检出率
- 定义: 在模型给出的前 k k k 个原因中,只要包含至少一个真实原因,该事件就被计为成功。
- 逻辑: 与 HitRate 不同,它不要求找全,只要能抓到一个线索就算赢。
- 公式意义: RC-top-k = 前 k 个原因中包含至少一个真因的事件数 总事件数 \text{RC-top-k} = \frac{\text{前 } k \text{ 个原因中包含至少一个真因的事件数}}{\text{总事件数}} RC-top-k=总事件数前 k 个原因中包含至少一个真因的事件数。
6.4 RDCG@P%:重构折扣累积增益
- 定义: 借鉴自搜索领域的 NDCG。它根据**重构误差(Reconstruction Error)**对维度进行排名。
- 逻辑: 误差越大,该维度是故障源的可能性越高。RDCG 不仅看真因是否在名单里,还看它的排名先后。如果真因排在第 1 名,得分远高于排在第 10 名。
- 公式特点: 使用 log 2 ( i + 1 ) \log_2(i+1) log2(i+1) 作为折扣因子,排名越靠后,权重衰减越快。
| 指标 | 核心逻辑 | 奖励行为 | 实验室应用建议 |
|---|---|---|---|
| HitRate@P% | 覆盖率 | 奖励"找得全" | 验证模型对复杂故障的理解力 |
| RC-top-k | 命中率 | 奖励"不落空" | 适合对响应速度要求极高的初筛 |
| IPS | 段精确度 | 奖励"定点准" | 最常用的综合解释性指标 |
| RDCG | 排序质量 | 奖励"排得前" | 衡量模型对故障严重程度的排序能力 |
七、应用领域
7.1 医疗健康 (Medicine & Health)
- 核心场景: 生理指标监测(ECG 心电图、EEG 脑电图、心率、痴呆症早期预警)。
- 技术特点: 利用 CNN 识别异常心跳波形,利用 RNN/LSTM 捕捉心脏搏动的长程时间特性,利用 TCN 提取脑电波特征进行癫痫检测。
7.2 物联网 (IoT) 与工业物联网 (IIoT)
- 核心场景: 智能家居通信监控、温室环境预测、工厂设备状态监测。
- 技术特点: 使用 LSTM 进行多步预测,利用 SCVAE(压缩卷积 VAE) 在边缘计算设备(算力有限的终端)上进行无监督检测。
7.3 服务器监控与维护 (重点关注)
- 核心场景: 微服务架构故障排除、云服务器健康检查。
- 代表模型: SLA-VAE (半监督 VAE),支持在线更新模型,只需少量样本即可应对不确定的云环境。
- 指标: 关注 CPU 使用率、负载、磁盘和内存(和你目前的研究方向完全一致)。
7.4 城市事件管理 (Urban Events)
- 核心场景: 交通拥堵预测、事故检测、人流聚集预警。
- 技术特点: 强调**时空(Spatiotemporal)**特性,使用 STGAN (时空图卷积对抗网络)和 GTransformer 捕捉不同地点和时间之间的复杂关联。
7.5 & 7.6 航天与天文 (Aerospace & Astronomy)
- 核心场景: 星体"光变曲线"分析、航天器遥测数据监控。
- 技术特点: 航天故障可能是毁灭性的,因此使用 Transformer 的遮罩策略进行提前预警,以及处理多源缺失数据的无监督方法。
7.7 自然灾害检测
- 核心场景: 地震预测。
- 技术特点: 监测前兆数据中的"趋势变化"和"高频扰动"。使用 CNN 定位震源,使用 CrowdQuake(卷积 RNN)分析加速度传感器数据。
7.8 能源 (Energy)
- 核心场景: 石油炼化厂故障监测、电网网络攻击检测、建筑能耗异常。
- 技术特点: 针对数据稀疏问题使用迁移学习 。利用 PMU(相量测量单元) 数据包检测针对电力系统的网络攻击。
7.9 工业控制系统 (ICS)
- 核心场景: 系统调用(System Calls)分析、半导体制造(晶圆质量检测)。
- 技术特点: 在内核级别提取特征,捕捉复杂的机器交互。使用 MTS-CNN 对半导体生产进行根因分析(RCA)。
7.10 机器人 (Robotics)
- 核心场景: 生产线机器人预防性维护、康复辅助机器人。
- 技术特点: 使用 SWCVAE(滑动窗口卷积 VAE)实时追踪机器人状态,防止在执行喂食或剃须等精细任务时发生故障。
7.11 环境管理 (Environmental)
- 核心场景: 海洋监测系统(OOS)、污水处理厂(WWTP)、管道泄漏检测。
- 技术特点: 使用 OceanWNN (小波神经网络)处理极端环境下的传感器数据,使用 CNN 识别管道内的流体噪声。
| 领域 | 核心架构倾向 | 关键目标 |
|---|---|---|
| 服务器/云 | VAE, AE | 在线更新、微服务链路追踪 |
| 交通/城市 | GNN, Transformer | 时空依赖、不确定性估计 |
| 医疗 | CNN, RNN | 波形分类、生理规律捕捉 |
| 工业/机器人 | VAE, TCN | 实时性、边缘计算适配 |
八、未来挑战
非平稳性与动态环境 (Non-stationarity):
- 挑战: 现实世界(如服务器集群)的分布一直在变。传统的静态模型很快就会失效。
- 对策: 需要研究**在线学习(Online Learning)**或增量学习,让模型能实时更新。
多变量高维数据处理:
- 挑战: 当维度极高时,数据变得稀疏(维数灾难),且模型必须同时兼顾"时间依赖"和"维度间相关性"。
减少误报率 (False Positives):
- 挑战: 在无监督学习中,由于没有标签指导,模型经常把"罕见的正常波动"错报为异常。
- 对策: 寻找能降低误报、提升召回率的稳健机制。
噪声干扰:
- 挑战: 时序数据中充满了噪声,且分布不均,模型容易被噪声误导产生性能波动。
可解释性 (Interpretability) 匮乏:
- 挑战: 目前大多数研究只追求"算得准(F1值)",但不解释"为什么是异常"。
- 对策: 诊断异常的具体维度(根因分析)是未来急需加强的方向。
周期性子序列异常:
- 挑战: 目前研究多集中在"点异常",而忽略了以一定周期重复出现的"序列异常"。