引言
你好,我是司沐。在上个月月初,有个朋友说,他们团队正在做Text2SQL系统,想问问我有没有什么技巧。
恰好我自己也落地过几个Text2SQL系统,而且每次设计好新的一版系统,再回看旧系统时,都会感叹------之前怎么写的这么烂!
于是我和他聊了聊他们团队目前的设计思路,没想到真的是我自己曾经踩过坑的那些原始设计,比如大模型直接执行SQL,并且使用的是本地部署的十几B的小参数开源模型。聊这一场下来,感觉看到了自己的来时路。
于是,为了避免更多的人踩坑,就有了本系列。
一开始,我想直接从当下经过实战检验的架构开始写。但是想了想,所有事物都是在矛盾中发展的,如果抽掉系统演化的过程而直接展示最新版本的系统,其实并不利于建立工程思维,也会影响理解的深度。
所以,我会从最原始的需求出发,以需求驱动的方式,将Text2SQL系统抽象出三层演进,并逐层递进地讲讲每一层的设计。

在做大型企业级应用(特别是ERP、CRM或者复杂的商品订单库)时,我们经常会面临一个让后端开发极其头大的问题:数据的查询需求实在是太刁钻、太庞杂了。
想象一下,你面对一个庞大的数据系统,数据量动辄千万级,表结构复杂得像迷宫。业务方的需求总是千奇百怪、刁钻至极:
- "帮我查一下上个季度在华东地区下单超过三次但没有退货记录的用户的平均客单价。"
- "我想看那个谁......对,就那个新渠道进来的用户,留存率怎么样?"
作为后端开发,如果每一个这种"拍脑袋"的需求都要写一个专门的接口,那我们哪怕有三头六臂也得累死在键盘上。
这就催生了 Text to SQL 的核心驱动力------低频动态非标查询。
如果能借助大模型,直接把自然语言转成SQL,还能自动处理边界条件、做数据汇总,那我们岂不是可以省掉这些低频场景的开发量?
在实现这个愿景的途中,我把Text to SQL系统的进化之路分为了三层境界。今天,我们就像剥洋葱一样,一层一层地来拆解这套系统的演进逻辑。

第一层境界:博学型AI的"直觉"
从直觉出发,如果我们想让AI查数据,最简单的路径是什么?
当然是:我给表结构,AI写SQL。
但是,刚出生的AI就像个实习生,它对你的数据库一无所知。它不知道表名,不知道字段意图,更不知道数据规模。你直接问它,它只能凭直觉写出来一堆飘红的查询语句。
所以,第一阶段的建设重点,是 "注入知识"。
我们需要构建一个系统提示词,把数据库的各类定义信息都告诉AI。在这个过程中,下面五类信息是绝对不能少的:
- 表名:准确的物理表名。
- 字段名:每个列的名称。
- 字段类型:是Int,Varchar,还是Datetime?
- 数据量:这张表是100行,还是1个亿?
- 索引信息 :(划重点!这是最容易被忽略但最致命的)

为什么要强调索引?
如果没有索引信息,AI可能会写出那种看起来逻辑正确,但实际上是"性能杀手"的SQL。比如在几千万数据的表上做一个没有索引的WHERE查询,满怀豪情地写三四张表的 join,或者随手搞个笛卡尔积。
结果就是:SQL发出去,数据库CPU飙升100%,整个业务系统卡死,DBA提着电推子赶来立誓要你华发早脱。
所以,告诉AI哪些字段有索引,是保命的关键。
遭遇瓶颈:当业务逻辑开始"作妖"
有了上面这五类信息,简单的查询(比如"查一下用户表有多少人")已经能跑通了。但现实往往很骨感。
考虑到不同群体的业务方法不一样,电商人不太理解CRM业务,写物流仓储的也不理解IM软件表结构,我们就用一个大家一定接触过的场景来举例:学校。
假设学校教务系统数据库设计如下(已经非常简化了):

此时,业务方甩来一个问题:
"今年某某班级学生在C语言程序设计这一门课中,比上一次考试提升幅度超过20%的学生有哪些?"
这时候,第一阶段的AI就开始懵圈了。
一个能解决这个问题的SQL语句如下:
sql
SELECT
s.student_id AS 学号,
s.name AS 姓名,
mid_score.score AS 期中成绩,
final_score.score AS 期末成绩,
ROUND(((final_score.score - mid_score.score) / mid_score.score) * 100, 2) AS 提升百分比
FROM
sys_student s
-- 1. 关联行政班级,锁定特定班级
JOIN sys_admin_class c ON s.class_id = c.class_id
-- 2. 关联选课记录,锁定特定课程
JOIN edu_enrollment e ON s.student_id = e.student_id
JOIN edu_course_offering co ON e.offering_id = co.offering_id
JOIN edu_course_catalog cc ON co.course_id = cc.course_id
JOIN edu_semester sem ON co.semester_id = sem.semester_id
-- 3. 自连接获取"期中"成绩 (Previous Exam)
JOIN edu_exam_definition mid_def ON co.offering_id = mid_def.offering_id
AND mid_def.exam_name = '期中考试'
JOIN edu_exam_score mid_score ON mid_def.exam_def_id = mid_score.exam_def_id
AND mid_score.student_id = s.student_id
-- 4. 自连接获取"期末"成绩 (Current Exam)
JOIN edu_exam_definition final_def ON co.offering_id = final_def.offering_id
AND final_def.exam_name = '期末考试'
JOIN edu_exam_score final_score ON final_def.exam_def_id = final_score.exam_def_id
AND final_score.student_id = s.student_id
WHERE
-- 筛选条件
c.class_name = '计算机科学与技术2301班' -- 某某班级
AND cc.name = 'C语言程序设计' -- 某某课程
AND sem.name = '2024-2025-1' -- 今年/特定学期
AND mid_score.score > 0 -- 避免除以0错误
-- 核心逻辑:提升幅度 > 20%
AND ((final_score.score - mid_score.score) / mid_score.score) > 0.20
ORDER BY
提升百分比 DESC;我们上一版的AI能写出来吗?我看很难,因为这是一个典型的多表联查 + 业务逻辑问题。
- "上一次考试"是指哪一次?期中?还是月考?
- "提升幅度"怎么算?
- 表与表之间怎么关联?是用
student_id还是user_no?
光给字段类型,AI是悟不出这些"潜规则"的。

这时候,我们需要进入 "后端架构师模式"。
思考一下,如果我们要把这个任务交给一个完全不懂业务的新人,我们会给他看什么?肯定是业务文档。
所以,我们需要进阶。仅仅给Schema是不够的,我们还得像教一个新来的后端架构师那样去教AI。我们需要额外注入:
- 表的DSL(领域特定语言)。
- 表在业务中的实际作用。
- 表与表之间的联动逻辑。
- 字段的业务映射(比如表里叫name,但业务上叫student_name)。
这一步非常耗时,可能需要花费数小时甚至数天来构建这个知识库。但如果你做到了,你会发现你的AI突然变得非常有"灵性",它仿佛开窍了,能处理非常复杂的聚合查询。
第二层境界:化繁为简的Agent分身术
随着业务发展,新的噩梦来了。
随着业务复杂度不断上升,你的系统从10张表膨胀到了50张、100张。每张表的DSL和元数据加起来,Prompt长度直接爆表。
就算模型支持长文本,过多的干扰信息也会让AI注意力涣散(Lost in the Middle现象),导致它开始胡言乱语。
这时候怎么办?换更强的模型?
当然可以。换更强的模型是一个万金油解法。
但是,使用更强的模型通常意味着更昂贵的成本。即使你能接受成本问题,也还有其他问题,比如很多保密项目只能私有化部署,显存有限,我们可能只能用几B或十几B的小模型。
那这个问题如何解决呢?我们还是回到直觉。
如果让人去查这样一个巨型系统,他会背下所有文档吗?不会。他会 "按需查阅"。
- 这次任务涉及订单,我就只看订单表和用户表。
- 下次任务涉及库存,我就去翻库存文档。
我们可以把这个思路复刻给AI,这就引入了 MultiAgents系统。我们需要两个角色的配合:
- 信息披露 Agent (The Librarian):它的任务不是写SQL,而是"看懂需求,筛选资料"。
- SQL执行 Agent (The Worker):它的任务是拿着筛选好的资料,专心写SQL。

为什么要拆分?
有人问,合在一起不行吗?
不行。
拆分是为了上下文隔离。
- 把所有职能塞给一个Agent,Prompt会混乱,身份认知会模糊。各司其职,才能让Prompt能够专业化。
- 按职能拆分Agent可以显著降低Tokens消耗,因为两个Agent的上下文可以分开独立计价。
赋予"自我纠错"的能力
在这个架构中,SQL执行Agent 不需要知道全量数据,但它需要一把"瑞士军刀"------自主披露工具。
如果在写SQL的过程中,它发现:"咦,这张表的这个字段类型好像不对?" 或者 "我需要知道这个外键的具体约束"。
它可以通过工具调用来实现:
- 查阅特定表详情:获取某张表的完整定义。
- 询问披露Agent:通过自然语言回问上游Agent获取补充信息。
这样,即使第一轮披露的信息不完美,执行Agent也能通过Self-check(自检)补全信息,而不是直接报错。

终极杀手锏:直接"读代码"
如果系统复杂到连文档都写不清楚了怎么办?或者文档写好了,但数据库和业务层里全是祖传的"魔改逻辑"和触发器?
代码不会撒谎。
对于这种超高复杂度的场景,我们可以祭出大招:允许Agent阅读代码库。
这听起来很危险(确实有代码泄露风险,需谨慎),但对于理解业务约束(Constraints)和隐式逻辑(Implicit Logic)有着奇效。
实现技术难点在于:RAG + Language Server。
- 普通的RAG(检索增强生成)负责找相关代码片段。
- Language Server负责做"函数跳转",找到变量的定义、函数的调用链。
这些信息,最终都变成了Agent手中的工具,让它能像资深程序员Debug一样去理解数据背后的逻辑。

灵魂拷问:成本与效率的博弈
至此,第二阶段的系统(多Agent + 工具链 + 代码阅读)已经非常强大了。准确度高,上下文不爆炸。
但是,凡事都有代价。
我自己参与过很多项目,算过一笔账:对于一个百表级的系统,跑完这一套Agent流程(多轮对话、Token消耗、推理时间),一次查询的成本可能高达几十元人民币,甚至几美刀。

- 如果是 Boss Agent(老板偶尔问几个战略问题),这钱花得值。
- 如果是 客服平台 或 高频接单系统,这种成本会直接把项目搞破产。
这就要提到那个著名的**"不可能三角"**了。在Agent系统中,我们也有五个维度的取舍:
- 能力范围(能干多少事?)
- 结果准度(答案正确率怎么样?)
- 金钱成本(跑一次多少钱?)
- 时间开销(跑一次要多久?)
- 预先构建(事前要准备多少知识?)
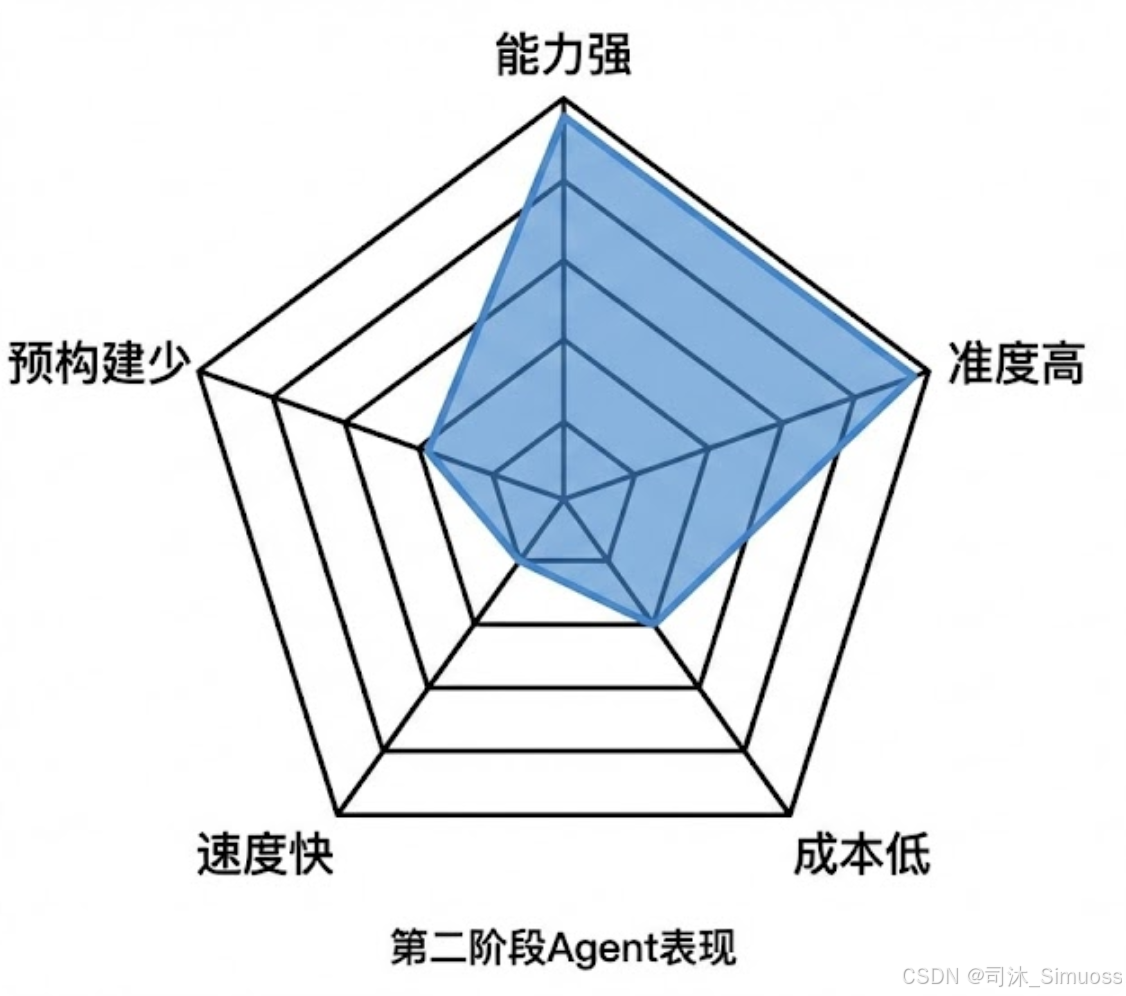
我们不可能五个全占。但如果我们愿意舍弃其中几个,剩下的指标就会变得非常漂亮。
这就引出了我们的第三层境界。这也是我唯一推荐在生产环境大规模部署的方案。
根据取舍的不同,Agent系统可以演化出多种"变体"。
到底怎么取舍?如何用最低的成本实现80%甚至90%的效果?这些"生产级"的干货,我们留到下一篇文章详细拆解。
