文章目录
-
- 网络传输原理:数据如何在网络中旅行
- 一、局域网通信原理
-
- [1.1 两台主机在同一局域网能直接通信吗](#1.1 两台主机在同一局域网能直接通信吗)
- [1.2 认识MAC地址](#1.2 认识MAC地址)
- [1.3 以太网的通信规则](#1.3 以太网的通信规则)
- [1.4 局域网通信的完整流程](#1.4 局域网通信的完整流程)
- 二、数据封装与分用
-
- [2.1 报文的组成](#2.1 报文的组成)
- [2.2 不同层对报文的叫法](#2.2 不同层对报文的叫法)
- [2.3 封装过程](#2.3 封装过程)
- [2.4 分用过程](#2.4 分用过程)
- [2.5 报头的作用](#2.5 报头的作用)
- 三、认识IP地址
-
- [3.1 为什么需要IP地址](#3.1 为什么需要IP地址)
- [3.2 IP地址的格式](#3.2 IP地址的格式)
- [3.3 IP地址的作用](#3.3 IP地址的作用)
- 四、跨网络传输流程
-
- [4.1 跨网络传输的问题](#4.1 跨网络传输的问题)
- [4.2 路由器的作用](#4.2 路由器的作用)
- [4.3 完整的跨网络传输流程](#4.3 完整的跨网络传输流程)
- [4.4 IP地址和MAC地址的对比](#4.4 IP地址和MAC地址的对比)
- 五、网络层的意义
-
- [5.1 为什么需要网络层](#5.1 为什么需要网络层)
- [5.2 IP网络的虚拟化](#5.2 IP网络的虚拟化)
- [5.3 路由器的转发原理](#5.3 路由器的转发原理)
- 六、封装与分用的宏观理解
-
- [6.1 学习协议的两个关键问题](#6.1 学习协议的两个关键问题)
- [6.2 数据传输的完整图示](#6.2 数据传输的完整图示)
- [6.3 协议栈的分层处理](#6.3 协议栈的分层处理)
- 七、本篇总结
-
- [7.1 核心要点](#7.1 核心要点)
- [7.2 容易混淆的点](#7.2 容易混淆的点)
网络传输原理:数据如何在网络中旅行
💬 开篇:上一篇我们理清了协议分层的框架,但数据到底怎么从一台主机传到另一台?局域网内的通信和跨网络的通信有什么区别?MAC地址和IP地址各自解决什么问题?这一篇会从数据封装的角度,带你看清数据在网络中的完整旅程。理解了封装和分用的过程,后面学习每一层的协议时,你就能把它们串起来。
👍 点赞、收藏与分享:这篇会讲清楚报文、报头、载荷这些核心概念,以及路由器在跨网络传输中的作用。如果对你有帮助,请点赞收藏!
🚀 循序渐进:从局域网通信到跨网络传输,从MAC地址到IP地址,一步步理解网络传输的完整流程。
一、局域网通信原理
1.1 两台主机在同一局域网能直接通信吗
答案是可以的。但这里有个前提:主机之间要能识别彼此。你在局域网里广播一条消息,所有主机都能收到,但怎么知道这条消息是不是发给自己的?
这就需要MAC地址。
1.2 认识MAC地址
MAC地址(Media Access Control Address)是数据链路层用来识别设备的唯一标识。每块网卡在出厂时就被分配了一个全球唯一的MAC地址,长度48位(6个字节),通常用16进制表示,比如 08:00:27:03:fb:19。
MAC地址的作用:
- 在局域网内标识设备的唯一性
- 数据链路层通过MAC地址转发数据帧
- 网卡收到数据帧后,检查目标MAC地址是否匹配,匹配就接收,不匹配就丢弃
这里要注意一点:虚拟机的MAC地址不是真实的MAC地址,可能会冲突。另外,某些网卡支持用户修改MAC地址,但正常情况下,物理网卡的MAC地址是全球唯一的。
1.3 以太网的通信规则
以下碰撞/CSMA/CD主要发生在共享介质或集线器(Hub)的半双工以太网;现代交换机+全双工以太网基本没有碰撞域。
以太网(Ethernet)是最常见的局域网类型。它有几个基本规则:
-
同一时刻只允许一台设备发送数据。如果多台设备同时发送,信号会相互干扰,这叫数据碰撞(Collision)。
-
碰撞检测和避免。发送数据的主机需要检测是否发生碰撞,如果检测到碰撞,就停止发送,等待一段随机时间后重试。
-
没有交换机的情况下,一个以太网就是一个碰撞域。所有设备共享同一个传输介质,任何两台设备同时发送都会发生碰撞。
-
广播方式。主机A要给主机B发送数据,实际上是把数据广播到整个局域网,所有主机都能收到,但只有目标MAC地址匹配的主机才会接收并处理。
这里可以从操作系统角度理解:网卡收到数据后,先检查目标MAC地址。如果不是发给自己的,直接丢弃;如果是发给自己的,就把数据交给上层协议栈处理。
1.4 局域网通信的完整流程
假设主机A(MAC地址:AA:AA:AA:AA:AA:AA)要给主机B(MAC地址:BB:BB:BB:BB:BB:BB)发送数据:
- 主机A的应用层产生数据
- 数据逐层向下传递,每一层都添加自己的报头
- 到达数据链路层时,添加以太网帧头(包含源MAC和目标MAC)
- 物理层把数据转换成电信号,发送到网线上
- 局域网内所有主机都收到这个信号
- 主机B的网卡检查目标MAC地址,发现是发给自己的,就接收
- 数据逐层向上传递,每一层剥掉自己的报头
- 最终应用层拿到原始数据
其他主机(主机C、主机D...)也收到了信号,但检查发现目标MAC不是自己,就直接丢弃了。
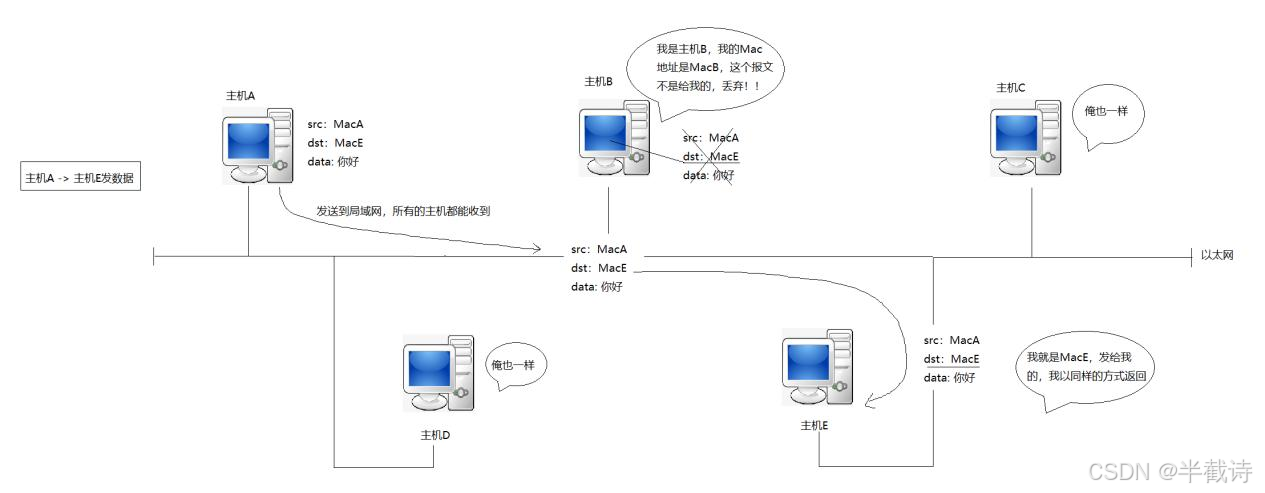
注意:现代交换机具备自学习算法:
首次通信:可能会因为 ARP 触发广播(广播帧所有主机都收到)
拿到 B 的 MAC 后:A 发给 B 的数据帧一般是 单播,交换机会根据 MAC 表只转发到 B 所在端口(其他主机收不到)
二、数据封装与分用
2.1 报文的组成
网络中传输的数据叫做报文(Message)。每个报文由两部分组成:
- 报头(Header):协议规定的结构体字段,包含控制信息
- 有效载荷(Payload):真正要传输的数据内容
报头就像快递单上的地址、电话、备注,载荷就是快递盒里的实际物品。
公式很简单:报文 = 报头 + 有效载荷
2.2 不同层对报文的叫法
不同的协议层对数据包有不同的称谓:
- 应用层:数据(Data)或消息(Message)
- 传输层:段(Segment),TCP段或UDP段
- 网络层:数据报(Datagram)或分组(Packet)
- 数据链路层:帧(Frame)
- 物理层:比特流(Bit Stream)
这些名字只是约定俗成的叫法,本质都是"报头+载荷"的结构。
2.3 封装过程
数据从应用层向下传递时,每一层都会添加自己的报头,这个过程叫做封装(Encapsulation)。
以发送一封邮件为例:
-
应用层:邮件内容(原始数据)
-
传输层:添加TCP报头(源端口、目的端口、序列号...)
bash
[TCP报头 | 邮件内容]- 网络层:添加IP报头(源IP、目的IP、TTL...)
bash
[IP报头 | TCP报头 | 邮件内容]- 数据链路层:添加以太网帧头(源MAC、目的MAC...)和帧尾
bash
[以太网帧头 | IP报头 | TCP报头 | 邮件内容 | 帧尾]- 物理层:转换成比特流发送
每一层的报头都包含了该层需要的控制信息。比如TCP报头告诉对方"这是第几个数据包,要不要确认",IP报头告诉对方"我的地址是多少,你的地址是多少"。
2.4 分用过程
数据到达目标主机后,需要逐层向上传递,每一层剥掉自己的报头,这个过程叫做分用(Demultiplexing)或解封装。
bash
接收端的处理过程:
1. 物理层收到比特流
2. 数据链路层检查以太网帧头,确认目标MAC是自己,剥掉帧头
3. 网络层检查IP报头,确认目标IP是自己,剥掉IP报头
4. 传输层检查TCP报头,根据目的端口号找到对应的进程,剥掉TCP报头
5. 应用层拿到邮件内容关键问题:每一层怎么知道上层是什么协议?
答案在报头里。每一层的报头都有一个字段,标识上层协议的类型。比如:
- 以太网帧头有"类型"字段,0x0800表示上层是IP协议
- IP报头有"协议"字段,6表示上层是TCP,17表示上层是UDP
- TCP/UDP报头有"目的端口号"字段,80表示HTTP,22表示SSH
这样,数据在向上传递时,每一层根据报头中的"上层协议"字段,就知道该把数据交给哪个上层协议处理。
2.5 报头的作用
报头里存放的是协议规定的控制信息。不同协议的报头内容不同,但作用类似:
- 标识信息:源地址、目的地址、协议类型
- 控制信息:序列号、确认号、标志位
- 校验信息:校验和,用于检测数据是否损坏
报头是协议的核心。学习任何协议,最重要的就是搞清楚它的报头格式。后面我们学TCP、IP协议时,会详细分析每个报头字段的含义。
三、认识IP地址
3.1 为什么需要IP地址
MAC地址能在局域网内标识设备,为什么还要IP地址?
问题在于:MAC地址只能在局域网内使用。你的公司在北京,分公司在上海,两个局域网不直接相连,怎么让北京的主机找到上海的主机?
这就需要IP地址。IP地址是网络层的概念,用来在全球范围内标识主机。
3.2 IP地址的格式
IPv4地址是一个32位的整数,通常用"点分十进制"表示,比如 192.168.0.1。每个数字表示一个字节(8位),范围是0-255。
bash
192.168.0.1
= 11000000.10101000.00000000.00000001 (二进制)
= 0xC0A80001 (十六进制)IP地址有两个重要特点:
-
全球唯一性(公网IP)。互联网上的每个主机都有一个唯一的公网IP地址。当然,局域网内可以使用私网IP(如192.168.x.x),私网IP不是全球唯一的。
-
层次性。IP地址分为网络部分和主机部分,这样可以通过网络部分快速定位到目标网络,再通过主机部分找到具体主机。这和电话号码的区号+本地号码类似。
3.3 IP地址的作用
IP地址在网络层用来标识主机,路由器根据IP地址进行路径选择。
你可以这样理解:
- MAC地址:局域网内的"门牌号",只在本地有效
- IP地址:全球范围的"邮政编码+地址",可以跨网络使用
四、跨网络传输流程
4.1 跨网络传输的问题
局域网内通信很简单:主机A把数据广播出去,主机B根据MAC地址接收。但跨网络通信就复杂了:
- 主机A在北京的局域网,主机B在上海的局域网
- 两个局域网不直接相连,中间隔着多个路由器
- 数据怎么从北京传到上海?
答案是:通过路由器逐跳转发。
4.2 路由器的作用
路由器(Router)工作在网络层,它的主要职责是:
- 路径选择:根据目的IP地址,查找路由表,决定数据应该从哪个接口转发出去
- 连接不同网络:路由器有多个网络接口,每个接口连接一个不同的网络
- 解包和重新封装:路由器收到数据后,剥掉数据链路层的帧头,查看IP报头,然后重新添加新的帧头转发
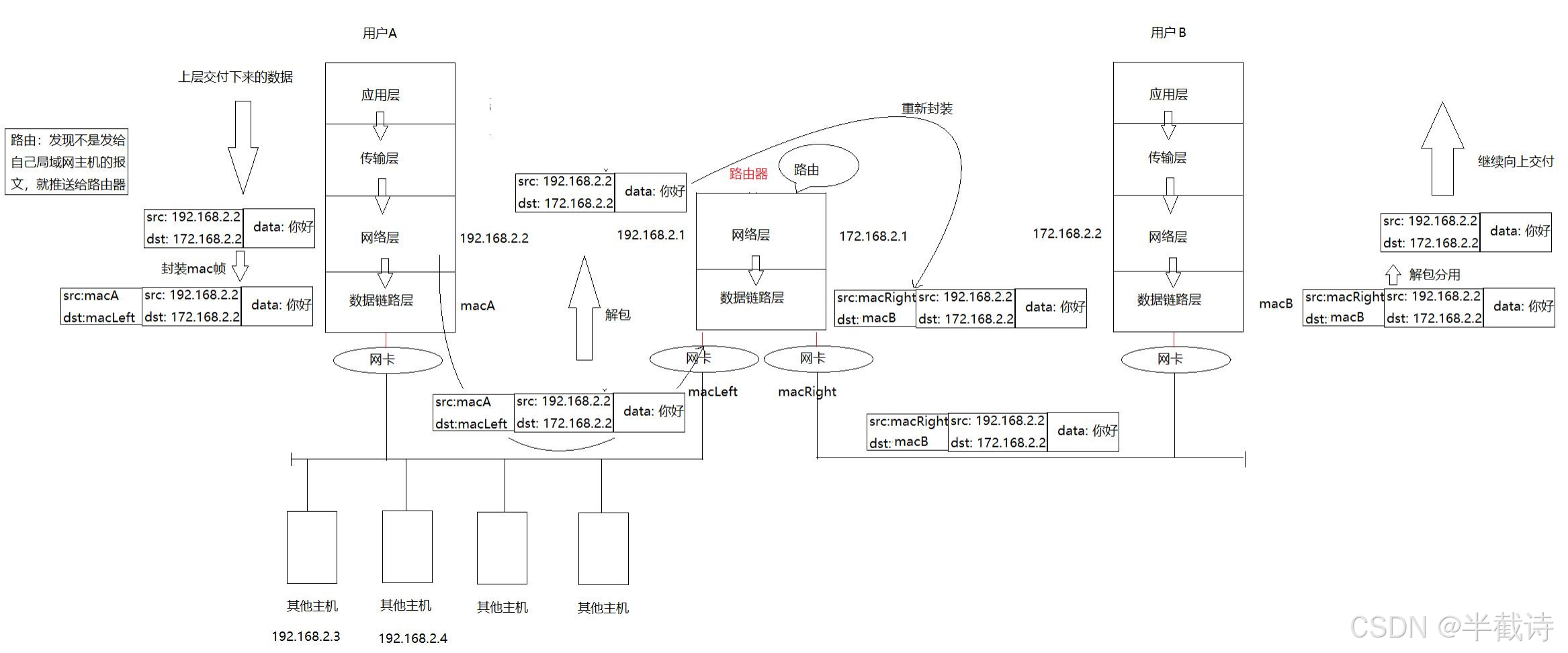
这里要理解一个关键点:路由器不转发帧,它转发的是数据报(IP报文)。
具体来说:
- 数据从主机A发出,到达路由器1
- 路由器1剥掉以太网帧头(源MAC和目的MAC),只保留IP报文
- 路由器1查看目的IP地址,决定从哪个接口转发
- 路由器1添加新的以太网帧头(源MAC改为路由器1的MAC,目的MAC改为下一跳路由器的MAC)
- 数据到达路由器2,重复上述过程
- 最终数据到达目标主机B所在的局域网
4.3 完整的跨网络传输流程
假设主机A(IP:192.168.1.10)要给主机B(IP:10.0.0.20)发送数据,中间经过路由器R1和R2。
第一跳:主机A → 路由器R1
- 主机A封装数据:
bash
[以太网帧头(源MAC=A, 目的MAC=R1) | IP报头(源IP=A, 目的IP=B) | TCP报头 | 数据]- 路由器R1收到后:
- 检查目的MAC是自己,接收
- 剥掉以太网帧头
- 查看IP报头的目的IP(B),查路由表,决定从接口2转发
第二跳:路由器R1 → 路由器R2
- 路由器R1重新封装:
bash
[以太网帧头(源MAC=R1, 目的MAC=R2) | IP报头(源IP=A, 目的IP=B) | TCP报头 | 数据]注意:源IP和目的IP始终是A和B。但以太网帧头变了,源MAC变成R1,目的MAC变成R2。
- 路由器R2收到后,重复上述过程
第三跳:路由器R2 → 主机B
- 路由器R2重新封装:
bash
[以太网帧头(源MAC=R2, 目的MAC=B) | IP报头(源IP=A, 目的IP=B) | TCP报头 | 数据]- 主机B收到后:
- 检查目的MAC是自己,接收
- 逐层解封装,最终应用层拿到数据
4.4 IP地址和MAC地址的对比
通过上面的流程,我们可以总结IP地址和MAC地址的区别:
| 特性 | IP地址 | MAC地址 |
|---|---|---|
| 作用范围 | 全球范围,可跨网络 | 局域网内,不可跨网络 |
| 变化性 | 在整个传输过程中不变 | 每经过一个路由器就变一次 |
| 作用 | 路径选择的依据 | 局域网转发的依据 |
| 层次 | 网络层 | 数据链路层 |
换句话说:
- 目的IP地址是长远目标,决定了数据最终要去哪里
- 目的MAC地址是阶段目标,决定了数据下一跳去哪里
主机A要给主机B发数据:
- 目的IP始终是B,这是最终目标
- 但目的MAC会变:先是R1(去往第一个路由器),然后是R2(去往第二个路由器),最后是B(到达目标主机)
五、网络层的意义
5.1 为什么需要网络层
我们已经有了数据链路层和MAC地址,为什么还要网络层和IP地址?
问题在于:世界上的网络类型有很多。以太网、WiFi、光纤、卫星链路,它们的底层实现完全不同。如果应用程序要直接面对这些差异,那每换一种网络类型,程序都要重写。
网络层的作用就是提供统一的抽象层,让上层协议(传输层、应用层)不需要关心底层网络的差异。
5.2 IP网络的虚拟化
IP协议让所有网络都变成"IP网络"。不管底层是以太网、WiFi还是光纤,在应用层看来都是一样的:
- 发送方:把数据交给IP层,IP层负责选路和转发
- 接收方:从IP层拿到数据,不需要知道底层是怎么传的
这种虚拟化的思想和操作系统的文件系统类似。你用fopen打开文件,不需要关心底层是机械硬盘还是固态硬盘,文件系统把这些差异屏蔽了。
5.3 路由器的转发原理
路由器维护一张路由表(Routing Table),记录 了"去往某个网络,应该从哪个接口转发"。
简化版路由表:
bash
目的网络 下一跳 接口
10.0.0.0/8 192.168.1.1 eth0
172.16.0.0/12 192.168.1.2 eth1
0.0.0.0/0 192.168.1.254 eth0 (默认路由)当路由器收到一个数据报时:
- 查看目的IP地址
- 在路由表中查找匹配的网络
- 从对应的接口转发出去
- 如果找不到匹配项,就用默认路由
这个过程叫做路由选择(Routing)。路由表可以是静态配置的,也可以通过路由协议(RIP、OSPF、BGP)动态学习。
六、封装与分用的宏观理解
6.1 学习协议的两个关键问题
从现在开始,我们学习任何协议,都要思考两个问题:
-
这个协议怎么解包的?
- 报头格式是什么?
- 每个字段的含义是什么?
- 怎么判断报文是否合法?
-
这个协议怎么把数据交给上层的?
- 报头中的哪个字段标识上层协议?
- 怎么根据这个字段找到对应的上层处理函数?
只要搞清楚了解包和向上交付,封包的过程也就理解了。因为封包和解包是镜像的过程。
6.2 数据传输的完整图示
从主机A到主机B的数据传输:
bash
主机A (应用层)
|
v
主机A (传输层) ← 添加TCP报头
|
v
主机A (网络层) ← 添加IP报头
|
v
主机A (数据链路层) ← 添加以太网帧头
|
v
主机A (物理层) → 发送到网络
|
v
路由器R1 (物理层) ← 接收
|
v
路由器R1 (数据链路层) ← 剥掉以太网帧头
|
v
路由器R1 (网络层) ← 查路由表,决定转发
|
v
路由器R1 (数据链路层) ← 添加新的以太网帧头
|
v
路由器R1 (物理层) → 发送到网络
|
v
... (可能经过多个路由器)
|
v
主机B (物理层) ← 接收
|
v
主机B (数据链路层) ← 剥掉以太网帧头
|
v
主机B (网络层) ← 剥掉IP报头
|
v
主机B (传输层) ← 剥掉TCP报头
|
v
主机B (应用层) ← 拿到原始数据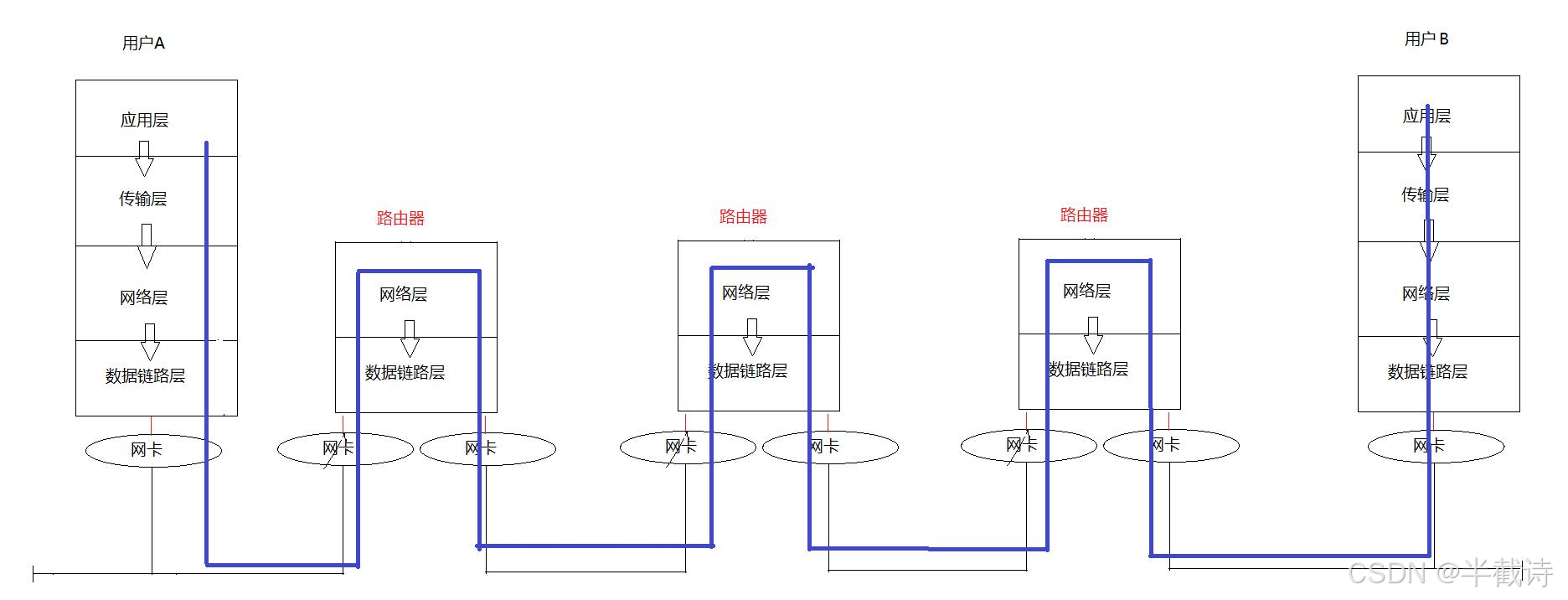
关键点:
- 主机A和主机B都经过完整的五层协议栈
- 路由器只经过三层(物理层、数据链路层、网络层)
- IP报头在整个过程中保持不变
- 以太网帧头每经过一个路由器就要重新封装
6.3 协议栈的分层处理
操作系统内核实现协议栈时,每一层都是一个独立的模块。数据在各层之间传递,每层只关心自己的报头:
c
// 伪代码示意
// 发送端
void send_data(char *data, int len) {
// 应用层
char *app_data = data;
// 传输层:添加TCP报头
char *tcp_segment = add_tcp_header(app_data);
// 网络层:添加IP报头
char *ip_packet = add_ip_header(tcp_segment);
// 数据链路层:添加以太网帧头
char *eth_frame = add_eth_header(ip_packet);
// 物理层:发送
send_to_network(eth_frame);
}
// 接收端
void receive_data(char *frame) {
// 数据链路层:检查并剥掉以太网帧头
char *ip_packet = remove_eth_header(frame);
// 网络层:检查并剥掉IP报头
char *tcp_segment = remove_ip_header(ip_packet);
// 传输层:检查并剥掉TCP报头
char *app_data = remove_tcp_header(tcp_segment);
// 应用层:处理数据
process_data(app_data);
}实际实现要复杂得多,但思路就是这样:逐层添加报头,逐层剥掉报头。
七、本篇总结
7.1 核心要点
局域网通信:
- MAC地址在数据链路层标识设备,全球唯一(物理网卡)
- 以太网采用广播方式,主机根据目标MAC地址判断是否接收
- 同一时刻只允许一台设备发送,多台同时发送会碰撞
数据封装与分用:
- 报文 = 报头 + 有效载荷
- 封装:数据向下传递,每层添加自己的报头
- 分用:数据向上传递,每层剥掉自己的报头
- 报头中包含"上层协议"字段,用于分用时找到对应的上层处理函数
IP地址的作用:
- 网络层的地址,用于全球范围内标识主机
- 32位整数,点分十进制表示(如192.168.0.1)
- 具有层次性,分为网络部分和主机部分
跨网络传输:
- 路由器工作在网络层,连接不同网络
- 路由器根据目的IP地址查路由表,决定转发路径
- IP报头在整个传输过程中保持不变
- MAC地址每经过一个路由器就要重新封装
IP地址 vs MAC地址:
- IP地址:长远目标,决定最终去哪里,不变
- MAC地址:阶段目标,决定下一跳去哪里,每跳都变
网络层的意义:
- 提供统一的抽象层,屏蔽底层网络的差异
- 让世界上所有网络都变成"IP网络"
- 类似操作系统的文件系统,屏蔽磁盘类型的差异
7.2 容易混淆的点
-
MAC地址只在局域网内有效:不要以为MAC地址能跨网络使用。跨网络传输时,MAC地址会不断变化,IP地址才是始终不变的。
-
路由器不转发帧:路由器转发的是IP数据报,它会剥掉原来的帧头,重新添加新的帧头。这是因为不同网络的帧格式可能不同(以太网、WiFi、光纤)。
-
封装和分用是镜像过程:发送端逐层添加报头,接收端逐层剥掉报头。理解了一个,另一个也就理解了。
-
目的IP不变,目的MAC一直在变:这是理解跨网络传输的关键。目的IP是最终目标,目的MAC是下一跳目标。类比一下:你从北京坐飞机到上海,"上海"是最终目的地(IP),但你要先去机场(第一跳的MAC),再上飞机(第二跳的MAC),最后到上海机场(第三跳的MAC)。
-
学习协议的方法:先搞清楚解包的过程(报头格式、字段含义),再搞清楚向上交付的机制(上层协议字段)。封包的过程就是解包的逆过程。
💬 总结:这一篇把网络传输的完整流程讲清楚了。从局域网通信到跨网络传输,从MAC地址到IP地址,从封装到分用,这些是理解网络协议的基础。后面我们会深入讲解每一层的具体协议,比如以太网帧格式、IP报文格式、TCP报文格式,但核心思路都是这样:报头定义了协议的规则,封装和分用实现了数据的传递。
👍 点赞、收藏与分享:如果这篇文章帮你理清了网络传输的流程,请点赞收藏!下一篇我们会讲Socket编程的预备知识,包括端口号、网络字节序、Socket API。