随着大模型参数规模、上下文长度和多模态能力持续提升,AI 算力的瓶颈正在从"峰值算力"转向显存容量、带宽与能效。在这一背景下,NVIDIA 于 GTC 2024 发布了基于 Blackwell 架构的 B200 GPU,其目标并非简单替代 H100 / H200,而是面向新一代超大模型工作负载进行系统级重构。
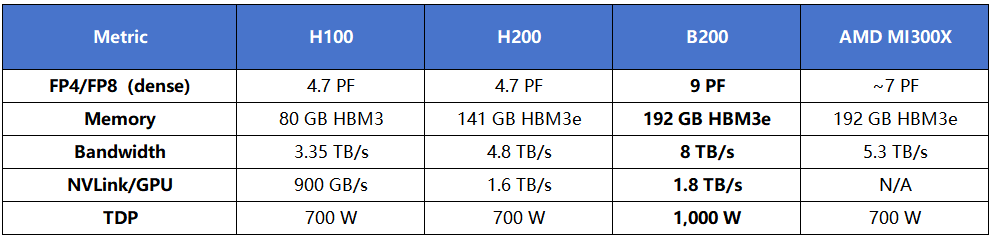
B200 采用双芯片(Dual-Die)封装,单卡集成约 2080 亿晶体管,配备 192 GB HBM3e 显存,并通过 NVLink 5 提供 1.8 TB/s 的 GPU 间互联带宽。同时,第五代 Tensor Core 原生支持 FP4 / FP6 / FP8 精度,为长上下文推理和规模化部署带来显著的性能与能效提升。

一、从架构看 B200 与 Hopper 的关键差异
B200 与 Hopper 架构最大的不同,在于其围绕大模型规模化运行进行的系统性设计调整。
在封装层面,B200 采用 双 GPU Die + 高速片间互联的方式,通过约 10 TB/s 的芯片级互联,在单个 SXM 插槽内形成统一的逻辑 GPU。这一设计在保持制造可行性的前提下,大幅提升了单卡的计算密度与显存容量。
在存储层面,192 GB HBM3e 与约 8 TB/s 带宽,直接缓解了长上下文推理、多专家模型和大规模训练中常见的显存不足与带宽受限问题,减少 offload 和重计算,对吞吐与稳定性都有明显改善。

在计算层面,第五代 Tensor Core 是 Blackwell 的核心价值之一。FP4 精度首次具备工程级可用性,在大模型推理场景下可以显著降低显存占用和单位 token 能耗,使高并发推理和长上下文处理更具现实可行性。
同时,B200 引入 第二代 Transformer Engine,通过改进张量调度、内存访问与流水线执行效率,提升真实负载下的 GPU 利用率。这类优化并不直接体现在峰值算力指标中,但在实际模型运行中效果明显。
在多卡扩展方面,NVLink 5 将单 GPU 互联带宽提升至 1.8 TB/s,配合 NVSwitch,可实现更接近线性的多卡扩展能力,为整机和整柜级部署奠定基础。
二、B200 更适合哪些实际工作负载?
从现阶段行业测试和部署经验来看,B200 并非所有场景的默认选择,但在以下工作负载中优势非常集中:
1. 超大规模语言模型训练与微调
对于 70B 以上 的密集模型或 MoE 架构,B200 可以在更少 GPU 数量下完成模型驻留,降低通信复杂度,并缩短训练和微调周期。
2. 长上下文推理与企业级 RAG 场景
在 64k--128k token 上下文长度下,B200 的显存容量与带宽优势尤为明显,可稳定支撑更大的 KV Cache,减少分页和 offload 行为。
3. MoE(混合专家)模型
更大的显存空间与 NVLink 5 高带宽互联,使多个专家能够更高效地并行调度,降低跨卡通信成本。
4. 多模态与生成式视觉任务
大规模视觉 Transformer、扩散模型等对显存带宽高度敏感,B200 的高带宽设计能够持续为计算单元供给数据,避免算力空转。
5. AI 与 HPC 混合负载
B200 具备接近 90 TFLOPS 的 FP64 性能,可在一定程度上同时承载科学计算与 AI 工作负载,适合统一算力平台的部署需求。

三、软件栈与模型层面的实践建议
B200 对软件生态提出了更新要求,但整体迁移成本可控:
●CUDA 建议 12.4 及以上
●推理侧优先考虑 TensorRT-LLM、vLLM
●注意显存管理与注意力机制实现(如 Flash-Attention)
在模型层面,参数规模大、上下文长、带宽依赖高的模型更容易体现 B200 的性价比优势;中小模型或短上下文任务并不一定需要 Blackwell 级别硬件。
四、B200、H200 与 H100 的选型思路
从工程角度,可以简化为以下判断逻辑:
●40B 以下模型 / 中短上下文:H100 仍然成熟、性价比高
●40B--70B 模型 / 中长上下文:H200 是较稳妥的升级路径
●70B 以上 / 长上下文 / MoE / 高并发推理:B200 更具优势
需要注意的是,B200 单卡功耗接近 1 kW,通常依赖液冷方案,更适合数据中心级或规模化部署环境。

总结
B200 的核心价值,并不只是性能数字的提升,而在于降低了超大模型稳定运行的工程门槛。更多复杂模型可以在更少节点、更低通信成本的条件下完成训练与推理,使算力资源真正转化为可持续的生产能力。
在实际落地过程中,GPU 选型仍需结合模型规模、业务负载、功耗条件与交付周期综合评估。