博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
以Python作为核心开发语言,基于Django框架搭建系统整体架构,结合Echarts可视化库实现数据可视化展示效果,采用MySQL数据库存储各类业务数据,辅以HTML完成前端页面的搭建与呈现。
功能模块
- 电影数据可视化分析
- 电影票房数据可视化分析
- 票房预测可视化分析
- 电影数据
- 个人信息
- 用户数据管理
- 首页
- 注册登录
项目介绍
本项目围绕基于Python的电影市场预测分析系统展开设计与开发,依托真实的电影市场数据,借助Python技术完成电影市场各类信息的预测分析工作。系统选用MySQL数据库存储数据,兼顾使用成本与操作便捷性,基于Django框架搭建整体架构,通过Echarts将票房、场次等核心电影数据以可视化形式呈现。该系统可清晰展现电影市场行情及各类关键指标,把原始电影数据转化为有价值的参考信息,为了解电影市场动态、开展市场预测分析提供了有力的数据支撑。
2、项目界面
(1)电影数据可视化分析
左侧设导航栏含首页、票房分析等入口,页面主体通过柱状图、饼图展示影片的票房、场次、人次、上座率等数据,支持查看不同维度的影片数据分布与占比,实现电影多维度数据的可视化统计与直观展示。
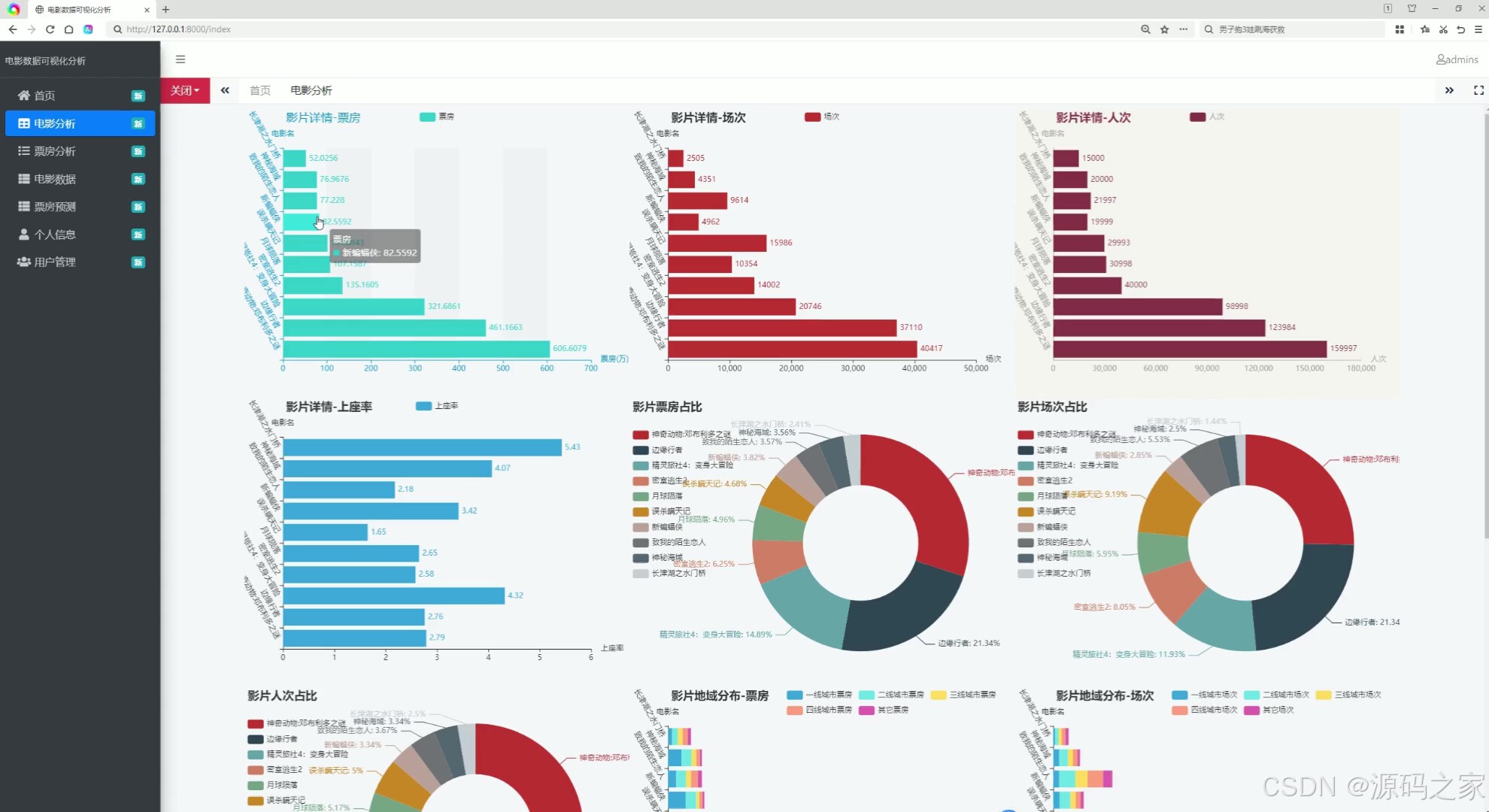
(2)电影票房数据可视化分析
左侧设含首页、电影分析等入口的导航栏,页面主体通过柱状图展示票房相关统计、词云图呈现片名信息、饼图展示电影分类占比,还包含不同维度的票房数据图表,实现票房、影片类型等数据的多形式可视化统计与直观展示。
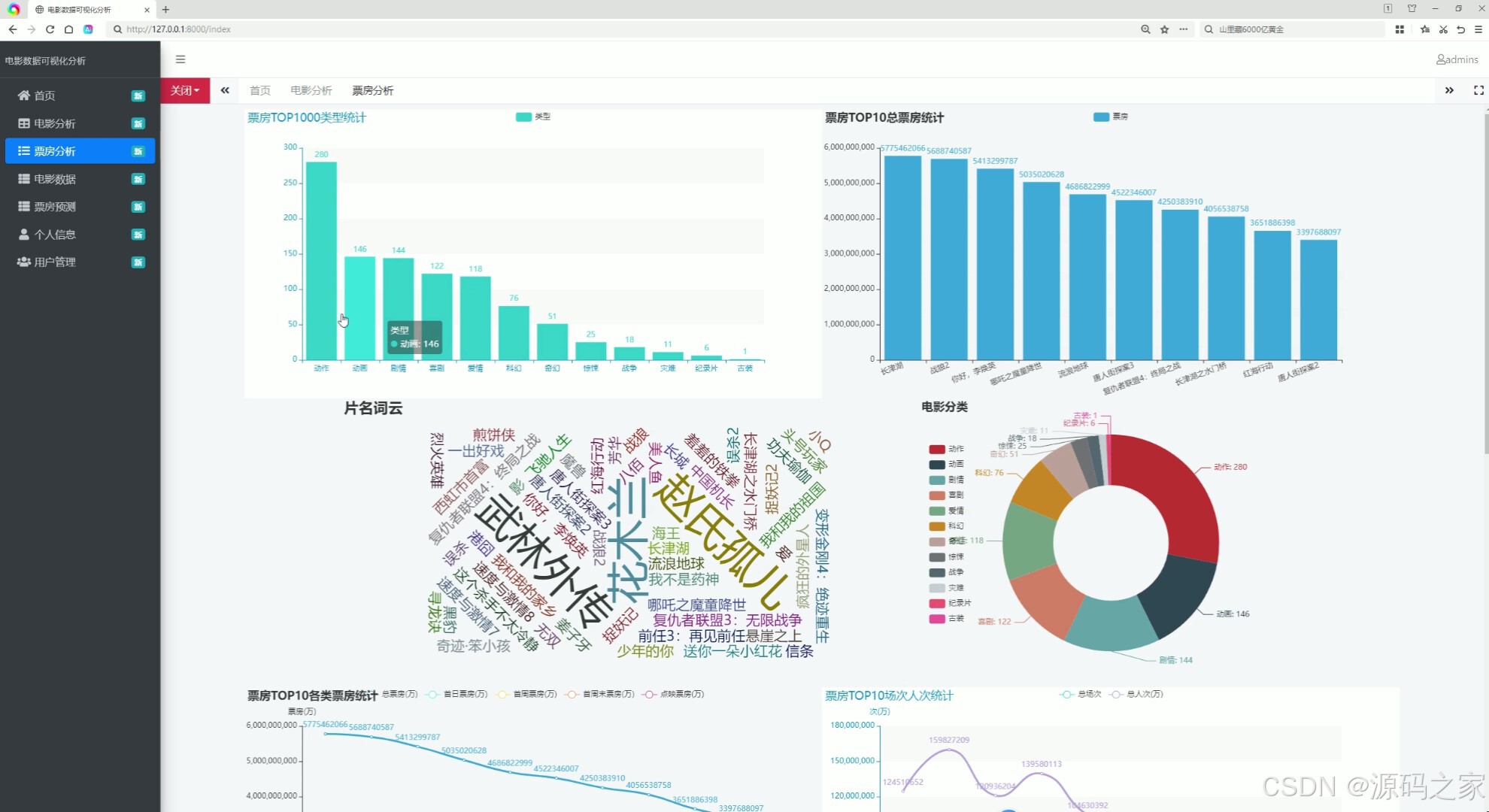
(3)票房预测可视化分析
左侧设含首页、电影分析等入口的导航栏,页面主体通过柱状图展示票房预测分析数据,可直观查看不同项目对应的预测票房情况,实现票房预测数据的可视化呈现与统计展示。
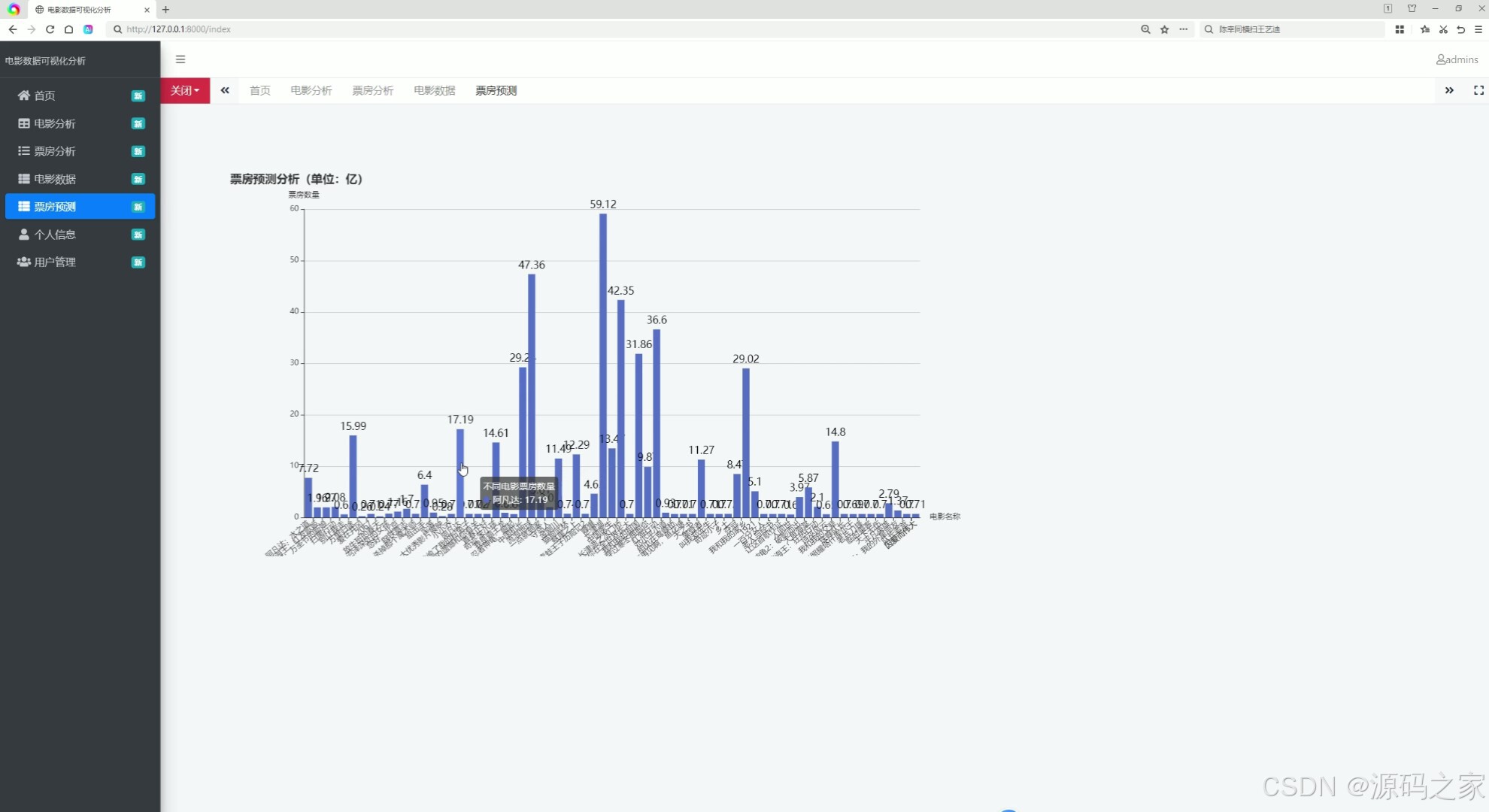
(4)电影数据
左侧设含首页、电影分析等入口的导航栏,页面主体以列表形式展示电影的排名、名称、票房、上映时间等多类信息,同时支持分页导航与每页条数选择,实现电影数据的集中展示、查阅与分页管理。
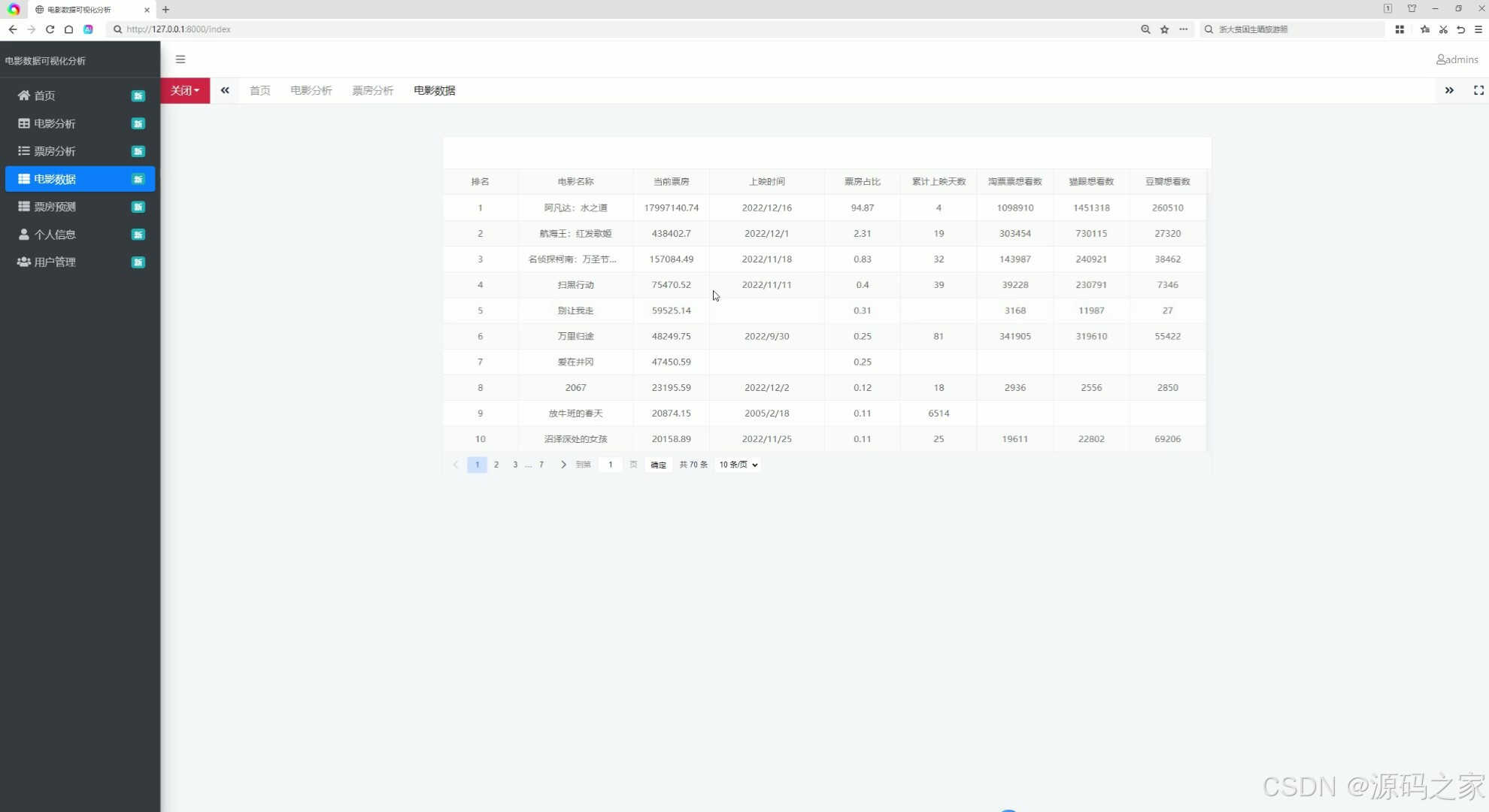
(5)个人信息
左侧设含首页、电影分析等入口的导航栏,页面主体以列表形式展示当前用户的 ID、姓名、联系方式、账号状态等个人信息,实现用户自身账号相关信息的集中查看功能。
(6)用户数据管理
左侧设含首页、电影分析等入口的导航栏,页面主体有搜索框可查询用户,以列表展示用户的 ID、姓名等信息,同时支持新增用户,以及对现有用户进行修改、删除操作,还配备分页功能,实现用户信息的管理、查询与操作处理。
(7)首页
左侧设包含电影分析、票房预测等功能入口的导航栏,页面主体展示欢迎提示与可视化背景,作为系统的入口页面,可引导用户通过左侧导航栏进入各功能模块,实现系统功能的快速访问与跳转。
(8)注册登录
页面展示用户登录表单,包含用户名、密码输入框与登录按钮,支持用户输入账号信息并提交登录操作,实现系统的身份验证与权限准入功能,是进入系统各模块的前置验证入口。
3、项目说明
一、技术栈
本项目以Python为核心开发语言,基于Django框架搭建系统整体架构,结合Echarts可视化库实现数据可视化展示效果,采用MySQL数据库存储各类业务数据,辅以HTML完成前端页面的搭建与呈现。
二、功能模块详细介绍
- 电影数据可视化分析:左侧设导航栏含首页、票房分析等入口,主体通过柱状图、饼图展示影片票房、场次等数据,支持查看不同维度数据分布与占比,实现多维度数据可视化统计。
- 电影票房数据可视化分析:左侧有含首页、电影分析等入口的导航栏,主体通过柱状图、词云图、饼图等形式展示票房、片名、电影分类等数据,实现票房相关数据多形式可视化统计。
- 票房预测可视化分析:左侧配备含首页、电影分析等入口的导航栏,主体以柱状图展示票房预测分析数据,直观呈现不同项目的预测票房情况,实现预测数据可视化展示。
- 电影数据:左侧设含首页、电影分析等入口的导航栏,主体以列表展示电影排名、名称、票房等信息,支持分页导航与条数选择,实现电影数据集中展示与分页管理。
- 个人信息:左侧有含首页、电影分析等入口的导航栏,主体以列表展示用户ID、姓名、联系方式等信息,实现用户个人账号信息的集中查看。
- 用户数据管理:左侧配备含首页、电影分析等入口的导航栏,主体有搜索框可查询用户,列表展示用户信息,支持新增、修改、删除用户及分页操作,实现用户信息管理。
- 首页:左侧设包含电影分析、票房预测等入口的导航栏,主体展示欢迎提示与可视化背景,作为系统入口,引导用户快速访问各功能模块。
- 注册登录:页面展示登录表单,含用户名、密码输入框与登录按钮,支持账号信息提交登录,完成身份验证,是进入系统的前置验证入口。
三、项目总结
本项目围绕基于Python的电影市场预测分析系统开展设计与开发,依托真实的电影市场数据,借助Python技术完成市场各类信息的预测分析。系统选用MySQL数据库存储数据,兼顾使用成本与操作便捷性,基于Django框架搭建架构,通过Echarts将票房、场次等核心数据以可视化形式呈现。该系统能清晰展现电影市场行情及关键指标,将原始数据转化为有价值的参考信息,为了解市场动态、开展预测分析提供了有力的数据支撑。
4、核心代码
python
import datetime
from django.http import HttpResponseRedirect, HttpResponse, HttpResponseForbidden, JsonResponse
from django.shortcuts import render
from user.models import User
import os
import csv
work_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
def login(req):
"""
跳转登录
:param req:
:return:
"""
return render(req, 'login.html')
def register(req):
"""
跳转注册
:param req:
:return:
"""
return render(req, 'register.html')
def index(req):
"""
跳转首页
:param req:
:return:
"""
username = req.session['username']
total_user = len(User.objects.all())
date = datetime.datetime.today()
month = date.month
year = date.year
return render(req, 'index.html', locals())
def index2(req):
"""
跳转首页
:param req:
:return:
"""
username = req.session['username']
total_user = len(User.objects.all())
date = datetime.datetime.today()
month = date.month
year = date.year
return render(req, 'welcome_index.html', locals())
def login_out(req):
"""
注销登录
:param req:
:return:
"""
del req.session['username']
return HttpResponseRedirect('http://127.0.0.1:8000/')
def personal(req):
username = req.session['username']
role_id = req.session['role']
user = User.objects.filter(name=username).first()
return render(req, 'personal.html', locals())
def zydy(request):
username = request.session['username']
return render(request, 'zydyfx.html', locals())
def pffx(request):
username = request.session['username']
return render(request, 'pffx.html', locals())
def dysj(request):
username = request.session['username']
return render(request, 'dysj.html', locals())
def get_data(request):
keyword = request.GET.get('name')
page = int(request.GET.get("page", ''))
limit = request.GET.get("limit", '')
response_data = {}
response_data['code'] = 0
response_data['msg'] = ''
data = []
with open(os.path.join(work_dir, 'movie/data/recentlyMovies.csv'), 'r') as csv_file:
csv_reader = csv.reader(csv_file)
for arrTxt in csv_reader:
dict_values = {
'id':arrTxt[0],
'name':arrTxt[1],
'pf':arrTxt[2],
'sj':arrTxt[3],
'dqcc':arrTxt[4],
'dqrc':arrTxt[5],
'pfzb':arrTxt[7],
'ljsyts':arrTxt[8],
'tpp':arrTxt[10],
'my':arrTxt[11],
'db':arrTxt[12],
}
data.append(dict_values)
if page == 1:
results = data[1:11]
elif page == 2:
results = data[11:21]
elif page == 3:
results = data[21:31]
elif page == 4:
results = data[31:41]
elif page == 5:
results = data[41:51]
elif page == 6:
results = data[51:61]
elif page == 7:
results = data[61:71]
response_data['count'] = len(data)
response_data['data'] = results
return JsonResponse(response_data)
def update_data(request):
from movie.getData import recently
recently()
return JsonResponse({'msg':'ok'})
def pfyc(request):
data =[]
value = []
with open(os.path.join(work_dir, 'movie/data/predict_result.csv'), 'r') as csv_file:
csv_reader = csv.reader(csv_file)
for arrTxt in csv_reader:
data.append(arrTxt[0])
value.append(arrTxt[1])
data = data[1:]
value=value[1:]
print(data)
print(value)
return render(request,'pfyc.html',locals())5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻