Simple-BEV论文概述
研究动机:BEV研究是否走偏
近几年,BEV感知发展迅速,发展趋势非常明显:lifting方法越来越复杂。
depth -> MLP -> attention -> deformable transformer同时:backbone/分辨率/batch size/训练策略都在变化。所以到底是lifting方法变强了还是训练方案变强了?这就是本文所要讨论的。
核心思想:重新做一次公平实验
作者构建了一个统一框架,只改变一个变量,其他全部固定,下面是文章中分析的变量:
1. backbone
2. 分辨率
3. batch size
4. augmentations
5. loss
6. 优化器这样可以真正衡量lifting改进对模型性能的贡献。
模型结构
-
整体pipeline:
多相机 RGB ↓ 2D ResNet-101 ↓ Lift 到 3D voxel ↓ 压缩 Y 维 → BEV ↓ BEV ResNet-18 ↓ Segmentation + offset + centerness -
BEV空间设置:
- 100m*100m
- 分辨率200*200
- 垂直方向8层
- voxel尺度:
- 0.5m*1.25m*0.5m
最关键:Lifting机制
- parameter-free lifting
流程:
a. 定义3d voxel坐标
b. 投影到每个相机
c. 在2d feature map上bilinear sample
d. 多相机取valid-weighted average 没有depth/MLP/attention/transforner。
- 与Lift-Splat区别
- Lift-Splat:每个2d pixel沿ray向3d "splat",对应下面的左图
- Sample-BEV:每个3d voxel去2d "pull", 对应下面的右图
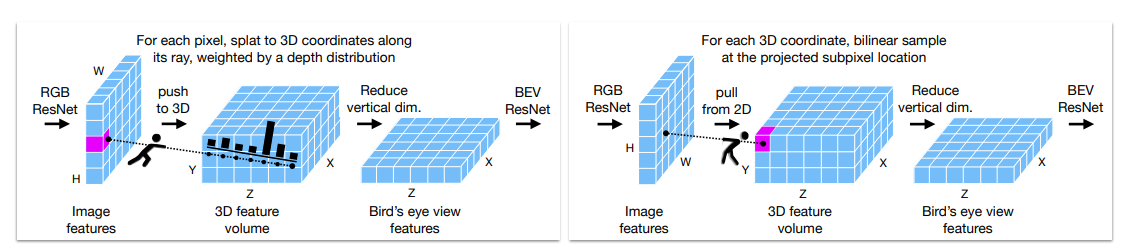
区别:
| 距离 | splat | sampling |
|---|---|---|
| 近距离 | 更好 | 略差 |
| 远距离 | 稀疏 | 更稳定 |
总体sampling略优。
控制变量实验
- Lifting策略对比
| 方法 | IOU |
|---|---|
| unweighted splat | 43.1 |
| depth splat | 44.4 |
| deformable attn | 46.5 |
| bilinear sampling | 47.4 |
| multi-scale attn | 48.9 |
最差和最好的结果只相差4个点。
- 输入分辨率
从112*208增大到672*1200,IOU大幅增长。关键点:
- 低于448*800性能明显下降
- 最高分辨率反而下降(预训练mismatch)
最佳分辨率:672*1200。分辨率提升可以带来5-8个点提升。远大于lifting差异。
- batch size
最震撼的实验结果:
| batch | IOU |
|---|---|
| 2 | 33 |
| 8 | 40 |
| 16 | 44 |
| 40 | 47+ |
随着batch增大,IOU提升了14个点,增大batch效果十分明显。
- backbone
| backbone | IOU |
|---|---|
| EfficientNet-B0 | 43.7 |
| EfficientNet-B4 | 46.4 |
| ResNet-50 | 46.6 |
| ResNet-101 | 47.4 |
backbone影响3-4个点。
- augmentation
| 增强 | 提升 |
|---|---|
| random crop | +1.6 |
| random ref camera | +0.6 |
| camera dropout | 反而下降 |
效果不大。
Radar分析
- 模态对比
| 模态 | IOU |
|---|---|
| RGB | 47.4 |
| RGB+Radar | 55.7 |
| RGB+Lidar | 60.8 |
多模态对IOU提升巨大:+8。
- radar使用细节
- 使用meta-data:速度、置信度等,提升+0.7 IOU
- 不做官方filtering:官方过虑,降低2 IOU;过滤会误删真值
- 多帧radar:1 sweep -> 53.1,3 sweep -> 55.7;radar太稀疏,需要时间积累
与SOTA对比
| 方法 | IOU |
|---|---|
| BEVFormer | 44.4 |
| Simple-BEV | 47.4 |
| Simple-BEV + Radar | 55.7 |
Simple-BEV优势:
1. 参数更少
2. 速度更快
3. 训练更稳定总结
本文证明:训练规模 + 多模态信息 >> 复杂 lifting 设计。