
10.3 多模态Transformer
在大模型时代,人形机器人面对的环境不仅包含视觉信息,还可能涉及点云、语音、触觉等多种感知模态。多模态Transformer提供了统一的架构,使来自不同模态的数据能够在同一个模型中进行联合建模、语义对齐和推理,从而支持复杂任务的执行和高层决策。多模态Transformer的核心优势是信息融合能力:它可以学习模态间的交互关系,捕捉各模态的互补信息,使机器人能够在感知、理解和决策中实现更高的准确性和鲁棒性。
10.3.1 跨模态融合的注意力架构
在现代人形机器人系统中,机器人需要同时感知视觉、点云、语音和触觉等多种模态的信息。这些模态提供了环境的不同侧面:视觉捕捉图像和视频信息,点云提供精细的三维几何结构,语音传递语言指令或环境声音,触觉反馈则提供物体表面的力学状态。单独使用某一模态进行感知往往存在局限:视觉容易受遮挡或光照变化影响,点云无法提供颜色或材质信息,语音可能存在噪声或歧义,而触觉只能局部感知交互对象。
因此,需要一种能够统一处理多模态信息的融合机制,使不同模态能够互相补充信息,实现跨模态的语义对齐和综合理解。这种融合不仅可以提高机器人对环境的感知准确性,还能够让机器人根据语言指令直接定位目标、理解空间关系并制定操作策略。本小节介绍的跨模态注意力架构,正是为实现这一目标而设计的统一建模方法。
- 模态特征编码
在多模态系统中,不同类型的数据在结构、维度和信息量上存在差异。例如,图像是二维矩阵数据,每个像素包含颜色信息;点云是稀疏的三维坐标集合,记录空间结构;语音是连续的时间序列信号,反映语言或环境音;触觉数据可能是压力或力矩的向量序列。这些模态的特征维度和表示方式完全不同,如果直接输入融合模块,模型难以有效处理。
因此,需要为每种模态设计专门的编码器,将原始数据映射为统一高维向量表示,既保留模态特有的信息,又便于跨模态交互。
模态特征编码的公式表示为:
F I = f I ( Image*),* F P = f P ( PointCloud*),* F A = f A ( Audio*)* 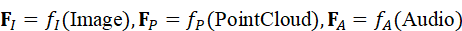
其中,F I ∈ RN I×d 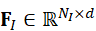 、F P ∈ RN P×d
、F P ∈ RN P×d 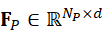 、F A ∈ RN A×d
、F A ∈ RN A×d 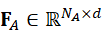 ,N I , N P , NA
,N I , N P , NA 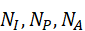 是每种模态token数量,d
是每种模态token数量,d 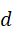 是统一特征维度。这一步确保了不同模态可以在同一空间内进行语义比较和交互,为后续融合打下基础。
是统一特征维度。这一步确保了不同模态可以在同一空间内进行语义比较和交互,为后续融合打下基础。
- 跨模态注意力交互
在机器人任务中,各模态之间往往存在互补关系。例如,视觉可以识别目标颜色和纹理,但无法提供深度信息;点云能够准确描述物体形状和位置,但缺乏语义标签;语音指令提供任务目标,但可能不包含精确空间信息。为了充分利用这些互补信息,需要让不同模态之间能够相互"交流",动态调整特征表示,使每个模态在理解环境时不仅依赖自身信息,还参考其他模态的上下文。
跨模态注意力机制实现了这种信息交互。设查询、键、值分别为Q,K,V 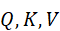 ,计算不同模态间的相关性:
,计算不同模态间的相关性:
Attention*(Q,K,V)=* softmaxQ K ⊤dV 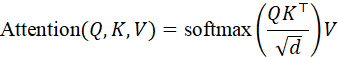
例如,将图像token作为查询,点云token作为键和值,可以让视觉表示参考三维几何结构进行调整,确保机器人在执行抓取或导航任务时能够准确定位目标。
- 多头注意力与子空间分解
在复杂环境中,单一注意力计算可能难以捕捉多模态间的多层次关系。例如,语音指令可能包含动作意图、对象属性和空间约束,而视觉和点云提供几何和纹理信息。为了同时捕捉多层语义和空间关系,需要将注意力机制扩展为多头形式,每个头在不同子空间独立学习特征依赖,从而提高整体表达能力。
多头注意力公式为:
MultiHead*(Q,K,V)=* Concat*(* head1 ,..., headh ) WO 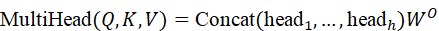
headi = Attention*(Q* W i Q ,K W i K ,V W i V) 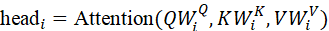
多头机制使机器人能够在多个语义维度上理解模态间关系,例如同时考虑目标位置、可抓取性和空间约束,从而为任务规划提供丰富信息。
- 序列建模与时序融合
机器人操作通常是动态过程,环境和目标会随时间变化。例如,在抓取移动物体或导航复杂场景时,机器人需要连续感知多模态信息,并结合历史观测进行判断。单帧融合无法捕捉这些时序依赖,因此需要对高层多模态特征进行序列建模。
设时间序列特征为 F 1:T =* **F** *1* *,...,* **F** *T 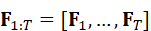 ,通过注意力交互模块可以捕捉跨模态和跨时间步的依赖关系:
,通过注意力交互模块可以捕捉跨模态和跨时间步的依赖关系:
H t = CrossModalEncoder*(* F 1:T) 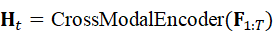
编码后的高维表示H t 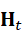 综合了历史观测、空间结构和语义信息,为机器人动作决策提供丰富输入。
综合了历史观测、空间结构和语义信息,为机器人动作决策提供丰富输入。
- 下游任务接口
融合后的多模态表示不仅是感知结果,还直接支撑机器人下游模块的决策。例如抓取任务需要结合目标位置、物体材质和力学约束;导航任务需要同时考虑障碍物、路径可达性和任务优先级;交互任务需要结合语言意图和触觉反馈。通过多模态注意力网络生成的高维表示,可以直接输入策略网络或规划模块,实现感知到动作的闭环衔接。
a t =π( H t) 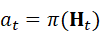
其中,π(⋅) 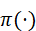 可以为深度策略网络、优化规划算法或强化学习策略,使机器人能够在复杂场景中高效执行任务。
可以为深度策略网络、优化规划算法或强化学习策略,使机器人能够在复杂场景中高效执行任务。
- 技术优势与工程考虑
跨模态注意力架构相比传统规则或优化方法,在处理多源、动态、高维信息时具有明显优势,但同时也带来工程挑战。理解这些优势和限制,有助于在实际系统中合理设计和优化多模态融合模块。
(1)优势:
- 能捕捉模态间非线性依赖和长时序关系;
- 统一高维表示易于扩展新模态或任务;
- 支持端到端训练,提高策略适应性和鲁棒性。
(2)工程挑战:
- 高维输入和长序列对内存与实时性要求高;
- 计算复杂度大,需要剪枝、蒸馏或量化优化;
- 训练依赖大规模多模态数据,同时需考虑模态缺失和噪声鲁棒性。
总而言之,跨模态注意力架构提供了一种统一的高维表示方法,使机器人能够在复杂动态环境中实现语义理解、空间感知和任务决策的闭环衔接。通过模态特征编码、注意力交互、多头分解和序列建模,机器人能够将多感知信息转化为可执行策略,实现语言驱动的目标定位、空间推理和操作规划。
10.3.2 图像、点云和语音的联合建模
在现代人形机器人系统中,单一模态信息往往难以满足复杂任务的需求。视觉提供丰富的纹理和颜色信息,但在深度和空间关系理解上存在局限;点云捕捉三维几何结构,但缺乏语义信息;语音传递指令和任务目标,但无法提供环境空间感知。仅依靠单模态建模可能导致目标定位不精确、任务执行失败或环境理解不完整。
为了实现机器人在动态环境下的高层语义理解和精确操作,需要将图像、点云和语音的多模态特征进行联合建模,使不同模态信息互相补充和校正,形成统一的环境表示。这种联合建模不仅可以增强语义对齐能力,还能够将语言意图直接映射到视觉和空间信息,实现语言驱动的操作决策。
- 多模态特征准备
每种模态数据结构和信息内容不同,因此首先需要对其进行特征提取和标准化处理,使其能够在同一空间中进行联合建模。
(1)图像特征:通常通过卷积网络或视觉编码器提取局部 patch 或全局图像向量,得到视觉token序列:
Z I = f I ( Image*)∈* RN I×d 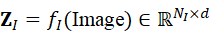
(2)点云特征:利用PointNet、Point Transformer 或体素化方法,将三维点云划分为局部区域,并提取几何和拓扑信息:
Z P = f P ( PointCloud*)∈* RN P×d 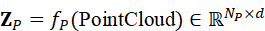
(3)语音特征:语音指令或环境声音经过时序特征编码(如 MFCC 或音频编码器),得到语言token序列:
Z A = f A ( Audio*)∈* RN A×d 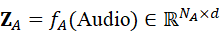
通过这种方式,三种模态的数据被映射到统一维度d 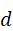 的向量空间,为跨模态交互提供基础。
的向量空间,为跨模态交互提供基础。
- 跨模态信息交互
机器人执行任务时,各模态信息往往是互补的。例如:视觉提供目标物体的外观信息,点云提供空间位置,语音提供任务意图。为了让机器人同时理解目标的属性和位置,需要让这些模态的特征在高维空间中进行交互与对齐。
设查询、键、值分别为Q,K,V 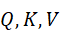 ,跨模态注意力机制计算为:
,跨模态注意力机制计算为:
Attention*(Q,K,V)=* softmaxQ K ⊤dV 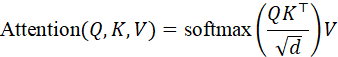
在实际应用中,可以让图像token作为查询,点云和语音 token 作为键和值,从而视觉特征根据空间几何和语言指令进行动态调整,实现信息互补。例如,机器人接收到"抓左侧桌子上的红色杯子"指令时,视觉token会通过语言token指定颜色和位置,通过点云token确定三维坐标,实现精确定位。
- 联合表示生成
在多模态交互之后,需要生成一个统一的联合表示,用于下游任务如目标识别、抓取规划或导航决策。联合表示能够整合视觉、几何和语言信息,使机器人对环境形成完整、可推理的认知模型。
联合表示公式为:
Z joint*=* Fusion*(* **Z** *I* *;* **Z** *P* *;* **Z** *A)* 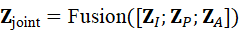
这里的Fusion可以是加权求和、跨模态注意力或者图神经网络操作,目的是将各模态的互补信息融合为一致的高维表示。机器人通过Z joint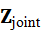 可以同时理解目标属性、空间位置和任务意图。
可以同时理解目标属性、空间位置和任务意图。
- 时序与动态建模
环境是动态变化的,机器人需要随时间连续感知和决策。例如,在抓取移动物体或避开行人时,单帧联合表示不足以捕捉运动和状态变化。因此,需要对联合表示形成时间序列:
Z 1:T joint*=* **Z** joint*,1* *,...,* **Z** joint*,T* 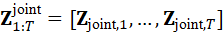
通过对时间序列建模,机器人能够结合历史信息预测目标运动、环境变化和任务执行状态,为动态决策提供基础。
- 下游任务应用
联合表示不仅是感知结果,还直接用于支持机器人动作策略和任务执行。例如:
- 抓取任务:结合颜色、形状和三维坐标选择抓取对象;
- 导航任务:融合几何约束和语言指令规划路径;
- 交互任务:将语言意图映射到可操作对象和动作序列。
下游动作生成可表示为:
a t =π( Z joint*,t)* 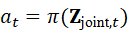
其中,π(⋅) 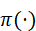 可以是深度策略网络、规划算法或强化学习策略,实现语言驱动的"感知---理解---动作"闭环。
可以是深度策略网络、规划算法或强化学习策略,实现语言驱动的"感知---理解---动作"闭环。
- 技术优势与工程注意事项
图像、点云和语音联合建模能够显著增强机器人对环境的理解能力,使机器人在复杂场景中更智能、更鲁棒,但同时也带来一定工程挑战。
(1)优势:
- 融合多模态信息,实现语义、空间和任务意图的统一理解;
- 支持复杂任务的动态执行,如抓取移动物体或导航动态环境;
- 联合表示可直接用于下游策略,实现感知到动作的闭环。
(2)工程挑战:
- 多模态数据维度大,计算和内存开销高;
- 时序联合建模需要保持实时性;
- 不同模态存在噪声和缺失,融合策略需具备鲁棒性。
总而言之,图像、点云和语音的联合建模是机器人多感知系统的核心能力。通过特征编码、跨模态信息交互、联合表示生成和时序建模,机器人能够同时理解环境、目标和任务意图,为动作决策提供统一、高维、可推理的输入。联合建模不仅增强了感知的完整性和鲁棒性,也为语言驱动的操作和导航任务提供了基础支撑,使机器人能够在动态复杂场景中高效执行任务。
10.3.3 Tokenization策略
在多模态机器人感知系统中,不同模态的数据具有不同的结构和特性。直接将原始图像、点云或触觉信号输入融合模块往往会导致信息冗余、计算复杂或难以捕捉关键语义。因此,将原始数据切分、编码成离散化的Token成为高效处理多模态信息的关键步骤。Token不仅可以统一不同模态的表示形式,还可以在后续注意力交互、联合建模和任务执行中进行灵活操作,从而提高机器人系统的感知效率与任务适应性。
Token化策略不仅是数据预处理手段,更是跨模态特征统一、信息选择和语义对齐的基础。合理的 Token 化可以保留关键语义信息,同时降低计算复杂度,为机器人在动态环境中执行任务提供可靠的输入。
- 视觉Token化
图像包含大量像素信息,但并非每个像素对任务都有意义。例如,在抓取任务中,背景像素对动作决策贡献有限,而目标物体区域是关键。为了高效处理视觉信息,需要将图像切分成局部 patch,并提取每个 patch 的高维特征作为视觉token。
视觉Token化的实现方式如下:
- 将图像I∈ RH×W×C
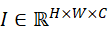 按固定尺寸 P×P
按固定尺寸 P×P 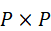 切分为N I = HW P2
切分为N I = HW P2 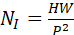 个patch;
个patch; - 对每个patch使用卷积网络或线性投影提取特征向量v i ∈ Rd
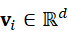 ;
; - 形成视觉token序列:
Z I =* **v** *1* *,* **v** *2* *,...,* **v** *N* *I* *∈ RN I×d 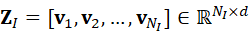
这种token化不仅降低了输入维度,也便于在跨模态注意力机制中与点云或语音token对齐,实现了语言驱动的视觉目标聚焦。
- 点云Token化
点云数据稀疏且三维结构复杂,直接处理全部点会导致计算开销过大,同时容易受到噪声影响。通过token化,可以将点云划分为局部区域(如体素、球形邻域或关键点),提取每个区域的几何特征作为点云token,使机器人能够高效理解三维空间结构。
点云Token化的实现方式如下:
- 将点云P={ p i } i=1M
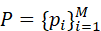 进行分组,形成NP
进行分组,形成NP 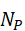 个局部区域;
个局部区域; - 对每个局部区域提取特征p j ∈ Rd
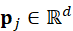 ,包括位置、法向量、几何描述子等;
,包括位置、法向量、几何描述子等; - 形成点云token序列:
Z P =* **p** *1* *,* **p** *2* *,...,* **p** *N* *P* *∈ RN P×d 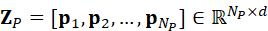
这种token化方法使机器人可以关注三维环境中的关键区域,例如可抓取物体、障碍物或可通行区域,提高空间理解和操作决策效率。
- 触觉Token化
触觉信号包括压力、力矩和接触点信息,通常为连续高维序列。在机器人操作任务中,触觉数据主要反映物体表面状态、抓取稳定性或接触异常。将触觉数据 token 化能够提取局部关键信息,并与视觉和点云信息联合建模,使机器人在操作中实现感知闭环。
触觉Token化的实现方式如下:
- 将触觉传感器读数按时间或空间切分为局部片段;
- 对每个片段提取特征向量 t k ∈ Rd
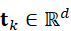 ,包括压力值、力矩、滑动状态等;
,包括压力值、力矩、滑动状态等; - 形成触觉token序列:
Z T =* **t** *1* *,* **t** *2* *,...,* **t** *N* *T* *∈ RN T×d 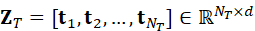
这种token化策略使机器人能够在抓取或操作过程中快速判断物体是否可抓、是否稳定,并结合视觉和点云信息调整操作策略。
- 联合多模态Token表示
在机器人系统中,各模态token经过独立编码和token化后,需要形成统一的多模态表示,以便后续交互和任务决策。统一token表示能够保持各模态特征独立性,同时支持跨模态注意力、信息选择和语义对齐。
联合token表示可以表示为:
Z multi*=* **Z** *I* *;* **Z** *P* *;* **Z** *T* *∈* R*(* N I + N P + N T)×d 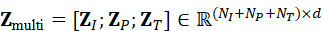
机器人可以利用该序列进行跨模态信息交互,完成目标定位、操作规划和动态调整。
-
应用场景
-
抓取任务:视觉token提供目标物体信息,点云token提供空间位置,触觉token提供抓取反馈,联合token支持闭环抓取策略。
-
导航任务:视觉token提供场景纹理信息,点云token提供障碍物几何信息,联合token支持路径规划和避障决策。
-
交互任务:语音指令可以通过token化融入联合表示,与视觉和触觉token对齐,实现任务意图落地。
总之,Tokenization策略是多模态机器人系统感知的关键步骤。通过将视觉、点云和触觉数据切分为离散token,机器人可以高效表示环境信息,支持跨模态融合和语义对齐。联合token表示不仅降低计算复杂度,还为任务驱动的闭环决策提供可靠输入,使机器人在抓取、导航和交互等任务中实现高效、准确、鲁棒的操作。