这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
作者正在学习斯坦福大学的CS224N课程。此文章的图片均来自该课程视频,之后会继续更新斯坦福大学CS224N课程,以及加上补充的知识,让我们一起探讨 NLP 的世界!!
第一节:机器翻译的历史黎明与早期规则建模的局限
机器翻译作为自然语言处理(NLP)领域最古老且最具挑战性的课题之一,其构想几乎与现代计算机的诞生同步。早在 20 世纪 50 年代,研究人员就开始尝试让机器理解并转换人类语言。
1. 1950s:冷战背景下的技术萌芽
机器翻译的起步受到了冷战时期情报处理需求的强烈推动。1954 年著名的"乔治敦实验"(Georgetown-IBM experiment)首次向公众展示了计算机自动将俄语翻译成英语的能力。然而,当时执行这些任务的机器性能甚至不如今天的智能手机,甚至低于 90 年代的高中科学计算器。
在那个"人工智能"术语尚未正式提出的年代,MT 的研究与自动机理论(Automata)、形式语言(Formal Languages)以及刚刚兴起的信息论(Information Theory)是高度并发发展的。

2. 早期范式:基于规则的简单词汇替换
早期的 MT 系统主要依赖于军事资助,其核心逻辑非常朴素:基于规则的词对词替换(Word Substitution)。 这种系统的逻辑是建立一个详尽的电子词典,并编写大量的语言学规则来处理词序调整。这种方法虽然在特定、受限的语料库上表现尚可,但在处理真实世界的自然语言时很快便撞上了南墙。
3. 自然语言的复杂性瓶颈
语言学家很快发现,人类语言并非简单的符号排列,其复杂性远超早期的数学模型。主要挑战集中在以下三个维度:
-
句法(Syntax): 不同语言的句子结构差异巨大(例如主谓宾顺序的变换)。
-
语义(Semantics): 词汇在不同语境下具有歧义性(Polysemy)。
-
语用(Pragmatics): 语言背后的社会背景和说话人的意图难以通过硬编码规则捕捉。
由于缺乏对语言深度结构的理解,研究者们在 60 年代中期意识到,翻译问题在当时的计算能力和理论框架下几乎是不可计算的(Intractable)。这导致了 MT 研究进入了长达数十年的低谷期,直到 90 年代统计方法的出现才真正打破僵局。
第二节:经典范式:统计机器翻译 (SMT) 的概率分解
与早期试图通过硬编码语法规则不同,统计机器翻译的核心逻辑是:"让机器从数据中学习概率模型"。如果我们想将法语源句 x翻译成目标英语句子 y,SMT 的目标就是找到那个使条件概率 P(y|x) 最大化的句子 y:
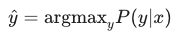
1. 贝叶斯法则与双重约束
为了更好地建模,研究者利用**贝叶斯法则(Bayes Rule)**对上述公式进行了拆解:
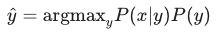
这一拆解极具天才之处,它将翻译任务分解成了两个独立学习的组件,分别应对翻译中最重要的两个维度:忠实度 与流利度。

-
翻译模型 P(x|y) (Translation Model): 负责建模忠实度(Fidelity)。它通过对大规模平行语料(Parallel Data)的学习,计算源词/短语与目标词/短语之间的对应概率。它告诉机器:"这个词在这种情况下通常应该被翻译成那个词"。
-
语言模型 P(y) (Language Model): 负责建模流利度(Fluency)。它仅通过大规模的目标语言单语语料(Monolingual Data)进行学习。它的作用是确保输出的句子听起来像地道的英语,而不是生硬的词汇堆砌。
2. 翻译建模的非平凡性(Non-trivial Modeling)
尽管概率框架很完美,但实际建模过程极其复杂。语言之间的转换并非简单的线性对应,而是涉及复杂的**对齐(Alignment)**问题。

如图片所示,德语到英语的翻译中,词序往往会发生剧烈的交叉和重新排列(Reordering)。例如:
-
词对多/多对一: 一个词可能对应多个词,或者多个词合并为一个词。
-
语序调优: 动词位置的改变或修饰语的位移。
这种复杂的对齐逻辑需要建立极其庞大的特征工程,且往往需要手工设计大量的辅助规则。
3. SMT 的局限性与"特征疲劳"
虽然 SMT 在 2000 年代取得了巨大成功(早期的 Google Translate 便是基于此技术),但它也逐渐暴露出了瓶颈:
-
过度依赖特征工程: 系统由成百上千个独立的模块组成,需要大量语言专家进行维护。
-
长距离依赖难题: 由于模型通常基于 n-gram 或局部短语,很难处理句子两端跨度较大的语义关联。
-
缺乏端到端优化: 每个组件(翻译模型、语言模型、重排序模型)都是独立训练的,无法实现整体性能的最优化。
正是这些痛点,促使研究者们开始思考:是否可以用一个统一的、深层的神经网络来完成所有的工作?
第三节:范式转移:神经机器翻译 (NMT) 的崛起
2014 年前后,研究界开始探索一种全新的路径:不再将翻译视为多个独立概率组件的堆砌,而是将其视为一个端到端的映射问题。这就是神经机器翻译(NMT)。
1. 什么是神经机器翻译?
不同于 SMT 需要分别训练翻译模型、语言模型和重排序模型,NMT 旨在构建一个单一的端到端神经网络(Single end-to-end neural network)。

在这种范式下,网络的输入是源语言序列,输出直接是目标语言序列。这种设计极大地简化了系统流程:
-
特征自动提取: 不再需要人工设计复杂的对齐规则或短语表。
-
联合优化: 整个系统的所有参数都可以通过同一个目标函数进行同步优化。
2. 核心架构:序列到序列模型 (Seq2Seq)
实现 NMT 的主流技术架构被称为 Sequence-to-Sequence (Seq2Seq) 模型。它的直观逻辑非常符合人类的翻译习惯:先"读懂"整句话,再"写出"翻译。

Seq2Seq 架构由两个核心神经网络组成:
-
Encoder (编码器): 负责接收输入序列,并将其转化为一个高维的、包含语义信息的数学表示(Neural Representation)。
-
Decoder (解码器): 负责基于编码器提供的语义表示,逐词生成输出序列。
3. Seq2Seq 的通用性与灵活性
Seq2Seq 架构的魅力在于它的普适性。只要问题的输入和输出都是序列(Sequences),它就能发挥作用。除了机器翻译,它还被广泛应用于:
-
文本摘要: 输入长文章,输出短摘要。
-
对话系统: 输入用户提问,输出机器回答。
-
代码生成: 输入自然语言描述,输出程序代码。
这种灵活性使得 NMT 不仅仅是一个翻译工具,更成为了处理序列预测问题的通用范式。
第四节:基于 RNN 的 Seq2Seq 编码器-解码器架构
Seq2Seq 模型的精髓在于两个循环神经网络(RNN)的耦合。在早期的 NMT 实现中,这种架构通过将源句"压缩"成一个固定维度的向量,再由解码器逐字"还原"来实现翻译。
1. Encoder RNN:源句信息的语义压缩
编码器(Encoder)的任务是处理输入的源句子。它通过 RNN 逐个读入单词(Word Embeddings),并在每一个时间步(Time Step)更新其隐藏状态(Hidden State)。
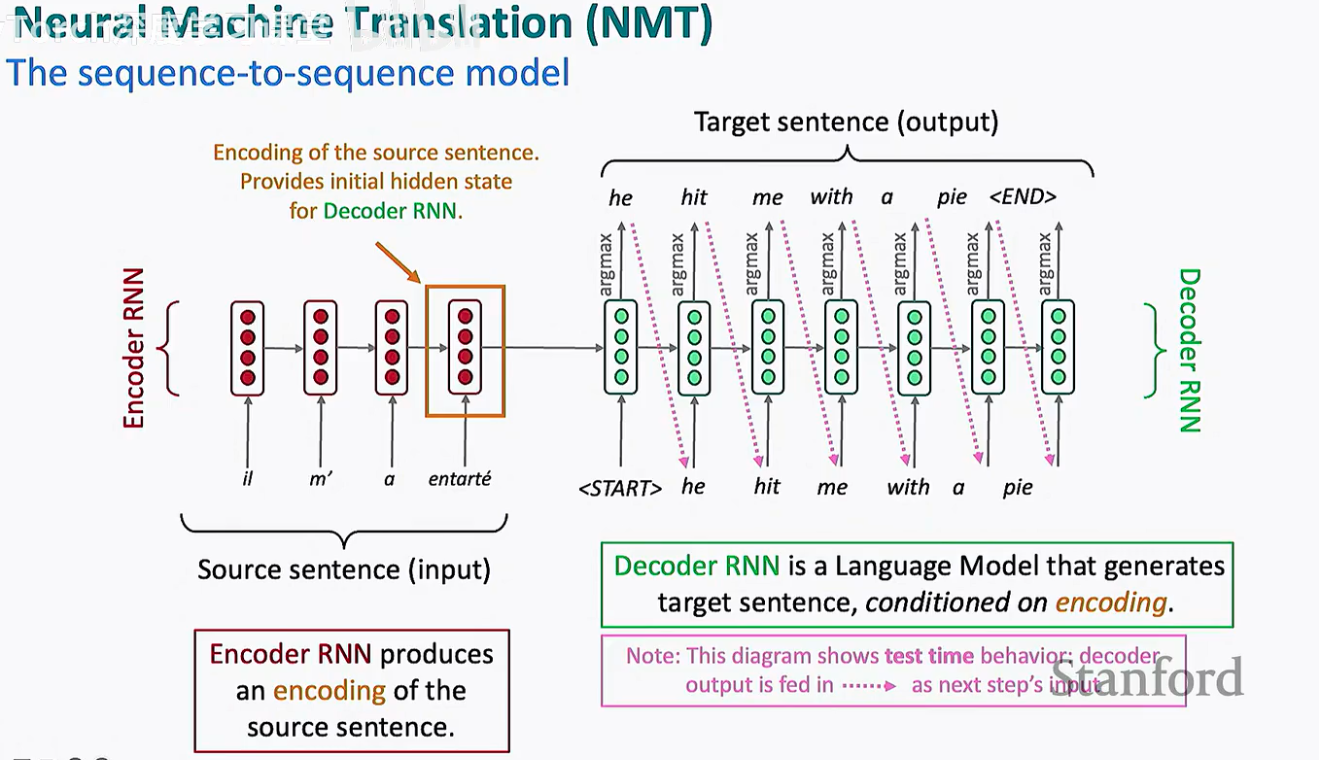
-
信息的传递: 如图所示,编码器的最后一个隐藏状态(图中橙色方框标注的部分)捕捉了整句话的语义信息。
-
编码(Encoding): 这个最终的隐藏状态充当了源句子的"浓缩表示",并作为初始输入传递给解码器。
2. Decoder RNN:作为条件语言模型的生成机制
解码器(Decoder)本质上是一个条件语言模型(Conditional Language Model)。与普通语言模型(LM)预测下一个词不同,它的预测是基于编码器提供的"背景信息"进行的。
-
初始化: 解码器的第一个隐藏状态由编码器的最后一个隐藏状态初始化。
-
逐词生成: 在每个步长,解码器输出一个单词(如 "he"),并将其作为下一个时间步的输入,循环往复直到生成
<END>标志。 -
条件依赖: 每一个生成词的概率都**条件依赖(Conditioned on)**于编码器的隐藏状态以及之前已经生成的词序列。
3. 信息瓶颈:Seq2Seq 的关键挑战
尽管这种架构在 2014 年引起了轰动,但它存在一个显著的物理限制:信息瓶颈(Information Bottleneck)。
编码器必须将变长的源句子(无论是 5 个词还是 50 个词)全部压缩进一个固定维度的向量中。
-
对于长句子,这种"强行压缩"会导致句首信息的丢失。
-
这就像要求翻译员在看完一整篇小说后,只准凭大脑记住的一个点(隐含向量)来复述整篇内容。
技术提示: 这种局限性后来促成了 注意力机制(Attention Mechanism) 的诞生,它允许解码器在生成每个词时,"回头看"编码器中特定的原始单词。
第五节:训练与优化:端到端的联合建模与梯度传播
与统计机器翻译(SMT)需要分别优化翻译模型和语言模型不同,神经机器翻译(NMT)将整个翻译过程视为一个单一的数学函数。
1. 概率分解:NMT 的条件概率建模
NMT 的核心任务是直接计算给定源句子 x 时,目标句子 y 的条件概率 P(y\|x)。利用概率论中的链式法则,我们可以将一个句子的生成概率分解为一系列词步概率的乘积:
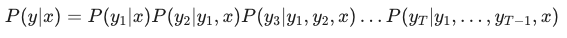

这意味着在每一个时间步,解码器都在根据源句子的编码信息 x 以及已经生成的单词序列 y<t,来预测下一个单词 yt 的概率分布。
2. 损失函数:负对数似然(Negative Log Likelihood)
为了训练这个系统,我们需要一个衡量"翻译质量"的指标。NMT 使用大规模的**平行语料库(Parallel Corpus)**进行监督学习。
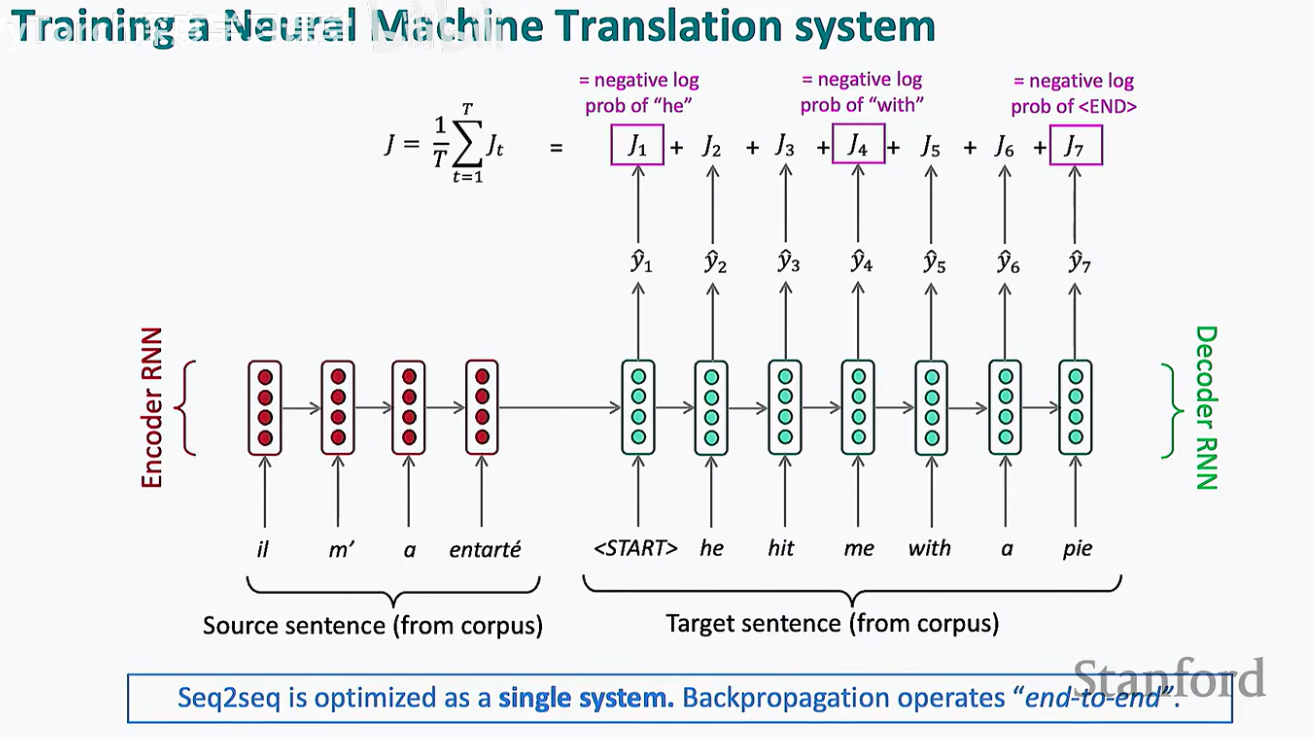
对于语料库中的每一对标准答案(Ground Truth),我们计算模型预测值 ^y 与真实值 y 之间的差异。损失函数 J 通常定义为所有步骤负对数似然的平均值:
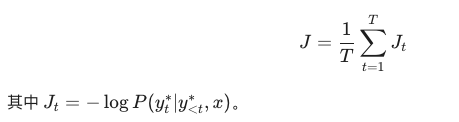
- 直观理解: 训练的目标就是不断调整网络参数,使得模型在看到源句 x 时,产生标准答案 y 的概率达到最大。
3. 反向传播:端到端的单一梯度优化
这是 NMT 相比 SMT 最显著的工程优势:反向传播(Backpropagation)运作于整个"端到端"系统。
-
单一系统优化: 由于整个 Encoder-Decoder 结构是完全可微的,梯度可以从最后的损失函数一直向前传导至编码器的第一层参数。
-
自动化: 不需要像 SMT 那样由数百名工程师花费数年去手动调优成千上万个离散特征。在 NMT 中,一小组工程师只需定义好网络结构,在 GPU 集群上训练数月,模型就能自动"学会"复杂的对齐和翻译逻辑。
这种极高的开发效率和性能上限,直接导致了 2014 年后翻译技术的集体转向。
第六节:技术展望:多层深层结构与全球翻译引擎的更迭
在 2014 年 Seq2Seq 架构横空出世后,研究者们很快意识到,单层 RNN 的表达能力尚不足以处理极度复杂的全球语言。为了进一步提升翻译质量,深层堆叠架构成为了必然的选择。
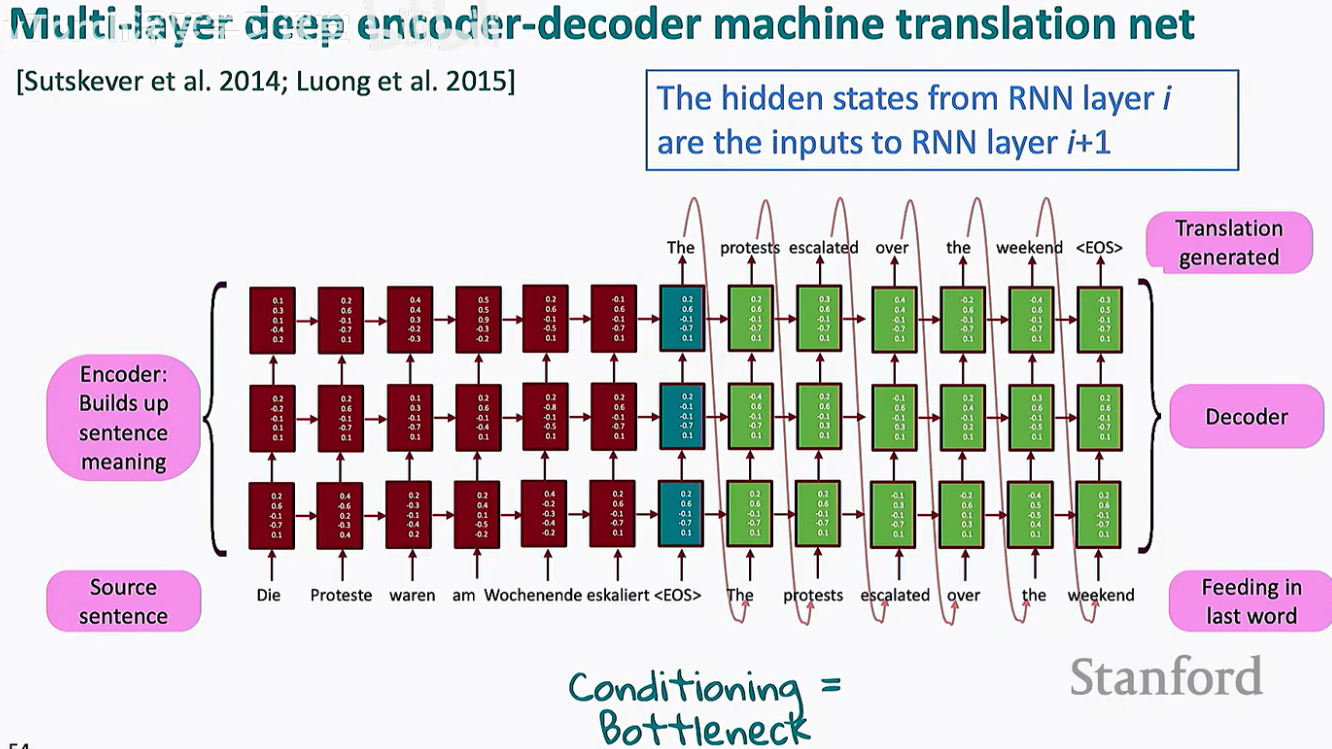
1. 深度堆叠:多层 Encoder-Decoder 架构
正如 Sutskever 等人在 2014 年的论文以及 Luong 等人在 2015 年的研究中所展示的,将多个 RNN 层纵向堆叠(Stacking)可以显著增强模型的建模能力。
-
层次化语义: 在这种结构中,第 i 层的隐藏状态作为第 i+1 层的输入。底层通常负责捕捉基础的词法特征,而高层则负责构建更抽象的句子含义。
-
残差连接与优化: 随着层数的增加,训练变得更具挑战性,这也催生了各种门控机制(如 LSTM/GRU)以及后来的残差连接技术。
2. 行业分水岭:从边缘研究到行业标准
NMT 的发展轨迹在 AI 历史上极其罕见:它仅用了不到两年的时间,就从一个边缘研究尝试(Fringe research attempt)跃升为全球领先的标准方法(Leading standard method)。

-
2014 年: 第一篇真正意义上的 Seq2Seq 论文发表。
-
2016 年: Google Translate 宣布全面从 SMT 切换为 NMT 架构。随后,Microsoft、Baidu、Facebook 以及腾讯等科技巨头纷纷跟进,彻底完成了产业升级。
-
效率的降维打击: 曾经需要数百名工程师耗费多年构建的 SMT 系统,在性能上被一小组工程师仅用几个月训练出的 NMT 系统全面超越。
3. 结语:NLP 深度学习的里程碑
Neural Machine Translation 不仅仅改善了我们的翻译体验,它更重要的意义在于证明了端到端深度学习 在复杂认知任务上的巨大潜力。它直接为后来更强大的架构------如 Attention 机制 和 Transformer------扫清了理论障碍。
如今,当我们享受着丝滑的跨语言沟通时,不应忘记这背后经历的从"规则定义"到"概率统计",再到"神经模拟"的技术史诗。
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
作者正在学习斯坦福大学的CS224N课程。此文章的图片均来自该课程视频,之后会继续更新斯坦福大学CS224N课程,以及加上补充的知识,让我们一起探讨 NLP 的世界!!