
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在算法学习中,动态规划一直是绕不开的核心内容.它既常见于各类笔试、面试和算法竞赛,也广泛应用于路径规划、序列匹配、资源分配等实际问题中.然而,对很多学习者来说,动态规划并不是"不会写代码",而是"想不清状态":为什么要这样定义dp?状态之间如何转移?边界条件从哪里来?尤其当问题涉及两个数组时,状态往往从一维扩展到二维,子问题之间的关系更加复杂,也更容易让人陷入"看题解能懂,自己做却无从下手"的困境.两个数组的DP 问题是动态规划中非常典型的一类,例如最长公共子序列、编辑距离、字符串匹配、交错序列判断、最小路径匹配等,都可以归入这一范畴.它们通常要求我们同时考虑两个序列中的元素关系,通过构建二维状态表来描述"前 i 个元素"和"前 j 个元素"之间的最优解或可行性.相比单数组DP,这类问题更强调状态含义的精确定义、转移方向的判断以及匹配与不匹配情况下的分类讨论.本文将围绕"两个数组的 DP 问题"展开深入剖析,从动态规划的基本思想出发,逐步讲解这类问题的常见建模方式、状态定义技巧、转移方程推导方法以及边界初始化规则.通过系统梳理典型题型和解题套路,帮助读者建立一套清晰、可复用的分析框架,不再只是机械记忆公式,而是能够真正理解两个数组DP问题背后的逻辑,从而在面对类似题目时快速识别问题类型、准确设计状态,并写出正确高效的解法.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
- 1.两个数组的DP问题背景介绍
- 2.最长公共子序列(OJ题)
- 3.不相交的线(OJ题)
- 4.不同的子序列(OJ题)
- 5.通配符匹配(OJ题)
- 6.正则表达式匹配(OJ题)
- 7.交错字符串(OJ题)
- 8.两个字符串的最⼩ASCII删除和(OJ题)
- 9.最长重复子数组(OJ题)
1.两个数组的DP问题背景介绍
两个数组的动态规划问题,通常指在求解过程中需要同时考虑两个序列、两个字符串或两个数组之间关系的一类DP问题.与单数组 DP 只关注一个序列内部的状态变化不同,两个数组的 DP 往往需要在两个维度上共同推进,例如比较 nums1i 与 nums2j、分析 s1 的前 i 个字符与 s2 的前 j 个字符之间的关系,并据此构建状态转移.
这类问题在算法体系中非常常见,尤其集中出现在字符串处理、序列匹配、最优编辑、路径选择和子序列分析等场景中.典型问题包括最长公共子序列、编辑距离、最长重复子数组、正则表达式匹配、通配符匹配、交错字符串等.它们表面形式各不相同,但本质上都可以抽象为:在两个数组或字符串中,分别取前若干个元素,研究它们之间是否匹配、如何匹配,以及在某种约束下能够得到的最优结果.
两个数组 DP 的核心背景在于:许多问题无法只通过单个元素或单个数组的局部信息完成判断,而必须同时记录两个序列的处理进度.例如,在比较两个字符串是否相似时,仅知道第一个字符串处理到了哪里是不够的,还必须知道第二个字符串处理到了哪里;在求两个序列的公共部分时,也需要同时考虑两个序列当前元素是否相等,以及跳过其中某个元素后是否能得到更优结果.因此,这类问题通常会使用二维 DP表,令 dpij 表示第一个数组前 i 个元素与第二个数组前 j 个元素之间的某种关系.
从学习角度看,两个数组DP是动态规划从一维状态走向二维状态的重要阶段.它不仅考察对"最优子结构"和"重叠子问题"的理解,还要求学习者能够准确把握两个序列之间的对应关系.很多初学者在这类问题上容易感到困难,主要原因在于状态定义不够清晰,或者无法判断当前元素相等与不相等时应该如何转移.事实上,只要抓住"两个数组的前缀关系"这一核心思想,大多数问题都可以按照统一的思路进行拆解.
因此,两个数组的DP问题不仅是动态规划中的高频题型,也是理解复杂状态设计的重要入口.掌握这类问题,有助于进一步理解字符串匹配、序列比对、文本编辑、基因序列分析等实际应用中的算法思想,也能为后续学习区间 DP、多维 DP 和更复杂的状态压缩方法打下基础.
2.最长公共子序列(OJ题)

算法思路:解法(动态规划):
1.状态表示:
对于两个数组的动态规划,我们的定义状态表示的经验就是:
i. 选取第一个数组 [0, i] 区间以及第二个数组 [0, j] 区间作为研究对象;
ii. 结合题目要求,定义状态表示.
在这道题中,我们定义状态表示为:
dp[i][j] 表示:s1 的 [0, i] 区间以及 s2 的 [0, j] 区间内的所有子序列中,最长公共子序列的长度.
2.状态转移方程:
分析状态转移方程的经验就是根据最后一个位置的状况,分情况讨论.
对于 dp[i][j],我们可以根据 s1[i] 与 s2[j] 的字符分情况讨论:
i. 两个字符相同,s1[i] == s2[j] :
那么最长公共子序列就在 s1 的 [0, i - 1] 以及 s2 的 [0, j - 1] 区间上找到一个最长的,然后再加上 s1[i] 即可.
因此 dp[i][j] = dp[i - 1][j - 1] + 1;
ii. 两个字符不相同,s1[i] != s2[j] :
那么最长公共子序列一定不会同时以 s1[i] 和 s2[j] 结尾.找最长公共子序列时,有下面三种策略:
- 去
s1的[0, i - 1]以及s2的[0, j]区间内找:此时最大长度为dp[i - 1][j]; - 去
s1的[0, i]以及s2的[0, j - 1]区间内找:此时最大长度为dp[i][j - 1]; - 去
s1的[0, i - 1]以及s2的[0, j - 1]区间内找:此时最大长度为dp[i - 1][j - 1].
我们取三者的最大值即可.但第三种情况包含在前两种情况的最大值中,因此只需求前两种情况的最大值即可.
综上,状态转移方程为:
cpp
if(s1[i] == s2[j]) dp[i][j] = dp[i - 1][j - 1] + 1;
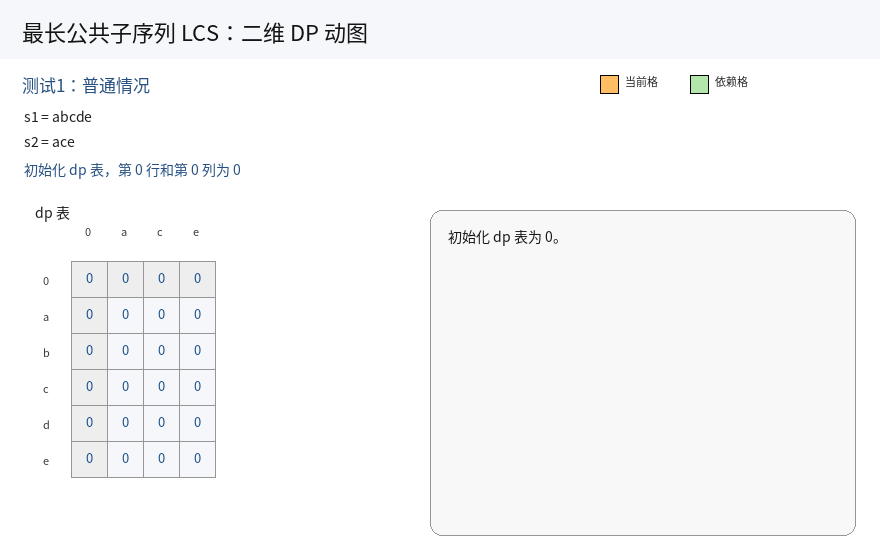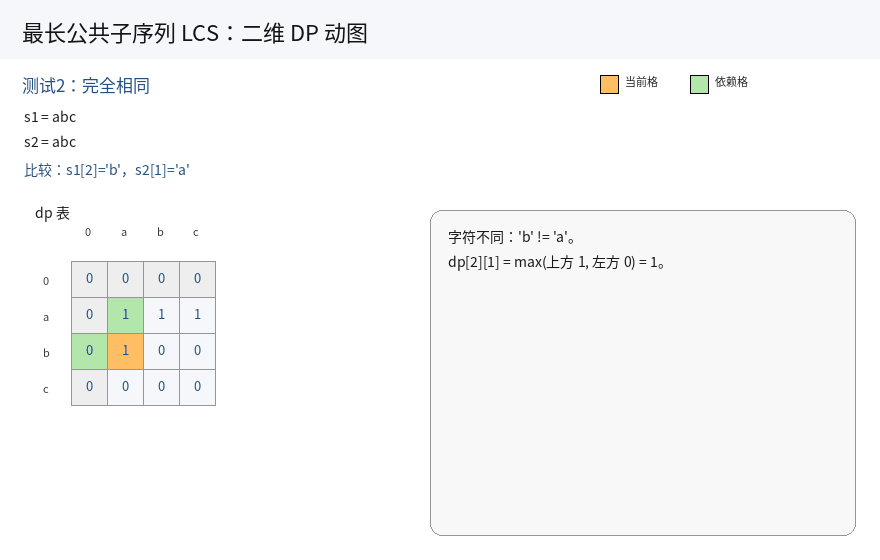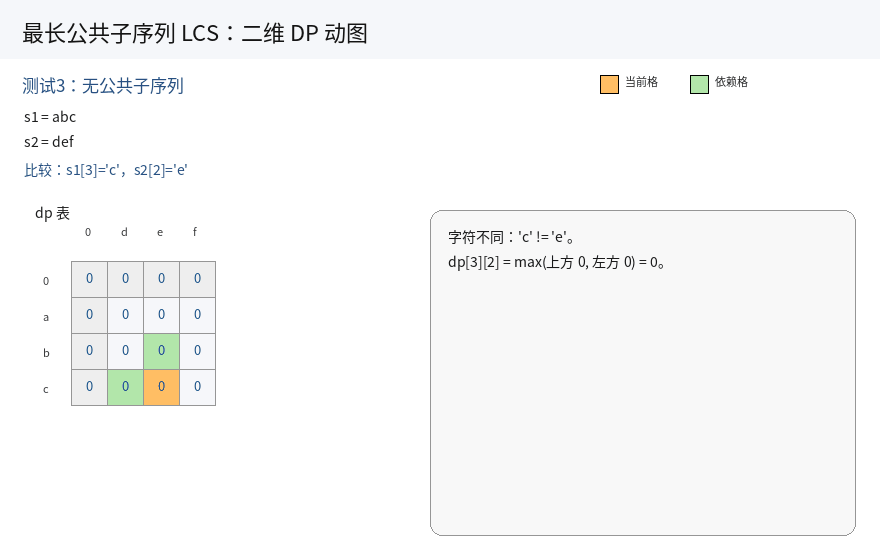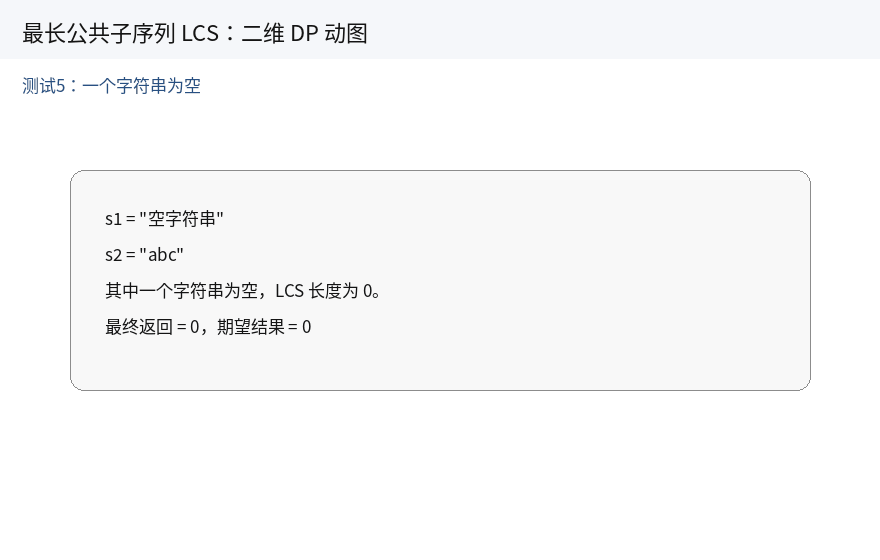
if(s1[i] != s2[j]) dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);3.初始化:
a. 空串是有研究意义的,因此我们将原始 dp 表的规模多加上一行和一列,表示空串.
b. 引入空串后,大大方便了初始化操作。
c. 同时要注意下标的映射关系,保证后续填表的正确性.
当 s1 为空时,没有公共子序列长度;同理 s2 为空时也一样.因此 dp 表的第一行和第一列初始化为 0,即可保证后续填表正确.
4.填表顺序:
根据状态转移方程,填表顺序为:从上往下填写每一行,每一行从左往右.
5.返回值:
根据状态表示,最终返回 dp[m][n](m 为 s1 长度,n 为 s2 长度).
核心代码
cpp
//子序列:不改变字符相对顺序,可删除部分字符的序列
//解法:二维动态规划
class Solution
{
public:
//求两个字符串的最长公共子序列的长度
int longestCommonSubsequence(string s1, string s2)
{
//获取两个字符串的原始长度
int m = s1.size(), n = s2.size();
//技巧:在字符串开头添加空格,让下标从 1 开始
//避免处理 i=0 / j=0 的复杂边界情况
s1 = " " + s1, s2 = " " + s2;
//1.创建二维 dp 表 + 初始化
//dp[i][j] 状态定义:
//表示字符串 s1 的【前 i 个字符】和 s2 的【前 j 个字符】的最长公共子序列长度
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//2.填表:从上到下、从左到右遍历
for(int i = 1; i <= m; i++) //遍历 s1 的每个字符
for(int j = 1; j <= n; j++)//遍历 s2 的每个字符
//情况1:当前两个字符相等
if(s1[i] == s2[j])
//公共子序列长度 = 左上角值 + 1(两个字符都加入公共序列)
dp[i][j] = dp[i - 1][j - 1] + 1;
//情况2:当前两个字符不相等
else
//取两种情况的最大值:
//①舍弃s1当前字符:dp[i-1][j]
//②舍弃s2当前字符:dp[i][j-1]
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
//3.返回结果
//dp[m][n] 就是 s1 和 s2 完整字符串的最长公共子序列长度
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
// 子序列:不改变字符相对顺序,可删除部分字符的序列
// 解法:二维动态规划
class Solution
{
public:
// 求两个字符串的最长公共子序列的长度
int longestCommonSubsequence(string s1, string s2)
{
// 获取两个字符串的原始长度
int m = s1.size(), n = s2.size();
// 技巧:在字符串开头添加空格,让下标从 1 开始
// 避免处理 i=0 / j=0 的复杂边界情况
s1 = " " + s1;
s2 = " " + s2;
// 1. 创建二维 dp 表 + 初始化
// dp[i][j] 表示:
// 字符串 s1 的前 i 个字符 和 s2 的前 j 个字符
// 的最长公共子序列长度
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// 2. 填表:从上到下、从左到右遍历
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:当前两个字符相等
if (s1[i] == s2[j])
{
// 公共子序列长度 = 左上角值 + 1
dp[i][j] = dp[i - 1][j - 1] + 1;
}
// 情况2:当前两个字符不相等
else
{
// 舍弃 s1 当前字符 或 舍弃 s2 当前字符,取最大值
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 3. 返回结果
return dp[m][n];
}
};
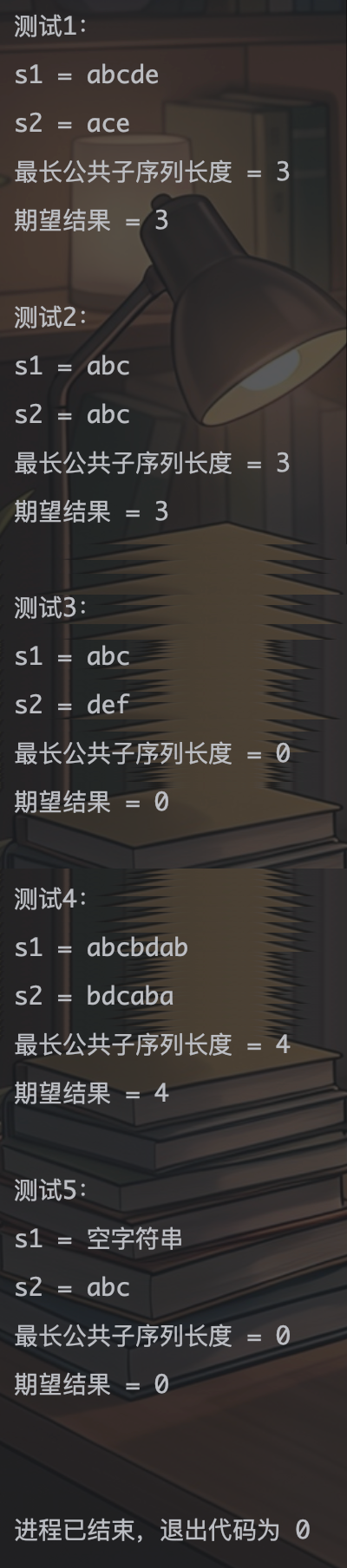
int main()
{
Solution solution;
// 测试用例1:普通情况
string s1 = "abcde";
string s2 = "ace";
cout << "测试1:" << endl;
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "最长公共子序列长度 = "
<< solution.longestCommonSubsequence(s1, s2) << endl;
cout << "期望结果 = 3" << endl;
cout << endl;
// 测试用例2:两个字符串完全相同
s1 = "abc";
s2 = "abc";
cout << "测试2:" << endl;
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "最长公共子序列长度 = "
<< solution.longestCommonSubsequence(s1, s2) << endl;
cout << "期望结果 = 3" << endl;
cout << endl;
// 测试用例3:没有公共子序列
s1 = "abc";
s2 = "def";
cout << "测试3:" << endl;
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "最长公共子序列长度 = "
<< solution.longestCommonSubsequence(s1, s2) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
// 测试用例4:较复杂情况
s1 = "abcbdab";
s2 = "bdcaba";
cout << "测试4:" << endl;
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "最长公共子序列长度 = "
<< solution.longestCommonSubsequence(s1, s2) << endl;
cout << "期望结果 = 4" << endl;
cout << endl;
// 测试用例5:其中一个字符串为空
s1 = "";
s2 = "abc";
cout << "测试5:" << endl;
cout << "s1 = 空字符串" << endl;
cout << "s2 = " << s2 << endl;
cout << "最长公共子序列长度 = "
<< solution.longestCommonSubsequence(s1, s2) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
return 0;
}
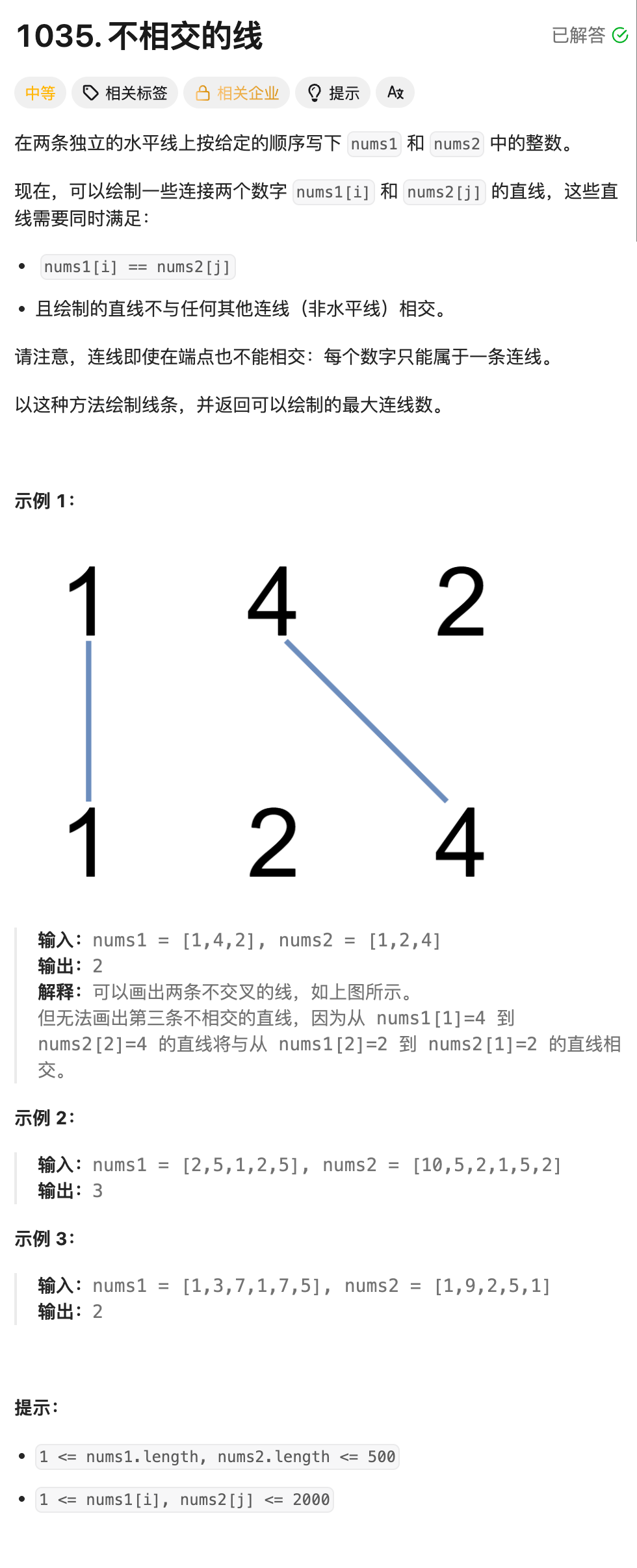
3.不相交的线(OJ题)
算法思路:解法(动态规划):
如果要保证两条直线不相交,那么我们下一个连线必须在上一个连线对应的两个元素的后面寻找相同的元素.这不就转化成最长公共子序列的模型了嘛.那就是在这两个数组中寻找最长的公共子序列.
只不过是在整数数组中做一次最长的公共子序列,代码几乎一模一样,这里就不再赘述算法原理啦~
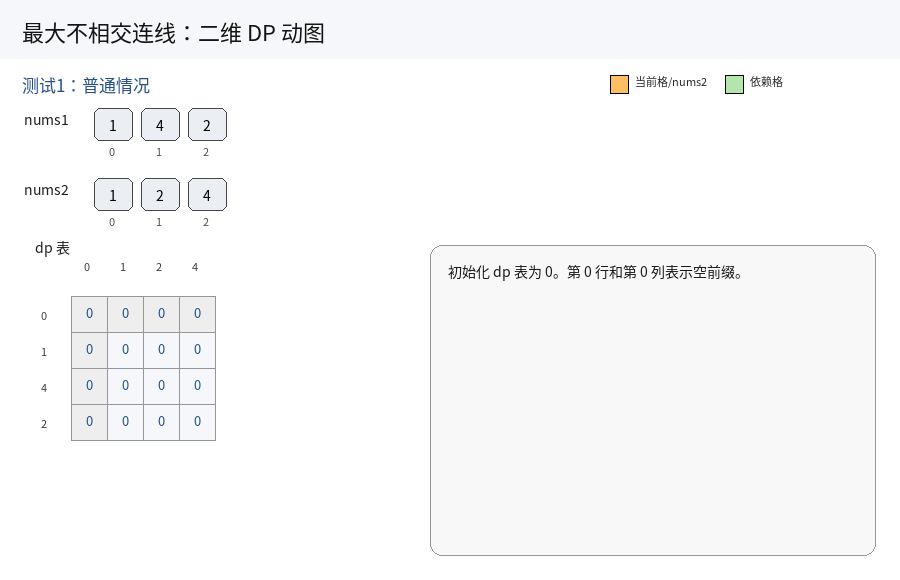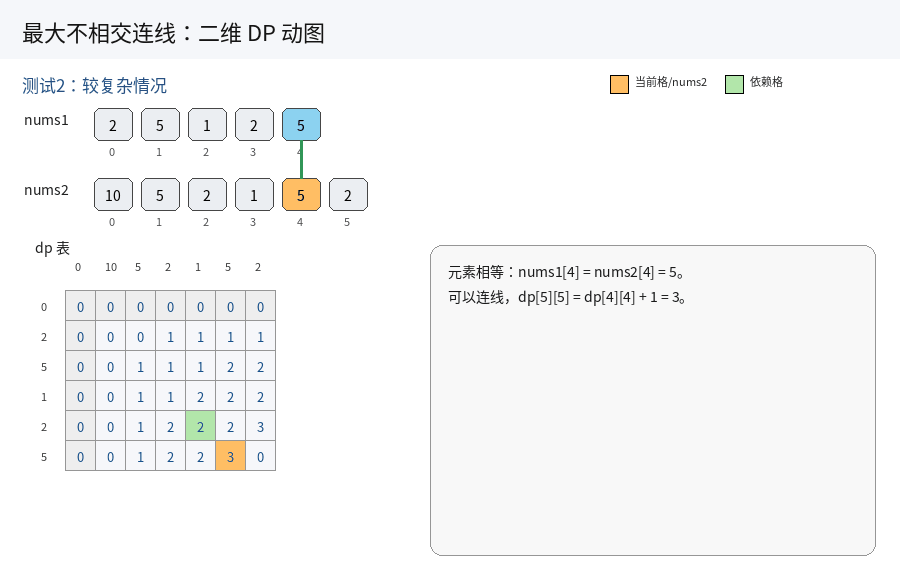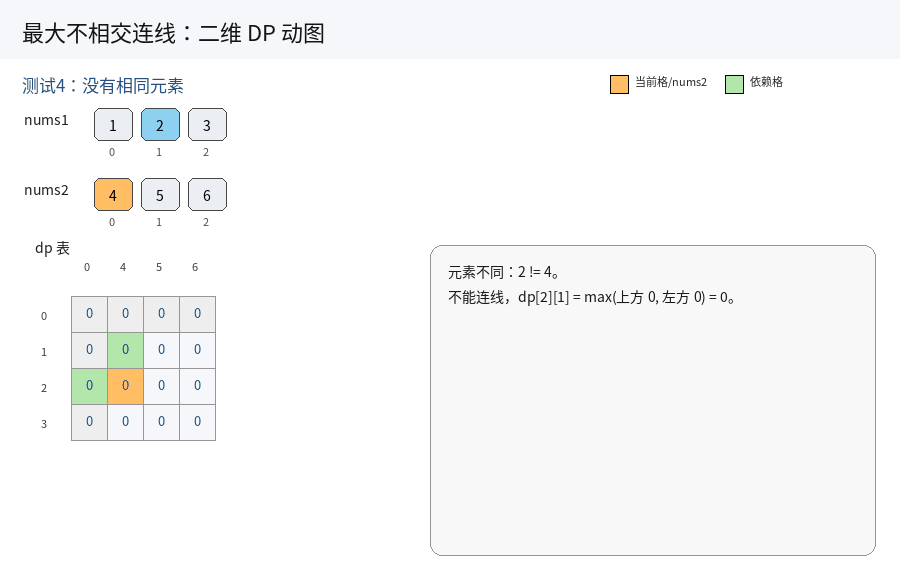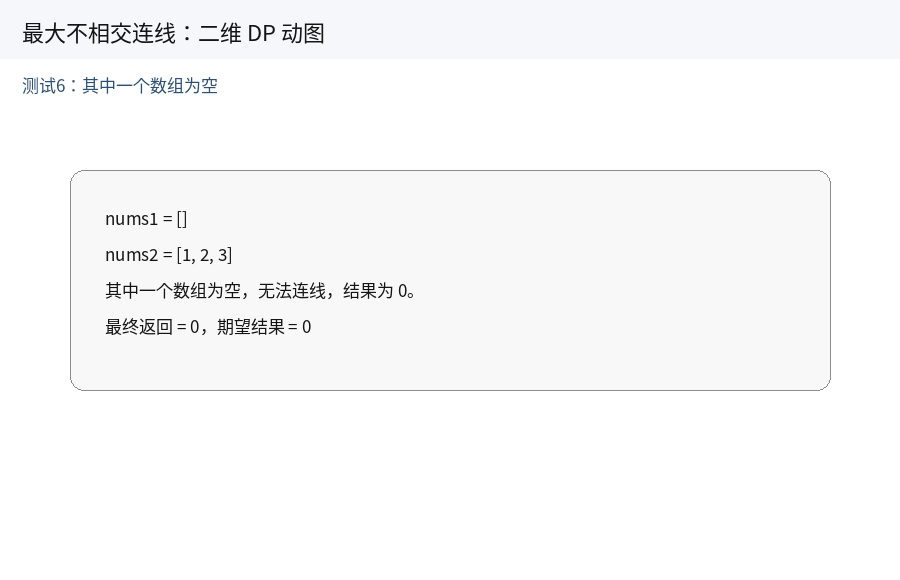
核心代码
cpp
//解题本质:求两个数组的最长公共子序列长度(连线不相交 = 子序列顺序不变)
class Solution
{
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2)
{
//动态规划四步走
//1.创建 dp 表
//2.初始化
//3.填表
//4.返回值
//获取两个数组的长度
int m = nums1.size(), n = nums2.size();
//dp[i][j] 状态定义:
//nums1前i个元素 与 nums2前j个元素 之间,最多的不相交连线数(最长公共子序列长度)
//二维dp数组,大小 (m+1)*(n+1),默认初始化为 0
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//遍历填充dp表:从上到下,从左到右
for(int i = 1; i <= m; i++)
{
for(int j = 1; j <= n; j++)
{
//情况1:当前两个元素相等,可以连线
//不相交连线数 = 左上角值 + 1(继承前序结果,新增一条连线)
if(nums1[i - 1] == nums2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
//情况2:当前两个元素不相等,无法连线
//取两种情况最大值:舍弃nums1当前元素 / 舍弃nums2当前元素
else
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
//返回结果:两个完整数组的最大不相交连线数
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 连线不相交 = 子序列顺序不变
class Solution
{
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2)
{
// 动态规划四步走
// 1. 创建 dp 表
// 2. 初始化
// 3. 填表
// 4. 返回值
// 获取两个数组的长度
int m = nums1.size(), n = nums2.size();
// dp[i][j] 状态定义:
// nums1 前 i 个元素 与 nums2 前 j 个元素 之间
// 最多的不相交连线数,也就是最长公共子序列长度
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// 遍历填充 dp 表:从上到下,从左到右
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:当前两个元素相等,可以连线
if (nums1[i - 1] == nums2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
}
// 情况2:当前两个元素不相等,无法连线
else
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 返回结果:两个完整数组的最大不相交连线数
return dp[m][n];
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (int i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
{
cout << ", ";
}
}
cout << "]";
}
int main()
{
Solution solution;
// 测试用例1:普通情况
vector<int> nums1 = {1, 4, 2};
vector<int> nums2 = {1, 2, 4};
cout << "测试1:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 2" << endl;
cout << endl;
// 测试用例2:较复杂情况
nums1 = {2, 5, 1, 2, 5};
nums2 = {10, 5, 2, 1, 5, 2};
cout << "测试2:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 3" << endl;
cout << endl;
// 测试用例3:重复元素较多
nums1 = {1, 3, 7, 1, 7, 5};
nums2 = {1, 9, 2, 5, 1};
cout << "测试3:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 2" << endl;
cout << endl;
// 测试用例4:没有相同元素
nums1 = {1, 2, 3};
nums2 = {4, 5, 6};
cout << "测试4:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
// 测试用例5:两个数组完全相同
nums1 = {1, 2, 3, 4};
nums2 = {1, 2, 3, 4};
cout << "测试5:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 4" << endl;
cout << endl;
// 测试用例6:其中一个数组为空
nums1 = {};
nums2 = {1, 2, 3};
cout << "测试6:" << endl;
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最大不相交连线数 = "
<< solution.maxUncrossedLines(nums1, nums2) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
return 0;
}
4.不同的子序列(OJ题)

算法思路:解法(动态规划):
1.状态表示:
对于两个字符串之间的dp问题,我们一般的思考方式如下:
i. 选取第一个字符串的 [0, i] 区间以及第二个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义状态表示;
ii. 然后根据两个区间上最后一个位置的字符,来进行分类讨论,从而确定状态转移方程.
我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题.
dp[i][j] 表示:在字符串 s 的 [0, j] 区间内的所有子序列中,有多少个 t 字符串 [0, i] 区间内的子串.
2.状态转移方程:
根据最后一个位置的元素,结合题目要求,分情况讨论:
i. 当 t[i] == s[j] 的时候,此时的子序列有两种选择:
- 一种选择是:子序列选择
s[j]作为结尾,此时相当于在状态dp[i - 1][j - 1]中的所有符合要求的子序列的后面,再加上一个字符s[j],此时dp[i][j] = dp[i - 1][j - 1]; - 另一种选择是:不选择
s[j]作为结尾.此时相当于选择了状态dp[i][j - 1]中所有符合要求的子序列,此时dp[i][j] = dp[i][j - 1];
两种情况加起来,就是t[i] == s[j]时的结果.
ii. 当 t[i] != s[j] 的时候,此时的子序列只能从 dp[i][j - 1] 中选择所有符合要求的子序列,只能继承上个状态里面求得的子序列,dp[i][j] = dp[i][j - 1];
综上所述,状态转移方程为:
- 所有情况下都可以继承上一次的结果:
dp[i][j] = dp[i][j - 1]; - 当
t[i] == s[j]时,可以多选择一种情况:dp[i][j] += dp[i - 1][j - 1]
3.初始化:
a. 空串是有研究意义的,因此我们将原始 dp 表的规模多加上一行和一列,表示空串.
b. 引入空串后,大大方便了初始化.
c. 同时要注意下标的映射关系,以及保证后续填表的正确性.
当 s 为空时,t 的子串中有一个空串和它一样,因此初始化第一行全部为 1.
4.填表顺序:
从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,返回 dp[m][n] 的值.
本题有一个需要注意的点:题目上说结果不会超过 int 的最大值,但实际计算过程中数值可能会溢出.为了避免报错,我们选择 double 存储中间结果.

核心代码
cpp
//题目:求 s 中有多少个不同的子序列 等于 t
class Solution
{
public:
int numDistinct(string s, string t)
{
//动态规划标准四步
//1.创建 dp 表
//2.初始化
//3.填表
//4.返回值
//m:目标串t的长度,n:源串s的长度
int m = t.size(), n = s.size();
//dp[i][j] 状态定义:
//源串 s 的【前 j 个字符】中,包含 目标串 t 的【前 i 个字符】的子序列数量
//使用 double 类型:避免 int/long long 数值溢出
vector<vector<double>> dp(m + 1, vector<double>(n + 1));
//初始化:第一行全为 1
//含义:空串 t 是任意字符串 s 的子序列,且只有 1 种方式(删除所有字符)
for(int j = 0; j <= n; j++)
dp[0][j] = 1;
//填表:从上到下、从左到右遍历
for(int i = 1; i <= m; i++)
{
for(int j = 1; j <= n; j++)
{
//情况1:不使用 s 的第 j 个字符
//数量 = s 前 j-1 个字符 包含 t 前 i 个字符的数量
dp[i][j] += dp[i][j - 1];
//情况2:使用 s 的第 j 个字符(仅当字符相等时有效)
//数量 += s 前 j-1 个字符 包含 t 前 i-1 个字符的数量
if(t[i - 1] == s[j - 1])
dp[i][j] += dp[i - 1][j - 1];
}
}
//返回结果:s 完整字符串 包含 t 完整字符串的子序列数量
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Solution
{
public:
int numDistinct(string s, string t)
{
// 动态规划标准四步
// 1. 创建 dp 表
// 2. 初始化
// 3. 填表
// 4. 返回值
// m:目标串 t 的长度,n:源串 s 的长度
int m = t.size(), n = s.size();
// dp[i][j] 状态定义:
// 源串 s 的前 j 个字符中,包含目标串 t 的前 i 个字符的子序列数量
// 使用 double 类型:避免 int / long long 数值溢出
vector<vector<double>> dp(m + 1, vector<double>(n + 1, 0));
// 初始化:第一行全为 1
// 含义:空串 t 是任意字符串 s 的子序列
// 且只有 1 种方式:删除 s 中所有字符
for (int j = 0; j <= n; j++)
{
dp[0][j] = 1;
}
// 填表:从上到下、从左到右遍历
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:不使用 s 的第 j 个字符
// 数量 = s 前 j - 1 个字符包含 t 前 i 个字符的数量
dp[i][j] += dp[i][j - 1];
// 情况2:使用 s 的第 j 个字符
// 仅当 t[i - 1] == s[j - 1] 时有效
if (t[i - 1] == s[j - 1])
{
dp[i][j] += dp[i - 1][j - 1];
}
}
}
// 返回结果:s 完整字符串包含 t 完整字符串的子序列数量
return dp[m][n];
}
};
int main()
{
Solution solution;
// 测试用例1:经典示例
string s = "rabbbit";
string t = "rabbit";
cout << "测试1:" << endl;
cout << "s = " << s << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 3" << endl;
cout << endl;
// 测试用例2:经典示例
s = "babgbag";
t = "bag";
cout << "测试2:" << endl;
cout << "s = " << s << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 5" << endl;
cout << endl;
// 测试用例3:s 和 t 完全相同
s = "abc";
t = "abc";
cout << "测试3:" << endl;
cout << "s = " << s << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 1" << endl;
cout << endl;
// 测试用例4:t 比 s 长,不可能匹配
s = "abc";
t = "abcd";
cout << "测试4:" << endl;
cout << "s = " << s << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
// 测试用例5:目标串为空
s = "abc";
t = "";
cout << "测试5:" << endl;
cout << "s = " << s << endl;
cout << "t = 空字符串" << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 1" << endl;
cout << endl;
// 测试用例6:源串为空,目标串非空
s = "";
t = "abc";
cout << "测试6:" << endl;
cout << "s = 空字符串" << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 0" << endl;
cout << endl;
// 测试用例7:多个重复字符
s = "aaaaa";
t = "aa";
cout << "测试7:" << endl;
cout << "s = " << s << endl;
cout << "t = " << t << endl;
cout << "不同子序列数量 = "
<< solution.numDistinct(s, t) << endl;
cout << "期望结果 = 10" << endl;
cout << endl;
return 0;
}
5.通配符匹配(OJ题)

算法思路:解法(动态规划):
1.状态表示:
对于两个字符串之间的dp问题,我们一般的思考方式如下:
i. 选取第一个字符串的 [0, i] 区间以及第二个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义状态表示;
ii. 然后根据两个区间上最后一个位置的字符,来进行分类讨论,从而确定状态转移方程.
我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题.
因此,我们定义状态表示为:
dp[i][j] 表示:p 字符串 [0, j] 区间内的子串能否匹配字符串 s 的 [0, i] 区间内的子串.
2.状态转移方程:
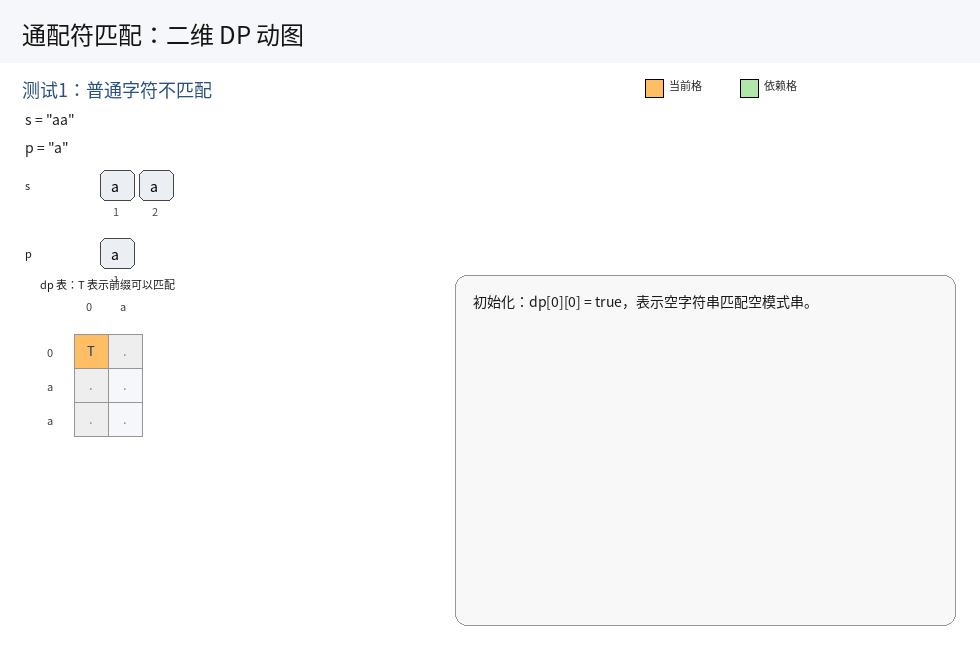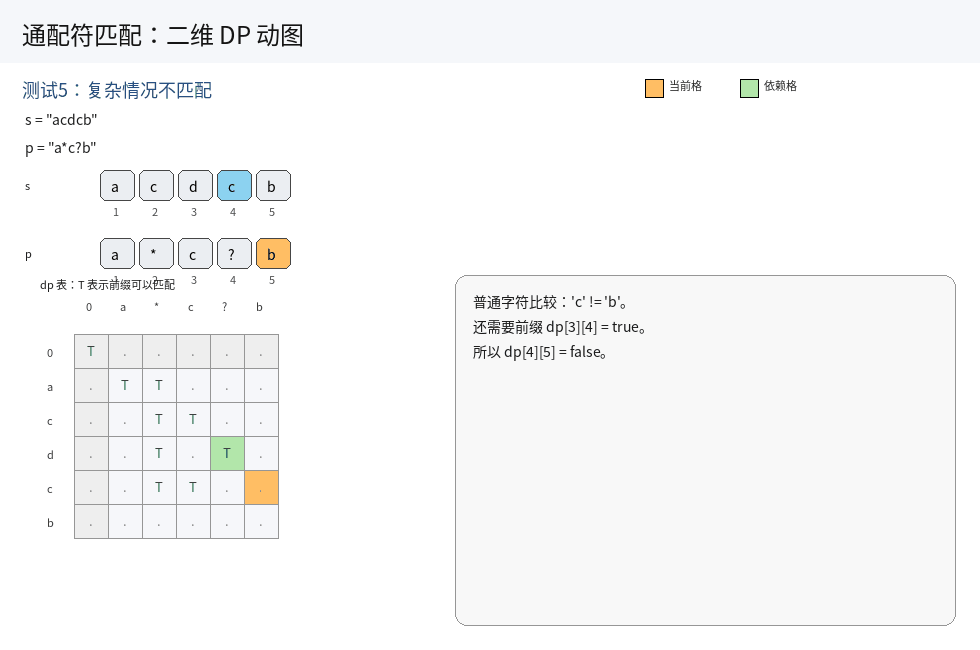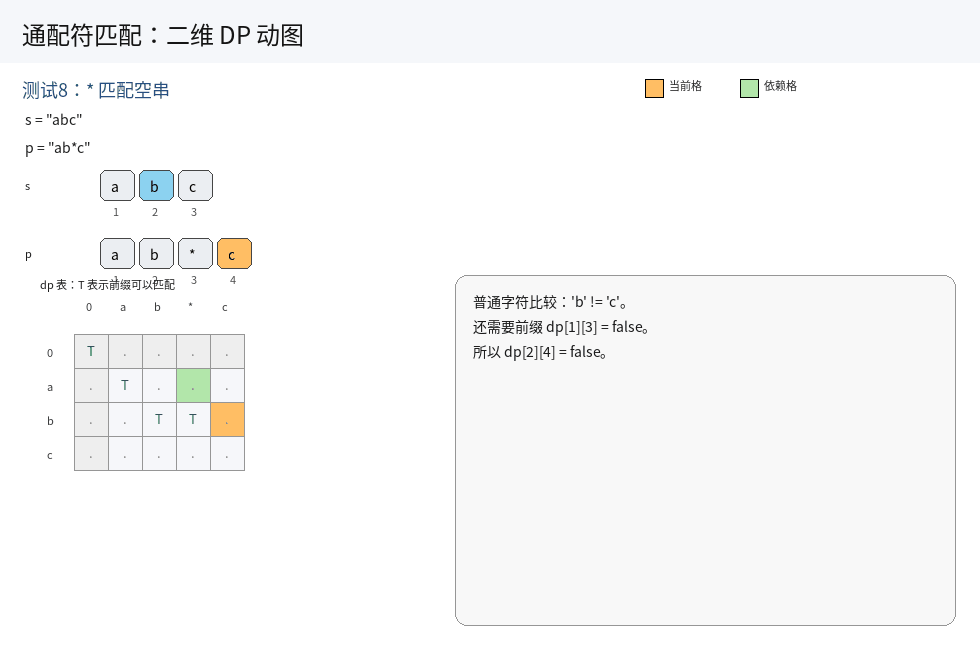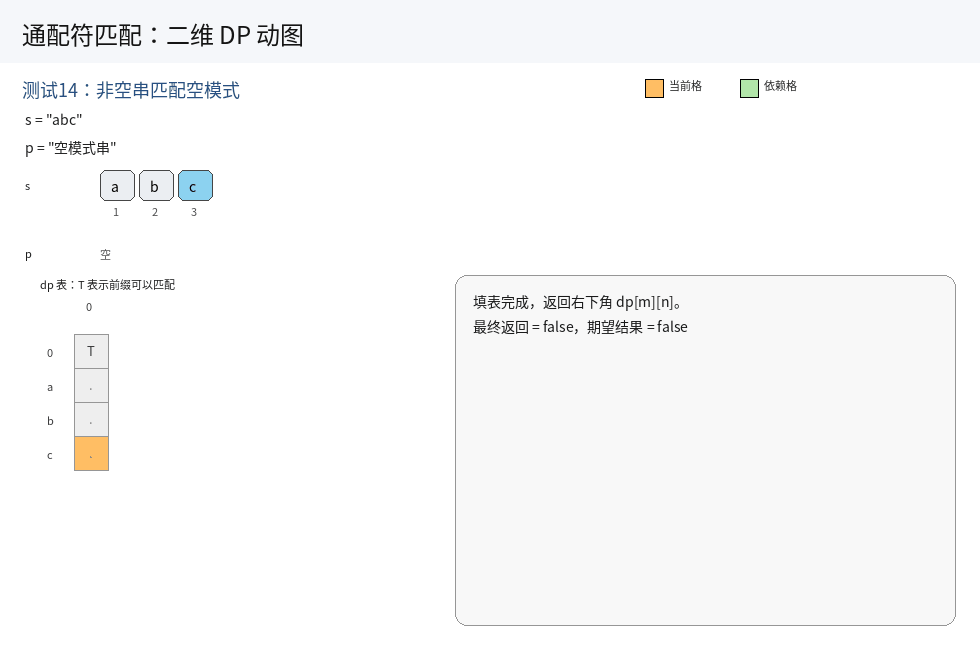
根据最后一个位置的元素,结合题目要求,分情况讨论:
i. 当 s[i] == p[j] 或 p[j] == '?' 的时候,此时两个字符串匹配上了当前的一个字符,只能从 dp[i - 1][j - 1] 中看当前字符前面的两个子串是否匹配,继承上个状态中的匹配结果,即 dp[i][j] = dp[i][j - 1];
ii. 当 p[j] == '*' 的时候,此时匹配策略有两种选择:
- 一种选择是:
*匹配空字符串,此时直接继承状态dp[i][j - 1],即dp[i][j] = dp[i][j - 1]; - 另一种选择是:
*向前匹配1 ~ n个字符,直至匹配上整个s串.此时相当于从dp[k][j - 1](0 <= k <= i)中所有匹配情况里,选择性继承可以成功的情况,即dp[i][j] = dp[k][j - 1](0 <= k <= i);
iii. 当 p[j] 不是特殊字符,且不与 s[i] 相等时,无法匹配.
三种情况加起来,就是所有可能的匹配结果.
综上所述,状态转移方程为:
- 当
s[i] == p[j]或p[j] == '?'时:dp[i][j] = dp[i][j - 1]; - 当
p[j] == '*'时:dp[i][j] = dp[k][j - 1](0 <= k <= i);
优化:
当计算一个状态需要循环时,可通过数学等价替换优化:
当 p[j] == '*' 时,状态转移方程为:
dp[i][j] = dp[i][j - 1] || dp[i - 1][j - 1] || dp[i - 2][j - 1] ......
观察 dp[i - 1][j]:
dp[i - 1][j] = dp[i - 1][j - 1] || dp[i - 2][j - 1] || dp[i - 3][j - 1] ......
可以发现,dp[i][j] 除第一项外,其余部分都能用 dp[i - 1][j] 替代,因此优化后的状态转移方程为:
dp[i][j] = dp[i - 1][j] || dp[i][j - 1].
3.初始化:
由于 dp 数组表示"是否匹配",需将整个数组初始化为 false,再初始化第一行、第一列:
dp[0][0]表示两个空串匹配,初始化为true;- 第一行:
s为空串时,只有p为前导连续*时可匹配,遍历p串,将所有前导为*的子串对应dp值设为true; - 第一列:
p为空串时,无法匹配非空s串,跟随数组默认初始化即可.
4.填表顺序:
从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,返回 dp[m][n] 的值.
核心代码
cpp
//通配符规则:? 匹配单个任意字符;* 匹配任意长度的字符序列(包括空串)
class Solution
{
public:
//判断字符串s是否能被模式串p匹配
bool isMatch(string s, string p)
{
//m:字符串s的长度,n:模式串p的长度
int m = s.size(), n = p.size();
//技巧:在字符串开头添加空格,让下标从1开始
//避免处理i=0/j=0的复杂边界,简化代码逻辑
s = " " + s, p = " " + p;
//1.创建 dp 表
//dp[i][j] 状态定义:
//字符串s的【前i个字符】 和 模式串p的【前j个字符】 是否能够匹配
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1));
//2.初始化
dp[0][0] = true; //空字符串 匹配 空模式串,结果为true
//处理特殊情况:s为空串时,p开头连续的*都可以匹配空串
for(int j = 1; j <= n; j++)
{
if(p[j] == '*')
dp[0][j] = true; //* 匹配空串
else
break; //遇到非*字符,后续无法匹配空串,直接退出
}
//3.填表:从上到下、从左到右遍历
for(int i = 1; i <= m; i++)
{
for(int j = 1; j <= n; j++)
{
//情况1:模式串当前字符是 *
if(p[j] == '*')
//* 有两种选择:
//① dp[i][j-1]:* 匹配空字符(不使用当前*)
//② dp[i-1][j]:* 匹配s的当前字符(使用当前*匹配多个字符)
//两种情况满足其一即可匹配
dp[i][j] = dp[i - 1][j] || dp[i][j - 1];
//情况2:模式串当前字符是 普通字符 或 ?
else
//满足两个条件:
//① 当前字符匹配:p[j]是? 或 s[i]与p[j]字符相等
//② 前i-1个字符和前j-1个字符已匹配
dp[i][j] = (p[j] == '?' || s[i] == p[j]) && dp[i - 1][j - 1];
}
}
//4.返回值
// dp[m][n] 表示s完整字符串 和 p完整模式串 是否匹配
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
// 通配符规则:? 匹配单个任意字符;* 匹配任意长度的字符序列,包括空串
class Solution
{
public:
// 判断字符串 s 是否能被模式串 p 匹配
bool isMatch(string s, string p)
{
// m:字符串 s 的长度,n:模式串 p 的长度
int m = s.size(), n = p.size();
// 技巧:在字符串开头添加空格,让下标从 1 开始
// 避免处理 i=0 / j=0 的复杂边界,简化代码逻辑
s = " " + s;
p = " " + p;
// 1. 创建 dp 表
// dp[i][j] 表示:
// 字符串 s 的前 i 个字符 和 模式串 p 的前 j 个字符 是否能够匹配
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
// 2. 初始化
dp[0][0] = true;
// 处理特殊情况:
// s 为空串时,p 开头连续的 * 都可以匹配空串
for (int j = 1; j <= n; j++)
{
if (p[j] == '*')
{
dp[0][j] = true;
}
else
{
break;
}
}
// 3. 填表:从上到下、从左到右遍历
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:模式串当前字符是 *
if (p[j] == '*')
{
// * 有两种选择:
// 1. dp[i][j - 1]:* 匹配空字符
// 2. dp[i - 1][j]:* 匹配 s 的当前字符
dp[i][j] = dp[i - 1][j] || dp[i][j - 1];
}
// 情况2:模式串当前字符是普通字符 或 ?
else
{
// 当前字符匹配,并且前面的部分也匹配
dp[i][j] = (p[j] == '?' || s[i] == p[j]) && dp[i - 1][j - 1];
}
}
}
// 4. 返回值
return dp[m][n];
}
};
void runTest(Solution& solution, string s, string p, bool expected)
{
bool result = solution.isMatch(s, p);
cout << "s = \"" << s << "\"" << endl;
cout << "p = \"" << p << "\"" << endl;
cout << "匹配结果 = " << (result ? "true" : "false") << endl;
cout << "期望结果 = " << (expected ? "true" : "false") << endl;
if (result == expected)
{
cout << "测试通过" << endl;
}
else
{
cout << "测试失败" << endl;
}
cout << "------------------------" << endl;
}
int main()
{
Solution solution;
// 测试用例1:普通字符不匹配
runTest(solution, "aa", "a", false);
// 测试用例2:* 可以匹配任意长度字符串
runTest(solution, "aa", "*", true);
// 测试用例3:? 匹配单个字符
runTest(solution, "cb", "?a", false);
// 测试用例4:* 匹配中间多个字符
runTest(solution, "adceb", "*a*b", true);
// 测试用例5:复杂情况,不匹配
runTest(solution, "acdcb", "a*c?b", false);
// 测试用例6:完全相同
runTest(solution, "abc", "abc", true);
// 测试用例7:? 和普通字符组合
runTest(solution, "abc", "a?c", true);
// 测试用例8:* 匹配空串
runTest(solution, "abc", "ab*c", true);
// 测试用例9:多个 * 连续出现
runTest(solution, "abc", "a**c", true);
// 测试用例10:空字符串匹配空模式串
runTest(solution, "", "", true);
// 测试用例11:空字符串匹配 *
runTest(solution, "", "*", true);
// 测试用例12:空字符串无法匹配 ?
runTest(solution, "", "?", false);
// 测试用例13:空字符串匹配多个 *
runTest(solution, "", "***", true);
// 测试用例14:字符串非空,模式串为空
runTest(solution, "abc", "", false);
return 0;
}
6.正则表达式匹配(OJ题)

算法思路:解法(动态规划):
1.状态表示:
对于两个字符串之间的 dp 问题,我们一般的思考方式如下:
i. 选取第一个字符串的 [0, i] 区间以及第二个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义状态表示;
ii. 然后根据两个区间上最后一个位置的字符,来进行分类讨论,从而确定状态转移方程.
我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题.
因此我们定义状态表示:
dp[i][j] 表示:字符串 p 的 [0, j] 区间和字符串 s 的 [0, i] 区间是否可以匹配.
2.状态转移方程:
老规矩,根据最后一个位置的元素,结合题目要求,分情况讨论:
a. 当 s[i] == p[j] 或 p[j] == '.' 的时候,此时两个字符串匹配上了当前的一个字符,只能从 dp[i - 1][j - 1] 中看当前字符前面的两个子串是否匹配.只能继承上个状态中的匹配结果,dp[i][j] = dp[i - 1][j - 1];
b. 当 p[j] == '*' 的时候,和上道题稍有不同的是,上道题 "*" 本身便可匹配 0 ~ n 个字符,但此题是要带着 p[j - 1] 的字符一起,匹配 0 ~ n 个和 p[j - 1] 相同的字符.此时,匹配策略有两种选择:
-
一种选择是:
p[j - 1]*匹配空字符串,此时相当于这两个字符都匹配了一个寂寞,直接继承状态dp[i][j - 2],此时dp[i][j] = dp[i][j - 2]; -
另一种选择是:
p[j - 1]*向前匹配1 ~ n个字符,直至匹配上整个s1串.此时相当于从dp[k][j - 2](0 < k <= i)中所有匹配情况中,选择性继承可以成功的情况.此时dp[i][j] = dp[k][j - 2](0 < k <= i且s[k]~s[i] = p[j - 1]);
c. 当 p[j] 不是特殊字符,且不与 s[i] 相等时,无法匹配.
三种情况加起来,就是所有可能的匹配结果.
综上所述,状态转移方程为:
- 当
s[i] == p[j]或p[j] == '.'时:dp[i][j] = dp[i][j - 1]; - 当
p[j] == '*'时,有多种情况需要讨论:dp[i][j] = dp[i][j - 2];dp[i][j] = dp[k][j - 1](0 <= k <= i).
优化:当我们发现,计算一个状态的时候,需要一个循环才能搞定的时候,我们要想到去优化.优化的方向就是用一个或者两个状态来表示这一堆的状态.通常就是把它写下来,然后用数学的方式做一下等价替换:
当 p[j] == '*' 时,状态转移方程为:
dp[i][j] = dp[i][j - 2] || dp[i - 1][j - 2] || dp[i - 2][j - 2] ......
我们发现 i 是有规律的减小的,因此我们去看看 dp[i - 1][j]:
dp[i - 1][j] = dp[i - 1][j - 2] || dp[i - 2][j - 2] || dp[i - 3][j - 2] ......
我们惊奇的发现,dp[i][j] 的状态转移方程里面除了第一项以外,其余的都可以用 dp[i - 1][j] 替代.因此我们优化我们的状态转移方程为:dp[i][j] = dp[i][j - 2] || dp[i - 1][j].
3.初始化:
由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为 false.
由于需要用到前一行和前一列的状态,我们初始化第一行、第一列即可.
dp[0][0] 表示两个空串能否匹配,答案是显然的,初始化为 true.
第一行表示 s 是一个空串,p 串和空串只有一种匹配可能,即 p 串全部字符表示为 "任一字符 + *",此时也相当于空串匹配上空串.所以,我们可以遍历 p 串,把所有前导为 "任一字符 + *" 的 p 子串和空串的 dp 值设为 true.
第一列表示 p 是一个空串,不可能匹配上 s 串,跟随数组初始化即可.
4.填表顺序:
从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,返回 dp[m][n] 的值.

核心代码
cpp
//解题类:正则表达式匹配(支持. 和 * 通配符)
class Solution
{
public:
//函数功能:判断字符串s是否和模式串p完全匹配
//s:待匹配的字符串
//p:包含通配符的正则表达式
bool isMatch(string s, string p)
{
//获取字符串s和模式串p的原始长度
int m = s.size(), n = p.size();
//核心技巧:在字符串开头添加一个空格(占位符)
//让字符串下标从1开始,避免dp数组处理0下标时的边界问题
s = ' ' + s;
p = ' ' + p;
//1.创建dp表
//dp[i][j]:定义状态,表示【s的前i个字符】和【p的前j个字符】是否匹配
//初始化:所有值默认为false
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1));
//2. 初始化dp表
//边界1:空字符串匹配空模式串 → 一定匹配,为true
dp[0][0] = true;
//边界2:处理s为空字符串,但p包含*的情况(如 a*b*)
//* 必须跟在字符后,因此j从2开始,步长为2
for(int j = 2; j <= n; j += 2)
{
//如果当前位置是*,说明可以匹配0个前导字符,空串能匹配
if(p[j] == '*')
dp[0][j] = true;
//一旦遇到不是*的字符,后续无法匹配空串,直接退出循环
else
break;
}
//3.填充dp表(状态转移)
//遍历s的所有字符(i从1到m)
for(int i = 1; i <= m; i++)
{
//遍历p的所有字符(j从1到n)
for(int j = 1; j <= n; j++)
{
//情况1:模式串当前字符是 *(核心难点:* 可以匹配0个/多个前导字符)
if(p[j] == '*')
{
//状态转移:两种选择,满足其一即可
//① 让 * 匹配 0 个前导字符 → 直接继承 dp[i][j-2] 的结果
//② 让 * 匹配 至少1个前导字符 → 前导字符(p[j-1])和s[i]匹配(或为.),且s前i-1个字符与p前j个字符匹配
dp[i][j] = dp[i][j - 2] || (p[j - 1] == '.' || p[j - 1] == s[i]) && dp[i - 1][j];
}
//情况2:模式串当前字符不是 *(普通字符 或 .)
else
{
//状态转移:
//要么字符完全相等,要么模式串是.(匹配任意字符)
//同时 前i-1个字符和前j-1个字符必须匹配
dp[i][j] = (p[j] == s[i] || p[j] == '.') && dp[i - 1][j - 1];
}
}
}
//4.返回最终结果
//dp[m][n] 代表:s的全部m个字符 和 p的全部n个字符 是否匹配
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
// 解题类:正则表达式匹配,支持 . 和 * 通配符
class Solution
{
public:
// 函数功能:判断字符串 s 是否和模式串 p 完全匹配
// s:待匹配的字符串
// p:包含通配符的正则表达式
bool isMatch(string s, string p)
{
// 获取字符串 s 和模式串 p 的原始长度
int m = s.size(), n = p.size();
// 核心技巧:在字符串开头添加一个空格,占位符
// 让字符串下标从 1 开始,避免 dp 数组处理 0 下标时的边界问题
s = ' ' + s;
p = ' ' + p;
// 1. 创建 dp 表
// dp[i][j] 表示:
// s 的前 i 个字符 和 p 的前 j 个字符 是否匹配
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
// 2. 初始化 dp 表
// 空字符串匹配空模式串
dp[0][0] = true;
// 处理 s 为空字符串,但 p 包含 * 的情况
// 例如:a*、a*b*、.*、a*b*c*
for (int j = 2; j <= n; j += 2)
{
if (p[j] == '*')
{
dp[0][j] = true;
}
else
{
break;
}
}
// 3. 填充 dp 表
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:模式串当前字符是 *
if (p[j] == '*')
{
// 选择1:* 匹配 0 个前导字符
// 选择2:* 匹配至少 1 个前导字符
dp[i][j] = dp[i][j - 2] ||
((p[j - 1] == '.' || p[j - 1] == s[i]) && dp[i - 1][j]);
}
// 情况2:普通字符 或 .
else
{
dp[i][j] = (p[j] == s[i] || p[j] == '.') && dp[i - 1][j - 1];
}
}
}
// 4. 返回最终结果
return dp[m][n];
}
};
void runTest(Solution& solution, string s, string p, bool expected)
{
bool result = solution.isMatch(s, p);
cout << "s = \"" << s << "\"" << endl;
cout << "p = \"" << p << "\"" << endl;
cout << "匹配结果 = " << (result ? "true" : "false") << endl;
cout << "期望结果 = " << (expected ? "true" : "false") << endl;
if (result == expected)
{
cout << "测试通过" << endl;
}
else
{
cout << "测试失败" << endl;
}
cout << "------------------------" << endl;
}
int main()
{
Solution solution;
// 测试用例1:普通字符不匹配
runTest(solution, "aa", "a", false);
// 测试用例2:* 匹配多个前导字符
runTest(solution, "aa", "a*", true);
// 测试用例3:. 匹配任意单个字符
runTest(solution, "ab", ".*", true);
// 测试用例4:复杂情况,匹配
runTest(solution, "aab", "c*a*b", true);
// 测试用例5:复杂情况,不匹配
runTest(solution, "mississippi", "mis*is*p*.", false);
// 测试用例6:完全相同
runTest(solution, "abc", "abc", true);
// 测试用例7:. 匹配中间字符
runTest(solution, "abc", "a.c", true);
// 测试用例8:* 匹配 0 个前导字符
runTest(solution, "ab", "abc*", true);
// 测试用例9:多个 * 组合
runTest(solution, "aaa", "a*a", true);
// 测试用例10:多个 * 组合
runTest(solution, "aaa", "ab*a*c*a", true);
// 测试用例11:空字符串匹配空模式串
runTest(solution, "", "", true);
// 测试用例12:空字符串匹配 a*
runTest(solution, "", "a*", true);
// 测试用例13:空字符串匹配 a*b*
runTest(solution, "", "a*b*", true);
// 测试用例14:空字符串不能匹配 .
runTest(solution, "", ".", false);
// 测试用例15:字符串非空,模式串为空
runTest(solution, "abc", "", false);
// 测试用例16:.* 可以匹配任意字符串
runTest(solution, "abcdef", ".*", true);
// 测试用例17:末尾字符不匹配
runTest(solution, "abcd", ".*e", false);
return 0;
}
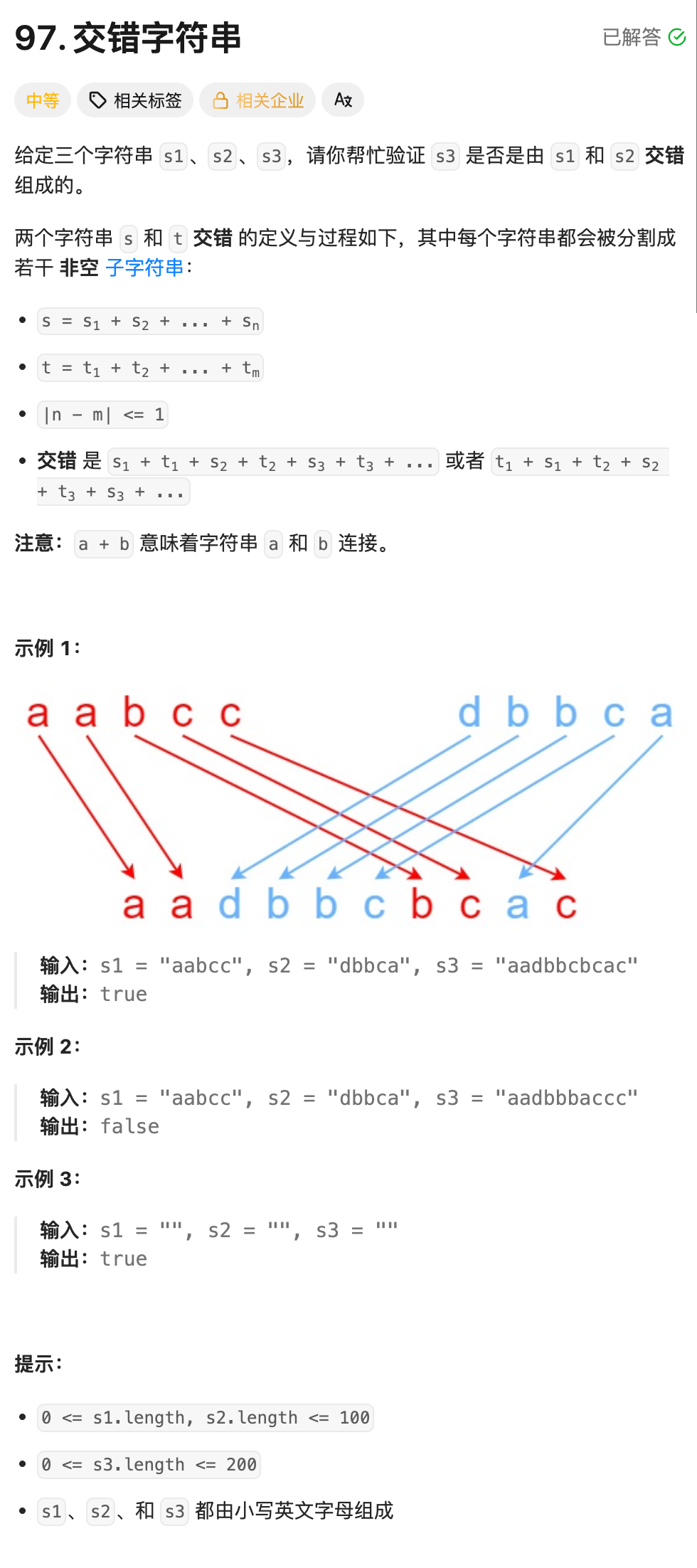
7.交错字符串(OJ题)
算法思路:解法(动态规划):
对于两个字符串之间的 dp 问题,我们一般的思考方式如下:
i. 选取第一个字符串的 [0, i] 区间以及第二个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义状态表示;
ii. 然后根据两个区间上最后一个位置的字符,来进行分类讨论,从而确定状态转移方程.
我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题.
这道题里面空串是有研究意义的,因此我们先预处理一下原始字符串,前面统一加上一个占位符:
s1 = " " + s1, s2 = " " + s2, s3 = " " + s3.
1.状态表示:
dp[i][j] 表示字符串 s1 中 [1, i] 区间内的字符串以及 s2 中 [1, j] 区间内的字符串,能否拼接成 s3 中 [1, i + j] 区间内的字符串.
2.状态转移方程:
先分析一下题目,题目中交错后的字符串为 s1 + t1 + s2 + t2 + s3 + t3......,看似一个 s 一个 t.实际上 s1 能够拆分成更小的一个字符,进而可以细化成 s1 + s2 + s3 + t1 + t2 + s4.......
也就是说,并不是前一个用了 s 的子串,后一个必须要用 t 的子串.这一点理解,对我们的状态转移很重要.
继续根据两个区间上最后一个位置的字符,结合题目的要求,来进行分类讨论:
i. 当 s3[i + j] = s1[i] 的时候,说明交错后的字符串的最后一个字符和 s1 的最后一个字符匹配了.那么整个字符串能否交错组成,变成:
s1 中 [1, i - 1] 区间上的字符串以及 s2 中 [1, j] 区间上的字符串,能够交错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i - 1][j];
此时 dp[i][j] = dp[i - 1][j]
ii. 当 s3[i + j] = s2[j] 的时候,说明交错后的字符串的最后一个字符和 s2 的最后一个字符匹配了.那么整个字符串能否交错组成,变成:
s1 中 [1, i] 区间上的字符串以及 s2 中 [1, j - 1] 区间上的字符串,能够交错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i][j - 1];
iii. 当两者的末尾都不等于 s3 最后一个位置的字符时,说明不可能是两者的交错字符串.
上述三种情况下,只要有一个情况下能够交错组成目标串,就可以返回 true.因此,我们可以定义状态转移为:
dp[i][j] = (s1[i - 1] == s3[i + j - 1] && dp[i - 1][j]) || (s2[j - 1] == s3[i + j - 1] && dp[i][j - 1])
只要有一个成立,结果就是 true.
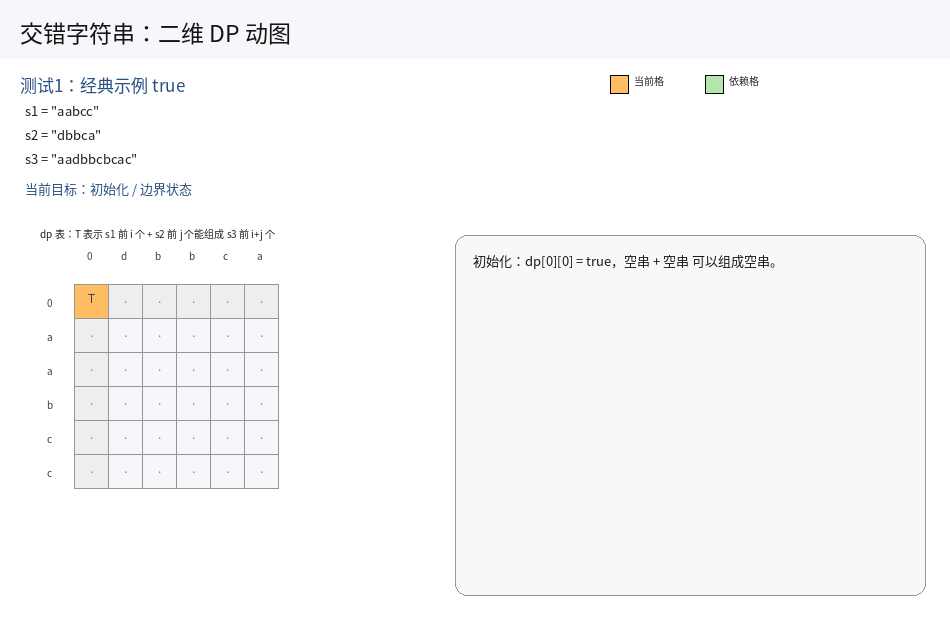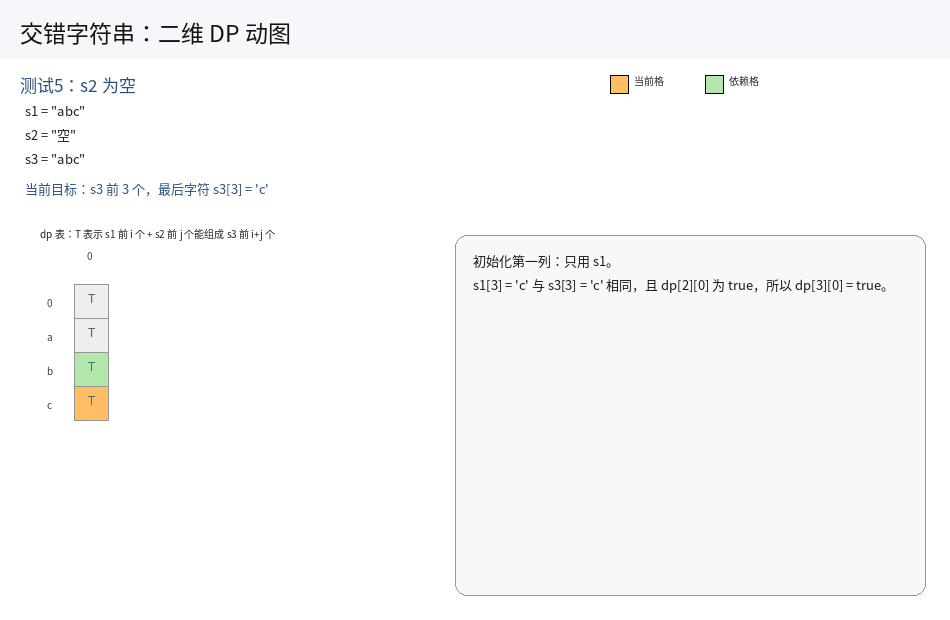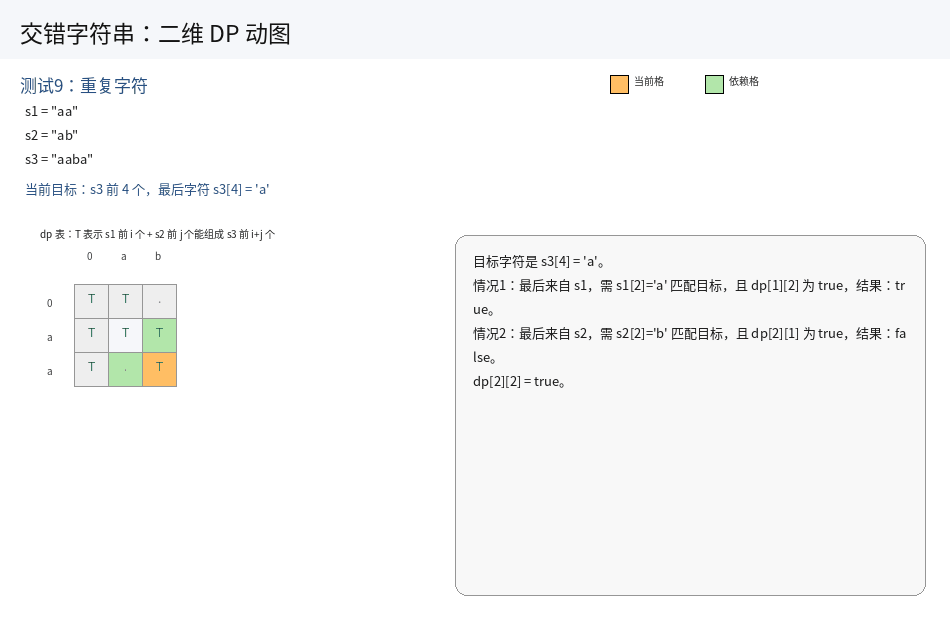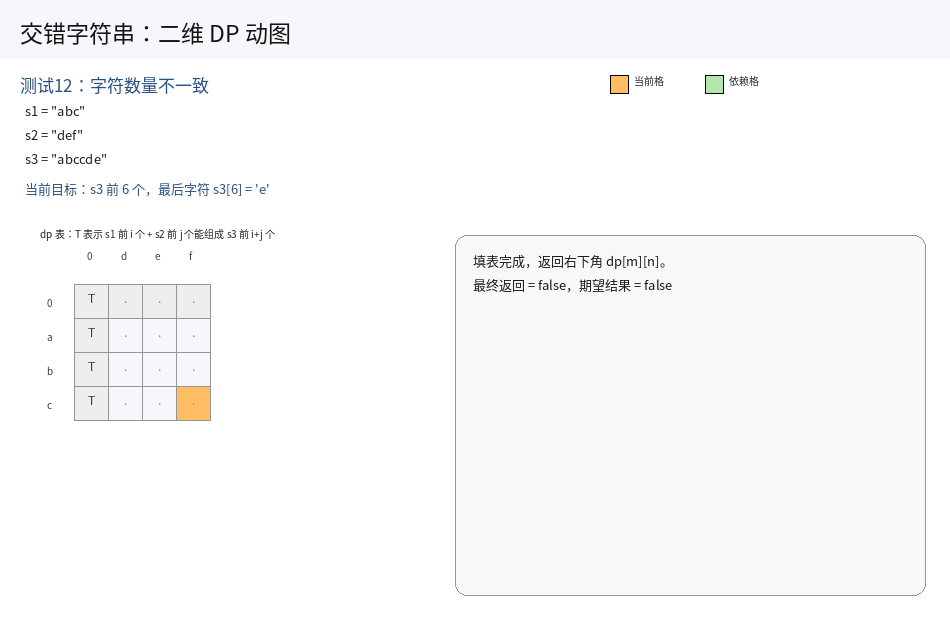
3.初始化:
由于用到 i - 1,j - 1 位置的值,因此需要初始化第一个位置以及第一行和第一列.
-
第一个位置 :
dp[0][0] = true,因为空串 + 空串能够构成一个空串. -
第一行 :
第一行表示
s1是一个空串,我们只用考虑s2即可.因此状态转移之和s2有关:
dp[0][j] = s2[j - 1] == s3[j - 1] && dp[0][j - 1],j从1到n(n为s2的长度) -
第一列 :
第一列表示
s2是一个空串,我们只用考虑s1即可.因此状态转移之和s1有关:
dp[i][0] = s1[i - 1] == s3[i - 1] && dp[i - 1][0],i从1到m(m为s1的长度)
4.填表顺序:
根据状态转移,我们需要从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,我们需要返回 dp[m][n] 的值.
核心代码
cpp
//解题类:交错字符串(判断s3是否由s1和s2交错组成)
class Solution
{
public:
//函数功能:判断字符串 s3 是否可以由字符串 s1 和字符串 s2 交错拼接而成
//交错拼接:字符顺序保持不变,交替选取s1、s2的字符组成s3
bool isInterleave(string s1, string s2, string s3)
{
//预处理步骤
//获取s1、s2的长度
int m = s1.size(), n = s2.size();
//剪枝:如果s3长度不等于s1+s2的长度,直接返回false(不可能交错组成)
if(m + n != s3.size()) return false;
//核心技巧:字符串开头添加空格,让下标从1开始
//避免dp数组处理0下标时的边界问题,简化逻辑
s1 = " " + s1;
s2 = " " + s2;
s3 = " " + s3;
//1.创建dp表
//状态定义:dp[i][j] 表示
//s1的前i个字符 + s2的前j个字符,能否交错组成 s3的前 i+j 个字符
//初始化:所有值默认为false
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1));
//2. 初始化dp表
//边界:s1取0个、s2取0个 → 组成空串,必然匹配
dp[0][0] = true;
//初始化第一行:s1取0个字符,仅用s2的前j个字符组成s3的前j个字符
for(int j = 1; j <= n; j++)
{
//字符匹配则继承前一个状态,不匹配直接终止(后续都不成立)
if(s2[j] == s3[j]) dp[0][j] = true;
else break;
}
//初始化第一列:s2取0个字符,仅用s1的前i个字符组成s3的前i个字符
for(int i = 1; i <= m; i++)
{
//字符匹配则继承前一个状态,不匹配直接终止
if(s1[i] == s3[i]) dp[i][0] = true;
else break;
}
//3.填充dp表(状态转移)
//遍历s1的所有长度i
for(int i = 1; i <= m; i++)
{
//遍历s2的所有长度j
for(int j = 1; j <= n; j++)
{
//状态转移方程(满足其一即可):
//1.最后一个字符来自s1:s1[i] == s3[i+j],且前i-1个s1 + j个s2匹配
//2.最后一个字符来自s2:s2[j] == s3[i+j],且前i个s1 + j-1个s2匹配
dp[i][j] = (s1[i] == s3[i + j] && dp[i - 1][j])
|| (s2[j] == s3[i + j] && dp[i][j - 1]);
}
}
//4.返回最终结果
//dp[m][n]:s1全部m个字符 + s2全部n个字符,能否组成s3全部字符
return dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
// 解题类:交错字符串,判断 s3 是否由 s1 和 s2 交错组成
class Solution
{
public:
// 函数功能:判断字符串 s3 是否可以由字符串 s1 和字符串 s2 交错拼接而成
// 交错拼接:字符顺序保持不变,交替选取 s1、s2 的字符组成 s3
bool isInterleave(string s1, string s2, string s3)
{
// 预处理步骤
int m = s1.size(), n = s2.size();
// 剪枝:如果 s3 长度不等于 s1 + s2 的长度,直接返回 false
if (m + n != s3.size())
{
return false;
}
// 核心技巧:字符串开头添加空格,让下标从 1 开始
s1 = " " + s1;
s2 = " " + s2;
s3 = " " + s3;
// 1. 创建 dp 表
// dp[i][j] 表示:
// s1 的前 i 个字符 + s2 的前 j 个字符
// 能否交错组成 s3 的前 i + j 个字符
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
// 2. 初始化 dp 表
dp[0][0] = true;
// 初始化第一行:
// s1 取 0 个字符,仅用 s2 的前 j 个字符组成 s3 的前 j 个字符
for (int j = 1; j <= n; j++)
{
if (s2[j] == s3[j] && dp[0][j - 1])
{
dp[0][j] = true;
}
else
{
break;
}
}
// 初始化第一列:
// s2 取 0 个字符,仅用 s1 的前 i 个字符组成 s3 的前 i 个字符
for (int i = 1; i <= m; i++)
{
if (s1[i] == s3[i] && dp[i - 1][0])
{
dp[i][0] = true;
}
else
{
break;
}
}
// 3. 填充 dp 表
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:最后一个字符来自 s1
bool fromS1 = (s1[i] == s3[i + j]) && dp[i - 1][j];
// 情况2:最后一个字符来自 s2
bool fromS2 = (s2[j] == s3[i + j]) && dp[i][j - 1];
dp[i][j] = fromS1 || fromS2;
}
}
// 4. 返回最终结果
return dp[m][n];
}
};
void runTest(Solution& solution, string s1, string s2, string s3, bool expected)
{
bool result = solution.isInterleave(s1, s2, s3);
cout << "s1 = \"" << s1 << "\"" << endl;
cout << "s2 = \"" << s2 << "\"" << endl;
cout << "s3 = \"" << s3 << "\"" << endl;
cout << "判断结果 = " << (result ? "true" : "false") << endl;
cout << "期望结果 = " << (expected ? "true" : "false") << endl;
if (result == expected)
{
cout << "测试通过" << endl;
}
else
{
cout << "测试失败" << endl;
}
cout << "------------------------" << endl;
}
int main()
{
Solution solution;
// 测试用例1:经典示例,能够交错组成
runTest(solution, "aabcc", "dbbca", "aadbbcbcac", true);
// 测试用例2:经典示例,不能交错组成
runTest(solution, "aabcc", "dbbca", "aadbbbaccc", false);
// 测试用例3:三个字符串都为空
runTest(solution, "", "", "", true);
// 测试用例4:s1 为空,只由 s2 组成
runTest(solution, "", "abc", "abc", true);
// 测试用例5:s2 为空,只由 s1 组成
runTest(solution, "abc", "", "abc", true);
// 测试用例6:长度不匹配,直接 false
runTest(solution, "abc", "def", "abcdefg", false);
// 测试用例7:简单交错
runTest(solution, "abc", "def", "adbcef", true);
// 测试用例8:顺序被破坏,不能交错
runTest(solution, "abc", "def", "abdfec", false);
// 测试用例9:s1 和 s2 中有重复字符,能够交错
runTest(solution, "aa", "ab", "aaba", true);
// 测试用例10:重复字符较多,能够交错
runTest(solution, "aaaa", "bbbb", "abababab", true);
// 测试用例11:重复字符较多,不能交错
runTest(solution, "aaaa", "bbbb", "aaaabbbb", true);
// 测试用例12:字符数量不一致,不能交错
runTest(solution, "abc", "def", "abccde", false);
return 0;
}
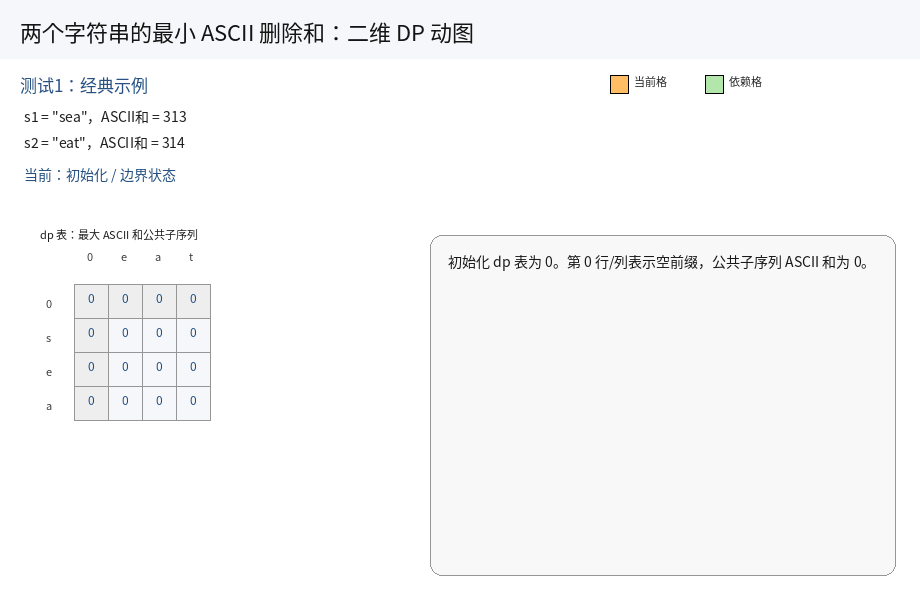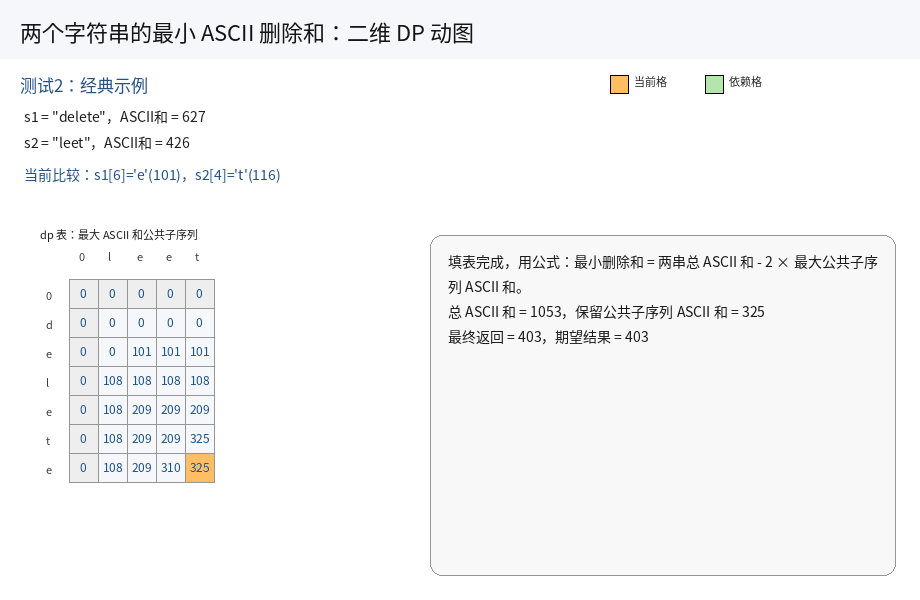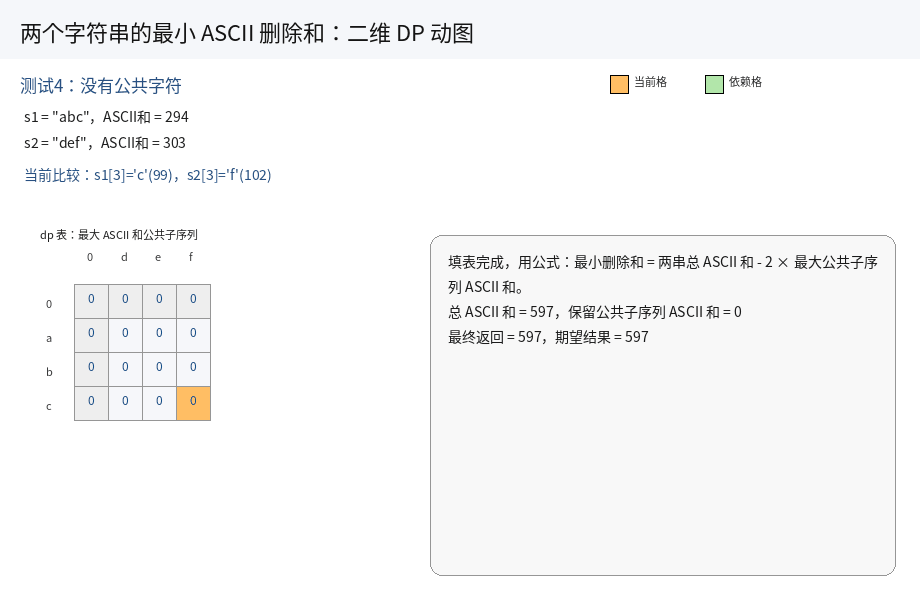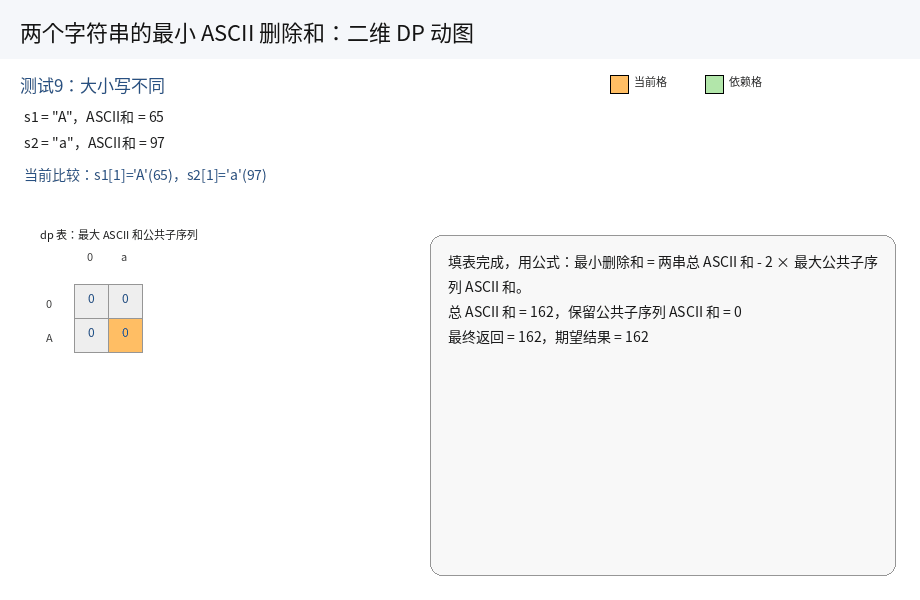
8.两个字符串的最⼩ASCII删除和(OJ题)

算法思路:解法(动态规划):
正难则反:求两个字符串的最小 ASCII 删除和,其实就是找到两个字符串中所有的公共子序列里面,ASCII 最大和.
因此,我们的思路就是按照最长公共子序列的分析方式来分析.
1.状态表示:
dp[i][j] 表示:s1 的 [0, i] 区间以及 s2 的 [0, j] 区间内的所有的子序列中,公共子序列的 ASCII 最大和.
2.状态转移方程:
对于 dp[i][j] 根据最后一个位置的元素,结合题目要求,分情况讨论:
i. 当 s1[i] == s2[j] 时:应该先在 s1 的 [0, i - 1] 区间以及 s2 的 [0, j - 1] 区间内找一个公共子序列的最大和,然后在它们后面加上一个 s1[i] 字符即可.
此时 dp[i][j] = dp[i - 1][j - 1] + s1[i];
ii. 当 s1[i] != s2[j] 时:公共子序列的最大和会有三种可能:
s1的[0, i - 1]区间以及s2的[0, j]区间内:此时dp[i][j] = dp[i - 1][j];s1的[0, i]区间以及s2的[0, j - 1]区间内:此时dp[i][j] = dp[i][j - 1];s1的[0, i - 1]区间以及s2的[0, j - 1]区间内:此时dp[i][j] = dp[i - 1][j - 1].
但是前两种情况里面包含了第三种情况,因此仅需考虑前两种情况下的最大值即可.
综上所述,状态转移方程为:
- 当
s1[i - 1] == s2[j - 1]时,dp[i][j] = dp[i - 1][j - 1] + s1[i]; - 当
s1[i - 1] != s2[j - 1]时,dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
3.初始化:
a. 空串是有研究意义的,因此我们将原始 dp 表的规模多加上一行和一列,表示空串.
b. 引入空串后,大大的方便我们的初始化.
c. 但也要注意下标的映射关系,以及里面的值要保证后续填表是正确的.
当 s1 为空时,没有长度,同理 s2 也是.因此第一行和第一列里面的值初始化为 0 即可保证后续填表是正确的.
4.填表顺序:
从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,我们不能直接返回 dp 表里面的某个值:
i. 先找到 dp[m][n],也是最大公共 ASCII 和;
ii. 统计两个字符串的 ASCII 码和 sum;
iii. 返回 sum - 2 * dp[m][n].
核心代码
cpp
//解题类:两个字符串的最小ASCII删除和
//核心思路:转化为求【最大ASCII和的公共子序列】
//最小删除和 = 两个字符串总ASCII和 - 2 * 最大公共子序列ASCII和
class Solution
{
public:
//函数功能:计算使s1和s2相等所需删除的字符的最小ASCII值之和
int minimumDeleteSum(string s1, string s2)
{
//1.创建 dp 表
//获取s1、s2的长度
int m = s1.size(), n = s2.size();
//dp[i][j]:状态定义
//表示s1的前i个字符 和 s2的前j个字符中,最大ASCII和的公共子序列的ASCII总和
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//2.填表(状态转移)
//遍历s1的所有长度i
for(int i = 1; i <= m; i++)
{
//遍历s2的所有长度j
for(int j = 1; j <= n; j++)
{
//情况1:当前字符不匹配/不选取
//取两种选择的最大值:
//①不选s1的第i个字符 → dp[i-1][j]
//②不选s2的第j个字符 → dp[i][j-1]
dp[i][j] = max(dp[i][j - 1], dp[i - 1][j]);
//情况2:s1的第i个字符 和 s2的第j个字符 相等
if(s1[i - 1] == s2[j - 1])
{
//可以选取该字符,更新最大值:
//前i-1和j-1的最大和 + 当前字符的ASCII值
dp[i][j] = max(dp[i][j], dp[i - 1][j - 1] + s1[i - 1]);
}
}
}
//3.计算总ASCII和
int sum = 0;
//累加s1所有字符的ASCII值
for(auto s : s1) sum += s;
//累加s2所有字符的ASCII值
for(auto s : s2) sum += s;
//4.返回最终结果
//最小删除和 = 总ASCII和 - 2*最大公共子序列ASCII和
//(公共子序列的字符不需要删除,两边都要保留,因此减去两倍)
return sum - dp[m][n] - dp[m][n];
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
// 解题类:两个字符串的最小 ASCII 删除和
// 核心思路:转化为求【最大 ASCII 和的公共子序列】
// 最小删除和 = 两个字符串总 ASCII 和 - 2 * 最大公共子序列 ASCII 和
class Solution
{
public:
// 函数功能:计算使 s1 和 s2 相等所需删除的字符的最小 ASCII 值之和
int minimumDeleteSum(string s1, string s2)
{
// 1. 创建 dp 表
int m = s1.size(), n = s2.size();
// dp[i][j] 表示:
// s1 的前 i 个字符 和 s2 的前 j 个字符中,
// 最大 ASCII 和的公共子序列的 ASCII 总和
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// 2. 填表
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 情况1:不选当前字符
dp[i][j] = max(dp[i][j - 1], dp[i - 1][j]);
// 情况2:当前字符相等,可以选取
if (s1[i - 1] == s2[j - 1])
{
dp[i][j] = max(dp[i][j], dp[i - 1][j - 1] + s1[i - 1]);
}
}
}
// 3. 计算两个字符串的 ASCII 总和
int sum = 0;
for (char ch : s1)
{
sum += ch;
}
for (char ch : s2)
{
sum += ch;
}
// 4. 返回最终结果
return sum - 2 * dp[m][n];
}
};
void runTest(Solution& solution, string s1, string s2, int expected)
{
int result = solution.minimumDeleteSum(s1, s2);
cout << "s1 = \"" << s1 << "\"" << endl;
cout << "s2 = \"" << s2 << "\"" << endl;
cout << "最小 ASCII 删除和 = " << result << endl;
cout << "期望结果 = " << expected << endl;
if (result == expected)
{
cout << "测试通过" << endl;
}
else
{
cout << "测试失败" << endl;
}
cout << "------------------------" << endl;
}
int main()
{
Solution solution;
// 测试用例1:经典示例
// 删除 s1 中的 's',ASCII = 115
// 删除 s2 中的 't',ASCII = 116
// 总和 = 231
runTest(solution, "sea", "eat", 231);
// 测试用例2:经典示例
runTest(solution, "delete", "leet", 403);
// 测试用例3:两个字符串完全相同,不需要删除
runTest(solution, "abc", "abc", 0);
// 测试用例4:没有公共字符,需要全部删除
// "abc" ASCII 和 = 97 + 98 + 99 = 294
// "def" ASCII 和 = 100 + 101 + 102 = 303
// 总和 = 597
runTest(solution, "abc", "def", 597);
// 测试用例5:其中一个字符串为空
// 需要删除 "abc" 的全部字符:97 + 98 + 99 = 294
runTest(solution, "abc", "", 294);
// 测试用例6:另一个字符串为空
// 需要删除 "abc" 的全部字符:97 + 98 + 99 = 294
runTest(solution, "", "abc", 294);
// 测试用例7:两个字符串都为空
runTest(solution, "", "", 0);
// 测试用例8:存在多个可选公共子序列
// 最优保留 "aa",删除 b 和 c
// 'b' + 'c' = 98 + 99 = 197
runTest(solution, "aab", "aac", 197);
// 测试用例9:大小写不同,ASCII 不同
// 'A' = 65, 'a' = 97
// 没有相同字符,需要全部删除:65 + 97 = 162
runTest(solution, "A", "a", 162);
return 0;
}
9.最长重复子数组(OJ题)

算法思路:解法(动态规划):
子数组是数组中连续的一段,我们习惯上以某一个位置为结尾来研究.由于是两个数组,因此我们可以尝试:以第一个数组的 i 位置为结尾以及第二个数组的 j 位置为结尾来解决问题.
1.状态表示:
dp[i][j] 表示以第一个数组的 i 位置为结尾,以及第二个数组的 j 位置为结尾公共的、长度最长的子数组的长度.
2.状态转移方程:
对于 dp[i][j],当 nums1[i] == nums2[j] 的时候,才有意义,此时最长重复子数组的长度应该等于 1 加上除去最后一个位置时,以 i - 1, j - 1 为结尾的最长重复子数组的长度.
因此,状态转移方程为:dp[i][j] = 1 + dp[i - 1][j - 1]
3.初始化:
为了处理越界的情况,我们可以添加一行和一列,dp 数组的下标从 1 开始,这样就无需额外初始化.
- 第一行表示第一个数组为空,此时没有重复子数组,因此里面的值设置成
0即可; - 第一列也是同理.
4.填表顺序:
根据状态转移,我们需要从上往下填每一行,每一行从左往右.
5.返回值:
根据状态表示,我们需要返回 dp 表里面的最大值.

核心代码
cpp
//解题类:最长重复子数组(连续公共子数组)
//核心:子数组是连续的,子序列是不连续的,本题要求连续
class Solution
{
public:
//函数功能:求两个数组的【最长连续公共子数组】的长度
int findLength(vector<int>& nums1, vector<int>& nums2)
{
//1.创建 dp 表
//获取两个数组的长度
int m = nums1.size(), n = nums2.size();
//dp[i][j]:状态定义
//表示【nums1前i个元素】和【nums2前j个元素】中,
//以nums1[i-1]、nums2[j-1]结尾的【最长连续公共子数组】的长度
//初始化:所有值默认为0(空数组的公共长度为0)
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
//2.遍历填表 + 记录最大值
//存储最终结果:最长连续公共子数组的长度
int ret = 0;
//遍历nums1的所有长度i
for(int i = 1; i <= m; i++)
{
//遍历nums2的所有长度j
for(int j = 1; j <= n; j++)
{
//核心:子数组要求连续,只有当前元素相等时才更新
if(nums1[i - 1] == nums2[j - 1])
{
//状态转移:当前元素相等,长度 = 前一个位置的长度 + 1
dp[i][j] = dp[i - 1][j - 1] + 1;
//填表过程中实时更新最大值,无需最后遍历
ret = max(ret, dp[i][j]);
}
//元素不相等时:dp[i][j] 保持默认值 0(连续中断,重新计数)
}
}
//4.返回最终结果
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 解题类:最长重复子数组,连续公共子数组
// 核心:子数组是连续的,子序列是不连续的,本题要求连续
class Solution
{
public:
// 函数功能:求两个数组的【最长连续公共子数组】的长度
int findLength(vector<int>& nums1, vector<int>& nums2)
{
// 1. 创建 dp 表
int m = nums1.size(), n = nums2.size();
// dp[i][j] 表示:
// nums1 前 i 个元素 和 nums2 前 j 个元素中,
// 以 nums1[i - 1]、nums2[j - 1] 结尾的
// 最长连续公共子数组的长度
vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));
// 2. 遍历填表 + 记录最大值
int ret = 0;
for (int i = 1; i <= m; i++)
{
for (int j = 1; j <= n; j++)
{
// 只有当前元素相等时,连续公共子数组才能延续
if (nums1[i - 1] == nums2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
ret = max(ret, dp[i][j]);
}
// 如果不相等,dp[i][j] 保持为 0
// 表示连续关系中断
}
}
// 3. 返回最终结果
return ret;
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (int i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
{
cout << ", ";
}
}
cout << "]";
}
void runTest(Solution& solution, vector<int> nums1, vector<int> nums2, int expected)
{
int result = solution.findLength(nums1, nums2);
cout << "nums1 = ";
printVector(nums1);
cout << endl;
cout << "nums2 = ";
printVector(nums2);
cout << endl;
cout << "最长连续公共子数组长度 = " << result << endl;
cout << "期望结果 = " << expected << endl;
if (result == expected)
{
cout << "测试通过" << endl;
}
else
{
cout << "测试失败" << endl;
}
cout << "------------------------" << endl;
}
int main()
{
Solution solution;
// 测试用例1:经典示例
// 最长连续公共子数组是 [3, 2, 1]
runTest(solution,
{1, 2, 3, 2, 1},
{3, 2, 1, 4, 7},
3);
// 测试用例2:两个数组完全相同
runTest(solution,
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
5);
// 测试用例3:没有公共元素
runTest(solution,
{1, 2, 3},
{4, 5, 6},
0);
// 测试用例4:只有一个公共元素
runTest(solution,
{1, 2, 3},
{7, 8, 2},
1);
// 测试用例5:多个重复元素
runTest(solution,
{0, 0, 0, 0, 0},
{0, 0, 0},
3);
// 测试用例6:公共子数组出现在中间
// 最长连续公共子数组是 [2, 3, 4]
runTest(solution,
{9, 8, 2, 3, 4, 7},
{1, 2, 3, 4, 5},
3);
// 测试用例7:公共子数组出现在末尾
// 最长连续公共子数组是 [4, 5, 6]
runTest(solution,
{1, 2, 3, 4, 5, 6},
{8, 9, 4, 5, 6},
3);
// 测试用例8:其中一个数组为空
runTest(solution,
{},
{1, 2, 3},
0);
// 测试用例9:两个数组都为空
runTest(solution,
{},
{},
0);
// 测试用例10:注意连续和不连续的区别
// 公共子序列可以是 [1, 2, 3],但连续公共子数组最长只有 1
runTest(solution,
{1, 9, 2, 8, 3},
{1, 2, 3},
1);
return 0;
}

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容:【动态规划算法】(背包问题经典模型与解题套路)
每日心灵鸡汤:"别回头,别停留,往前走,我会站在你身后"
其实选错了就是选错了.不要总是一遍遍去想"如果当初怎样就好了".人生不可能每个选择都正确,很多事就算能重来一遍,以当时的心态和阅历还是会做出同样的选择,避免不了同样的结果.人生是单向不可逆的轨迹,所以人才会一直憧憬未知的路径,重来一遍你也未必会满意重来后的自己.不用回头看,也不必批判当时的自己.世事自有因果,冥冥之中必有安排.
