01
背景
AutoMQ1 作为一款流系统,被广泛应用在客户的核心链路中,对可靠性的要求非常的高。所以我们需要一套模拟真实生产场景、长期运行的测试环境,在注入各种故障场景的前提下验证 SLA 的可行性,为新版本的发布和客户的使用提供信心保证。基于这样的考虑,我们研发了一套针对流系统的自动化持续测试平台 Marathon。在实现 Marathon 这套框架之前,我们提炼出三个设计原则:
-
易拓展:随着被测系统的发展,支持测试用例甚至部署模式的拓展
-
可观测:既然是测试平台,发现 Bug 可以说是一种必然。那么就需要有足够的 Debug 手段找到根因排除问题
-
低成本:测试场景的流量模式会有很大的差别,对资源的占用应该随着流量变化弹性增减
之后的技术选型、架构设计都将围绕上述三原则来执行。
02
架构总览
首先来看一下总体架构图
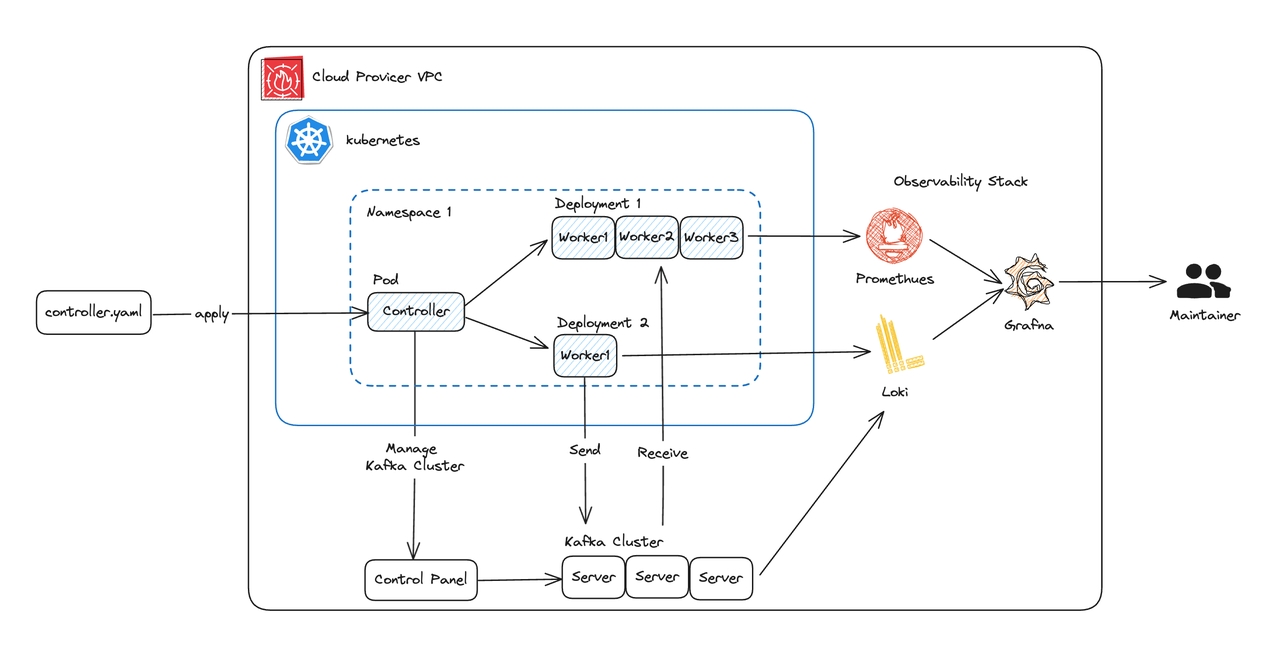
Marathon 项目的 Controller 和 Worker 以及 AutoMQ 企业版控制面都位于 K8S 中:
-
Controller 调用位于同一 VPC 的 AutoMQ 企业版控制面接口管理 Kafka 集群的创建/变更/销毁,同时负责测试任务编排与管理 Worker 的数量与配置。AutoMQ 控制面
-
Worker:运行 Kafka 客户端产生任务所需的负载,同时负责可观测数据的上报和客户端侧的 SLA 检查
-
AutoMQ 企业版控制面:为数据面提供完整产品化能力包括集群生命周期管理、可观测性、安全审计、集群迁移等能力。Marathon 主要使用其提供的集群生命周期管理相关的 OpenAPI 来创建、变更和销毁集群,辅助整个测试流程的执行
Controller 和 Worker 的架构被设计为一个分布式系统:Controller 类似 K8S 的 Operator,通过调谐循环动态调整 Worker 的数量和配置来匹配任务的需要;Worker 则是一个完全无状态的系统,通过产生各种事件来通知 Controller 进行相应的处理逻辑。这样的设计使得整个架构具有非常优秀的灵活性,可以支持任务的拓展需求。同时轻量、灵活的 Worker 可以进行动态弹性甚至使用 Spot 实例2运行,这极大的降低了运行成本,使得超大规模弹性任务变得可行
03
技术细节
3.1 运行 Controller
启动流程Controller 的定位是资源管理与任务编排,所以启动时最先运行的就是各种资源的管理器:
-
服务发现:监测 Worker 的运行状态
-
事件总线:与 Worker 通信的渠道
-
告警服务:通知管理员有需要关注的事件
-
Kafka 集群管理器:探测 Kafka 集群状态;监听 Kafka 版本发布并执行升级
-
信号处理器:捕获 SIG_TERM 进入终止流程,回收创建的资源
Controller 支持多种 Kafka 集群类型:
-
已存在的 Kafka 集群:对指定集群快速验证功能是否可用
-
托管 Kafka 集群:由 Controller 管理集群的整个生命周期,托管的 Kafka 集群依赖 AutoMQ 控制面的能力创建/销毁
任务循环Controller 具有类似 K8S Operator 的机制,通过调谐循环根据任务需要动态调整 Worker 的数量与配置。每个任务对应一个测试场景,使用代码编写任务对 Kafka 收发消息,构造不同的流量模型进行黑盒测试每个任务分为四个阶段,在同一个线程中依次运行:
-
创建资源
-
预热
-
运行任务负载
-
回收资源
Marathon 框架提供了一系列工具类来简化任务的编写,包括创建 Kafka topic,查询消费堆积,修改 Worker 流量,等待某个指定事件,对 Kafka 集群注入故障等等。通过这些工具以及 Worker 可以模拟任意规格的流量,以及多种特殊场景,比如我们的任务集中有对大规模冷读的测试;强制关闭某个 Kafka 节点并验证数据完整性的测试等等通过代码编写任务可以非常灵活的构造想要的场景,唯一的限制是不得编写任何不可中断的阻塞操作。Controller 在必要时(如运行 Worker 的 Spot 实例被回收)会中断任务线程并回收资源,然后重试当前任务
3.2 管理 Worker
Worker 的创建与服务发现
对 Kafka 集群执行压力测试需要数十 GB/s 规模的流量,这显然不是单台机器可以满足的。设计一个分布式系统势在必行,那么首先要考虑的就是如何发现新创建的 Worker 以及如何进行通信。既然我们选择基于 K8S 编排整个系统,很自然的就会考虑使用 K8S 的机制来进行服务发现
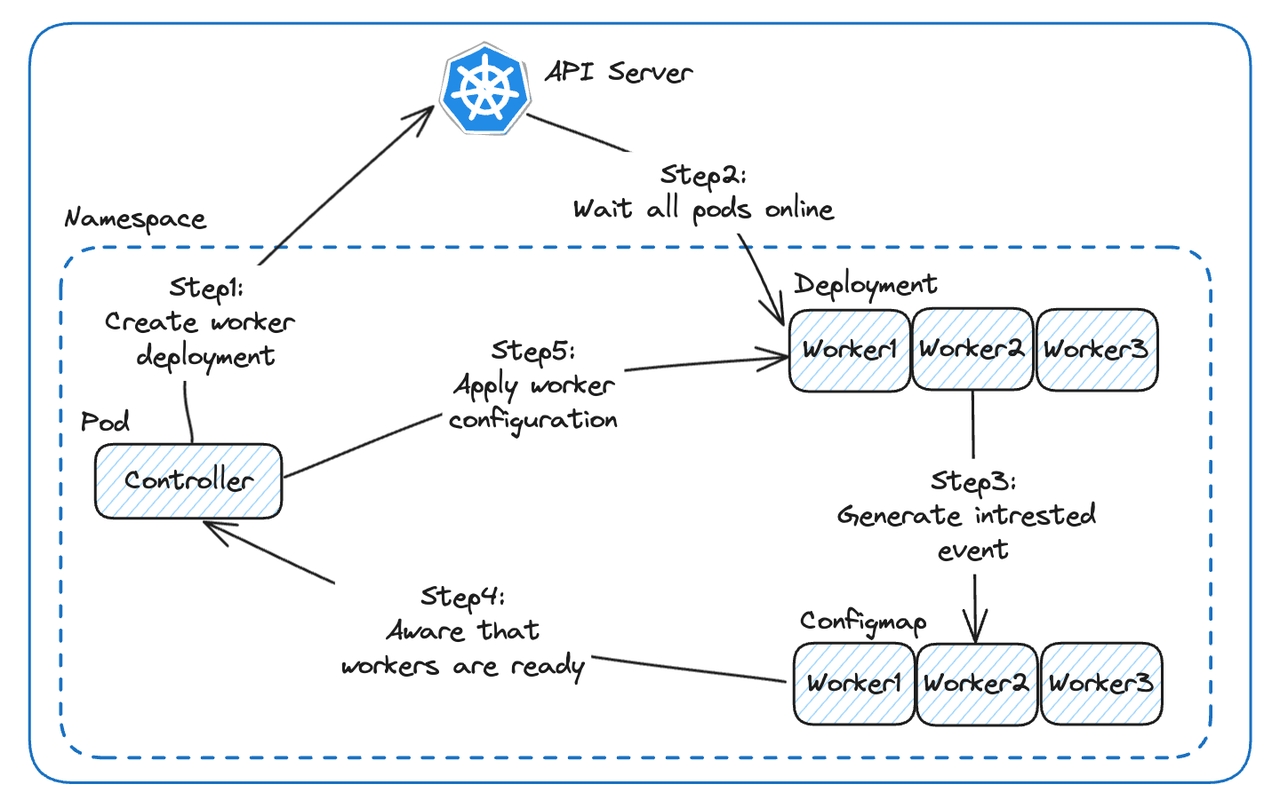
我们将一组具有相同配置的 Worker 定义为一个 Worker Deployment,对应 K8S 的 Deployment 概念,每个 Worker 对应这个 Deployment 中的一个 Pod。这样 Controller 创建 Worker 就相当于向 API Server 提交一个 Deployment 并等待所有 Pod 上线(上图 Step 1、Step 2),K8S 的节点组会按需扩容,生产出我们需要的 Sopt 实例虚拟机每个 Worker 启动后会生成一个 Configmap,描述它关心的所有 Event 列表(Step 3),此时 Worker 只关心初始化事件。Controller 通过 K8S 提供的 Watch API 订阅到有新的 Configmap 生成(Step 4),然后 Controller 会向这些 Worker 发送包含配置信息的初始化事件(Step 5)至此,Worker 的服务发现和初始化流程就完成了,后续 Worker 通过更新 Configmap 来订阅它所关心的事件。服务发现机制赋予了 Controller 动态创建 Worker 的能力,也是下一节中事件总线建立的基石
事件总线
通过上一节的服务发现机制,Controller 已经得知每个 Worker 的服务地址(组合 Pod IP 和端口)和这些 Worker 关心的事件(订阅 Configmap 变更),那么 Controller 就可以向特定的 Worker 推送事件了
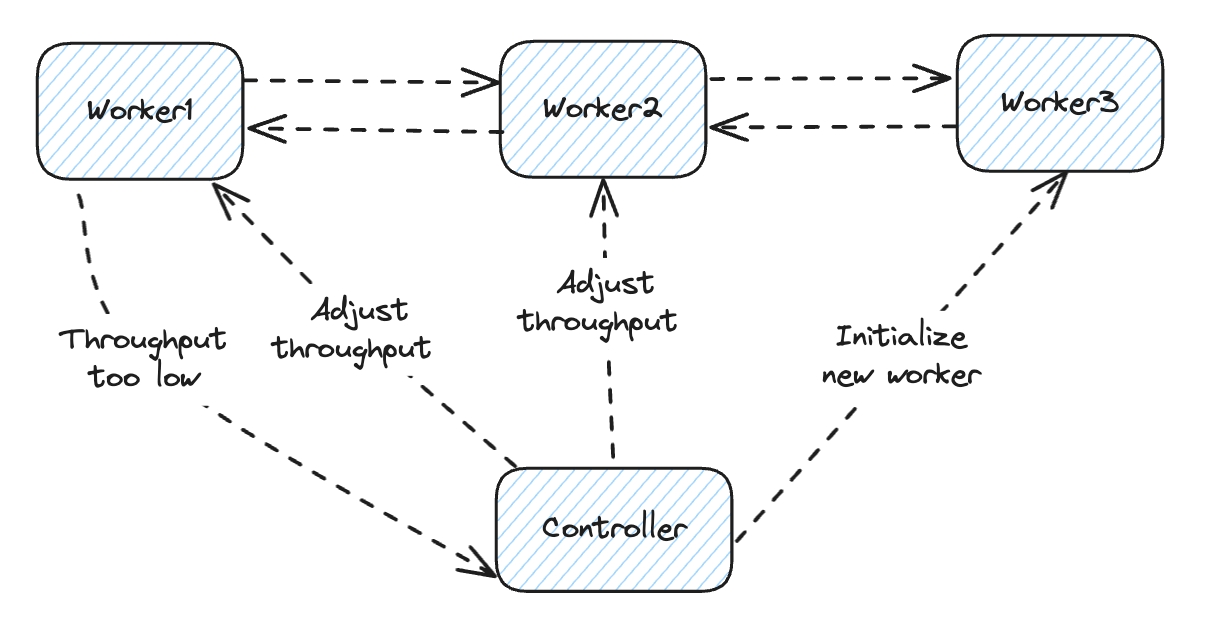
市面上有众多的 RPC 框架,Marathon 选用的是 Vert.x。它不仅支持一般的 request-reply 通信模型,也支持多接收者的 publish-subscribe 模型,这在一个事件需要被多个节点感知的场景下十分有用(例如上图中的 Adjust throughput 指令)
Spot 实例应用
从上两节不难看出 Worker 可以根据任务需要动态创建,Worker 上执行的任务也可以通过事件总线下发(上图中 Initialize new worker 指令)。也就是说 Worker 本身是无状态的并且可以简单的生产和销毁,这就给 Worker 使用 Spot 实例带来了可能(Controller 资源占用极小,可以使用一个小规格的 Reserve 实例运行)

Controller 会使用 K8S 提供的 Watch API 监测 Pod 的状态,当发现 pod 被异常终止会停止并重新运行当前任务。在 Spot 实例回收时可以及时发现,并且排除对任务的影响。Spot 实例来自于云厂商的闲置资源,相比于 Reserve 实例具有非常大的价格优势。通过对 Spot 实例的使用,可以极大降低 Marathon 这种低稳定性需求且长时间运行任务的使用成本
3.3 测试场景
场景描述与资源管理
Marathon 中的测试场景用代码的形式描述,具体来说是继承 Abstract 类,指定测试用例的配置并实现其生命周期方法。以下是目前的一些测试场景:

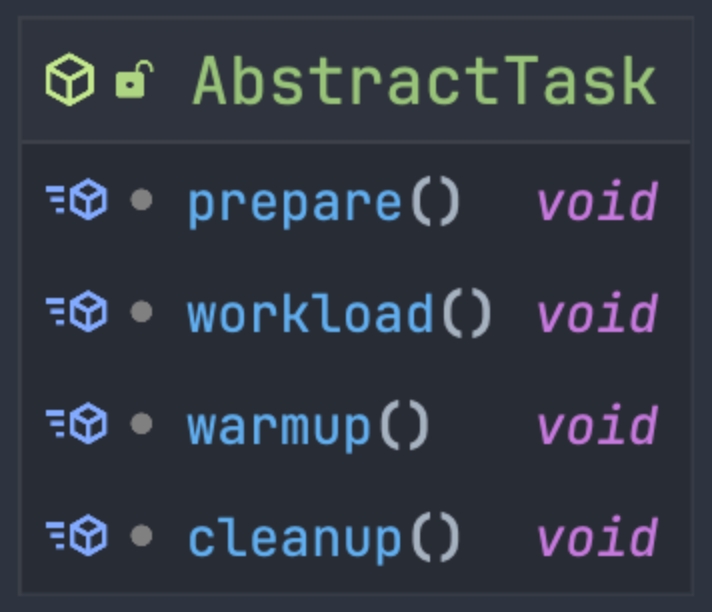
测试用例的配置通过泛型指定,以 CatchUpReadTask 为例,这个类的定义是public class CatchUpReadTask extends AbstractTask <CatchUpReadTaskConfig>对应的配置类 CatchUpReadTaskConfig 中定义了运行这个任务所需的参数,可以由用户动态指定每个任务场景都是通过实现以下生命周期方法描述一个特定的流量模型:
-
prepare:创建任务所需的资源
-
warmup:预热 Worker 和待测试的集群
-
workload:生成任务负载
-
cleanup:销毁任务中创建的资源
还是以 CatchUpReadTask 为例:

Workload 阶段是不同任务场景最本质的区别,CatchUpReadTask 需要构造合适的堆积数据量再断言在 5 分钟内完成消费,对于 ChaosTask 就会变成杀掉一个节点断言 1 分钟内其上的分区可以转移到其他节点。为了满足不同任务的需要,Marathon 框架提供了一系列的工具帮助编写测试场景,比如在上图中出现的部分工具:
-
KafkaUtils:创建/删除 topic(Kafka 集群中的一种资源)
-
WorkerDeployment:创建 Worker
-
ThroughputChecker:持续检查流量是否符合预期
-
AwaitUtils:验证五分钟内是否能消费完堆积的消息
任务编排
有了 AbstractTask 的诸多实现类,就具备了多种测试场景。为了让 Controller 能够运行以上场景,还需要编排不同的任务阶段乃至于不同的任务。

再来看下 AbstractTask 的其他方法可以发现它继承了 Runnable 接口,通过重写 run 方法来依次执行 prepare、warmup、workload、cleanup 四个生命周期,这样就可以将 Task 交给一个线程来执行Controller 启动时会创建一个任务循环,根据用户需要创建出对应的 Task 对象后调用 start 方法来启动一个新线程运行该任务,然后 Controller 会调用 join 方法等待 Task 的生命周期结束,再继续运行下一个任务。周而复始重复运行每个任务,持续保障被测系统的稳定性当遇到不可恢复的错误(如 Spot 实例被回收)或手动执行运维命令中断任务时 Controller 调用当前 Task 的 interrupt 方法中断运行任务的线程,此时任务会被停止。任务循环会根据需要回收资源、继续运行下一个任务或阻塞等待后续指令
3.4 断言、可观测性与告警
断言
框架根据检测的指标不同分为以下三种断言:
-
客户端断言:消息消息连续性断言、事务隔离级别断言等
-
服务端状态断言:流量阈值断言、负载均衡断言等
-
基于时间断言:堆积消化时间断言、任务超时断言等
如果上述断言规则不能满足需要,也可实现 Checker 接口定制所需的断言
可观测性
既然是建设稳定性保证的系统,那么可观测手段是必不可少的,不然只能盯着告警望洋兴叹。Marathon 框架不仅采集 Controller 和 Worker 的运行信息,而且无侵入的收集被测系统的可观测数据。借助 Grafana 的可视化能力,可以方便的可视化查看 metrics、Log、Profiling 等可观测数据
Metrics

Log

Profiling
告警
作为一个事件驱动的系统,在断言不满足时会生成对应的事件。这些事件分别有不同的严重级别,其中需要运维人员关注的事件会作为告警发送到 OnCall 群组中以供查看。配合上可观测数据可以帮助快速、准确的定位问题,先于我们的客户发现并解决潜在风险并持续优化性能

04
总结与展望
4.1 Spot 实例、K8S 与无状态应用
回顾下我们的设计三原则:易拓展、可观测、低成本。这要求 Marathon 框架在设计上就要面向运维考虑:
-
根据任务场景不同如何构建弹性负载?
-
负载不同消耗的底层机器资源也有很大区别,底层资源能否随着负载动态扩缩?
-
成本分则为使用成本和运行成本
使用成本方面如何快速创建/销毁,降低用户的门槛? 运行成本方面如何使用尽量少的资源构建出所需的负载?Marathon 采用 Spot 实例、K8s 与无状态 Worker 结合的方式解答上述问题,这三者分别对应底层资源层面、调度运维层面与应用层面既然又要弹性又要价廉,那么云上的 Spot 实例自然是不二之选,只有同等规格下 Reserve 实例 10% 的价格。但是 Spot 实例并非是毫无代价,不可预测的实例回收对应用的架构设计是很大的挑战。但是对 Marathon 来说,可用性是可以取舍的,大不了重新运行下任务即可简化设计的最佳办法就是压根不设计:Marathon 聚焦场景描述与任务编排,而调度交给 K8S 来做。Marathon 只关注我需要多大的负载,每个单位的负载需要多少核的资源;而底层资源的弹性交给 K8S 来负责,只需事先申请一个 Spot 实例节点组,然后专注于测试场景的逻辑即可然而能够利用 Spot 实例和 K8S 强大能力的前提是应用本身是无状态的,否则还需要操心状态的持久化与迁移。这也是 Worker 模块设计的出发点
4.2 测试场景泛化
Marathon 在很多模块的设计上都有很好的抽象,服务发现、任务调度、负载生成都能很好的迁移到其他场景:
-
服务发现:目前的服务发现基于 K8S API server 提供的 API,但数据结构抽象为 Node 和 Registration。前者对应 Worker 节点的地址和端口,后者对应每个 Worker 关心的事件。也就是说任何一个可以储存这两种数据结构的共享存储都可以作为服务发现组件,可以是 MySQL 也可以是 Redis
-
任务调度:目前 Worker 打包为 Docker image,使用 K8S Deployment 的形式部署。当然也可以打包成 AMI 通过云的接口直接启动 EC2,或是使用 vagrant 和 Ansible 等进行部署
-
负载生成:目前 Marathon 实现了 Kafka workload 作为每个 Worker 的负载,实际上就是根据 Controller 下发的配置启动对应数量的 Kafka client 收发消息,将 Kafka client 换成 RocketMQ client 甚至 HTTP client 的工作量并不大
依靠优秀的抽象能力设计,Marathon 对外部系统的依赖均是可插拔的。所以其不仅仅是 Kafka 的持续可靠性测试平台,也可以用很小的开发成本改头换面成为任何分布式系统的测试平台,运行在云上云下多种环境中
参考资料
1 AutoMQ: https://github.com/AutoMQ/automq
2 Spot Instance: https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/using-spot-instances.html
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq