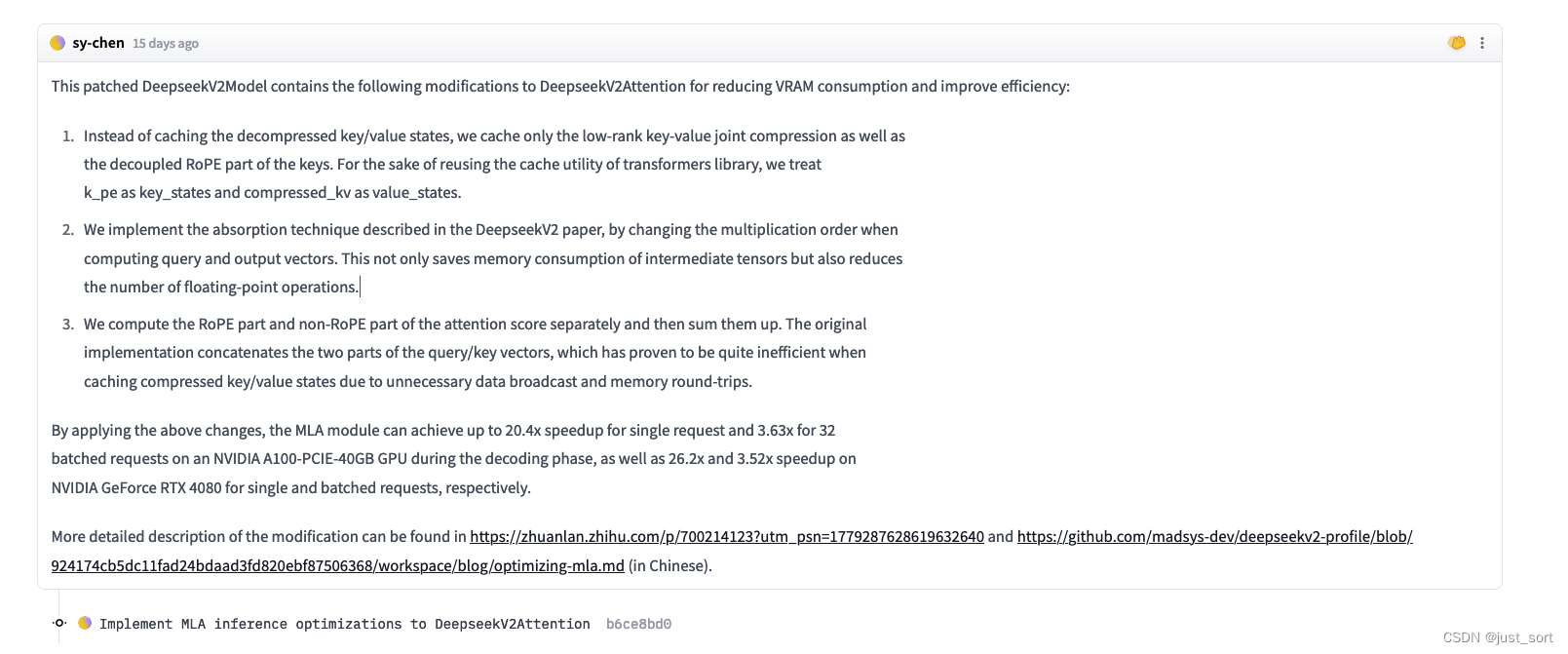
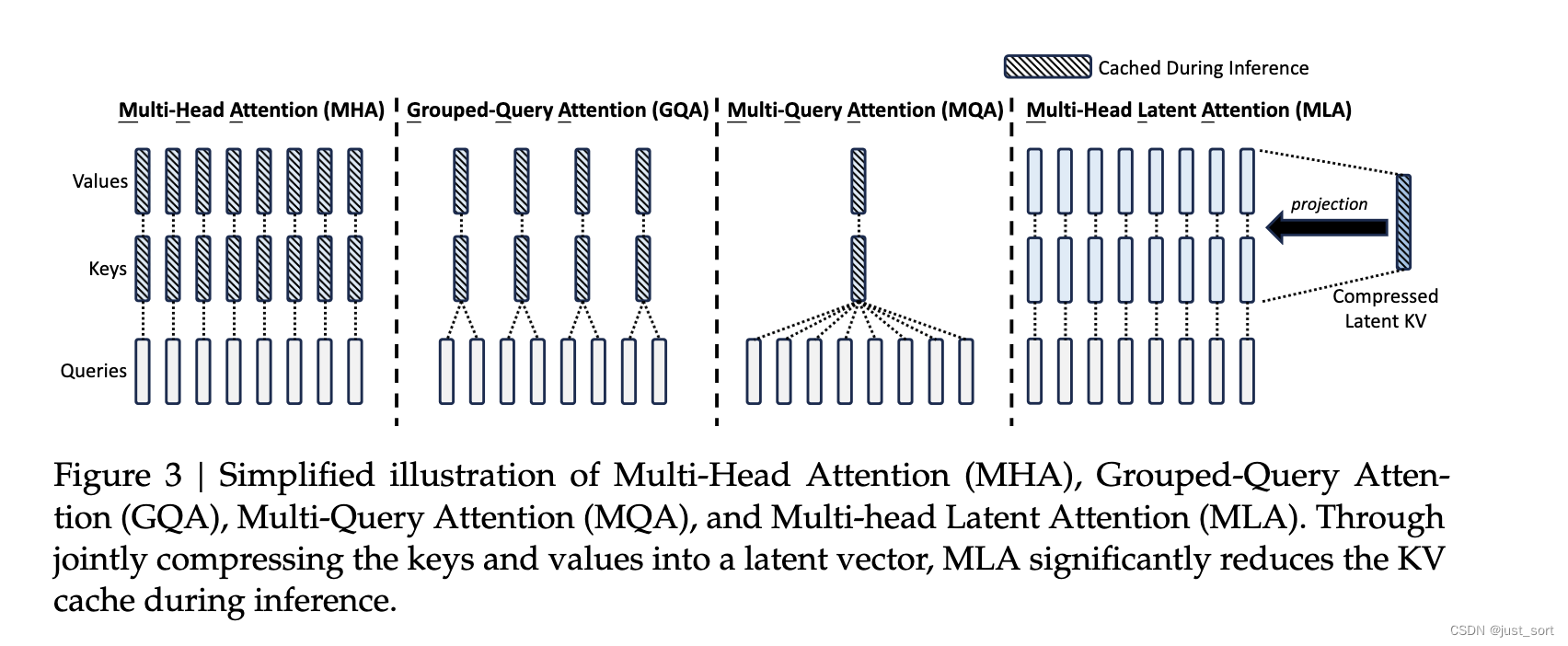
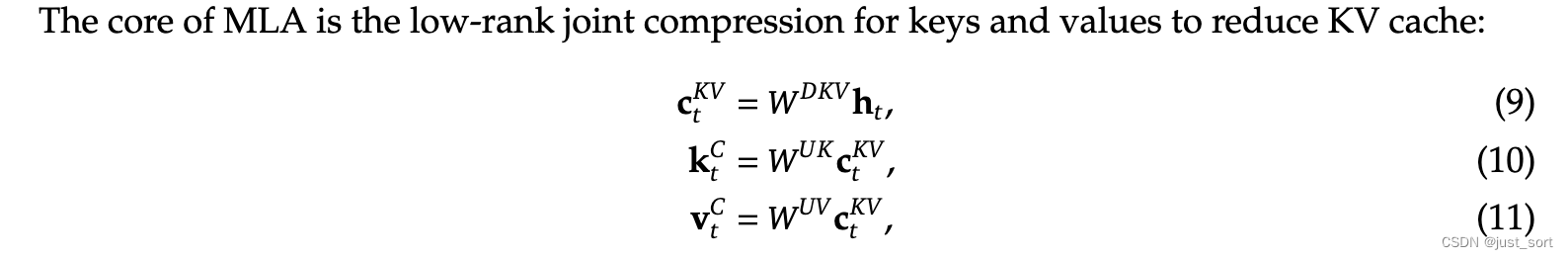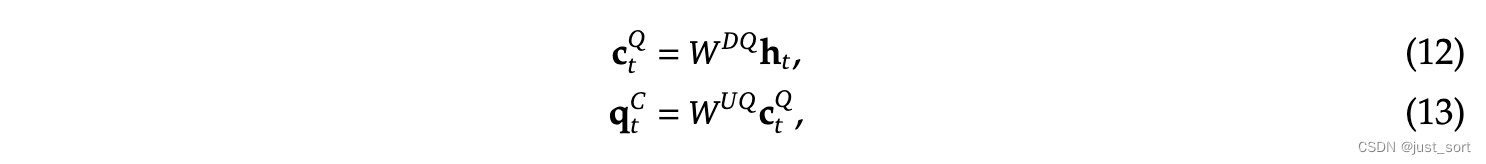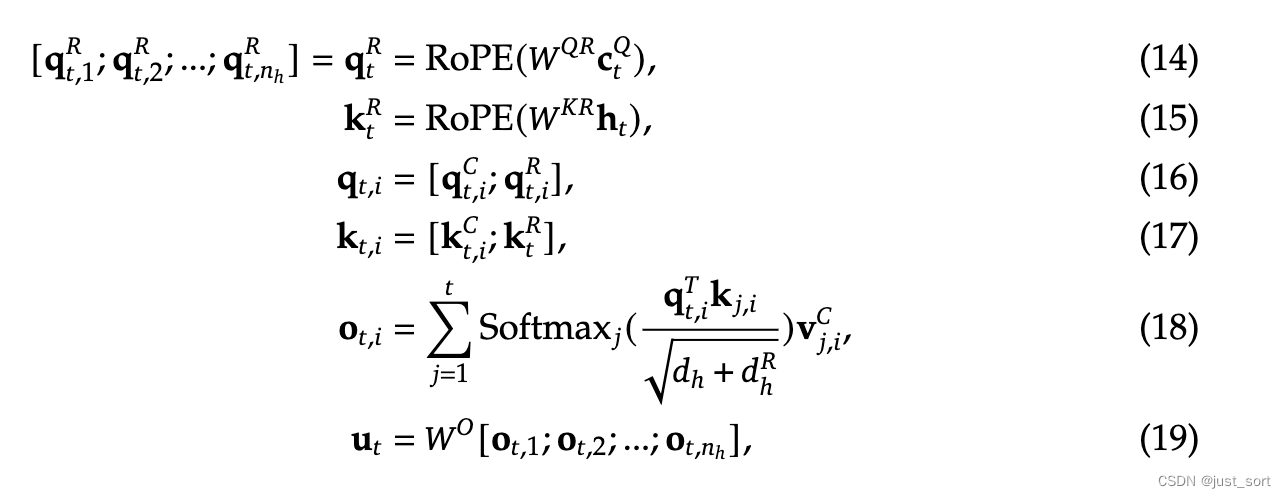首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应了完整公式中的具体行并且对每个操作前后的Tensor Shape变化也进行了解析。我们可以看到目前的官方实现在存储KV Cache的时候并不是存储隐向量,而是把隐向量都解压缩变成了标准的MHA的KV Cache,实际上是完全不能节省显存的。接着,就继续学习了一下清华大学的ZHANG Mingxing组实现的MLA矩阵吸收的工程实现,在这一节也详细分析了原理包括 W U K W^{UK} WUK和 W U V W_{UV} WUV分别如何吸收到 W U Q W_{UQ} WUQ和 W o W_o Wo中,分析了实现了矩阵吸收的每行代码的原理以及操作发生前后相关Tensor的维度变化。接着,对矩阵吸收代码实现里的矩阵乘法的性质进行分析,可以看到MLA在大多数阶段都是计算密集型而非访存密集型的。最后引用了作者团队的Benchmark结果,以及说明为何不是直接保存吸收后的大投影矩阵,而是在forward里面重新计算两个矩阵的吸收。
假设batch_size为1,另外由于是解码阶段,输入只有一个token,所以序列的长度也是1,所以输入可以表示为 h t ∈ R d h_t \in \mathbb{R}^d ht∈Rd。接着假设embedding词表维度为 d d d,并且有 n h n_h nh表示注意力头的数量, d h d_h dh表示每个注意力头的维度。
t表示解码阶段当前是第几个token。
然后通过 W Q , W K , W V ∈ R d h n h × d W^Q, W^K, W^V \in \mathbb{R}^{d_h n_h \times d} WQ,WK,WV∈Rdhnh×d三个参数矩阵得到 q t , k t , v t ∈ R d h n h q_t, k_t, v_t \in \mathbb{R}^{d_h n_h} qt,kt,vt∈Rdhnh,具体方法就是三个矩阵乘:
q t = W Q h t , k t = W K h t , v t = W V h t , q_t = W^Q h_t, \newline k_t = W^K h_t, \newline v_t = W^V h_t, qt=WQht,kt=WKht,vt=WVht,
在 MHA 的计算中,这里的 q t , k t , v t q_t, k_t, v_t qt,kt,vt 又会分割成 n h n_h nh 个注意力头,即:
q t , 1 ; q t , 2 ; ⋯ ; q t , n h = q t k t , 1 ; k t , 2 ; ⋯ ; k t , n h = k t v t , 1 ; v t , 2 ; ⋯ ; v t , n h = v t \begin{bmatrix} q_{t,1}; q_{t,2}; \cdots ; q_{t,n_h} \end{bmatrix} = q_t \newline \begin{bmatrix} k_{t,1}; k_{t,2}; \cdots ; k_{t,n_h} \end{bmatrix} = k_t \newline \begin{bmatrix} v_{t,1}; v_{t,2}; \cdots ; v_{t,n_h} \end{bmatrix} = v_t qt,1;qt,2;⋯;qt,nh=qtkt,1;kt,2;⋯;kt,nh=ktvt,1;vt,2;⋯;vt,nh=vt
这里 q t , i , k t , i , v t , i ∈ R d h q_{t,i}, k_{t,i}, v_{t,i} \in \mathbb{R}^{d_h} qt,i,kt,i,vt,i∈Rdh 分别表示query、key和value的第 i i i个头的计算结果。
接下来就是计算注意力分数和输出了,公式如下:
o t , i = ∑ j = 1 t Softmax j ( q t , i k j , i d h ) v j , i , u t = W O o t , 1 ; o t , 2 ; ⋯ ; o t , n h o_{t,i} = \sum_{j=1}^{t} \text{Softmax}j \left( \frac{q{t,i} k_{j,i}}{\sqrt{d_h}} \right) v_{j,i}, \newline u_t = W^O o_{t,1}; o_{t,2}; \\cdots ; o_{t,n_h} ot,i=j=1∑tSoftmaxj(dh qt,ikj,i)vj,i,ut=WOot,1;ot,2;⋯;ot,nh
这里 W O ∈ R d × d h n h W^O \in \mathbb{R}^{d \times d_h n_h} WO∈Rd×dhnh 表示输出映射矩阵。从上面的公式可以看出来,对于当前的第 t t t 个 token的query,会和 t t t之前所有token的key, value做注意力计算,并且由于token by token的生成 t t t之前所的有token对应的 k k k, v v v我们都可以Cache下来,避免重复计算,这就是KV Cache的由来。
对于一个 l l l层的标准MHA的网络来说,每个token需要的KV Cache大小为 2 n h d h l 2n_hd_hl 2nhdhl,其中2表示bf16的字节。
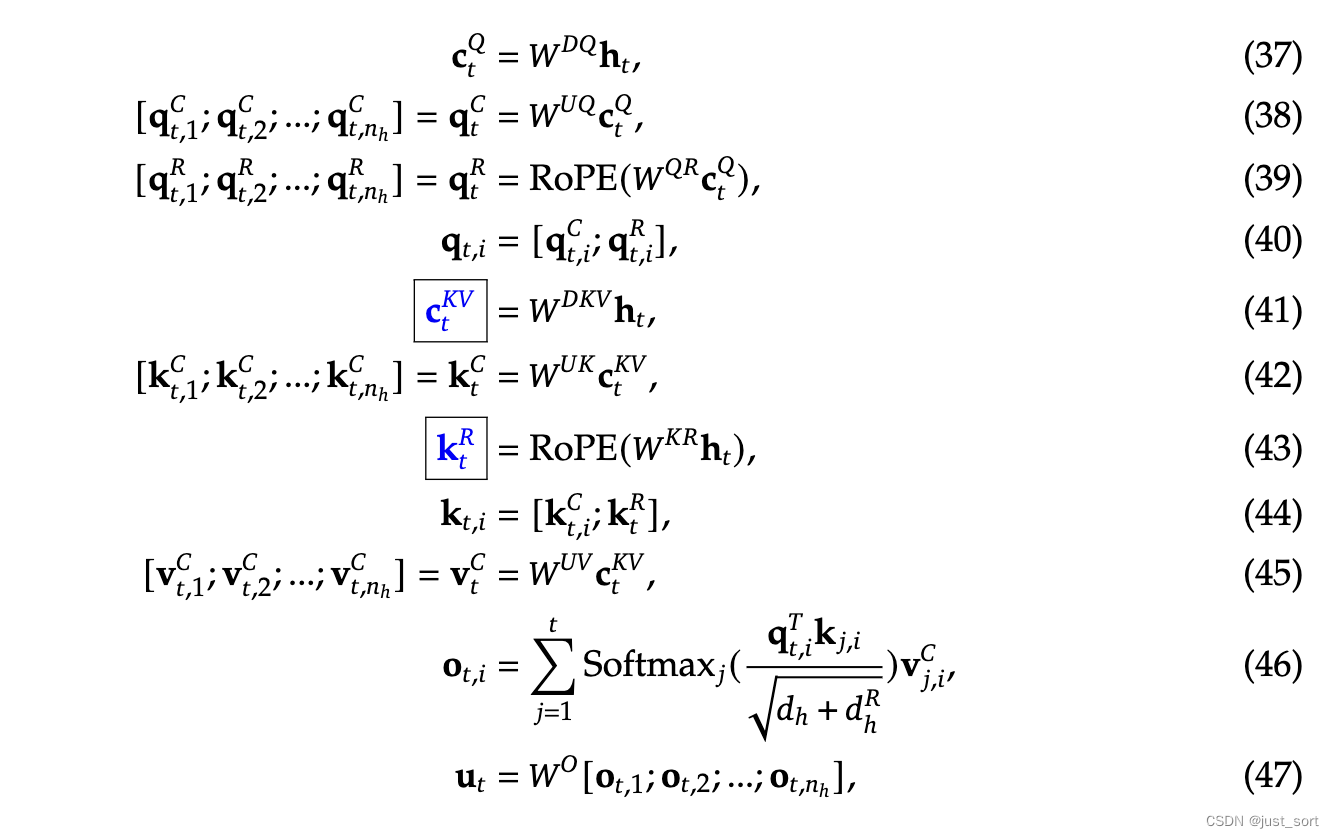
c t K V ∈ R d c \mathbf{c}_{t}^{KV} \in \mathbb{R}^{d_c} ctKV∈Rdc:表示对 key 和 value 压缩后的隐向量 latent vector ,这里 d c ( ≪ d h n h ) d_c (\ll d_h n_h) dc(≪dhnh) 表示 KV Cache压缩的维度。
W D K V ∈ R d c × d \mathbf{W}^{DKV} \in \mathbb{R}^{d_c \times d} WDKV∈Rdc×d:表示向下映射 down-projection 矩阵
W U K , W U V ∈ R d h n h × d c \mathbf{W}^{UK}, \mathbf{W}^{UV} \in \mathbb{R}^{d_h n_h \times d_c} WUK,WUV∈Rdhnh×dc:表示向上映射 up-projection 矩阵
这样在推理时,只需要缓存隐向量 c t K V \mathbf{c}_{t}^{KV} ctKV 即可,因此 MLA 对应的每一个 token 的 KV Cache 参数只有 2 d c l 2d_c l 2dcl 个,其中 l l l是网络层数, 2 2 2是bfloat16的字节。
c t Q ∈ R d c ′ \mathbf{c}_{t}^{Q} \in \mathbb{R}^{d'_c} ctQ∈Rdc′:表示将 queries 压缩后的隐向量, d c ′ ( ≪ d h n h ) d'_c (\ll d_h n_h) dc′(≪dhnh) 表示 query 压缩后的维度
W D Q ∈ R d c ′ × d , W U Q ∈ R d h n h × d c ′ \mathbf{W}^{DQ} \in \mathbb{R}^{d'_c \times d}, \mathbf{W}^{UQ} \in \mathbb{R}^{d_h n_h \times d'_c} WDQ∈Rdc′×d,WUQ∈Rdhnh×dc′ 分别表示 down-projection 和 up-projection 矩阵
由于对 query 和 key 来说,RoPE 都是位置敏感的。如果对 k t C \mathbf{k}_{t}^{C} ktC 采用 RoPE,那么当前生成 token 相关的 RoPE 矩阵会在 W Q \mathbf{W}^{Q} WQ 和 W U K \mathbf{W}^{UK} WUK 之间,并且矩阵乘法不遵循交换律,因此在推理时 W U K \mathbf{W}^{UK} WUK 就无法整合到 W Q \mathbf{W}^{Q} WQ 中。这就意味着,推理时我们必须重新计算所有之前 tokens 的 keys,这将大大降低推理效率。
这里的 W U K \mathbf{W}^{UK} WUK 就整合到 W Q \mathbf{W}^{Q} WQ 请看下面截图的解释,来自苏神的博客。我会在下一大节再仔细讨论这个原理。
因此,DeepSeek2提出了解耦 RoPE 策略,具体来说:
使用额外的多头 queries q t , i R ∈ R d h R \mathbf{q}{t, i}^{R} \in \mathbb{R}^{d_h^R} qt,iR∈RdhR 以及共享的 key k t R ∈ R d h R \mathbf{k}{t}^{R} \in \mathbb{R}^{d_h^R} ktR∈RdhR 来携带 RoPE 信息,其中 d h R d_h^R dhR 表示解耦的 queries 和 key 的一个 head 的维度。
基于这种解耦的 RoPE 策略,MLA 遵循的计算逻辑为:
其中:
W Q R ∈ R d h R n h × d c ′ \mathbf{W}^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c'} WQR∈RdhRnh×dc′ 和 W K R ∈ R d h R × d \mathbf{W}^{KR} \in \mathbb{R}^{d_h^R \times d} WKR∈RdhR×d 分别表示计算解耦后的 queries 和 key 的矩阵
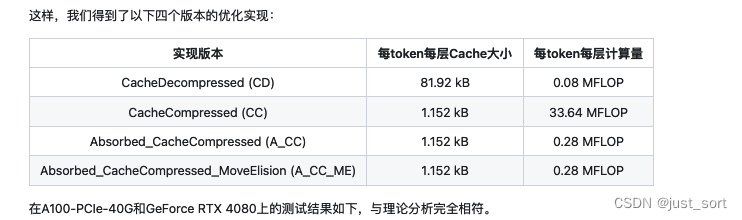
推理时,只需要缓存解耦后的 key 即可,当然还有上面的隐向量 c t K V \mathbf{c}_{t}^{KV} ctKV,因此对于单个 token 的 KV Cache 只包含 ( d c + d h R ) l (d_c + d_h^R)l (dc+dhR)l 个元素,这里没考虑层数和bf16的字节数。具体可以看一下Table 1的数据对比:
翻译一下:
表1 | 各种注意力机制中每个token的KV Cache对比。 n h n_h nh 表示注意力头的数量, d h d_h dh 表示每个注意力头的维度, l l l 表示层数, n g n_g ng 表示GQA中的组数, d c d_c dc 和 d h R d_h^R dhR 分别表示KV压缩维度和MLA中解耦后queries和key的每头维度。KV Cache的数量以元素的数量来衡量,而不考虑存储精度。对于DeepSeek-V2, d c d_c dc 被设置为 4 d h 4d_h 4dh 而 d h R d_h^R dhR 被设置为 d h 2 \frac{d_h}{2} 2dh。因此,其KV Cache等于只有2.25组的GQA,但其性能强于MHA。
atten_weights = q t ⊤ k t = ( W U Q c t Q ) ⊤ W U K c t K V = c t Q ⊤ W U Q ⊤ W U K c t K V \text{atten\weights} = \mathbf{q}{t}^\top \mathbf{k}{t} = (\mathbf{W}^{UQ} \mathbf{c}{t}^{Q})^\top \mathbf{W}^{UK} \mathbf{c}{t}^{KV} = \mathbf{c}{t}^{Q^\top} \mathbf{W}^{UQ^\top} \mathbf{W}^{UK} \mathbf{c}_{t}^{KV} atten_weights=qt⊤kt=(WUQctQ)⊤WUKctKV=ctQ⊤WUQ⊤WUKctKV
也就是说我们实际上不需要将低维的 c t K V \mathbf{c}_{t}^{KV} ctKV 展开再计算,而是直接将 W U K \mathbf{W}^{UK} WUK 通过结合律先和左边做乘法。
从0x4节的讲解已经知道kv_b_proj就是 W U K W^{UK} WUK 和 W U V W^{UV} WUV两部分,这里是把 W U K W^{UK} WUK吸收到 W U Q W^{UQ} WUQ,所以需要先把两者分离出来。注意到 self.kv_b_proj weight shape为 [kv_lora_rank, num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim)] = [512, 128*((128+64)-64+128)] = [512, 32768],所以kv_b_proj的shape为[num_heads,q_head_dim - qk_rope_head_dim + v_head_dim , kv_lora_rank], q_absorb的shape为[num_heads, qk_nope_head_dim , kv_lora_rank]=[128, 128, 512],同样out_absorb的shape为[num_heads, v_head_dim , kv_lora_rank]=[128, 128, 512]。
q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope) 这行代码中,q_nope的shape是[batch_size, num_heads, q_len, q_head_dim]。所以这行代码就是一个矩阵乘法,把 W U K W^{UK} WUK吸收到 W U Q W^{UQ} WUQ。
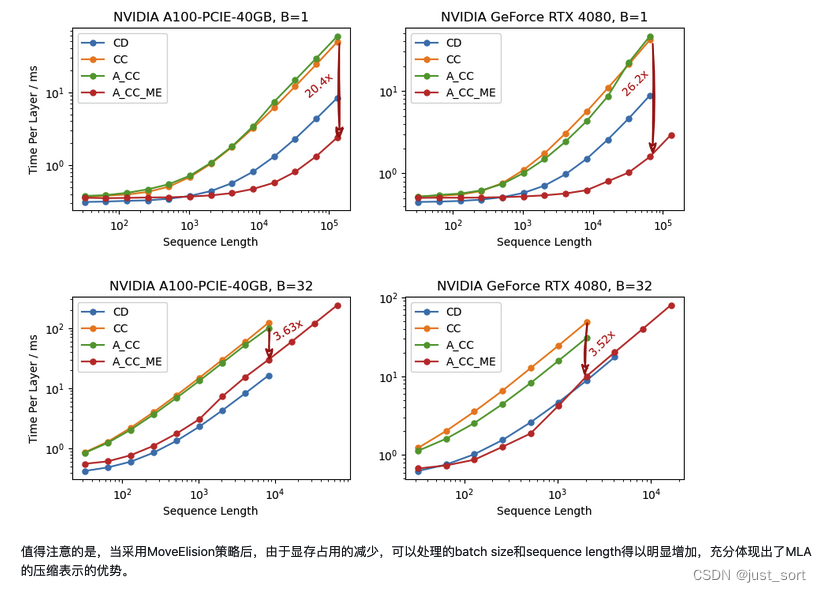
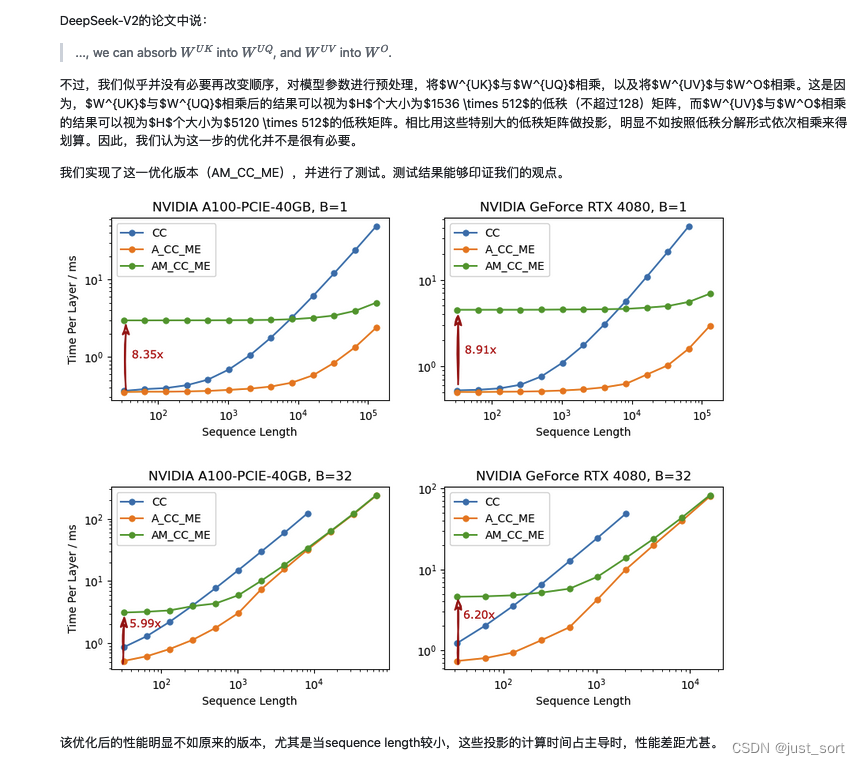
以 W U K W^{UK} WUK的吸收为例子,这里实际上是说在矩阵吸收的时候是否要提前把 W U K W^{UK} WUK和 W U Q W^{UQ} WUQ的矩阵乘结果保存下来,而不是在forward的时候重计算。作者在评论区回复过这个问题,意思就是直接在forward的时候重计算速度会更优。博客里面的解释如下:
0x5. 总结
这就是本篇博客的全部内容了,这里总结一下。首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应了完整公式中的具体行并且对每个操作前后的Tensor Shape变化也进行了解析。我们可以看到目前的官方实现在存储KV Cache的时候并不是存储隐向量,而是把隐向量都解压缩变成了标准的MHA的KV Cache,实际上是完全不能节省显存的。接着,就继续学习了一下清华大学的ZHANG Mingxing组实现的MLA矩阵吸收的工程实现,在这一节也详细分析了原理包括 W U K W^{UK} WUK和 W U V W_{UV} WUV分别如何吸收到 W U Q W_{UQ} WUQ和 W o W_o Wo中,分析了实现了矩阵吸收的每行代码的原理以及操作发生前后相关Tensor的维度变化。接着,对矩阵吸收代码实现里的矩阵乘法的性质进行分析,可以看到MLA在大多数阶段都是计算密集型而非访存密集型的。最后引用了作者团队的Benchmark结果,以及说明为何不是直接保存吸收后的大投影矩阵,而是在forward里面重新计算两个矩阵的吸收。