题目:MARformer: An Efficient Metal Artifact Reduction Transformer for Dental CBCT Images
一种有效的牙科CBCT图像金属伪影还原变压器
论文地址:arxiv
不重要的地方尽量一句话一段,减轻大家阅读压力
摘要
锥形束计算机断层扫描(CBCT)在牙科诊断和外科手术中发挥着关键作用。然而,金属牙种植体在CBCT成像过程中会带来烦人的金属伪影,干扰诊断和牙齿分割等下游处理。在本文中,我们开发了一种有效的变压器,用于从牙科CBCT图像中执行金属伪影还原(MAR)。
基于CBCT图像具有全局相似性的特点,提出了一种新的降维自注意(DRSA)模块 ,降低了多头自注意的计算复杂度。提出了一种基于斑块感知前馈网络(P2FFN)的局部图像信息感知方法。实验结果表明,该方法具有较好的有效性,优于现有的修复方法和两种修复变压器。
介绍
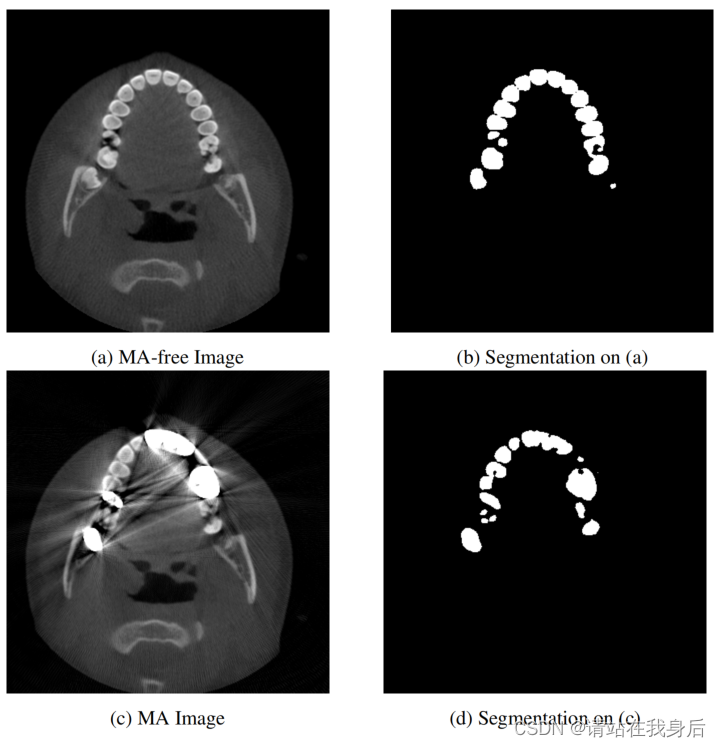
展示了两张CBCT图像,其中有或没有被牙齿中的金属污染的耀斑伪影,点出了金属伪影影响分割
现有方法有基于正弦图、优化、数据驱动的方法,这些基于CNN的缺少全局相关性,因此使用Transformer,但是Transformer计算成本高
因此提出了降维自注意(DRSA)模块,和具有大卷积核的斑块感知前馈网络(P2FFN)模块
由于牙科CBCT图像在局部区域具有空间相似性,因此可以通过在降维特征张量上执行多头自关注(MHSA)来减轻计算负担,这在变压器中消耗了最多的计算成本。为此,我们提出了一种高效的降维自注意(DRSA)模块,通过计算通道维数而不是空间维数的相似性矩阵来降低标准MHSA的计算复杂度,同时保持其利用全局相关性的能力。此外,在每个DRSA模块之后,我们引入了一个新的具有大卷积核的斑块感知前馈网络(P2FFN)模块,可以很好地恢复牙齿CBCT图像中的局部细节。
相关工作就不看啦
模型
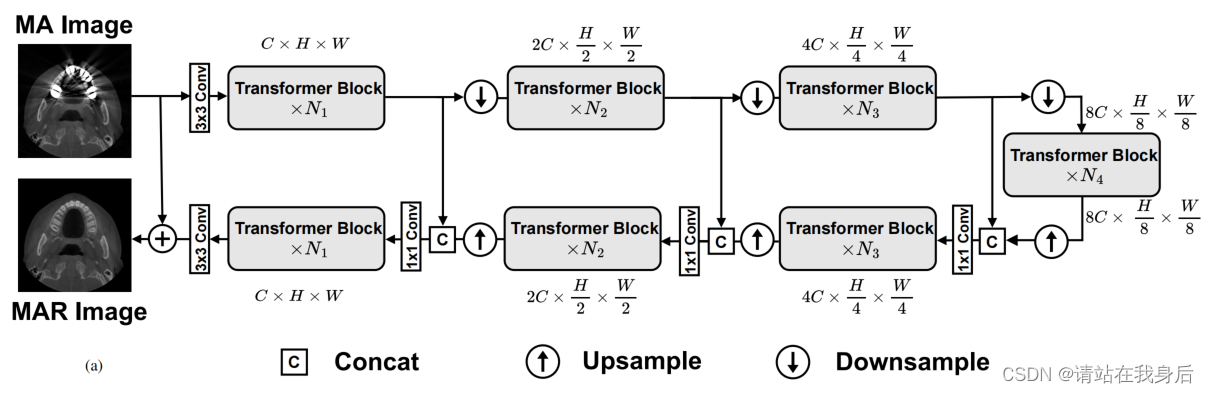 整体流程
整体流程
可以看到框架采用Unet,三层编码解码,每层N个变压器块,熟悉的童鞋可以只看维度就可以了
作为有监督网络,训练肯定是采用的退化方法,将添加了金属伪影的输入X 金国3*3卷积提取特征,然后输入第一层编码器输出特征是空间方向的下采样和通道方向的扩展到2C × h/2 × w/2的大小。然后再第二层同样,经过三层分层编码器后,将大小为8C × h8 × w8的输出特征图输入到bottleneck。
在解码器阶段,特征映射在解码器的每个级别上向上采样,并在信道上缩小一半,并与相应级别编码器的特征输出相连接。为了保持不同级别之间的通道维度一致,使用1×1卷积将连接特征的维度从2C降至C,然后再将其馈送到下一级解码器。
不同级别编码器或解码器之间的下采样和上采样操作是通过像素unshuffle/shuffle操作来实现的。将最后一个解码器后的feature map进行3×3卷积融合得到图像残差,将残差R加入到输入图像I中,得到最终的MAR图像I' = I + R。
 b:Transformer 块,c:降维自关注(DRSA)模块,d:
b:Transformer 块,c:降维自关注(DRSA)模块,d:
斑块感知前馈网络(P2FFN)
每个变压器块由DRSA和P2FFN组成
DRSA模块 的目标是对高分辨率特征图进行有效的自关注。首先沿着通道维度计算全局相似矩阵,通过DW卷积将数据投影到注意力机制需要用到的Q\K\V,然后计算获得注意力得分,后面的reshape操作是因为医学图dcm一般很小,因此进行一定程度的转换。总体来说就是一个注意力
深度分离卷积(Depthwise Separable Convolution)不同于常规卷积操作,
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,
同样是对于一张 5×5 像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5)
具体参考大佬博客 https://blog.csdn.net/IT__learning/article/details/119107079
P2FFN模块是由一个1×1扩大频道维度从C到γC, GELU激活函数,一个深度方面7×7卷积GELU感知局部图像,而另一个1×1卷积缩减渠道维度从γC 到C。
细节部分,之后复现网络可能用到
Tranformer块数量分别是,1、2、4、8, 注意力头的数目为1、2、4、8
空间和通道下采样比r均设为2。我们在P2FFN中设置通道尺寸C = 48,扩展因子γ = 2。

实验
数据就不看了,看两张图

效果可以说好的离谱