深度学习库(TensorFlow 和 Pytorch)中的 bug 对下游任务系统是重要的,保障安全性和有效性。在深度学习(DL)库的模糊测试领域,直接生成满足输入语言(例如 Python )语法/语义和张量计算的DL API 输入/形状约束的深度学习程序具有挑战性。此外,深度学习 API 可能包含复杂的输入条件约束,难以在没有人工干预的情况下生成符合条件的输入用例。TitanFuzz 是首个直接利用大语言模型(LLM)生成测试程序来模糊测试DL库的方法。
API 级模糊测试:仅针对孤立 API 进行测试,无法暴露由 API 调用链引发的缺陷;模糊级模糊测试:缺乏多样化 API 序列,如 Muffin 需要手动注释考虑的深度学习 API 的输入/输出限制,并使用额外的 reshaping 操作保证有效连接,以及无法生成任意代码。

- log 函数应该为负数产生 NaN,CPU 调用 matrix_exp 时应该包含 NaN 值,但 GPU 调用时不输出任何 NaN 值。
- Bug:在 CPU 上计算时分正负号,导致分别出现正无穷和负无穷。正常:在 GPU 上计算时不分正负号,1/0 为正无穷。
| 传统 | LLM-based | |
|---|---|---|
| 基于规则/随机变异 | 基于分布概率生成 | 规则->统计建模 |
| 结构化输入 | 基于语义理解 | 语法->语义 |
| 人工设计策略 | Prompt | |
| 显式定义张量/类型约束 | 隐式学习 API 约束 | 标注->推理 |
| 单 API | 任意组合 | 代码覆盖率 |
LLM 为差分测试提供语义合理、适配不同后端的测试输入。
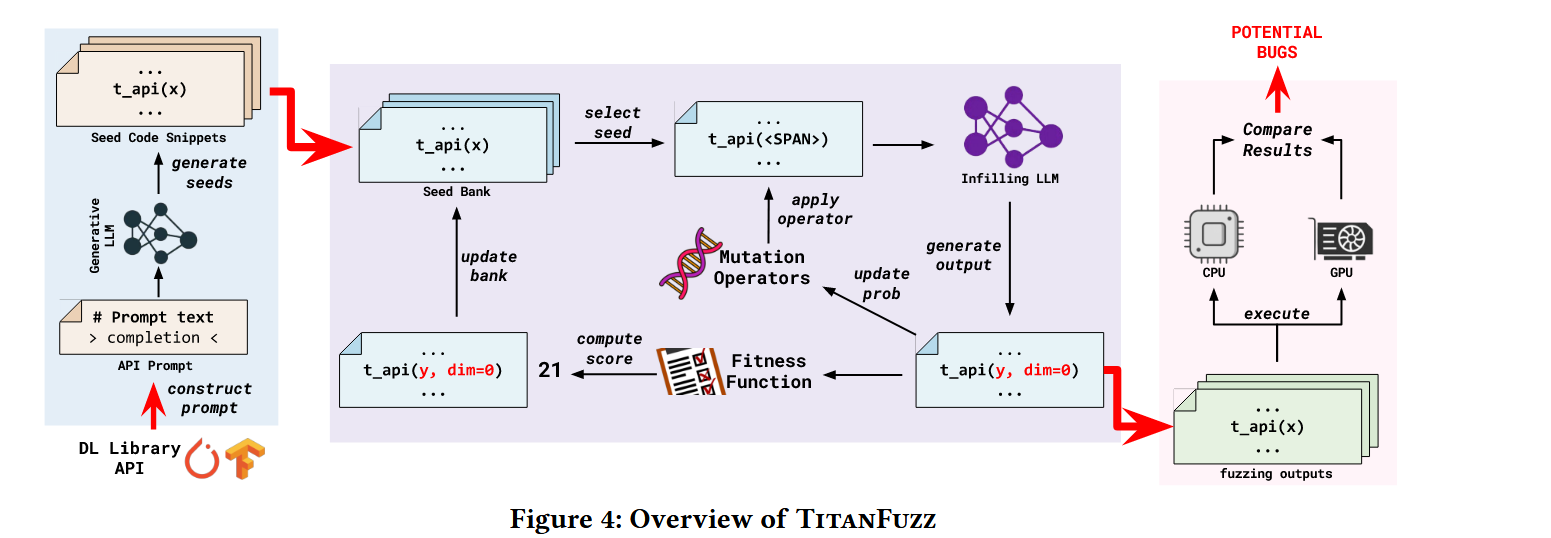
- 提供 step-by-step 的 prompt engineering,调用 codex 生成直接借用目标 API 的代码片段。
- 使用进化模糊算法,生成新的代码。
- 差分测试,在不同后端上执行,识别潜在错误。

Prompt 中包含了目标库和目标 API 定义(爬虫从官方文档爬取)并设计了分布指令,按照 Task 的顺序执行。原始种子程序从 Codex 中采样得到。

通过 Codex 生成初始种子,用 InCoder 去预测 mask 的代码片段以保持语义的连贯性,其中代码片段通过 Multi-Armed Bandit(MAB) 算法动态学习操作符优先级策略,并用 < s p a n > <span> <span> 覆盖,采样策略选择了 Top-N;
算子:
- 参数(augment):选择目标 API 中的参数 Mask,可以是已写的,也可以是未写的;
- 前缀(prefix):在目标 API 调用前插入代码段,并 Mask 掉一部分前缀;
- 后缀(suffix):在目标 API 调用后插入代码段,并 Mask 掉一部分后缀;
- 方法(method):Mask API 调用,使用新的 API;
MAB:
f ( x ; α , β ) = Γ ( α + β ) Γ ( α ) Γ ( β ) x α − 1 ( 1 − x ) β − 1 f(x;\alpha,\beta)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}x^{\alpha-1}(1-x)^{\beta-1} f(x;α,β)=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1
- 初始化每个变异操作符 𝑚 的成功次数 𝑚.S 和失败次数 𝑚.F 为1,即每个操作 𝑚 的先验分布被假设为 Beta(1, 1),即均匀分布。
- 在观察到 𝑚.S-1 次成功和 𝑚.F-1 次失败后,更新操作 𝑚 的后验分布为 Beta(𝑚.S, 𝑚.F)。
- 为了选择一个操作(arm),从每个操作的后验分布中抽取一个样本 𝜃𝑚,然后选择具有最大样本值的操作(表示它具有最高的成功率概率)。
- 在使用 LLMs 生成代码后,根据生成的程序的执行状态,更新所选择的变异操作的后验分布。与随机选择变异操作相比,这种方法可以帮助识别有助于生成更有效和独特代码片段的变异操作。
- 需要注意的是,最佳的变异操作可能因不同的目标API而异,因此为每个针对一个API的演化模糊测试的端到端运行开始一个单独的MAB游戏,并重新初始化操作符的先验分布。
Fitness Score: F i t n e s s F u n c t i o n ( C ) = D + U − R FitnessFunction(C)=D+U-R FitnessFunction(C)=D+U−R
- 数据流图深度 (D):衡量代码片段中数据依赖关系的复杂性。
- 唯一API调用数量 (U):鼓励使用更多不同的库API。
- 重复API调用惩罚 ®:减少重复API调用的影响,提高模糊测试的效率。
Differential Testing:
- Wrong Computation:在 CPU 和 GPU 上执行相同代码,记录所有中间变量,为了区分真正的错误和非关键差异,TitanFuzz 使用容差阈值来检查值是否显著不同。计算值的差异可能表明库 API 的不同后端实现或不同 API 之间的交互存在潜在的语义错误。
- Crash:在程序执行过程中,监控是否有段错误、终止、INTERNAL_ASSERT_FAILED 等异常发生。
实验
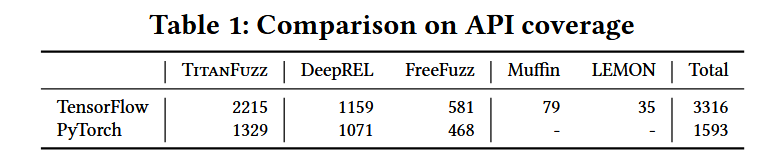
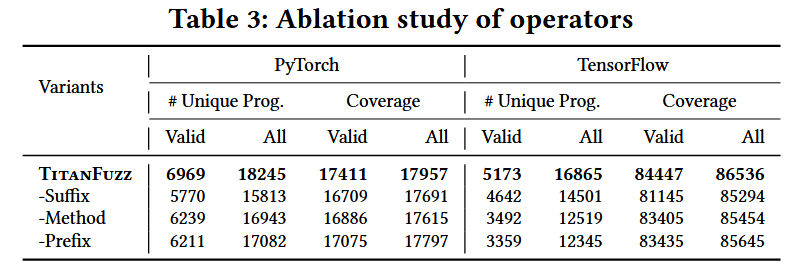
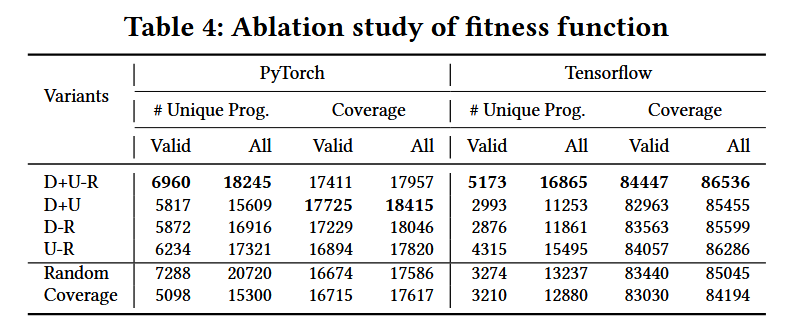
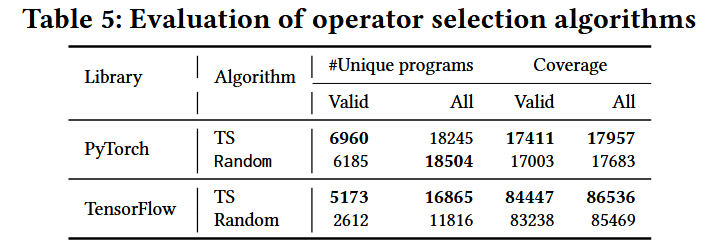
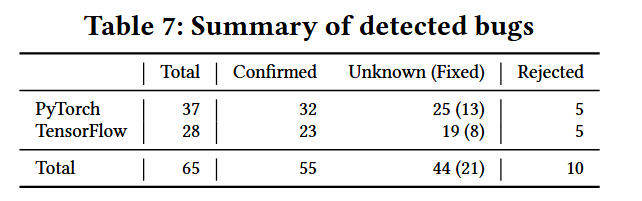
经过广泛的评估,TitanFuzz在两个流行的深度学习库(PyTorch和TensorFlow)上表现出了显著的改进,包括:
- 增加了库API的数量和代码覆盖率。
- 直接利用现代大型预训练语言模型进行模糊测试的前景。