Stable Video Diffusion:将潜在视频扩散模型扩展到大规模数据集
Blattmann A, Dockhorn T, Kulal S, et al. Stable video diffusion: Scaling latent video diffusion models to large datasetsJ. arXiv preprint arXiv:2311.15127, 2023.
1. 引言与背景
Stable Video Diffusion (SVD) 是Stability AI团队开发的一个里程碑式的潜在视频扩散模型,专门用于高分辨率、高质量的文本到视频和图像到视频生成。与以往的视频生成方法不同,SVD通过系统化的数据筛选策略和精心设计的三阶段训练流程,在生成质量上取得了显著突破。
论文的核心贡献在于首次系统地研究了数据质量对视频生成模型的影响。作者发现,即使在大规模预训练后进行高质量微调,预训练数据的质量仍会对最终模型性能产生持续影响。这一发现对整个视频生成领域具有重要的指导意义。
2. 理论基础与数学框架
2.1 连续时间扩散模型
SVD基于连续时间扩散模型框架,其核心思想是通过一个马尔可夫链逐步向数据添加噪声,然后学习反向过程来生成新数据。设 pdata(x0)p_{\text{data}}(x_0)pdata(x0) 表示原始数据分布,通过向数据添加方差为 σ2\sigma^2σ2 的高斯噪声,得到扰动分布:
p(x;σ)=∫pdata(x0)N(x;x0,σ2I)dx0p(x; \sigma) = \int p_{\text{data}}(x_0) \mathcal{N}(x; x_0, \sigma^2 I) dx_0p(x;σ)=∫pdata(x0)N(x;x0,σ2I)dx0
当 σmax\sigma_{\max}σmax 足够大时,扰动分布近似于纯高斯噪声:p(x;σmax)≈N(0,σmax2I)p(x; \sigma_{\max}) \approx \mathcal{N}(0, \sigma_{\max}^2 I)p(x;σmax)≈N(0,σmax2I)。
生成过程通过求解概率流常微分方程(Probability Flow ODE)实现:
dxdt=−σ˙(t)σ(t)∇xlogp(x;σ(t))\frac{dx}{dt} = -\dot{\sigma}(t)\sigma(t)\nabla_x \log p(x; \sigma(t))dtdx=−σ˙(t)σ(t)∇xlogp(x;σ(t))
这里 ∇xlogp(x;σ)\nabla_x \log p(x; \sigma)∇xlogp(x;σ) 是得分函数,表示对数概率密度的梯度。扩散模型的训练目标是学习一个神经网络 sθ(x;σ)s_\theta(x; \sigma)sθ(x;σ) 来近似这个得分函数。
2.2 去噪得分匹配
模型通过去噪得分匹配(Denoising Score Matching, DSM)进行训练。训练损失函数为:
LDSM=Ex0∼pdata,σ∼p(σ),n∼N(0,σ2I)λ(σ)∥Dθ(x0+n;σ,c)−x0∥22\mathcal{L}{\text{DSM}} = \mathbb{E}{x_0 \sim p_{\text{data}}, \sigma \sim p(\sigma), n \sim \mathcal{N}(0, \sigma^2 I)} \left \\lambda(\\sigma) \\\|D_\\theta(x_0 + n; \\sigma, c) - x_0\\\|_2\^2 \\rightLDSM=Ex0∼pdata,σ∼p(σ),n∼N(0,σ2I)λ(σ)∥Dθ(x0+n;σ,c)−x0∥22
其中 DθD_\thetaDθ 是参数化的去噪器,ccc 是条件信号(如文本提示),λ(σ)\lambda(\sigma)λ(σ) 是依赖于噪声水平的权重函数。
2.3 EDM预条件框架
为了改善训练稳定性和生成质量,论文采用了EDM(Elucidating the Design Space of Diffusion-Based Generative Models)预条件框架。去噪器被参数化为:
Dθ(x;σ)=cskip(σ)⋅x+cout(σ)⋅Fθ(cin(σ)⋅x;cnoise(σ))D_\theta(x; \sigma) = c_{\text{skip}}(\sigma) \cdot x + c_{\text{out}}(\sigma) \cdot F_\theta(c_{\text{in}}(\sigma) \cdot x; c_{\text{noise}}(\sigma))Dθ(x;σ)=cskip(σ)⋅x+cout(σ)⋅Fθ(cin(σ)⋅x;cnoise(σ))
预条件函数的具体形式为:
- cskip(σ)=σ2/(σ2+σdata2)c_{\text{skip}}(\sigma) = \sigma^2 / (\sigma^2 + \sigma_{\text{data}}^2)cskip(σ)=σ2/(σ2+σdata2)
- cout(σ)=σ⋅σdata/σ2+σdata2c_{\text{out}}(\sigma) = \sigma \cdot \sigma_{\text{data}} / \sqrt{\sigma^2 + \sigma_{\text{data}}^2}cout(σ)=σ⋅σdata/σ2+σdata2
- cin(σ)=1/σ2+σdata2c_{\text{in}}(\sigma) = 1 / \sqrt{\sigma^2 + \sigma_{\text{data}}^2}cin(σ)=1/σ2+σdata2
- cnoise(σ)=14ln(σ)c_{\text{noise}}(\sigma) = \frac{1}{4} \ln(\sigma)cnoise(σ)=41ln(σ)
其中 σdata=1\sigma_{\text{data}} = 1σdata=1 是数据标准差的估计值。
3. 数据处理与筛选策略
3.1 级联切分检测

论文实现了一个三级级联切分检测系统,在不同帧率下运行检测器以捕获各种类型的场景转换。图11展示了级联方法相对于单一检测器的优势:级联方法能够检测到渐变转场和慢速淡入淡出效果,而这些在单一fps检测中经常被遗漏。处理流程使用PySceneDetect在三个不同的配置下运行:
- 第一级:原生fps,标准阈值
- 第二级:降采样到15fps,降低阈值
- 第三级:降采样到8fps,进一步降低阈值
3.2 运动评估与静态过滤

图12展示了静态视频的例子,这类内容会对生成模型训练产生负面影响。论文通过计算密集光流来量化运动强度。使用Farnebäck算法在2fps下提取光流场,然后计算平均幅度作为全局运动分数:
Motion Score=1T⋅H⋅W∑t,h,w∥vt,h,w∥2\text{Motion Score} = \frac{1}{T \cdot H \cdot W} \sum_{t,h,w} \|\mathbf{v}_{t,h,w}\|_2Motion Score=T⋅H⋅W1t,h,w∑∥vt,h,w∥2
其中 vt,h,w\mathbf{v}_{t,h,w}vt,h,w 是时刻 ttt 位置 (h,w)(h,w)(h,w) 处的光流向量。图2右侧的直方图显示原始数据集中存在大量接近零运动的片段,通过设置阈值0.25可以有效过滤。
3.3 合成字幕生成

图13展示了三种字幕生成方法的对比:
- CoCa:基于图像的字幕器,擅长捕捉空间细节
- VideoBLIP:视频字幕器,能够描述时间动态
- LLM融合:结合前两者优势的语言模型生成
实验发现,虽然CoCa是纯图像模型,但其生成的字幕对视频训练最有益,可能因为它提供了更准确的空间描述。
3.4 文本检测与美学评分
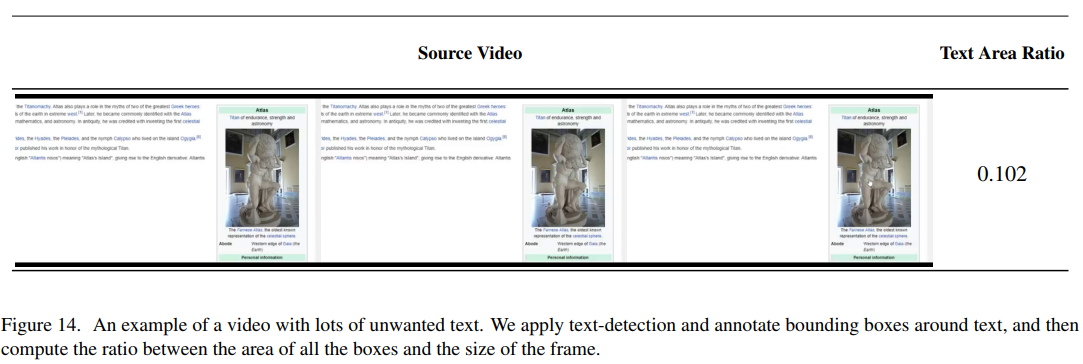
图14展示了包含大量文本的视频帧示例。使用CRAFT文本检测器标注边界框,当文本区域超过帧面积的7%时过滤该片段。美学评分通过CLIP嵌入计算,用于识别视觉质量较低的内容。
4. 三阶段训练策略详解
4.1 第一阶段:图像预训练
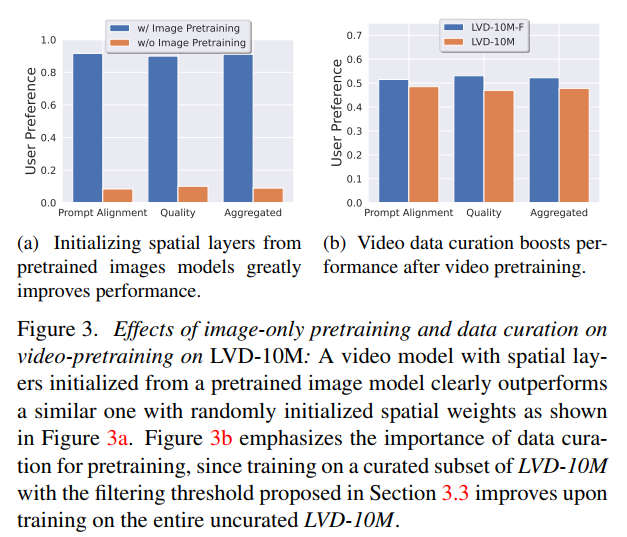
图3a清晰展示了图像预训练的重要性。对比实验使用相同的架构和训练设置,唯一区别是是否使用Stable Diffusion 2.1的预训练权重初始化。结果显示,预训练模型在提示词对齐和质量两个维度上都显著优于随机初始化模型,用户偏好率分别达到约70%和65%。
4.2 第二阶段:视频预训练
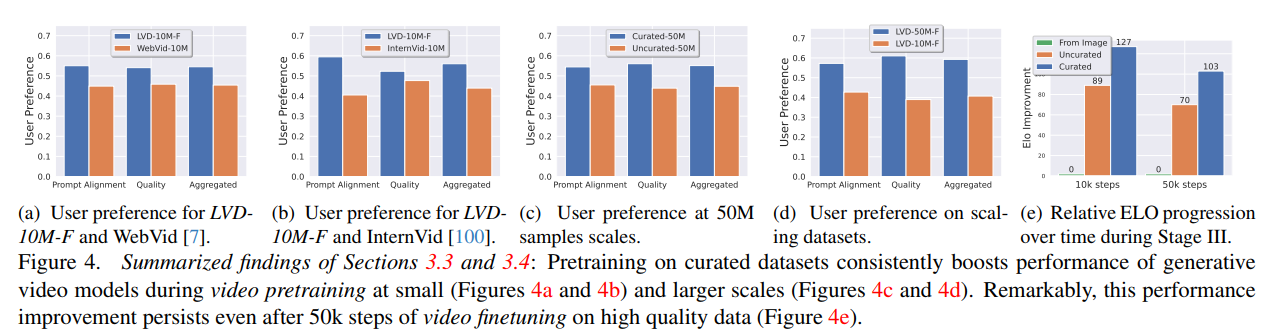
图4展示了数据筛选对性能的持续影响。图4a和4b比较了在筛选后的LVD-10M-F(2.3M样本)与WebVid-10M和InternVid-10M的性能,尽管数据量仅为四分之一,筛选后的数据集训练出的模型仍然更受用户青睐。图4c在50M规模上验证了这一结论,图4d显示数据集大小也是关键因素。
训练配置:
- 分辨率:256×384,14帧
- 批大小:1536
- 学习率:10−410^{-4}10−4
- 迭代次数:150k
- 噪声调度:logσ∼N(−1.2,1.02)\log \sigma \sim \mathcal{N}(-1.2, 1.0^2)logσ∼N(−1.2,1.02)
4.3 第三阶段:高质量微调
图4e展示了预训练质量的长期影响。三条曲线分别代表:
- 从图像模型初始化(基线)
- 从未筛选数据预训练的模型初始化
- 从筛选数据预训练的模型初始化
即使经过50k步的高质量微调,筛选数据预训练的优势仍然保持,相对基线的ELO提升从10k步的89增长到50k步的127。
5. 模型架构与实现细节
5.1 UNet架构扩展
基础UNet采用Stable Diffusion 2.1的架构,通过插入时间层扩展到视频域。每个空间块后添加相应的时间块:
- 空间自注意力 → 时间自注意力
- 空间卷积 → 时间卷积(1D卷积沿时间轴)
- 空间交叉注意力 → 时间交叉注意力
总参数量从865M增加到1521M。
5.2 无分类器引导
模型实现了无分类器引导以提高生成质量:
s~θ(xt,c)=(1+w)⋅sθ(xt,c)−w⋅sθ(xt,∅)\tilde{s}\theta(x_t, c) = (1 + w) \cdot s\theta(x_t, c) - w \cdot s_\theta(x_t, \emptyset)s~θ(xt,c)=(1+w)⋅sθ(xt,c)−w⋅sθ(xt,∅)
其中 www 是引导权重,∅\emptyset∅ 表示空条件。训练时15%的概率将条件信号置空。
5.3 线性递增引导技术
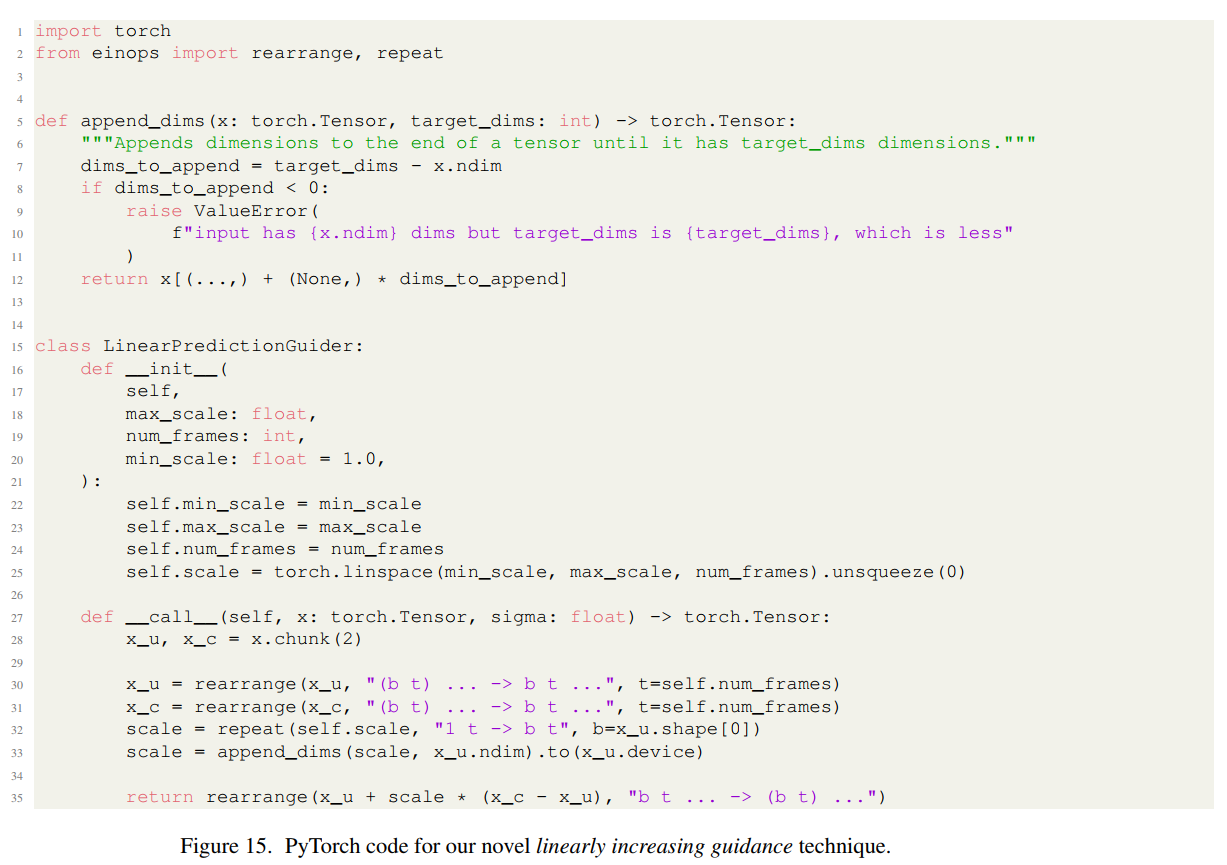
图15的代码实现展示了论文提出的创新技术。传统的恒定引导尺度会导致过饱和或与条件帧不一致。线性递增引导通过在时间轴上逐渐增加引导强度解决了这个问题:
wt=wmin+tT−1(wmax−wmin)w_t = w_{\min} + \frac{t}{T-1}(w_{\max} - w_{\min})wt=wmin+T−1t(wmax−wmin)
其中 t∈0,T−1t \in 0, T-1t∈0,T−1 是帧索引。
6. 实验结果与应用
6.1 文本到视频生成

图5展示了576×1024分辨率的生成样本。顶部是图像到视频的结果(最左侧为条件帧),底部是纯文本到视频的结果。生成的视频展现了丰富的运动动态和高视觉质量。
表2显示了UCF-101零样本评估结果:
- SVD:242.02 FVD(最佳)
- PYOCO:355.20 FVD
- Make-A-Video:367.23 FVD
- Video LDM:550.61 FVD
6.2 相机运动控制

图7展示了三种相机运动LoRA的效果(水平移动、缩放、静态),应用于同一条件帧。每个LoRA仅包含16秩的低秩矩阵,参数量极小但效果显著。训练仅需5k步即可收敛。
6.3 多视角生成

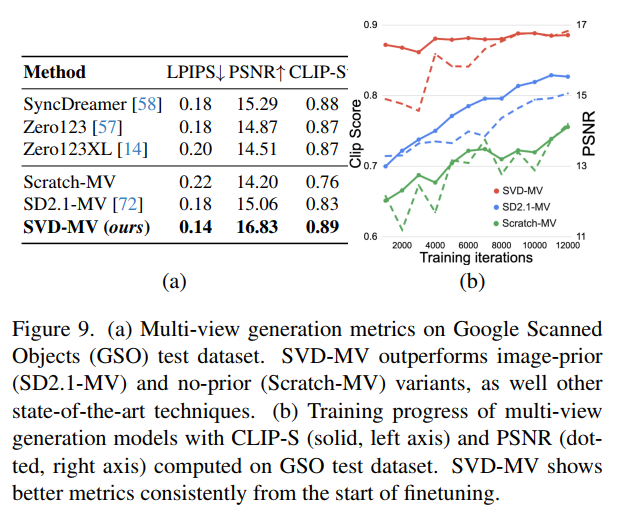

图8-10展示了多视角生成结果。与Zero123XL和SyncDreamer相比,SVD-MV生成的多视角图像具有更好的一致性和细节保真度。定量结果(图9a)显示:
- SVD-MV:PSNR 16.83,LPIPS 0.14,CLIP-S 0.89
- SyncDreamer:PSNR 15.29,LPIPS 0.18,CLIP-S 0.88
- Zero123XL:PSNR 14.51,LPIPS 0.20,CLIP-S 0.87
图9b的训练曲线显示,SVD-MV从训练初期就保持优势,仅需1k步即超越基于图像的方法。
6.4 时间提示解耦

图21展示了一个有趣的发现:模型能够独立处理空间和时间提示。通过向空间交叉注意力层和时间交叉注意力层提供不同的文本提示,可以独立控制场景内容和运动模式。例如,固定空间提示为"山坡前花盆中的花",改变时间提示为"平移"、"旋转"、"缩放",生成的视频保持相同场景但呈现不同的相机运动。
7. 消融研究
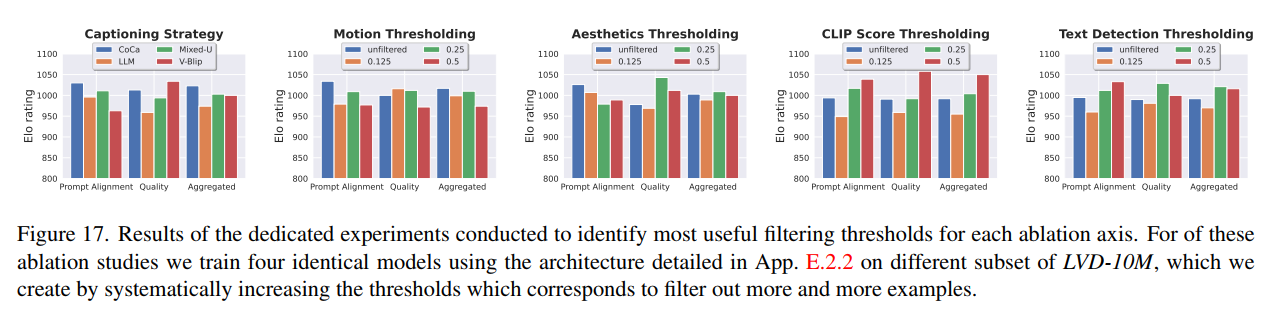
图17详细展示了各种数据筛选策略的系统性消融研究结果。每个子图对应一种筛选维度(字幕策略、运动阈值、美学阈值、CLIP分数阈值、文本检测阈值),通过训练相同架构的模型并进行人工评估得出最优阈值:
- 字幕:CoCa优于其他方法
- 运动:25%阈值最优
- 美学:25%阈值最优
- CLIP分数:50%阈值最优
- 文本检测:25%阈值最优
8. 结论与展望
SVD通过系统化的方法论推进了视频生成技术的发展。关键贡献包括:建立了完整的数据筛选流程,证明了预训练数据质量的长期影响,开发了高效的多阶段训练策略,以及展示了视频模型在多视角生成等任务上的潜力。
局限性主要在于长视频生成的计算成本、有时运动幅度不足,以及扩散模型固有的采样速度问题。未来工作可以探索更高效的架构、更长序列的生成方法,以及扩散蒸馏技术来加速推理。
附录:数学推导
A. 扩散模型的理论基础
A.1 前向扩散过程
前向扩散过程定义为一个马尔可夫链,逐步向数据添加高斯噪声:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t I)q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
其中 βt\beta_tβt 是噪声调度。定义 αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt 和 αˉt=∏s=1tαs\bar{\alpha}t = \prod{s=1}^t \alpha_sαˉt=∏s=1tαs,可以直接从 x0x_0x0 采样 xtx_txt:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1-\bar{\alpha}_t) I)q(xt∣x0)=N(xt;αˉt x0,(1−αˉt)I)
等价地,可以写成:
xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I)x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)xt=αˉt x0+1−αˉt ϵ,ϵ∼N(0,I)
A.2 反向扩散过程
反向过程的后验分布为:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)q(x_{t-1} | x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I)q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
其中:
μ~t(xt,x0)=αˉt−1βt1−αˉtx0+αt(1−αˉt−1)1−αˉtxt\tilde{\mu}t(x_t, x_0) = \frac{\sqrt{\bar{\alpha}{t-1}} \beta_t}{1-\bar{\alpha}t} x_0 + \frac{\sqrt{\alpha_t}(1-\bar{\alpha}{t-1})}{1-\bar{\alpha}_t} x_tμ~t(xt,x0)=1−αˉtαˉt−1 βtx0+1−αˉtαt (1−αˉt−1)xt
β~t=1−αˉt−11−αˉtβt\tilde{\beta}t = \frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}_t} \beta_tβ~t=1−αˉt1−αˉt−1βt
A.3 训练目标的推导
变分下界(Variational Lower Bound, VLB)可以写成:
LVLB=EqDKL(q(xT∣x0)∥p(xT))+∑t\>1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−logpθ(x0∣x1)\mathcal{L}_{\text{VLB}} = \mathbb{E}_q \left D_{KL}(q(x_T\|x_0) \\\| p(x_T)) + \\sum_{t\>1} D_{KL}(q(x_{t-1}\|x_t,x_0) \\\| p_\\theta(x_{t-1}\|x_t)) - \\log p_\\theta(x_0\|x_1) \\rightLVLB=EqDKL(q(xT∣x0)∥p(xT))+t\>1∑DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−logpθ(x0∣x1)
简化后的训练目标(忽略权重):
Lsimple=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2\mathcal{L}{\text{simple}} = \mathbb{E}{t,x_0,\epsilon} \left \\\|\\epsilon - \\epsilon_\\theta(x_t, t)\\\|\^2 \\rightLsimple=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2
其中 ϵθ\epsilon_\thetaϵθ 是噪声预测网络。
A.4 得分函数与去噪器的关系
得分函数定义为:
s(x,σ)=∇xlogp(x;σ)s(x, \sigma) = \nabla_x \log p(x; \sigma)s(x,σ)=∇xlogp(x;σ)
对于高斯扰动分布:
p(x;σ)=∫pdata(x0)N(x;x0,σ2I)dx0p(x; \sigma) = \int p_{\text{data}}(x_0) \mathcal{N}(x; x_0, \sigma^2 I) dx_0p(x;σ)=∫pdata(x0)N(x;x0,σ2I)dx0
得分函数可以表示为:
s(x,σ)=Ex0∣x;σ−xσ2s(x, \sigma) = \frac{\mathbb{E}x_0 \| x; \\sigma - x}{\sigma^2}s(x,σ)=σ2Ex0∣x;σ−x
因此,去噪器 Dθ(x;σ)≈Ex0∣x;σD_\theta(x; \sigma) \approx \mathbb{E}x_0 \| x; \\sigmaDθ(x;σ)≈Ex0∣x;σ 与得分函数的关系为:
sθ(x;σ)=Dθ(x;σ)−xσ2s_\theta(x; \sigma) = \frac{D_\theta(x; \sigma) - x}{\sigma^2}sθ(x;σ)=σ2Dθ(x;σ)−x
A.5 概率流ODE的推导
从SDE(随机微分方程)出发:
dx=f(x,t)dt+g(t)dwdx = f(x, t)dt + g(t)dwdx=f(x,t)dt+g(t)dw
其中 f(x,t)=−12β(t)xf(x, t) = -\frac{1}{2}\beta(t)xf(x,t)=−21β(t)x,g(t)=β(t)g(t) = \sqrt{\beta(t)}g(t)=β(t) ,www 是布朗运动。
对应的概率流ODE为:
dx=f(x,t)−12g2(t)∇xlogpt(x)dtdx = \left f(x, t) - \\frac{1}{2}g\^2(t) \\nabla_x \\log p_t(x) \\right dtdx=f(x,t)−21g2(t)∇xlogpt(x)dt
代入具体形式:
dx=−12β(t)x+∇xlogpt(x)dtdx = -\frac{1}{2}\beta(t) \left x + \\nabla_x \\log p_t(x) \\right dtdx=−21β(t)x+∇xlogpt(x)dt
使用重参数化 σ(t)=(1−αˉt)/αˉt\sigma(t) = \sqrt{(1-\bar{\alpha}_t)/\bar{\alpha}_t}σ(t)=(1−αˉt)/αˉt ,可以得到论文中的形式:
dx=−σ˙(t)σ(t)∇xlogp(x;σ(t))dtdx = -\dot{\sigma}(t)\sigma(t)\nabla_x \log p(x; \sigma(t)) dtdx=−σ˙(t)σ(t)∇xlogp(x;σ(t))dt
B. EDM框架的理论分析
B.1 最优预条件函数
EDM框架通过分析训练动力学推导出最优的预条件函数。考虑训练损失的期望:
L(θ)=Eσ,x0,nλ(σ)∥Dθ(x0+n;σ)−x0∥2\mathcal{L}(\theta) = \mathbb{E}_{\sigma, x_0, n} \left \\lambda(\\sigma) \\\|D_\\theta(x_0 + n; \\sigma) - x_0\\\|\^2 \\rightL(θ)=Eσ,x0,nλ(σ)∥Dθ(x0+n;σ)−x0∥2
其中 n∼N(0,σ2I)n \sim \mathcal{N}(0, \sigma^2 I)n∼N(0,σ2I)。
为了使不同噪声水平下的梯度贡献均衡,需要选择合适的 λ(σ)\lambda(\sigma)λ(σ) 和预条件函数。通过分析梯度的方差,可以推导出:
λopt(σ)=σ2σ2+σdata2\lambda_{\text{opt}}(\sigma) = \frac{\sigma^2}{\sigma^2 + \sigma_{\text{data}}^2}λopt(σ)=σ2+σdata2σ2
相应的预条件函数已在正文中给出。
B.2 噪声调度的优化
连续时间框架下,噪声分布 p(σ)p(\sigma)p(σ) 的选择影响训练效率。EDM推荐使用对数正态分布:
logσ∼N(Pmean,Pstd2)\log \sigma \sim \mathcal{N}(P_{\text{mean}}, P_{\text{std}}^2)logσ∼N(Pmean,Pstd2)
参数选择基于数据集统计:
- PmeanP_{\text{mean}}Pmean:使得 ePmean≈σdatae^{P_{\text{mean}}} \approx \sigma_{\text{data}}ePmean≈σdata
- PstdP_{\text{std}}Pstd:覆盖从低噪声到高噪声的合理范围
C. 无分类器引导的理论基础
C.1 条件得分的贝叶斯分解
条件得分函数可以分解为:
∇xlogp(x∣c)=∇xlogp(x)+∇xlogp(c∣x)\nabla_x \log p(x|c) = \nabla_x \log p(x) + \nabla_x \log p(c|x)∇xlogp(x∣c)=∇xlogp(x)+∇xlogp(c∣x)
第二项可以近似为:
∇xlogp(c∣x)≈∇xlogpϕ(c∣x)\nabla_x \log p(c|x) \approx \nabla_x \log p_\phi(c|x)∇xlogp(c∣x)≈∇xlogpϕ(c∣x)
其中 pϕ(c∣x)p_\phi(c|x)pϕ(c∣x) 是一个分类器。
C.2 无分类器引导的推导
为了避免训练额外的分类器,可以使用条件和无条件模型的组合:
p~θ(x∣c)∝pθ(x∣c)1+w/pθ(x)w\tilde{p}\theta(x|c) \propto p\theta(x|c)^{1+w} / p_\theta(x)^wp~θ(x∣c)∝pθ(x∣c)1+w/pθ(x)w
对应的得分为:
∇xlogp~θ(x∣c)=(1+w)∇xlogpθ(x∣c)−w∇xlogpθ(x)\nabla_x \log \tilde{p}\theta(x|c) = (1+w) \nabla_x \log p\theta(x|c) - w \nabla_x \log p_\theta(x)∇xlogp~θ(x∣c)=(1+w)∇xlogpθ(x∣c)−w∇xlogpθ(x)
这等价于隐式地使用分类器 p(c∣x)∝p(x∣c)/p(x)p(c|x) \propto p(x|c)/p(x)p(c∣x)∝p(x∣c)/p(x)。
D. 视频扩散的时空分解
D.1 时空因子分解
视频数据 x∈RT×H×W×Cx \in \mathbb{R}^{T \times H \times W \times C}x∈RT×H×W×C 的概率分布可以因子分解为:
p(x)=p(x(1))∏t=2Tp(x(t)∣x(1:t−1))p(x) = p(x^{(1)}) \prod_{t=2}^T p(x^{(t)} | x^{(1:t-1)})p(x)=p(x(1))t=2∏Tp(x(t)∣x(1:t−1))
其中 x(t)x^{(t)}x(t) 表示第 ttt 帧。
D.2 时空注意力机制
时空自注意力可以分解为空间和时间两个阶段:
-
空间自注意力(帧内):
SpatialAttn(x(t))=Softmax(Qs(t)(Ks(t))Tdk)Vs(t)\text{SpatialAttn}(x^{(t)}) = \text{Softmax}\left(\frac{Q_s^{(t)} (K_s^{(t)})^T}{\sqrt{d_k}}\right) V_s^{(t)}SpatialAttn(x(t))=Softmax(dk Qs(t)(Ks(t))T)Vs(t) -
时间自注意力(帧间):
TemporalAttn(xh,w)=Softmax(Qt(h,w)(Kt(h,w))Tdk)Vt(h,w)\text{TemporalAttn}(x_{h,w}) = \text{Softmax}\left(\frac{Q_t^{(h,w)} (K_t^{(h,w)})^T}{\sqrt{d_k}}\right) V_t^{(h,w)}TemporalAttn(xh,w)=Softmax(dk Qt(h,w)(Kt(h,w))T)Vt(h,w)
其中 xh,w∈RT×Cx_{h,w} \in \mathbb{R}^{T \times C}xh,w∈RT×C 是所有帧在位置 (h,w)(h,w)(h,w) 的特征。
E. 多视角生成的几何约束
E.1 相机投影模型
多视角间的几何关系由相机投影矩阵描述:
λuv1=KR∣tXYZ1\lambda \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} = K R\|t \begin{bmatrix} X \\ Y \\ Z \\ 1 \end{bmatrix}λ uv1 =KR∣t XYZ1
其中 KKK 是内参矩阵,R∣tR\|tR∣t 是外参矩阵。
E.2 视角一致性损失
为了保证多视角一致性,可以添加几何约束损失:
Lgeo=∑i,j∥Πj(Πi−1(xi))−xj∥2\mathcal{L}{\text{geo}} = \sum{i,j} \|\Pi_j(\Pi_i^{-1}(x_i)) - x_j\|^2Lgeo=i,j∑∥Πj(Πi−1(xi))−xj∥2
其中 Πi\Pi_iΠi 表示第 iii 个视角的投影变换。
然而,SVD-MV通过时间注意力机制隐式学习了这种一致性,无需显式的几何约束。
F. 采样算法
F.1 DDIM采样器
确定性采样使用DDIM(Denoising Diffusion Implicit Models):
xt−1=αˉt−1(xt−1−αˉtϵθ(xt,t)αˉt)+1−αˉt−1ϵθ(xt,t)x_{t-1} = \sqrt{\bar{\alpha}{t-1}} \left( \frac{x_t - \sqrt{1-\bar{\alpha}t} \epsilon\theta(x_t, t)}{\sqrt{\bar{\alpha}t}} \right) + \sqrt{1-\bar{\alpha}{t-1}} \epsilon\theta(x_t, t)xt−1=αˉt−1 (αˉt xt−1−αˉt ϵθ(xt,t))+1−αˉt−1 ϵθ(xt,t)
F.2 概率流ODE求解器
使用Heun方法(二阶龙格-库塔)求解ODE:
k1=−σ˙(t)σ(t)sθ(xt,σ(t))x~t+Δt=xt+Δt⋅k1k2=−σ˙(t+Δt)σ(t+Δt)sθ(x~t+Δt,σ(t+Δt))xt+Δt=xt+Δt2(k1+k2)\begin{align} k_1 &= -\dot{\sigma}(t)\sigma(t) s_\theta(x_t, \sigma(t)) \\ \tilde{x}{t+\Delta t} &= x_t + \Delta t \cdot k_1 \\ k_2 &= -\dot{\sigma}(t+\Delta t)\sigma(t+\Delta t) s\theta(\tilde{x}{t+\Delta t}, \sigma(t+\Delta t)) \\ x{t+\Delta t} &= x_t + \frac{\Delta t}{2}(k_1 + k_2) \end{align}k1x~t+Δtk2xt+Δt=−σ˙(t)σ(t)sθ(xt,σ(t))=xt+Δt⋅k1=−σ˙(t+Δt)σ(t+Δt)sθ(x~t+Δt,σ(t+Δt))=xt+2Δt(k1+k2)
这提供了比一阶欧拉方法更高的精度。