

AI的提示词专栏:Prompt 与传统机器学习特征工程的异同
本文围绕 Prompt 与传统机器学习特征工程展开分析,二者本质均为构建 "人类需求" 与 "模型能力" 的输入桥梁,目标一致(降低模型理解成本)、依赖领域知识、需迭代优化。但核心差异显著:特征工程作用于模型训练前,需结构化数据,高度依赖人工且适配特定模型,适用于需求稳定、高并发的线上业务;Prompt 作用于推理时,输入灵活,可部分自动化且跨模型通用,更适合需求多变、非结构化数据处理场景。文章还指出二者可协同应用,如 Prompt 辅助特征设计、特征工程提升 Prompt 精准度,助力从业者根据业务需求选择或融合使用。

人工智能专栏介绍
人工智能学习合集专栏是 AI 学习者的实用工具。它像一个全面的 AI 知识库,把提示词设计、AI 创作、智能绘图等多个细分领域的知识整合起来。无论你是刚接触 AI 的新手,还是有一定基础想提升的人,都能在这里找到合适的内容。从最基础的工具操作方法,到背后深层的技术原理,专栏都有讲解,还搭配了实例教程和实战案例。这些内容能帮助学习者一步步搭建完整的 AI 知识体系,让大家快速从入门进步到精通,更好地应对学习和工作中遇到的 AI 相关问题。

这个系列专栏能教会人们很多实用的 AI 技能。在提示词方面,能让人学会设计精准的提示词,用不同行业的模板高效和 AI 沟通。写作上,掌握从选题到成稿的全流程技巧,用 AI 辅助写出高质量文本。编程时,借助 AI 完成代码编写、调试等工作,提升开发速度。绘图领域,学会用 AI 生成符合需求的设计图和图表。此外,还能了解主流 AI 工具的用法,学会搭建简单智能体,掌握大模型的部署和应用开发等技能,覆盖多个场景,满足不同学习者的需求。

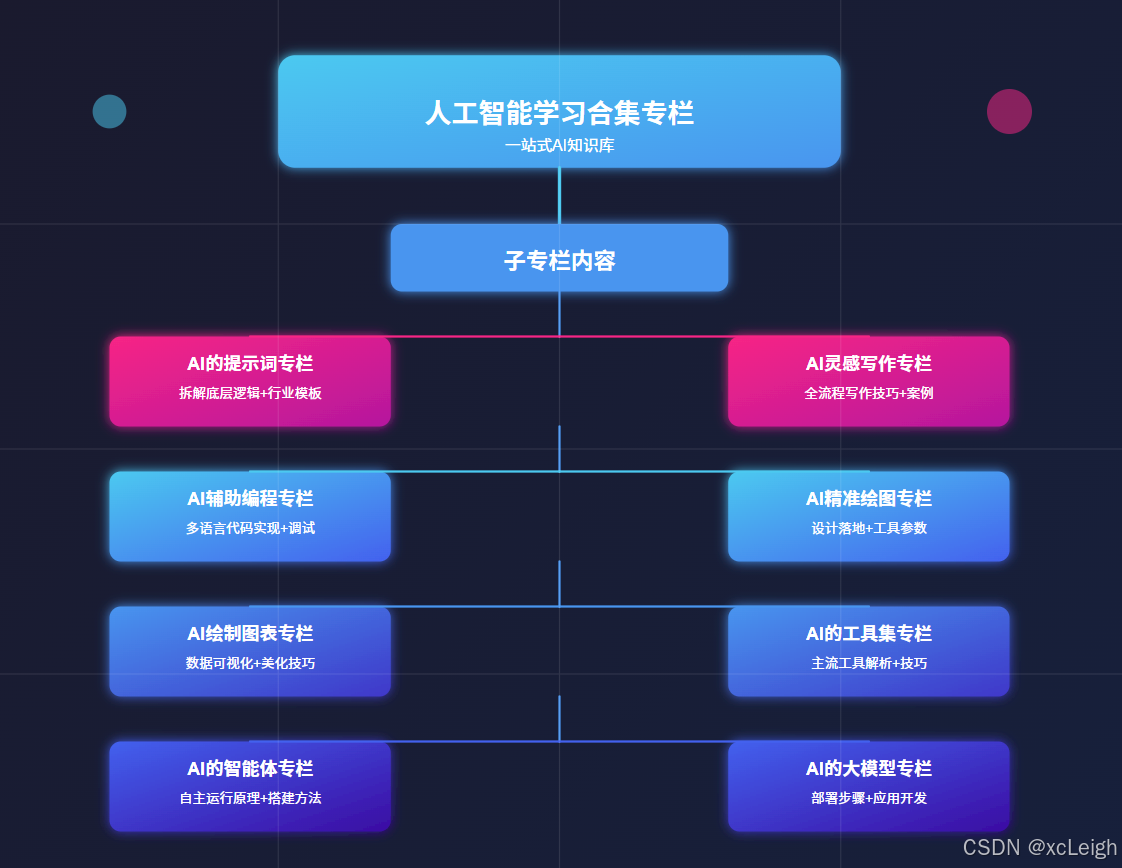
1️⃣ ⚡ 点击进入 AI 的提示词专栏,专栏拆解提示词底层逻辑,从明确指令到场景化描述,教你精准传递需求。还附带包含各行业适配模板:医疗问诊话术、电商文案指令等,附优化技巧,让 AI 输出更贴合预期,提升工作效率。
2️⃣ ⚡ 点击进入 AI 灵感写作专栏,AI 灵感写作专栏,从选题到成稿,全流程解析 AI 写作技巧。涵盖论文框架搭建、小说情节生成等,教你用提示词引导 AI 输出内容,再进行人工润色。附不同文体案例,助你解决写作卡壳,产出高质量文本。
3️⃣ ⚡ 点击进入 AI 辅助编程专栏,AI 辅助编程专栏,通过实例教你用 AI 写代码:从功能描述到调试优化。涵盖前端、后端、数据库等,语言包括HTML5、VUE、Python、Java、C# 等语言,含算法实现、Bug 修复技巧,帮开发者减少重复劳动,专注核心逻辑,提升开发速度。
4️⃣ ⚡ 点击进入 AI 精准绘图专栏,AI 精准绘图,聚焦 AI 绘图在设计场景的落地。详解如何描述风格、元素、用途,生成 logo、商标等。含 Midjourney 等工具参数设置,及修改迭代方法,帮设计新手快速出图,满足商业与个人需求。
5️⃣ ⚡ 点击进入 AI 绘制图表专栏,AI 绘制图表专栏,教你用 AI 工具将数据转化为直观图表。涵盖曲线图数据输入、流程图逻辑梳理等,附 Excel 联动、格式美化技巧,适合学生、职场人快速制作专业图表,提升数据展示效果。
6️⃣ ⚡ 点击进入 AI 的工具集专栏,AI 的工具集专栏,盘点主流 AI 工具:ChatGPT、DeepSeek、 Claude、Gemini、Copilot 等。解析各工具优势,附使用场景与技巧,帮你根据需求选工具,快速上手提升效率,覆盖办公、创作、开发等场景。
7️⃣ ⚡ 点击进入 AI 的智能体专栏,AI 的智能体专栏,解析智能体自主运行原理,包括任务拆解、环境交互等。教你用大模型搭建简单智能体,附多智能体协作案例,适合想探索 AI 自主系统的开发者入门。
8️⃣ ⚡ 点击进入 AI 的大模型专栏,AI 的大模型专栏,详解大模型部署步骤,从本地搭建到云端部署。含 API 调用教程、应用开发案例,教你将大模型集成到项目,掌握企业级 AI 应用开发技能,应对实际业务需求。
一、引言:从"输入桥梁"看两者的核心价值
在人工智能技术落地的过程中,"如何让模型理解任务并输出高质量结果"始终是核心问题。无论是传统机器学习(Traditional Machine Learning, TML)还是基于大语言模型(Large Language Model, LLM)的 Prompt 技术,本质上都是在构建"人类需求"与"模型能力"之间的输入桥梁------前者通过特征工程 将原始数据转化为模型可学习的结构化信息,后者通过Prompt 设计将模糊的任务需求转化为模型可理解的精确指令。
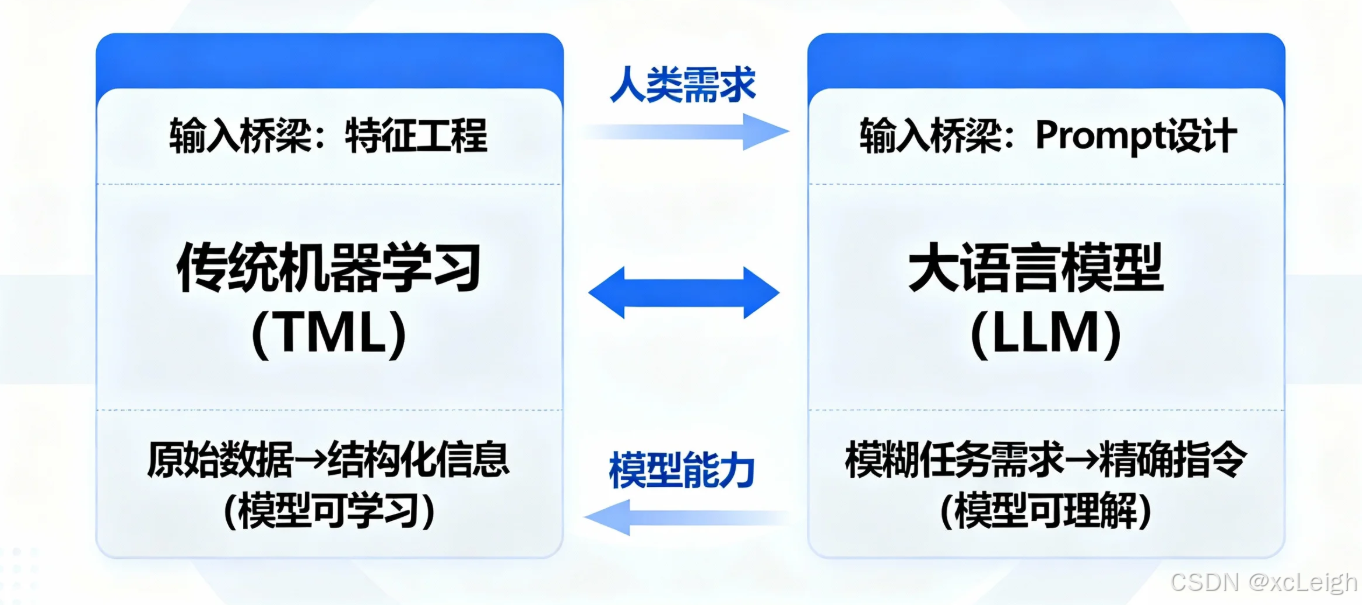
以电商用户购买预测场景为例:传统机器学习中,工程师需要从用户的历史购买记录、浏览时长、收藏行为等原始数据中,提取"近30天购买频率""平均客单价""品类偏好标签"等特征,才能让逻辑回归、随机森林等模型学习到用户的购买规律;而在 LLM 场景下,若要实现类似的用户需求预测,工程师只需设计 Prompt(如"基于以下用户行为数据,分析该用户未来1个月内最可能购买的3类商品,并说明理由:用户行为数据列表"),即可让模型直接输出预测结果。
理解两者的异同,不仅能帮助从业者在不同技术场景下选择更高效的方案,更能为"传统机器学习与 LLM 融合"(如用 Prompt 辅助特征生成)提供思路。本文将从核心定义、工作流程、技术特点等维度,系统剖析两者的相同点与差异,并结合实际案例说明其适用场景。
二、核心定义:明确两者的技术边界
在深入对比前,需先明确 Prompt 与传统机器学习特征工程的核心定义,避免因概念混淆导致分析偏差。

(一)传统机器学习特征工程
传统机器学习特征工程是指在模型训练前,对原始数据进行预处理、转换、提取和选择,最终生成符合模型输入要求的结构化特征的过程。其核心目标是"降低模型学习难度"------由于传统机器学习模型(如逻辑回归、SVM、XGBoost)的"自主理解能力"较弱,无法直接处理非结构化数据(如文本、图像原始像素)或杂乱的结构化数据(如含缺失值的表格),必须通过人工或半自动化手段将数据"加工"成模型能"读懂"的格式。
特征工程的产出物是"特征向量",例如:
- 对文本数据,通过 TF-IDF 转化为"词语-频率"矩阵(如"苹果"在某篇文章中出现5次,对应特征值为0.8;"手机"出现2次,对应特征值为0.3);
- 对图像数据,通过边缘检测、纹理提取等算法生成"边缘强度""色彩直方图"等特征;
- 对结构化数据,通过归一化(如将"年龄"从0-100映射到0-1)、独热编码(如将"性别"的"男/女"转化为1,0/0,1)生成标准特征向量。
(二)Prompt
Prompt 是指在与大语言模型交互时,用户输入的包含"任务指令、背景信息、示例(可选)"的文本内容,其核心目标是"引导模型准确理解任务需求并输出符合预期的结果"。与传统特征工程不同,Prompt 不直接参与模型训练过程,而是在"模型推理阶段"通过文本指令调节模型的输出,相当于为模型提供"临时任务说明书"。
Prompt 的产出物是"模型可理解的任务描述",例如:
- 基础指令类:"总结以下文章的核心观点,要求分3点,每点不超过20字:文章内容";
- 示例引导类(Few-Shot Prompt):"请模仿以下示例,将中文句子翻译成英文。示例1:输入'我喜欢读书',输出'I like reading';示例2:输入'今天天气很好',输出'Today the weather is very good'。现在输入'明天要去旅行',输出:";
- 逻辑链引导类(Chain-of-Thought Prompt):"请计算:小明有5个苹果,吃了2个,又买了3个,现在有几个?请分步说明计算过程。"
三、相同点:构建"输入-模型"连接的核心逻辑
尽管 Prompt 与传统特征工程的技术路径差异显著,但两者在解决"模型如何理解任务"的核心问题上,存在三大关键共性。
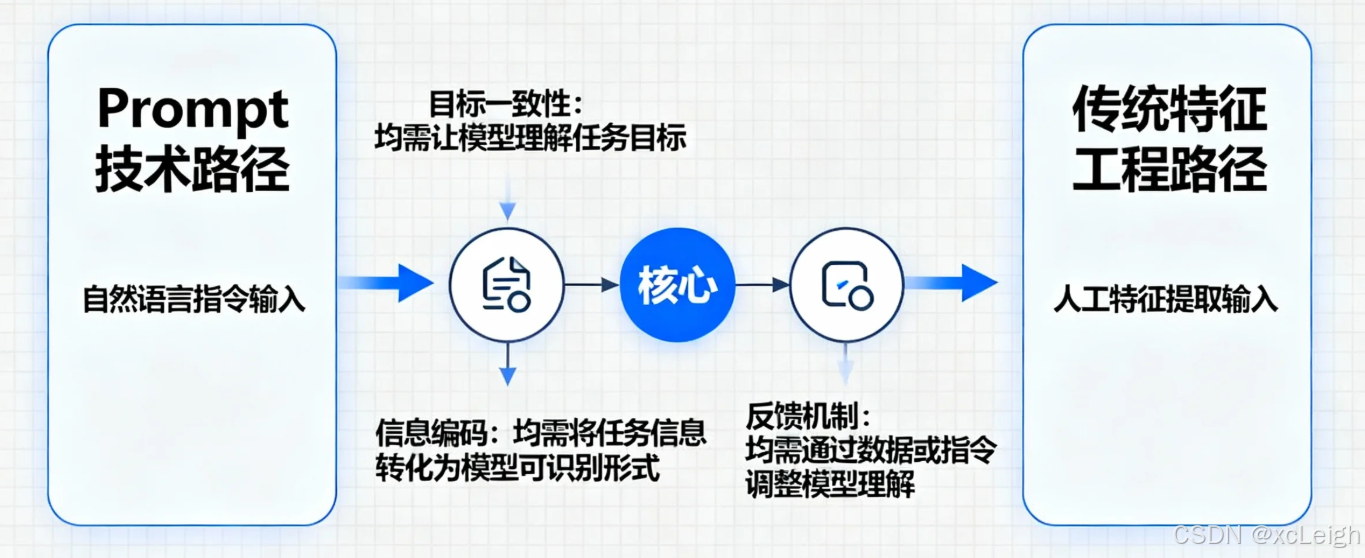
(一)目标一致:降低模型的"理解成本"
无论是特征工程还是 Prompt,最终目的都是让模型更轻松地理解任务需求,减少"无效学习"或"误解任务"的概率。
- 传统特征工程中,若直接将原始的用户行为日志(如"2024-05-01 浏览商品A;2024-05-03 收藏商品B")输入XGBoost模型,模型无法直接识别"浏览-收藏"的关联性,也无法量化用户的兴趣强度;而通过特征工程提取"近7天浏览品类数""收藏商品与历史购买商品的重合度"等特征后,模型可直接基于这些结构化信息学习"兴趣-购买"的映射关系,大幅降低理解成本。
- Prompt 场景中,若仅向 ChatGPT 输入"分析用户行为",模型会因任务模糊(分析什么?输出格式是什么?)而输出泛泛的结论;但通过明确的 Prompt(如"分析以下用户的3个核心消费偏好:1. 偏好的商品品类;2. 消费频率;3. 价格敏感度。要求每个偏好配1个行为案例支撑:用户行为数据"),模型可快速定位任务核心,直接输出精准结果。
(二)依赖"领域知识":人工经验是关键输入
两者的效果均高度依赖从业者的领域知识,而非完全自动化的技术流程------缺乏对业务场景的理解,无论是特征工程还是 Prompt 设计,都难以产出高质量结果。
- 传统特征工程中,以"信用卡欺诈检测"为例:若工程师不了解欺诈用户的典型行为(如"短时间内跨地域交易""单次交易金额远超历史均值"),可能会忽略"交易地域与用户常用地域的差异度""单笔交易金额/近30天平均交易金额"等关键特征,导致模型漏检欺诈行为;而具备领域知识的工程师会针对性设计这些特征,大幅提升模型的检测精度。
- Prompt 场景中,以"生成医疗科普文章"为例:若 Prompt 设计者不了解医学科普的"准确性-通俗性平衡"原则(如避免专业术语堆砌,用"高血压"而非"原发性高血压",用"血管弹性下降"而非"动脉粥样硬化"),可能会设计出"详细解释高血压的病理机制"的 Prompt,导致模型输出的内容过于专业,普通读者无法理解;而具备医疗领域知识的设计者会在 Prompt 中加入"用生活化比喻解释病理,避免超过3个专业术语,适合50岁以上读者"的约束,确保输出符合需求。
(三)需"迭代优化":通过反馈调整提升效果
两者均非"一次性设计即可完美"的过程,而是需要基于模型输出结果的反馈,持续迭代优化,直至达到预期效果------本质上都是"试错-调整-验证"的循环过程。
- 传统特征工程的迭代:以"电影评分预测"任务为例,初始设计的特征可能包括"电影类型""导演知名度""演员粉丝数",但模型训练后发现"预测误差较高";通过分析误差样本(如某部"小成本喜剧片"评分远超模型预测),工程师可能会补充"电影喜剧元素密度""观众笑点匹配度"等特征,再次训练后模型误差显著降低;若仍有误差,可能还需调整特征的归一化方式(如从"Min-Max归一化"改为"Z-Score归一化"),持续优化至满足业务要求。
- Prompt 的迭代:以"生成产品推广文案"为例,初始 Prompt 为"为手机X写一段推广文案",模型输出的内容可能过于笼统(如"手机X性能强,拍照好");基于反馈,设计者补充约束(如"突出手机X的2个核心卖点:1. 120W超快闪充(30分钟充满电);2. 1英寸大底主摄(夜景拍摄清晰)。文案风格要年轻化,用网络热词,适合朋友圈传播"),模型输出的文案更精准(如"手机Xyyds!120W闪充半小时满血,1英寸大底夜拍封神,年轻人的第一台全能机!");若发现"网络热词使用过于生硬",可进一步在 Prompt 中加入"热词自然融入,不刻意堆砌"的要求,持续优化至符合推广需求。
四、差异点:技术路径与应用场景的核心区分
尽管两者存在共性,但在"作用阶段""数据要求""自动化程度"等关键维度,Prompt 与传统特征工程存在显著差异,这些差异直接决定了它们在不同技术场景下的适用性。
(一)作用阶段:"训练前" vs "推理时"
这是两者最核心的差异------传统特征工程作用于模型训练前 ,是"一次性投入,长期复用";而 Prompt 作用于模型推理时,是"单次任务单次设计,灵活调整"。
| 维度 | 传统特征工程 | Prompt |
|---|---|---|
| 作用阶段 | 模型训练前(数据预处理阶段) | 模型推理时(与模型交互的实时阶段) |
| 复用性 | 一旦设计完成,可用于多次模型训练(如同一批特征可用于XGBoost、LightGBM等不同模型的训练) | 单次任务专用,下次任务需重新设计或调整(如"生成手机文案"的Prompt无法直接用于"生成电脑文案") |
| 调整成本 | 调整特征需重新处理数据、重新训练模型,成本高(如补充一个新特征可能需要重新跑通整个数据 pipeline) | 调整 Prompt 仅需修改文本指令,无需重新训练,成本低(如修改文案风格仅需在 Prompt 中加入"风格改为商务风"的约束) |
案例对比:以"电商商品推荐"为例
- 传统特征工程:在训练推荐模型(如协同过滤+LR)前,工程师需提取"用户历史购买特征""商品属性特征""用户-商品交互特征"等,这些特征一旦确定,模型训练完成后可长期用于推荐(如半年内若业务逻辑不变,无需重新设计特征);若要新增"用户近期搜索关键词"特征,需重新处理近半年的搜索日志,生成新特征向量,再重新训练模型,整个过程可能需要1-2周。
- Prompt 场景:用 LLM 做商品推荐时,每次推荐前需根据用户当前的行为(如"刚浏览了笔记本电脑")设计 Prompt(如"基于用户刚浏览的笔记本电脑(型号:XX,预算:5000-7000元),推荐3款同价位、配置相近的竞品,每款推荐理由不超过2句话");若用户后续浏览了"无线鼠标",只需直接修改 Prompt 中的商品信息,无需重新训练模型,调整过程仅需1-2分钟。
(二)数据要求:"结构化输入" vs "灵活输入"
传统特征工程对数据的"结构化程度"要求极高,而 Prompt 可接受非结构化、半结构化的灵活输入,大幅降低了数据预处理的门槛。
- 传统特征工程:必须将数据转化为固定维度的结构化特征向量 ,否则模型无法输入。例如:
- 处理文本数据时,需通过 TF-IDF、Word2Vec 等方法将文本转化为长度固定的向量(如每个句子转化为100维的向量);
- 处理图像数据时,需将图像 resize 到固定尺寸(如224×224),再通过 CNN 提取固定维度的特征(如512维);
- 若数据存在缺失值(如部分用户的"年龄"未填写),需通过均值填充、中位数填充等方法补全,否则特征向量不完整,模型无法训练。
- Prompt:可直接接受非结构化文本、半结构化表格、甚至混合格式的输入 ,无需提前转化为固定维度的向量。例如:
- 输入非结构化文本:直接将用户的自由评论(如"这个手机续航太差了,玩1小时游戏就没电,而且拍照颜色偏黄")输入 Prompt(如"分析以下用户评论的2个核心负面反馈,并提出1个改进建议:评论内容"),模型可直接处理;
- 输入半结构化表格:将包含"商品名称、价格、销量"的表格(如"商品A:价格199元,销量1000件;商品B:价格299元,销量800件")输入 Prompt(如"对比以下2款商品的性价比,给出购买建议"),模型可识别表格结构并分析;
- 无需处理缺失值:若输入数据中缺少"商品重量"信息,只需在 Prompt 中说明"部分商品重量未提供,分析时可忽略该维度",模型会自动调整分析逻辑,无需提前填充数据。
(三)自动化程度:"高度依赖人工" vs "部分自动化"
传统特征工程的全流程(特征设计、提取、选择)高度依赖人工,自动化工具仅能辅助部分环节;而 Prompt 可通过"自动 Prompt 生成""Prompt 模板"等方式实现部分自动化,降低人工成本。
-
传统特征工程:
- 核心环节(特征设计)完全依赖人工:工程师需基于业务经验设计"有价值"的特征,例如"信用卡欺诈检测"中,"交易间隔时间""交易金额波动"等特征无法通过工具自动生成,必须人工思考;
- 辅助环节(特征提取、选择)可自动化:例如用 Python 的 Pandas 库自动提取"近7天交易次数",用 sklearn 的 SelectKBest 自动选择信息量最大的前20个特征,但这些工具仅能执行"人工设计好的规则",无法自主创造新特征;
- 痛点:当数据维度极高(如用户行为日志有1000+个原始字段)时,人工设计特征的效率极低,可能遗漏关键特征,导致模型效果不佳。
-
Prompt:
- 基础场景可通过"模板化"实现自动化:例如"生成商品文案"可设计固定模板(如"【商品名称】:{name};【核心卖点】:{selling_point};【文案风格】:{style};要求:用{style}风格突出{selling_point},字数控制在{word_count}字以内"),只需替换模板中的变量(如{name}填"无线耳机"),即可自动生成 Prompt,无需每次人工从零设计;
- 复杂场景可通过"Meta-Prompt"实现半自动化:例如用"请为'分析用户购物车商品的消费需求'任务设计一个 Prompt,要求包含:1. 任务目标;2. 输出格式(分点说明);3. 分析维度(价格、品类、使用场景)"作为 Meta-Prompt,输入 LLM 后,模型可自动生成符合要求的 Prompt,人工仅需微调即可使用;
- 优势:对于非专业用户(如市场营销人员,无机器学习背景),可通过模板或 Meta-Prompt 快速生成 Prompt,无需理解"特征工程"的复杂逻辑,降低了使用门槛。
(四)模型适配性:"针对特定模型" vs "跨模型通用"
传统特征工程的设计需适配特定模型的输入要求,不同模型的特征格式可能完全不同;而 Prompt 具有"跨模型通用性",同一 Prompt 可在不同 LLM 中使用(如 ChatGPT、Claude、Gemini 均可理解相同的 Prompt 指令)。
-
传统特征工程:
- 模型输入格式约束严格:例如逻辑回归模型要求输入"数值型特征向量",若特征中包含文本(如"商品描述"),必须先转化为数值向量;而图神经网络(GNN)要求输入"图结构特征"(如用户-商品的关联图),与传统的向量特征完全不同,需重新设计特征;
- 特征类型适配:例如决策树模型对"类别型特征"的处理更友好(无需独热编码),而 SVM 模型对"归一化后的数值特征"更敏感,工程师需根据模型类型调整特征工程的方法(如给 SVM 模型的特征做 Z-Score 归一化,给决策树模型的特征做标签编码)。
-
Prompt:
- 跨 LLM 通用:同一 Prompt 可在不同 LLM 中使用,无需因模型差异调整指令。例如"总结以下文章的3个核心观点,每点不超过20字:文章内容"这一 Prompt,无论是输入 ChatGPT-4、Claude-2 还是 Gemini Pro,模型都能理解任务需求并输出符合格式的结果;
- 无需适配模型结构:LLM 的输入均为文本格式,无论模型的底层结构是 Transformer 还是其他架构,只要支持文本输入,Prompt 均可直接使用,无需考虑"特征是否符合模型的输入维度""是否需要归一化"等问题。
五、适用场景对比:如何选择更高效的方案?
基于上述异同点,Prompt 与传统特征工程在不同的业务场景、技术条件下,各有其适用范围。选择的核心逻辑是:"业务需求是否需要快速迭代?数据是否结构化?模型是否为 LLM?"

(一)传统特征工程更适用的场景
当业务需求稳定、数据结构化程度高、模型为传统机器学习模型时,传统特征工程是更高效的选择------其"一次性投入,长期复用"的特点可降低长期成本。
-
高并发、低延迟的线上业务
例如电商平台的"实时推荐""广告点击率预测":这类业务要求模型响应时间在毫秒级(如推荐结果需在0.5秒内返回),且业务逻辑(如推荐的核心指标是"点击率"还是"转化率")半年内基本稳定。传统特征工程可提前将特征预处理为固定维度的向量,模型训练完成后直接加载特征向量进行推理,响应速度快;而 Prompt 依赖 LLM 推理,响应时间通常在秒级(如 ChatGPT 生成结果需1-3秒),无法满足高并发、低延迟的需求。
-
数据结构化且维度固定的场景
例如银行的"信贷风险评估":输入数据为用户的"收入、负债、征信记录"等结构化表格,维度固定(如20个字段),且业务目标(评估用户的还款能力)长期不变。传统特征工程可通过人工设计"收入负债比""征信逾期次数"等关键特征,模型训练后可长期复用这些特征;而 Prompt 需每次输入用户数据后生成指令,且 LLM 对结构化数据的分析效率(如计算"收入负债比")不如传统模型(如逻辑回归)精准、快速。
-
模型为传统机器学习模型的场景
例如用 XGBoost 做"用户流失预测":传统机器学习模型无法理解文本指令,必须通过特征工程将原始数据转化为数值向量;若强行用 Prompt 辅助,需先将特征向量转化为文本描述(如"用户近3个月登录次数10次,消费金额500元"),再输入 LLM 预测,不仅增加了数据转换成本,还可能因文本描述丢失关键信息(如"登录次数的归一化值"),导致预测精度下降。
(二)Prompt 更适用的场景
当业务需求灵活迭代、数据非结构化、模型为 LLM 时,Prompt 是更高效的选择------其"快速调整、灵活适配"的特点可大幅提升业务响应速度。
-
需求频繁变化的创意类业务
例如市场营销的"文案生成""活动策划":这类业务的需求每天可能变化(如今天需要"幽默风格的短视频文案",明天需要"商务风格的产品介绍"),且输出格式不固定(如文案、脚本、PPT大纲)。Prompt 可通过调整指令(如"改为商务风格,输出PPT标题+3点核心内容")快速适配需求,无需重新训练模型;而传统特征工程若要支持这类需求,需为每种"文案风格""输出格式"设计不同的特征(如"幽默风格特征""PPT结构特征"),需求变化时需重新设计特征、训练模型,响应速度远不及 Prompt。
-
非结构化数据处理场景
例如企业的"客户评论分析""文档摘要生成":输入数据为非结构化的文本(如用户的自由评论、100页的PDF报告),传统特征工程需先将文本转化为 TF-IDF 向量,再用分类模型(如SVM)做情感分析,或用主题模型(如LDA)提取关键词,但无法直接生成"分点摘要""情感原因分析"等结构化结果;而通过 Prompt(如"分析以下100条客户评论:1. 统计正面/负面评论占比;2. 列出负面评论的3个核心原因,每个原因配2个例子;3. 生成100字的总结"),LLM 可直接处理非结构化文本,输出符合要求的结构化结果,无需复杂的特征预处理。
-
低数据量、高定制化的场景
例如初创公司的"竞品分析报告""用户调研总结":这类场景通常数据量小(如仅50份用户问卷、3份竞品报告),且需求定制化程度高(如"分析竞品的定价策略与用户反馈的关联性")。传统特征工程因"需要大量数据训练模型"且"特征设计成本高",难以快速落地;而 Prompt 可基于少量数据直接生成定制化结果(如"基于以下50份用户问卷,分析用户对竞品定价的3个核心反馈,以及与自身产品的定价差异:问卷内容"),无需数据训练,10分钟内即可输出结果。
六、融合趋势:Prompt 与传统特征工程的协同应用
随着 LLM 与传统机器学习的融合,Prompt 与传统特征工程不再是"非此即彼"的选择,而是可形成"协同互补"的关系------用 Prompt 辅助特征工程,或用特征工程提升 Prompt 的效果,成为新的技术趋势。

(一)用 Prompt 辅助传统特征工程:降低人工成本
传统特征工程中,"特征设计"是最依赖人工的环节,而 Prompt 可通过"自动生成特征建议""辅助特征筛选",大幅提升特征工程的效率。
- 案例:"用户流失预测"的特征工程辅助
工程师可向 LLM 输入 Prompt:"我需要为'电商用户流失预测'任务设计特征,已知原始数据包含'用户近3个月的登录记录、购买记录、收藏记录、客服咨询记录',请列出10个可能的关键特征,并说明每个特征的设计逻辑(如'近30天登录次数':反映用户活跃度,活跃度低的用户更易流失)。"
LLM 会输出特征建议(如"近30天购买次数""近7天客服咨询次数""收藏商品与历史购买商品的重合度"等),工程师无需从零思考,仅需基于这些建议筛选、调整即可,将特征设计时间从"3天"缩短至"1天"。
(二)用传统特征工程提升 Prompt 效果:增强结果精准度
在 Prompt 场景中,若输入数据包含结构化信息(如用户的消费金额、购买频率),可先通过传统特征工程提取关键指标,再将这些指标融入 Prompt,让模型的分析更精准。
- 案例:"用户消费能力分析"的 Prompt 优化
原始 Prompt 若仅输入"用户的购买记录"(如"2024-05-01 购买商品A(199元);2024-05-03 购买商品B(299元)"),模型可能仅能判断"用户消费金额较低",但无法量化;而通过传统特征工程提取"近3个月平均客单价(249元)""近3个月消费总额(747元)""购买商品的价格区间(100-300元)"等特征后,将这些特征融入 Prompt:"基于用户的消费特征(近3个月平均客单价249元,消费总额747元,购买商品价格区间100-300元),分析该用户的消费能力等级(低/中/高),并说明判断依据。"
模型可基于这些结构化特征输出更精准的结论(如"消费能力中等:平均客单价处于平台100-300元的主流区间,消费总额符合月度300-1000元的中等用户水平"),避免因原始数据杂乱导致的分析偏差。
七、总结:从"工具选择"到"思维升级"
Prompt 与传统特征工程并非对立的技术,而是分别适用于"灵活迭代场景"与"稳定需求场景"的核心工具------两者的本质都是"通过优化输入,最大化模型价值",但技术路径的差异决定了它们的适用边界。
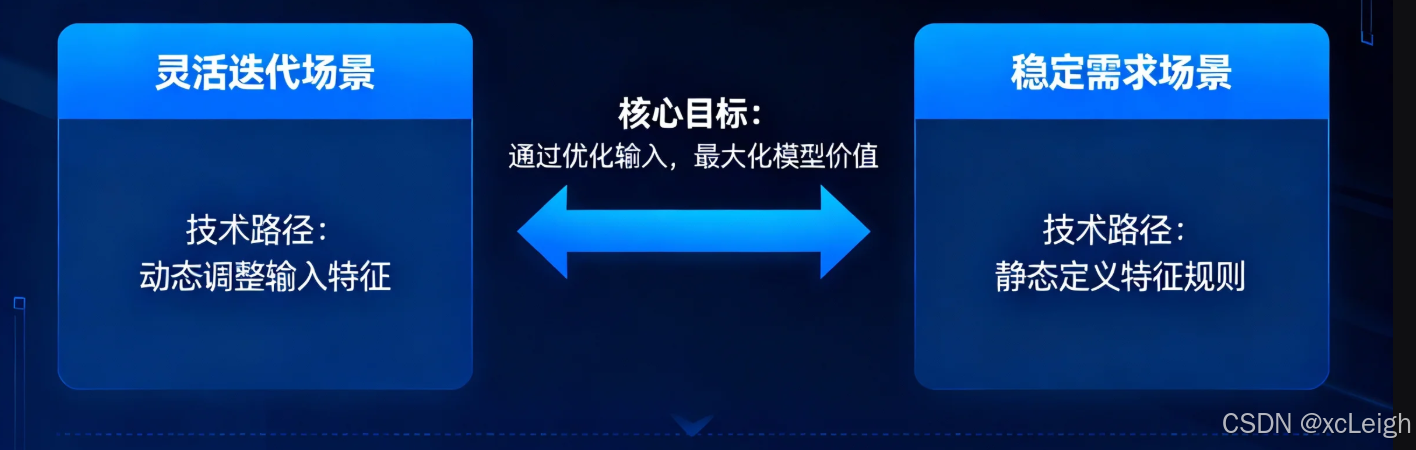
- 当你面临稳定的业务需求、结构化数据、传统机器学习模型时,传统特征工程是更高效的选择,其"一次性投入,长期复用"的特点可降低长期成本;
- 当你面临灵活的创意需求、非结构化数据、LLM 模型时,Prompt 是更优的方案,其"快速调整、低门槛"的特点可大幅提升业务响应速度;
- 当你需要平衡效率与精准度时,可尝试两者的融合(如用 Prompt 生成特征建议,用传统特征工程验证、筛选特征),实现"1+1>2"的效果。
对于从业者而言,理解两者的异同不仅是"选择工具"的问题,更是"思维升级"的过程------从"传统机器学习的特征驱动思维"到"LLM 时代的指令驱动思维",再到"两者融合的协同思维",才能在快速变化的 AI 技术浪潮中,始终选择最适合业务需求的解决方案。
联系博主
xcLeigh 博主,全栈领域优质创作者,博客专家,目前,活跃在CSDN、微信公众号、小红书、知乎、掘金、快手、思否、微博、51CTO、B站、腾讯云开发者社区、阿里云开发者社区等平台,全网拥有几十万的粉丝,全网统一IP为 xcLeigh。希望通过我的分享,让大家能在喜悦的情况下收获到有用的知识。主要分享编程、开发工具、算法、技术学习心得等内容。很多读者评价他的文章简洁易懂,尤其对于一些复杂的技术话题,他能通过通俗的语言来解释,帮助初学者更好地理解。博客通常也会涉及一些实践经验,项目分享以及解决实际开发中遇到的问题。如果你是开发领域的初学者,或者在学习一些新的编程语言或框架,关注他的文章对你有很大帮助。
亲爱的朋友,无论前路如何漫长与崎岖,都请怀揣梦想的火种,因为在生活的广袤星空中,总有一颗属于你的璀璨星辰在熠熠生辉,静候你抵达。
愿你在这纷繁世间,能时常收获微小而确定的幸福,如春日微风轻拂面庞,所有的疲惫与烦恼都能被温柔以待,内心永远充盈着安宁与慰藉。
至此,文章已至尾声,而您的故事仍在续写,不知您对文中所叙有何独特见解?期待您在心中与我对话,开启思想的新交流。
💞 关注博主 🌀 带你实现畅游前后端!
🏰 大屏可视化 🌀 带你体验酷炫大屏!
💯 神秘个人简介 🌀 带你体验不一样得介绍!
🥇 从零到一学习Python 🌀 带你玩转Python技术流!
🏆 前沿应用深度测评 🌀 前沿AI产品热门应用在线等你来发掘!
💦 注 :本文撰写于CSDN平台 ,作者:xcLeigh (所有权归作者所有) ,https://xcleigh.blog.csdn.net/,如果相关下载没有跳转,请查看这个地址,相关链接没有跳转,皆是抄袭本文,转载请备注本文原地址。

📣 亲,码字不易,动动小手,欢迎 点赞 ➕ 收藏,如 🈶 问题请留言(或者关注下方公众号,看见后第一时间回复,还有海量编程资料等你来领!),博主看见后一定及时给您答复 💌💌💌