在自动驾驶技术发展过程中,传统模块化方案(感知、预测、规划独立部署)存在信息丢失、误差累积等问题,而多任务学习范式又易出现 "负迁移" 现象。为解决这些痛点,上海 AI 实验室等机构联合提出了UniAD(Unified Autonomous Driving) ------ 一个以规划为核心导向,融合全栈驾驶任务的端到端统一框架。
原文链接:https://arxiv.org/pdf/2212.10156
代码链接:https://github.com/OpenDriveLab/UniAD
沐小含持续分享前沿算法论文,欢迎关注...
一、论文核心背景与创新点
1.1 现有方案的局限性
自动驾驶系统的经典实现路径主要分为三类,各有明显缺陷:
- 独立模块化方案:感知、预测、规划采用独立模型部署(如图 1 (a)),虽简化研发流程,但模块间优化目标孤立,易导致信息丢失、误差累积和特征错位。
- 多任务学习方案:通过共享骨干网络 + 独立任务头实现多任务联合训练(如图 1 (b)),虽节省计算成本,但存在任务间 "负迁移" 风险,且未围绕核心目标优化。
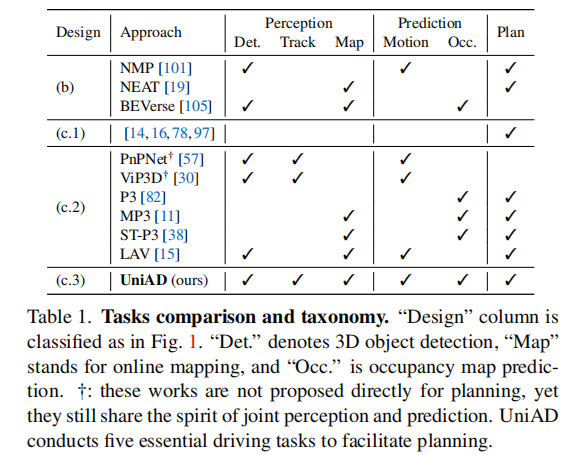
- 传统端到端方案:要么直接跳过中间任务预测规划轨迹(如图 1 (c.1)),缺乏安全性和可解释性;要么仅整合部分中间任务(如图 1 (c.2)),未充分发挥任务协同价值。
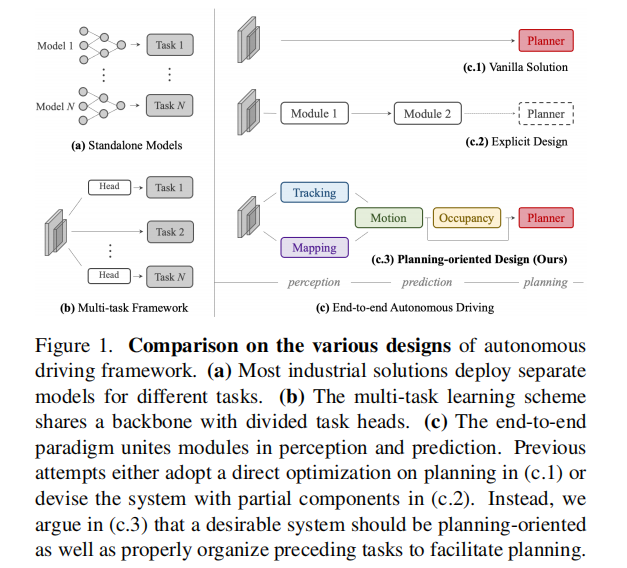
1.2 核心创新思想
UniAD 的核心突破在于 "以规划为中心的任务协同设计":不将感知、预测视为独立任务,而是将其作为规划的前置支撑模块,通过统一查询接口实现任务间高效通信,让所有模块共同为安全规划服务(如图 1 (c.3))。具体创新点包括:
- 提出规划导向的全栈任务整合范式,明确感知、预测任务的优先级和协同逻辑;
- 设计基于查询(Query)的统一接口,连接所有任务模块,缓解误差累积并强化 agent 交互建模;
- 首次全面整合五大核心驾驶任务(3D 目标检测与跟踪、在线地图构建、运动预测、占用预测、规划),形成端到端闭环;
- 通过两阶段训练、非线性优化等技术,平衡感知精度与规划安全性。
二、UniAD 整体框架详解
UniAD 的整体 pipeline 如图 2 所示,以多相机图像为输入,通过 BEV 特征编码、四大基于 Transformer 解码器的感知 / 预测模块,最终输出安全的驾驶规划轨迹。所有模块通过查询接口实现信息交互,形成 "感知 - 预测 - 规划" 的有机闭环。
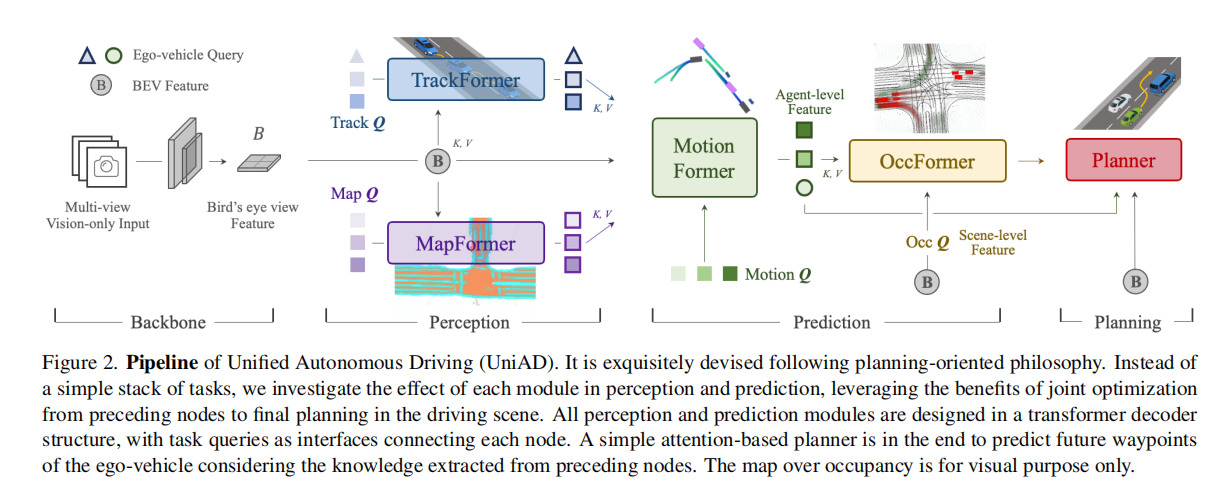
2.1 输入与特征编码
- 输入:多相机环绕视图图像序列(无激光雷达依赖,纯视觉方案);
- BEV 特征提取:采用 BEVFormer 的 BEV 编码器,将透视视图特征转换为统一的鸟瞰图(BEV)特征 B。该编码器支持多模态融合、长时时间融合等扩展,为后续任务提供全局空间特征支撑。
2.2 感知模块:跟踪与地图构建
感知模块的核心目标是为后续预测和规划提供准确的动态 agent 信息和静态环境信息,包含两个子模块:
2.2.1 TrackFormer:联合检测与多目标跟踪
TrackFormer 实现端到端的 3D 目标检测与多目标跟踪(MOT),无需非可微后处理(如 NMS),核心设计如下:
- 双查询机制:
- 检测查询(Detection Queries):负责检测当前帧新出现的 agent;
- 跟踪查询(Track Queries):持续建模前序帧已检测到的 agent,通过自注意力模块聚合时序信息;
- ** ego-vehicle 查询 **:专门引入 ego-vehicle 查询,显式建模自动驾驶车辆自身状态,为后续规划提供直接支撑;
- 输出 :有效 agent 的特征表示
(包含位置、运动状态等信息),以及 ego-vehicle 的特征查询。
2.2.2 MapFormer:在线地图全景分割
MapFormer 基于 Panoptic SegFormer 设计,实现无 HD 地图依赖的在线道路元素分割,核心特点:
- 地图查询设计:将道路元素(车道线、分隔符、人行横道、可行驶区域)编码为地图查询(Map Queries);
- 分类建模:将车道线、分隔符、人行横道视为 "thing"(实例级),可行驶区域视为 "stuff"(语义级);
- 输出 :地图查询特征
2.3 预测模块:运动预测与占用预测
预测模块是连接感知与规划的关键,通过两种互补的预测任务(运动预测、占用预测),全面建模未来场景动态,为规划提供安全约束:
2.3.1 MotionFormer:多模态运动预测
MotionFormer 以场景为中心(scene-centric),预测所有 agent 的多模态未来轨迹,核心设计如下:
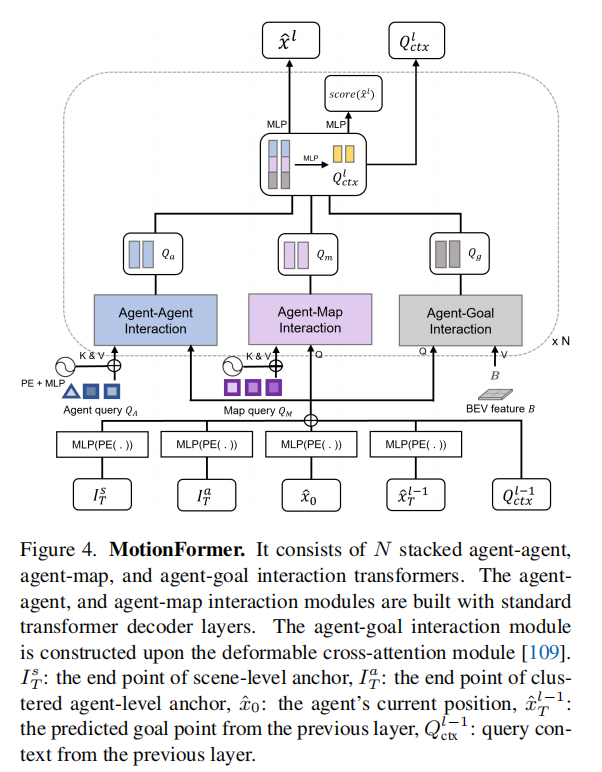
- 输入 :TrackFormer 输出的 agent 特征
- 三重交互建模:通过并行的注意力模块建模三类关键交互:
- agent-agent 交互:捕获多 agent 间的行为影响;
- agent-map 交互:结合道路结构约束 agent 运动;
- agent-goal 交互:通过可变形注意力聚焦 agent 目标点周围特征,优化轨迹平滑性;
- 运动查询(Motion Queries):融合场景级锚点、agent 级锚点、当前位置、预测目标点四类位置信息,通过正弦位置编码和 MLP 生成,支持粗到精的轨迹优化;
- 非线性优化(NLO):针对上游感知误差,通过 kinematic 约束(加加速度、曲率、横向加速度等)优化目标轨迹,确保物理可行性;
- 输出 :每个 agent 的 top-K 多模态轨迹(
2.3.2 OccFormer:实例级占用预测
占用预测任务旨在建模未来场景的稠密占用状态,与运动预测形成互补(运动预测聚焦 agent 个体,占用预测覆盖全局场景),核心设计:
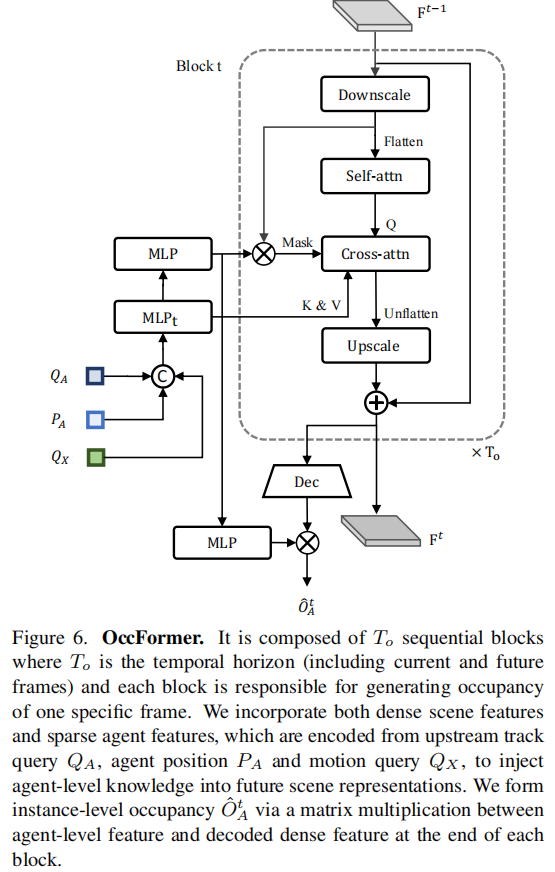
- 输入 :BEV 特征
- 时序块设计 :由
- 像素 - agent 交互:通过交叉注意力实现稠密场景特征与稀疏 agent 特征的融合,引入注意力掩码限制像素仅关注对应占用的 agent,提升定位准确性;
- 实例级占用生成 :通过矩阵乘法将 agent 特征与场景特征结合,直接生成保留 agent 身份的实例级占用图(
- 输出 :多时刻的实例级占用图
2.4 规划模块:安全轨迹生成
规划模块以 ego-vehicle 的安全行驶为最终目标,整合所有上游信息生成最优轨迹,核心设计:
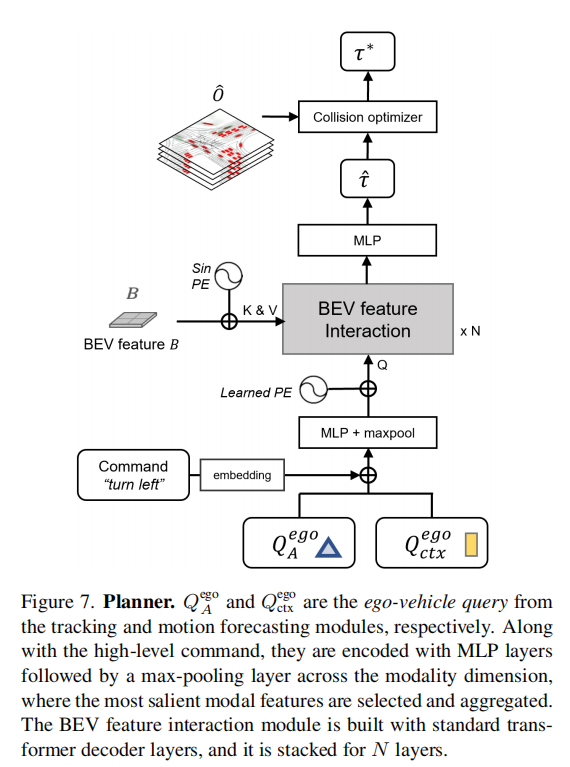
- 输入:MotionFormer 输出的 ego-vehicle 查询、OccFormer 输出的占用预测、导航指令(左转 / 右转 / 直行);
- 规划查询(Plan Query):将 ego-vehicle 特征与导航指令编码融合,形成规划查询,通过注意力机制感知 BEV 全局特征;
- 碰撞优化:基于牛顿法优化原始轨迹,通过成本函数平衡轨迹一致性(与原始预测的 L2 距离)和碰撞风险(远离占用区域);
- 输出 :优化后的未来轨迹
2.5 训练策略
UniAD 采用两阶段训练策略,确保训练稳定性和任务协同效果:
-
阶段一(感知预训练):仅训练 TrackFormer 和 MapFormer,加载 BEVFormer 预训练权重初始化,训练 6 个 epoch,冻结图像骨干网络以节省显存;
-
阶段二(端到端训练):联合训练所有模块(感知、预测、规划),冻结 BEV 编码器,训练 20 个 epoch,总损失函数为各任务损失加权和:
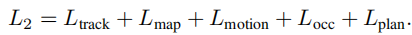
-
共享匹配机制:在感知和预测任务中采用二分图匹配算法,确保 agent 身份在跟踪、运动预测、占用预测中的一致性。
三、实验验证与结果分析
论文在 nuScenes 数据集上进行了全面实验,从任务协同有效性、模块性能、端到端效果三个维度验证 UniAD 的优越性。
3.1 实验设置
-
数据集:nuScenes(含多相机图像、3D 标注、轨迹标注等);
-
评价指标:
- 跟踪:AMOTA、AMOTP、IDS(身份切换次数);
- 地图构建:各类道路元素的 IoU;
- 运动预测:minADE、minFDE、MR(漏检率)、EPA;
- 占用预测:IoU(近 / 远场)、VPQ(视频全景质量);
- 规划:平均 L2 误差、碰撞率;
-
基线模型:BEVFormer、BEVerse、ST-P3、FIERY 等主流方案。
3.2 任务协同有效性验证
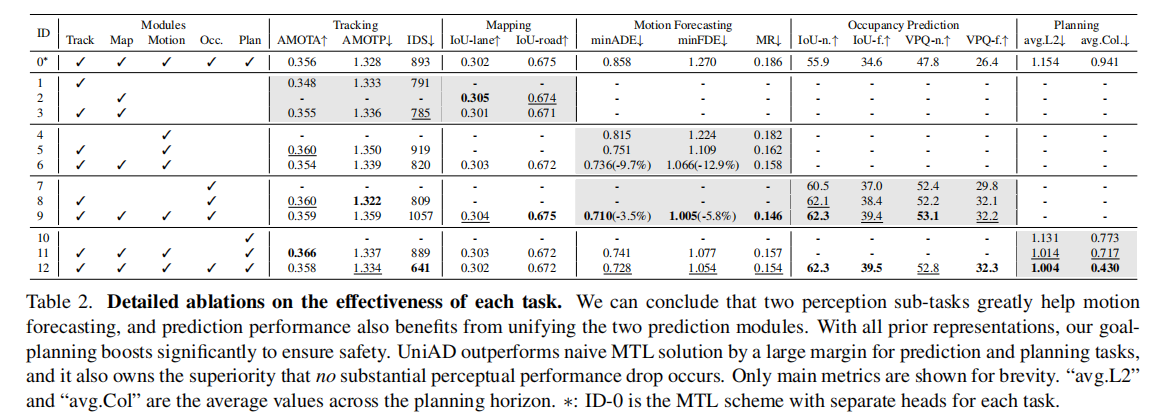
通过消融实验验证各模块对最终性能的贡献(表 2),关键结论:
- 感知双任务(跟踪 + 地图)协同能显著提升运动预测性能:minADE 降低 9.7%,minFDE 降低 12.9%;
- 预测双任务(运动 + 占用)联合建模能相互促进:运动预测 minADE 再降 3.5%,占用预测 IoU-f 提升 2.4%;
- 全任务整合后,规划性能大幅提升:平均 L2 误差降低 0.15m,碰撞率降低 51%,显著优于独立多任务基线(ID-0)。
3.3 各模块性能对比
3.3.1 感知模块性能
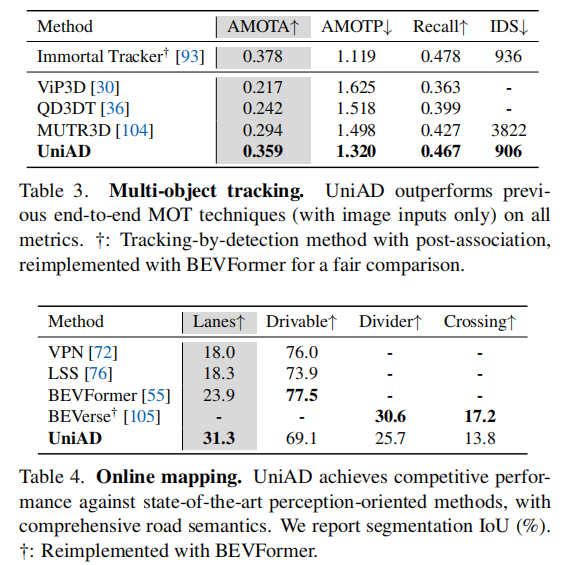
- 多目标跟踪(表 3):UniAD 的 AMOTA 达到 0.359,比 MUTR3D(0.294)提升 6.5%,比 ViP3D(0.217)提升 14.2%,且 IDS 最低, temporal 一致性更优;
- 在线地图构建(表 4):车道线分割 IoU 达到 31.3%,比 BEVFormer(23.9%)提升 7.4%,可行驶区域 IoU 达 69.1%,兼顾全面性和准确性。
3.3.2 预测模块性能
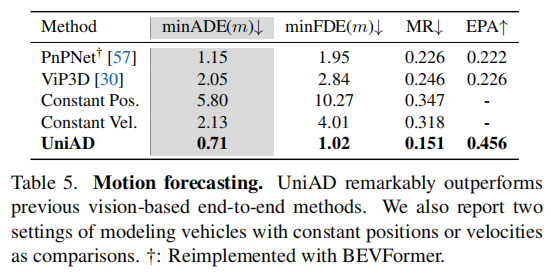
- 运动预测(表 5):minADE 仅 0.71m,比 PnPNet(1.15m)降低 38.3%,比 ViP3D(2.05m)降低 65.4%,MR 降至 0.151,多模态预测准确性显著提升;
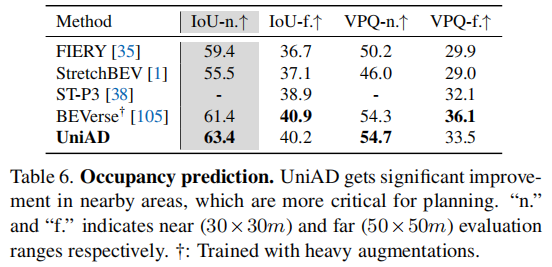
- 占用预测(表 6):近场 IoU 达 63.4%,比 FIERY(59.4%)提升 4.0%,比 BEVerse(61.4%)提升 2.0%,近场预测更精准(对规划更关键)。
3.3.3 规划模块性能
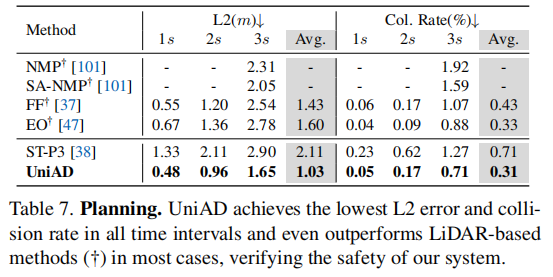
规划性能是 UniAD 的核心优势(表 7):
- 平均 L2 误差仅 1.03m,比 ST-P3(2.11m)降低 51.2%;
- 平均碰撞率仅 0.31%,比 ST-P3(0.71%)降低 56.3%;
- 在 1s/2s/3s 所有时间 horizon 均优于主流方案,甚至超过部分激光雷达基线路径。
3.4 定性结果分析

-
场景适应性:在城市巡航、行人避让、障碍物变道等场景中(图 9-11,以图9为例),UniAD 能准确感知环境、预测多 agent 行为,并生成安全轨迹;
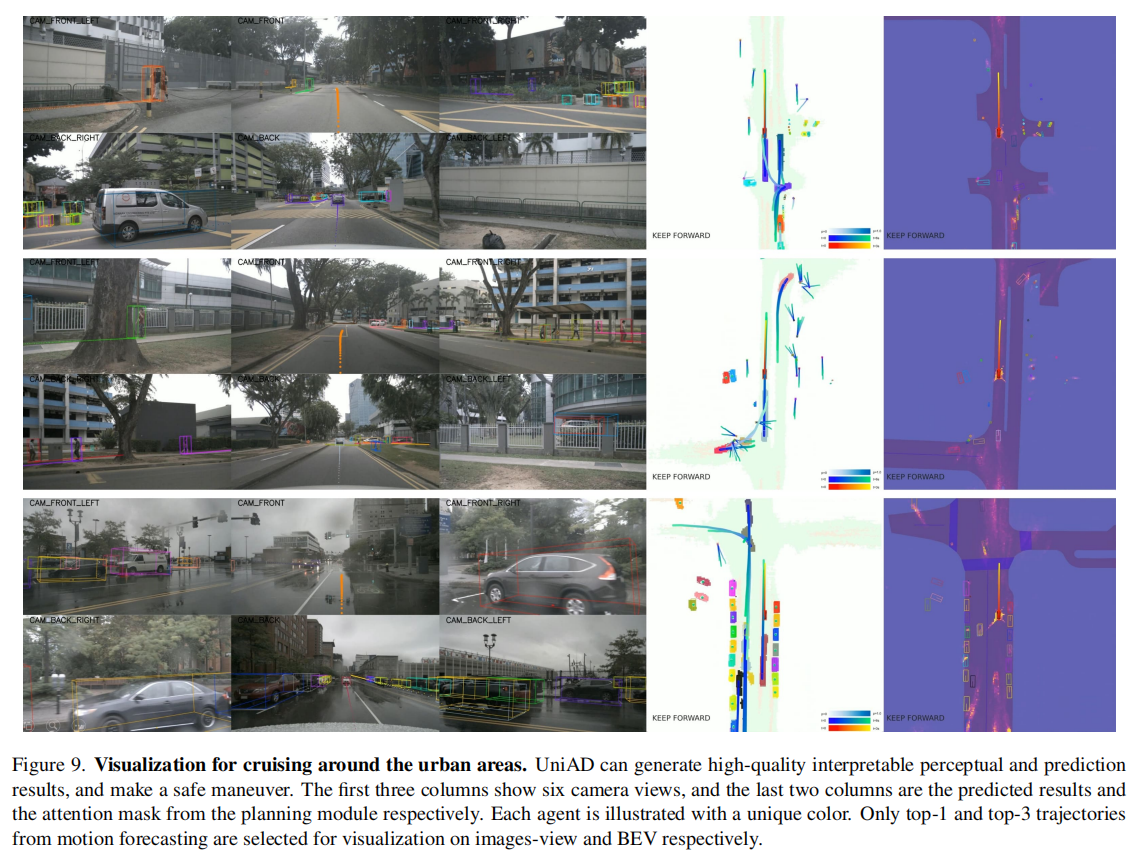
-
鲁棒性:即使感知模块出现误差(如漏检 agent),规划模块仍能通过占用预测和全局特征关注关键区域,实现轨迹恢复(图 12);
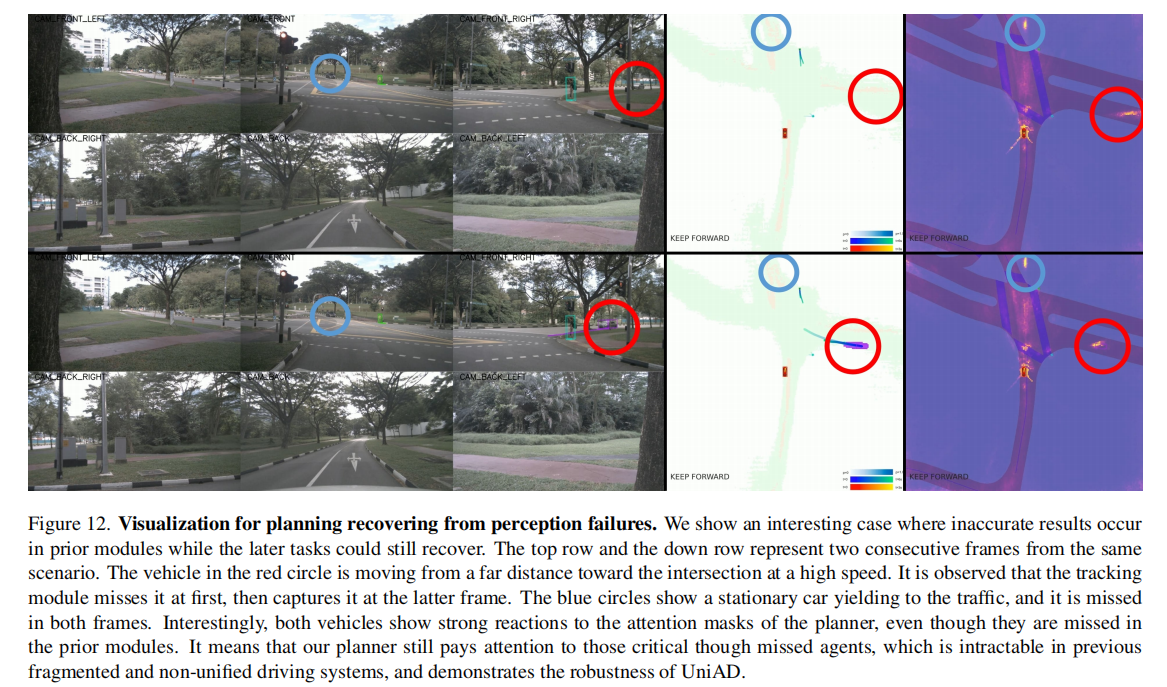
-
可解释性:规划模块的注意力掩码能精准聚焦目标车道和关键 agent,与导航指令和场景动态高度匹配(图 8)。

3.5 模型复杂度分析
UniAD 虽整合五大任务,但通过高效的查询设计和特征共享,保持了合理的计算开销(表 13):

- 总参数量 125M,FLOPs 1709G,比 BEVerse(102.5M/1921G)参数略增但计算量更低;
- 在 NVIDIA A100 上推理速度达 1.8 FPS,满足实时性需求;
- 提供 S/B/L 三种模型变体(表 12),可根据硬件资源灵活选择。

四、局限性与未来展望
4.1 现有局限
- 计算开销仍较大,特别是长时序历史数据训练时,对硬件资源要求较高;
- 在长尾场景(如大型卡车、拖车检测,昏暗环境)中性能有待提升;
- 未整合深度估计、行为预测等额外任务,潜在协同价值未充分挖掘。
4.2 未来方向
- 轻量化部署:优化模型结构,降低计算开销,适配车载低功耗芯片;
- 任务扩展:探索深度估计、行为意图预测等任务的整合方式;
- 场景泛化:提升在极端天气、特殊交通参与者等长尾场景的鲁棒性;
- 多模态融合:结合激光雷达、毫米波雷达数据,进一步提升感知精度。
五、总结
UniAD 提出了一种 "以规划为中心" 的自动驾驶统一框架,通过整合感知、预测、规划全栈任务,设计统一查询接口和协同训练策略,从根本上解决了传统方案的误差累积、任务割裂等问题。在 nuScenes 数据集上的实验表明,UniAD 在所有核心任务上均显著优于现有方案,尤其在规划安全性和端到端闭环性能上实现了突破性提升。
该论文的核心价值不仅在于提出了一个高性能的自动驾驶框架,更在于确立了 "目标导向的任务协同" 设计理念 ------ 自动驾驶系统应围绕 "安全规划" 这一最终目标,优化各模块的分工与协作,而非孤立追求单个任务的精度。这一理念为未来自动驾驶技术的发展提供了重要指引,有望推动端到端方案在实际场景中的落地应用。