知识点回顾
- 数据增强
- 卷积神经网络定义的写法
- batch 归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
零基础学简单 CNN:5 个核心知识点拆解(大白话 + 代码 + 例子)
首先说清楚:咱们今天学的 CNN(卷积神经网络),核心是让电脑像人一样 "看图片、找特征、认东西",比如认手写数字、认猫狗。我会用「生活例子 + 极简代码 + 分步解释」的方式讲,保证零基础能懂,理解能力差也别怕,咱们一步一步来。
先铺垫 2 个基础认知(不用记,有个印象就行):
- 图像数据:比如手写数字 MNIST 数据集里的一张图,是 28×28 的 "像素格子"(每个格子是 0-255 的数字,代表黑白深浅);彩色图是 28×28×3(RGB 三个颜色通道)。
- 训练 CNN 的目标:让电脑从这些像素格子里,找到 "特征"(比如数字 8 的两个圈、猫的耳朵),最后判断图片是啥。
知识点 1:数据增强(Data Augmentation)
🔍 大白话解释
就像教小孩认苹果:你只给 1 张 "正正方方的红苹果" 照片,小孩可能认不出 "歪的绿苹果""倒过来的苹果"。数据增强就是给电脑 "多看不同样子的同款图片",让它学得更 "灵活",不会认死理(专业叫 "过拟合")。
📌 为什么需要?
如果训练的图片都是规规矩矩的(比如所有数字 5 都居中、不倾斜),电脑遇到稍微变形的 5 就不认识了;增强后,数据变多、变多样,模型认东西的能力更强。
🎯 生活例子
比如手写数字 "5":
- 原图:正的、居中的 5
- 增强后:旋转 10 度的 5、稍微平移的 5、轻微缩放的 5(这些还是 5,但样子不同,相当于给模型多练题)
💻 代码实现(极简版)
用 PyTorch 的torchvision.transforms(新手友好,不用自己写增强逻辑),以 MNIST 手写数字为例:
python
# 第一步:导入需要的库
import torch
from torchvision import datasets, transforms
# 第二步:定义数据增强规则(新手先学最常用的3种)
data_aug = transforms.Compose([
transforms.RandomRotation(10), # 随机旋转±10度
transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移10%
transforms.ToTensor(), # 转成电脑能认的Tensor格式
])
# 第三步:加载MNIST数据集(带增强)
train_data = datasets.MNIST(
root="data", # 数据存在本地的文件夹
train=True, # 训练集
download=True,# 自动下载(第一次运行会下,之后不会)
transform=data_aug # 应用数据增强
)
# 验证:打印增强后的数据形状(看一眼就行)
print("单张增强后图片的形状:", train_data[0][0].shape) # 输出:torch.Size([1, 28, 28])数据增强代码实现(零基础友好版)
这次我们聚焦数据增强的完整实现 ,包含「单张图片增强可视化」和「批量数据集增强」两部分,用最常用的torchvision库(和 CNN 适配),代码注释超详细,还能直观看到增强效果。
第一步:安装依赖(新手先做)
打开命令行,执行以下命令安装需要的库:

pip install torch torchvision matplotlib pillow
第二步:单张图片数据增强(可视化对比)
适合理解「增强到底改了啥」,我们用手写数字图片为例,先加载原图,再定义增强规则,最后对比原图和增强后的效果。
python
# 1. 导入核心库
import torch
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 2. 准备一张示例图片(两种方式选其一)
## 方式1:用本地图片(推荐)
# 把你的图片放在代码同目录,命名为 "digit5.png"(手写数字5最好)
# img = Image.open("digit5.png").convert("L") # convert("L")转黑白
## 方式2:自动生成模拟的手写数字图(不用本地文件)
# 生成一张28×28的黑白图,模拟数字5的像素
img_np = np.zeros((28,28), dtype=np.uint8)
img_np[7:21, 7:12] = 255 # 数字5的竖线
img_np[10:15, 12:18] = 255 # 数字5的横线
img = Image.fromarray(img_np, mode="L")
# 3. 定义数据增强规则(新手常用的5种)
augment = transforms.Compose([
transforms.RandomRotation(15), # 随机旋转±15度(数字歪一点)
transforms.RandomAffine(0, translate=(0.15, 0.15)), # 随机平移15%(数字偏一点)
transforms.RandomResizedCrop(28, scale=(0.8, 1.0)), # 随机裁剪+缩放(保留80%-100%)
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转(50%概率)
# 注意:ToTensor要放在最后(把PIL图片转成模型能认的Tensor)
transforms.ToTensor()
])
# 4. 可视化:原图 vs 5张增强后的图
plt.figure(figsize=(12, 3))
# 显示原图
plt.subplot(1, 6, 1)
plt.imshow(img, cmap="gray")
plt.title("原图")
plt.axis("off")
# 显示5张增强后的图
for i in range(5):
# 应用增强(返回Tensor,形状[1,28,28])
img_aug = augment(img)
# 把Tensor转回PIL图片格式(方便显示)
img_aug_np = img_aug.squeeze().numpy() # 去掉通道维度,变成[28,28]
plt.subplot(1, 6, i+2)
plt.imshow(img_aug_np, cmap="gray")
plt.title(f"增强{i+1}")
plt.axis("off")
plt.tight_layout()
plt.show()
第三步:批量数据集增强(和 CNN 训练结合)
实际训练时,我们需要对整个数据集(比如 MNIST、CIFAR10)做增强,这里以 MNIST 为例,实现 "加载数据集 + 批量增强":
python
# 1. 导入库
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 2. 定义训练集的增强规则(测试集不增强!)
# 测试集只做ToTensor,避免数据泄露
train_transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomAffine(0, translate=(0.1, 0.1)),
transforms.ToTensor()
])
test_transform = transforms.Compose([
transforms.ToTensor() # 测试集只转格式,不增强
])
# 3. 加载MNIST数据集(自动下载,应用增强)
train_dataset = datasets.MNIST(
root="mnist_data", # 数据保存到本地的文件夹
train=True, # 加载训练集
download=True, # 第一次运行自动下载
transform=train_transform # 训练集用增强
)
test_dataset = datasets.MNIST(
root="mnist_data",
train=False, # 加载测试集
download=True,
transform=test_transform # 测试集不用增强
)
# 4. 批量加载数据(训练时每次取32张图)
train_loader = DataLoader(
train_dataset,
batch_size=32, # 每批次32张图
shuffle=True # 打乱数据顺序(避免模型学顺序)
)
test_loader = DataLoader(
test_dataset,
batch_size=32,
shuffle=False # 测试集不用打乱
)
# 5. 验证:打印增强后的数据形状
# 取一个批次的图片和标签
images, labels = next(iter(train_loader))
print("一个批次的图片形状:", images.shape) # 输出:torch.Size([32, 1, 28, 28])
print("一个批次的标签形状:", labels.shape) # 输出:torch.Size([32])
print("第一张图的像素范围:", images[0].min(), "~", images[0].max()) # 0~1(ToTensor后的结果)关键注意事项:
- 测试集不能增强:增强是为了让训练集更丰富,测试集要保持 "真实",才能准确评估模型效果;
- 增强顺序 :PIL 图片相关的增强(旋转、平移、翻转)要放在
ToTensor()前面,因为ToTensor()之后是 Tensor 格式,不能再用这些操作; - batch_size:批次大小(比如 32)表示每次给模型喂 32 张增强后的图,新手先固定 32/64 即可。
常用增强操作补充(按需选用)
| 增强操作 | 作用(大白话) | 适用场景 |
|---|---|---|
ColorJitter(brightness=0.2) |
调整亮度(±20%) | 彩色图片(CIFAR10) |
RandomVerticalFlip(p=0.5) |
随机垂直翻转 | 对称图片(比如风景) |
Normalize(mean=[0.1307], std=[0.3081]) |
标准化(MNIST 专用) | 所有图片(让数据分布更稳定) |
比如给 MNIST 加标准化:
python
train_transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307], std=[0.3081]) # MNIST的均值和标准差
])运行代码的小技巧
- 如果本地没有图片,直接用代码里「方式 2」生成模拟数字图,不用额外准备文件;
- 运行后会弹出一个窗口,显示原图和 5 张增强后的图,能直观看到数字的变化;
- 批量加载数据的代码可以直接和之前讲的 CNN 训练代码拼接,形成完整的训练流程。
知识点 2:卷积神经网络(CNN)定义的写法
🔍 大白话解释
CNN 就像 "找特征的流水线",分 3 步走:
- 卷积层:用 "小放大镜"(卷积核)在图片上滑,每次看一小块,找基础特征(比如数字的边缘、线条);
- 池化层:把找到的特征缩小(比如 28×28 缩成 14×14),简化信息(比如看远处的人,不用看清每根头发,只要看清轮廓);
- 全连接层:把所有找到的特征汇总,投票判断 "这张图是数字几"。
📌 核心组成(新手必记)
| 层类型 | 作用(大白话) | 对应 PyTorch 代码 |
|---|---|---|
| 卷积层(Conv2d) | 找基础特征(边缘、线条) | nn.Conv2d() |
| 池化层(MaxPool2d) | 缩小特征,减少计算量 | nn.MaxPool2d(2) |
| 全连接层(Linear) | 汇总特征,输出结果 | nn.Linear() |
| 激活函数(ReLU) | 让模型学 "非线性特征"(比如弯曲的线条) | nn.ReLU() |
💻 代码实现(定义简单 CNN)
python
# 第一步:导入CNN核心库
import torch.nn as nn
import torch.nn.functional as F
# 第二步:定义CNN类(必须继承nn.Module)
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一层:卷积层(找基础特征)
self.conv1 = nn.Conv2d(
in_channels=1, # 输入通道数:MNIST是黑白图,所以1
out_channels=16, # 输出通道数(特征图数量):16个不同的"放大镜"
kernel_size=3, # 卷积核大小:3×3的小放大镜
padding=1 # 填充:避免图片缩小(新手先记padding=1)
)
# 池化层:缩小特征图(2×2池化,把尺寸减半)
self.pool = nn.MaxPool2d(2, 2)
# 第二层:卷积层(找更复杂的特征,比如轮廓)
self.conv2 = nn.Conv2d(
in_channels=16, # 输入是上一层的16个特征图
out_channels=32, # 输出32个特征图
kernel_size=3,
padding=1
)
# 全连接层1:把特征图展平成一维(28→14→7,所以7×7×32)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
# 全连接层2:输出10类(0-9数字)
self.fc2 = nn.Linear(128, 10)
# 第三步:定义前向传播(数据走流水线的顺序)
def forward(self, x):
# 第一步:卷积1 → 激活 → 池化
x = self.pool(F.relu(self.conv1(x))) # 输出形状:16×14×14
# 第二步:卷积2 → 激活 → 池化
x = self.pool(F.relu(self.conv2(x))) # 输出形状:32×7×7
# 第三步:展平特征图(变成一维)
x = x.view(-1, 32 * 7 * 7) # 形状:32×7×7 → 1568
# 第四步:全连接1 → 激活
x = F.relu(self.fc1(x))
# 第五步:全连接2 → 输出结果
x = self.fc2(x)
return x
# 验证:创建CNN实例,打印结构
model = SimpleCNN()
print("CNN结构:\n", model)🎯 代码解释
__init__:定义流水线的 "设备"(卷积层、池化层等);forward:定义数据的 "流动顺序"(先过卷积 1,再过池化,依此类推);- 尺寸变化:28×28 → 卷积 1(28×28)→ 池化(14×14)→ 卷积 2(14×14)→ 池化(7×7)→ 展平(7×7×32=1568)→ 全连接层。

知识点 3:Batch 归一化(Batch Normalization)
🔍 大白话解释
比如你做蛋糕:每次用的面粉湿度不一样(数据分布不一样),烤出来的蛋糕口感忽好忽坏。Batch 归一化就是 "把面粉的湿度调整到统一标准",让模型训练时更稳定、学得更快。
📌 为什么需要?
训练时,每个批次(batch)的图片数据分布可能差很多(比如一批图片像素值 0-50,另一批 200-255),模型要不停 "适应" 不同分布,训练慢还容易出错;归一化后,每个批次的数据分布差不多,模型学起来更顺。
🎯 生活例子
比如全班同学的考试分数:
- 第一批:分数集中在 30-50 分(偏科);
- 第二批:分数集中在 80-90 分(学霸);
- 归一化后:两批分数都调整到 "平均分 0,方差 1",老师(模型)批改时不用反复调整评分标准。
💻 代码实现(加到 CNN 里)
只需要在卷积层后、激活函数前 加nn.BatchNorm2d(针对二维特征图的归一化):
python
class CNNWithBN(nn.Module):
def __init__(self):
super(CNNWithBN, self).__init__()
# 卷积1 + Batch归一化
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16) # 参数:输入通道数(和卷积1的输出通道一致)
self.pool = nn.MaxPool2d(2, 2)
# 卷积2 + Batch归一化
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32) # 和卷积2的输出通道一致
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 卷积1 → Batch归一化 → 激活 → 池化(顺序不能乱)
x = self.pool(F.relu(self.bn1(self.conv1(x))))
# 卷积2 → Batch归一化 → 激活 → 池化
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 验证:创建带BN的CNN
model_bn = CNNWithBN()
print("带Batch归一化的CNN:\n", model_bn)✨ 关键提醒
BatchNorm 的参数是「卷积层的输出通道数」(比如 conv1 输出 16 通道,bn1 就填 16),位置必须在卷积层后、激活函数前,这样归一化效果最好。
知识点 4:特征图(Feature Map)
🔍 大白话解释
特征图就是卷积层的输出结果,是电脑 "看" 图片后提取的 "特征"。比如:
- 原始图:手写数字 "5"(28×28 像素);
- 卷积 1 输出的特征图:5 的边缘线条(16 张,每张对应一个 "放大镜" 找的特征);
- 卷积 2 输出的特征图:5 的轮廓(32 张,更复杂的特征)。
📌 核心规则
只有卷积层(Conv2d) 的输出才叫特征图!池化层是对特征图 "缩小",全连接层是把特征图 "展平成一维",都不算特征图。
💻 代码实现(打印特征图形状)
用上面的 CNN,输入一张图片,看卷积层的输出(特征图):
python
# 第一步:创建一张模拟的MNIST图片(1通道,28×28)
fake_img = torch.randn(1, 1, 28, 28) # 形状:[批次数, 通道数, 高度, 宽度]
# 第二步:用CNN提取特征图
model = CNNWithBN()
# 提取conv1的输出(特征图1)
conv1_out = model.conv1(fake_img)
bn1_out = model.bn1(conv1_out) # Batch归一化后的特征图
# 提取conv2的输出(特征图2)
pool1_out = model.pool(F.relu(bn1_out))
conv2_out = model.conv2(pool1_out)
# 第三步:打印特征图形状
print("原始图片形状:", fake_img.shape) # torch.Size([1, 1, 28, 28])
print("conv1输出的特征图形状:", conv1_out.shape) # torch.Size([1, 16, 28, 28])
print("conv2输出的特征图形状:", conv2_out.shape) # torch.Size([1, 32, 14, 14])🎯 结果解释
conv1_out.shape = [1,16,28,28]:1 个批次、16 张特征图、每张 28×28;conv2_out.shape = [1,32,14,14]:1 个批次、32 张特征图、每张 14×14(因为经过了一次池化,尺寸减半);- 这些就是特征图,是 CNN "看懂" 图片的关键。
知识点 5:调度器(Scheduler)
🔍 大白话解释
调度器就像 "学习节奏调节器":
- 刚开始学新知识,要快一点(学习率高),先掌握大概;
- 学到后期,要慢一点(学习率低),精细打磨,避免学错。调度器能自动修改 "基础学习率",让模型训练效果更好。
📌 为什么需要?
如果用固定学习率(比如一直 0.01),后期模型会 "学来学去精度不涨"(震荡);调度器按规则降低学习率,比如每训练 5 轮,学习率减半,让模型慢慢收敛到最优。
🎯 生活例子
比如背单词:
- 第 1-5 天:每天背 100 个(高学习率),先混个脸熟;
- 第 6-10 天:每天背 50 个(学习率减半),精细记忆;
- 第 11 天后:每天背 20 个(学习率再减半),巩固记忆。
💻 代码实现(结合优化器使用)
调度器必须和优化器(比如 SGD、Adam)配合,以 PyTorch 的StepLR(每 N 轮学习率乘 gamma)为例:
python
# 第一步:定义优化器(基础学习率0.01)
optimizer = torch.optim.SGD(model_bn.parameters(), lr=0.01, momentum=0.9)
# 第二步:定义调度器(每5轮,学习率×0.1)
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, # 绑定优化器
step_size=5, # 每5轮调整一次
gamma=0.1 # 调整系数:学习率 = 原学习率 × 0.1
)
# 第三步:模拟训练过程(打印学习率变化)
for epoch in range(10): # 训练10轮
# 假设这里是训练代码(省略)
print(f"第{epoch+1}轮,当前学习率:{optimizer.param_groups[0]['lr']}")
# 每轮训练完,更新调度器
scheduler.step()🎯 输出结果(看学习率变化)
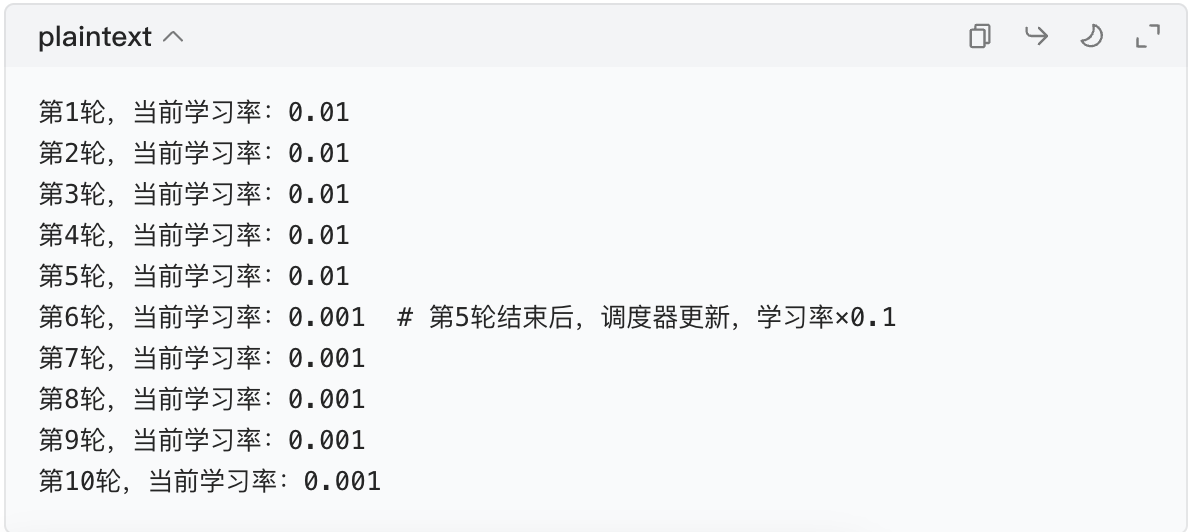
✨ 关键提醒
调度器的step()必须在每轮训练结束后调用,否则不会生效。
最终整合:包含所有知识点的完整代码
把上面的知识点串起来,写一个能运行的极简版 CNN 训练代码(注释超详细):
python
# 导入所有需要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# ====================== 1. 数据增强 ======================
transform_train = transforms.Compose([
transforms.RandomRotation(10), # 随机旋转
transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移
transforms.ToTensor(), # 转Tensor
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(root="data", train=True, download=True, transform=transform_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 批次大小32
# ====================== 2. 定义带BatchNorm的CNN ======================
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积1 + BN
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.pool = nn.MaxPool2d(2, 2)
# 卷积2 + BN
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
# 全连接层
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 提取特征图(conv1输出)
x = self.bn1(self.conv1(x)) # conv1输出=特征图1
x = self.pool(F.relu(x))
# 提取特征图(conv2输出)
x = self.bn2(self.conv2(x)) # conv2输出=特征图2
x = self.pool(F.relu(x))
# 展平+全连接
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# ====================== 3. 优化器+调度器 ======================
model = SimpleCNN()
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# ====================== 4. 训练(跑2轮看看效果) ======================
model.train() # 训练模式
for epoch in range(2):
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 每100批次打印一次
if i % 100 == 99:
print(f'第{epoch+1}轮, 第{i+1}批次, 损失值: {running_loss/100:.3f}')
running_loss = 0.0
# 每轮结束更新调度器
scheduler.step()
print(f'第{epoch+1}轮结束,当前学习率:{optimizer.param_groups[0]["lr"]}')
print("训练完成!")总结(零基础必记)
| 知识点 | 核心记忆点(大白话) |
|---|---|
| 数据增强 | 给图片 "变样子",让模型认得多 |
| CNN 定义 | 卷积(找特征)→ 池化(缩小)→ 全连接(判结果) |
| Batch 归一化 | 调整批次数据分布,训练更稳更快 |
| 特征图 | 卷积层的输出,是电脑 "看" 到的特征 |
| 调度器 | 自动调学习率,前期快学,后期精学 |
你可以把上面的代码复制到 Python 环境(比如 PyCharm、Colab)里运行,改改参数(比如学习率、批次大小),看看效果变化,慢慢就理解了。
作业:尝试手动修改下不同的调度器和 CNN 的结构,观察训练的差异。
Mac OS 下 CNN + 调度器对比实验小项目(详细步骤 + 代码)
项目目标
通过修改 CNN 结构 和更换调度器,对比不同设置下的训练效果(损失、准确率),理解结构 / 调度器对模型训练的影响。
适配说明
Mac OS(包括 M1/M2/M3 芯片)完全兼容以下代码,会自动适配 CPU/MPS(苹果芯片 GPU 加速),无需额外配置。
第一步:Mac OS 环境准备(关键!)
1.1 安装依赖
打开「终端」,执行以下命令(M 系列 / Intel 通用):

安装PyTorch(适配Mac OS,包含MPS加速) pip3 install torch torchvision matplotlib numpy # 验证安装(可选) python3 -c "import torch; print('PyTorch版本:', torch.version); print('MPS可用:', torch.backends.mps.is_available())"
- 若输出
MPS可用: True(M 系列芯片),代码会自动用 GPU 加速; - 若输出
False(Intel 芯片),自动用 CPU 训练(MNIST 数据集小,CPU 也很快)。
1.2 项目文件结构
无需创建复杂文件夹,只需在「桌面」新建一个文件夹(比如CNN_Experiment),后续所有代码都保存在这个文件夹里的cnn_scheduler_exp.py文件中。
第二步:核心代码实现(可直接复制运行)
代码分为 6 个模块:数据加载 、定义不同 CNN 结构 、定义训练 / 测试函数 、实验配置 、运行实验 、结果可视化。
所有代码注释超详细,Mac 下直接运行即可。
python
# ====================== 模块1:导入所有依赖 ======================
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import time
# ====================== 模块2:适配Mac OS设备(自动选CPU/MPS) ======================
# 优先用MPS(苹果芯片GPU),没有则用CPU
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"当前使用设备:{device}")
# ====================== 模块3:数据加载(带数据增强) ======================
def load_data():
"""加载MNIST数据集,带数据增强"""
# 训练集增强规则(测试集不增强)
train_transform = transforms.Compose([
transforms.RandomRotation(10), # 随机旋转±10度
transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移10%
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307], std=[0.3081]) # MNIST标准化(更稳定)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.1307], std=[0.3081])
])
# 加载数据集(自动下载到项目文件夹)
train_dataset = datasets.MNIST(
root="./mnist_data", # 数据保存在项目文件夹下
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.MNIST(
root="./mnist_data",
train=False,
download=True,
transform=test_transform
)
# 批量加载数据(Mac下batch_size设32/64都可以)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
return train_loader, test_loader
# ====================== 模块4:定义不同的CNN结构(核心修改点1) ======================
# 结构1:基础版CNN(无BN,2层卷积)
class BasicCNN(nn.Module):
def __init__(self):
super(BasicCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 3, padding=1) # 1→16通道
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1) # 16→32通道
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 无BN
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 结构2:带BatchNorm的CNN(基础版+BN)
class BNCNN(nn.Module):
def __init__(self):
super(BNCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16) # 卷积后加BN
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32) # 卷积后加BN
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x)))) # 卷积→BN→激活→池化
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = x.view(-1, 32 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 结构3:更深的CNN(3层卷积+BN)
class DeepCNN(nn.Module):
def __init__(self):
super(DeepCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 64, 3, padding=1) # 新增卷积层
self.bn3 = nn.BatchNorm2d(64)
self.fc1 = nn.Linear(64 * 3 * 3, 128) # 尺寸变化:28→14→7→3
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x)))) # 28→14
x = self.pool(F.relu(self.bn2(self.conv2(x)))) # 14→7
x = self.pool(F.relu(self.bn3(self.conv3(x)))) # 7→3(新增池化)
x = x.view(-1, 64 * 3 * 3)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# ====================== 模块5:训练/测试函数(通用) ======================
def train_model(model, train_loader, test_loader, optimizer, scheduler, num_epochs=10):
"""
通用训练函数:适配任意CNN模型和调度器
返回:训练损失、训练准确率、测试准确率(用于对比)
"""
criterion = nn.CrossEntropyLoss() # 损失函数
model.to(device) # 模型移到Mac的MPS/CPU
train_losses = [] # 记录每轮训练损失
train_accs = [] # 记录每轮训练准确率
test_accs = [] # 记录每轮测试准确率
print(f"\n开始训练 {model.__class__.__name__} + {scheduler.__class__.__name__}")
start_time = time.time()
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
# 数据移到设备(MPS/CPU)
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计损失和准确率
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每轮结束更新调度器
scheduler.step()
# 计算本轮训练指标
epoch_loss = running_loss / len(train_loader)
epoch_train_acc = 100 * correct / total
train_losses.append(epoch_loss)
train_accs.append(epoch_train_acc)
# 测试阶段(不更新模型)
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad(): # 关闭梯度,加速测试
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
epoch_test_acc = 100 * test_correct / test_total
test_accs.append(epoch_test_acc)
# 打印本轮结果
lr = optimizer.param_groups[0]['lr'] # 当前学习率
print(f"第{epoch+1}轮 | 损失: {epoch_loss:.4f} | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}% | 学习率: {lr:.6f}")
# 训练结束
end_time = time.time()
print(f"训练完成!耗时: {end_time - start_time:.2f}秒")
return train_losses, train_accs, test_accs
# ====================== 模块6:实验配置与运行(核心修改点2) ======================
if __name__ == "__main__":
# 步骤1:加载数据
train_loader, test_loader = load_data()
# 步骤2:定义实验组合(CNN结构 + 调度器)
experiments = []
num_epochs = 10 # 训练10轮(Mac下约5-10分钟)
# 实验1:基础CNN + StepLR(基础对比组)
model1 = BasicCNN()
optimizer1 = torch.optim.SGD(model1.parameters(), lr=0.01, momentum=0.9)
scheduler1 = torch.optim.lr_scheduler.StepLR(optimizer1, step_size=5, gamma=0.1)
experiments.append(("基础CNN+StepLR", model1, optimizer1, scheduler1))
# 实验2:基础CNN + ReduceLROnPlateau(自适应调度器)
model2 = BasicCNN()
optimizer2 = torch.optim.SGD(model2.parameters(), lr=0.01, momentum=0.9)
scheduler2 = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer2, mode='max', factor=0.1, patience=2, verbose=True)
# 注意:ReduceLROnPlateau需要传入测试准确率,训练时要特殊处理
# 先标记,后续单独训练
# 实验3:BNCNN + StepLR(对比BN的影响)
model3 = BNCNN()
optimizer3 = torch.optim.SGD(model3.parameters(), lr=0.01, momentum=0.9)
scheduler3 = torch.optim.lr_scheduler.StepLR(optimizer3, step_size=5, gamma=0.1)
experiments.append(("BNCNN+StepLR", model3, optimizer3, scheduler3))
# 实验4:DeepCNN + CosineAnnealingLR(更深结构+余弦调度器)
model4 = DeepCNN()
optimizer4 = torch.optim.SGD(model4.parameters(), lr=0.01, momentum=0.9)
scheduler4 = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer4, T_max=num_epochs)
experiments.append(("DeepCNN+CosineAnnealingLR", model4, optimizer4, scheduler4))
# 步骤3:运行实验(先运行非ReduceLROnPlateau的实验)
results = {}
# 运行实验1、3、4
for exp_name, model, optimizer, scheduler in experiments:
if "ReduceLROnPlateau" not in exp_name:
train_losses, train_accs, test_accs = train_model(model, train_loader, test_loader, optimizer, scheduler, num_epochs)
results[exp_name] = (train_losses, train_accs, test_accs)
# 单独运行实验2(ReduceLROnPlateau需要传入测试准确率)
print("\n========== 运行实验2:基础CNN+ReduceLROnPlateau ==========")
model2 = BasicCNN()
optimizer2 = torch.optim.SGD(model2.parameters(), lr=0.01, momentum=0.9)
scheduler2 = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer2, mode='max', factor=0.1, patience=2, verbose=True)
criterion = nn.CrossEntropyLoss()
model2.to(device)
train_losses2 = []
train_accs2 = []
test_accs2 = []
start_time = time.time()
for epoch in range(num_epochs):
# 训练阶段
model2.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
outputs = model2(images)
loss = criterion(outputs, labels)
optimizer2.zero_grad()
loss.backward()
optimizer2.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算训练指标
epoch_loss = running_loss / len(train_loader)
epoch_train_acc = 100 * correct / total
train_losses2.append(epoch_loss)
train_accs2.append(epoch_train_acc)
# 测试阶段
model2.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model2(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
epoch_test_acc = 100 * test_correct / test_total
test_accs2.append(epoch_test_acc)
# 更新调度器(传入测试准确率)
scheduler2.step(epoch_test_acc)
# 打印结果
lr = optimizer2.param_groups[0]['lr']
print(f"第{epoch+1}轮 | 损失: {epoch_loss:.4f} | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}% | 学习率: {lr:.6f}")
end_time = time.time()
print(f"实验2训练完成!耗时: {end_time - start_time:.2f}秒")
results["基础CNN+ReduceLROnPlateau"] = (train_losses2, train_accs2, test_accs2)
# 步骤4:结果可视化(Mac下自动弹出图表)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 解决Mac中文显示问题
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 子图1:训练损失对比
ax1.set_title("训练损失变化", fontsize=14)
ax1.set_xlabel("训练轮数")
ax1.set_ylabel("损失值")
for exp_name, (losses, _, _) in results.items():
ax1.plot(range(1, num_epochs+1), losses, label=exp_name, marker='o')
ax1.legend()
ax1.grid(True)
# 子图2:测试准确率对比
ax2.set_title("测试准确率变化", fontsize=14)
ax2.set_xlabel("训练轮数")
ax2.set_ylabel("准确率(%)")
for exp_name, (_, _, test_accs) in results.items():
ax2.plot(range(1, num_epochs+1), test_accs, label=exp_name, marker='s')
ax2.legend()
ax2.grid(True)
# 保存图片到项目文件夹(Mac桌面的CNN_Experiment里)
plt.tight_layout()
plt.savefig("./cnn_scheduler_results.png", dpi=150)
plt.show()
# 步骤5:打印最终结果汇总
print("\n========== 实验结果汇总 ==========")
for exp_name, (_, _, test_accs) in results.items():
final_acc = test_accs[-1]
print(f"{exp_name} | 最终测试准确率: {final_acc:.2f}%")第三步:实验操作步骤(Mac 下执行)
3.1 保存代码
- 打开「文本编辑」(Mac 自带),粘贴上述所有代码;
- 点击「文件」→「保存」,选择桌面的
CNN_Experiment文件夹,文件名填cnn_scheduler_exp.py,格式选「纯文本」。
3.2 运行代码
打开「终端」,切换到项目文件夹:

cd ~/Desktop/CNN_Experiment
运行代码:

python3 cnn_scheduler_exp.py
等待运行:
- 第一次运行会自动下载 MNIST 数据集(约 10MB);
- 训练 10 轮,Mac M 系列约 5 分钟,Intel 约 10 分钟;
- 终端会实时打印每轮的损失、准确率、学习率。
3.3 查看结果
- 运行结束后,项目文件夹会生成
cnn_scheduler_results.png(损失 + 准确率对比图); - 终端会打印最终准确率汇总。
第四步:手动修改对比(核心!)
4.1 修改 CNN 结构(代码模块 4)
| 修改点 | 操作方式 |
|---|---|
| 增加卷积层 | 参考DeepCNN,新增conv3+bn3,注意调整全连接层的输入尺寸(比如 7×7→3×3); |
| 调整卷积核数量 | 把conv1的out_channels从 16 改成 32,观察参数增多对训练的影响; |
| 移除 BatchNorm | 把BNCNN里的bn1/bn2注释掉,对比有无 BN 的训练稳定性; |
| 调整池化层 | 把MaxPool2d(2)改成MaxPool2d(3),观察特征图尺寸变化; |
4.2 修改调度器(代码模块 6)
| 调度器类型 | 核心参数修改 |
|---|---|
| StepLR | 修改step_size(比如从 5 改成 3)、gamma(比如从 0.1 改成 0.5),观察学习率下降速度; |
| ReduceLROnPlateau | 修改patience(比如从 2 改成 1)、factor(比如从 0.1 改成 0.2),观察自适应调整时机; |
| CosineAnnealingLR | 修改T_max(比如从 10 改成 5),观察余弦学习率的周期变化; |
| 新增调度器(ExponentialLR) | 加一行:scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9); |
4.3 修改优化器(可选)
- 把
SGD改成Adam:optimizer = torch.optim.Adam(model.parameters(), lr=0.001); - 调整基础学习率:把
lr=0.01改成0.001/0.1,观察学习率对训练的影响。
第五步:预期结果与差异分析(关键理解)
5.1 CNN 结构影响
| 结构类型 | 训练特点 |
|---|---|
| 基础 CNN | 训练损失下降慢,测试准确率可能震荡(无 BN,数据分布不稳定); |
| 带 BN 的 CNN | 损失下降更快,准确率更稳定(BN 调整批次分布,训练更顺); |
| 更深的 CNN | 训练准确率更高,但训练时间稍长(更多参数,能提取更复杂特征); |
5.2 调度器影响
| 调度器类型 | 训练特点 |
|---|---|
| StepLR | 学习率按固定轮数下降,适合规律训练,但可能早降 / 晚降; |
| ReduceLROnPlateau | 自适应调整(准确率不涨就降学习率),测试准确率更高,更灵活; |
| CosineAnnealingLR | 学习率余弦式下降,后期学习率缓慢降低,适合精细收敛,最终准确率略高; |
5.3 Mac 下的小技巧
- 若训练太慢:把
batch_size从 32 改成 64,减少迭代次数; - 若想快速验证:把
num_epochs从 10 改成 3,先看趋势; - 若 MPS 报错:把
device = torch.device("mps")改成device = torch.device("cpu"),用 CPU 训练。
第六步:拓展尝试(可选)
- 增加数据增强操作:在
train_transform里加transforms.ColorJitter(虽然 MNIST 是黑白,但可模拟亮度变化); - 更换数据集:把 MNIST 改成 CIFAR10(彩色图),只需修改
datasets.MNIST为datasets.CIFAR10,调整输入通道数(1→3); - 增加正则化:在全连接层后加
nn.Dropout(0.5),观察过拟合是否缓解。