目录
1.LeNet-5
(1)介绍
-
LeNet-5示例
-
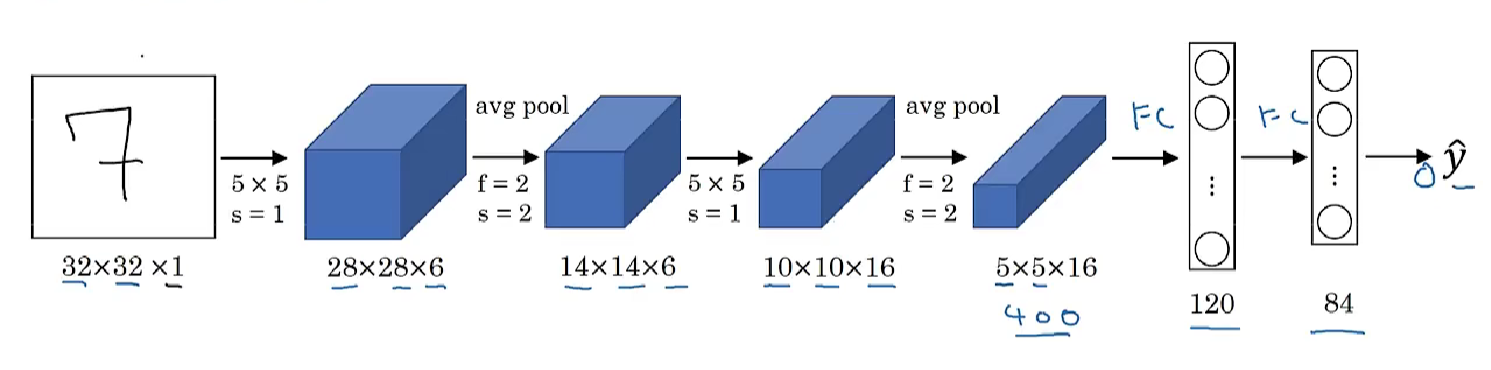
上图是LeNet-5的网络结构,假设有一张32×32×1的图片(输入),LeNet-5可以识别图中的手写数字。
-
使用6个5×5的过滤器,步幅为1,padding为0,输出结果为28×28×6,图像尺寸从32×32缩小到28×28。然后进行池化(pooling)操作(当时流行平均池化),过滤器的宽度为2,步幅为2,图像的宽高都缩小为一半,输出是一个14×14×6的图像,如果严格按照比例绘制,新图像的尺寸应该刚好是原图像的一半。
-
接下来是卷积层,用一组16个5×5的过滤器。当时使用valid卷积,所以每进行一次卷积,图像的高度和宽度都会缩小,所以这个图像从14到14缩小到了10×10。然后又是池化层,高度和宽度再缩小一半,输出一个5×5×16的图像。最后平铺成400个单元。
-
下一层是全连接层,在全连接层中,有400个节点,每个节点有120个神经元,这里已经有了一个全连接层。但有时还会从这400个节点中抽取一部分节点构建另一个全连接层,有2个全连接层。
-
最后一步就是利用这84个特征得到最后的输出,我们还可以在这里再加一个节点用来预测y帽的值,y帽有10个可能的值(对应识别0-9这10个数字)。现在则使用softmax函数输出十种分类结果,而在当时,LeNet-5网络在输出层使用了另外一种,现在已经很少用到的分类器。
(2)特点
- 处理的是灰度图像
- 参数约6万个
- 那时还流行平均池化
- 使用sigmoid和tanh函数
2.AlexNet
(1)介绍
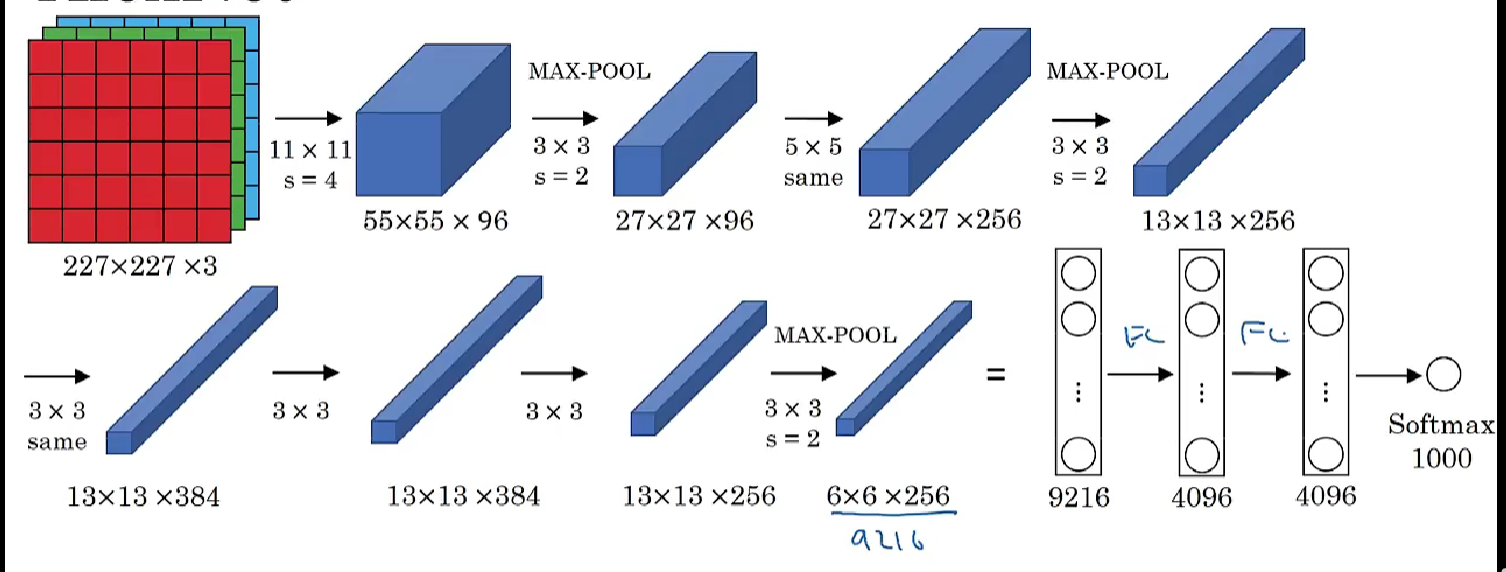
- 首先用一张227×227×3的图片作为输入(实际上原文中使用的图像是224×224×3,但是227×227这个尺寸更好一些)。
- 第一层使用96个11×11的过滤器,步幅为4,因此尺寸缩小到55×55。然后用一个3×3的过滤器构建最大池化层,f = 3,步幅为2,卷积层尺寸缩小为27×27×96。
- 接着再执行一个5×5的卷积,padding之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。
- 再做一次same卷积,相同的padding,得到的结果是13×13×384,384个过滤器。
- 再做一次same卷积。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。
- 展开为9216个单元,然后是一些全连接层。最后使用softmax函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
(2)特点
- 处理RGB图像
- 参数约6000万,比LeNet-5大很多
- 使用ReLu激活函数
3.VGGNet(VGG-16)
(1)介绍
- VGG-16的卷积层和全连接层一共16个,这是一种结构简单的网络(same卷积+减半池化)
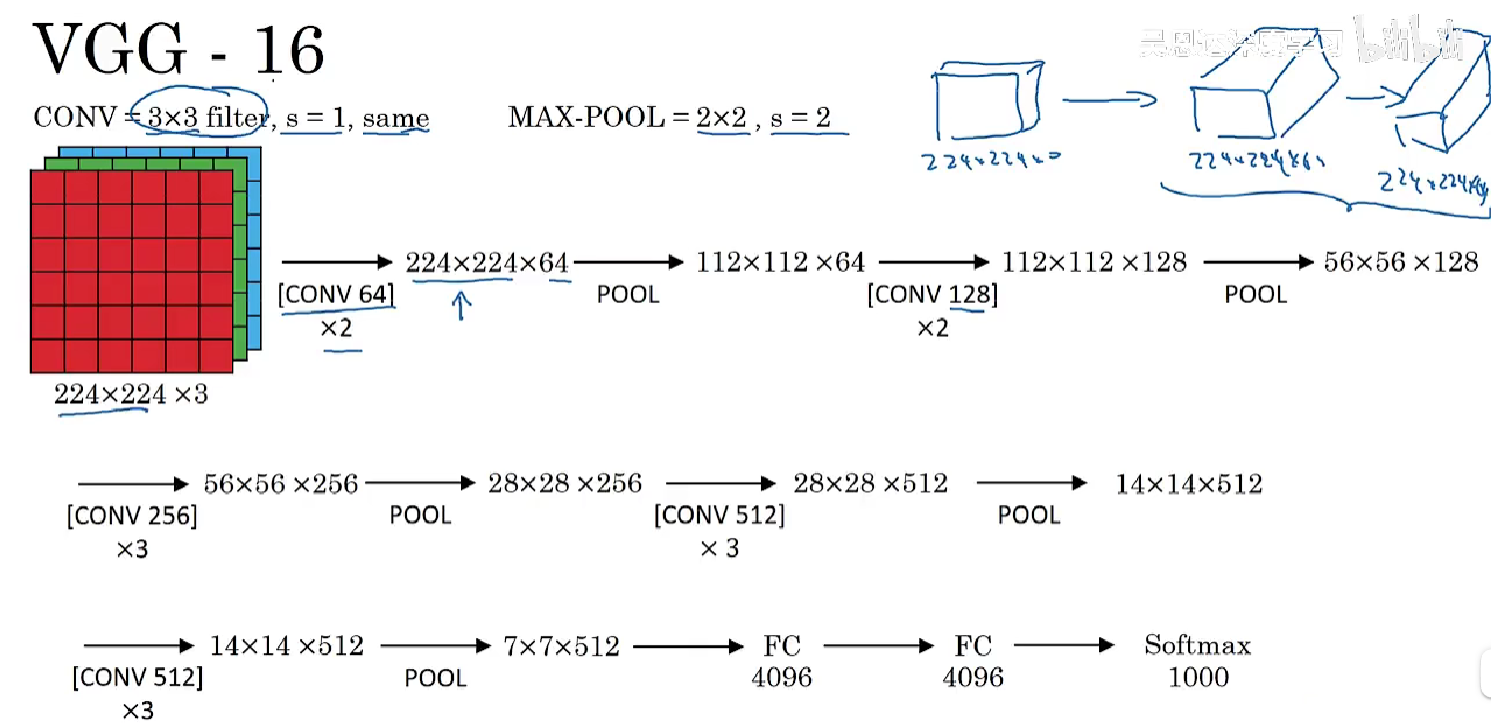
- 输入图像为224×224×3,在最开始的两层用64个3×3的过滤器对输入图像进行卷积,输出结果是224×224×64,因为使用了same卷积,通道数量也一样。(注意这里没有画出所有的卷积层)进行第一个卷积之后得到224×224×64的特征图,接着还有一层224×224×64,得到这样2个厚度为64的卷积层,意味着我们用64个过滤器进行了两次卷积。接下来创建一个池化层,池化层将输入图像进行压缩,从224×224×64缩小到一半,减少到112×112×64。
- 然后又是若干个卷积层,使用129个过滤器,以及一些same卷积,输出112×112×128。然后进行池化,结果是(56×56×128)。
- 再重复以上的多次same卷积+减半池化,最终得到4096个单元,然后进行softmax激活,输出从1000个对象中识别的结果。
(2)特点
- 很大的但结构规整简单的网络,约1.38亿个参数
- same卷积
- 多个卷积层后跟一个池化层
- 每次池化宽高缩小一半,通道数翻倍
4.1×1卷积(网络中的网络)
(1)介绍
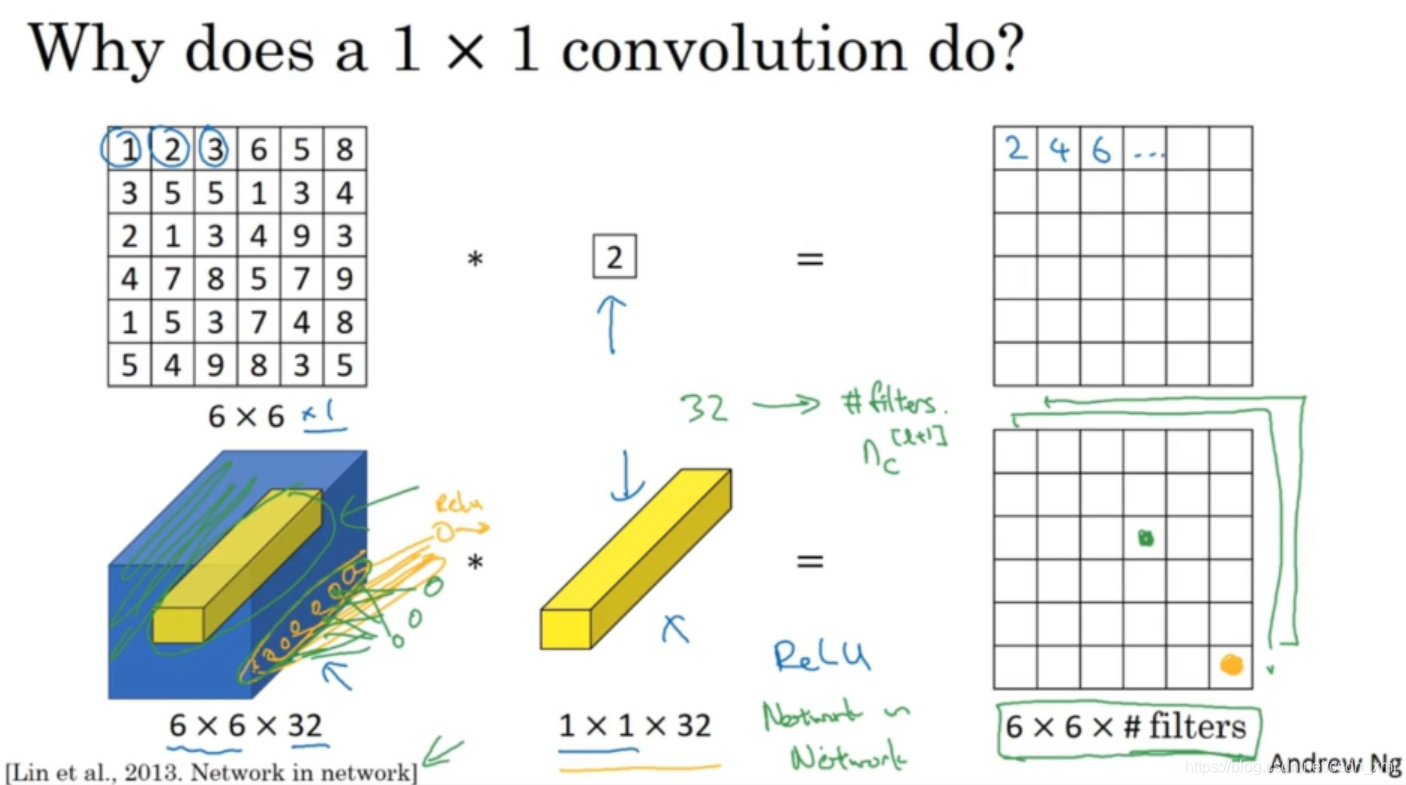
- 如上图第一行,输入一张6×6×1的图片,然后对它做卷积,过滤器大小为1×1×1,这里是数字2,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,。
- 如上图第二行,如果输入是一张6×6×32的图片,那么使用1×1过滤器进行卷积,所实现的是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,所以1×1卷积又叫Network in Network。
(2)应用
- 在保持宽高的情况下,减少通道数
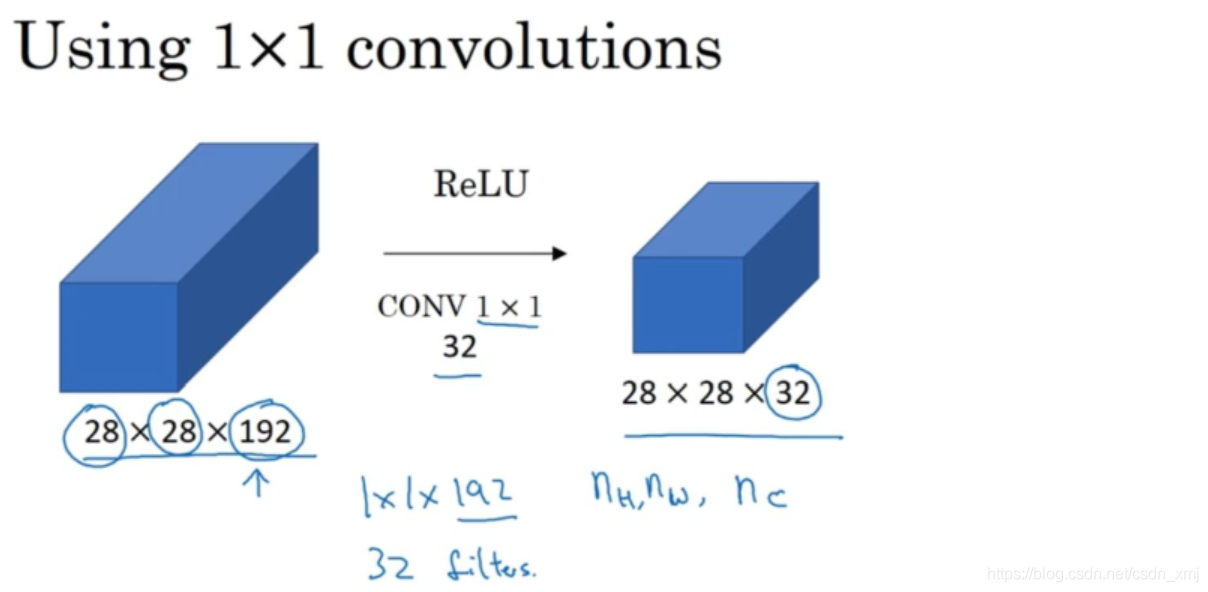
- 假设这是一个28×28×192的输入层,该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1×192的过滤器。