这个系列开始介绍多模态模型相关知识,需要一定知识基础:
Transformer结构介绍可以看:深度学习基础-5 注意力机制和Transformer
基于Transformer结构的Backbone可以看:计算机视觉Transformer-1 基础结构
基于Transformer结构的自监督方法可以看:计算机视觉Transformer-3 自监督模型
大模型理论基础可以看:大模型基础理论-BPE/DeepNorm/FlashAttention/GQA/RoPE
这篇文章介绍开始这个多模态系列需要具备的一些基础知识。
一 基础概念
1)模态:模态是指感知事物和表达信息的方式,每一种信息的来源或者形式都可以被称为一种模态,如文本、图像、音频等,它们都是表达客观事物的一种模态
2)多模态:多模态是指利用多种不同的信息模态(如文本、图像、音频、视频等)来共同表达或描述同一内容。人类在理解现实世界时,通常不会只依赖单一的感官或信息来源,而是会综合来自多个角度的信息进行整体判断。尽管计算机在单模态任务(如自然语言处理、计算机视觉等)上已取得显著进展,但要实现更接近人类的认知能力,仍需具备融合与理解多模态信息的能力。多模态技术正是为了赋予计算机这种跨模态的综合感知与理解能力而发展起来的
3)语义空间:语义空间指的是一种能够统一表示不同模态信息的共享抽象空间,在这个空间中,来自不同模态(如文本、图像、音频等)的数据被映射到具有相同语义含义的相近位置,从而实现跨模态的理解、对齐与交互。不同模态的数据在原始形式上差异巨大,如文本是离散的符号序列,图像是连续的像素矩阵,音频是时间序列的声波信号等,这些数据在原始特征空间中彼此不兼容,无法直接比较或融合。然而它们可能描述的是同一个语义概念(例如:"一只狗在草地上奔跑"可以对应一张图片、一段文字描述、甚至一段狗叫和奔跑声的音频)。因此需要一个统一的语义空间,使得不同模态的数据在该空间中能以语义一致的方式进行表示和交互。同一语义内容的不同模态表示在语义空间中应彼此靠近(例如,一张猫的图片和"这是一只猫"的句子在语义空间中的向量距离很小)。语义相近的内容(无论来自哪种模态)在该语义空间中距离较近,语义差异大的内容则距离较远
4)模态对齐:模态对齐就是将不同模态的数据映射到同一个语义空间中的过程
5)模态融合:模态融合的目的是将不同模态的输入信息进行整合,以实现多模态的特征提取,如将从图像和文本数据中提取出来的特征拼接在一起,作为下游模型的输入,通过监督训练使模型能够理解这两种信息,模态融合并不要求不同模态的语义空间进行对齐,它强调的是让模型具备能够同时接收、处理不同模态数据的能力
二 模态表示
模态表示要解决的问题是如何利用最合适的数据格式与结构来有效表达特定模态所承载的信息,使其既能保留原始语义特征,又便于后续的计算、融合与推理。不同模态因其物理特性和信息结构差异,需采用针对性的表示方法,以下分别介绍文本、视觉和声音三大基础模态的典型表示方式。
2.1 文本模态表示
文本是以符号序列形式存在的离散信息,其表示方法经历了从浅层统计到深层语义建模的演进:
1)词袋模型(Bag-of-Words, BoW):忽略词序,仅统计词汇出现频率,适用于简单分类任务,但无法捕捉语义和上下文
2)TF-IDF:在BoW基础上引入逆文档频率加权,突出关键词的重要性
3)词嵌入(Word Embedding):如 Word2Vec、GloVe,将词语映射为低维稠密向量,使语义相近的词在向量空间中距离更近
4)上下文感知表示:基于深度语言模型(如 BERT、RoBERTa、T5),通过 Transformer 架构动态生成依赖于上下文的词或句子表示,能有效捕获语法、语义及长距离依赖
5)句子/篇章级表示:可通过 CLS 向量、平均池化、注意力池化等方式从预训练模型中提取整体语义向量
现代多模态系统通常直接使用预训练语言模型(如 BERT 或其变体)作为文本编码器,输出固定维度的语义向量,用于与其他模态对齐。
2.2 视觉模态表示
视觉信息(如图像或视频帧)本质上是高维像素矩阵,其表示目标是从原始像素中提取具有判别性和语义意义的特征:
1)手工特征:早期方法依赖人工设计的特征提取器,如 SIFT、HOG、LBP 等,用于描述边缘、纹理或局部形状,但泛化能力有限
2)卷积神经网络(CNN)特征:自深度学习兴起后,CNN(如 ResNet、VGG、EfficientNet)成为主流视觉编码器。通过多层卷积和池化操作,自动学习从底层边缘到高层语义(如物体类别)的层次化特征,具体介绍可以看:深度学习基础-3 卷积神经网络
3)全局表示:取最后一层全局平均池化(GAP)后的向量作为整图语义表示
4)局部表示:保留中间层的空间特征图(feature maps),用于细粒度对齐(如词-区域对齐)
5)视觉 Transformer(如ViT):将图像划分为图像块(patches),类比文本 token,通过自注意力机制建模全局依赖关系,在大规模数据下表现优于 CNN,具体可以看:计算机视觉Transformer-1 基础结构
6)视频表示:在图像基础上引入时间维度,常用 3D CNN、Two-Stream Networks 或 TimeSformer 等架构联合建模空间与时间信息
在多模态任务中,视觉编码器通常输出一个或多个向量(全局或区域级),作为图像在语义空间中的表示。
2.3 声音模态表示
声音是随时间变化的连续信号,其表示需兼顾时域动态性与频域语义特征:
1)原始波形(Waveform):最原始的声音表示,采样率为 16kHz 或更高,但直接使用计算开销大且冗余度高。
2)声谱图(Spectrogram):通过对短时傅里叶变换(STFT)将时域信号转换为时频二维图,横轴为时间,纵轴为频率,颜色表示能量强度。
3)梅尔频谱图(Mel-spectrogram):在声谱图基础上,将频率轴按人耳感知特性(梅尔刻度)进行非线性压缩,更符合人类听觉系统。
4)滤波器组特征(Filter Bank Features, FBank):常用于语音识别,是对梅尔频谱的能量进行对数压缩后的表示。
5)MFCC(梅尔频率倒谱系数):在 FBank 基础上进一步做离散余弦变换(DCT),保留主要频谱包络信息,曾广泛用于传统语音系统。
6)深度音频表示:现代方法使用 CNN(如 WaveNet)、Transformer(如 Audio Spectrogram Transformer, AST)或自监督模型(如 wav2vec 2.0、HuBERT)从原始音频或频谱中学习上下文感知的语义嵌入。
在多模态场景中(如视频-语音-文本对齐),声音模态常被编码为固定长度的向量序列或全局嵌入,用于与文本或视觉特征进行跨模态交互。
以上三类模态表示构成了多模态学习的基础。随着预训练技术的发展,越来越多的系统倾向于使用统一的架构(如多模态 Transformer)对不同模态进行联合编码,从而在共享语义空间中实现更高效的融合与推理。
三 模态融合
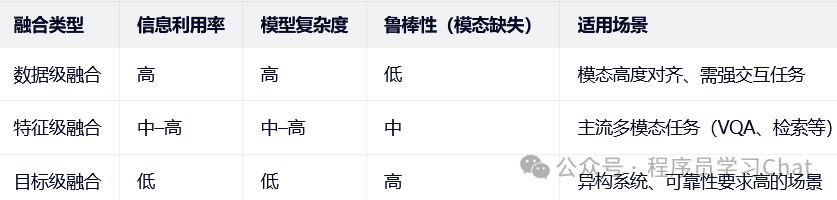
模态融合是指将来自两个或多个不同模态的信息进行整合,以提升模型在感知、理解或决策任务中的性能。由于各模态在信息表达形式、噪声特性及语义粒度上存在差异,如何有效融合成为核心挑战。根据融合发生的阶段,模态融合通常分为:数据级融合、特征级融合和目标级融合。
3.1 数据级融合
数据级融合,也称为早期融合,是指在原始模型数据输入层直接拼接或组合不同模态的数据,然后将其送入统一的模型进行处理,这种融合发生在输入端,模型从一开始就联合学习跨模态交互,能够捕捉模态间最底层的关联,理论上信息保留是最完整的,但是数据集融合要求模态在时间、空间或语义上高度对齐,而原始输入数据一般维度高、异构性强,直接融合易引入噪声或计算负担,鲁棒性较差。
3.2 特征级融合
特征级融合是最广泛采用的融合策略,也常被称为中间融合,它先对各模态分别进行编码,提取高层的语义特征,再在一个统一的特征空间中进行模态融合,能够兼顾模态特异性与跨模态交互,可灵活设计模态融合机制(如注意力、门控、张量融合等),对模态缺失具有一定容忍度(可通过掩码等方式处理)。
常用特征级融合方法:
1)简单操作:特征向量的拼接(concatenation)、逐元素相加/相乘(element-wise sum/product)
2)注意力机制:使用 cross-attention 让一个模态的特征作为 query,另一模态作为 key/value(如 ViLBERT、LXMERT)进行模态特征信息融合
3)张量融合(Tensor Fusion):通过外积构建高阶交互张量(如 TFN, Multimodal Factorized Bilinear Pooling)
4)门控机制:利用 LSTM 或 GRU 中的门控单元动态调节模态贡献(如 Gated Multimodal Units)
特征级融合发生在语义更丰富的层次,有利于捕捉深层关联,而且模块化的设计便于优化和扩展。
3.3 目标级融合
目标级融合,又称晚期融合,是指各模态独立完成各自的推理或预测,最终在决策层(如分类概率、回归结果)进行融合。目标级融合中各模态模型完全解耦,训练和推理可并行,对模态异步、数据缺失或采样率不一致的情况具有较强鲁棒性。
常用方法:
1)加权平均:对各模态输出的概率分布进行加权(权重可学习或固定)
2)投票机制:分类任务中采用多数投票、置信度加权投票等
3)元学习器(Meta-classifier):用一个轻量级模型(如 MLP)学习如何组合各模态的预测结果
4)集成学习:将不同模态视为独立"专家",通过 stacking 或 boosting 进行集成
目标级融合无法建模模态间的细粒度交互,若单模态模型的性能较差,可能会拖累整体的多模态效果,丢失了底层和中层的互补信息。
四 模态对齐
模态对齐是指在多模态系统中建立不同模态之间语义或结构上的对应关系,使得来自不同模态的信息能够在共享的语义空间中相互关联、互相解释,对齐是实现多模态信息有效融合、跨模态检索、生成和推理的前提,根据是否依赖人工标注的对齐关系,模态对齐可分为显式对齐和隐式对齐两类。
4.1 显式对齐
显式对齐依赖于人工标注的细粒度对齐关系(如词-图像区域对、语音片段-文本词对等),在训练过程中直接监督模型学习模态间的局部或全局匹配。
特点:
1)对齐信号明确、可解释性强
2)通常需要高质量的人工标注数据(成本高、规模有限)
3)能实现细粒度的跨模态理解(如定位图像中被描述的物体)
典型形式:
1)图文对齐:如 Flickr30k Entities、RefCOCO 等数据集中,每个名词短语都标注了对应的图像区域框(bounding box)
2)语音-文本对齐:通过强制对齐(forced alignment)工具(如 Gentle、Montreal Forced Aligner)将音素或词与音频时间戳对齐
3)视频-字幕对齐:动作片段与描述性句子的时间同步标注
建模方法:
1)使用对比损失(如 triplet loss)拉近匹配的跨模态单元对,推远不匹配对
2)引入注意力机制,让文本 token 关注对应的视觉区域(如 co-attention)
3)在训练目标中加入对齐正则项(如 KL 散度约束注意力分布与标注对齐矩阵一致)
优势与局限:
1)对齐精度高,适用于需要可解释性的任务(如视觉指代表达、医疗报告生成)
2)严重依赖标注数据,难以扩展到大规模无标注场景
3)标注可能存在主观偏差或噪声
4.2 隐式对齐
隐式对齐不依赖人工标注的对应关系,而是通过自监督或弱监督信号,在模型训练过程中自动发现模态间的潜在语义关联。
特点:
1)无需细粒度标注,仅需粗粒度配对数据(如"一张图 + 一段文本描述")
2)对齐过程由模型内部机制(如注意力、对比学习)隐式完成
3)更适合大规模预训练和通用多模态表示学习
核心技术:
1)对比学习(Contrastive Learning):如 CLIP、ALIGN 等模型通过最大化匹配图文对的相似度、最小化非匹配对的相似度,在共享语义空间中实现全局对齐。虽然未指定"哪个词对应哪个区域",但模型在推理时可通过注意力机制自发形成局部对齐
2)跨模态注意力(Cross-modal Attention):在 Transformer 架构中,一个模态的 token 作为 query,另一模态作为 key/value,通过自注意权重隐式建立关联(如 BLIP、ALBEF)
3)掩码建模(Masked Modeling):随机掩码部分模态输入(如遮盖图像区域或文本词),要求模型基于另一模态重建被掩码内容,从而迫使模型学习跨模态依赖关系
4)互信息最大化(Mutual Information Maximization):通过估计不同模态表示之间的互信息下界,鼓励共享语义信息的保留
优势与局限:
1)可扩展性强,适用于海量网络数据(如网页图文对)
2)模型具备更强的泛化与零样本迁移能力
3)对齐过程不可控、不可解释,可能出现"虚假相关"
4)在细粒度任务(如指代解析)上性能可能不如显式对齐方法
近年来,研究者开始探索结合两者优势的混合对齐策略,先在大规模无标注数据上通过隐式对齐进行预训练,再在小规模精细标注数据上进行显式对齐微调(如 BLIP-2 的两阶段训练)。
五 多模态理解
多模态理解是指多模态模型综合来自多个模态(如文本、图像、音频等)的信息,对内容进行语义层面的联合解析与推理,从而获得比单模态更全面、准确的认知。通过模态表示、对齐与融合技术,在共享语义空间中整合异构的信息。常结合注意力机制、图神经网络或大语言模型进行跨模态推理。
典型应用:
1)视觉问答(VQA):根据图像回答自然语言问题
2)多模态情感分析:结合语音语调、面部表情和文本判断情绪
3)图文内容审核:识别图文不一致或违规内容
4)自动驾驶感知:融合摄像头、雷达与地图信息理解道路场景
六 多模态检索
多模态检索指支持跨模态的查询与结果返回,例如用文本搜索图像,或用图像搜索相关视频/文本,一般会将不同模态映射到统一的语义向量空间,通过计算向量相似度(如余弦相似度)实现跨模态匹配,常采用对比学习进行端到端训练。
典型应用:
1)图文互搜:输入一句话,返回最相关的图片(如搜索引擎中的"以文搜图")
2)视频-文本检索:在视频库中查找描述某动作的片段
3)跨模态推荐:根据用户上传的图片推荐风格相似的商品或文章
七 多模态生成
多模态生成是指模型基于一种或多种模态输入,自动生成另一种或多种模态的输出内容,一般利用编码器-解码器架构,将输入模态编码为语义表示,再由生成式解码器(如 GAN、扩散模型、自回归 Transformer)合成目标模态的数据,多模态生成强调跨模态的语义一致性与生成质量(真实性、多样性)可控性。
典型应用:
1)文生图(Text-to-Image):如 DALL·E、Stable Diffusion,能够根据文本描述生成逼真图像
2)图生文(Image Captioning):为图像自动生成自然语言描述
3)语音合成+口型同步(Talking Head Generation):根据文本或语音模态,生成说话人脸视频模态
4)多模态对话系统:结合图像与上下文生成带图回复(如电商客服机器人)