
一、概念
少量丢包------重传就行
大量丢包------OS判定网络拥塞
一旦网络拥塞,所有主机要不发或者减少数据发送,不是直接重传,因为一旦重传,所有主机都重传,导致网络更加拥堵;所以所有主机要么不发、等等再发、减少数据发送,这时因为 TCP 构建了全网内所有主机的面对拥塞的共识,因为大家都用的是 TCP 协议;
二、如何进行拥塞控制
TCP引入慢启动机制,先发少量的数据,探探路,摸清当前的网络拥堵状态,再决定按照多大的速度传输数据;例如:先发送一个报文,如果有应答,再发两个,如果有2个应答,在发送4个报文。。。。以此类推;这个发送的报文数量是:指数增长的:2^n
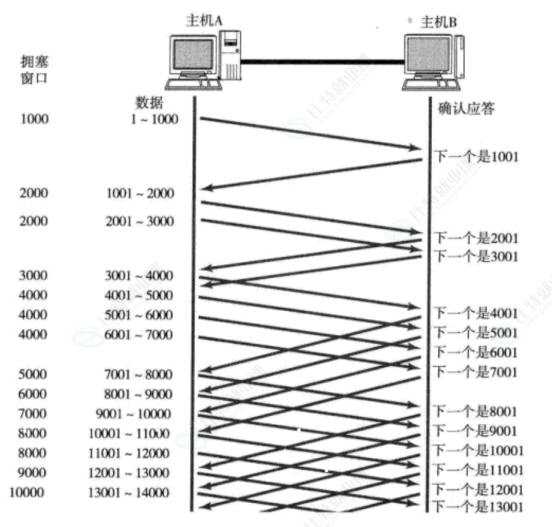
拥塞窗口在 TCP/IP 协议栈中用一个 int 来表示,拥塞窗口用来衡量网络的拥塞程度,例如:拥塞窗口 = 10,如果主机单次发送数据量大于 10 此时就会可能发生拥塞,小于 10 就可能不会发生拥塞;
发送数据要考虑:1.网络,2.接收方
所以:滑动窗口 = min(对方的接收缓冲区的剩余空间,拥塞窗口);也就是:start = ack_seq,end = start + min(对方的接收缓冲区的剩余空间的大小,拥塞窗口);
那么发送方是如何控制自己的发送量的,例如:满启动?
答:直接让 拥塞窗口 = 1 ,此时根据滑动窗口 = start = ack_sq,end = satrt + min(对方的接收缓冲区的剩余空间大小,1)这样就能控制数据的发送量;但是拥塞窗口不是一致等于1的,而是动态变化的;
为什么慢启动的是指数增长(2^n)
答:这个 2^n 是前期增长慢,后期增长快,因为一旦拥塞情况经过探测,发送不怎么拥塞,那么主要矛盾变成了,尽快恢复正常通信;慢启动是可靠性和效率之间的平衡点;
指数增长不能让这个数字一直增长,指数增长没有意义,但是持续探测网络拥塞情况有意义:
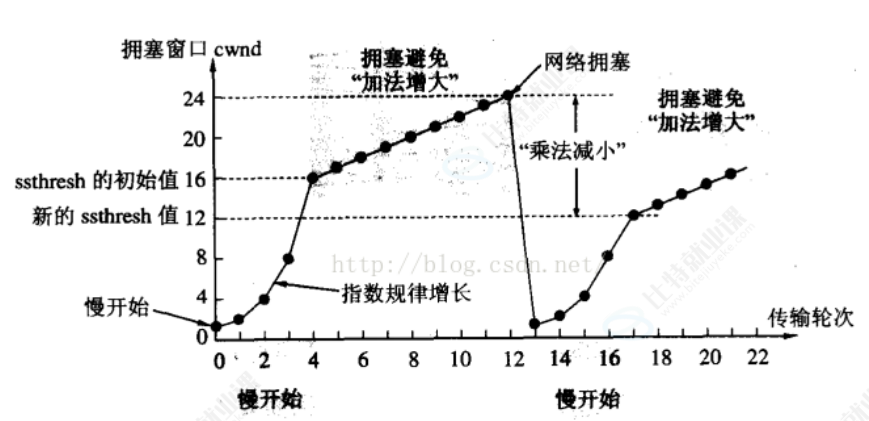
当增长到 ssthresh 值时变成线性增长,第一次 ssthresh 的值为12,在线性增长的过程中,如果发生拥堵,拥塞窗口 = 1,ssthresh 值为上一次当前值的一半;
那么立马从线性增长到指数增长的那个值就是网络拥堵的临界值,它可以作为后续拥塞窗口的参考值;如果变成了线性增长,后面一直没有拥堵,那么拥塞窗口理论上是会一直在增长的、一直在探测;因为增长的本质是在探测最真实的网络拥堵窗口值,因为网络是动态变化的;但是实际上是不会一直增长的,他不会超过本地的带宽;
三、TCP 异常情况
进程终止:客户端或者服务端挂掉,此时 OS 会自动断开连接,相当于自动释放文件描述符(引用计数);
进程重启:和进程终止一样;
机器掉网 / 网线断开(面试题):只有一方断网的情况:断网的那一方通过硬件中断 OS 会自动断开连接,此时对方没有断网的可以发送消息,但是 TCP 内置自己的保活定时器,会定期询问对方是否存在(就是发送报文没有应答),如果对方不存在就会释放掉;即使没有这个保活机制,如果一方的写端或者读端关闭,此时就会触发 SIGPIPE 信号自动杀掉进程,所以我们要忽略掉这个信号,如果断网的那一方重新连上了网,此时对方也没有断开和我的连接,此时对方发送报文,此时我就会回个 reset 要求重新三次握手;因为 TCP 内置的保活机制的保活定时器的时间太长了,这就需要我们用户层自定义保活机制(时间戳);如果一方断开网,此时会触发硬件中断,OS 会自动断开所有链接;