目录
[4.1 系统挑战的四面楚歌:数据、内存、延迟与成本](#4.1 系统挑战的四面楚歌:数据、内存、延迟与成本)
[4.2 可扩展架构:突破Transformer的物理极限](#4.2 可扩展架构:突破Transformer的物理极限)
[4.3 大规模训练:万卡集群的交响乐](#4.3 大规模训练:万卡集群的交响乐)
[4.4 推理优化:毫秒必争的响应艺术](#4.4 推理优化:毫秒必争的响应艺术)
[4.5 成本与效率:数据经济的精细化运营](#4.5 成本与效率:数据经济的精细化运营)
[4.6 计算平台:硬件与软件的协同进化](#4.6 计算平台:硬件与软件的协同进化)
[4.7 AGI系统的未来形态:从集中到分布式](#4.7 AGI系统的未来形态:从集中到分布式)
导读:如果说认知架构是AGI的"灵魂",接口是"肢体",那么系统层就是支撑这一切的"心血管与神经系统"。当模型参数量从十亿级跃升至万亿级,当上下文长度从2K扩展到百万token,传统的深度学习工程范式正在经历根本性重构。本文将深入AGI系统的技术腹地,探讨如何在算力、内存与能耗的物理极限中,为通用智能构建可扩展、高效率、可持续的数字基座。
前几章我们探讨了AGI如何"思考"与"行动",但一个关键问题始终悬而未决:这些能力如何在工程层面落地?当GPT-4在回答你的问题时,当Sora在生成视频时,当Voyager在Minecraft中探索时,支撑它们的不是魔法,而是精心设计的系统架构------从分布式训练集群的并行策略,到GPU显存中KV缓存的精密管理,再到推理引擎的毫秒级调度。
AGI系统层面临的是物理定律与计算理论的交叉战场。在这里,光速限制了数据中心内部的通信延迟,热力学第二定律制约着芯片的功耗密度,而内存墙(Memory Wall)成为了比模型架构更难逾越的屏障。
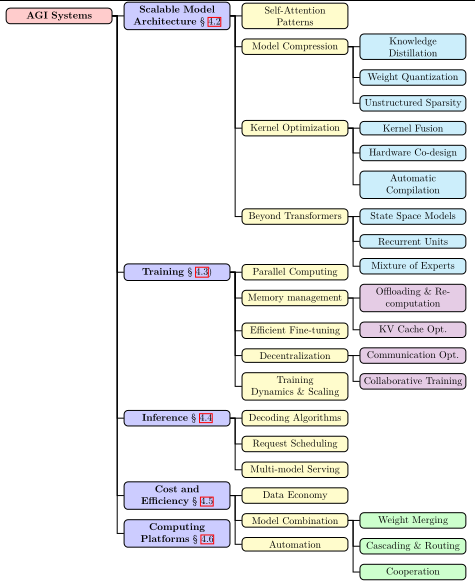
4.1 系统挑战的四面楚歌:数据、内存、延迟与成本
在深入具体技术之前,我们必须理解AGI系统面临的根本性约束。这些约束不是暂时的工程难题,而是伴随着规模指数级增长而凸显的结构性矛盾。
数据处理的吞吐量困境 是现代AGI系统的首要瓶颈。按照Chinchilla Scaling Law,一个最优训练的模型需要的数据量与参数量成正比。当模型达到万亿参数规模,所需的token数量将达到天文数字。更严峻的是,互联网上的原始数据质量参差不齐,合成数据的爆炸式增长带来了数据污染 (Data Contamination)的风险。这要求系统具备自动化的数据筛选管道------能够实时清洗、去重、混合不同来源的数据,而这本身就需要巨大的计算资源。
内存墙 (Memory Wall)是第二个致命约束。Transformer模型的自注意力机制具有二次方复杂度------序列长度每增加一倍,显存占用和计算量增长四倍。当上下文窗口扩展到百万token级别,即使是H100 GPU的80GB显存也显得捉襟见肘。KV缓存(Key-Value Cache)技术虽然通过存储历史计算的键值对避免了重复计算,但它在长序列场景下本身就会成为显存的主要占用者。
迭代速度的摩尔定律失效 体现在训练成本的指数级攀升。GPT-4级别的模型训练需要数千张GPU连续运行数月,单次实验成本高达数百万美元。更糟糕的是,训练过程中的软硬件故障 (如GPU掉线、网络抖动、数据损坏)会导致训练中断,而检查点(Checkpoint)的保存与恢复又会引入额外开销。这要求系统具备容错能力 (Fault Tolerance)和弹性扩展(Elastic Scaling)能力。
隐私与边缘化的张力 构成了第四个维度。当前的AGI集中在数据中心运行,但真正的普及需要边缘部署------在用户的手机、汽车、家庭机器人上本地运行。这要求在有限的算力和功耗预算下,通过模型压缩、量化、剪枝等技术,将庞大的模型塞进边缘设备的内存中,同时保持可接受的推理质量。
4.2 可扩展架构:突破Transformer的物理极限
模型架构是AGI系统的"基因"。当前的架构创新围绕着三个核心目标:降低计算复杂度 、提升长序列处理能力 、实现条件计算(Conditional Computation)。
注意力机制的稀疏化革命
标准Transformer的自注意力机制虽然强大,但其O(n²) 的复杂度在长文本场景下成为不可承受之重。研究人员发现,并非所有token对之间的关系都同等重要------这催生了稀疏注意力模式(Sparse Attention Patterns)。
滑动窗口注意力 (Sliding Window Attention)假设远距离的依赖关系可以通过局部连接的叠加来近似,从而将复杂度降至线性。** dilated attention**(空洞注意力)则通过降低远距离关注的分辨率来节省计算。更精妙的是**全局token策略**------如StreamingLLM识别出的"注意力汇点"(Attention Sinks),发现初始token和特定 landmark token在长序列中承载着全局信息,保持对这些token的全局关注即可维持性能。
下表对比了主流长文本处理技术的复杂度与适用场景:
| 技术方案 | 计算复杂度 | 显存占用 | 适用场景 | 代表工作 |
|---|---|---|---|---|
| 标准全注意力 | O(n²) | O(n) | 短文本(<8K) | Original Transformer |
| 滑动窗口 | O(n×w) | O(w) | 局部依赖强的任务 | Longformer, BigBird |
| 线性注意力 | O(n) | O(1) | 超长序列(>100K) | Linear Attention, Performer |
| 分块压缩 | O(n×c) | O(c) | 文档级理解 | Transformer-XL, LongNet |
注:w为窗口大小,c为压缩后的块数,n为序列长度
专家混合(MoE):条件计算的稀疏激活
当模型规模超过千亿参数,密集前馈网络 (Dense FFN)成为了计算资源的巨大浪费------每个token都要激活所有参数。Mixture of Experts (MoE) 提供了一种优雅解决方案:将FFN层替换为多个"专家"子网络,通过路由机制(Routing Mechanism)为每个token选择Top-K个专家。
这实现了稀疏激活 (Sparse Activation)------虽然模型总参数量可能达到万亿级别,但每个token只激活其中的一小部分(如1/8或1/16)。这不仅降低了推理成本,还赋予了模型任务专门化(Task Specialization)的能力:不同的专家可以自动学习处理不同类型的token(如代码、数学、常识)。
然而,MoE引入了新的系统挑战:负载均衡 (Load Balancing)要求每个专家处理的token数量大致相等,避免某些专家过载而其他专家闲置;显存碎片(Memory Fragmentation)问题则源于需要将所有专家的参数加载到显存中,即使它们很少被同时使用。
超越Transformer:状态空间模型与线性复杂度
State Space Models (SSM) 代表了对Transformer架构最激进的挑战。Mamba等模型通过选择性状态空间 (Selective State Space)机制,实现了线性复杂度(O(n))的长序列建模,同时保持了Transformer的并行训练能力。
与Transformer的二次方注意力不同,SSM将序列建模视为状态转移问题 :通过可学习的参数(Δ, A, B, C),将输入序列压缩为固定大小的隐藏状态,随时间步递推更新。这类似于RNN的递归结构,但通过硬件感知的并行扫描算法 (Parallel Associative Scan),Mamba实现了与Transformer相当的训练速度,同时推理时具有常数级内存占用(与序列长度无关)。
最新的架构融合趋势表明,未来的AGI系统可能采用混合架构(Hybrid Architecture)------如Jamba结合Transformer层与Mamba层,或者MAD(Mixture of Depths)发现的Striped Hyena架构,在不同层使用不同的计算模式,以平衡局部细节捕捉与长程依赖建模。
4.3 大规模训练:万卡集群的交响乐
训练万亿参数模型不是简单的"堆硬件",而是分布式系统的艺术。当数千张GPU跨越多个计算节点协同工作时,通信延迟、内存瓶颈和并行策略的选择决定了训练的可行性。
四维并行策略的精密编排
现代大模型训练采用4D并行(Four-Dimensional Parallelism):
数据并行(Data Parallelism, DP)是最基础的形式------模型复制到多个设备,数据分片处理,梯度同步更新。ZeRO(Zero Redundancy Optimizer)系列技术通过分片优化器状态、梯度和参数,将数据并行的内存效率推向极致。
张量并行(Tensor Parallelism, TP)将单层内的计算拆分到多个GPU。例如,矩阵乘法的行和列可以分布在不同设备上,通过集合通信(All-Reduce)聚合结果。Megatron-LM展示了如何将Transformer层内的注意力头和FFN网络高效切分。
流水线并行 (Pipeline Parallelism, PP)按层垂直切分模型。数据像流水线一样依次流经各GPU,但简单的流水线会导致气泡 (Bubble)------GPU在等待上游数据时空转。先进的调度算法如交错流水线 (Interleaved Pipeline)和动态重计算(Dynamic Recomputation)可以最小化这些气泡。
序列并行(Sequence Parallelism, SP)针对长文本场景,沿序列维度切分输入。结合Ring Attention等技术,可以将超长序列的计算分散到多个节点,突破单卡显存限制。
这四种并行策略的组合需要精心的并行策略搜索(Parallelism Strategy Search)。Alpha和FlexFlow等系统使用动态规划算法,根据集群的网络拓扑(NVLink带宽、节点间延迟、内存容量)自动寻找最优并行配置,往往比人工设计的策略效率高出20%以上。
内存管理与通信优化
KV缓存的精细化管理 在长文本推理中至关重要。vLLM提出的PagedAttention 借鉴了操作系统的虚拟内存思想:将KV缓存分割为非连续的块(Blocks),按需分配,显著减少内存碎片。Scissorhands和H2O则通过注意力权重分析,发现并非所有历史token都同等重要------可以主动驱逐(Evict)不重要的token,仅保留"关键快照"(Key Snapshots)。
去中心化训练 (Decentralized Training)探索了利用地理分布的异构算力的可能。Petals项目允许用户通过互联网贡献GPU资源,共同微调BLOOM-176B级别的模型。这要求解决慢速网络下的梯度压缩 (如CocktailSGD的稀疏化与量化组合)、异步同步(如DiLoCo的联邦平均算法)等挑战,将通信量降低500倍而保持收敛性。
4.4 推理优化:毫秒必争的响应艺术
训练是离线的、批量的,而推理是在线的、实时的。AGI系统必须同时满足低延迟 (Latency)和高吞吐(Throughput)的要求------这对矛盾在自回归生成模型中尤为尖锐。
投机解码:用计算换延迟
投机解码 (Speculative Decoding)是解决自回归模型串行生成瓶颈的巧妙策略。它使用一个轻量级的草稿模型 (Draft Model)快速生成多个候选token,然后由大模型(目标模型)并行验证这些候选。由于Transformer的并行验证能力,只要草稿模型的准确率足够高(通常由大模型自身的小版本或早期层担任),就能实现2-5倍的加速而保持输出分布不变。
Medusa和Lookahead Decoding进一步扩展了这一思想,通过引入额外的解码头 (Decoding Heads)或利用输入序列中的重复模式,无需独立的草稿模型即可生成候选序列。Flash-Decoding++则通过异步Softmax 和双缓冲GEMM优化,将长序列解码的硬件利用率提升至90%以上。
请求调度与动态批处理
LLM推理服务面临请求长度的高度不确定性 ------有的查询只有10个token,有的可能上传整本书。传统的静态批处理(Static Batching)会导致严重的填充浪费(Padding Waste)------短序列必须填充到批次内最长序列的长度。
连续批处理 (Continuous Batching)或迭代级调度 (Iteration-level Scheduling)改变了游戏规则。vLLM和Orca系统在每次迭代后重新组织批次,将已完成序列的位置分配给新请求,实现GPU的100%利用率。DeepSpeed-FastGen的Dynamic SplitFuse更进一步,将长提示(Prompt)分割成小块,与短提示的生成阶段混合调度,平衡了首token延迟(TTFT)和整体吞吐量。
多LoRA服务 (Multi-LoRA Serving)针对个性化需求。当数千个用户各自微调了专属的LoRA适配器(Adapter)时,系统需要在共享的基础模型上快速切换不同的适配器权重。S-LoRA和Punica通过统一内存池 和异构批处理内核,实现了单卡服务上千个LoRA适配器的能力,为"千人千面"的AGI应用提供了基础设施。
4.5 成本与效率:数据经济的精细化运营
AGI的民主化不仅依赖算法突破,更取决于经济可行性。当模型训练成本以千万美元计,推理成本以每千token美分计时,效率就是生命线。
数据价值与模型合并
数据经济(Data Economy)关注如何量化训练数据的价值。Shapley Value等博弈论方法被用于评估单个数据点对模型性能的贡献,指导数据清洗和定价策略。TracIn等方法通过追踪梯度变化来识别最具影响力的训练样本。
模型合并 (Model Merging)提供了一种无需重新训练即可组合多个专家模型的路径。通过权重平均、任务算术(Task Arithmetic)或SLERP(球面线性插值),可以将不同领域微调的模型(如数学专家、代码专家、医学专家)融合为通用模型,实现1+1>2 的零成本性能提升。FrugalGPT则展示了级联推理(Cascading Inference)的经济学------简单查询由小模型处理,复杂查询才调用大模型,通过 learned router 降低80%的API成本。
4.6 计算平台:硬件与软件的协同进化
软件优化终究受限于硬件的物理特性。AGI系统的发展推动了专用硬件的革新,也要求算法设计充分考虑硬件架构。
GPU的进化 从通用计算向专用AI加速发展。NVIDIA的Hopper架构引入了Transformer Engine ,支持FP8精度计算,将吞吐量提升一倍。H100的NVLink Switch允许GPU之间以900GB/s的速度通信,打破了多节点训练的带宽瓶颈。
替代架构 正在崛起。Google的TPU v5p提供了更强的矩阵计算密度;Groq的LPU(Language Processing Unit)通过张量流架构(Tensor Streaming Architecture)实现了惊人的低延迟(毫秒级响应千亿参数模型);AWS的Inferentia和Trainium系列则针对云规模部署优化了成本结构。
边缘硬件 的AI化趋势明显。Apple的M3 Max神经引擎支持大模型本地运行;Qualcomm的Cloud AI 100 Ultra可以在150瓦功耗下服务千亿参数模型;甚至核电池(Nuclear Battery)技术也开始探索为边缘AGI设备提供50年无需充电的能源方案。
编译器与内核优化 架起了算法与硬件的桥梁。TVM、Triton和MLC-LLM等工具链能够将PyTorch模型自动编译为针对特定硬件(ARM、CUDA、Metal)优化的内核,实现算子融合 (Operator Fusion)和内存布局优化,让同样的模型在不同设备上性能提升数倍。
4.7 AGI系统的未来形态:从集中到分布式
展望未来,AGI系统将呈现三种主要形态,分别对应不同的应用场景和约束条件:
数据中心级超算:终极智能的算力堡垒
第一种形态是当前的延续:数据中心内的超大规模模型 。这些模型拥有万亿级参数,配备超长上下文(百万token),支持复杂的多模态推理和科学计算。它们将成为人类解决基础科学问题(如药物发现、气候模拟、数学证明)的"超级大脑"。技术上,这将依赖于三维集成芯片 (3D Stacking)和光学互连(Optical Interconnect)突破当前的带宽墙。
去中心化社区网络:民主化的算力众筹
第二种形态是去中心化AGI (Decentralized AGI)。通过区块链和联邦学习技术,全球分布的计算资源可以 pooling 起来,共同训练和 serving 大型模型。这种形态具有抗审查性 (Censorship Resistance)和隐私保护 优势------用户数据无需上传至中心化服务器。技术挑战在于异步共识 和异构容错,确保即使部分节点掉线或作恶,系统仍能稳定运行。
边缘端侧智能:私人化的隐形助手
第三种形态是边缘AGI (Edge AGI)。通过模型压缩 (4-bit/8-bit量化)、动态加载 (按需加载模型层)和神经架构搜索 (NAS),百亿参数级别的模型可以在手机、眼镜、耳机上流畅运行。这种形态强调零延迟 、数据主权 (Data Sovereignty)和个性化------你的AI助手真正了解你,因为它就在你的设备上,无需云端通信。
这三种形态不是互斥的,而是构成了分层智能网络 :边缘设备处理实时感知和简单决策,去中心化网络提供领域专业知识,超算中心处理复杂推理和科学计算。AGI的未来不是单一的巨大模型,而是有机协作的智能生态系统。
结语:在物理极限中寻找智能的出路
AGI系统的演进史,就是一部与物理定律妥协和博弈的历史。我们无法违背热力学第二定律,无法超越光速,无法让硅基芯片的功耗密度无限增长。但正是在这些约束中,工程师们展现出了惊人的创造力------通过稀疏激活避免无效计算,通过并行策略分散通信压力,通过编译优化榨取硬件的最后一滴性能。
这些底层系统的创新,往往比上层算法的突破更悄无声息,却同样关键。因为AGI不仅是智能的科学,也是工程的科学。当未来的历史学家回顾AGI的诞生时,他们会记得Transformer的架构,但同样应该记得FlashAttention对内存墙的冲击,记得4D并行让万亿参数训练成为可能,记得量化技术让大模型跑进了千家万户的手机。
下一篇,我们将转向AGI的**"道德罗盘"**------Alignment(对齐)技术。探讨如何在赋予AGI强大能力的同时,确保它始终服务于人类的价值观,避免潜在的存在性风险。
技术术语速查表:
-
Chinchilla Optimal: 模型参数量与训练数据量的最优配比原则
-
KV Cache: 存储历史计算的键值对以避免重复计算的技术
-
MoE: 专家混合模型,稀疏激活的大规模架构
-
4D Parallelism: 数据、张量、流水线、序列四种并行维度的组合
-
Speculative Decoding: 用小模型草稿加速大模型生成的技术