Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式
- [0. 导言](#0. 导言)
- [1. 为什么几何优先之后,大模型仍然会出现](#1. 为什么几何优先之后,大模型仍然会出现)
-
- [1.1 路线二解决了什么](#1.1 路线二解决了什么)
- [1.2 但 geometry-first 并没有消灭大模型需求](#1.2 但 geometry-first 并没有消灭大模型需求)
- [1.3 为什么 LRM 路线会出现](#1.3 为什么 LRM 路线会出现)
- [2. GRM:pixel-aligned Gaussian + transformer aggregation](#2. GRM:pixel-aligned Gaussian + transformer aggregation)
-
- [2.1 GRM 的核心句法](#2.1 GRM 的核心句法)
- [2.2 GRM 与 pixelSplat 的本质差异](#2.2 GRM 与 pixelSplat 的本质差异)
- [2.3 它相比 geometry-first 做了什么取舍](#2.3 它相比 geometry-first 做了什么取舍)
- [3. GS-LRM:最简 transformer 化 reconstruction](#3. GS-LRM:最简 transformer 化 reconstruction)
-
- [3.1 GS-LRM 的极简范式](#3.1 GS-LRM 的极简范式)
- [3.2 为什么它的"简单性"具有结构性意义](#3.2 为什么它的“简单性”具有结构性意义)
- [3.3 为什么路线三不一定需要复杂几何模块也能成立](#3.3 为什么路线三不一定需要复杂几何模块也能成立)
- [4. Long-LRM:为什么 32 张输入会改变问题性质](#4. Long-LRM:为什么 32 张输入会改变问题性质)
-
- [4.1 从 2--4 张到 32 张,不是量变,而是 regime change](#4.1 从 2–4 张到 32 张,不是量变,而是 regime change)
- [4.2 为什么长上下文需要 Mamba / token merging / Gaussian pruning](#4.2 为什么长上下文需要 Mamba / token merging / Gaussian pruning)
- [4.3 为什么 Long-LRM 是场景级拐点](#4.3 为什么 Long-LRM 是场景级拐点)
- [5. Long-LRM++:为什么直接预测数百万 Gaussian 容易模糊细节](#5. Long-LRM++:为什么直接预测数百万 Gaussian 容易模糊细节)
-
- [5.1 路线三的新主矛盾:context 足够大,但细节开始发虚](#5.1 路线三的新主矛盾:context 足够大,但细节开始发虚)
- [5.2 semi-explicit representation 到底修正了什么](#5.2 semi-explicit representation 到底修正了什么)
- [5.3 为什么 lightweight decoder 是必要的,而不是妥协](#5.3 为什么 lightweight decoder 是必要的,而不是妥协)
- [5.4 从 Long-LRM 到 Long-LRM++,主问题已经变了](#5.4 从 Long-LRM 到 Long-LRM++,主问题已经变了)
- [6. LRM 路线的优势:统一、多任务潜力、长序列扩展](#6. LRM 路线的优势:统一、多任务潜力、长序列扩展)
-
- [6.1 统一的 token-based 输入接口](#6.1 统一的 token-based 输入接口)
- [6.2 更容易与"大模型方法学"对接](#6.2 更容易与“大模型方法学”对接)
- [6.3 对 wide-coverage reconstruction 更自然](#6.3 对 wide-coverage reconstruction 更自然)
- [6.4 更有希望连接到多任务与空间基础模型](#6.4 更有希望连接到多任务与空间基础模型)
- [7. LRM 路线的代价:显式几何可解释性下降、训练资源上升](#7. LRM 路线的代价:显式几何可解释性下降、训练资源上升)
-
- [7.1 显式几何可解释性下降](#7.1 显式几何可解释性下降)
- [7.2 训练与推理资源上升](#7.2 训练与推理资源上升)
- [7.3 长上下文并不自动保证局部细节](#7.3 长上下文并不自动保证局部细节)
- [7.4 大模型越大,越像系统设计而不是单模块设计](#7.4 大模型越大,越像系统设计而不是单模块设计)
- [8. 它与 cost volume 路线是替代关系还是互补关系](#8. 它与 cost volume 路线是替代关系还是互补关系)
-
- [8.1 不宜简单说"大模型取代几何方法"](#8.1 不宜简单说“大模型取代几何方法”)
- [8.2 二者的真正边界](#8.2 二者的真正边界)
- [8.3 未来更可能是深度融合](#8.3 未来更可能是深度融合)
- [9. 大重建模型是否会成为空间基础模型的入口](#9. 大重建模型是否会成为空间基础模型的入口)
- [10. 结语](#10. 结语)
- [附:GRM / GS-LRM / Long-LRM / Long-LRM++ 统一对比](#附:GRM / GS-LRM / Long-LRM / Long-LRM++ 统一对比)
- 参考文献
系列文章全文导航(总览篇)
Part I:前馈式 3DGS 的起步范式:从像素到高斯
Part II:前馈式 3DGS 的 depth-first 转向
Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式
[Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合](#Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合)
[Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座](#Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座)
[Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS](#Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS)
路线三真正值得单独成篇,不是因为它把参数做大了,而是因为它把前馈式 3DGS 的核心问题,从"如何更显式地估计局部几何"逐步改写成"如何在一个全局 token sequence 中吸收、压缩、重组多视图信息,并最终解码为 Gaussian 表示"。如果说路线二的主旋律是 geometry-first,那么路线三的主旋律就是 transformer aggregation / global context / long sequence。GRM、GS-LRM、Long-LRM、Long-LRM++ 共同标记了这条转向:多视图几何不再主要被写进 cost volume,而是越来越多地被写进 token mixing、sequence modeling 与 representation decoding 里。
需要提前说明的是,本文主角严格限定为 GRM、GS-LRM、Long-LRM、Long-LRM++ 。MVSplat、DepthSplat 只作为路线二的背景,用于说明为什么 field 会从几何优先继续走向大模型化;pose-free / uncalibrated / foundation-geometry 一支,以及 structured latent / voxel-aligned 一支,不在本文主线之内。本文关心的不是"谁更大",而是 多视图几何与场景信息如何被全局 token 序列吸收、压缩、重组,并最终解码为 Gaussian 表示。
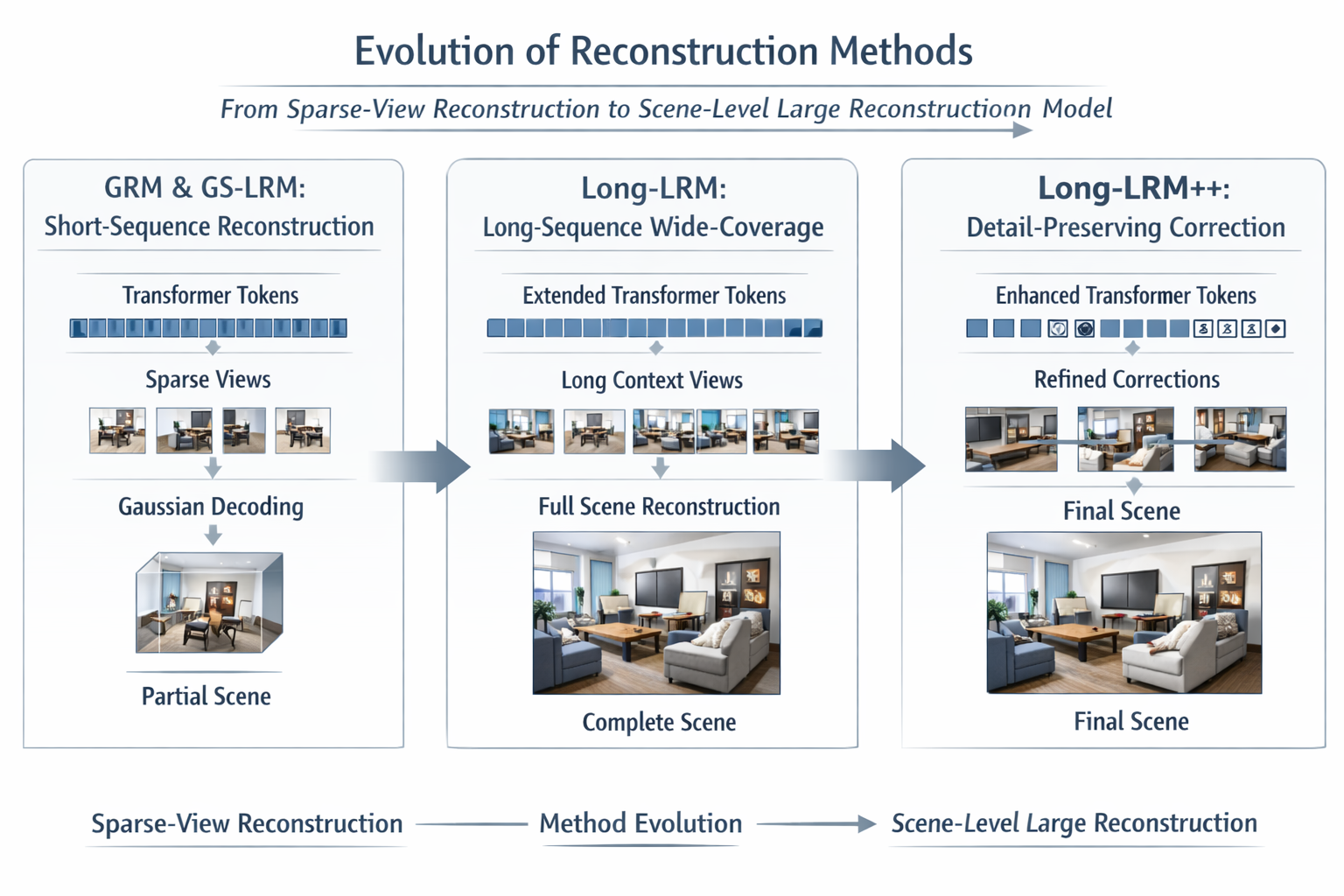
0. 导言
路线三是前馈式 3DGS 从"几何模块驱动"走向"全局上下文聚合驱动"的关键转折。原始 3DGS 的核心优势在于显式高斯表示与实时渲染,但它依然依赖场景级优化;而 feed-forward generalizable 3DGS 的任务,是把"每个场景都要优化"的流程,改写成"一个模型直接预测一个场景的高斯表示"。
在这件事上,GRM 与 GS-LRM 率先把 sparse-view reconstruction 写成 transformer 风格的 token-to-Gaussian 映射;Long-LRM 则进一步把问题推进到 32 张高分辨率输入、wide-coverage、scene-level reconstruction;Long-LRM++ 又指出,仅有更大的上下文并不自动等于更好的细节,因而把 fine-detail preservation 拉成一条新的主矛盾。
换句话说,路线三不是在说"大模型更强",而是在说:一旦前馈式 3DGS 的问题从局部几何定位,转向场景级信息整合、跨视图一致性压缩、长范围覆盖与统一表示学习,token aggregation 就会自然成为新的主路。
这也是为什么理解路线三,不只是为了理解四篇论文本身,更是为了理解后续的空间基础模型、世界模型、结构化 3D latent 乃至生成式 3D 资产模型会如何继承这条方法论。这个判断属于趋势推断,但它是建立在 LRM 一系"用高容量 transformer + 大规模数据学习重建先验"的演进事实上。
形式上,我们可以先把路线三抽象成一个统一问题:
T = ⋃ i = 1 N P a t c h i f y ( C o n c a t ( I i , P i ) ) , (1) \mathcal{T}= \bigcup_{i=1}^{N} \mathrm{Patchify}\big(\mathrm{Concat}(I_i, P_i)\big), \tag{1} T=i=1⋃NPatchify(Concat(Ii,Pi)),(1)
Z = A θ ( T ) , G ^ = D ϕ ( Z ) , (2) Z= A_\theta(\mathcal{T}), \qquad \hat{\mathcal G}= D_\phi(Z), \tag{2} Z=Aθ(T),G^=Dϕ(Z),(2)
其中, I i I_i Ii 表示第 i i i 个输入视图, P i P_i Pi 表示与其绑定的相机条件(常见为 pose、Plücker rays 等), T \mathcal{T} T 是跨视图拼接后的 token sequence, A θ A_\theta Aθ 是 sequence aggregator,通常由 transformer、Mamba 或二者混合构成, D ϕ D_\phi Dϕ 则把聚合后的 token 状态解码为 Gaussian 表示 G ^ \hat{\mathcal G} G^。
真正的分歧不在于是否使用高斯,而在于几何信息到底是在显式中间变量里被组织,还是在 token mixing 的隐藏状态里被吸收。 这也是后文分析 token aggregation 与 explicit geometry 边界时的前提。
1. 为什么几何优先之后,大模型仍然会出现
1.1 路线二解决了什么
路线二的代表工作------例如 MVSplat、DepthSplat------把前馈式 3DGS 的关键难题,首先归结为 Gaussian center localization 。MVSplat 明确用 plane sweeping 构建 cost volume,并将跨视图特征相似性存储在 cost volume 中,以获得深度估计的几何线索;DepthSplat 则进一步把高斯重建与深度估计绑定起来,强调 pre-trained monocular depth features 与 multi-view depth model 的互相增益。也就是说,路线二的核心句法是:先把几何中心估准,再去回归其它 Gaussian 属性。
形式上,可将 geometry-first 写为:
C ( x , d ) = A g g ( F i ( π i ( Π − 1 ( x , d ) ) ) i = 1 N ) , (3) C(x,d)= \mathrm{Agg}\Big( {F_i(\pi_i(\Pi^{-1}(x,d)))}_{i=1}^{N} \Big), \tag{3} C(x,d)=Agg(Fi(πi(Π−1(x,d)))i=1N),(3)
d ^ ( x ) = arg max d C ( x , d ) , μ ( x ) = Π − 1 ( x , d ^ ( x ) ) , (4) \hat d(x)=\arg\max_d C(x,d), \qquad \mu(x)=\Pi^{-1}(x,\hat d(x)), \tag{4} d^(x)=argdmaxC(x,d),μ(x)=Π−1(x,d^(x)),(4)
其中, x x x 是参考视图像素, d d d 是候选深度, F i F_i Fi 是第 i i i 个视图的 2D 特征, π i ( ⋅ ) \pi_i(\cdot) πi(⋅) 表示把 3D 点投影到第 i i i 个视图, Π − 1 ( x , d ) \Pi^{-1}(x,d) Π−1(x,d) 则是像素-深度到 3D 点的反投影。这一路线的优点是:中间变量具有明确的几何语义。 你可以直接讨论 plane sweep、深度峰值、可见性与投影一致性。工程上,这种可解释性极其珍贵。
1.2 但 geometry-first 并没有消灭大模型需求
问题在于,cost volume 天生更像一个 局部几何推理器 ,而不是一个 长范围场景信息整合器。它擅长在有限视角、有限深度假设、有限空间邻域内推理局部结构;但当输入视角从 2--4 张增加到几十张、视场覆盖从局部片段扩展到 360° 场景、数据分布从对象走向复杂室内外场景时,问题就不再只是"哪个深度最合理",而变成"如何把大范围、多尺度、长上下文的跨视图信息统一压缩到一个可泛化的 scene representation 中"。
Long-LRM 的出发点就很直接:此前的 feed-forward GS 模型通常只能处理 1--4 张输入图像,覆盖范围有限,因此无法重建真正的大场景。
这意味着,geometry-first 并没有过时;它只是暴露出边界。一旦问题从"局部深度估计"转向"场景级信息整合",全局 token aggregation 就会自然出现。 因为此时的主问题不再只是显式三维几何的局部定位,而是:哪些视图该互相通信、哪些上下文该跨尺度共享、哪些冗余该在中间状态中被压缩、哪些信息该保留到最终 Gaussian 解码。这个问题的语言,更接近 sequence modeling,而不只是 stereo matching。
1.3 为什么 LRM 路线会出现
如果把时间线再往前追,LRM 本身就已经给出了一个先例:它用一个高容量 transformer,从单张输入图像直接预测 NeRF/triplane 表示,并在大规模数据上训练重建先验。GS-LRM 明确把自己放在这条谱系里,但指出早期 LRM 基于 triplane NeRF,存在固定 triplane 分辨率与体渲染开销的问题,这会限制细节保持与训练/渲染速度。
因此,GS-LRM 的关键动作不是简单照搬 LRM,而是把"large reconstruction model"改写成"针对 3D Gaussian Splatting 的 large reconstruction model"。
本质上,路线三出现的根本原因不是"想把网络做大",而是 field 需要一种更统一的信息聚合基底(reconstruction substrate):它要能吞下对象与场景、短序列与长序列、局部结构与全局覆盖,并且尽可能少依赖手工拼接的几何模块。这条路线的历史作用,正在于它把前馈式 3DGS 从"一个聪明的几何头"逐步推向"一个真正的场景级重建模型"。
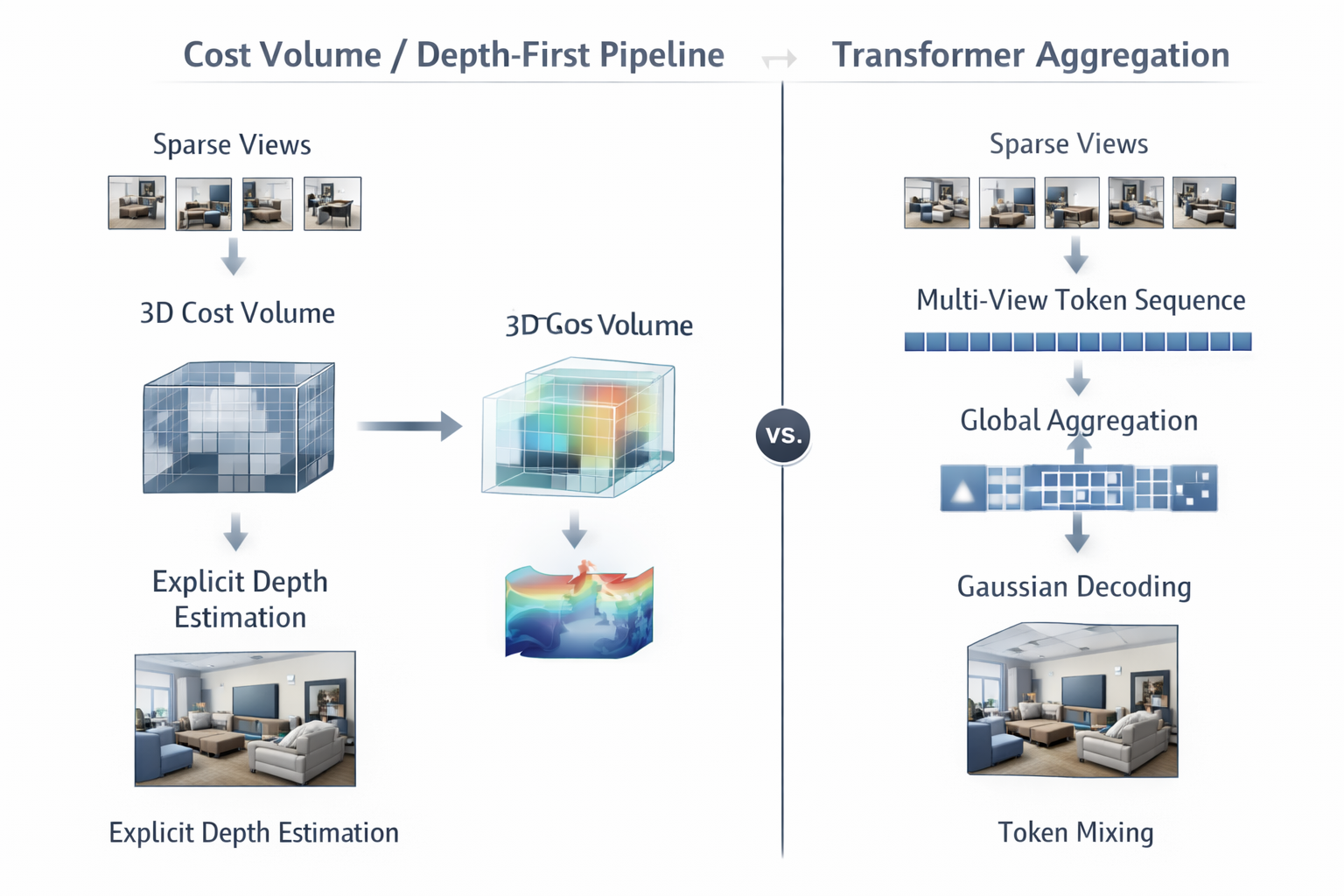
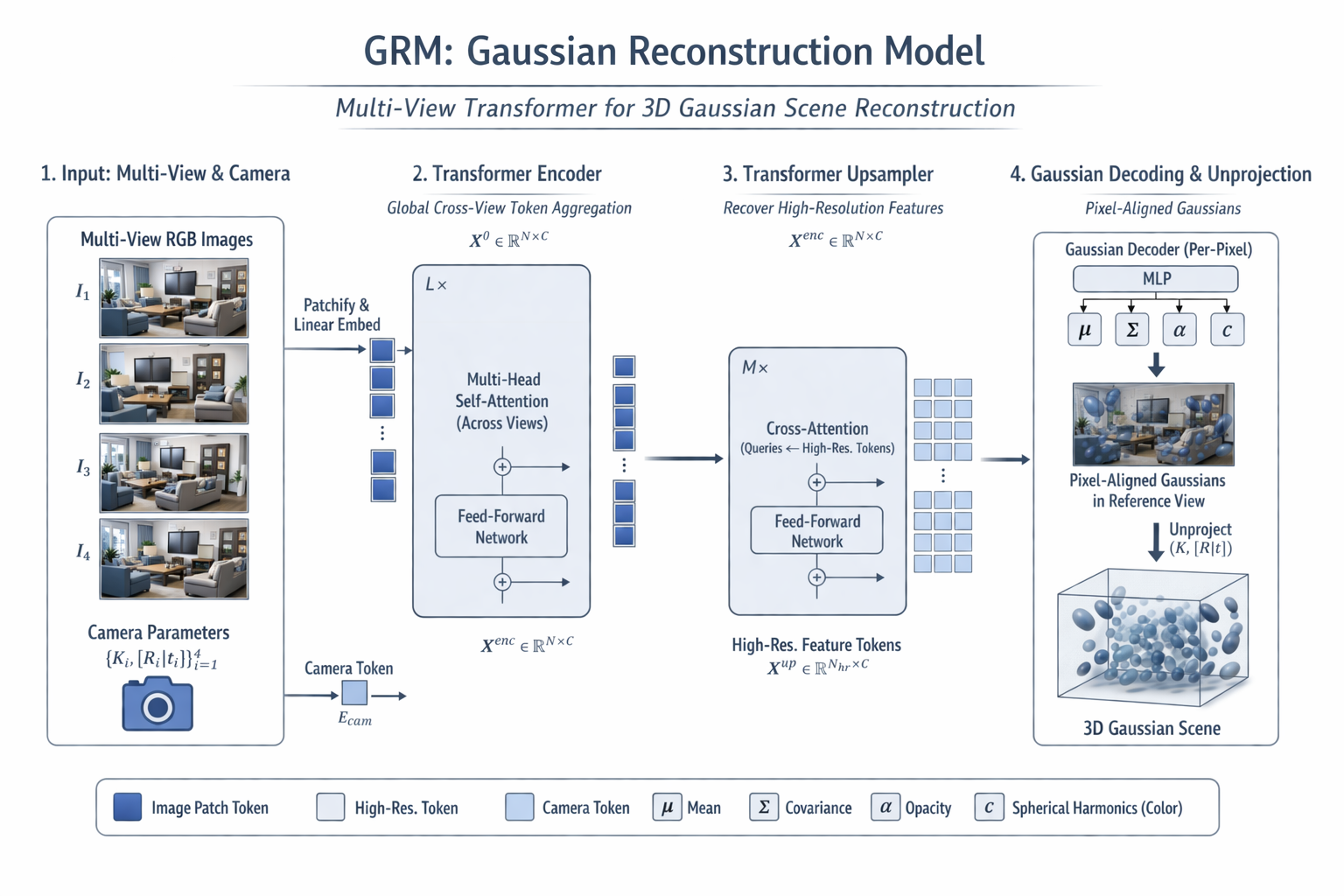
2. GRM:pixel-aligned Gaussian + transformer aggregation
2.1 GRM 的核心句法
GRM 的重要性,不只是它效果好,而是它第一次很明确地把 pixel-aligned Gaussian prediction 放进了 全局 transformer aggregation 框架中。GRM 的做法是:对每个输入视图预测一张 Gaussian attribute map,每个像素对应一个沿该视线约束的高斯;属性包括深度、旋转、尺度、opacity 与颜色项,然后再把这些 pixel-aligned Gaussians 反投影到 3D,形成稠密的 3D Gaussian 集合。与此同时,GRM 用纯 transformer 编码器跨所有视图做全局 self-attention,并引入 transformer-based upsampler 逐步恢复到输入分辨率,以补偿低分辨率 tokenization 对高频细节的损失。
形式上,GRM 的 pixel-aligned Gaussian 可以写为:
μ i , u = o i + d ^ i , u , r i , u , (5) \mu_{i,u}= o_i + \hat d_{i,u}, r_{i,u}, \tag{5} μi,u=oi+d^i,u,ri,u,(5)
g i , u = ( μ i , u , R i , u , S i , u , α i , u , c i , u ) , G ^ = ⋃ i , u g i , u , (6) g_{i,u}=\big( \mu_{i,u}, R_{i,u}, S_{i,u}, \alpha_{i,u}, c_{i,u} \big), \qquad \hat{\mathcal G}= \bigcup_{i,u} g_{i,u}, \tag{6} gi,u=(μi,u,Ri,u,Si,u,αi,u,ci,u),G^=i,u⋃gi,u,(6)
其中, u u u 表示第 i i i 个视图中的像素位置, o i o_i oi 为相机中心, r i , u r_{i,u} ri,u 为该像素对应的 viewing ray, d ^ i , u \hat d_{i,u} d^i,u 为网络预测的深度, R , S , α , c R,S,\alpha,c R,S,α,c 分别对应旋转、尺度、不透明度与颜色项。这里的关键不是公式本身,而是 高斯中心不再自由漂浮在 3D 空间中,而是被约束在射线上。工程上,这显著降低了学习难度,也保留了一部分可解释性。
2.2 GRM 与 pixelSplat 的本质差异
GRM 与 pixelSplat 都不是 optimization-based 3DGS,它们都在探索 feed-forward Gaussian reconstruction。但二者的方法本质不同:pixelSplat 从图像对出发,预测 3D 概率分布并从中可微采样 Gaussian means,以应对 sparse、局部支撑表示带来的局部最小值问题;GRM 则不再把重点放在"两视图对上的高斯均值采样",而是把多视图输入统一编码为一个全局 token state,再在这个 state 上预测 pixel-aligned Gaussian maps,并通过 transformer upsampler 恢复细节。
换句话说,pixelSplat 更像"带 probabilistic mean sampling 的 pairwise reconstruction",而 GRM 已经明显转向"multi-view transformer aggregation + pixel-aligned decoding"。
这也是 GRM 的结构性意义:它不是单纯延续 pixel-aligned 路线,而是在告诉后续工作,pixel-aligned Gaussian 本身可以只是解码约束,真正的核心可以转移到前面的全局 aggregation。 一旦接受这件事,后面的 GS-LRM 与 Long-LRM 就顺理成章了------它们会进一步把"显式几何模块"从中心位置后撤,把"序列聚合器"推到舞台中央。
2.3 它相比 geometry-first 做了什么取舍
GRM 并没有像 MVSplat 那样显式构造 cost volume,也没有把深度概率体作为方法中心。它保留了沿光线约束的几何偏置,却把跨视图 correspondence 的主要求解交给 self-attention 与 token communication。真正的分歧不在于"有没有几何",而在于 几何是被显式地组织为中间结构,还是被隐式地吸收进 token mixing。GRM 属于重要中间态:它还没有走到 Long-LRM 的场景级 regime,但已经完成了从"局部几何模块中心"到"全局 aggregation 中心"的第一次方法论转向。
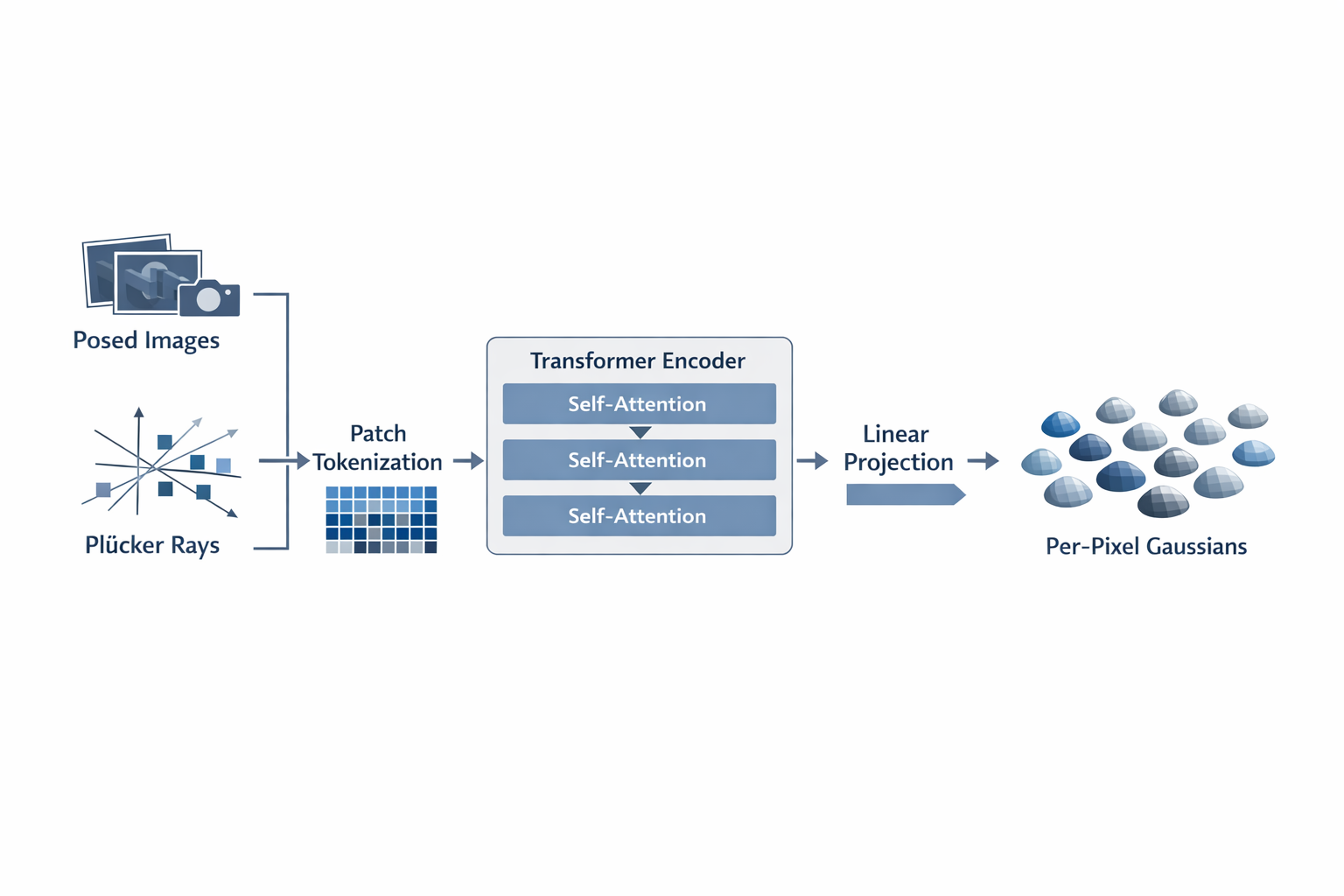
3. GS-LRM:最简 transformer 化 reconstruction
3.1 GS-LRM 的极简范式
如果说 GRM 还是"pixel-aligned Gaussian + transformer upsampler"的复合设计,那么 GS-LRM 则把路线三写到了一个极简而清晰的形式:直接 patchify 多视图 posed images,把所有 tokens 串联后送入 transformer blocks,再从输出 tokens 直接线性解码 per-pixel Gaussian 参数。
GS-LRM 明确把 posed image tokenization、multi-view concatenation、transformer self-attention、linear decoding 这四件事,写成一个干净的 sequence-to-Gaussian pipeline。
形式上,可写为:
t i , j = L i n e a r ( P a t c h i f y p ( C o n c a t ( I i , P i ) ) ) , (7) {t_{i,j}}= \mathrm{Linear}\Big( \mathrm{Patchify}_p( \mathrm{Concat}(I_i, P_i) ) \Big), \tag{7} ti,j=Linear(Patchifyp(Concat(Ii,Pi))),(7)
Z = T r a n s f o r m e r ( C o n c a t ∗ i , j t ∗ i , j ) , G i , j = L i n e a r ( Z ) , (8) Z= \mathrm{Transformer}\Big( \mathrm{Concat}*{i,j}{t*{i,j}} \Big), \qquad {G_{i,j}}= \mathrm{Linear}(Z), \tag{8} Z=Transformer(Concat∗i,jt∗i,j),Gi,j=Linear(Z),(8)
再经 unpatchify,把每个 patch token 对应的 p 2 p^2 p2 个像素级 Gaussian 参数恢复为 per-pixel Gaussians。这里 P i P_i Pi 常用 Plücker ray coordinates 进行 pose conditioning。
GS-LRM 特别有意思的一点是:由于 Plücker 坐标已经随像素与视角变化,作者直接用它作为空间区分信号,因此不再额外使用位置编码或 view embedding。这个设计非常"干净",也非常有大模型气质。
3.2 为什么它的"简单性"具有结构性意义
GS-LRM 的简单,并不是工程偷懒,而是方法学上的清场。早期 LRM 面向单图到 NeRF/triplane,需要复杂的 latent representation 与 volumetric rendering;GS-LRM 则直接把输出改成 per-pixel Gaussians,从而让输入与输出在像素空间上形成了强对齐:每个像素沿着视线吐出一个高斯。
这带来两个结构性好处:第一,架构更像标准 ViT/transformer encoder-decoder,更容易扩展模型规模、数据规模与训练范式;第二,per-pixel Gaussian 天然适配不同分辨率输入,比固定 triplane resolution 更容易保住高频细节。
GS-LRM 自己也明确强调,早期 LRM 的 triplane NeRF 在分辨率与体渲染开销上存在限制,而 per-pixel Gaussian prediction 可以自然处理对象与复杂场景。
换句话说,GS-LRM 的价值不只在于"用 transformer 做 3DGS",而在于它首次给出了一个非常清晰的范式定义:large reconstruction model for 3DGS = patchified posed images + global self-attention + direct per-pixel Gaussian decoding。 这条定义后来几乎直接被 Long-LRM 继承。Long-LRM 自己也明确写道,它"similar to GS-LRM"地将 per-pixel GS prediction 视作一个 sequence-to-sequence mapping,只是把问题推向更长序列与更高分辨率。
3.3 为什么路线三不一定需要复杂几何模块也能成立
GS-LRM 给出的核心启发是:前馈式 3DGS 并不一定要先显式估深,再解码高斯。 只要输入 token 足够承载 pose-conditioned visual evidence,global self-attention 就有可能在隐藏状态里完成大量 correspondence aggregation,最后直接回归 pixel-aligned Gaussians。这不意味着几何不重要,而是意味着几何推理的"显式载体"发生了变化。它从 cost volume / depth map 这样的中间结构,转移到了 token interactions 里。
但这种极简路线也有隐患。它的优势是统一、清晰、可扩展;它的风险则是显式几何可解释性下降,而且在长序列、高分辨率、多场景 coverage 设定下,token 数量会迅速膨胀。也正因如此,GS-LRM 更像路线三的"范式奠基者",而不是终局。真正把这条路推到新 regime 的,是 Long-LRM。
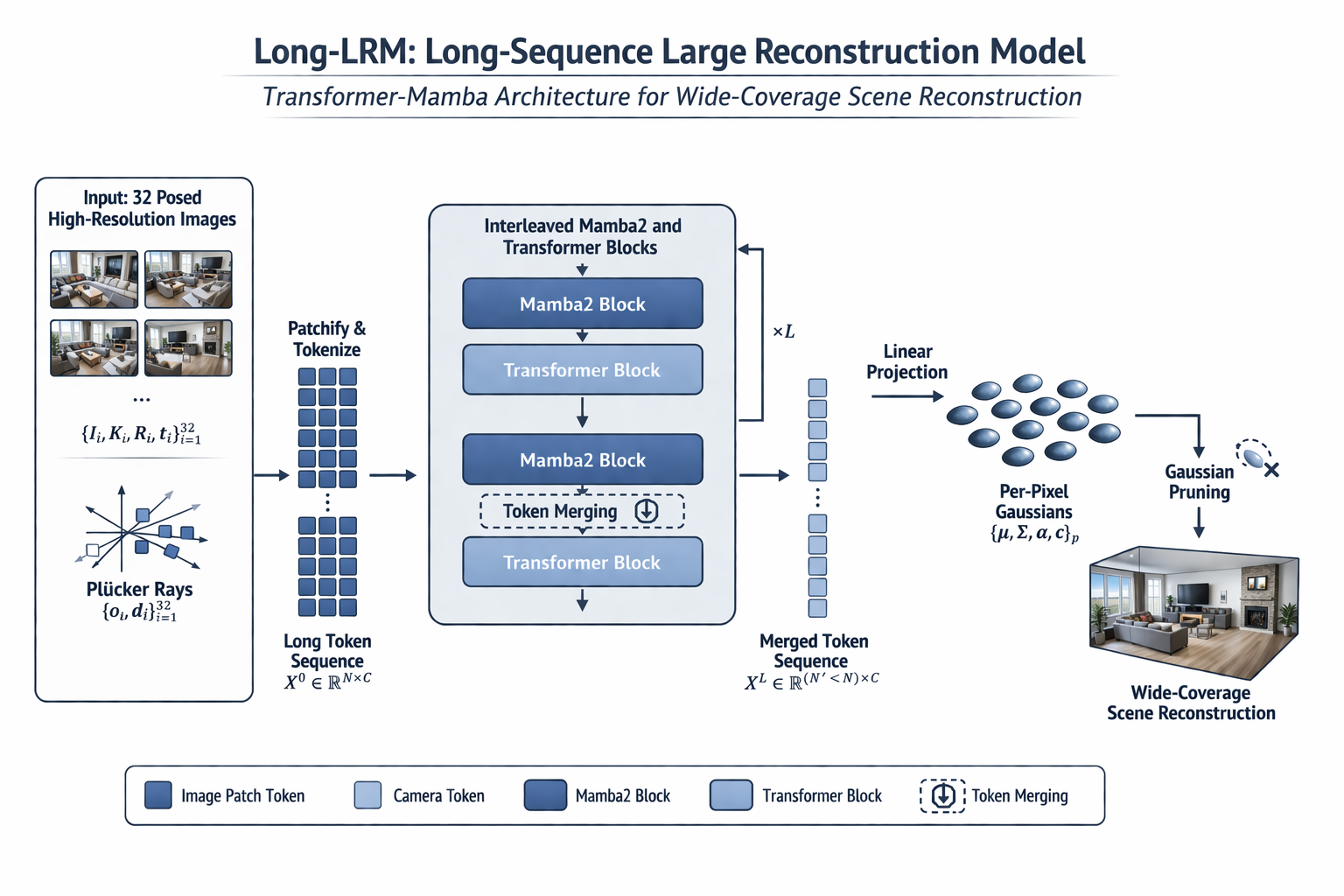
4. Long-LRM:为什么 32 张输入会改变问题性质
4.1 从 2--4 张到 32 张,不是量变,而是 regime change
Long-LRM 的问题意识非常清楚:此前的 feed-forward 3DGS,大都停留在 1--4 张输入图像的设定,覆盖范围有限,更多是在做局部 sparse-view reconstruction;而真实世界的大场景 reconstruction,需要至少几十张图像去覆盖足够大的视角跨度。因此,Long-LRM 把输入直接提升到 32 张 960×540 图像 ,并尝试在 单次前向 中完成 wide-coverage、scene-level Gaussian reconstruction 。作者明确指出,这样的输入配置对应约 250K tokens,已经比很多现代大语言模型的上下文还长。
形式上,这个 regime change 可以直接写出来:
L = N ⋅ H W p 2 , (9) L= N \cdot \frac{HW}{p^2}, \tag{9} L=N⋅p2HW,(9)
当 N = 32 , H = 960 , W = 540 , p = 8 N=32,\ H=960,\ W=540,\ p=8 N=32, H=960, W=540, p=8 时,
L = N ⋅ H W p 2 , (9) L= N \cdot \frac{HW}{p^2}, \tag{9} L=N⋅p2HW,(9)
L = 32 × 960 × 540 8 2 = 259,200 ≈ 250 K . (10) L= 32 \times \frac{960 \times 540}{8^2}= 259{,}200 \approx 250K. \tag{10} L=32×82960×540=259,200≈250K.(10)
从 2--4 张到 32 张,问题不再只是多喂一些图,而是 token sequence 的组织、压缩、传输与预算控制本身,已经变成方法核心。 在这个长度下,谁负责 global context,谁负责线性扩展,谁负责压缩冗余,都会影响模型是否可训练、可推理、可保真。
4.2 为什么长上下文需要 Mamba / token merging / Gaussian pruning
这正是 Long-LRM 选择 Mamba2 + Transformer 混合架构 的原因。Long-LRM 没有彻底放弃 transformer,因为作者明确提到 transformer 在长上下文推理与质量上仍然更强;但也没有坚持纯 transformer,因为其序列代价会过高。因此它采用 interleaved 的 hybrid block:大量 Mamba2 blocks 负责更可扩展的 sequence mixing,少量 global self-attention transformer blocks 负责质量与长程依赖。作者给出的实现是每个 hybrid block 由 7 个 Mamba blocks + 1 个 transformer block 组成。
但仅有 Mamba 还不够。Long-LRM 明确指出,在 32 张 960×540、patch size 8 的设定下,即使是线性复杂度的 Mamba,内存仍然会爆掉。因此它必须在网络中部引入 token merging ,通过类似 CNN 多层级编码器的思路,把 token length 压缩到原来的 1/4。这不是一个可有可无的微调,而是长序列可训练性的硬前提。
接着,token 压缩解决的是"中间状态太长"的问题,而 Gaussian pruning 解决的是"输出显式表示太大"的问题。因为 per-pixel Gaussian decoding 在 32 张高分辨率输入下会产生约 1700 万个 Gaussians。Long-LRM 明确指出,这样的数量对显存与渲染速度都会造成巨大压力,而且由于视锥重叠与高分辨率输入,冗余极高,因此必须在训练与测试阶段做 opacity-based pruning。
这正好回答了本文要求显式写深的第二个学术问题:为什么长上下文需要 Mamba / token merge / Gaussian pruning? 因为在长序列大场景设定下,问题已经变成一个三重预算问题:
第一,sequence budget ------中间 token 太多,attention/Mamba 都会吃不消;
第二,representation budget ------输出的显式高斯太多,渲染和反传都顶不住;
第三,coverage budget------如果你不允许更多视角进入模型,就根本拿不到 wide-coverage scene reconstruction。
Long-LRM 的贡献,就是第一次把这三种预算同时放进一个统一的 feed-forward 3DGS 系统设计里。
4.3 为什么 Long-LRM 是场景级拐点
Long-LRM 的历史作用,不只是"把图像数从 4 变成 32",而是它首次让 feed-forward 3DGS 进入了 scene-level large reconstruction model 的语境。此前的 short-context 模型,更像局部场景片段的泛化器;而 Long-LRM 则开始具备"整场景一次性重建"的问题定义。作者自己也直接把它表述为:前作只能处理 1--4 张输入并重建场景的一小部分,而 Long-LRM 则尝试在单次前向中重建整个场景。
换句话说,Long-LRM 把路线三从"transformer 化 reconstruction"推进到了"wide-coverage reconstruction"。真正的分歧不在于多了多少张图,而在于 输入规模改变了任务语义:模型不再只是做 sparse-view interpolation,而是在做长范围场景信息压缩、全局结构协调与 coverage-aware Gaussian budgeting。自这一点起,feed-forward 3DGS 才真正有资格谈"空间基础模型的入口"。
5. Long-LRM++:为什么直接预测数百万 Gaussian 容易模糊细节
5.1 路线三的新主矛盾:context 足够大,但细节开始发虚
Long-LRM++ 的问题意识极具代表性。它没有否定 Long-LRM 对长上下文与大覆盖范围的推进,而是指出:当输入视角和场景覆盖范围已经足够大时,新的主问题不再是"上下文够不够",而是"全局上下文如何与局部高频细节兼容"。
作者非常直接地说明:传统 color splatting 机制下,每个 Gaussian 只携带一个颜色;要想忠实复现文本、细线、锐利边界等 fine details,往往需要预测 tens of millions of Gaussians,甚至接近 one-per-pixel 的密度,而轻微的 pose 或 Gaussian position 误差都会进一步放大成可见的 blur。
这正是本文第三个必须写深的学术问题:为什么 fine details preservation 会成为大重建模型路线的新瓶颈? 因为在 short-context、小场景、低覆盖设定下,模型的主矛盾是"信息不够";而在 long-context、scene-level、wide-coverage 设定下,模型的主矛盾逐渐变成"信息太多,但必须被压进一个一次性显式表示里"。
如果这个显式表示仍然要求每个 Gaussian 同时承担 精确几何定位 + 颜色承载 + 高频细节表达 ,那么误差传播就会非常敏感。更大上下文并不自动等于更好细节;它只是让全局一致性更有希望,而细节保真则需要新的表示与解码策略。
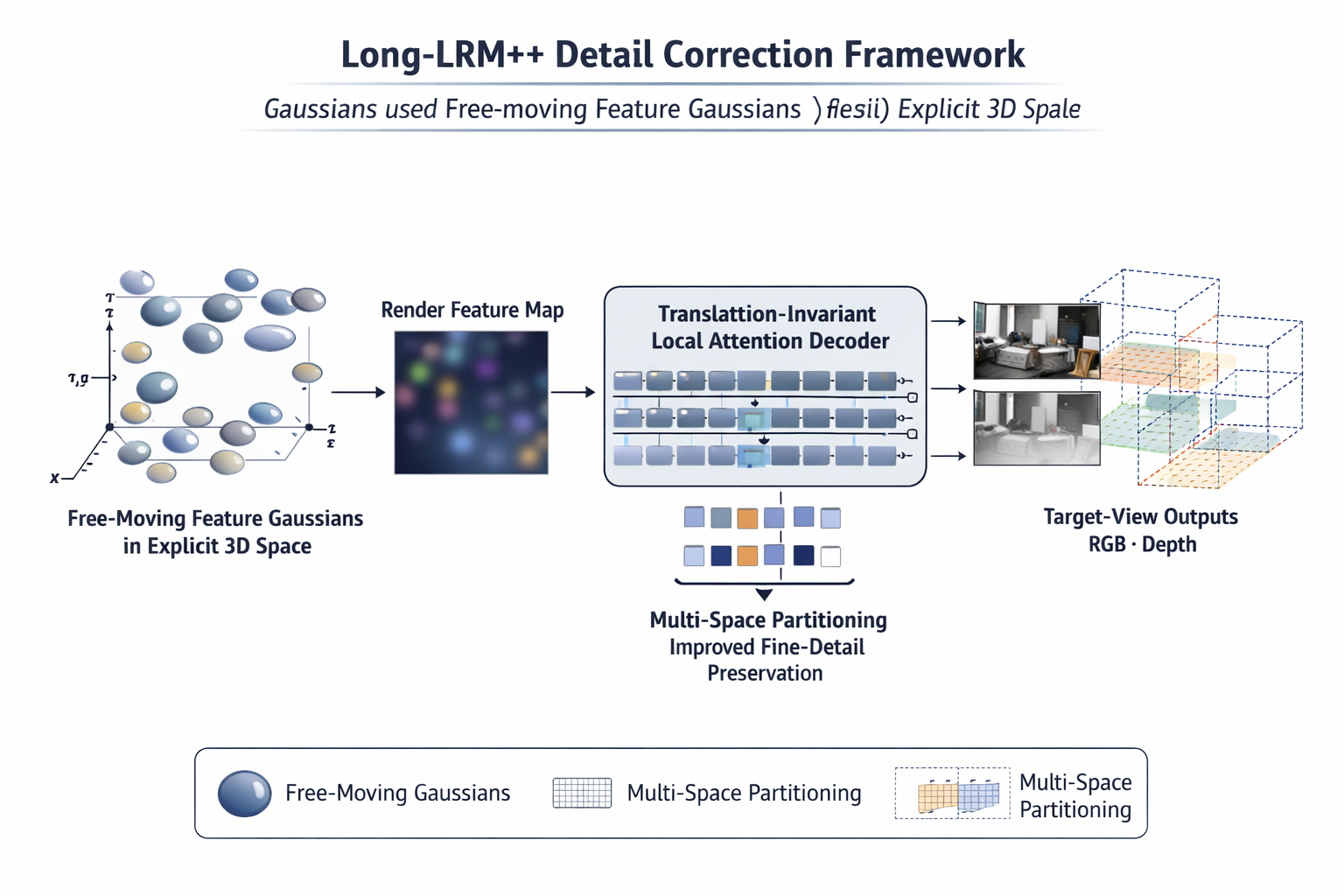
5.2 semi-explicit representation 到底修正了什么
Long-LRM++ 的核心修正,是从 Long-LRM 的 pixel-aligned color Gaussians ,转向 free-moving feature Gaussians + lightweight decoder 的半显式表示。它仍然保留 3D Gaussian 的显式空间位置与实值度量关系,但放松了 Gaussian position/color 与真实表面的严格一一对齐;每个 Gaussian 携带的不再是固定颜色,而是 feature vector。渲染时,先把 feature Gaussians splat 成目标视角的 feature map,再通过一个轻量级 decoder 生成最终 RGB 或 depth。
形式上,可写为:
g k = ( μ k , Σ k , α k , f k ) , (11) g_k= (\mu_k,\Sigma_k,\alpha_k,f_k), \tag{11} gk=(μk,Σk,αk,fk),(11)
F t = R g s ( g k , Π t ) , I ^ t = D d e c ( F t ) , (12) F_t= R_{\mathrm{gs}}({g_k}, \Pi_t), \qquad \hat I_t= D_{\mathrm{dec}}(F_t), \tag{12} Ft=Rgs(gk,Πt),I^t=Ddec(Ft),(12)
其中, f k f_k fk 是 Gaussian feature,而不再是固定颜色; R g s R_{\mathrm{gs}} Rgs 是把 feature Gaussians splat 到目标视角的操作, D d e c D_{\mathrm{dec}} Ddec 是目标帧 decoder。
与 Long-LRM 的"直接把高斯当作最终颜色单元"相比,这相当于把表示分成两层:显式空间锚点 + 轻量隐式解码器。这就是所谓 semi-explicit representation。工程上,这种分层让高频细节不必完全依赖"高斯数量暴涨"来表达。
5.3 为什么 lightweight decoder 是必要的,而不是妥协
Long-LRM++ 的 decoder 不是随便加一层网络,而是针对细节问题做了两项关键设计。第一,decoder 中引入 translation-invariant local-attention blocks ,作者指出这相比带绝对位置编码的全局 attention,能更稳地处理目标帧中的局部结构,因为同一个物体不应因为出现在不同图像区域就被不同方式处理。第二,它加入 multi-space partitioning and merging,把 Gaussian 集合分成多个子集独立渲染和解码,再在输出前融合,以降低不同内容子空间互相干扰的风险。
这一设计的结构性意义在于:Long-LRM++ 承认,仅靠一个统一的 feed-forward decoder 去直接输出数百万 color Gaussians,是一条在细节上过于脆弱的路线。因此,它不是继续把 decoder 做得更深、更慢,而是通过 半显式表示 + 轻量解码 ,把"高斯负责几何锚定,decoder 负责局部细节恢复"这件事重新分工。Long-LRM++ 甚至明确说明,在这种表示下,它只需要 Long-LRM 1/4 的 Gaussian 数量,就能显著超过后者的渲染质量。
5.4 从 Long-LRM 到 Long-LRM++,主问题已经变了
到这一步,路线三的主问题已经发生第二次转移。GRM / GS-LRM 的问题是"如何把多视图 reconstruction 改写成 transformer aggregation";Long-LRM 的问题是"如何让 aggregation 扩展到 long sequence / wide coverage";Long-LRM++ 的问题则是"当 aggregation 已经足够强时,如何避免 explicit Gaussian decoder 把 fine details 平滑掉"。这不是简单补 patch,而是意味着路线三内部也在发生方法论深化。
6. LRM 路线的优势:统一、多任务潜力、长序列扩展
6.1 统一的 token-based 输入接口
路线三最重要的优势,不是单点性能,而是它提供了一个高度统一的 reconstruction substrate。无论是 GRM 的 multi-view transformer encoder、GS-LRM 的 patchified posed images、Long-LRM 的 long token sequence,还是 Long-LRM++ 的 interleaved Mamba/Transformer backbone,它们都把 3D reconstruction 的输入写成了相似的形式:图像 + 相机条件 → token sequence → global aggregation → Gaussian decoding。这使得模型规模扩展、数据规模扩展、任务迁移与统一训练范式变得自然得多。
6.2 更容易与"大模型方法学"对接
相比 cost volume 路线,LRM 路线与主流大模型方法学的耦合更直接。它天然拥有 token 序列、统一 backbone、可扩展上下文、预训练/微调空间,以及与生成模型、语言模型、世界模型接口对齐的潜力。原始 LRM 已经证明,高容量 transformer + 大规模多视图数据,可以学习强泛化的重建先验;GS-LRM、Long-LRM 与 Long-LRM++ 则把这一点从单图 NeRF 进一步推进到 sparse-view 3DGS、scene-level reconstruction 与长序列输入。
6.3 对 wide-coverage reconstruction 更自然
cost volume 路线擅长显式局部几何,但它对 long-context scene reconstruction 的"语言"并不天然;而 LRM 路线的语言就是 sequence modeling,因此它面对多视角 coverage 扩展时更自然。Long-LRM 之所以重要,恰恰因为它把"整场景一次性 feed-forward reconstruction"从不现实变成了可讨论的问题;Long-LRM++ 则进一步表明,这一路线不只可以扩输入长度,还可以在 scene-level high-resolution reconstruction 上追求质量与效率的再平衡。
6.4 更有希望连接到多任务与空间基础模型
从前瞻性视角看,路线三最值得关注的,不是它现在是否已经终结了几何方法,而是它是否提供了一个足够统一的"空间学习接口"。如果未来要把 reconstruction、novel view synthesis、depth、editing、generation、semantic grounding、language-conditioned spatial reasoning 放到同一个模型族里,token-based、large-context、representation-decoding 这套句法显然比 task-specific cost volume 更容易扩展。这里我强调的是"更容易扩展",不是"已经解决"。因为几何正确性、可解释性与评测协议仍然是硬问题。
7. LRM 路线的代价:显式几何可解释性下降、训练资源上升
7.1 显式几何可解释性下降
与 cost volume / depth-first 方法相比,LRM 路线最大的问题之一,就是几何推理越来越隐含在 token mixing 中。MVSplat 可以相对直接地回答"中心为什么落在这个深度";DepthSplat 也仍然围绕 depth model 组织中间语义。相反,在 GS-LRM、Long-LRM 一类方法中,center localization 与 cross-view correspondence 更多被折叠进 hidden states,最后直接回归为 per-pixel Gaussians。你当然仍然可以可视化 attention 或特征,但那不等价于拥有一个明确的几何中间变量。
这就回答了本文第一个问题:token aggregation 与 explicit geometry 的边界在哪里? 我的判断是,边界不在于是否使用相机条件,也不在于是否输出高斯,而在于 中间推理变量是否仍保留了可直接解释的 metric geometry semantics。
若核心推理通过 C ( x , d ) C(x,d) C(x,d)、depth hypotheses、plane sweep、triangulation-like constraints 来组织,那么它更靠近 explicit geometry;若核心推理通过 T → Z → G ^ \mathcal T \rightarrow Z \rightarrow \hat{\mathcal G} T→Z→G^ 的隐藏状态变换来完成,那么它更靠近 token aggregation。GRM 站在边界上,因为它仍沿光线约束高斯;GS-LRM 与 Long-LRM 则进一步向 token-side 倾斜;Long-LRM++ 又通过 semi-explicit representation 部分把显式空间锚点拉回来。
7.2 训练与推理资源上升
路线三的第二个代价非常现实:token 数量、分辨率、序列长度都会迅速推高训练与推理成本。 Long-LRM 自己就给出最直接的证据:32 张 960×540、patch size 8 会形成约 250K token,哪怕采用 Mamba2,最高分辨率设置下纯 Mamba2 也会内存爆炸,因此必须上 token merging;而 per-pixel Gaussian decoding 又会带来约 1700 万个显式高斯,因此还必须做 Gaussian pruning。
这意味着,当模型规模上升时,问题越来越不像"设计一个模块",而更像"设计一个系统"。你要同时考虑 tokenizer、patch size、backbone mix、merge position、token width、Gaussian budget、rendering memory、training curriculum。Long-LRM++ 之所以把 hidden dimension 降到 768、去掉 token merging,同时改用 feature Gaussians,本质上也是在重新做系统预算,而不只是加一个更强 decoder。
7.3 长上下文并不自动保证局部细节
global context 有利于 scene coherence,这几乎没有疑问。但 local high-frequency structure 往往会在大范围聚合中被平均化、平滑化。Long-LRM++ 的整篇论文其实就是在证明这件事:Long-LRM 在 wide-coverage 上打开了新局面,但直接预测大量 color Gaussians 对微小误差过于敏感,从而在 text、thin structure、sharp edge 等 fine details 上容易出现 blur。
这也是我对路线三最重要的批判性判断之一:大上下文更像是"全局一致性增益器",而不是"细节保真正则项"。 这两件事没有天然等价关系。前者解决"信息是否被看见",后者解决"信息是否被保留并精确释放"。如果表示与解码不做改造,更多上下文反而可能把局部高频平均掉。Long-LRM++ 的 semi-explicit feature Gaussians + local-attention decoder,正是对这一矛盾的第一次系统回应。
7.4 大模型越大,越像系统设计而不是单模块设计
这是路线三最"企业级"的地方。真正的分歧不在于 backbone 是 transformer 还是 Mamba,而在于整套系统是否能在长上下文下同时维持:
- 一、可训练;
- 二、可推理;
- 三、可渲染;
- 四、可保真。
Long-LRM 用 token merging 与 Gaussian pruning 维持这四者的平衡;Long-LRM++ 用 semi-explicit representation 与 lightweight decoder 重新分配表示压力。它们都说明,scene-level large reconstruction model 的核心挑战已经从"单个 clever module"转向"token compression + representation budgeting + decoding strategy"的系统协同。
8. 它与 cost volume 路线是替代关系还是互补关系
8.1 不宜简单说"大模型取代几何方法"
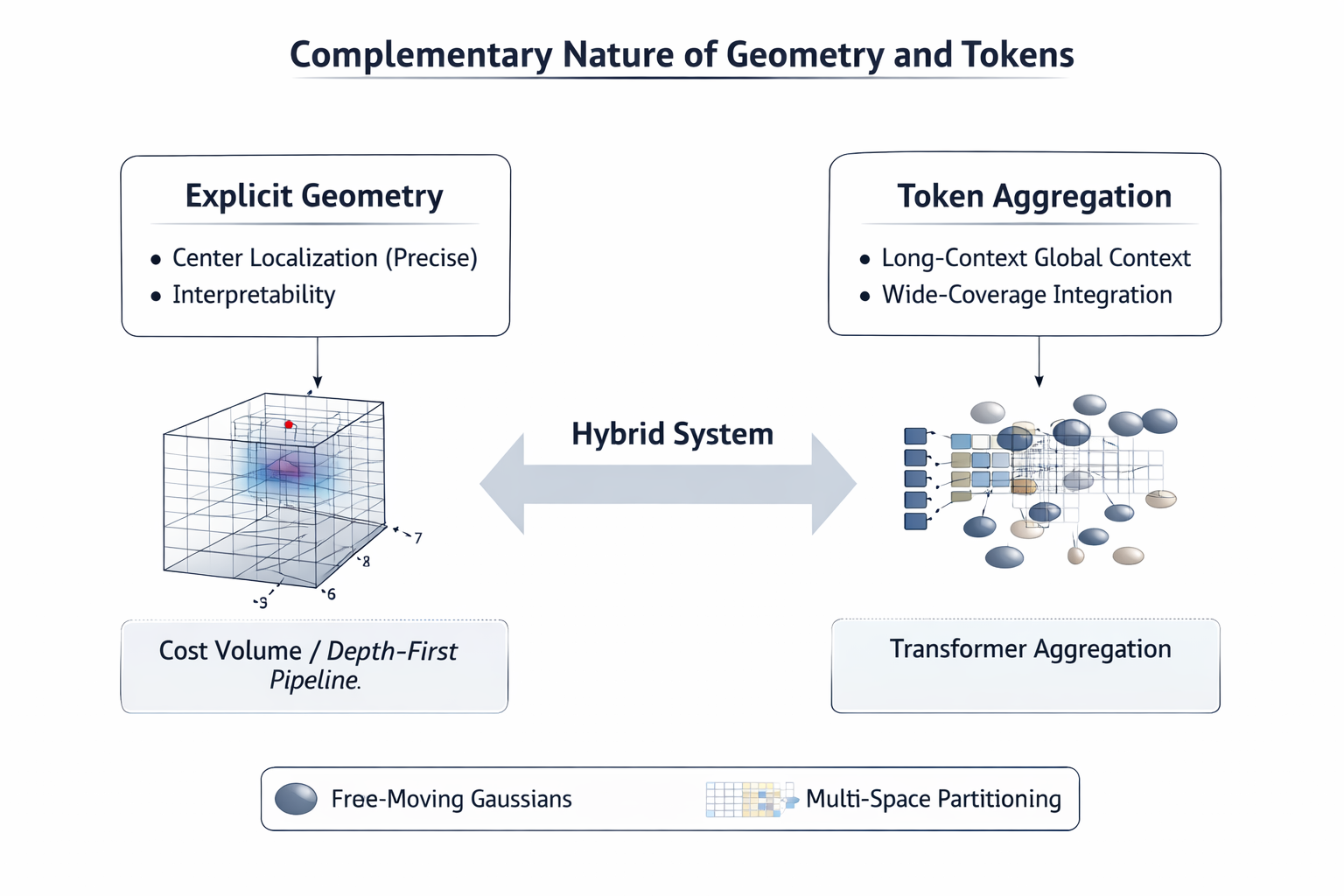
我不赞同把路线三理解为"最终会取代路线二"。这种说法过于线性。cost volume 路线的核心优势,是 显式几何归纳偏置 :中心定位、深度假设、几何一致性都更可解释,也更便于分析错误模式;LRM 路线的核心优势,则是 全局上下文聚合与统一表示学习:更容易吞下对象、场景、长序列、多任务与大规模训练。两者的强项并不完全重合。
8.2 二者的真正边界
如果用一组抽象公式对比,可以写为:
Geometry-first: d ^ , μ ^ ← arg max d C ( x , d ) , G ^ ← D attr ( μ ^ , ⋅ ) , (13) \text{Geometry-first: } \hat d,\hat \mu \leftarrow \arg\max_d C(x,d), \qquad \hat{\mathcal G} \leftarrow D_{\text{attr}}(\hat \mu, \cdot), \tag{13} Geometry-first: d^,μ^←argdmaxC(x,d),G^←Dattr(μ^,⋅),(13)
LRM-style: Z ← A θ ( T ) , G ^ ← D ϕ ( Z ) . (14) \text{LRM-style: } Z \leftarrow A_\theta(\mathcal T), \qquad \hat{\mathcal G} \leftarrow D_\phi(Z). \tag{14} LRM-style: Z←Aθ(T),G^←Dϕ(Z).(14)
前者先显式求解几何,再补全属性;后者先进行 global token aggregation,再统一解码几何与属性。真正的分歧不在于谁更"3D-aware",而在于三维结构是被组织成中间变量,还是被吸收到隐藏状态。 这也是为什么两条路线完全可能互补:cost volume 可以向 LRM 提供更强的 geometry prior,LRM 则可以为 cost volume 之外的长范围信息整合提供更强的 global context。
8.3 未来更可能是深度融合
事实上,Long-LRM++ 已经在某种意义上说明了这点:当纯显式 color Gaussian 不足以保持细节时,它选择的不是回到传统 cost volume,而是引入 semi-explicit representation,让显式空间结构与轻量隐式解码协作。这提示我们,未来真正强的方案,未必是"pure geometry-first"或"pure token aggregation",而可能是:
- 前端用更强的显式几何偏置稳定中心与结构;
- 中端用 global token aggregation 跨长序列吸收上下文;
- 后端用 semi-explicit / structured decoder 释放细节。
这类混合系统,很可能才是 scene-level feed-forward reconstruction 的长期方向。这个结论属于方法论推断,但与现有论文的演进方向是一致的。
9. 大重建模型是否会成为空间基础模型的入口
我认为,在现阶段所有前馈式 3DGS 路线中,路线三看起来最接近"空间基础模型入口"。理由并不神秘:第一,它有统一 token 接口;第二,它与大规模数据训练天然兼容;第三,它可以从对象扩到场景、从短序列扩到长序列;第四,它更容易与生成模型、语言模型、世界模型在接口层对齐。原始 LRM 已经展示了"高容量 transformer + 大规模多视图数据"可学习广泛重建先验;GS-LRM、Long-LRM、Long-LRM++ 则把这种能力继续推进到 3DGS、wide-coverage 与 detail-preserving scene reconstruction.
但大模型化并不会自动解决几何正确性、细节保持、评价协议与训练资源的问题。Long-LRM++ 的出现,本身就是一个提醒:即便 long-context 已经建立,fine-detail preservation 仍会成为瓶颈;即便 Gaussian 仍然显式存在,几何推理也可能因为被隐藏在 token mixing 中而降低可解释性;即便模型具备 scene-level reconstruction 能力,评测协议也未必足以刻画其几何可信度与资产可用性。空间基础模型不是"更大的 backbone",而是"更统一的空间表征、推理与评测体系"。 路线三现在只是看上去离入口最近,而不是已经抵达终点。
10. 结语
路线三让前馈式 3DGS 从"小规模泛化器"开始走向"场景级大重建模型",但也把细节保持与可解释性问题重新推到了前台。
这句话之所以重要,是因为它准确概括了路线三在整个研究地图中的历史定位。GRM 证明了 pixel-aligned Gaussian prediction 可以被纳入全局 transformer aggregation;GS-LRM 用极简而干净的方式,定义了"large reconstruction model for 3DGS"的基本句法;Long-LRM 则把问题推进到 long sequence、wide-coverage、scene-level reconstruction 的新 regime;Long-LRM++ 进一步指出,scene-level 大模型并不天然保证 fine details,因而必须引入 semi-explicit representation 与更精细的 decoder 设计。换句话说,路线三真正改变的不是"模型大小",而是 多视图几何与场景信息的组织方式:它越来越多地被吸收到 token sequence 的 global aggregation 中,而不是显式写死在 cost volume 里。
也正因为如此,路线三既是一次能力扩张,也是一次问题前移。它把前馈式 3DGS 推向了更统一、更大规模、更接近空间基础模型的话语体系;但与此同时,它也重新暴露了"几何如何解释""细节如何保持""预算如何管理"这些更深的问题。顺着这条逻辑继续走,下一篇路线四------Pose-Free / Uncalibrated / Foundation Geometry------就会成为自然延伸:当 token aggregation 已经强到一定程度,field 接下来要问的,便不再只是"如何聚合 posed views",而是"能否在更弱标定、更开放输入、更基础化的几何前提下,继续完成空间重建"。
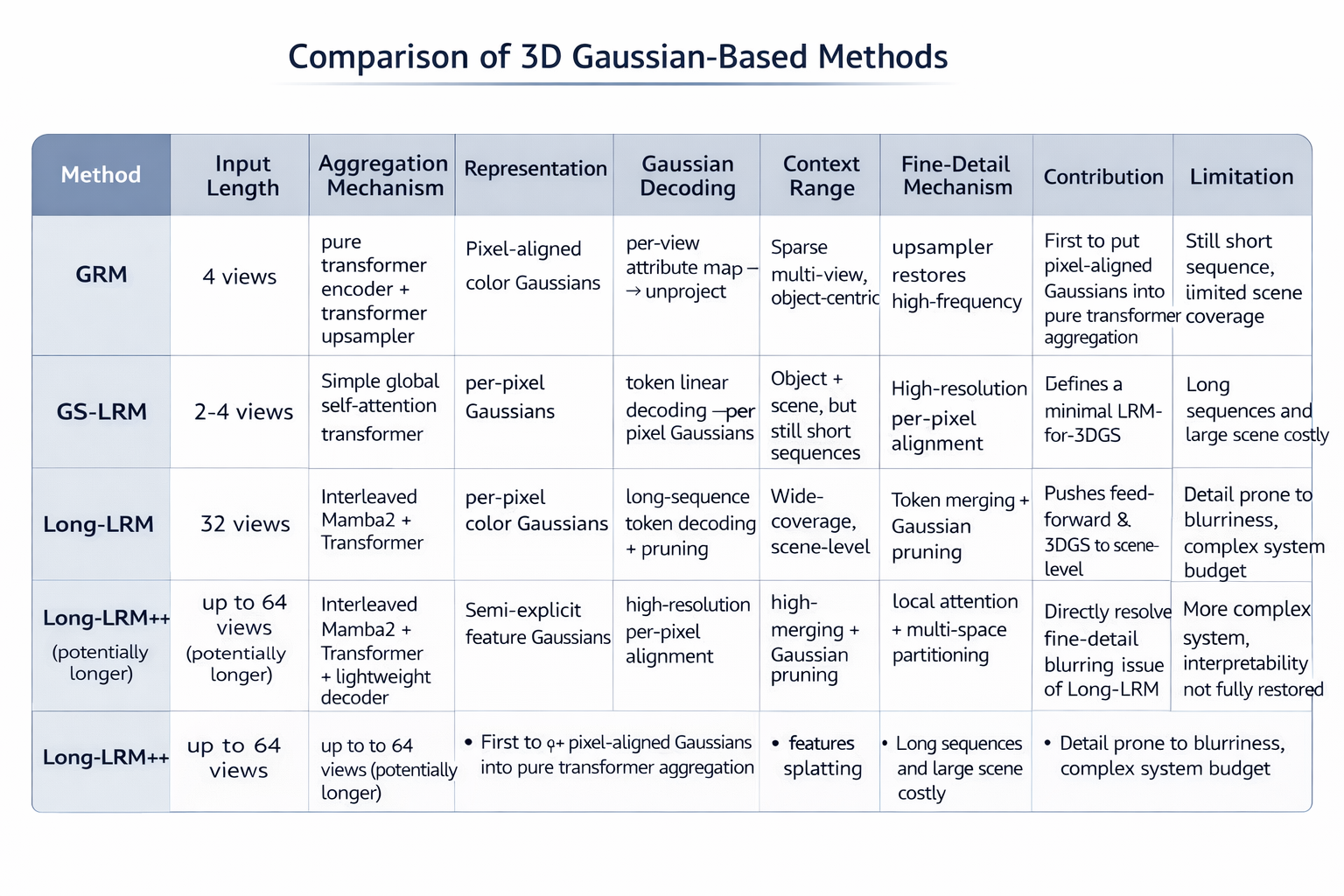
附:GRM / GS-LRM / Long-LRM / Long-LRM++ 统一对比
下表是对四篇主轴工作的结构化归纳,维度包括 input length、aggregation mechanism、representation、Gaussian decoding 方式、上下文范围、细节保持机制与主要局限。表中内容综合自四篇论文正文与摘要。
| 方法 | 输入长度 | aggregation mechanism | 表示形式 | Gaussian 解码方式 | 上下文范围 | 细节保持机制 | 主要贡献 | 主要局限 |
|---|---|---|---|---|---|---|---|---|
| GRM | 4 views | pure transformer encoder + transformer upsampler | pixel-aligned color Gaussians | per-view attribute map → unproject | sparse multi-view, object-centric | upsampler 恢复高频 | 首次把 pixel-aligned Gaussian 放进全局 transformer aggregation | 仍偏短序列,场景覆盖有限 |
| GS-LRM | 2--4 views | simple global self-attention transformer | per-pixel Gaussians | token 直接线性解码 per-pixel Gaussian | object + scene, 但仍短序列 | 高分辨率 per-pixel 对齐 | 定义极简 LRM-for-3DGS 范式 | 长序列与大场景预算压力大 |
| Long-LRM | 32 views | interleaved Mamba2 + Transformer | per-pixel color Gaussians | long-sequence token decoding + pruning | wide-coverage scene-level | token merging + Gaussian pruning | 把 feed-forward 3DGS 推进到场景级 long-context reconstruction | 细节容易变模糊,系统预算复杂 |
| Long-LRM++ | up to 64 views(部分设定更长) | interleaved Mamba2 + Transformer + lightweight decoder | semi-explicit feature Gaussians | feature splatting → decoder rendering | 高分辨率、wide-coverage、scene-level | local attention + multi-space partitioning | 正面解决 Long-LRM 的 fine-detail 模糊问题 | 系统更复杂,可解释性仍未完全回归 |
参考文献
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering :显式高斯表示与实时渲染的起点,也是所有 feed-forward 3DGS 路线试图摆脱"每场景优化"的基线背景。(arXiv)
- pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction :前馈式 Gaussian reconstruction 的早期关键工作,强调 pairwise 输入、3D 概率分布与可微 Gaussian mean sampling。(arXiv)
- MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images :路线二代表,明确以 plane-swept cost volume 提供几何线索,突出显式深度/中心定位。(arXiv)
- DepthSplat: Connecting Gaussian Splatting and Depth :路线二进一步强化版,把 Gaussian reconstruction 与单/多视图深度估计紧密连接。(arXiv)
- LRM: Large Reconstruction Model for Single Image to 3D :大重建模型前史,展示高容量 transformer + 大规模数据训练重建先验的可行性。(ICLR 会议录)
- GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation :路线三奠基工作之一,把全局 transformer aggregation 与 pixel-aligned Gaussian decoding 结合起来。(arXiv)
- GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting :用最简 transformer 句法定义 LRM-for-3DGS 的核心范式。(arXiv)
- Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats :把问题推进到 32-view、long-sequence、scene-level wide-coverage reconstruction。(arXiv)
- Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction :指出 long-context 之后的新主矛盾是 fine-detail preservation,并用 semi-explicit representation + lightweight decoder 给出修正方向。(arXiv)