Part II:前馈式 3DGS 的 depth-first 转向
- [0. 导言](#0. 导言)
-
- [0.1 路线二不是"把 depth 加进来",而是重新定义问题](#0.1 路线二不是“把 depth 加进来”,而是重新定义问题)
- [0.2 为什么路线二是路线一之后的自然下一步](#0.2 为什么路线二是路线一之后的自然下一步)
- [1. 为什么 pixel-aligned regression 会遇到几何瓶颈](#1. 为什么 pixel-aligned regression 会遇到几何瓶颈)
-
- [1.1 路线一的真正起点:从像素特征中"长出"高斯](#1.1 路线一的真正起点:从像素特征中“长出”高斯)
- [1.2 真正的瓶颈不在颜色,而在位置](#1.2 真正的瓶颈不在颜色,而在位置)
- [1.3 为什么局部 pixel-aligned 特征不足以稳定解决几何定位](#1.3 为什么局部 pixel-aligned 特征不足以稳定解决几何定位)
- [2. MVSplat:cost volume 如何进入 3DGS](#2. MVSplat:cost volume 如何进入 3DGS)
-
- [2.1 MVSplat 改写的不是模块,而是机制](#2.1 MVSplat 改写的不是模块,而是机制)
- [2.2 为什么 plane sweeping 天然适合 Gaussian mean localization](#2.2 为什么 plane sweeping 天然适合 Gaussian mean localization)
- [2.3 cost volume 与 token attention 的关系与区别是什么](#2.3 cost volume 与 token attention 的关系与区别是什么)
- [2.4 阶段性判断](#2.4 阶段性判断)
- [3. FreeSplat:长序列与低成本聚合为什么重要](#3. FreeSplat:长序列与低成本聚合为什么重要)
-
- [3.1 为什么长序列会改变问题性质](#3.1 为什么长序列会改变问题性质)
- [3.2 Low-cost Cross-View Aggregation 的真正作用](#3.2 Low-cost Cross-View Aggregation 的真正作用)
- [3.3 为什么 Gaussian redundancy / fusion 也是几何问题](#3.3 为什么 Gaussian redundancy / fusion 也是几何问题)
- [3.4 阶段性判断](#3.4 阶段性判断)
- [4. DepthSplat:高斯与深度之间的双向促进](#4. DepthSplat:高斯与深度之间的双向促进)
-
- [4.1 DepthSplat 的真正新意:它把两个任务写成互利关系](#4.1 DepthSplat 的真正新意:它把两个任务写成互利关系)
- [4.2 更强的 depth 如何促进更好的 Gaussian reconstruction](#4.2 更强的 depth 如何促进更好的 Gaussian reconstruction)
- [4.3 Gaussian splatting 如何反过来服务 depth learning](#4.3 Gaussian splatting 如何反过来服务 depth learning)
- [4.4 photometric supervision 是否足以支撑稳定 geometry](#4.4 photometric supervision 是否足以支撑稳定 geometry)
- [4.5 阶段性判断](#4.5 阶段性判断)
- [5. MonoSplat:foundation depth 为什么能增强泛化](#5. MonoSplat:foundation depth 为什么能增强泛化)
-
- [5.1 从任务内几何,走向外部世界先验](#5.1 从任务内几何,走向外部世界先验)
- [5.2 形式化理解:foundation prior 改变了什么](#5.2 形式化理解:foundation prior 改变了什么)
- [5.3 为什么 foundation depth 对 unfamiliar visual content 有帮助](#5.3 为什么 foundation depth 对 unfamiliar visual content 有帮助)
- [5.4 深度先验注入究竟是增益,还是新的耦合风险](#5.4 深度先验注入究竟是增益,还是新的耦合风险)
- [6. IDESplat:为什么还需要"迭代增强"深度概率](#6. IDESplat:为什么还需要“迭代增强”深度概率)
-
- [6.1 IDESplat 把主矛盾继续往前追了一层](#6.1 IDESplat 把主矛盾继续往前追了一层)
- [6.2 iterative depth probability boosting 的机制与意义](#6.2 iterative depth probability boosting 的机制与意义)
- [6.3 为什么"迭代增强"比单次 cost volume 更进一步](#6.3 为什么“迭代增强”比单次 cost volume 更进一步)
- [6.4 阶段性判断](#6.4 阶段性判断)
- [7. 这条路线的统一抽象:depth-first Gaussian prediction](#7. 这条路线的统一抽象:depth-first Gaussian prediction)
-
- [7.1 真正的共同点不是"都用了 cost volume"](#7.1 真正的共同点不是“都用了 cost volume”)
- [7.2 六个层面的统一理解](#7.2 六个层面的统一理解)
-
- [7.2.1 几何来源](#7.2.1 几何来源)
- [7.2.2 深度表征](#7.2.2 深度表征)
- [7.2.3 center localization](#7.2.3 center localization)
- [7.2.4 多视图融合](#7.2.4 多视图融合)
- [7.2.5 监督方式](#7.2.5 监督方式)
- [7.2.6 渲染闭环](#7.2.6 渲染闭环)
- [7.3 统一判断](#7.3 统一判断)
- [8. 这条路线的边界:复杂遮挡、尺度变化、输入扩展性](#8. 这条路线的边界:复杂遮挡、尺度变化、输入扩展性)
-
- [8.1 geometry-first 为什么比路线一强](#8.1 geometry-first 为什么比路线一强)
- [8.2 geometry-first 为什么仍然不够](#8.2 geometry-first 为什么仍然不够)
- [8.3 为什么它会自然导向路线三、四、五](#8.3 为什么它会自然导向路线三、四、五)
- [9. 为什么这条路线是 scene-level reconstruction 的主战场](#9. 为什么这条路线是 scene-level reconstruction 的主战场)
-
- [9.1 方法论层面:它最契合 posed multi-view reconstruction](#9.1 方法论层面:它最契合 posed multi-view reconstruction)
- [9.2 工程层面:它兼具可解释性、可部署性与可演进性](#9.2 工程层面:它兼具可解释性、可部署性与可演进性)
- [10. 结语](#10. 结语)
- 参考资料
系列文章全文导航(总览篇)
Part I:前馈式 3DGS 的起步范式:从像素到高斯
Part II:前馈式 3DGS 的 depth-first 转向
Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式
[Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合](#Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合)
[Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座](#Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座)
[Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS](#Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS)
0. 导言
0.1 路线二不是"把 depth 加进来",而是重新定义问题
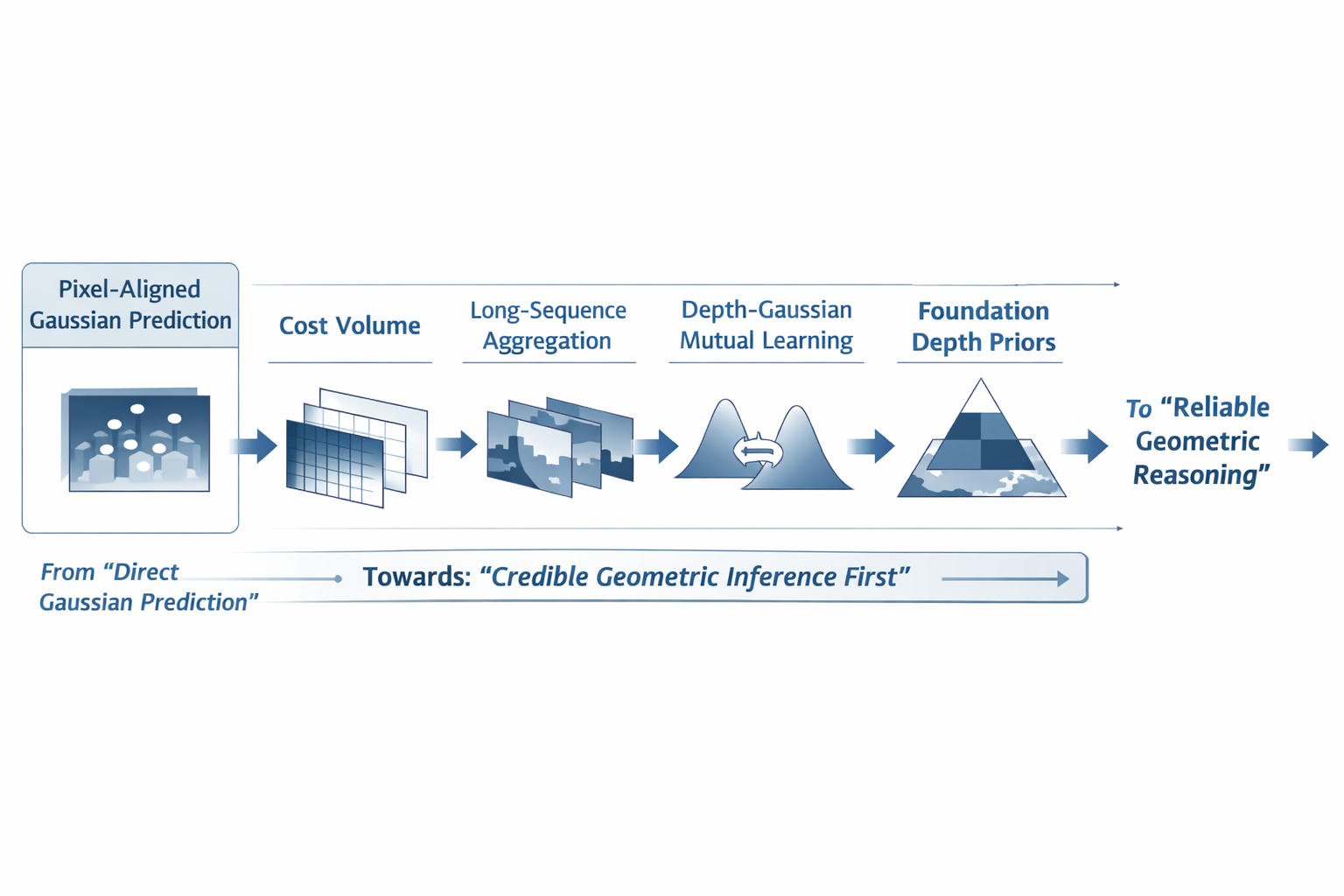
如果说路线一的历史作用,是让社区第一次接受"3D Gaussian 可以被前馈网络直接预测",那么路线二的历史作用,就是迫使这个方向承认一个更基本的事实:Gaussian mean localization 不是附属问题,而是整个 feed-forward 3DGS 的主矛盾之一。 从 MVSplat 到 FreeSplat,再到 DepthSplat、MonoSplat、IDESplat,这条线索并不是在堆叠模块,而是在持续把"预测高斯中心"重写为"估计深度/几何"。
MVSplat 明确以 plane sweeping cost volume 为中心来帮助 Gaussian center localization;FreeSplat 把 cost volume 与长序列场景扩展性联系起来;DepthSplat 把 Gaussian splatting 与 depth estimation 写成双向促进;MonoSplat 把 monocular depth foundation priors 注入 generalizable reconstruction;IDESplat 则进一步指出,单次 depth probability estimation 本身往往不够稳定、也不够精细。路线二因此不是一组同题不同解,而是一个问题被逐步写清楚的过程。
形式上,可将前馈式 3DGS 写成
G = G i i = 1 N , G i = ( μ i , Σ i , α i , c i , ψ i ) , (1) \mathcal{G}={G_i}_{i=1}^{N},\qquad G_i=(\mu_i,\Sigma_i,\alpha_i,c_i,\psi_i), \tag{1} G=Gii=1N,Gi=(μi,Σi,αi,ci,ψi),(1)
其中 μ i ∈ R 3 \mu_i\in\mathbb{R}^3 μi∈R3 为 Gaussian center, Σ i \Sigma_i Σi 为 3D 协方差, α i \alpha_i αi 为 opacity, c i c_i ci 与 ψ i \psi_i ψi 分别概括颜色与更高阶辐射属性。需要明确的是,在路线二的讨论框架下,真正决定重建是否可信的,不是 c i c_i ci 是否足够细腻,而是 μ i \mu_i μi 是否被稳定地放在了对的位置上。因为一旦中心放错,后续颜色、尺度、透明度都只能在错误几何上局部修补。工程上这意味着:几何先行不是风格偏好,而是错误传播链路上的刚性要求。
0.2 为什么路线二是路线一之后的自然下一步
路线一能成立,是因为 pixel-aligned 表征、概率采样与可微渲染足以让网络在少视图条件下学到一个可用的高斯表示;但路线一的问题也同样明显:它更像是"让系统能跑起来"的起步范式,而不是"让几何足够可信"的终态写法。MVSplat 在摘要中已经把重点放在"为准确定位 Gaussian centers 构建 cost volume";DepthSplat 则进一步强调,单靠传统多视图匹配仍会被遮挡、低纹理与反射表面拖住;MonoSplat 把 generalization 的问题追溯到训练分布与视觉先验不足;IDESplat 则把误差继续向前追溯到 depth probability 估计的不稳定与粗糙。
这说明路线二之所以自然出现,不是因为路线一失败,而是因为路线一解决的是可训练性 ,路线二要解决的是几何可信度。
更关键的是,理解路线二,实际上也是理解后续路线三、四、五的前提。因为无论是大重建模型、pose-free/unposed reconstruction,还是 structured latent / voxel-aligned 表征,本质上都绕不开同一个上游问题:输入图像中的 2D 证据,如何被组织成稳定的 3D spatial support。
路线二给出的答案最直接:把 Gaussian mean prediction 转写为 depth-first pipeline。后续路线即便改变网络容量、位姿假设或表示形态,也是在这个主矛盾之上继续推进。
1. 为什么 pixel-aligned regression 会遇到几何瓶颈
1.1 路线一的真正起点:从像素特征中"长出"高斯
pixelSplat 的代表性意义,是把 feed-forward reconstruction 写成"由输入图像对直接预测 3D Gaussian splats"的问题,并用对 3D probability distributions 的采样来缓解局部支持表示中的局部最优问题。这个范式之所以重要,不是因为它已经几何完备,而是因为它第一次证明:显式 3DGS 也可以脱离逐场景优化,进入 generalizable、前馈、可训练的框架。路线二的全部讨论,其实都要以这个起点为前史。
形式上,可把路线一的中心预测抽象为
p ( μ ∣ u , I , P ) , μ ∼ p ( ⋅ ) , (2) p(\mu\mid u,\mathcal{I},\mathcal{P}), \qquad \mu\sim p(\cdot), \tag{2} p(μ∣u,I,P),μ∼p(⋅),(2)
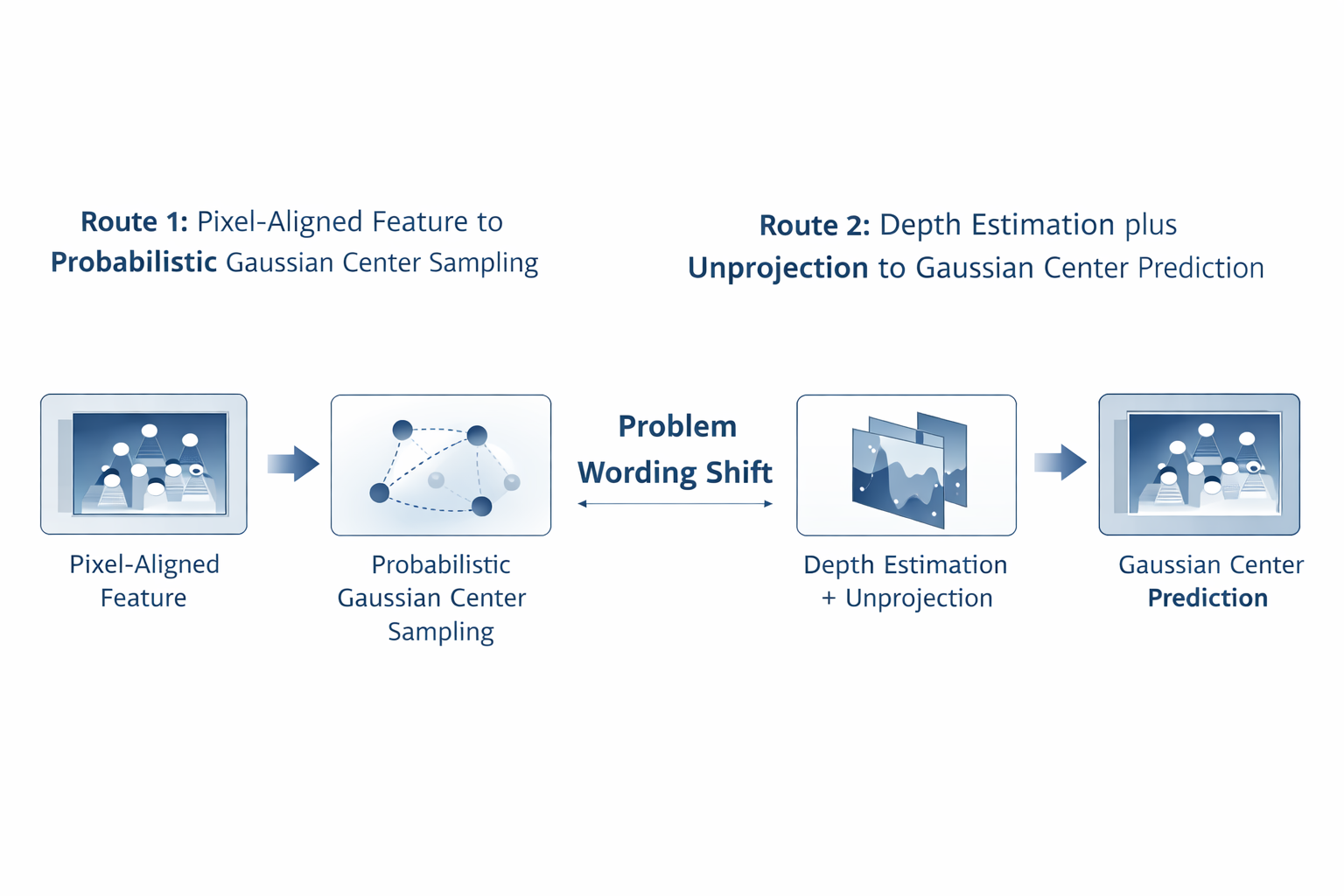
其中 u u u 是参考像素, I \mathcal{I} I 是输入图像集合, P \mathcal{P} P 是位姿集合。这个写法看似已经在处理 3D,但问题在于:如果 p ( μ ∣ ⋅ ) p(\mu\mid\cdot) p(μ∣⋅) 的主要支撑仍来自 pixel-aligned local features,那么这里的"3D"很大程度上只是输出空间是 3D,而不是推理机制本身具有足够强的多视图几何约束。换句话说,输出在三维,不等于推理是几何优先。 这也是后续 cost volume 会重新回来的根本原因。
1.2 真正的瓶颈不在颜色,而在位置
MVSplat 的核心表述非常值得注意:它并不是先强调外观更好,而是先强调"to accurately localize the Gaussian centers",为此构建 plane-sweeping cost volume。这个措辞本身就说明,问题的核心已经被重新定位。前馈式 3DGS 的难点,不是颜色是否足够丰富,也不是高斯半径是否足够平滑,而是中心是否落在了正确深度支撑上。一旦中心点漂移,rendering loss 可能仍然在局部上被优化得不错,但系统会通过"错位高斯 + 外观补偿"来掩盖几何错误。这样的模型能渲染,却未必能被称为更可信的重建。
可以把 Gaussian mean localization 写为
μ ( u ) = π − 1 ( u , d ( u ) ; K , T ) , (3) \mu(u)=\pi^{-1}(u,d(u);K,T), \tag{3} μ(u)=π−1(u,d(u);K,T),(3)
其中 π − 1 \pi^{-1} π−1 是由内参 K K K 与位姿 T T T 决定的反投影, d ( u ) d(u) d(u) 是像素 u u u 的深度。这个公式揭示了路线二最核心的逻辑变化:与其直接从像素特征回归 3D center,不如先把问题压缩为深度估计,再做几何反投影。因为对于已知位姿的 scene-level reconstruction,深度是连接 2D 观测与 3D 位置的最直接中间变量。 工程上这意味着,center localization 不再应该主要依赖隐式黑箱映射,而应依赖显式几何中间量。
1.3 为什么局部 pixel-aligned 特征不足以稳定解决几何定位
局部 pixel-aligned 特征的长处,是轻量、直接、容易与 2D backbone 对接;但它的短板同样结构性明显:遮挡场景下可见性不完整,低纹理区域匹配证据弱,镜面或重复纹理会产生歧义,宽视角时单视图局部证据更容易漂移。FreeSplat 的动机中直接把问题推进到 long sequence indoor scenes;DepthSplat 又指出传统 feature matching depth 在 occlusion、texture-less region、reflective surfaces 上会遇到典型困难;IDESplat 更进一步表明,即使接受"先估计 depth 再反投影"的路线,单次 warp 产生的 depth probability 仍可能不够稳。也就是说,路线一的问题并不是"没有几何",而是几何约束的组织强度仍然不足。
阶段性判断是:pixel-aligned regression 的瓶颈,本质上是几何证据的稀疏组织与弱约束问题。它更像"像素先行、几何隐含"的路线;而路线二要做的是把它改写成"几何先行、高斯随后"的 depth-first pipeline。
2. MVSplat:cost volume 如何进入 3DGS
2.1 MVSplat 改写的不是模块,而是机制
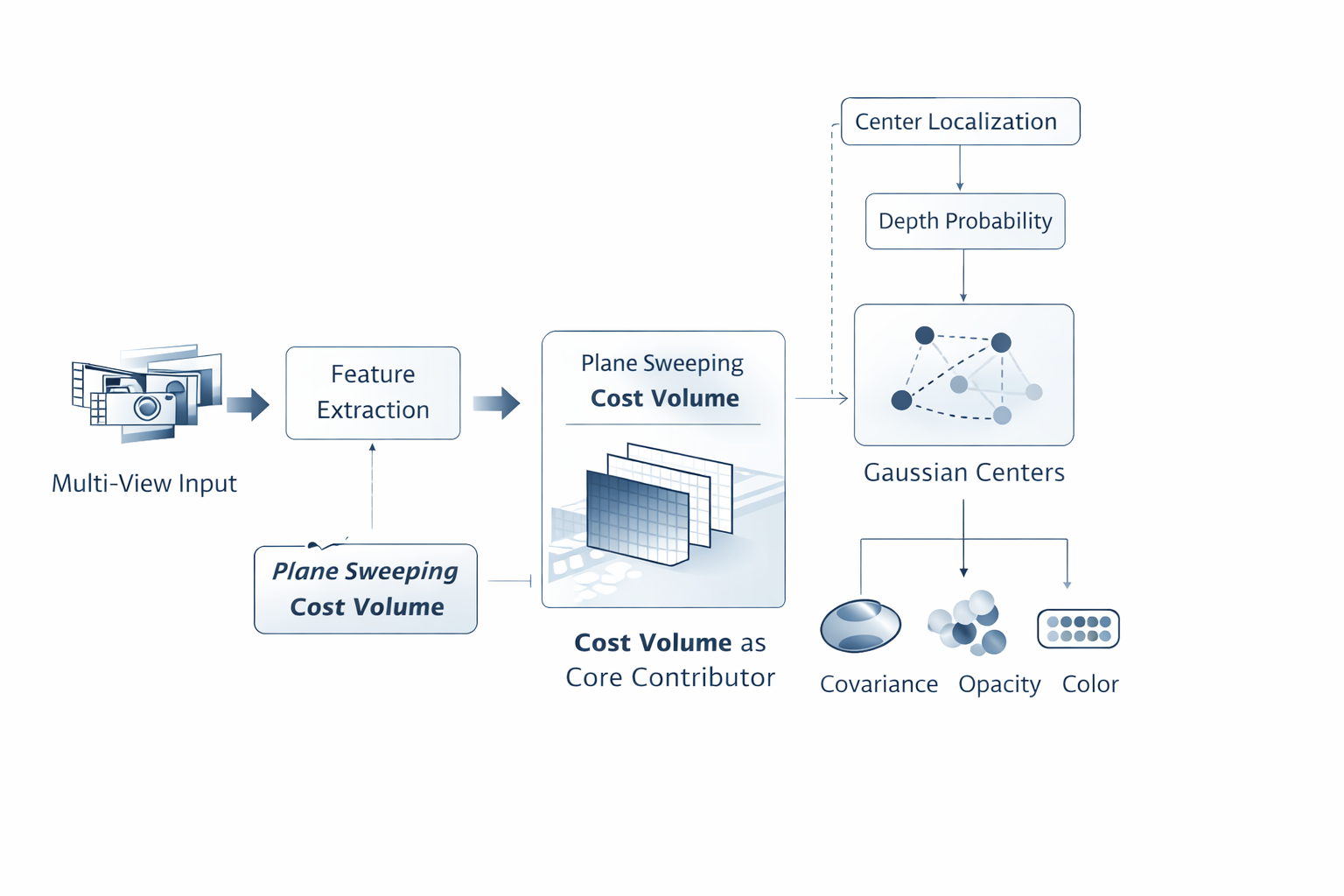
MVSplat 的突破性不在于"引入了一个 cost volume",而在于它改变了 Gaussian center prediction 的基本机制。论文摘要明确表示,模型通过 plane sweeping 构建 cost volume,其中 cross-view feature similarities 为 depth estimation 提供 geometry cues,再与其他 Gaussian 参数联合学习,而且主要依赖 photometric supervision。这个表述的重要性在于:Gaussian center 不再主要由局部 2D 特征直接猜,而是由一个显式的多视图深度假设空间来约束。 这不是局部修补,而是问题写法本身的改变。
形式上,可把其 cost volume 写为
C v ( u , k ) = Agg ∗ j ≠ v ϕ ! ( f v ( u ) , W ∗ j → v ( d k ) ( f j ) ) , (4) C_v(u,k)= \operatorname{Agg}*{j\neq v} \phi!\Big( f_v(u),\mathcal{W}*{j\rightarrow v}^{(d_k)}(f_j) \Big), \tag{4} Cv(u,k)=Agg∗j=vϕ!(fv(u),W∗j→v(dk)(fj)),(4)
其中 C v ( u , k ) C_v(u,k) Cv(u,k) 表示视图 v v v 的像素 u u u 在深度候选 d k d_k dk 上的匹配代价或相似性, f v f_v fv 是图像特征, W j → v ( d k ) \mathcal{W}_{j\rightarrow v}^{(d_k)} Wj→v(dk) 表示在深度假设 d k d_k dk 下将其他视图特征 warp 到当前视图, Agg \operatorname{Agg} Agg 是跨视图聚合算子, ϕ \phi ϕ 是相似性函数。这个表达式的工程意义非常明确:系统不再只问"这个像素长什么样",而是在问"它在不同深度候选上,与其他视图是否一致"。这就是 geometry-first 的第一块硬骨架。
2.2 为什么 plane sweeping 天然适合 Gaussian mean localization
plane sweeping 的价值,在于它把"3D 点应该落在哪个深度支撑上"转换成一个显式候选比较问题。对传统 MVS 来说,最终目标通常是 depth map 或 point cloud;而在 MVSplat 中,depth 并不是终点,而是 Gaussian center localization 的中间支架。
也就是说,plane sweeping 在这里不是机械复用传统 MVS,而是为 Gaussian prediction 服务。它的真正作用,是把 center localization 从"黑箱回归 3D 点"转写为"在一组离散深度假设中寻找最可信支撑,再做反投影"。
可写为
p v ( u , k ) = softmax ( − C v ( u , k ) ) , d v ( u ) = ∑ k p v ( u , k ) , d k , (5) p_v(u,k)=\operatorname{softmax}\big(-C_v(u,k)\big), \qquad d_v(u)=\sum_k p_v(u,k),d_k, \tag{5} pv(u,k)=softmax(−Cv(u,k)),dv(u)=k∑pv(u,k),dk,(5)
再由式 (3) \text{(3)} (3) 得到 μ ( u ) \mu(u) μ(u)。这里 p v ( u , k ) p_v(u,k) pv(u,k) 是 depth probability distribution, d v ( u ) d_v(u) dv(u) 是期望意义下的深度估计。需要强调的是,这一变化的历史作用不是"精度更高"四个字,而是它第一次让社区在方法层面真正承认:Gaussian mean prediction 正在变成 depth estimation 问题。
2.3 cost volume 与 token attention 的关系与区别是什么
这是路线二必须讲透的第一个学术问题。两者都能做 cross-view aggregation,但它们回答的问题并不一样。token attention 更擅长表达"哪些特征彼此相关",cost volume 更擅长表达"在什么几何假设下这些特征最一致"。
前者是 feature-space relation modeling,后者是 geometry-hypothesis evaluation。attention 的优势是灵活、表达能力强、易于全局建模;但如果不绑定显式几何假设,它形成的对应关系不一定具有明确的 3D 可解释性。cost volume 则把跨视图比较压到一组深度候选上,因此天然对应"哪个深度更可信"这一问题。
MVSplat 同样使用 Transformer 与 cross-view attention,但其几何主干仍然是 plane-sweeping cost volume,而不是仅靠 attention 自发学出几何。
因此,真正的分歧不在于"是不是用了 Transformer",而在于几何推理是否围绕显式深度假设组织。这也解释了为什么路线二并不排斥 attention,而是把它降级为几何主干之外的增强器。换句话说,在已知位姿、多视图 scene reconstruction 这个问题域中,attention 可以丰富表征,但很难完全替代显式 geometry hypotheses。
2.4 阶段性判断
MVSplat 是路线二真正意义上的奠基工作之一,因为它第一次清晰地把前馈式高斯中心预测写成了"cost volume + depth estimation + unprojection"这一链路。它让路线二从"有一点几何"变成了"以几何为主干"。
3. FreeSplat:长序列与低成本聚合为什么重要
3.1 为什么长序列会改变问题性质
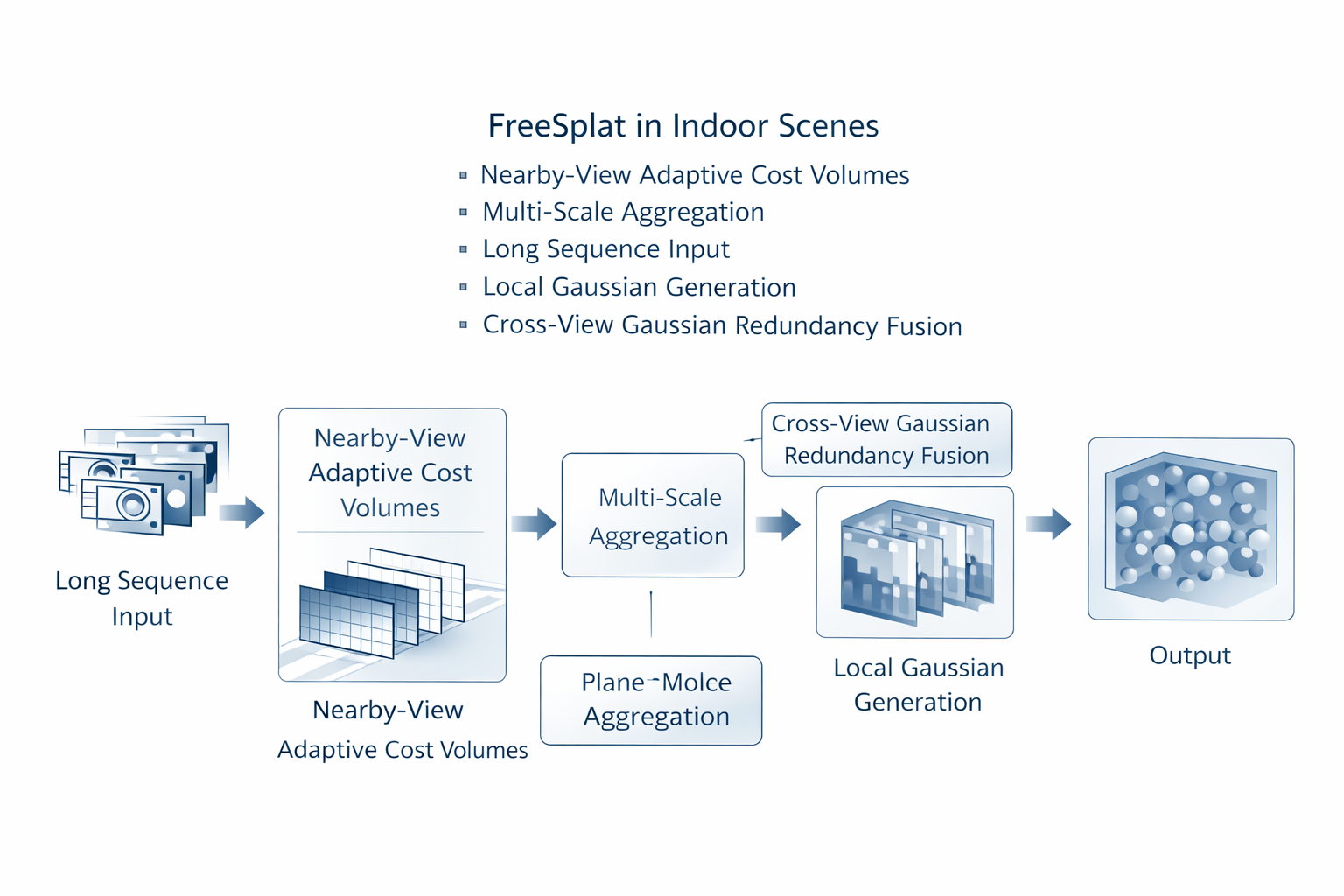
FreeSplat 的动机非常清楚:已有 generalizable 3DGS 往往受限于 narrow-range interpolation 与较重 backbone,而室内长序列 free-view synthesis 需要的是在更宽范围输入上保持几何一致性。
它提出 Low-cost Cross-View Aggregation,通过 nearby views 上的 adaptive cost volumes 与 multi-scale 结构做特征聚合,并引入 Pixel-wise Triplet Fusion 来处理 overlapping regions 中的 Gaussian redundancy。这里的关键点不是"更轻"或"更省",而是问题从少视角局部推理,升级为长序列场景级融合。
长序列会改变问题性质,因为输入不再只是多几张图,而是带来了三类新的系统性压力:第一,跨视图冗余会迅速累积;第二,局部遮挡与可见性关系在长链路中不断切换;第三,同一结构可能在不同时间或不同局部片段中被重复生成。于是 geometry-first 若想变成工程主线,就不能只会在小视角数上估 depth,还必须会在更长图像链条上做局部几何证据的累积、筛选与融合。这是 FreeSplat 的结构性意义。
3.2 Low-cost Cross-View Aggregation 的真正作用
FreeSplat 可抽象为
C v local ( u , k ) = Agg ∗ j ∈ N ( v ) ϕ ! ( f v ( u ) , W ∗ j → v ( d k ) ( f j ) ) , (6) C_v^{\text{local}}(u,k)= \operatorname{Agg}*{j\in\mathcal{N}(v)} \phi!\Big( f_v(u),\mathcal{W}*{j\rightarrow v}^{(d_k)}(f_j) \Big), \tag{6} Cvlocal(u,k)=Agg∗j∈N(v)ϕ!(fv(u),W∗j→v(dk)(fj)),(6)
其中 N ( v ) \mathcal{N}(v) N(v) 不是全局所有视图,而是与视图 v v v 邻近的一组视图。这个变化看似局部,实际上极其关键:系统不再追求一次构建巨大的全局 cost volume,而是采用局部化、层次化的几何聚合。工程上这意味着,geometry-first 要真正走向 scene-level reconstruction,必须同时考虑几何质量 与扩展性成本。FreeSplat 的"low-cost"不是简单的工程优化,而是场景规模变化后对问题重写的必然结果。
3.3 为什么 Gaussian redundancy / fusion 也是几何问题
FreeSplat 的项目说明明确指出,Pixel-wise Triplet Fusion 用于融合多视图 3D Gaussians,移除冗余项,并在 Gaussian localization 上提供 point-level latent fusion 与 regularization。这里最容易被低估的一点是:高斯去冗余不是后处理问题,而是几何一致性问题。 当同一空间结构从多个视图分别"长出"高斯时,如果缺少稳定的融合机制,系统会得到大量 overlapping、漂浮或局部错位的高斯,这不仅增加渲染负担,更会破坏几何解释性。
可以把这一过程写为
G ~ m = Fuse ( G i i ∈ Ω m ) , (7) \tilde{G}{m}= \operatorname{Fuse}\big({G_i}{i\in\Omega_m}\big), \tag{7} G~m=Fuse(Gii∈Ωm),(7)
其中 Ω m \Omega_m Ωm 表示属于同一潜在结构支撑的一组高斯, Fuse \operatorname{Fuse} Fuse 表示在 latent 或 primitive 空间中的融合算子。符号本身很简单,但其工程含义非常深:geometry-first 路线不仅要会"从深度中生长高斯",还必须会"把跨视图重复生长出的高斯重新压回一致结构"。这也是为什么 FreeSplat 在路线二中的位置并不只是"更省的 MVSplat",而是把路线二从局部多视图深度推进到了场景级几何组织。
3.4 阶段性判断
FreeSplat 证明了一件很重要的事:geometry-first 如果只在小规模输入上成立,还不能算真正的 scene-level 路线;它必须能在长序列与室内全场景条件下处理扩展性、冗余与融合。FreeSplat 将路线二正式推向了"场景级几何组织"这一更强命题。
4. DepthSplat:高斯与深度之间的双向促进
4.1 DepthSplat 的真正新意:它把两个任务写成互利关系
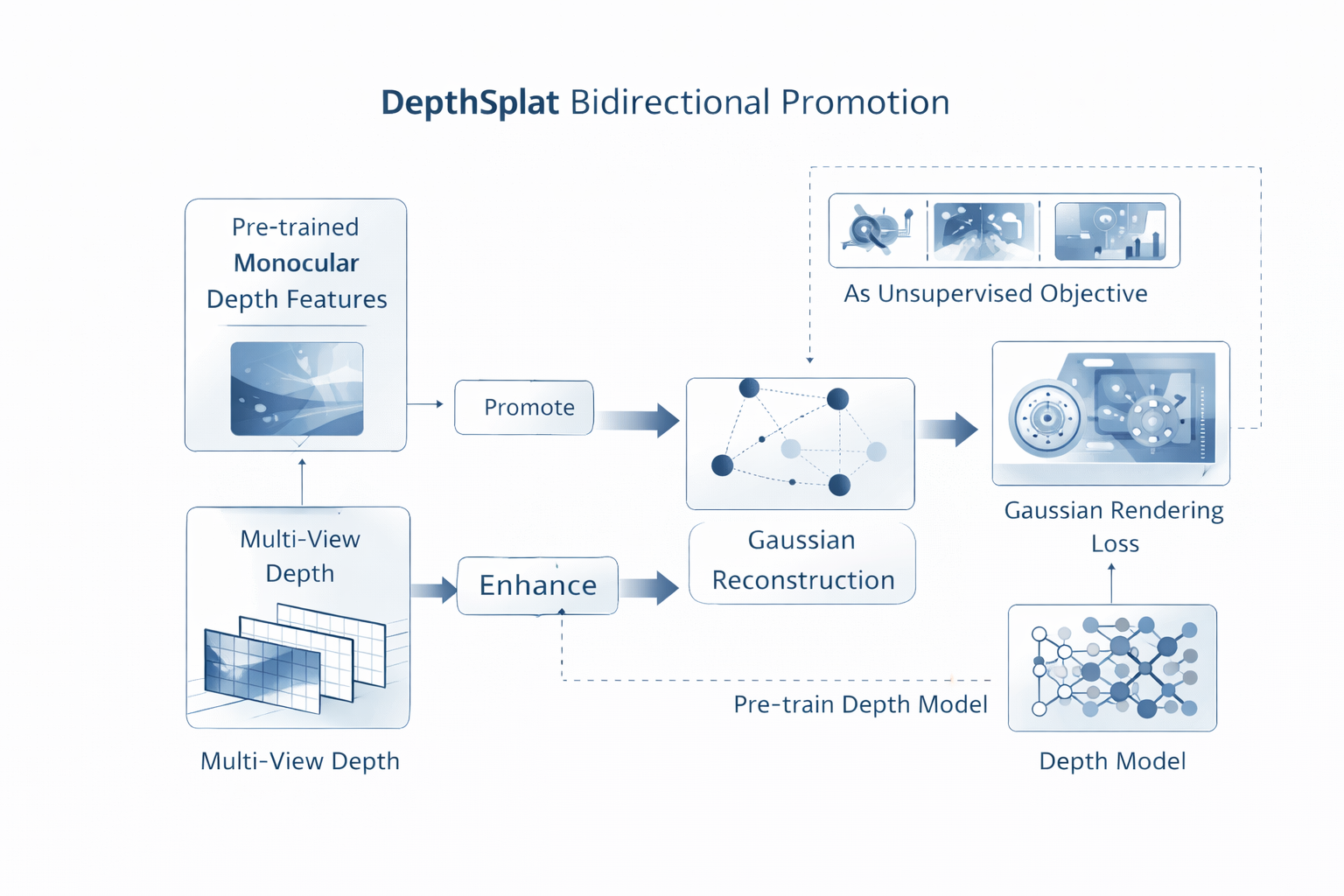
DepthSplat 的标题已经说明其立场:Connecting Gaussian Splatting and Depth。论文明确指出,Gaussian splatting 与单/多视图 depth estimation 通常被分开研究,而它的目标是研究二者之间的互动关系:一方面,利用预训练 monocular depth features 构建更稳健的 multi-view depth model,从而提升 feed-forward 3DGS reconstruction;另一方面,Gaussian splatting 也可以作为无监督预训练目标,帮助学到更强的 depth features。这个结构与前面的工作不同,因为它不再只是"借 depth 帮高斯",而是把两个任务写成了一个双向闭环。
这一步的理论意义很大。路线二此前主要还停留在"深度作为高斯中心的中间变量"这一层面;而到了 DepthSplat,问题被提升为:depth estimation 与 Gaussian reconstruction 能否互相作为对方的训练资源与结构约束。 这意味着路线二开始从方法工程上升到任务耦合层面。
4.2 更强的 depth 如何促进更好的 Gaussian reconstruction
DepthSplat 的核心链路可写为
d = D mv ( C mvs , F mono ) , μ = π − 1 ( u , d ; K , T ) , θ rest = H ( F ) , (8) d= D_{\text{mv}}\big(C_{\text{mvs}},F_{\text{mono}}\big), \qquad \mu= \pi^{-1}(u,d;K,T), \qquad \theta_{\text{rest}}=H(F), \tag{8} d=Dmv(Cmvs,Fmono),μ=π−1(u,d;K,T),θrest=H(F),(8)
其中 C mvs C_{\text{mvs}} Cmvs 表示多视图匹配/几何证据, F mono F_{\text{mono}} Fmono 表示来自预训练 monocular depth 模型的特征, D mv D_{\text{mv}} Dmv 是 depth estimator, H H H 是其余 Gaussian 参数预测头。其关键不在于网络结构细节,而在于它正面承认:更强的 depth model 会直接抬升 feed-forward Gaussian reconstruction 的上限。 这等于把前馈式 3DGS 的性能上界与 depth representation 的质量绑定了起来。
这也是路线二中极具历史意义的一步。此前人们可能仍会把 3DGS 看作一个主要由渲染驱动的显式表示学习问题;但 DepthSplat 清楚表明,在 generalizable、scene-level、posed multi-view 设定下,3DGS 的前馈性能,实质上已经越来越取决于 depth branch 能否提供强而稳的几何支撑。换句话说,3DGS 不再只是图形表示问题,它同时也是深度学习问题。
4.3 Gaussian splatting 如何反过来服务 depth learning
DepthSplat 另一项关键贡献,是展示 Gaussian splatting 可以作为 unsupervised pre-training objective 来帮助 depth learning。也就是说,novel-view rendering 的 photometric closure 不只是输出端的图像监督,它本身还能反过来塑造 depth feature。这个思想非常值得重视,因为它把 3DGS 渲染闭环从"评估与训练信号"提升为"上游几何表征的塑形器"。
可将其写为
L = λ rgb L ∗ render + λ ∗ depth L ∗ depth , (9) \mathcal{L}= \lambda_{\text{rgb}}\mathcal{L}*{\text{render}} + \lambda*{\text{depth}}\mathcal{L}*{\text{depth}}, \tag{9} L=λrgbL∗render+λ∗depthL∗depth,(9)
其中 L ∗ render \mathcal{L}*{\text{render}} L∗render 是 novel-view photometric supervision, L ∗ depth \mathcal{L}*{\text{depth}} L∗depth 是显式或隐式 depth supervision。需要强调的是,哪怕没有强 depth GT, L ∗ render \mathcal{L}*{\text{render}} L∗render 也能成为 depth branch 的有效自监督资源。工程上这意味着,前馈式 3DGS 不只是消费几何先验,它也能生产几何学习信号。
4.4 photometric supervision 是否足以支撑稳定 geometry
这是第二个必须深挖的学术问题。我的判断是:photometric supervision 必不可少,但通常不足以单独支撑稳定 geometry。 MVSplat 证明了仅依赖 photometric supervision 也能学到有效的 feed-forward Gaussians;但 DepthSplat 的动机恰恰说明,在 occlusion、texture-less regions、reflective surfaces 等典型几何难点下,仅靠渲染误差难以为系统提供唯一、稳定的几何答案。
因为 photometric consistency 约束的是"当前表示渲染出去是否像目标图像",而不是"当前表示是否对应唯一真实的三维结构"。当存在重复纹理、镜面反射、视差不足或薄结构时,这种监督很容易留下 geometry ambiguity。
因此,路线二并没有放弃 photometric supervision,而是重新定位了它的角色:它从"唯一监督源"变成了"闭环一致性监督的一部分"。真正更稳妥的做法,是把 photometric closure 与 depth branch、cost volume、foundation priors、iterative refinement 结合起来,让渲染一致性与几何一致性共同约束 center localization。这个判断也恰恰解释了为什么路线二会自然生长出 MonoSplat 与 IDESplat。
4.5 阶段性判断
DepthSplat 是路线二中最有"理论统一感"的工作之一。它真正完成的,不只是性能增强,而是把"借几何提升高斯"和"借高斯反哺几何"写成了同一个闭环系统。路线二因此不再只是几何模块增强,而是任务级双向耦合。
5. MonoSplat:foundation depth 为什么能增强泛化
5.1 从任务内几何,走向外部世界先验
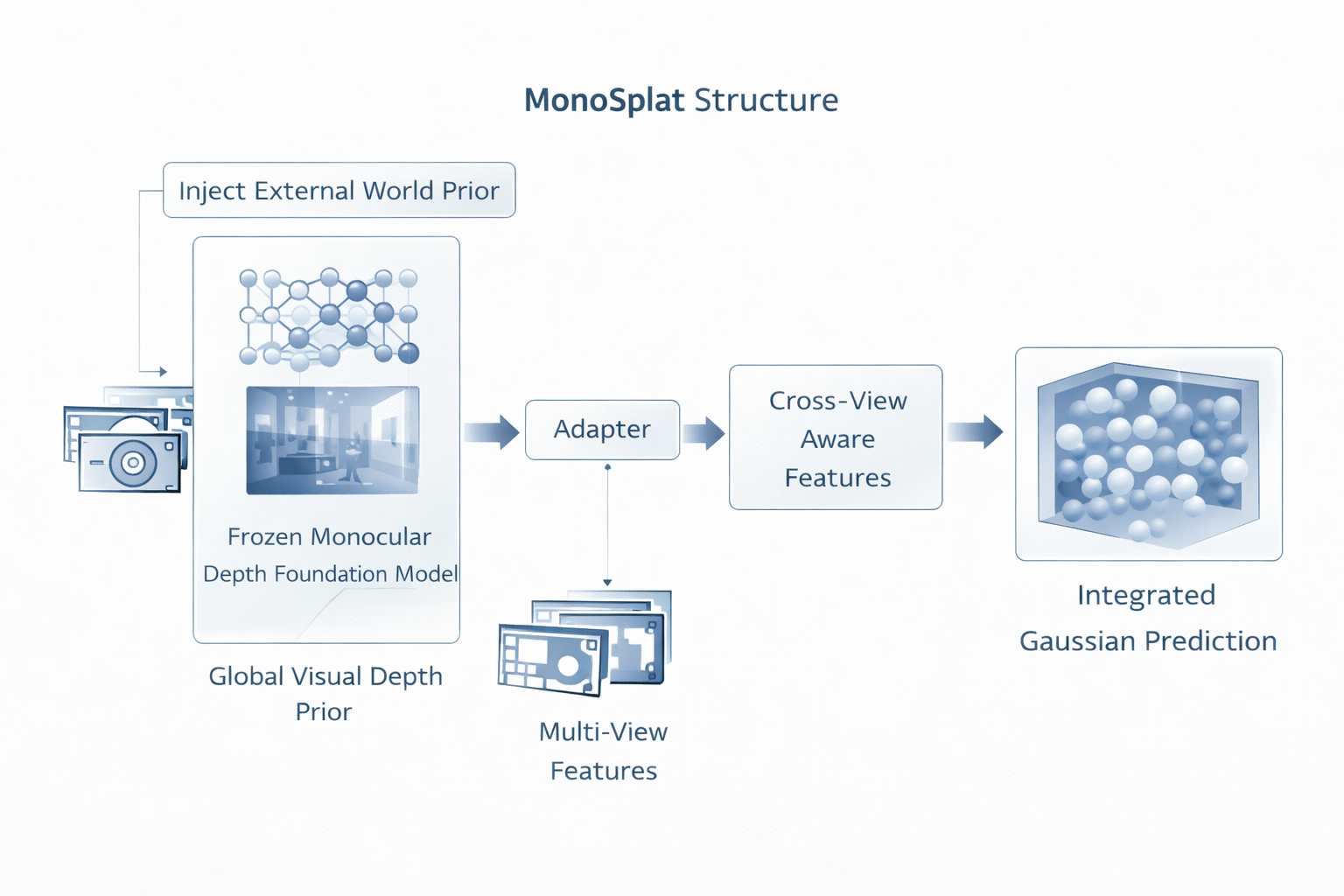
MonoSplat 的核心动机是 generalizability。论文指出,现有 generalizable 3DGS 在 novel scenes 上仍难以处理 unfamiliar visual content,因此引入 pre-trained monocular depth foundation models 的 rich visual priors,并通过 Mono-Multi Feature Adapter 将 monocular features 转换为 multi-view Gaussian reconstruction 可用的表征,最后用 Integrated Gaussian Prediction 生成 Gaussian primitives。它的重要性在于:geometry-first 开始不再只依赖任务内学到的几何,而是主动借用外部大规模世界先验。
MVSplat 与 FreeSplat 主要在多视图几何链路内部寻找更优组织方式,DepthSplat 则开始把 monocular depth features 与 multi-view depth 结合起来;而 MonoSplat 则更进一步,直接以 monocular depth foundation model 为表征底座。这意味着路线二已经不满足于"更强的几何模块",而是开始向"几何模块 + foundation prior"迁移。
5.2 形式化理解:foundation prior 改变了什么
MonoSplat 可抽象为
F mono = E fdm ( I ) , F mv = A ( F mono , I , P ) , G = P ( F mono , F mv ) , (10) F_{\text{mono}}=E_{\text{fdm}}(I), \qquad F_{\text{mv}}=A(F_{\text{mono}},I,\mathcal{P}), \qquad \mathcal{G}=P(F_{\text{mono}},F_{\text{mv}}), \tag{10} Fmono=Efdm(I),Fmv=A(Fmono,I,P),G=P(Fmono,Fmv),(10)
其中 E fdm E_{\text{fdm}} Efdm 是 monocular depth foundation model, A A A 是 Mono-Multi Feature Adapter, P P P 是 Gaussian prediction module。这个公式的重点不在于变量数,而在于系统的信息来源被根本扩展了:Gaussian prediction 不再只消费当前多视图样本中的几何证据,而是同时消费了来自大规模预训练的世界先验。工程上这意味着,模型在陌生内容上的初始几何判断,不再完全取决于当前训练集内的局部统计规律。
5.3 为什么 foundation depth 对 unfamiliar visual content 有帮助
foundation depth 的价值,不是它在任何数据集上都"绝对更准",而是它往往学习到了更广泛的视觉结构偏置:室内外布局、物体边界、透视关系、遮挡模式、地平面与墙面等宏观几何线索。当 novel scene 的局部多视图证据还不够稳定时,这类先验能提供更合理的初始几何倾向,从而帮助 Gaussian center localization 跨过弱纹理、局部歧义和分布外内容的初始不确定性。MonoSplat 因此不是简单"加点知识",而是在改变训练与泛化的底座。
5.4 深度先验注入究竟是增益,还是新的耦合风险
这是第三个问题。我的判断是:在 posed scene-level reconstruction 中,foundation depth priors 首先是净增益,但前提是它们不能脱离 multi-view consistency 单独成为几何裁判。 一旦系统过度依赖单目 foundation prior,而缺少足够强的跨视图校正,就会出现尺度偏置、布局偏置、对透明/反射介质的系统性误判等 domain bias。MonoSplat 的合理之处,正在于它并没有试图用单目模型替代多视图几何,而是通过 adapter 把 foundation features 转译成可被 multi-view reconstruction 消化的中间表示。换句话说,先验应当是几何主干的增益器,而不是替代者。
MonoSplat 标志着路线二进入一个更成熟的阶段------geometry-first 不再只是"更强的任务内几何推理",而开始成为"多视图几何 + foundation world prior"的复合系统。
6. IDESplat:为什么还需要"迭代增强"深度概率
6.1 IDESplat 把主矛盾继续往前追了一层
IDESplat 的摘要把路线二的核心矛盾说透了:在 generalizable 3DGS 中,Gaussian means 特别难预测,因此通常先估计 depth 再反投影;但现有方法通常只依赖 single warp 来估计 depth probability,这会妨碍系统充分利用 cross-view geometric cues,导致 depth maps 不稳定且粗糙。这个判断非常关键,因为它意味着到 2026 年,field 已经不再争论"需不需要 depth",而是在争论depth probability estimation 是否足够稳定、足够精细。
换句话说,MVSplat 解决了"显式几何假设要回来",MonoSplat 解决了"外部深度先验可以增强泛化",而 IDESplat 继续追问:即使接受了 depth-first 写法,单轮几何推理本身是不是还太粗糙。 这说明路线二真正的演化方向,不是"往网络里继续加模块",而是不断细化 depth reasoning 的稳定性与分辨率。
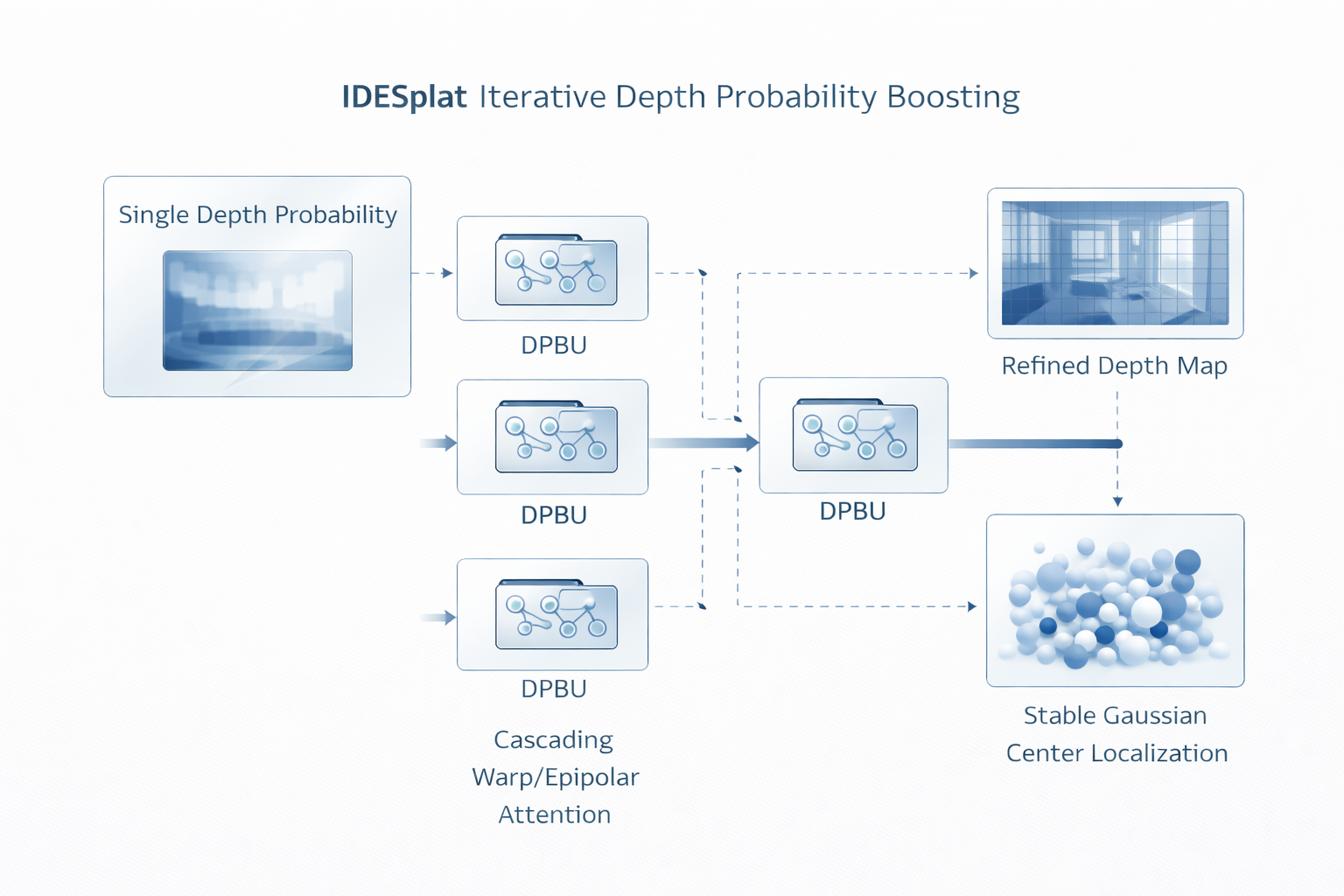
6.2 iterative depth probability boosting 的机制与意义
IDESplat 引入 Depth Probability Boosting Unit(DPBU),通过级联 warp operations 形成 epipolar attention maps,并以乘性方式进行整合;多个 DPBU 叠加形成 iterative depth estimation process,逐步识别更有可能的 depth candidates,并随着候选更新持续细化 depth map。其核心不是"多跑几轮",而是承认深度概率本身也需要一个被反复 sharpen 的过程。
形式上,可写为
p ( t + 1 ) ( u , k ) ∝ p ( t ) ( u , k ) ⋅ ψ ( t ) ( u , k ) , (11) p^{(t+1)}(u,k) \propto p^{(t)}(u,k)\cdot \psi^{(t)}(u,k), \tag{11} p(t+1)(u,k)∝p(t)(u,k)⋅ψ(t)(u,k),(11)
d ( t + 1 ) ( u ) = ∑ k p ( t + 1 ) ( u , k ) , d k ( t + 1 ) , (12) d^{(t+1)}(u)=\sum_k p^{(t+1)}(u,k),d_k^{(t+1)}, \tag{12} d(t+1)(u)=k∑p(t+1)(u,k),dk(t+1),(12)
其中 p ( t ) ( u , k ) p^{(t)}(u,k) p(t)(u,k) 是第 t t t 轮深度概率分布, ψ ( t ) \psi^{(t)} ψ(t) 是由级联 warp / epipolar attention 产生的 boosting 信号, d k ( t + 1 ) d_k^{(t+1)} dk(t+1) 是更新后的候选深度。这个写法的工程含义非常明确:Gaussian mean localization 不再被视为一次性分类/回归,而是一个候选空间逐步收缩、概率峰值逐步增强、几何置信度逐步提升 的过程。
6.3 为什么"迭代增强"比单次 cost volume 更进一步
单次 cost volume 的局限,在于它往往只在固定候选集合上做一次匹配与归一化。若局部特征模糊、视差不足、遮挡复杂或多峰分布明显,单次归一化得到的 depth distribution 就容易偏平、偏粗,进而把不确定性直接传给 Gaussian centers。IDESplat 的推进在于,它不把第一次深度概率视为最终答案,而把它视为可被继续优化的中间状态。换句话说,geometry-first 在这里已经从"显式深度估计"进化成"显式深度推断过程"。
它说明所谓"前馈式 Gaussian prediction"内部已经不再是纯单步映射。尽管系统仍是 end-to-end feed-forward inference,但在几何层面,它已经包含了一种轻量级迭代推断。这也是路线二与路线一之间更深层的分界:路线一更像单次生成,路线二越来越像受几何约束的前馈推断器。
6.4 阶段性判断
到 IDESplat 为止,路线二已经把问题写得非常清楚:Gaussian mean prediction 不是"一次预测一个 3D 点",而是一个需要稳定 depth probability、候选更新和迭代细化的深度推断问题。geometry-first 路线此时已经进入更精细的 depth reasoning 阶段。
7. 这条路线的统一抽象:depth-first Gaussian prediction
7.1 真正的共同点不是"都用了 cost volume"
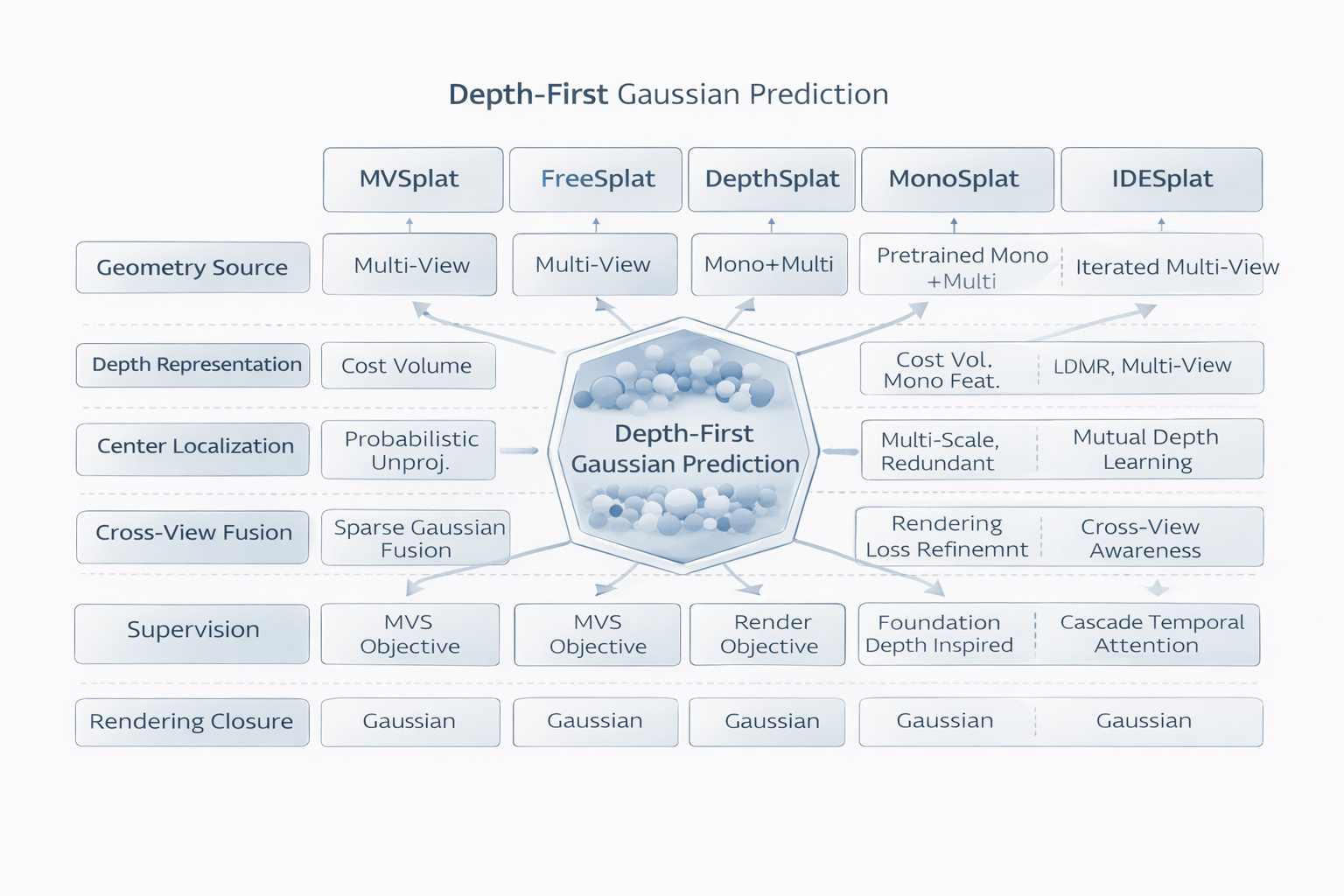
把 MVSplat、FreeSplat、DepthSplat、MonoSplat、IDESplat 放在一起看,真正的共同点并不是它们都用了 cost volume、attention 或 depth prior,而是它们共同在做一件事:先获得更可信的 depth / geometry,再由 depth unprojection 驱动 Gaussian center prediction。
这才是路线二的统一抽象。MVSplat 建立了 plane-sweeping cost volume;FreeSplat 把它推进到 long-sequence 场景组织;DepthSplat 把 depth 与 Gaussian 写成双向促进;MonoSplat 引入 monocular depth foundation priors;IDESplat 则把 depth probability 本身升级为可迭代求精对象。网络结构各不相同,但问题写法高度一致。
形式上,可统一写为
Z geo = Φ ( I , P , S ) , (13) Z_{\text{geo}}=\Phi(\mathcal{I},\mathcal{P},\mathcal{S}), \tag{13} Zgeo=Φ(I,P,S),(13)
d = D ( Z geo ) , μ = π − 1 ( u , d ; K , T ) , (14) d=D(Z_{\text{geo}}), \qquad \mu=\pi^{-1}(u,d;K,T), \tag{14} d=D(Zgeo),μ=π−1(u,d;K,T),(14)
θ rest = H ( Z geo , Z app ) , G = ( μ i , θ rest , i ) ∗ i = 1 N , (15) \theta_{\text{rest}}=H(Z_{\text{geo}},Z_{\text{app}}), \qquad \mathcal{G}={(\mu_i,\theta_{\text{rest},i})}*{i=1}^{N}, \tag{15} θrest=H(Zgeo,Zapp),G=(μi,θrest,i)∗i=1N,(15)
其中 S \mathcal{S} S 表示几何辅助源,可包含 cost volume、monocular foundation features、iterative probability booster 等; Z ∗ geo Z*{\text{geo}} Z∗geo 是几何表征, Z app Z_{\text{app}} Zapp 是外观表征。需要强调的是,这个统一式的中心不是 high-level features,而是深度作为中间变量的主导地位。
7.2 六个层面的统一理解
7.2.1 几何来源
MVSplat 的几何来源是 plane-sweeping cost volume;FreeSplat 是 nearby-view adaptive cost volumes;DepthSplat 是 multi-view cues 加 pre-trained monocular depth features;MonoSplat 是 monocular depth foundation priors;IDESplat 则是迭代增强的 depth probability。几何来源越来越强,但都围绕同一个目标:让 Gaussian mean 更可信。
7.2.2 深度表征
从单次 cost-volume depth,到融合 monocular priors 的 depth,再到 iterative refined depth probability,深度表征在路线二中不断升级。它不再是可有可无的副产品,而是 Gaussian localization 的主状态量。
7.2.3 center localization
几乎所有路线二方法都落在同一个核心公式上:
μ = π − 1 ( u , d ; K , T ) . (16) \mu=\pi^{-1}(u,d;K,T). \tag{16} μ=π−1(u,d;K,T).(16)
真正发生变化的,从来不是反投影本身,而是深度 d d d 的来源越来越强、越来越稳、越来越可解释。这是路线二最本质的统一点。
7.2.4 多视图融合
MVSplat 倾向于 per-view cost volume + attention;FreeSplat 强调 long-sequence local aggregation 与 redundancy fusion;DepthSplat 强调 monocular 与 multi-view 的互补;MonoSplat 用 adapter 让 foundation features 具备 cross-view awareness;IDESplat 则把 cross-view cues 继续压进 iterative probability refinement。它们的真正共性,不是怎么融合,而是融合围绕几何可信度组织。
7.2.5 监督方式
MVSplat 表明 photometric supervision 足以启动路线;DepthSplat 则表明它还可以反向服务于 depth pre-training;MonoSplat 与 IDESplat 则说明,当几何分支变强时,监督不再只靠 rendering closure,而是与显式几何模块共同塑形。路线二的监督逻辑因此从"纯渲染驱动"走向"渲染闭环 + geometry priors + geometric inference"联合体。
7.2.6 渲染闭环
尽管路线二越来越几何优先,但它并没有放弃 3DGS 的显式表示与实时渲染优势。所有工作最终仍落在 feed-forward Gaussian generation 与 splatting rendering 上。这意味着路线二的价值,不只是几何更强,还在于它保持了 3DGS 作为工程表示的部署优势。
7.3 统一判断
因此,路线二最准确的理论抽象不是"用了 cost volume 的 3DGS",而是 depth-first Gaussian prediction 。真正的共同点不在于模块,而在于问题写法:先做可信 geometry,再生成 Gaussian means。 这条路线的历史作用,正是把前馈式 3DGS 的中心矛盾写对了。
8. 这条路线的边界:复杂遮挡、尺度变化、输入扩展性
8.1 geometry-first 为什么比路线一强
geometry-first 比路线一强,首先强在可解释的中间变量。它不是让网络直接"吐出高斯",而是要求系统先回答"这个像素的深度支撑是什么"。这种写法天然更适合 scene-level reconstruction,因为它更容易建立 cross-view consistency,也更容易被诊断:错误究竟来自 depth hypothesis、cross-view aggregation、prior bias,还是 Gaussian fusion,链路相对清晰。对工程系统来说,可解释性本身就是能力。
8.2 geometry-first 为什么仍然不够
但 geometry-first 不是终局答案。DepthSplat 已经明确指出,多视图深度仍会被遮挡、低纹理、反射面拖住;MonoSplat 虽然通过 foundation priors 提升泛化,但也引入了潜在的 domain bias;FreeSplat 说明长序列和 whole-scene 条件下,内存、冗余 Gaussian、跨段融合都会成为压力;IDESplat 则说明即便接受 depth-first 写法,单轮 depth probability 仍可能太粗、太不稳。因此,geometry-first 解决的是"几何不够显式"的问题,但并没有彻底解决"几何是否足够完备"的问题。
可以将其残余误差写为
ϵ μ = ϵ match + ϵ occl + ϵ prior + ϵ scale + ϵ fusion , (17) \epsilon_{\mu}= \epsilon_{\text{match}} + \epsilon_{\text{occl}} + \epsilon_{\text{prior}} + \epsilon_{\text{scale}} + \epsilon_{\text{fusion}}, \tag{17} ϵμ=ϵmatch+ϵoccl+ϵprior+ϵscale+ϵfusion,(17)
其中 ϵ match \epsilon_{\text{match}} ϵmatch 表示匹配不稳定, ϵ occl \epsilon_{\text{occl}} ϵoccl 表示遮挡与低纹理退化, ϵ prior \epsilon_{\text{prior}} ϵprior 表示 foundation prior 偏差, ϵ scale \epsilon_{\text{scale}} ϵscale 表示大场景尺度压力, ϵ fusion \epsilon_{\text{fusion}} ϵfusion 表示长序列 Gaussian 融合误差。工程上这意味着:几何中间变量能提升平均正确率,但不能自动抹平所有三维歧义。
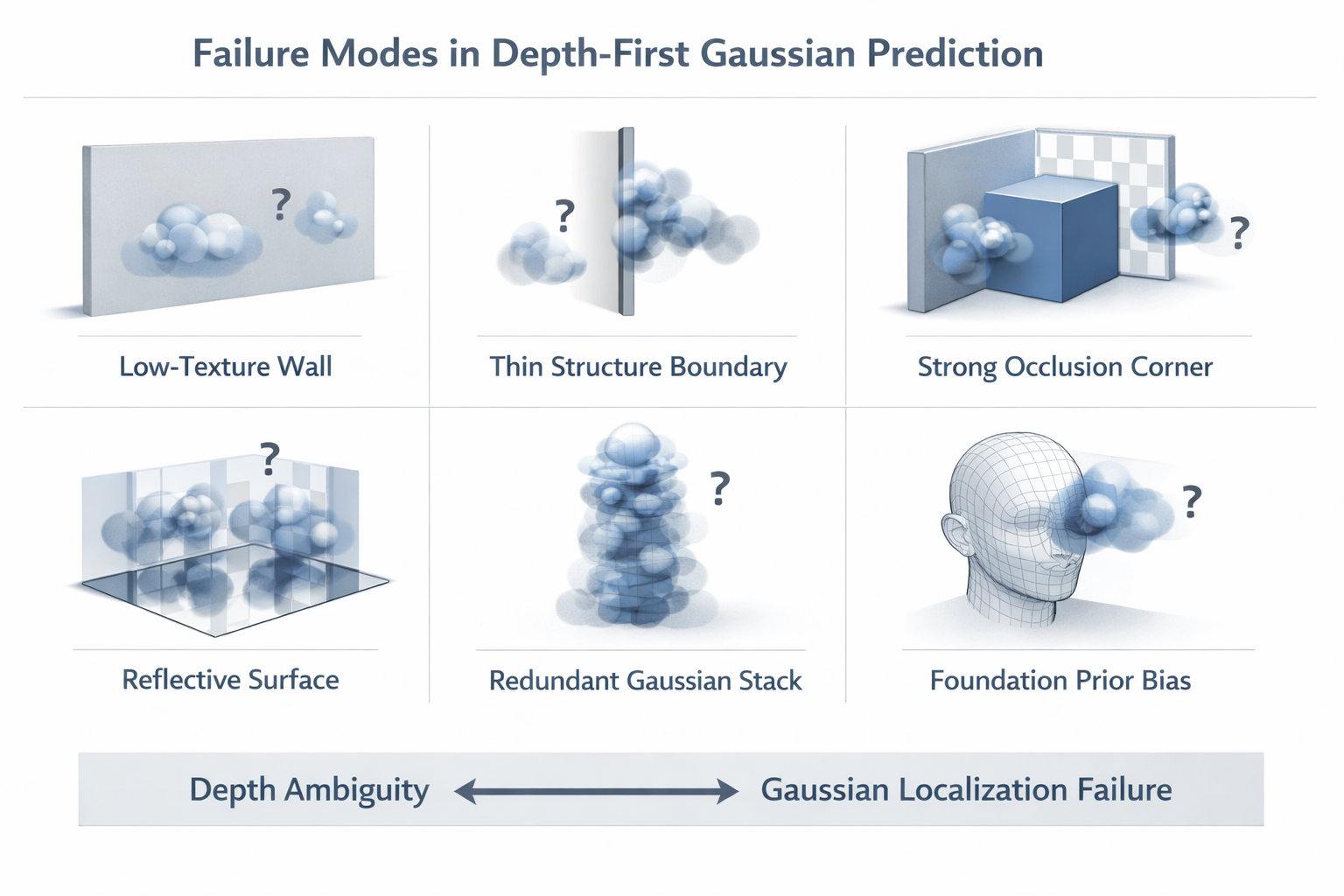
8.3 为什么它会自然导向路线三、四、五
正因为 geometry-first 仍不够,所以后续路线自然会分化。若局部 cost volume 与中等容量几何网络不足以承载更大范围上下文,就会走向路线三的大模型聚合;若已知位姿这一假设本身开始松动,就会走向路线四的 pose-free / uncalibrated reconstruction;若逐像素/逐高斯生成在扩展性与结构稳定性上受限,就会走向路线五的 structured latent / voxel-aligned 表征。路线二的意义不是"结束问题",而是把问题推进到一个更清晰的几何层级,让后续路线的分化更有根据。
9. 为什么这条路线是 scene-level reconstruction 的主战场
9.1 方法论层面:它最契合 posed multi-view reconstruction
在"已知位姿、少到中等数量输入视图、希望直接输出可渲染 3DGS"的设定下,路线二之所以成为主战场,是因为它同时满足三件事:第一,保留了 3DGS 的显式表示与实时渲染优势;第二,引入了更清晰的 geometry intermediate;第三,在 generalizable reconstruction 中具备相对明确的模块化升级路径。MVSplat、FreeSplat、DepthSplat、MonoSplat 与 IDESplat 的连续推进,本质上都在证明:对于 posed scene-level reconstruction,geometry-first 是当前最成熟的一条工程主线之一。
9.2 工程层面:它兼具可解释性、可部署性与可演进性
从工程链路看,路线二的优势在于它非常适合被拆成可演进模块:输入图像与位姿 → \rightarrow → cross-view aggregation / cost volume / foundation prior → \rightarrow → depth estimation → \rightarrow → unprojection → \rightarrow → Gaussian parameter prediction → \rightarrow → rendering closure。每一级都可以被替换、增强或诊断:depth branch 可以更强,prior 可以更广,probability refinement 可以更细,fusion 可以更稳,而输出仍保持在 3DGS 这一显式、可渲染、相对友好的表示上。对研发团队而言,这种"中间变量明确 + 输出表示稳定"的路线,比完全黑箱的直接生成路线更可控。
10. 结语
路线二把前馈式 3DGS 从"可训练"推进到"更可信的几何重建",因此它是当前最强的工程主线之一。这个判断之所以成立,不是因为路线二已经解决了全部问题,而是因为它第一次把主矛盾明确写成了:Gaussian mean localization 本质上是深度/几何问题。 从 MVSplat 的 plane-sweeping cost volume,到 FreeSplat 的 long-sequence geometry organization,再到 DepthSplat 的 depth--Gaussian 双向促进、MonoSplat 的 foundation depth priors、IDESplat 的 iterative depth probability boosting,这条路线不断做的,其实都是同一件事:让高斯中心的空间支撑更可信。
它在整个研究地图中的历史定位也因此十分清楚:路线一证明了前馈式 3DGS 可以成立,路线二证明了若想让它在 scene-level reconstruction 中真正站住脚,必须重新拥抱多视图几何;而下一篇路线三------LRM / Transformer / 大重建模型------要回答的,则是在这个几何主矛盾已经被澄清之后,如何用更大容量、更强上下文组织能力继续推进 generalizable 3D reconstruction。 换句话说,路线三不是路线二的否定,而是建立在路线二"把问题写对"之后的继续放大。
参考资料
- pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction(作为路线一前史) (arXiv)
- MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images(ECCV 2024) (arXiv)
- FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes(NeurIPS 2024) (arXiv)
- DepthSplat: Connecting Gaussian Splatting and Depth(CVPR 2025) (arXiv)
- MonoSplat: Generalizable 3D Gaussian Splatting from Monocular Depth Foundation Models(CVPR 2025) (arXiv)
- IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting(arXiv 2026) (arXiv)