第十二章:见微知著------特征工程的科学与艺术(进阶篇)
"数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。"
引言:从"燃料"到"精炼油"------特征工程的升维之战
在我们的旅程中,"数据是燃料"一章为我们奠定了坚实的基础。我们学会了如何评估数据质量、处理缺失值、进行基础的数值缩放与类别编码。那时,我们将原始数据视为一种粗犷的、未经加工的"原油"。
然而,在真实世界的机器学习竞赛和工业项目中,胜利的天平往往不是由最复杂的模型决定的,而是由最精妙的特征工程所倾斜的。 Kaggle 竞赛的冠军们无数次证明,一个经过精心雕琢的特征集,配合一个简单的线性模型,其威力常常能碾压一个在原始特征上训练的、参数量巨大的深度神经网络。
这背后的原因在于:机器学习模型,无论多么强大,都只能在其输入特征所构建的假设空间内进行搜索。 如果这个空间本身是贫瘠的、充满噪声的,或者无法有效捕捉数据背后的内在结构,那么再强大的模型也只能"巧妇难为无米之炊"。
本章,我们将超越基础预处理,深入特征工程的科学与艺术。 我们将系统性地探讨一系列高级技术,它们如同化学家手中的催化剂和分馏塔,能够将原始的"数据原油"提炼成高能量的"精炼油",从而极大地提升模型的性能上限。我们将聚焦于六大核心领域:特征交叉、目标编码、嵌入表示、时间序列特征、地理空间特征以及特征重要性的闭环优化。
一、特征交叉(Feature Crossing):揭示隐藏的交互模式
1.1 直觉与动机
线性模型(如逻辑回归)的一个根本局限在于其无法自动捕捉特征间的交互作用。 例如,考虑一个电商场景:
用户年龄(Age)是一个特征。商品类别(Category)是另一个特征。
单独来看,年轻用户可能更喜欢电子产品,年长用户可能更关注健康产品。但如果我们只将 Age 和 Category 作为独立特征输入线性模型,模型就无法学习到"年轻的用户购买电子产品的倾向性远高于其他组合"这一复杂的联合模式。
特征交叉(Feature Crossing)正是为了解决这个问题。它通过显式地创建新特征,来表示两个或多个原始特征的组合。
1.2 手动交叉 vs. 自动化交叉
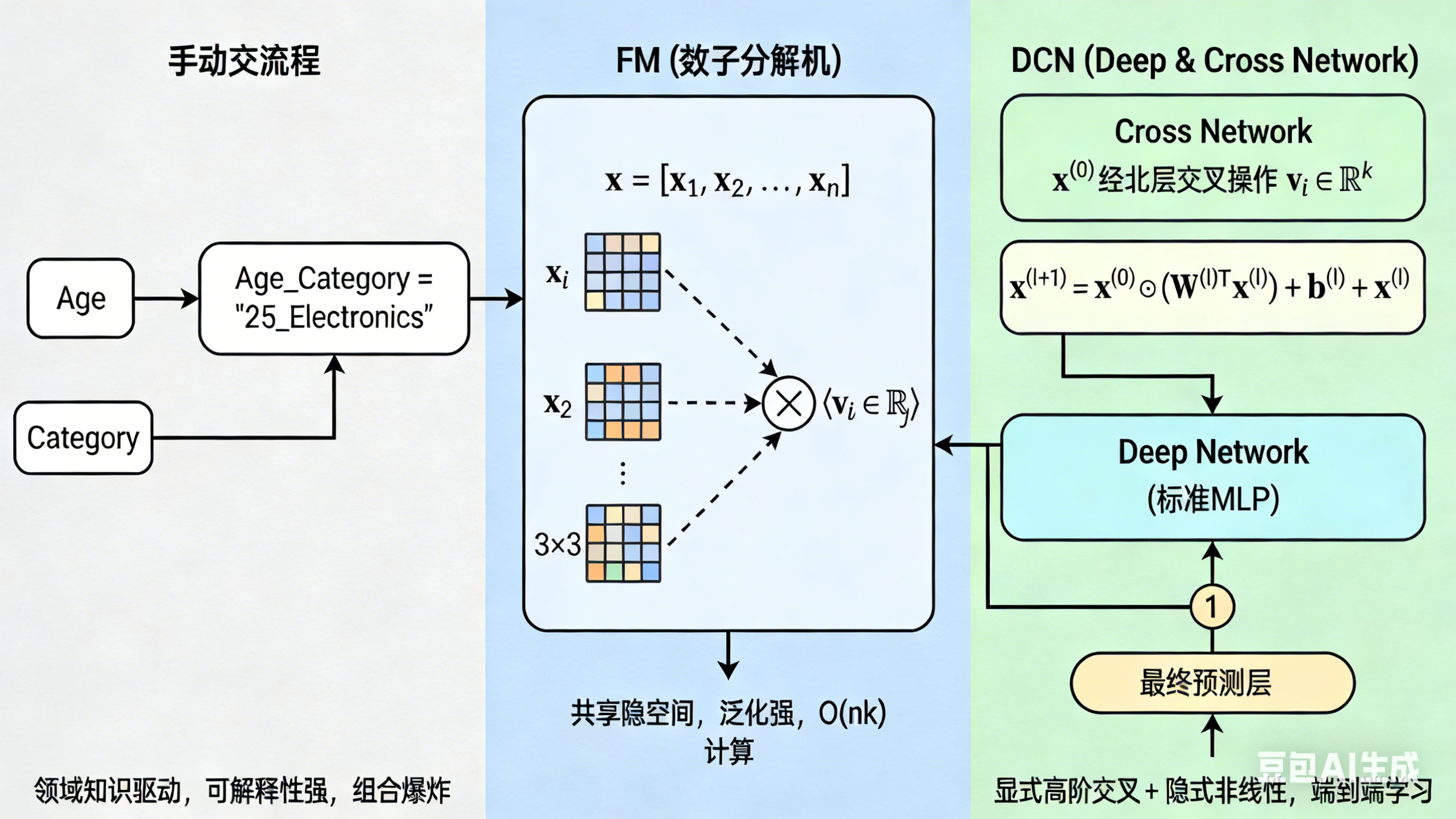
1.2.1 手动交叉:基于领域知识的智慧
最直接的方法是基于业务理解手动创建交叉特征。例如:
- 对于
Age和Category,可以创建一个新特征Age_Category = str(age_bin) + "_" + category。 - 在广告点击率预测中,
广告位(Ad_Position)和广告素材类型(Ad_Type)的交叉可能非常有效。
这种方法的优点是可解释性强 ,缺点是高度依赖专家经验 ,且在特征数量众多时,组合爆炸( O ( n 2 ) O(n^2) O(n2) 或更高)使得手动枚举变得不可能。
1.2.2 自动化交叉:FM 与 Deep & Cross Network
为了克服手动交叉的局限,研究者提出了能够自动学习特征交叉的模型。
-
因子分解机 (Factorization Machines, FM)
FM 的核心思想是为每个特征 x i x_i xi 学习一个隐向量 (latent vector) v i ∈ R k \mathbf{v}i \in \mathbb{R}^k vi∈Rk,其中 k k k 是隐向量的维度。两个特征 x i x_i xi 和 x j x_j xj 的交互强度不再是一个独立的参数 w i j w{ij} wij,而是由它们隐向量的点积来表示:
y ^ FM ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j \hat{y}{\text{FM}}(\mathbf{x}) = w_0 + \sum{i=1}^{n} w_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j y^FM(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩xixj其中 ⟨ v i , v j ⟩ = ∑ f = 1 k v i , f ⋅ v j , f \langle \mathbf{v}i, \mathbf{v}j \rangle = \sum{f=1}^{k} v{i,f} \cdot v_{j,f} ⟨vi,vj⟩=∑f=1kvi,f⋅vj,f。
优势:
- 泛化能力强 :即使在训练集中从未同时出现过特征 i i i 和 j j j,只要它们各自与其他特征有过交互,就能通过共享的隐向量空间推断出它们之间的潜在关系。
- 计算高效 :通过数学变换,交叉项的计算复杂度可以从 O ( n 2 ) O(n^2) O(n2) 降低到 O ( n k ) O(nk) O(nk)。
-
**Deep & Cross Network **(DCN)
DCN 将 FM 的思想与深度学习相结合。它包含两个并行的网络:
- Cross Network :显式地、逐层地应用特征交叉。第 l + 1 l+1 l+1 层的输出为:
x ( l + 1 ) = x ( 0 ) ⊙ ( W ( l ) T x ( l ) ) + b ( l ) + x ( l ) \mathbf{x}^{(l+1)} = \mathbf{x}^{(0)} \odot (\mathbf{W}^{(l)T} \mathbf{x}^{(l)}) + \mathbf{b}^{(l)} + \mathbf{x}^{(l)} x(l+1)=x(0)⊙(W(l)Tx(l))+b(l)+x(l)
其中 x ( 0 ) \mathbf{x}^{(0)} x(0) 是原始输入, ⊙ \odot ⊙ 表示逐元素相乘。这种结构能高效地学习有界度的特征交叉。 - Deep Network:一个标准的多层感知机(MLP),用于学习特征间的隐式、非线性交互。
最终的预测是两个网络输出的拼接(concatenation)经过一个最终层得到的。DCN 在推荐系统等领域取得了巨大成功。
- Cross Network :显式地、逐层地应用特征交叉。第 l + 1 l+1 l+1 层的输出为:
1.3 实践工具:scikit-learn 与 polynomialfeatures
对于简单的数值特征交叉,scikit-learn下载链接 提供了 PolynomialFeatures:
python
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
X = np.array([[1, 2], [3, 4]]) # 假设有两个特征
poly = PolynomialFeatures(degree=2, interaction_only=True) # 只生成交叉项,不生成平方项
X_crossed = poly.fit_transform(X)
print(X_crossed) # 输出: [[1. 1. 2. 2.] [1. 3. 4. 12.]]
# 新增的特征是 1*2=2 和 3*4=12虽然简单,但在许多场景下已足够有效。
二、目标编码(Target Encoding):用标签信息指导编码
2.1 问题背景:高基数类别特征的困境
在真实数据中,我们经常会遇到高基数 (High-Cardinality)的类别特征,例如 用户ID、商品SKU、IP地址 等。这些特征的唯一取值可能成千上万甚至更多。
- 独热编码(One-Hot Encoding)会生成海量的稀疏列,导致维度灾难,并且无法为在验证/测试集中新出现的类别(冷启动问题)提供表示。
- 标签编码 (Label Encoding)将类别映射为整数,但这错误地引入了类别间的序数关系(如
user_1 < user_2),对大多数模型是有害的。
目标编码 (Target Encoding),也称为均值编码(Mean Encoding),提供了一种优雅的解决方案。
2.2 核心思想与公式
目标编码的核心思想是:用该类别下所有样本的目标变量的统计量(通常是均值)来代表这个类别。
对于一个类别特征 C C C 中的某个取值 c c c,其目标编码值为:
TE ( c ) = ∑ i : y i ∈ c y i + λ ⋅ μ n c + λ \text{TE}(c) = \frac{\sum_{i:y_i \in c} y_i + \lambda \cdot \mu}{n_c + \lambda} TE(c)=nc+λ∑i:yi∈cyi+λ⋅μ
其中:
- n c n_c nc 是类别 c c c 在训练集中出现的次数。
- μ \mu μ 是整个训练集目标变量 y y y 的全局均值。
- λ \lambda λ 是一个平滑超参数(smoothing parameter)。
为什么需要平滑?
- 当 n c n_c nc 很大时, TE ( c ) ≈ ∑ y i n c \text{TE}(c) \approx \frac{\sum y_i}{n_c} TE(c)≈nc∑yi,即该类别的局部均值。
- 当 n c n_c nc 很小时(甚至为0), TE ( c ) ≈ μ \text{TE}(c) \approx \mu TE(c)≈μ,即全局均值。这有效地防止了对罕见类别进行过度拟合,并自然地解决了冷启动问题。
2.3 致命陷阱:数据泄露(Data Leakage)与防过拟合技巧
目标编码最大的风险在于数据泄露 。如果我们在整个训练集上计算 TE ( c ) \text{TE}(c) TE(c),然后用它来训练模型,模型就会"偷看"到验证集或测试集的信息,导致评估结果过于乐观,上线后性能急剧下降。
解决方案:留一法编码(Leave-One-Out Encoding, LOO)
LOO 是一种经典的防泄露方法。对于训练集中的每一个样本 i i i,在计算其类别 c i c_i ci 的编码时,排除掉样本 i i i 本身 :
LOO ( c i ) = ∑ j ≠ i , c j = c i y j n c i − 1 \text{LOO}(c_i) = \frac{\sum_{j \neq i, c_j = c_i} y_j}{n_{c_i} - 1} LOO(ci)=nci−1∑j=i,cj=ciyj
这样,每个样本的编码都不包含自己的标签信息,从而避免了泄露。
更优方案:K折交叉编码(K-Fold Target Encoding)
LOO 在样本量少时仍然不稳定。更稳健的做法是采用 K 折交叉验证的方式:
- 将训练集随机分成 K 个不重叠的子集(folds)。
- 对于第 k k k 个 fold 中的每个样本,使用其余 K-1 个 folds 的数据来计算其类别编码。
- 最终,每个训练样本都获得了一个无泄露的编码值。
对于验证集和测试集,直接使用整个训练集计算出的编码映射表即可。
2.4 实践工具:category_encoders 库
Python 的 category_encoders 库提供了多种目标编码的实现:
python
from category_encoders import TargetEncoder, LeaveOneOutEncoder
from sklearn.model_selection import cross_val_score
import pandas as pd
# 假设 df 是你的DataFrame,'high_card_col' 是高基数类别列,'target' 是目标列
X = df[['high_card_col', 'other_features']]
y = df['target']
# 使用K折交叉编码(TargetEncoder内部默认使用了类似LOO的策略)
encoder = TargetEncoder(cols=['high_card_col'])
X_encoded = encoder.fit_transform(X, y)
# 或者显式使用LOO
loo_encoder = LeaveOneOutEncoder(cols=['high_card_col'])
X_loo = loo_encoder.fit_transform(X, y)正确使用这些工具,可以安全、高效地处理高基数类别特征。
三、嵌入(Embedding):从稀疏到稠密的语义跃迁
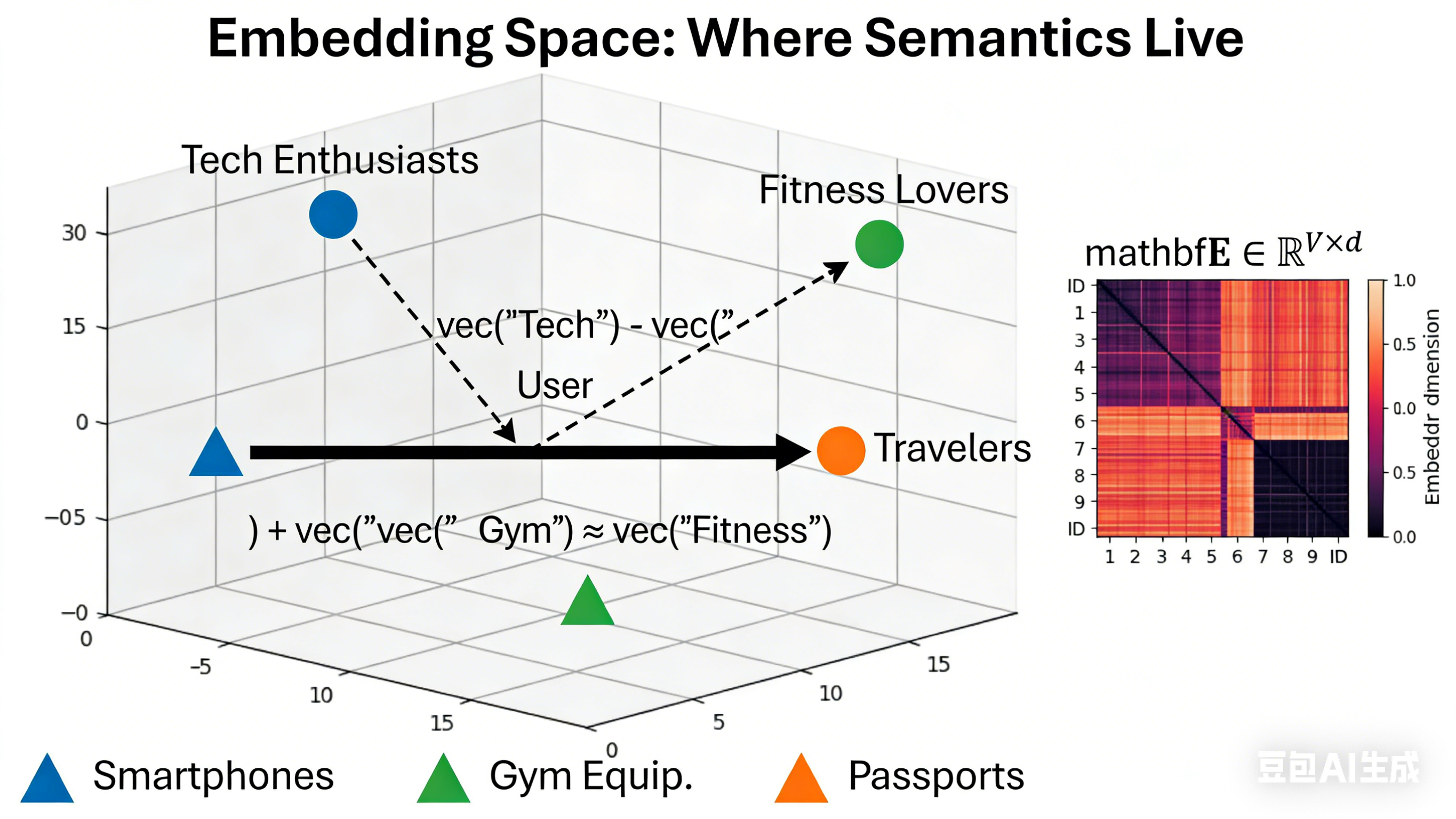
3.1 从 NLP 到通用特征表示
嵌入(Embedding)最初在自然语言处理(NLP)中大放异彩。Word2Vec、GloVe 等模型证明了,可以将离散的单词(如 "king", "queen")映射到一个低维、稠密的连续向量空间中,并且在这个空间里,语义相似的词距离相近(如 vec("king") - vec("man") + vec("woman") ≈ vec("queen"))。
很快,人们意识到,任何离散的、具有潜在语义或结构的实体 (如用户、商品、类别)。嵌入的本质,就是一种通过模型学习得到的、稠密的特征表示。
3.2 数学形式与学习机制
对于一个有 V V V 个唯一取值的类别特征,我们可以为其创建一个嵌入矩阵 (Embedding Matrix) E ∈ R V × d \mathbf{E} \in \mathbb{R}^{V \times d} E∈RV×d,其中 d d d 是嵌入的维度( d ≪ V d \ll V d≪V)。
- 当输入一个类别索引 i i i 时,其对应的嵌入向量就是矩阵的第 i i i 行: e i = E i , : \mathbf{e}_i = \mathbf{E}i, : ei=Ei,:。
- 这个嵌入矩阵 E \mathbf{E} E 不是预先定义的,而是作为模型的一部分,在端到端的训练过程中与其他参数一起被优化的。
损失函数驱动学习:嵌入向量之所以能学到有意义的表示,是因为它们被置于一个具体的任务中(如分类、回归)。模型为了最小化最终的损失(如交叉熵),会自动调整嵌入矩阵,使得在任务上有相似行为的实体,其嵌入向量在空间中也彼此靠近。
3.3 在非 NLP 任务中的应用
- 推荐系统 :为每个
用户ID和商品ID学习一个嵌入向量。用户的偏好可以表示为其用户嵌入和商品嵌入的点积或拼接后的 MLP 输出。 - 表格数据建模 :对于像
国家、职业这样的类别特征,使用嵌入代替独热编码,可以极大地降低维度,并让模型捕捉到"法国"和"德国"比"法国"和"日本"更相似这样的潜在信息。 - 图神经网络(GNN) 节点嵌入是 GNN 的核心,它聚合了邻居节点的信息来表示中心节点。
3.4 实践:在 PyTorch 中使用嵌入层
python
import torch
import torch.nn as nn
class TabularModel(nn.Module):
def __init__(self, num_categories, embedding_dim, num_numerical):
super().__init__()
# 为类别特征创建嵌入层
self.embedding = nn.Embedding(num_categories, embedding_dim)
# 定义后续的MLP
self.mlp = nn.Sequential(
nn.Linear(embedding_dim + num_numerical, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
def forward(self, categorical_input, numerical_input):
# categorical_input: [batch_size]
# numerical_input: [batch_size, num_numerical]
embedded = self.embedding(categorical_input) # [batch_size, embedding_dim]
combined = torch.cat([embedded, numerical_input], dim=1)
return self.mlp(combined)通过这种方式,嵌入成为了连接离散世界与连续模型的桥梁。
四、时间序列特征工程:解码时间的韵律
时间序列数据(如股票价格、传感器读数、用户行为日志)蕴含着丰富的动态模式。对其进行有效的特征工程,是预测未来的关键。
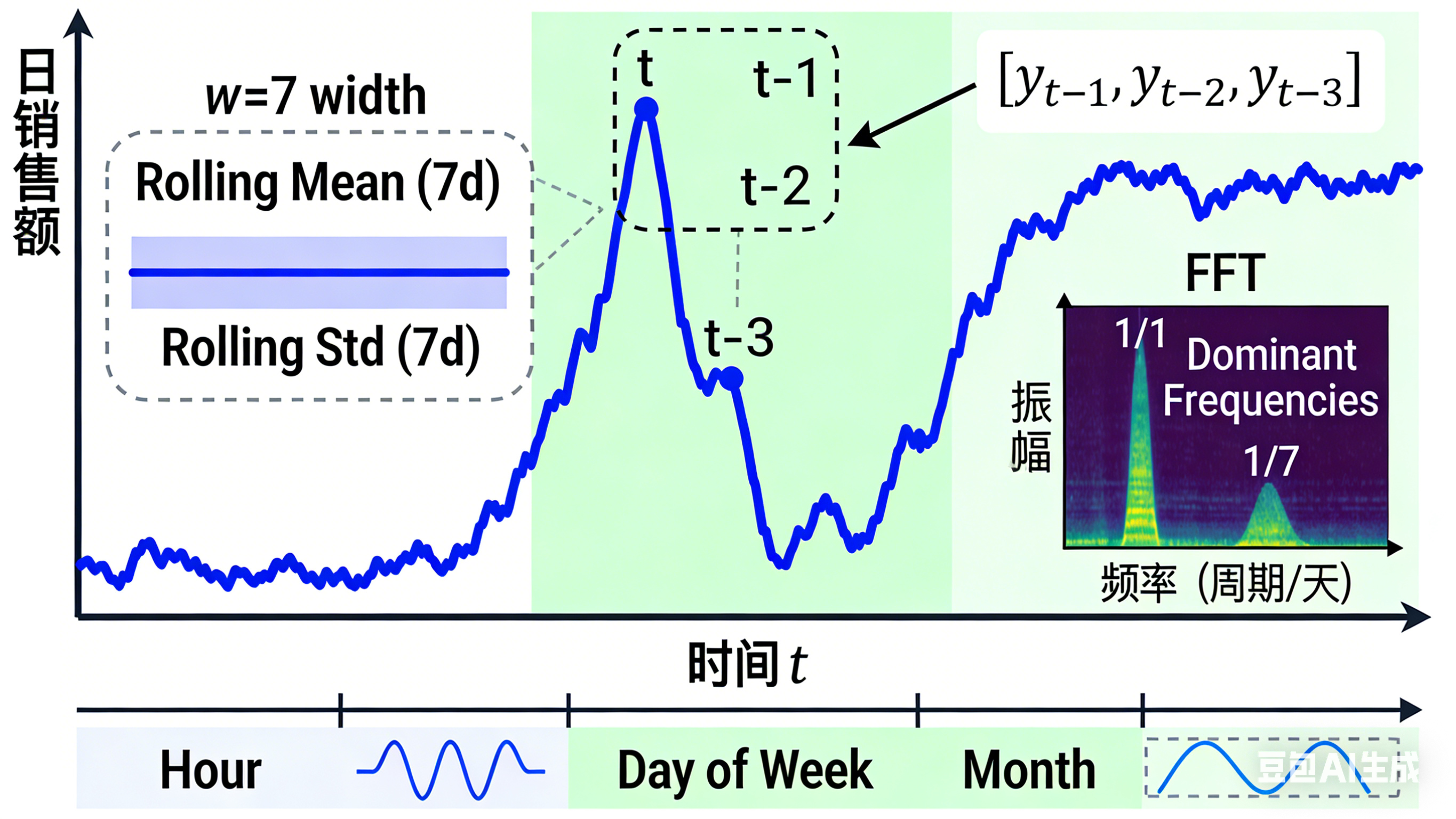
4.1 滑动窗口(Rolling Window)与滞后特征(Lag Features)
这是最基础也是最重要的两类时间特征。
-
滞后特征(Lag Features):直接使用过去时刻的值作为当前时刻的特征。
- 例如,用
t-1,t-2,t-3时刻的销售额来预测t时刻的销售额。 - 特征:
[sales_{t-1}, sales_{t-2}, sales_{t-3}]
- 例如,用
-
滑动窗口统计量(Rolling Window Statistics):计算过去一个时间窗口内的统计指标。
- 窗口均值 (Rolling Mean):
rolling_mean_t = (sales_{t-1} + sales_{t-2} + ... + sales_{t-w}) / w - 窗口标准差(Rolling Std):衡量近期波动性。
- 窗口最小/最大值:捕捉近期的极值。
- 指数加权移动平均 (EWMA):给予近期数据更高的权重,对最新变化更敏感。
EWMA t = α ⋅ x t + ( 1 − α ) ⋅ EWMA t − 1 \text{EWMA}t = \alpha \cdot x_t + (1-\alpha) \cdot \text{EWMA}{t-1} EWMAt=α⋅xt+(1−α)⋅EWMAt−1
其中 α \alpha α 是平滑因子。
- 窗口均值 (Rolling Mean):
这些特征能有效地将时间序列的趋势 (trend)、季节性 (seasonality)和周期性(cyclicity)信息编码到静态的特征向量中,使得标准的机器学习模型也能处理时间序列预测问题。
4.2 时间戳的分解与编码
原始的时间戳(如 2026-04-07 12:27:00)本身信息量有限,但将其分解后,可以提取出大量有用的周期性信息:
- 绝对时间 :
年、月、日、星期几、小时、分钟。 - 相对时间 :
距离月初的天数、距离周末的天数、是否为节假日、是否为工作日。
对于周期性特征(如 小时、星期几),不要直接使用整数编码 ! 因为 23(晚上11点)和 0(午夜)在时间上是相邻的,但数值上相差甚远。正确的做法是使用正弦/余弦编码 (Sinusoidal Encoding)将其映射到一个圆上:
hour_sin = sin ( 2 π ⋅ hour 24 ) , hour_cos = cos ( 2 π ⋅ hour 24 ) \text{hour\_sin} = \sin\left(2\pi \cdot \frac{\text{hour}}{24}\right), \quad \text{hour\_cos} = \cos\left(2\pi \cdot \frac{\text{hour}}{24}\right) hour_sin=sin(2π⋅24hour),hour_cos=cos(2π⋅24hour)
这样,23 和 0 的编码在向量空间中就是相邻的。
4.3 傅里叶变换:捕捉复杂周期性
当时间序列存在多个叠加的、复杂的周期时,滑动窗口可能力不从心。傅里叶变换(Fourier Transform)提供了一种全局视角。
- 快速傅里叶变换(FFT)可以将时域信号分解为不同频率的正弦和余弦波的叠加。
- 通过分析频谱,我们可以识别出主要的周期成分(如每日、每周、每年的周期)。
- 我们可以将这些主频成分的振幅和相位作为新的特征加入模型,或者直接使用傅里叶基函数来拟合和预测时间序列。
虽然在实践中不如前两种方法常用,但对于具有强周期性的信号(如电力负荷、天文数据),傅里叶特征是非常强大的。
五、地理空间特征处理:在地图上寻找模式
位置信息(经纬度)是许多应用(如打车、外卖、房产)的核心特征。直接使用 (latitude, longitude) 作为两个数值特征是远远不够的。
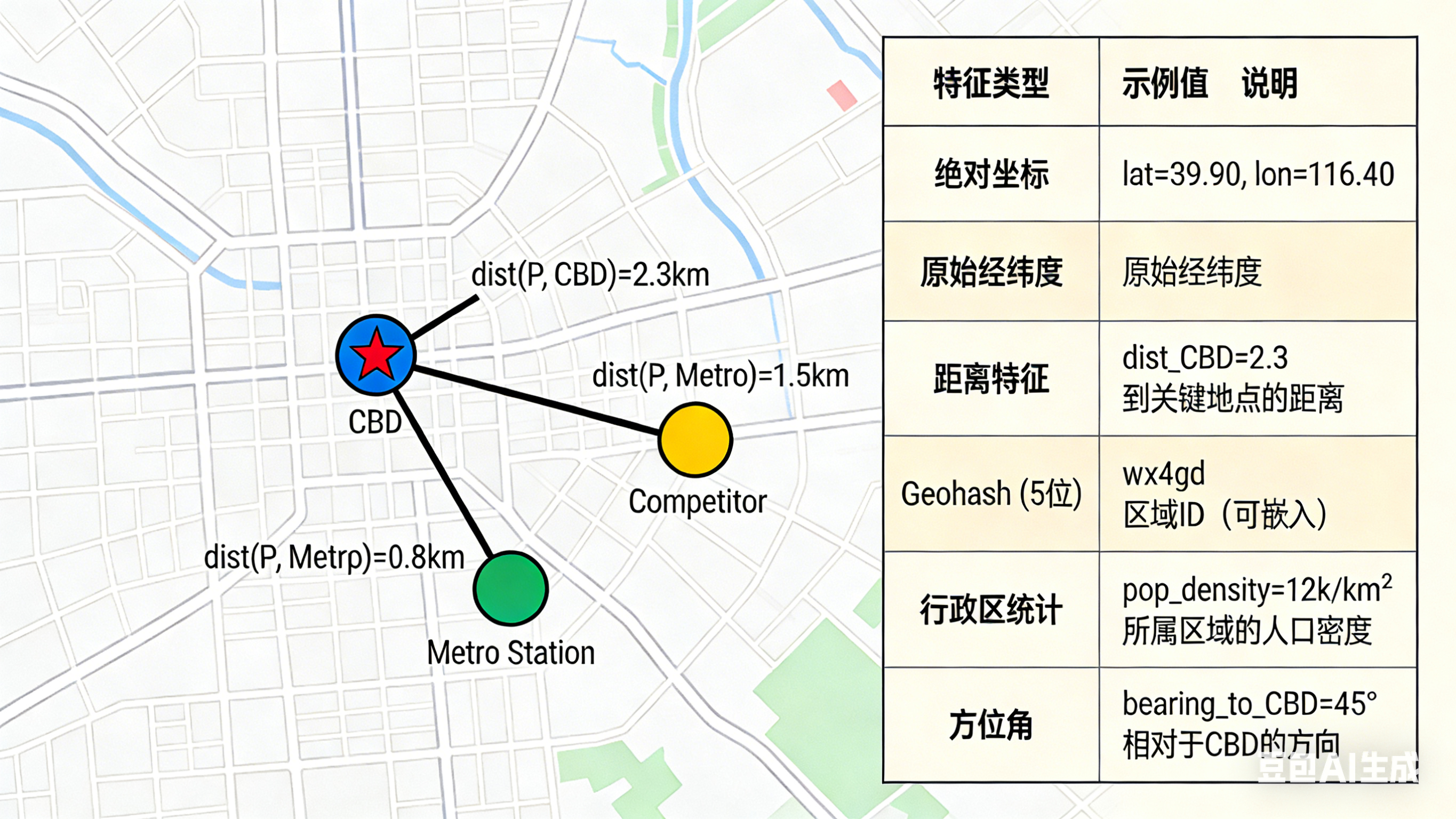
5.1 距离与方位角
-
计算与其他关键点的距离 :如到市中心的距离、到最近地铁站的距离、到竞争对手门店的距离。欧氏距离或更精确的 Haversine 距离(考虑地球曲率)都是常用选择。
d = 2 r ⋅ arcsin ( sin 2 ( Δ ϕ 2 ) + cos ( ϕ 1 ) cos ( ϕ 2 ) sin 2 ( Δ λ 2 ) ) d = 2r \cdot \arcsin\left(\sqrt{\sin^2\left(\frac{\Delta\phi}{2}\right) + \cos(\phi_1)\cos(\phi_2)\sin^2\left(\frac{\Delta\lambda}{2}\right)}\right) d=2r⋅arcsin(sin2(2Δϕ)+cos(ϕ1)cos(ϕ2)sin2(2Δλ) )其中 ϕ \phi ϕ 是纬度, λ \lambda λ 是经度, r r r 是地球半径。
-
计算方位角(Bearing):两点之间的方向(北偏东多少度)。这可以捕捉方向性偏好。
5.2 地理哈希(Geohashing)与区域编码
- Geohashing :将经纬度编码成一个短字符串(如
u4pruydqqvj)。这个字符串的前缀越长,代表的地理区域越精确。我们可以使用不同精度的 Geohash 作为类别特征,让模型学习不同尺度下的区域模式。 - 行政区域编码:将经纬度匹配到已知的行政区划(如省、市、区、邮政编码),并使用这些区域的统计数据(如人均收入、人口密度)作为特征。
5.3 空间交互特征
类似于特征交叉,可以创建两个地理位置之间的交互特征,例如:
- 两个地点之间的距离和方位角。
- 一个地点是否在另一个地点的特定半径范围内。
六、闭环:特征重要性分析与迭代优化
特征工程不是一次性的任务,而是一个持续的、迭代的闭环过程。
6.1 量化特征价值
在添加或修改特征后,我们需要一种方法来评估其有效性。特征重要性(Feature Importance)是核心工具。
- 基于树模型的重要性 :如 Random Forest 或 XGBoost 内置的
feature_importances_。它通常基于特征在所有树中用于分裂时所带来的不纯度(如 Gini impurity)减少的总和。 - Permutation Importance :一种更可靠、模型无关的方法。其步骤如下:
- 训练一个模型,并记录其在验证集上的基准性能(如 AUC)。
- 对于每个特征 j j j,随机打乱验证集中该特征的值,保持其他特征不变。
- 用打乱后的数据评估模型性能。
- 性能下降的幅度就是特征 j j j 的重要性得分。下降越多,说明该特征越重要。
Permutation Importance 能有效避免树模型对高基数特征的偏好偏差。
6.2 迭代优化流程
- 提出假设:基于业务理解和数据探索,提出一个新的特征构想。
- 实现与注入:将新特征加入特征集。
- 训练与评估:使用相同的模型和验证策略进行训练,比较新旧方案的性能。
- 分析与决策 :
- 如果性能显著提升,保留该特征。
- 如果性能不变或下降,分析原因(是否引入了噪声?是否与其他特征冗余?)。
- 查看新特征的重要性得分。
- 重复:回到步骤1,不断循环。
通过这个严谨的闭环,我们可以确保每一次特征工程的努力都朝着正确的方向前进,最终构建出一个既强大又简洁的特征集。
结语:
高级特征工程,是科学与艺术的完美结合。科学 体现在其坚实的数学基础和可复现的实验方法上;艺术则体现在对业务场景的深刻洞察、对数据直觉的敏锐把握,以及在无数可能性中做出最优选择的创造力上。
掌握了本章所阐述的技术,你就拥有了将原始数据点石成金的能力。你不再被动地接受数据的形态,而是主动地塑造它,引导模型去发现那些隐藏在表象之下的、真正驱动业务结果的深层规律。这,正是顶尖数据科学家与普通从业者的分水岭。