前言
在文档站进行搜索的一个痛点在于很难在站内的众多文档中找到自己想要的回答,其难点主要在于两方面:
- 一方面是用户进行搜索时需要精炼语句,越是精确的提问越容易得到正确的答案,这无异增加了用户的使用成本
- 另一方面在于文档站对提问进行搜索时只能做到关键字搜索或词法上的模糊查询,较难做到语义上的模糊查询
ChatGPT为解决上述问题提供了可能性,它是一个语言模型,生来就能够理解用户以自然语言发出的提问,在使用ChatGPT时用户不再需要提炼关键词,一切交给模型,它会自行生成答案。
全文目标:期望文档站能够理解用户的自然语言提问,并同时以自然语言进行回答。
下图为使用自然语言进行文档搜索的示例:
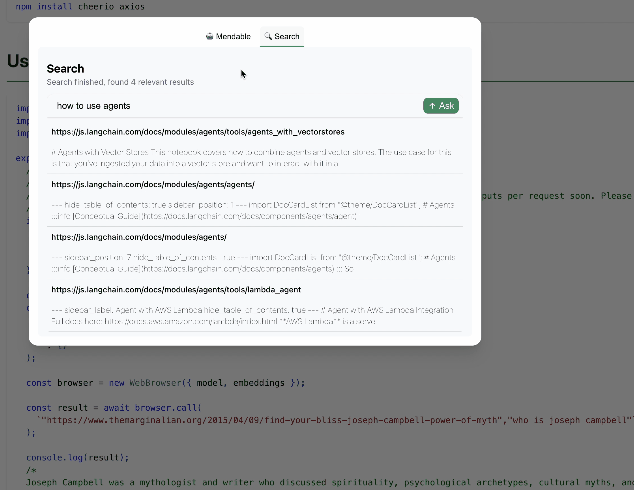
概念介绍
认识ChatGPT
ChatGPT介绍推荐这个视频
简要介绍
以前的时候,我们认为一个模型针对一个领域进行训练,可以成为这个领域内的专家,可以解决特定问题。 后来我们发现,单用这些领域内的知识来解决问题有时候不够,为了解决一个问题,有时候往往需要多个领域的知识。那么我们对领域的界定就会变得模糊而不清晰,甚至做扩大。随着不断扩大,就有了所谓通用大模型的意义。
GPT,全民为Generative Pre-trained Transformer,指 OpenAI 发布的一系列大型语言模型,它们在大型文本数据集上训练,可被用于文本生成,翻译,分类等任务。
ChatGPT是基于GPT、特化了聊天能力的聊天机器人程序。ChatGPT是微调的GPT-3,唯一的不同是知识的指向性,或者说模型对特定知识的筛选。GPT-3的知识没有任何标签,因此本质是一个无监督学习;而ChatGPT使用符合人类指令要求的知识,因此本质是一个自监督学习,两个模型学习知识的质量就完全不同了。
ChatGPT通过学习大量的数据,理解了自然语言中的通用规律。当用户向ChatGPT提问时,它理解了用户的问题符合某种已知的规律,进而生成符合该规律的回答。
ChatGPT能够回答问题的原理并不是搜索,而是生成,它并不存储数据,所有的数据训练只是为了调整模型以发现问答的通用规律。
适用场景
- 知识问答:专业问题回答、信息检索
- 内容生产:内容续写、文学创作、音乐创作
- 代码能力:生成代码、调试代码、为代码生成注释
存在意义
- 提升语言处理效率,减少语言处理成本
- 指明人工智能模型发展方向
- 开启Language User Interface的新篇章
- 离终极目标:让机器理解自然语言更进一步
为何ChatGPT如此重要,引用视频中的总结:语言的发明,允许人类将个体所获得的认识存储在体外,进而打通了整个物种的过去与未来。「创造知识」「继承知识」和「应用知识」都是依靠语言来实现的,大语言模型LLM展现了人们未曾想过的理解能力,这使得我们极有希望真正实现让机器理解自然语言这一目标。
现存问题
ChatGPT是革命性的产品,它能够理解人类自然语言生成自然语言文本和执行某些任务,擅长从海量的知识提取出用户需要的信息。
但它与人们期望的强人工智能 AGI 仍然差距巨大,GPT 模型使用前文 token 预测下一个 token,这种预测方法使得 GPT 模型是一种线性思维,而人的思维比这种线性思考复杂太多。
此外,ChatGPT强依赖于高质量数据,这类大模型的训练数据不可能涵盖用户所需的一切知识,训练数据总归是有限的。若是希望它去回答一些不在训练范围内的知识,ChatGPT的回答容易给人的感觉是胡乱编造。
为了让AI回答不在训练范围内的知识,一个思路是将额外的知识内容输送给模型,再度训练它以使其合乎需求。这种做法成本较高,ChatGPT是个拥有1750亿个参数的大语言模型,不可能将自己的数据喂给它微调做对应的子任务模型。另一个具有可行性的思路便是:仅使用ChatGPT对自然语言的理解能力,数据则进行外置搜索,这一思路也是本文将要介绍的内容。
向量和向量数据库
何为向量
向量意指用于描述对象特征的多维数据。当我们想要描述「猫」、「熊猫」和「麦子」的时候,我们需要抽离出它们的特征,并用数字对特征进行标注,这样一来一个具体的对象便被转换为了数学描述。
| 对象 | 是否为生物 | 是否为哺乳类 | 是否可饲养 |
|---|---|---|---|
| 猫 | 1 | 1 | 1 |
| 熊猫 | 1 | 1 | 0 |
| 麦子 | 1 | 0 | 0 |
相似查询
有了对象的向量描述后,AI可以对向量进行相似性查找,例如希望在上例中找到与「狗」最为接近的对象时,可以发现「狗」的向量表示与「猫」是最为相似的,于是「猫」会作为结果返回。
| 对象 | 是否为生物 | 是否为哺乳类 | 是否可饲养 |
|---|---|---|---|
| 狗 | 1 | 1 | 1 |
现实中相似查找的一个典型例子是识图,查询与制定图片相似的目标图片的能力依赖的是对向量的查询,将海量的图片转换为向量,然后在向量与向量之间对比,查询到最相似的结果,向量之间的距离标识了两个对象的相关性 。
向量数据库
向量数据库就是专门用于存储向量的数据库,一般的数据库是没有办法存储海量的向量信息的,也无法支持对向量的快速查找和匹配。
| 向量数据库 与传统数据库的区别 | ||||
|---|---|---|---|---|
| 数据类型 | 存储方式 | 查询方式 | 应用场景 | |
| 传统数据库 | 存储各种类型的数据,例如文本、数字、日期等 | 关系型模型或其他存储方式 | 采用SQL等查询语言进行查询 | 企业应用、网站应用 |
| 向量数据库 | 专门用于存储和管理向量数据 | 基于向量索引的存储方式,将向量数据映射到高维空间中,并在这个空间中构建索引结构,以支持高效的相似度查询 | 基于向量之间的相似度来检索数据 | 人工智能、机器学习、大数据等领域,例如图像搜索、音乐推荐、文本分类等 |
数据嵌入Embedding
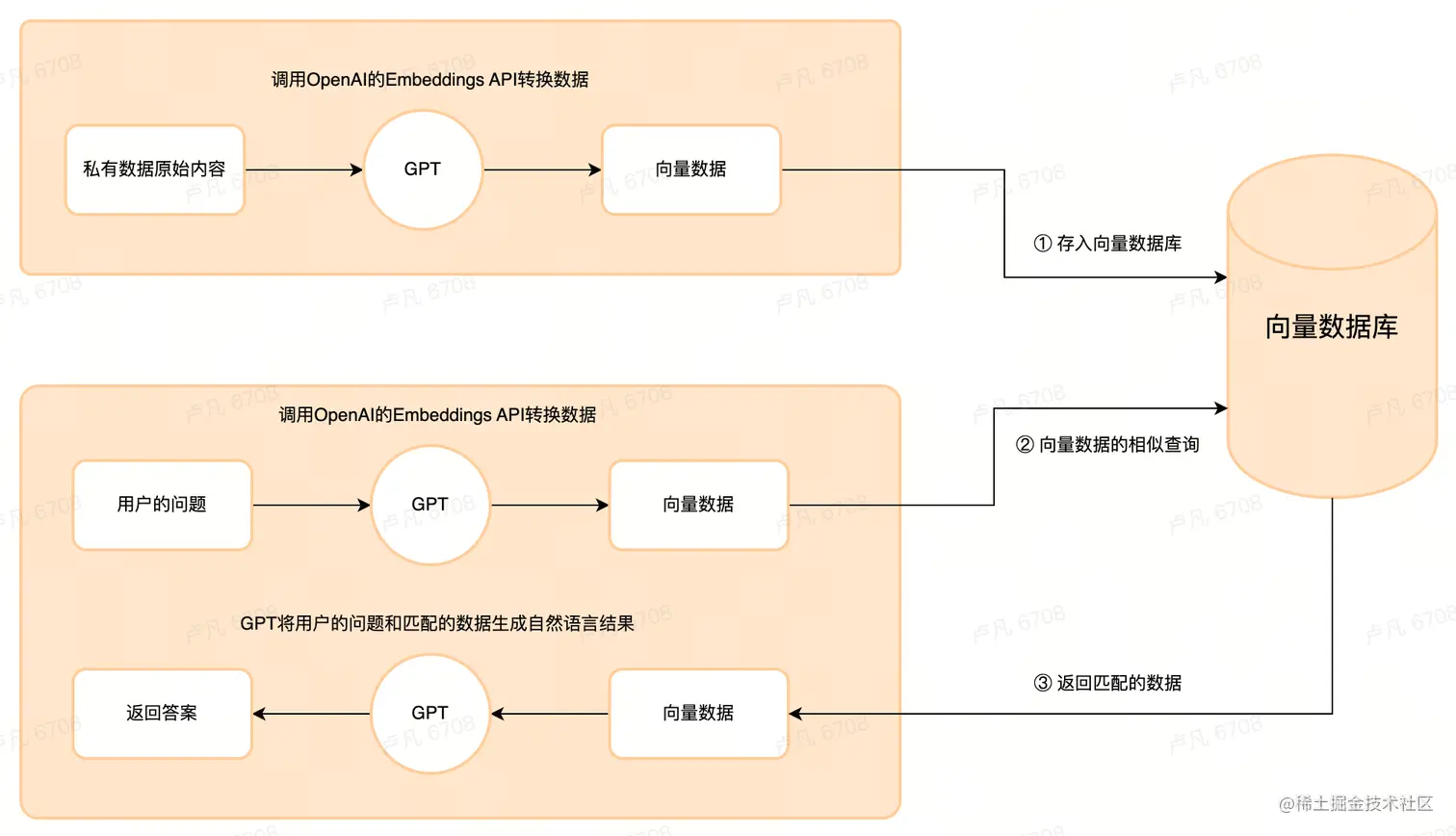
嵌入Embedding意指将对象转换为多维向量描述的这一过程,OpenAI提供了Embeddings API,这个也是 OpenAI API 能实现构建自己知识库的关键所在。
向量问答原理图
LangChain介绍
尽管实现「基于自有知识库实现自然语言的问答」的基本原理已经明确,但实现这一目标还需要一个简单易用的框架,以满足不了解AI技术的非专业人士的需求,LangChain即是这样的一个框架。
基本介绍
LangChain是一个开源的应用开发框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,它提供一个框架将LLM与其他工具或数据源连接起来,创建更强大的应用程序,比如通过 agent 让 gpt 指挥一个机器人干活,它是面向用户程序和 LLM 之间的一个中间层。
LangChain最初支持python语言,23年2月份支持了typescript语言,因而它很适合前端同学作为了解LLM的一个切入点。
框架作用
用户围绕模型构建应用时,更多是在使用它通过思想和记忆进行推理的能力。
OpenAI 的训练数据没有任何企业和个人的私有数据,模型经常给出与事实相悖的答案,直接通过 API 调用模型无法将推理所需的一些事实和知识给到它,模型总是缺少上下文。一个解决方法是在 Prompt 中将知识告诉模型,但是这往往受限于 token 数量,在 GPT-4 之前一般是 4000 个字的限制,绕开 token 数量的限制通常方法借鉴了 Map Reduce 的思想,给文档切片、使用 Embedding 引擎、向量数据库等。
另一方面,模型无法自由的调用外部API、搜索网页、查找数据库等,此前已有诸多探索增强此方面的探索。依托于开源模型与API,LangChain抽象出大量的相关逻辑和代码实现, 开发者们可以直接调用,加速了构建一个应用的速度。
LangChain的意义之一在于提升效率,不再需要复写大量固定逻辑,有了LangChain封装的交互逻辑,实现一个基于私有文档的问答机器人只需要两天时间。
使用示例
看一下示例,「The answer of XX question is A」不在ChatGPT的训练数据中,这里利用LangChain封装的OpenAIEmbeddings将这一信息通过MemoryVectorStore存储在内存中,后续利用RetrievalQAChain回答这些被嵌入的数据。
javascript
javascript复制代码import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { RetrievalQAChain } from "langchain/chains";
// 通过调用 OpenAI 的 Embeddings API 将文本向量化,
// 在这步处理之后,文本就从文字转换为了以向量化存储的信息。
const vectorStore = await MemoryVectorStore.fromTexts(
["The answer of XX question is A", "hello", "hello nice world"],
[{ id: 2 }, { id: 1 }, { id: 3 }],
new OpenAIEmbeddings({
openAIApiKey: "sk-xxx" ,
}),
);
// 进行问答
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());
const result = await chain.call({ query: 'What is the answer of XX question' });运行这段代码后发现,使用了LangChain进行增强的LLM成功回答出了「The answer of XX question is A」这一私有知识内容,而在此之前,ChatGPT是不会回答出用户想要的特定答案的。
\*OpenAIEmbeddings 概念说明
创建文本文件的向量化,OpenAI能实现构建自己知识库的关键。处理完文本之后,就可以对文本进行嵌入(Embeddings)了。通过调用 OpenAI 的 Embeddings API 将文本向量化。在这步处理之后,文本已经不再是文字,而是以向量化存储的信息。
\*MemoryVectorStore 概念说明
用于向量存储,它会将向量存储在内存中。MemoryVectorStore只是LangChain提供的向量存储方法之一,其提供了诸如开源的 Embeddings 数据库 ChromaDB 等多种存储选择。利用向量数据库保存 Embeddings 数据,就可以达到使用数据长期存储和快速调用。
\*RetrievalQAChain 概念说明
Chain可理解为任务,RetrievalQAChain将向量数据中心和问答任务链接起来,可通过自然语言对于文档内容进行提问。这一步中,自然语言的提问同样被转化成向量,由LangChain提供的强大链功能来执行这些问答,寻找到类似的向量类型答案并返回给提问者。
实现基于自有知识库的问答
回顾一下上文的例子,「使用LLM从私有知识库获取答案」的实现可以拆分为:
文本 向量化 (Embeddings)-> 保存向量信息(VectorStore)-> 使用链(Chain)对矢量数据库进行问答
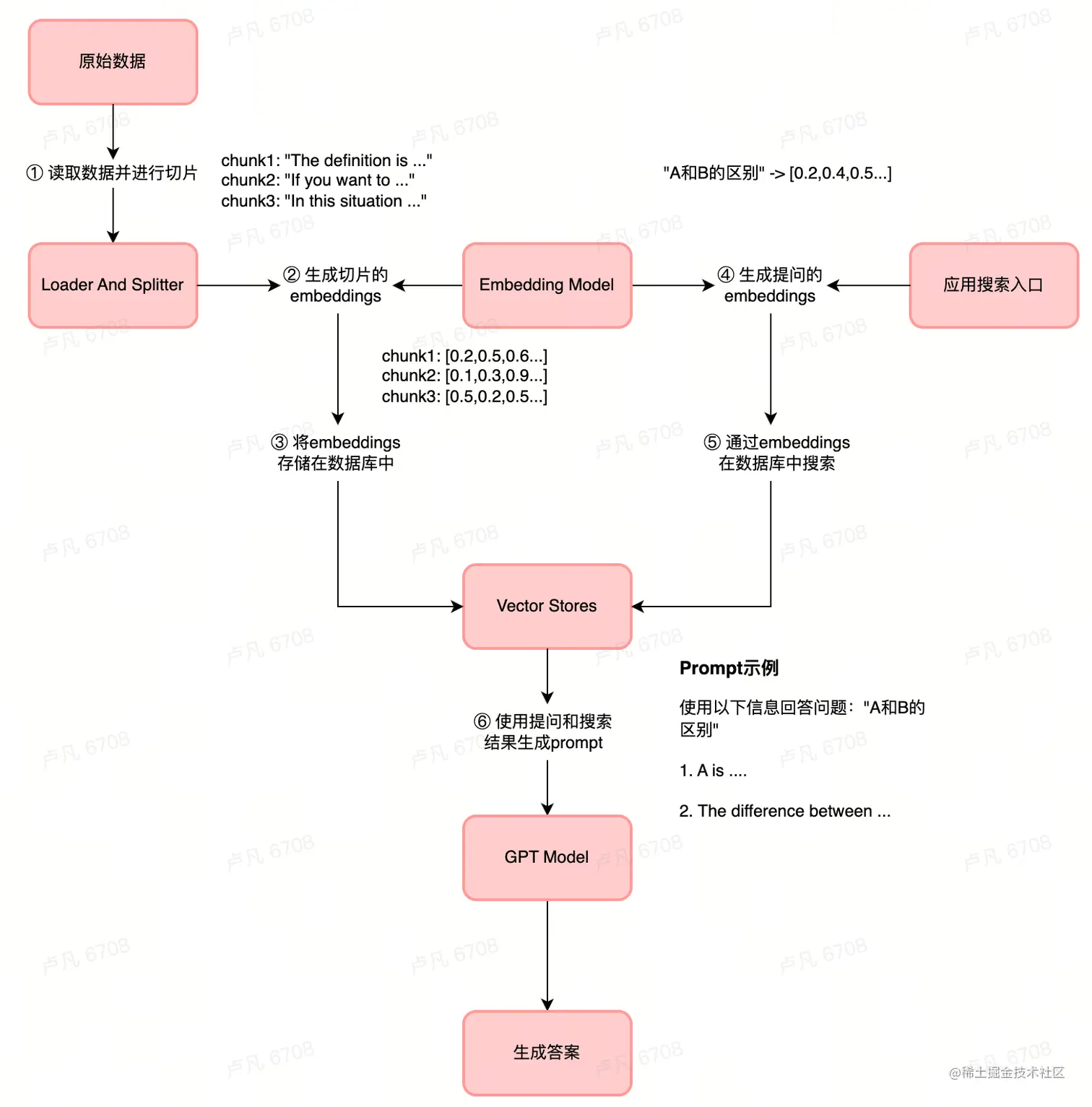
除此之外,为了形成实际可用的「私有知识库LLM」,需要对以上链路进行扩充:
- 从指定源加载全量数据,而不是上例中的简单 字符串 。LangChain内置了多种处理不同数据来源的加载器(Loader),比如文件夹
DirectoryLoader、Azure 存储AzureBlobStorageContainerLoader、CSV文件CSVLoader、任意的网页UnstructuredHTMLLoader、PDFPyPDFLoader。从数据源获取到数据后,将其转换为 Document 对象以供后续使用。 - 文本分割,让 LLM 能够接受数据内容。Embedding 功能是有字符限制的,将一份300页的 pdf 发给 openai api,让它进行总结肯定会报超过最大 Token 的错误,为此需要使用文本分割器去分割我们 loader 进来的 Document。每个文档都是由复杂长短句、多种语法结合写作而成的,可以利用RecursiveCharacterTextSplitter等工具对这些文字进行解构处理。
- 对文本进行嵌入,调用 OpenAI 的 Embeddings API 将文本 向量化。这步处理之后,文本就已经不再是文字,而是以向量化存储的信息,Embedding不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次。后续通过数据库长期存储向量信息,对这些信息的自然语言提问也是基于向量数据的查询与回答。
- 使用链Chain对矢量数据库进行问答。Chain可能来自多个模块的多个组件组成,将「自然语言提问与回答」和「文档内容」进行组合,让LLM针对性的学习特定内容,并基于特定内容回答用户。
整体实现流程如下图所示:
核心原理
Models
model 是一种抽象,表示框架中使用的不同类型的模型,LangChain为各种不同基础模型提供统一接口
arduino
arduino复制代码import { OpenAI } from 'langchain/llms/openai';
// 模型
const model = new OpenAI({
openAIApiKey: process.env.OPEN_AI_API_KEY,
// 简单来说,temperature 的参数值越小,模型就会返回越确定的一个结果。
// 如果调高该参数值,大语言模型可能会返回更随机的结果,也就是说这可能会带来更多样化或更具创造性的产出。
// 在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。
// 对于诗歌生成或其他创造性任务,可以适当调高 temperature 参数值。
temperature: 0.9,
});模型类Model是LangChain的核心组件,LangChain作为粘合剂并不提供模型,而是提供与主流模型沟通的接口。LangChain封装的Model可分为三类:基于文字的大语言模型LLMs、引入对话概念的聊天模型Chat Models和提供能力将文本数据转为数字表达的嵌入模型Embeddings Model。
- LLMs将文本字符串作为输入并返回文本字符串作为输出,它们是许多语言模型应用程序的支柱。
- Chat Models由语言模型支持,但和LLMs不同的是它们具有更结构化的 API,他们将聊天消息列表作为输入并返回聊天消息,这使得管理对话历史记录和维护上下文变得容易。
- Embeddings Model在整合「大语言模型」和「自有数据库」上起到关键作用,其本质是利用了语言模型提供的Embeddings API能力,将外部数据与模型结合,支持基于向量的相似性搜索等。
Chat Models
ChatGPT是语言模型,它可以理解用户的问题。这一特性意味着,和使用明确指向性命令的传统编程不同,使用ChatGPT这类大语言模型需要「告知」模型该如何做,它就如同和用户合作的另一位人,在与其合作时需要用自然语言告知它如何行动。
就像和人类合作时需要简洁、精准的语言一样,与模型合作同样需要高质量的沟通。什么样的语言才能更好的发挥ChatGPT的能力,对这个问题的解答形成了新的提示词工程学科Prompts Engineer。
Embedding Models
ChatGPT对外提供了embedding能力,将被给予的文字转化为向量这种数字表示。文本嵌入有助于从文本中提取信息,供后续使用,这些嵌入可用于文档检索、聚类和相似性比较等任务。不同的模型提供了不同的Embeddings能力,LangChain将这些实现进行一系列封装,下文将用到OpenAi Embedding模型的封装类OpenAIEmbeddings。

Prompts
prompts作用是给模型的指令,它是指一段文本或语句,用于引导机器学习模型生成特定类型、主题或格式的输出。
一般来说我们不会直接把输入给模型,而是将输入和一些别的句子连在一起,形成prompts之后给模型。想要获得预期的良好输出需要对提示进行相当多的调整,这个过程称为提示工程。
例子
| 提示词 | 输出结果 | 说明 |
|---|---|---|
| The sky is | blueThe sky is blue on a clear day. On a cloudy day, the sky may be gray or white. | 语言模型能够基于我们给出的上下文内容 "The sky is" 完成续写。输出的结果可能是出人意料的,或远高于我们的任务要求。如果想要实现更具体的目标,我们还必须提供更多的背景信息或说明信息。 |
| 完善以下句子:The sky is | so beautiful today. | 本例中,我们告知模型去完善句子,因此输出的结果和我们最初的输入是完全符合的。 |
提示工程(Prompt Engineering)就是探讨如何设计出最佳提示词,用于指导语言模型帮助我们高效完成某项任务。
在问答系统中,Prompt 可以被看做是一个问题或任务描述,例如"回答下面这个问题:EdenX和Eden2.0的区别?"。通过给定这样的 Prompt,模型可以生成相应的回答或翻译结果。
LangChain 内置的一段 prompt 模版:
vbnet
vbnet复制代码// langchainjs/blob/main/langchain/src/agents/mrkl/prompt.ts
export const PREFIX = `Answer the following questions as best you can. You have access to the following tools:`;
export const FORMAT_INSTRUCTIONS = `Use the following format in your response:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question`;
export const SUFFIX = `Begin!
Question: {input}
Thought:{agent_scratchpad}`;LangChain 内置的Prompt是优秀的范例,上文所示为LangChain内置的一段prompt模版,用来告知语言模型「从给定的工具集中选择合适的工具回答问题,可以重复思考直至得到结论」
提示工程是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型用于各场景和研究领域,掌握了提示工程相关技能将有助于更好地了解大型语言模型的能力和局限性。学习提示词工程可参照此篇文档或此课程。
链式思考Chain-of-Thought提示
足够大的语言模型涌现出名为思维链Chain of Thought的能力,这一能力的产生原因不明。
在给定的问答样例中将步骤进行拆解,使用分而治之的思想把复杂问题切分为一个个步骤,接下来大模型能够理解一步步思考的意义,在回答问题时的正确率会大大上升。
如果不给定样例,仅仅是在提问中加入一句「让我们逐步思考」也能够有效提升回答问题的正确率,这被称为零样本COT提示,简单的提示有时会特别有用。
CoT 微调的模型在涉及常识、算术和符号推理的任务上表现得更好。
Indexes
外部数据处理
语言模型仅仅知道它们的训练数据,为了回答训练数据范围以外的问题需要将信息传递给模型,为此第一步是从外部数据源得到数据内容并处理。
Loader And Splitter
处理数据的基本逻辑是: 连接到数据源 -> 拉取数据 -> 按照指定的大小切块。
LangChain提供非常多的内置Loader,可以处理文件与网络资源,涵盖多种格式,使用方式可参考官网示例。这里体现出LangChain的一大价值在于强大的内置功能封装,用户无需考虑文件格式的不同,只需要调用内置方法进行处理即可。
javascript
javascript复制代码import { DirectoryLoader } from 'langchain/document_loaders/fs/directory';
import { TextLoader } from 'langchain/document_loaders/fs/text';
import { PDFLoader } from 'langchain/document_loaders/fs/pdf';
// 文件加载
const loader = new DirectoryLoader(`src/documents/TxtFiles/docs`, {
'.txt': (path) => new TextLoader(path),
'.pdf': (path) => new PDFLoader(path),
'.md': (path) => new TextLoader(path),
});
const docs = await loader.load();在得到了数据之后需要对数据进行切片,做这一步是由于大语言模型自身的限制,它们会限制能够传递给它们的文本总量。LangChain提出了Document这一抽象结构体与模型交互,所有的外部信息无论来源于格式都会被转换为Document结构,以此封装与模型进行数据交互的逻辑。
typescript
typescript复制代码import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
// 给定分片大小,创建分片处理工具
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
});
// 将给定的文档进行切分,切分后的结构是Document[]
const splitDocs = await textSplitter.splitDocuments(docs);
// 其中,Document对象的pageContent属性用于与模型交互,metadata用户记录额外信息。
interface Document {
// 和语言模型进行交互
pageContent: string;
// 记录元数据, 例如来源
metadata: Record<string, any>;
}Vector Stores
数据相关性搜索其实是向量运算,不管我们是使用 openai api embedding 功能,还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。
在LangChain中,VectorStore类封装了操作向量数据库的操作,存储Document和其对应的embeddings向量,后续查询时找到与问题最相关的Document,实际上指的就是找到与「问题的embedding」最相似的「数据库中的embedding」。
javascript
javascript复制代码import { OpenAIEmbeddings } from 'langchain/embeddings/openai';
import { HNSWLib } from 'langchain/vectorstores/hnswlib';
// 生成向量数据
const vectorStore = await HNSWLib.fromDocuments(
splitDocs,
new OpenAIEmbeddings({
openAIApiKey: process.env.OPEN_AI_API_KEY,
}),
);Chains
将大语言模型与其他组件相结合
链(chain)的作用是将 LLM 与其他信息源或者 LLM 给连接起来,比如调用搜索 API 或者是外部的数据库等
使用示例
- LLMChain:将 LLM 与提示模板相结合
- Sequential Chain : 将第一个 LLM 的输出作为第二个 LLM 的输入来串联多个 LLM
- Index Related Chains:将 LLM 与外部数据相结合,例如用于问答
如下所示便是与外部数据结合的chain:
javascript
javascript复制代码import { RetrievalQAChain } from 'langchain/chains';
// 将向量数据和模型结合起来,形成问答链
// RetrievalQAChain归属为Index Related Chains一类
const chainFromCache = RetrievalQAChain.fromLLM(
model,
// 这里的vectorStore就是向量数据库对应的类,是外部数据
vectorStore.asRetriever(),
);
// 调用问答链回答问题
const rFromCache = await chainFromCache.call({
query: 'What is The 2022 World Cup winner',
});源码解析
Chain是LangChain的核心思想之一,看一下内部调用过程,以下代码做了删减,仅保留主逻辑。
实例化fromLLM
arduino
arduino复制代码// langchain/src/chains/retrieval_qa.ts
// -------- RetrievalQAChain ---------------
// 生成自身实例
static fromLLM(
llm: BaseLanguageModel,
retriever: BaseRetriever,
): RetrievalQAChain {
// langchain/src/chains/question_answering/load.ts
// 将llm和prompt传入 -> 生成Chain实例
export function loadQAStuffChain(llm: BaseLanguageModel) {
const llmChain = new LLMChain({ QA_PROMPT_SELECTOR.getPrompt(llm), llm });
const chain = new StuffDocumentsChain({ llmChain, verbose });
return chain;
}
const combineDocumentsChain = new loadQAStuffChain(llm);
return new this({ retriever, combineDocumentsChain, });
}调用过程call
可以看到回答问题的调用过程依次经历了RetrievalQAChain、StuffDocumentsChain和LLMChain的调用,每一步会使用一些外部方法用于处理数据等,最终一步步链式完成内容。
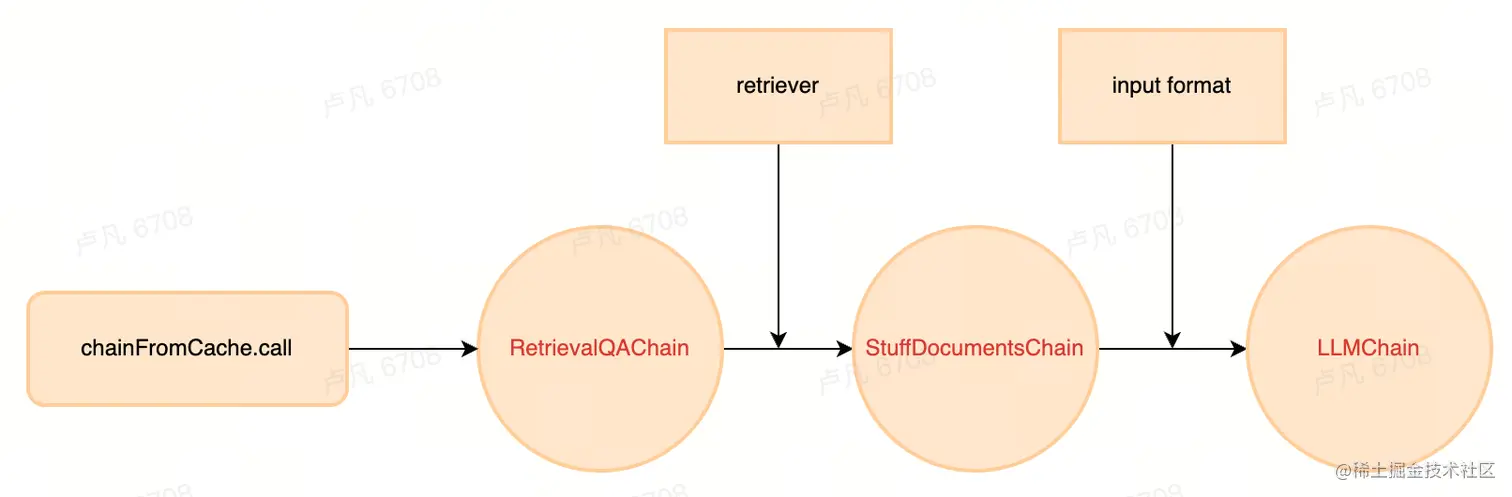
typescript
typescript复制代码// langchain/src/chains/retrieval_qa.ts
// -------- RetrievalQAChain ---------------
export class RetrievalQAChain extends BaseChain
// 运行chain的核心逻辑
async _call(
values: ChainValues,
runManager?: CallbackManagerForChainRun
): Promise<ChainValues> {
const question: string = values[this.inputKey];
// 使用retriever进行向量相似查询,找到相关数据
const docs = await this.retriever.getRelevantDocuments(question);
const inputs = { question, input_documents: docs };
// 将数据交给combineDocumentsChain进行处理
const result = await this.combineDocumentsChain.call(
inputs,
runManager?.getChild("combine_documents")
);
return result;
}
// -------- StuffDocumentsChain ---------------
// langchain/src/chains/combine_docs_chain.ts
// 处理数据格式并执行llmChain的call
async _call(
values: ChainValues,
runManager?: CallbackManagerForChainRun
): Promise<ChainValues> {
const result = await this.llmChain.call(
// 这个chain是文档处理相关的,因而提供方法对数据进行格式化
((values) => docs: Document[]),
runManager?.getChild("combine_documents")
);
return result;
}
// -------- LLMChain ---------------
// langchain/src/chains/llm_chain.ts
// 将输入交给llm得到回答
async _call(
values: ChainValues & this["llm"]["CallOptions"],
runManager?: CallbackManagerForChainRun
): Promise<ChainValues> {
const promptValue = await this.prompt.formatPromptValue({ ...values });
const { generations } = await this.llm.generatePrompt(
[promptValue],
runManager?.getChild()
);
return {
"text": generations[0],
};
Agents
根据 LLM 的输出来决定使用哪些工具来完成任务
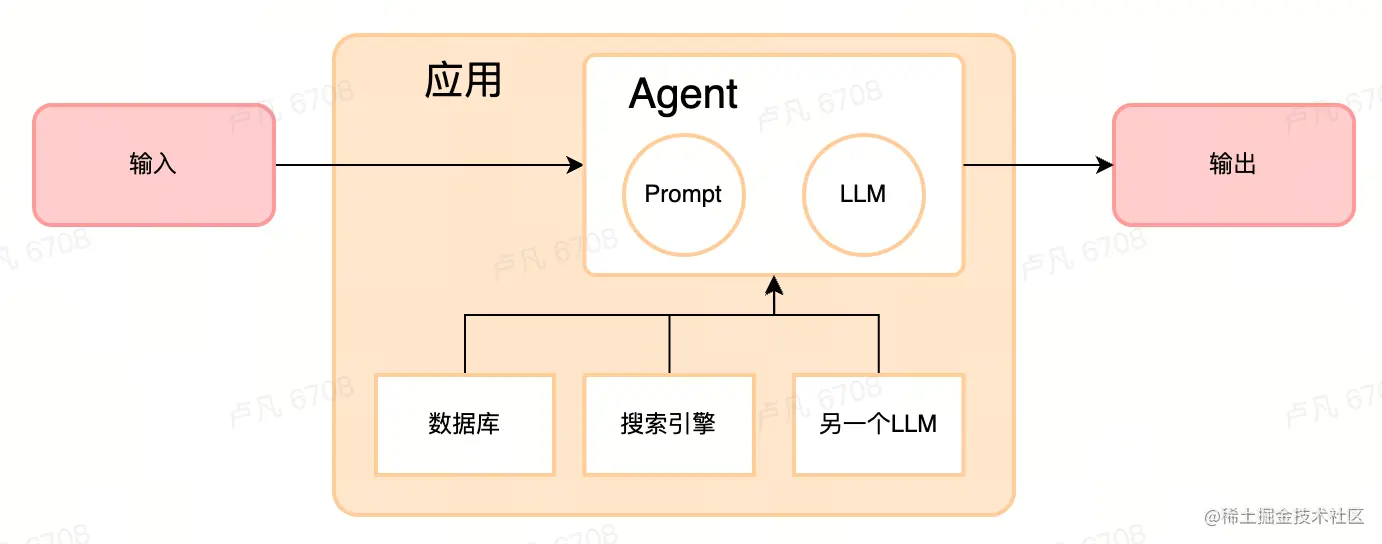
Agent 负责调用大模型,并且决定接下来的动作,调用大模型的结果是做决定的参考。
在 Chain 里,数据的来源和流动方式相对固定,而在 Agent 里,LLM 可以自己决定采用什么样的行动、使用哪些工具Tool,这些工具可以是搜索引擎、各类数据库、任意的输入或输出的字符串,甚至是另一个 LLM、Chain 和 Agent。
作为 Agent 的 LLM 体现了思维链的能力,充当了交通指挥员或者路由者的角色,Agent依赖于Chain完成调度。
Tools
Tool是一个执行特定职责的方法,通过属性name和description与模型交流,description属性告知模型Tool的作用以及什么时候应当使用。LangChain内置了大量Tool,例如使用搜索引擎获取数据的SerpAPI Tool。当然,用户也可以自定义自己的Tool。
创建自定义Tool
php
php复制代码interface Tool {
call(arg: string): Promise<string>;
name: string;
description: string;
}
const qaTool = new ChainTool({
// name标识这个自定义的Tool
name: 'state-of-union-qa',
// 当问题有关于体育时,需要使用自定义的qaTool
description:
'State of the Union QA - useful for when you need to ask questions about sports.',
chain: chain,
});
const tools = [new Calculator(), qaTool];
// https://js.langchain.com/docs/modules/agents/agents/action/llm_mrkl
// MRKL Agent for LLMs 基于tools的description 让模型决定执行什么操作
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: 'zero-shot-react-description',
// 这个verbose设置为true会将模型思考的过程打印出来
verbose: true,
});进入initializeAgentExecutorWithOptions源码可以看到如下内容,在这里发现了一个熟悉的代码fromLLMAndTools,因而initializeAgentExecutorWithOptions所做的事情其实是将用户自定义的工具、选定的模型和内置的prompt送入LLMChain构造方法,创造出一个符合用户需求的模型类,这个模型类会承担起回复用户回答的职责。
javascript
javascript复制代码// langchain/src/agents/initialize.ts
export async function initializeAgentExecutorWithOptions(
tools: Tool[],
llm: BaseLanguageModel,
options = {
agentType: "zero-shot-react-description",
}
): Promise<AgentExecutor> {
switch (options.agentType) {
case "zero-shot-react-description": {
return AgentExecutor.fromAgentAndTools({
agent: ZeroShotAgent.fromLLMAndTools(llm, tools as Tool[]),
tools,
});
}
}
// langchain/src/agents/chat/index.ts
static fromLLMAndTools(
llm: BaseLanguageModel,
tools: Tool[]
) {
ChatAgent.validateTools(tools);
// 此处的prompt用到了上文提及的createPrompt能力
const prompt = ChatAgent.createPrompt(tools, args);
const chain = new LLMChain({
prompt,
llm
});
const outputParser = ChatAgent.getDefaultOutputParser();
return new ChatAgent({
llmChain: chain,
outputParser,
allowedTools: tools.map((t) => t.name),
});
}
// langchain/src/agents/chat/index.ts
/**
* 利用其Chain能力将 LLM 与提示模板相结合。
* @param tools - List of tools the agent will have access to, used to format the prompt.
* @param args - Arguments to create the prompt with.
* @param args.suffix - String to put after the list of tools.
* @param args.prefix - String to put before the list of tools.
*/
static createPrompt(tools: Tool[], args?: ChatCreatePromptArgs) {
const {
prefix = PREFIX,
suffix = SUFFIX,
} = args ?? {};
const toolStrings = tools
.map((tool) => `${tool.name}: ${tool.description}`)
.join("\n");
const template = [prefix, toolStrings, FORMAT_INSTRUCTIONS, suffix].join("\n\n");
const messages = [SystemMessagePromptTemplate.fromTemplate(template)];
return ChatPromptTemplate.fromPromptMessages(messages);
}逻辑汇总
从外部读取数据,利用LLM进行问答的完整代码如下,三次输出分别是利用原生的GPT3.5API、问答Chain和使用自定义Tool的Agent:
javascript
javascript复制代码// node-v18版本
import { OpenAI } from "langchain/llms/openai";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { RetrievalQAChain, VectorDBQAChain } from "langchain/chains";
import { ChainTool } from "langchain/tools";
import { initializeAgentExecutorWithOptions } from "langchain/agents";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { Calculator } from "langchain/tools/calculator";
// 模型
const model = new OpenAI({
openAIApiKey: 'sk-xxx',
temperature: 0.9,
});
// 使用Model回答问题
const resFromModel = await model.call('lufan is a person, please give the company name and id of lufan');
console.log('===========================');
console.log('resFromModel:', resFromModel);
// 文件加载
const loader = new TextLoader("src/docs/oz.txt");
const docs = await loader.load();
// 切片
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
});
const splitDocs = await textSplitter.splitDocuments(docs);
// 创建向量
const vectorStore = await MemoryVectorStore.fromDocuments(
splitDocs,
new OpenAIEmbeddings({
openAIApiKey: 'sk-xxx',
})
);
// 创建问答链
const chain = RetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
);
// 使用Chain回答问题
const resFromChain = await chain.call({ query: 'Give the company name and id of lufan' });
console.log('===========================');
console.log('resFromChain', resFromChain);
// 自定义工具
const qaTool = new ChainTool({
name: 'state-of-union-qa',
description:
'State of the Union QA - useful for when you need to ask questions about personal information.',
chain: chain,
});
const tools = [new Calculator(), qaTool];
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: 'zero-shot-react-description',
// 将log打印出来
verbose: true,
});
// 使用Agent回答问题
const resFromAgent = await executor.call({ input: `lufan is a person, please give the company name and id of lufan` });
console.log('===========================');
console.log('resFromAgent', resFromAgent);运行可得到如下结果,可以看到原生的GPT3.5API无法得到想要的结果,而问答Chain和Agent均成功了。在初始化agent时指定了将运行日志打印出来
总结
GPT模型的应用与探索已有诸多文档,本文主要是聚焦于其中一个小方向的尝试,即「提升文档站的搜索效率」。此处的尝试浅尝辄止,实现demo并不意味着足以验证其落地价值,在实际的应用中很有可能因为缺少足够的数据量等原因得不到预期的效果,本文更多的是做一种交流探索。
ChatGPT 改变交互
ChatGPT理解用户的问题,意味着使用它能够有效减少软件的复杂度,一些复杂的操作流程可以通过询问AI得到解决,不再需要用户寻找各种操作入口或记住繁琐的指令。
本文展示的内容是一个小型的交互改变示例,大模型促进了新的提问模式的出现,产品交互的改变一定会到来,由最初的命令行转向现在的图形界面,未来还会增加更多语言操作的入口,集成AI能力主要用途之一是让产品变的更加易用,来综合提升产品的用户体验。
当然需要注意的是,与图形界面不同的是,AI问答是不确定的,不能保证稳定的输入输出。另一方面,一些简易的操作使用AI问答反而增加了交互的复杂度,得不偿失。没有绝对的问题解决手段,实际环境很复杂,需要细致的讨论。
LangChain 总结
LangChain是基于开源库的开源库,通过优秀的代码封装极大节省了开发者的人力成本,它将核心能力进行抽象,开发者通过API调用将这些能力串联起来。
全过程一站式的集成
本文介绍的LangChain能力只是冰山一角,实际上非结构化数据的预处理到不同模型结果的评估,LangChain对于开发者所需要的工具和库基本都有现成的集成。Hugging Face、OpenAI、Cohere 等提供底座模型和 API,LangChain帮助开发者在产品中集成和使用它们。
Model as a Service
LangChain抹平DATA层,使得用户可以更自由地在多个 LLM、Embedding 引擎等之间切换,以避免单点风险和降低成本。
开源社区高速发展
LangChain将持续获得最新的特性支持,这种灵活度以及不受限于某家特定公司的自由度能确保LangChain在长久的时间内的流行度。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。