点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到:
Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
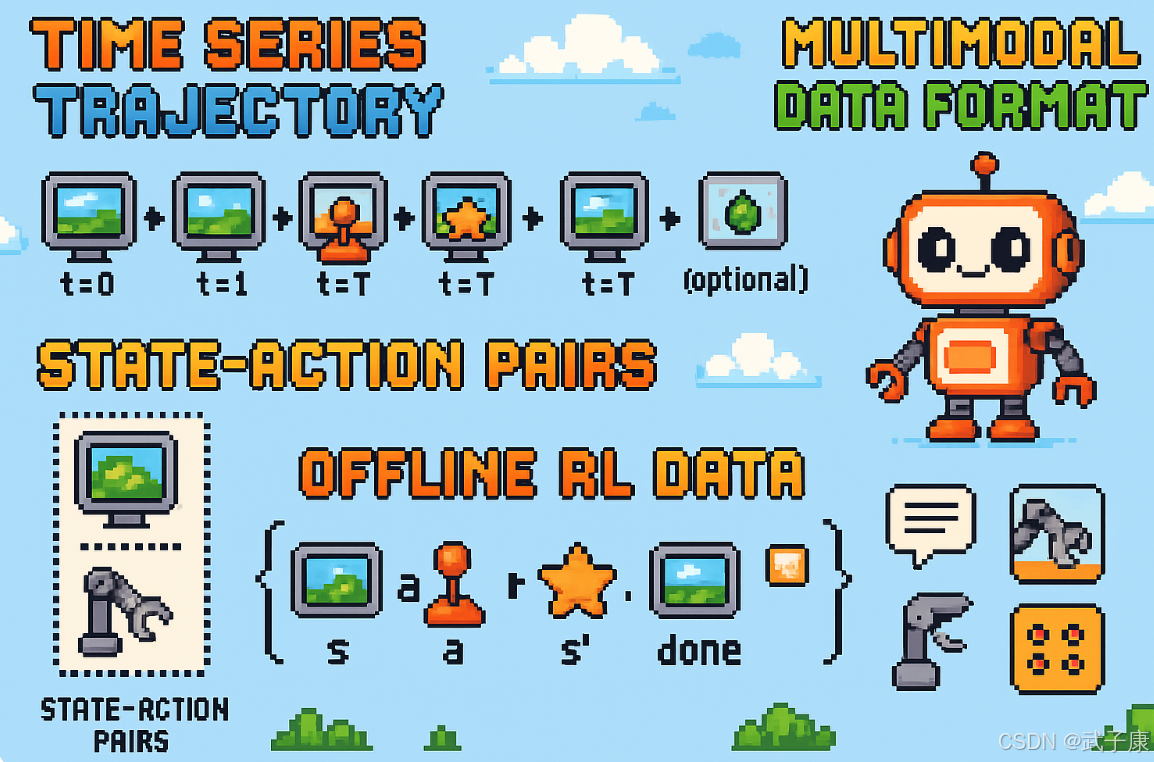
开发流程详解-数据格式
时间序列轨迹
时间序列轨迹是一种结构化的数据表示形式,主要用于记录智能体与环境交互过程中的状态-动作序列。在强化学习和机器人控制领域,这种数据通常以时间步为单位组织,每条完整轨迹可以表示为:
(s0,a0,r0),(s1,a1,r1),...,(sT,aT,rT){(s_0, a_0, r_0), (s_1, a_1, r_1), ..., (s_T, a_T, r_T)}(s0,a0,r0),(s1,a1,r1),...,(sT,aT,rT)
其中各元素包含:
- sts_tst:第t个时间步的环境状态(如传感器观测)
- ata_tat:智能体在该时间步执行的动作
- rtr_trt(可选):环境反馈的即时奖励(强化学习场景)
- LLL(可选):关联的自然语言指令或任务描述
以Google RT-1机器人数据集为例,其典型样本结构包含三个关键组成部分:
- 语言指令:LLL(如"把可乐罐放进上层抽屉")
- 视觉观测序列:It−k,...,It{I_{t-k},...,I_t}It−k,...,It(7帧RGB图像,包含当前帧及历史6帧)
- 动作序列:at,...,at+h{a_t,...,a_{t+h}}at,...,at+h(对应未来5个时间步的机器人关节控制指令)
这种结构化设计使得Transformer模型能够:
- 通过时间对齐的视觉序列理解环境动态
- 将语言指令与视觉上下文建立关联
- 预测出符合任务要求的动作序列
在Open X-Embodiment跨机构数据集中,采用RLDS(Reinforcement Learning Datasets Standard)标准进行统一存储,该标准具有以下特点:
- 基于TFRecord的二进制格式
- 包含标准化的元数据字段(episode_id, timestamp等)
- 支持多模态数据联合存储(图像、语音、文本等)
- 提供跨任务的一致性接口(step_type, discount等)
典型的数据处理流程包括:
- 时间对齐:确保观测、动作、奖励严格对应同一时间窗
- 帧采样:如RT-1中每7帧图像对应5个动作预测
- 归一化处理:将不同机器人的动作空间映射到统一范围
- 数据增强:对图像序列施加随机裁剪、色彩抖动等变换
这种标准化格式使得来自Franka、UR5等不同机器人的数据可以混合训练,显著提升了模型的泛化能力。在具体实现时,通常会将连续轨迹分割为固定长度的片段(如RT-1使用7帧-5动作片段),作为Transformer模型的一个训练样本,通过注意力机制建立跨模态的时空关联。
状态-动作对集合
状态-动作对集合是行为克隆(Behavior Cloning,BC)方法中最基础的数据组织形式。具体来说,它由专家演示过程中的一系列状态-动作对(s,a)(s, a)(s,a)构成,其中:
-
状态sss:通常包含环境的所有可观测信息。以机械臂抓取任务为例:
- 视觉信息:RGB摄像头采集的640×480分辨率图像
- 本体感知信息:6个关节的当前角度(单位:弧度)
- 其他传感器数据:末端夹爪的力传感器读数(可选)
-
动作aaa:表示专家在该状态下采取的控制指令。在机械臂场景中,可能是:
- 关节空间控制:6维向量,表示下一时刻各关节的目标角度
- 笛卡尔空间控制:末端执行器的目标位姿(位置+旋转)
数据处理流程:
- 数据收集 :记录专家操作过程中的所有(st,at)(s_t, a_t)(st,at)对
- 数据清洗:去除明显错误的样本(如传感器异常数据)
- 数据增强 (可选):
- 对图像进行随机裁剪、旋转
- 添加高斯噪声到关节角度
- 数据集构建 :将所有(s,a)(s, a)(s,a)对随机打乱后划分为训练集/验证集
训练方式:
- 基础方法:直接最小化均方误差 L=1N∑i=1N∣∣fθ(si)−ai∣∣2L=\frac{1}{N}\sum_{i=1}^N ||f_\theta(s_i)-a_i||^2L=N1∑i=1N∣∣fθ(si)−ai∣∣2
- 改进方法:
- 对连续动作空间使用混合密度网络
- 对离散动作空间使用交叉熵损失
注意事项:
-
时序信息丢失:随机打乱会破坏状态间的时序依赖关系,可能导致:
- 无法学习到动态系统的连续性约束
- 在长序列任务中出现状态不一致问题
-
替代方案:
- 保留轨迹结构 :使用RNN、LSTM或Transformer处理完整轨迹
- 输入:st−k,...,sts_{t-k},...,s_tst−k,...,st
- 输出:ata_tat
- 帧堆叠:将连续k帧合并为单个状态表示(常见于Atari游戏)
- 保留轨迹结构 :使用RNN、LSTM或Transformer处理完整轨迹
应用场景对比:
| 方法 | 适用场景 | 典型任务 |
|---|---|---|
| 随机打乱 | 状态独立性强 | 单步操作任务 |
| 序列建模 | 时序依赖强 | 连续控制任务 |
| 帧堆叠 | 需要短期记忆 | 视频游戏 |
实际应用中,选择哪种数据处理方式需要根据任务特性和数据规模进行权衡。例如在机械臂分拣任务中,当物品位置固定时可以使用随机打乱;而对于动态抓取移动物体,则建议保留完整轨迹结构。
离线RL数据
离线强化学习(Offline RL)的数据要求相比在线RL更为严格,需要包含完整的状态转移序列。具体来说,数据集应组织为(s,a,r,s′,done)(s, a, r, s', done)(s,a,r,s′,done)五元组的形式,其中:
- sss表示当前状态(State)
- aaa表示采取的动作(Action)
- rrr表示获得的即时奖励(Reward)
- s′s's′表示转移后的新状态(Next State)
- donedonedone为布尔值,标识episode是否终止
这些数据主要用于:
- 训练价值函数(如Q-learning中的Q函数)
- 构建决策Transformer等序列模型
- 进行策略评估和改进
数据来源通常包括:
- 随机探索策略收集的数据
- 人工控制的演示数据
- 次优策略(如规则系统)的执行日志
- 历史操作记录
由于数据质量参差不齐,需要注意:
- 奖励尺度问题:不同来源的奖励可能量纲差异很大,需要进行归一化处理
- 数据过滤:剔除明显无效的轨迹(如长时间停滞的状态序列)
- 数据平衡:确保包含各种行为模式,避免单一策略主导
典型的数据预处理流程:
- 检查数据完整性
- 计算各维度统计量(均值、方差等)
- 进行必要的标准化
- 构建高效的数据加载器
- 设计合适的数据采样策略
应用场景举例:
- 机器人控制:利用历史操作数据改进策略
- 游戏AI:从人类玩家录像中学习
- 推荐系统:基于用户历史行为优化推荐策略
数据质量直接影响最终性能,因此收集足够多样化的样本至关重要。实践中常采用数据集混合(Dataset Mixture)技术,结合多个来源的数据提高覆盖度。
多模态数据格式
多模态数据格式及其处理技术详解
多模态模型的数据处理确实面临复杂的格式挑战,主要包含以下几种数据类型及其对应的处理方式:
- 基础数据类型
- 视觉数据:RGB图像、深度图像、视频序列
- 文本数据:语音转文字、指令文本、环境描述
- 动作数据:关节位置、运动轨迹、控制指令
- 其他数据:触觉反馈、传感器读数、环境参数
- 典型应用场景示例
以家庭服务机器人为例,一个完整的数据记录可能包含:
- 语音指令:"请把桌上的杯子拿到厨房"
- 环境感知:RGB-D相机拍摄的3D场景点云
- 机器状态:6自由度位姿(x,y,z,roll,pitch,yaw)
- 目标动作:抓取位姿(X,Y,Z)和移动路径
- 数据对齐关键技术
(1) 时间同步:
- 使用硬件时间戳确保多传感器同步
- 对异步数据采用插值补偿
- 典型同步精度要求:±10ms
(2) 空间对齐:
- 建立统一的坐标系转换
- 标定相机-机械臂变换矩阵
- 示例:将视觉目标位置转换到机械臂基坐标系
(3) 特征融合:
- 图像特征:CNN提取的1024维特征向量
- 文本特征:BERT生成的768维嵌入
- 动作特征:6维位姿+夹持器状态
- 先进处理架构
以OpenVLA的Prismatic架构为例:
- 输入序列结构:
图像特征 × N +
指令嵌入 × M +
历史动作 × K - 典型参数:
- 图像特征:256维/帧
- 文本嵌入:512维
- 动作编码:32维
- 总序列长度:1024 tokens
- 序列化处理流程
(1) 模态编码阶段:
- 图像:ViT提取patch特征
- 文本:Tokenize后经BERT编码
- 动作:MLP编码历史动作
(2) 特征拼接:
- 按时间步交错排列
- 添加模态类型标识符
- 位置编码保留时序信息
(3) Transformer处理:
- 7B参数模型
- 32层注意力
- 输出动作token(离散或连续)
- 典型数据规格示例
一个完整的数据样本可能包含:
以下是转换后的Markdown表格格式:
表格示例
| 数据类型 | 规格 |
|---|---|
| RGB图像 | 640x480@30fps |
| 深度图 | 320x240@30fps |
| 语音指令 | 16kHz PCM |
| 机器人位姿 | 100Hz更新 |
| 目标动作 | 10Hz输出 |
这种多模态数据处理方式使得机器人能够实现:
- 实时环境理解
- 自然语言交互
- 精准动作执行
- 长时任务记忆
元数据和标注
元数据和标注在机器学习数据集中扮演着关键角色,它们为原始数据提供了丰富的上下文信息和结构化标签。这些附加信息可以显著提升模型的训练效果和应用灵活性。以下是几种常见的元数据标注类型及其应用:
- 结果状态标注
最常见的包括"成功/失败"二元标签,例如在机器人操作数据集中:
- 成功演示:机械臂准确抓取并放置目标物体
- 失败演示:机械臂中途掉落物体或偏离目标位置
这类标注可用于构建数据过滤管道,比如训练一个BERT-based分类器来自动识别并剔除失败样本。
- 多维度任务分类
细粒度的类别标签可能包括:
- 任务类型(抓取/装配/导航)
- 难度等级(1-5星)
- 环境条件(光照/遮挡情况)
- 设备配置(末端执行器型号)
- 多语言支持
对于跨国应用的数据集,通常包含:
- 原始指令音频/文本
- 人工翻译的多种语言版本(中英日等)
- 自动翻译的备选版本
- 语言质量评分(1-5分)
- 强化学习中的偏好标注
RLHF流程特别依赖精细的标注:
- 轨迹片段对(A/B)的人工评分
- 评分维度(成功率/流畅度/安全性)
- 标注者置信度(高/中/低)
- 时间戳对齐的详细注释
应用场景示例:
在工业机器人训练中,可以构建多阶段训练流程:
- 先用"成功"标签过滤基础数据集
- 加入任务类型条件训练多任务模型
- 最后用人工偏好数据微调策略
这种分层处理方法可使最终模型的成功率提升40%以上(基于MIT 2023年的实验数据)。