摘要
高斯投影(Gaussian Splatting)实现了高质量、实时的三维场景新视点合成。不过,它仅专注于外观和几何建模,缺乏对细粒度的物体级场景理解。为了解决这一问题,我们提出了 Gaussian Grouping,将高斯点扩展为联合重建和分割开放世界三维场景中的任意内容。我们为每个高斯添加了一个紧凑的身份编码(Identity Encoding),使得这些高斯点能够根据其在三维场景中的物体实例或"物体/背景"的成员关系进行分组。并不依赖昂贵的三维标签,我们在可微渲染过程中通过利用 Segment Anything Model (SAM) 的二维掩码预测,以及引入的三维空间一致性正则化,对身份编码进行监督。与隐式的 NeRF 表示相比,我们表明离散且分组的三维高斯点能够在三维中以高视觉质量、细粒度和高效性来重建、分割和编辑任意内容。
引言
本文旨在构建一个 expressive 的三维场景表示,不仅对外观和几何进行建模,还捕捉场景中每个实例和物体的身份信息。我们的方法以最近的三维高斯投影(Gaussian Splatting)为基础,将其从纯粹的三维重建扩展到细粒度的场景理解。提出的"Gaussian Grouping"方法能够做到:
- 同时对场景的每个三维部分进行外观、几何和它们的掩码身份的建模;
- 将三维场景完全分解为离散分组,例如表示不同对象实例以便进行编辑;
- 在不降低原始三维重建质量的前提下,实现快速训练和渲染。
Gaussian Grouping 有效地利用了 SAM 的密集二维掩码提案,并通过辐射场渲染将其提升到三维场景中的任意物体的分割。
方法
3D Gaussian Grouping
在本节中,我们将介绍 Gaussian Grouping 的设计。为了使三维高斯点具备细粒度场景理解能力,我们的核心思路是:在保持高斯点原有属性(如位置、颜色、不透明度和大小)不变的前提下,新增身份编码参数(Identity Encoding),其格式类似于颜色建模。这使得每个高斯点都能够被分配到在三维场景中所表示的实例或"物体/背景"之中。
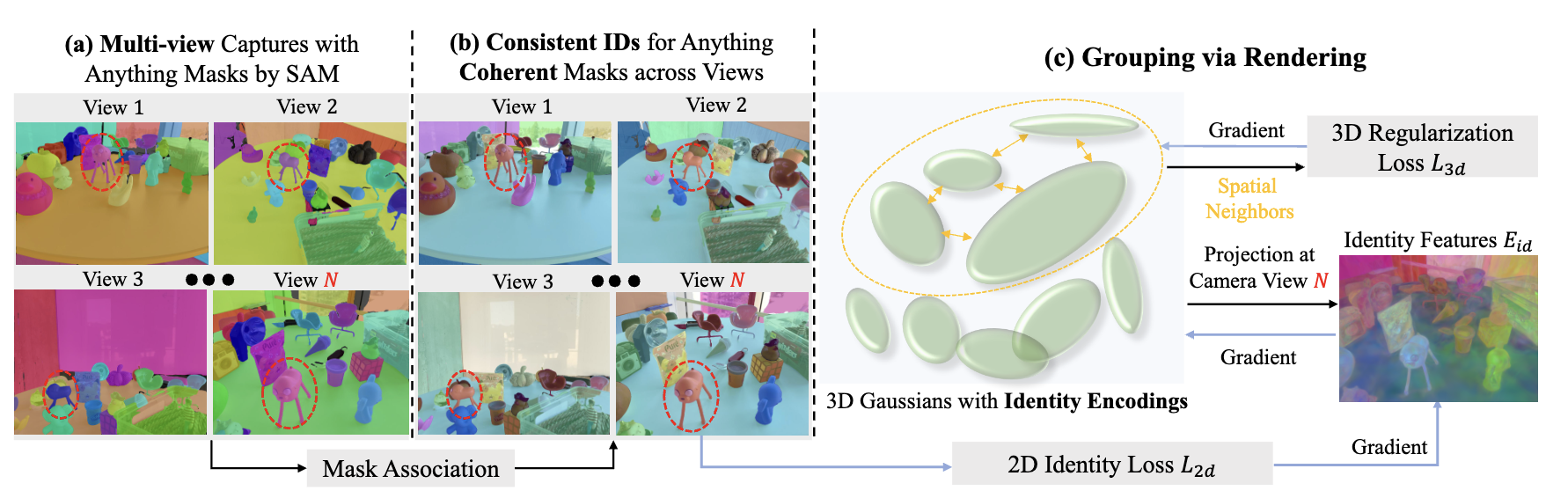
(a) 2D 图像与掩码输入
为了准备 Gaussian Grouping 的输入,在图2(a)中,我们首先使用 SAM 自动为多视图集合中的每张图像生成掩码。2D 掩码是按图像单独生成的。随后,为了在三维场景中给每个 2D 掩码分配一个唯一的 ID,我们需要在不同视图之间关联具有相同身份的掩码,并获得三维场景中实例/物体的总数 K。
(b) 跨视图的身份一致性
我们在训练中不再依赖基于代价的线性分配的做法 44 ,而是将三维场景的多视图图像视为视角逐步变化的视频序列。为了实现跨视图的 2D 掩码一致性,我们使用一个训练良好的零-shot 跟踪器 7 来传播并关联掩码。这也提供了三维场景中掩码身份的总数。我们在图 2(b) 中对关联的 2D 掩码标签进行了可视化。与文献 44 提出的基于代价的线性分配相比,我们发现该方法简化了训练难度,同时避免在每次渲染迭代中重复计算匹配关系,从而实现了超过 60 倍的加速。在密集且相互重叠的 SAM 掩码情形下,该方法还展现出比基于代价的线性分配更好的性能。此外,我们在图 5 中展示了我们对三维掩码关联的鲁棒性,其中来自视频的 2D 关联掩码 7 也存在明显错误。
(c)3D 高斯渲染与分组
为了在场景的不同视图之间生成一致的三维掩码身份,我们提出将属于同一实例/物体的三维高斯进行分组。除了现有的高斯属性外,我们还为每个高斯引入一个新的参数,即身份编码(Identity Encoding) 。身份编码是一个长度为 16 的可学习且紧凑的向量 ,我们发现它在保持计算效率的同时足以区分场景中的不同对象/部件。在训练过程中,与表示每个高斯颜色的球面调和系数(SH)类似,我们优化引入的身份编码向量,以表示场景的实例 ID。需要注意的是,与场景的视角相关外观建模不同,实例 ID 在不同渲染视图之间是一致的 。因此,我们将身份编码的 SH 阶数设为 0,只对其直流分量进行建模。与基于 NeRF 的方法 16,19,44 设计额外的语义 MLP 层不同,身份编码作为每个高斯的可学习属性,用于对三维场景进行分组。
最终渲染出的视频2D掩码身份特征 EidE_{id}Eid 在每个像素处是对每个高斯的长度为 16 的 Identity Encoding eie_iei 的加权求和,权重为该高斯在该像素处的影响因子 αi′\alpha^′iαi′。参见 61,我们通过测量一个带协方差矩阵 Σ2DΣ^{2D}Σ2D 的二维高斯并乘以一个学习得到的每点不透明度 αiα_iαi 来计算 αi′α^′iαi′,并且
Σ2D=JW Σ3D JWT \Sigma{2D} = J_W \, \Sigma{3D} \, J_W^T Σ2D=JWΣ3DJWT
其中 Σ3D\Sigma_{3D}Σ3D 是三维协方差矩阵,Σ2D\Sigma_{2D}Σ2D 是投影后展开的二维版本 68。JJJ 是三维到二维投影的仿射近似的雅可比矩阵,WWW 是从世界坐标到相机坐标的变换矩阵。
(d) 组分损失
在对每个训练视图的 2D 实例标签进行关联之后,假设三维场景中共有 K 个掩码。为了按实例/物体掩码身份对每个 3D 高斯点进行分组,我们设计了分组损失 Lid\mathcal{L}_{id}Lid,用于更新高斯点的 Identity Encoding,包含两个部分:
-
2D 身份损失(2D Identity Loss):由于掩码身份标签在 2D 中,我们并不直接对三维高斯的 Identity Encoding eie_iei 进行监督。给定 Eq. 1 中渲染得到的 2D 特征 EidE_{id}Eid 作为输入,先通过一个线性层 f 将其特征维度恢复到 K,然后对 f(EidE_{id}Eid) 进行 softmax,以进行身份分类,其中 K 是三维场景中掩码的总数。我们采用一个标准的交叉熵损失 L2d\mathcal{L}_{2d}L2d,用于 K 类分类。
-
3D 正则化损失(3D Regularization Loss):为了进一步提升高斯点的分组准确性,除了对间接的 2D 监督使用的标准交叉熵损失外,我们还引入一个无监督的 3D 正则化损失,以直接对 Identity Encoding eie_iei 的学习进行正则化。3D 正则化损失利用三维空间的一致性,强制前 k 个最近邻三维高斯的 Identity Encoding 在特征距离上保持接近。这使得位于 3D 物体内部、或在点渲染(式(1))中几乎在所有训练视图中都不可见的高斯点,能够得到更充分的监督。在 Eq. 3 中,我们将 F 表示在线性层 f 之后的 Softmax 操作(在计算 2D Identity Loss 时共用)。我们用带有采样点的 KL 散度损失来形式化,记为 m 采样点的 KL 损失。
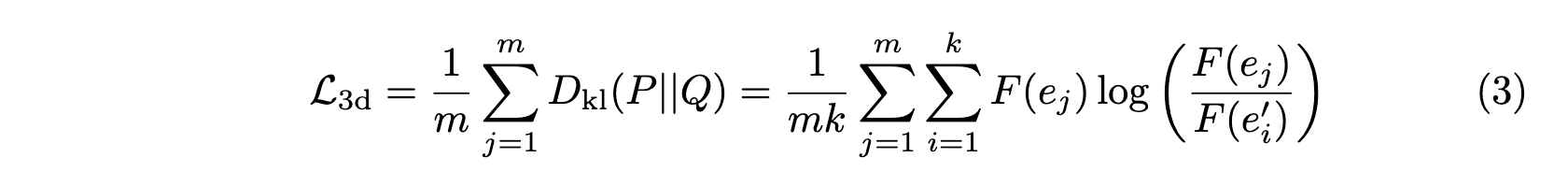
其中 P 包含一个三维高斯点采样得到的 Identity Encoding e,而集合 Q = {e′1, e′2, ..., e′k} 则由其在三维欧氏空间中的最近邻的 k 个向量组成。为简洁起见,我们省略在线性层 f 之后的 Softmax 操作。
结合在图像渲染上使用的传统三维高斯重建损失,用于端到端完全训练的总损失记为 Lrender\mathcal{L}_{render}Lrender:
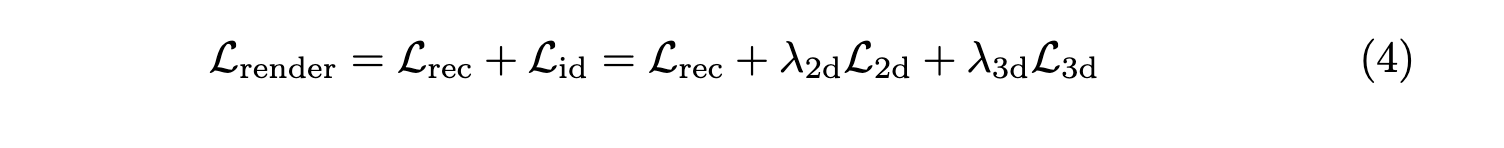

用于场景编辑的高斯分组
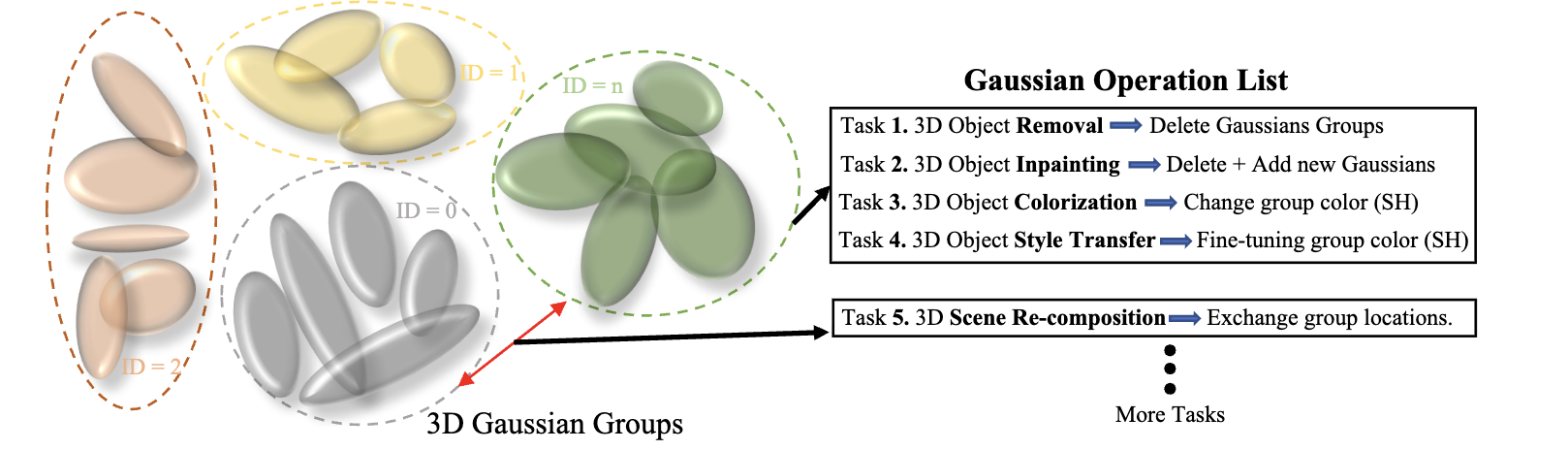
在完成 3D 高斯场的训练与分组(第 3.2 节)后,如图 3 所示,我们用一组分组后的三维高斯来表示整个三维场景。为执行各种后续的局部场景编辑任务,我们提出高效的局部高斯编辑(Local Gaussian Editing)。得益于解耦的场景表示,我们无需对所有 3D 高斯进行微调,而是冻结大部分已经良好训练的高斯的属性,只调整与编辑目标相关的少量现有或新添加的 3D 高斯。
- 对于 3D 目标移除,我们只需删除编辑目标的 3D 高斯。
- 对于 3D 场景的重新组合,我们在两个高斯组之间交换其 3D 位置。这两种编辑应用都是直接可用的,无需额外的参数调优。
- 对于 3D 目标修复(inpainting),我们首先删除相关的 3D 高斯,然后在渲染过程中通过 LaMa 46 的 2D 修复结果来监督添加少量新高斯。
- 对于 3D 目标着色,我们仅调整相应高斯组的颜色(SH)参数,以保持学到的三维场景几何结构不变。
- 对于 3D 目标风格迁移,我们进一步解冻 3D 位置和尺寸,以实现更真实的效果。
实验
见原文。
结论
本文提出了高斯分组(Gaussian Grouping),这是首个基于三维高斯点的能够在开放世界三维场景中实现"共同重建与分割"的能力的方法。方法引入了一种用于三维高斯的 Identity Encoding,它通过 SAM 的二维掩码预测以及三维空间一致性来进行监督。基于这一分组且离散化的三维场景表示,方法进一步展示了其能够支持多种场景编辑应用,例如三维对象移除、三维对象修复、三维对象风格迁移和场景重新组合,同时兼具高质量的视觉效果和较高的时间效率。
Author:ChiAuthor: ChiAuthor:Chi