文章目录
前言
进程是操作系统的核心骨架,所有程序的运行本质都是进程的调度与执行。理解进程的底层逻辑,不仅能打通操作系统、硬件与应用程序的关联,更能为排查性能问题、编写高效代码打下基础。
本文将从冯诺依曼体系结构出发,逐步拆解操作系统的核心职责,再深入进程的定义、PCB 结构、状态转换、优先级调度等核心知识点,同时搭配ps/top/fork等实操指令与代码示例,兼顾理论深度与实战性。无论是刚接触 Linux 系统的初学者,还是想夯实底层基础的开发者,都能通过本文理清进程的完整逻辑链,掌握从 "认识进程" 到 "操控进程" 的核心能力。
冯诺依曼体系结构
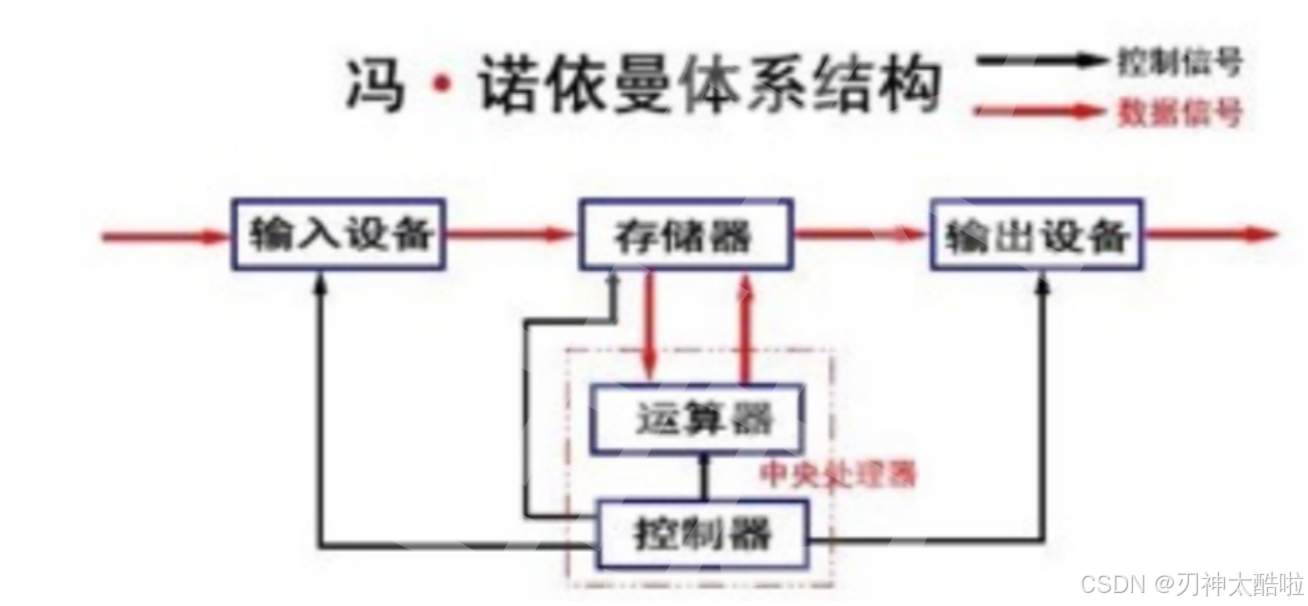
这里指的存储器是内存,是硬件级别的缓存空间(外存不算在这里)
外设分为输入设备和输出设备
输入设备:鼠标,键盘,磁盘,网卡...
输出设备:显示器,播放器硬件,磁盘,网卡
由此看出:有些设备既有输入功能,又有输出功能
中央处理器(CPU):由运算器和控制器组成
运算器:对数据进行计算任务(算数运算,逻辑运算啥的)
控制器:对计算硬件流程进行一定的控制
他们都是独立的个体!
不考虑缓存情况的话,这个中央处理器是不会跟输入输出设备直接联系的,都是通过存储器进行联系的这样设计的好处:提高CPU的工作效率(不用等输入输出设备慢慢输,可以趁这个时间搞其他的)
一个程序要运行,就必须先加载到内存中运行的原因:冯诺依曼体系结构的规定
操作系统
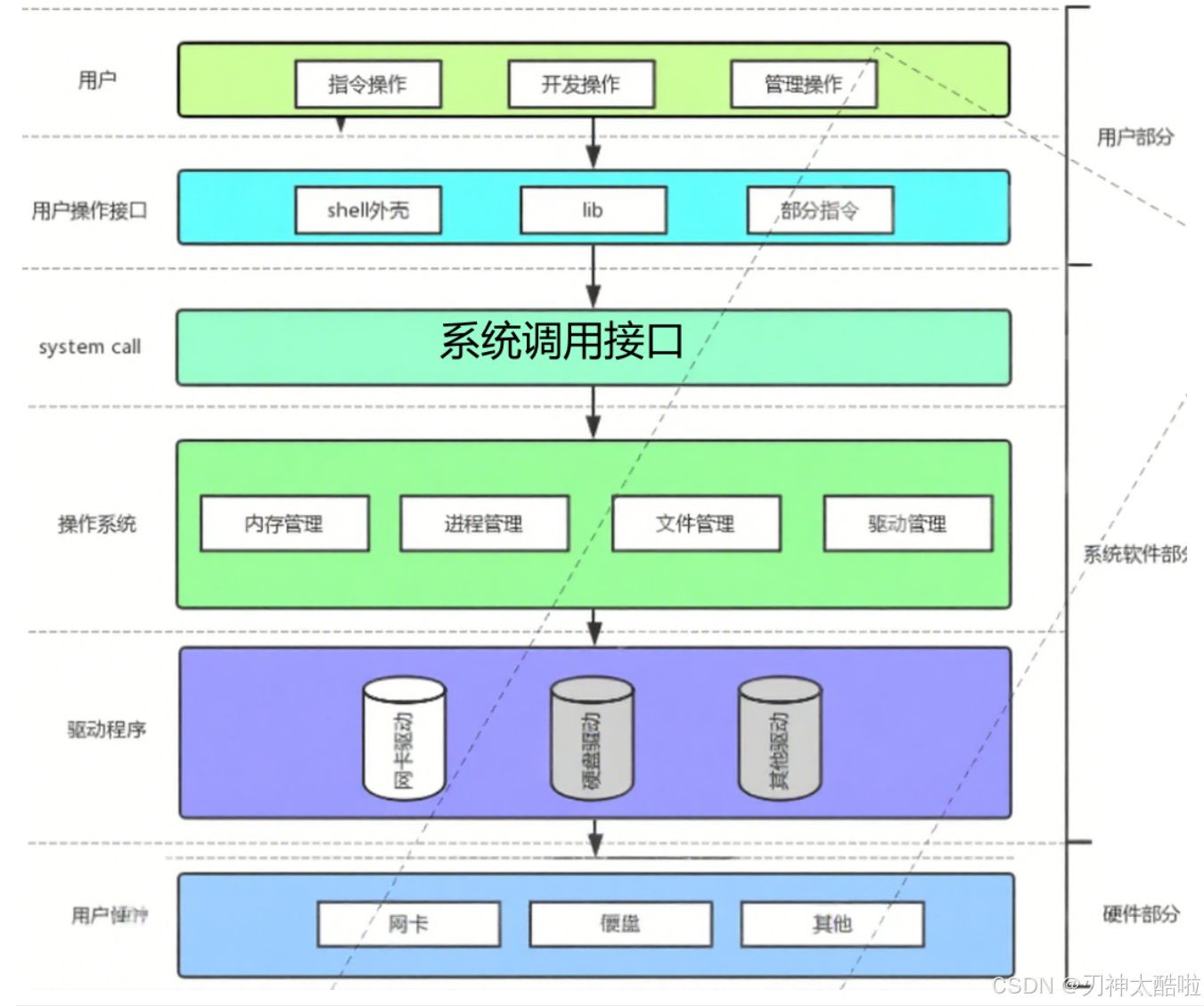
概念:操作系统是一款进行管理的软件(可以管理软件和硬件)
要管理这么多东西--注定了操作系统里面存在大量的数据结构(因为先描述再组织)
为什么要有操作系统:1.可以帮助用户管理好下面的软硬件资源
2.为用户提供一个良好(也就是稳定,高效,安全)的运行环境
也就是操作系统通过管理好底层的软硬件资源(手段),为用户提供一个良好的执行环境(目的)
操作系统里面由大量的数据,但是不想被用户获取所以:为了保证自己的数据安全,也为了能够给用户提供服务,操作系统以接口的方式给用户提供调用的入口,来使用操作系统内部的数据
这个接口是操作系统自己提供的,用C语言实现的,像这种操作系统自己内部进行的函数调用,称为系统调用
--所有访问操作系统的行为,都只能通过系统调用来完成
操作系统管理数据的方法--先描述再组织(6个字很重要)(也就是先描述数据属性,再把数据串起来)
在操作系统中,管理任何对象,最终都可以转化成对某种数据结构的增删查改
库函数和系统调用:库函数是通过系统调用提供的接口实现的
这俩个在写代码的时候都可以用(但是要编程语言支持这个)
进程的概念
一个加载到内存中的程序(也就是正在运行的程序),叫做进程--这个说法不准确哈
进程 = 内核PCB数据结构对象 + 代码和数据
(代码和数据一直在,只有在运行的时候才会产生PCB)
PCB(进程控制块):进程属性的集合,描述了这个进程的所有属性
在Linux内核里,进程有时候也叫做任务大多数Linux的指令都是bash的子进程
一个操作系统不仅仅只能运行一个进程,可以同时运行多个进程任何一个"进程"在加载到内存形成真正的进程时,操作系统会先创建描述进程的结构体对象--也就是PCB
对进程做管理其实也就是对PCB做管理
"进程的执行有先后"其实是PCB在排队等执行,而不是代码和数据
具体到Linux是怎么处理进程的:1.pcb在其中是
task_struct结构体,里面包含进程的所有属性(先描述)(也就是在Linux中描述进程的结构体叫做task_struct)
2.Linux中组织进程:用双向链表组织
如何通过链表节点(令为start)反向定位task_struct,从而访问其他PCB的数据:比如
task_struct里面跟start同位置的是link那么定位
start的task_struct的方法:
cpptask_struct*( (int)start - &(int)(task_struct*)0->link) &(int)(task_struct*)0->link--其实也就是看偏移量(看离0地址的task_struct的头有多远) 注意:这里的指针减指针的时候记得强转一下
task_struct内容分类标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器(也叫做PC指针): 程序中即将被执行的下一条指令的地址。
cpp作用:比如,在程序需要跳转到其他地方的时候,就先保存一下现在的地址,之后返回要用 系统也就是用的这个来得知当前执行到哪行代码了内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息
所有指令的运行都是进程
查看进程
引申:1.如果想要干掉一个进程的话,可以
kill -9 PID值(ctrl+c干不掉时用此可以试试)
`kill`有很多种方法,不止`-9`,可以输`kill -l`去看 2.程序里面遇到`exit(0)`的话是会关闭进程的--也就是关闭程序,跟遇到`return 0`差不多
/proc方法
语法:
ls /proc查看当前所有的进程信息
`ls /proc/PID值`看这个进程的信息
basheg: ls /proc/28128 -l 这里面的cwd表示的是PID对应那个进程的工作目录
ps指令
语法:
ps ajx | head -1就是查看系统中进程的状态信息(只用第一行,所以-1)PPID是当前进程的父进程的ID值 --PPID一般不变,在同一终端下的话
bashPPID一般都是一样的,比如:用命令行来使用Linux的话,父进程都是bashPID是进程的ID值(是唯一的),如果进程结束,再重新开始,PID大概率会变
--PID值也是个目录其实
COMMAND是进程对应的 "命令名称或启动路径"
语法:
ps ajx | grep 文件名可以查询这个文件对应的这些信息
bash这里的grep --color=auto myprocess是grep的进程(因为也带myprocess,所以被搜到了) 如果不想要的话就:ps ajx | grep proc | grep -v grep去过滤(不含grep的才留下)ps一般这样用:
ps ajx | head -1 ; ps ajx | grep 文件名
bash关于;和&& ;是不管前一个命令是否成功,都会执行后一个命令 &&是只有当前面的命令执行成功时,才会执行后面的命令



通过系统调用获取进程标示符
比如:getpid和getppid这俩个系统调用接口(具体的用
man指令去查)
进程的特性
1.竞争性
2.独立性:多进程运行期间互不干扰
3.并行:多个进程在多个CPU下分别同时进行运行
4.并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进
并发的逻辑:用的是基于进程切换和基于时间片进行轮换的调度算法相同优先级的时间片用完之后就会放入
waiting队列里面--到时run和wait交换一下,相同优先级的不同进程间的顺序跟之前一样--这几个名字借鉴的下面一个问题的上一个优先级时间片全用完了就轮到下一个优先级开始了
注意:进程在被切换时需要保存上下文和恢复上下文
--所以,进程在从CPU上离开时,要将自己的上下文数据保存好甚至带走
进程切换时,内核会把 CPU 里的寄存器数据(即进程上下文)拷贝到该进程
task_struct关联的内存结构里
引申:函数返回值被外部拿到,是通过的CPU寄存器--寄存器的作用:提高效率,进程高频数据会被放入寄存器中
--CPU寄存器中保存的是进程相关的数据(其实就是进程的临时数据--进程的上下文)
--寄存器的种类也有很多,比如通用寄存器:
eg: eax,ebx,ecx,edx
栈帧相关寄存器 `eg:ebp esp eip` 状态寄存器 `eg: status`
通过系统调用创建进程-fork
fork也是一个系统调用可以通过man fork去查他的用法引申:系统调用接口不能在命令行那里用
简述一下用法:
1.返回值:(是
pid_t类型的)2.函数声明:
fork之后会产生一个子进程,原来那个变成父进程父子进程的代码是共享的,但是数据和PCB不是
数据的话,在子进程想修改数据(修改的跟父进程不一样时)时,就会进行写时拷贝,把那一点想修改的数据单独开辟空间,其他的数据还是共享的 --父进程也同理
关于fork引申出的几个问题:1.为什么成功时,
fork给子进程返回0,给父进程返回的是子进程的pid值原因:一个父进程可以有多个子进程,返回pid值的话才能分清楚是哪个
返回不同的返回值,可以让不同的执行流执行不同的代码块 (借此特点,用完fork 之后通常要用 if 进行分流,来分开子进程和父进程)2.一个函数是如何做到返回两次的(说的
fork)原因:
fork函数内部的进程:
cpp1.先创建子进程PCB 2.填充PCB对应的内容 3.让子进程和父进程指向同样的代码啥的 然后就return 结果了(这一步的时候两个就分开执行了)3.一个变量怎么会有不同的内容
pid_t id = fork();--以后再给出原因4.如果父子进程用
fork搞好了之后,谁先运行这个由调度器决定,不确定的--兄弟进程谁先运行也是由调度器决定
cpp调度器:负责把进程搞到CPU上运行


bash创建子进程就是用了fork(执行外部命令,比如ls时,bash就会创建子进程)
进程状态
进程状态分为运行状态,阻塞状态和挂起状态等(还有比如阻塞挂起状态啥的)
运行态:会有个运行队列把进程穿起来,在运行队列里的进程都处于运行态(没给CPU的也算)
阻塞状态:每个设备都会有一个等待队列,在这个里面的处于阻塞状态,等设备写入到进程的数据里面,就会被交给运行队列(此时进程整体还是都在内存里的)
挂起状态:在阻塞状态的基础上,操作系统内部的内存资源严重不足了,就会把等待队列里面PCB对应的代码和数据先放在外存里面(PCB还是在内存里),此时这个进程就处于挂起状态(此时进程依然存在)
关于此的几个零碎的知识点
一个进程只要开始运行就会执行完毕才会停止吗--不是的
进程有个时间片的概念--时间片是操作系统分配给每个进程在 CPU 上运行的一段有限时间
在一个时间段内,所有的进程代码都会被执行(也叫做并发执行)
把进程从CPU上放上去,在取下来的操作叫做进程切换
具体到Linux的进程状态
R(running):是运行态
S(sleeping):是阻塞状态中的浅度睡眠--eg:进程等键盘写入数据
cpp引申: 程序看似一直在printf的话,其实是S状态 --因为运行进程是很快的,其实是一直在等IO设备执行完毕,然后继续运行进程的 程序那步是eg:sleep(1)--其实也是s状态D(disk sleep):是阻塞状态中的深度睡眠
cpp处于D状态的话是进程正在等待磁盘写入完毕--此时操作系统是不会去杀这个进程的 --不然会数据丢失 引申:操作系统在内存不足时会把不好的进程给杀掉T(stopped):停止状态--跟阻塞状态的区别就是T可能是停下来等写入的,也有可能是单纯停下来的
t(tracing stop):也是停止状态--跟T差不多--比如像gdb遇到断点停下时时就会出现t
X(dead):死亡状态
Z(zombie):僵尸状态
关于挂起状态的话,操作系统是不会跟你说这个状态的
像这种状态里面出现
+的话是表示进程在前台运行,此时用不了命令行解释在后台运行的进程要杀掉的话,
ctrl+c没用,要用kill那种方法想让他在后台运行的话,要在运行时加
&eg: ./text &或者把进程用kill暂停再运行之后,也会成在后台运行的
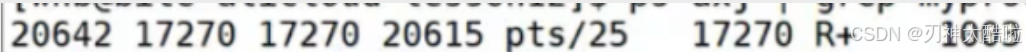
僵尸进程
子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码
僵尸状态的危害:会导致内存一直被占用(尤其是PCB不能被释放)--导致内存泄漏
孤儿进程
如果父进程比子进程早结束的话,子进程的父进程就会被改成
PID为1的那个进程(init 进程)(也就是操作系统),此时这个子进程就叫做孤儿进程如果不这样搞的话,孤儿进程就没人管了,没人将他从Z状态搞出去了
(孤儿进程本身不是一直是Z状态哈,进Z状态的条件跟其他人一样)
进程优先级
cpu资源分配的先后顺序,就是指进程的优先级
必要性:进程要去抢CPU,CPU有限--所以要有优先级
优先级要跟权限区分:优先级是谁先谁后 权限是谁能谁不能
如果进程长期得不到CPU运行的话,该进程就一直止步不前--这是进程的饥饿问题
查看系统进程
用
ps -l查看这个终端的进程
ps -al查看拥有这个终端的用户底下所有终端的所有进程UID : 代表执行者的身份
cppls那个指令加-n的话,就会把执行者的身份用数字的这种方式展示PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值--是进程优先级的修正数据

关于PRI和NI
nice取值范围是-20,19
PRI的取值范围一般是60,99
加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice--上图显示的就是PRI(new)
--注意:PRI(old)永远是80
top指令更改nice
top要超级用户或者sudo才行哈 --一般不建议改优先级!
使用方法:输入
top,然后按r,就会这样然后再输入想改的进程的PID值,回车
输入想要的nice值,回车,然后就OK了

系统如何通过优先级进行调度
cpp比如有个runqueue: struct runqueue { bitMap isempty; //位图,bitMap也是自定义的结构体,里面有eg: char bitmap[140] //数组里面的[100,139]一共40个位图--对应40个优先级 task_struct** run; task_struct** wait; //run里面进程被调度完了就swap(&run,&wait)这样 task_struct* running[140];//这样就形成一个队列 task_struct* waiting[140]; //一般都是[0,99]给其他种类的进程存(没学),[100,139]给这里的进程(PRI从60到99的)存 }每个
task_struct里面又有双向链表的特性,把PRI值相同的进程给串起来想要快速查找最高优先级进程的话:用到位图
--eg:优先级为60的进程加一个,就在100下标那个位图给+1
--在找时,就要位图等不等于0,不等于的话就说明有这个优先级的
--这也就是Linux的O(1)级别的调度算法
--如果嫌弃位图太多,还可以eg:一个位图代表8个优先级--每四个二进制表示一个优先级这样