1 树和二叉树习题

答案及解析:
-
错误
解析:二叉树不是树的特殊形式(树的子节点无左右次序,二叉树的子节点有左右次序),二者是不同的数据结构。
-
错误
解析:度为 2 的树仅要求节点最大度为 2,但二叉树要求子节点有左右区分(即使只有一个子节点,也要明确是左 / 右孩子),二者定义不同。
-
正确
解析:树转二叉树的规则是 "左孩子右兄弟",根节点无兄弟,因此其右子树必然为空。
-
错误
解析:A 有 3 个兄弟,则 B 的子节点数为(3+1)=4,因此 B 的度是 4。
-
错误
解析:仅先序 + 后序遍历无法唯一确定二叉树(例如:先序为 "AB"、后序为 "BA",可对应两种不同结构的二叉树)。
-
正确
解析:哈夫曼树的构造规则是 "选最小权值节点合并",因此权值大的节点会优先靠近根节点,保证带权路径长度最短。
2 二叉排序树

3 图算法

Prim 算法
Prim 算法是用来找连通网(带权无向连通图)最小生成树 的方法,核心是 "从小集合逐步扩展,选最短边"。
先明确几个概念
- 连通网:带权的无向连通图(比如城市之间的公路,权是距离)。
- 最小生成树:用最少的边(共 n-1 条,n 是顶点数)把所有顶点连起来,且边的总权值最小的子图。
算法过程翻译
假设现在有个连通网N(顶点集合V,边集合E),要找它的最小生成树T(顶点还是V,边集合TE):
-
初始化 :
先选一个 "起点顶点"u₀(随便选哪个都行) ,把它放进一个 "已选顶点集合"U里;此时最小生成树的边集合TE是空的(还没选边)。 -
选最短边,扩展集合 :
找一条 "一头在
U里(已选顶点)、另一头在V-U里(没选顶点) " 的边,挑权值最小的那条(比如(u₀, v₀))。把这条边加入
TE(现在生成树多了一条边),同时把v₀(这条边的 "未选顶点")放进U(现在U里的顶点变多了)。 -
重复到覆盖所有顶点 :
一直重复步骤 2,每次都选 "连接已选顶点和未选顶点的最短边",直到
U包含了所有顶点(U=V)。此时
TE里正好有n-1条边,T=<V, TE>就是最小生成树。
举个例子(比如 3 个城市 A、B、C)
- 顶点
V={A,B,C},边权:A-B=2,A-C=5,B-C=3。 - 步骤 1:选起点 A,
U={A},TE=空。 - 步骤 2:找 "U 里的 A" 连 "V-U 里的 B、C" 的边,最短边是 A-B(权 2),把 A-B 加入 TE,
U={A,B}。 - 步骤 3:找 "U 里的 A/B" 连 "V-U 里的 C" 的边:A-C=5,B-C=3 → 选 B-C(权 3),加入 TE,
U={A,B,C}(覆盖所有顶点)。 - 结果:
TE={A-B, B-C},总权 2+3=5,是最小生成树。
Kruscal 算法

算法核心逻辑
- 初始化 :将最小生成树
T初始化为仅包含所有顶点、无边的集合(即T = <V, ∅>); - 选边规则 :每次选择权值最小 且连接两个不同连通分量的边,将其加入生成树的边集合
TE; - 终止条件 :重复选边,直到所有顶点处于同一个连通分量(此时生成树包含
n-1条边,n为顶点数)。
算法特点
- 属于 "贪心算法":通过每一步选局部最优(最小权值且不形成环的边),最终得到全局最优(最小生成树);
- 通常结合 "并查集" 数据结构,高效判断边的两个顶点是否属于同一连通分量,避免生成环。
步骤
1.先对所有边的权值排序,由小到大排序。
2.从小的权值开始选边,核心是选边,选边加入生成树的队列但是不能有环(因为是树)。
Dijkstr 算法

步骤 1:初始化
- 设顶点集合
S(已确定最短路径的顶点),初始时S = {v_s}; - 设距离数组
dist:dist[i]表示v_s到顶点v_i的当前最短距离,初始时dist[s] = 0,其余顶点的dist设为 "无穷大"(表示暂未可达)。
步骤 2:迭代求最短路径
重复以下操作,直到S包含所有顶点:
- 选距离最小的顶点 :在
S外的顶点中,选dist值最小的顶点u,将u加入S; - 更新相邻顶点的距离 :对
u的每个邻接顶点v(若v不在S中),计算new_dist = dist[u] + 边(u,v)的权值;- 若
new_dist < dist[v],则更新dist[v] = new_dist。
- 若
示例说明(假设源点是v1,图中有边v1→v2(权6)、v1→v3(权4)):
- 初始:
S={v1},dist[v1]=0,dist[v2]=∞,dist[v3]=∞; - 第 1 次迭代:选
v2(dist=6)加入S,更新v2的邻接顶点距离; - 第 2 次迭代:选
v3(dist=4)加入S,更新v3的邻接顶点距离; - 最终
dist数组就是v1到各顶点的最短路径长度。
注意 :Dijkstra 算法仅适用于边权值非负的图(若有负权边,需用 Bellman-Ford 算法)。
4 拓扑排序

这是有向图的拓扑排序 ,它的核心作用是:
在一个 **有向无环图(DAG)**中,找到一个顶点的线性序列,使得对于图中任意一条有向边(u→v),顶点 u 都出现在顶点 v 的前面。
实际用途
拓扑排序常用于处理依赖关系的任务调度(课上讲的装修示例),比如:
- 课程安排:若课程 B 需要先学课程 A,拓扑排序能给出合理的选课顺序;
- 项目流程:任务 B 依赖任务 A 完成,拓扑排序可确定任务的执行顺序;
- 编译依赖:程序模块的编译顺序(被依赖的模块先编译)。
如果图中存在回路(比如 A→B、B→C、C→A),拓扑排序会执行失败,这也可以用来检测图中是否存在环。
5 AOE网
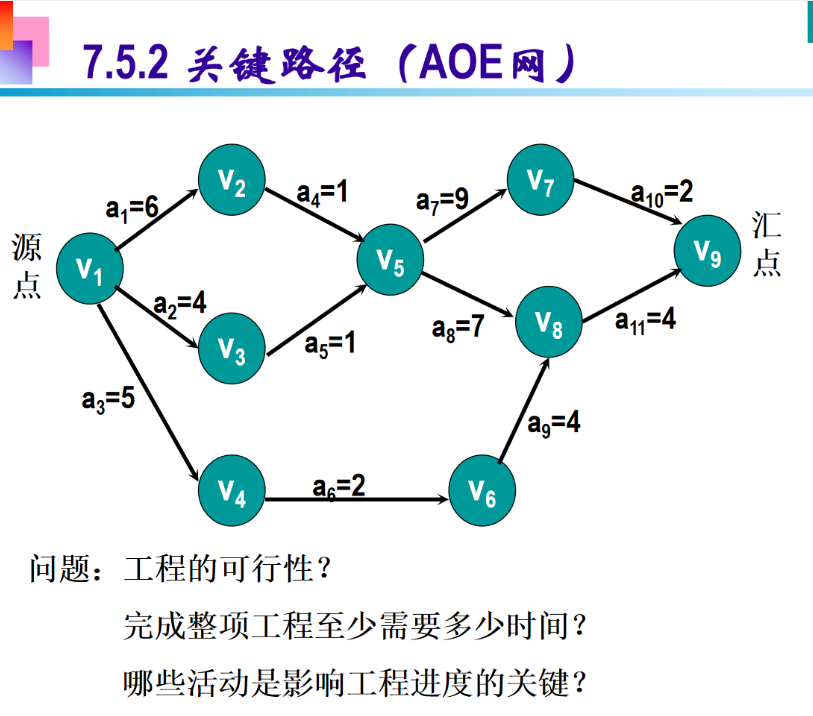
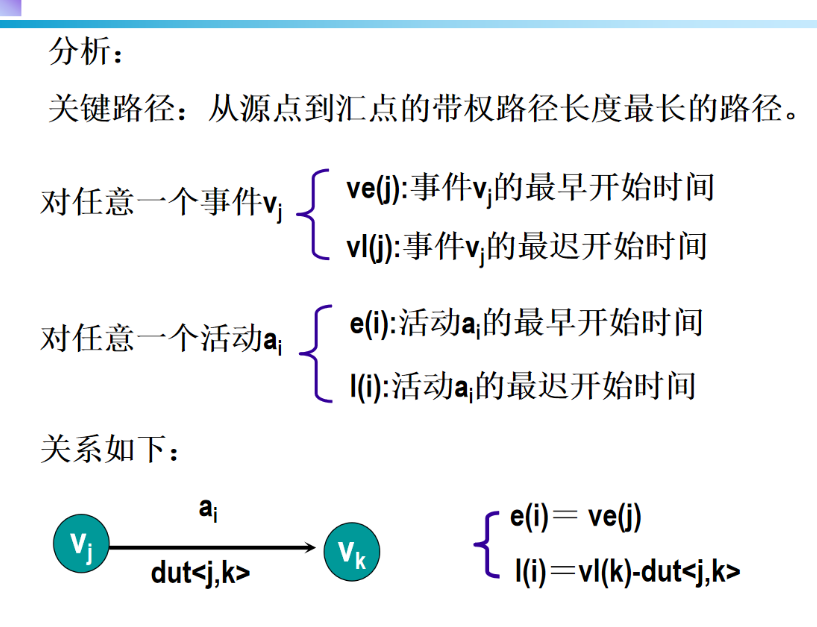

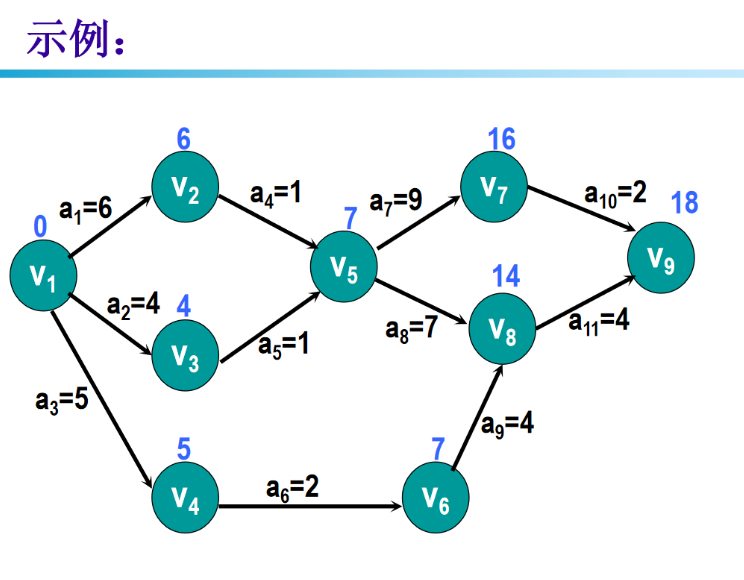
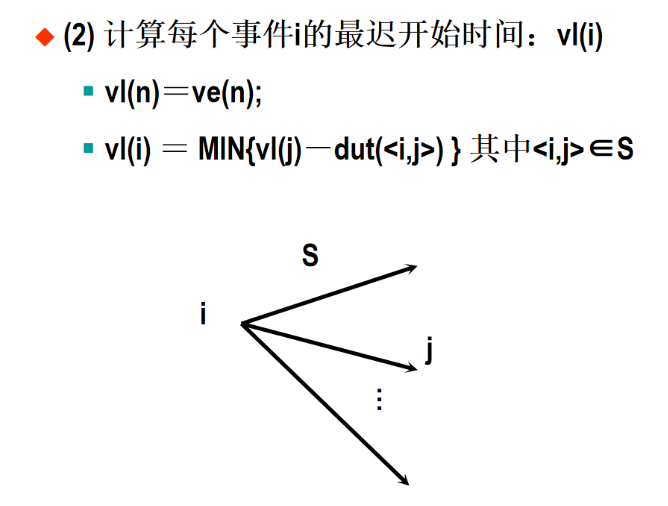
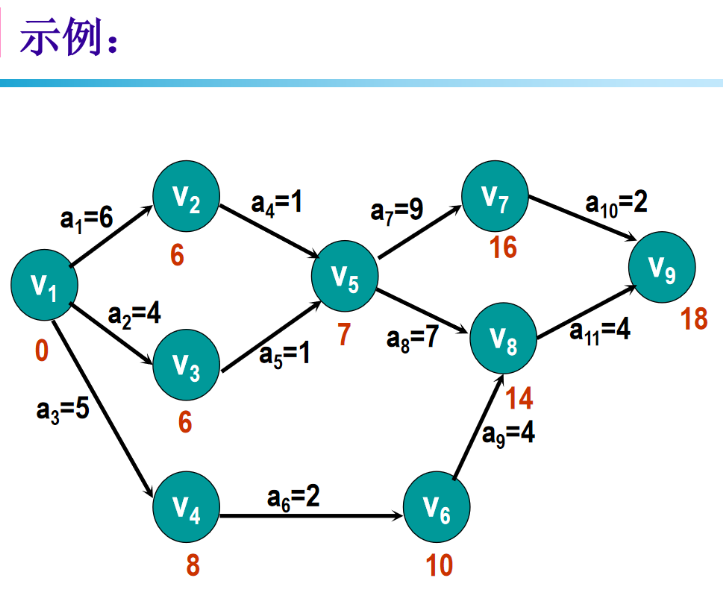
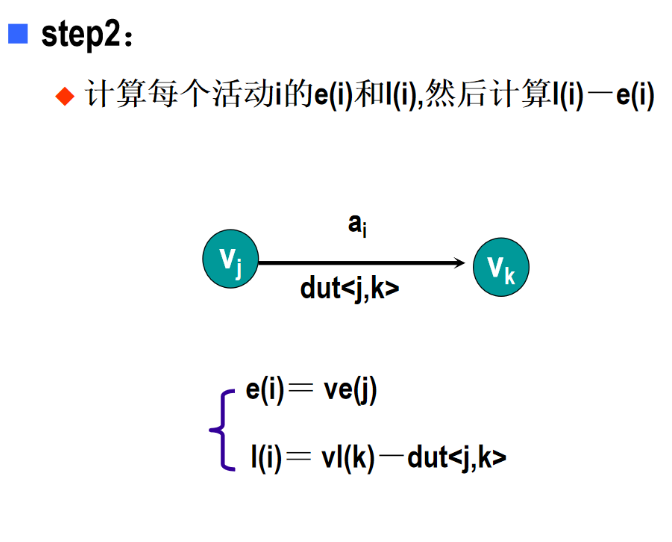
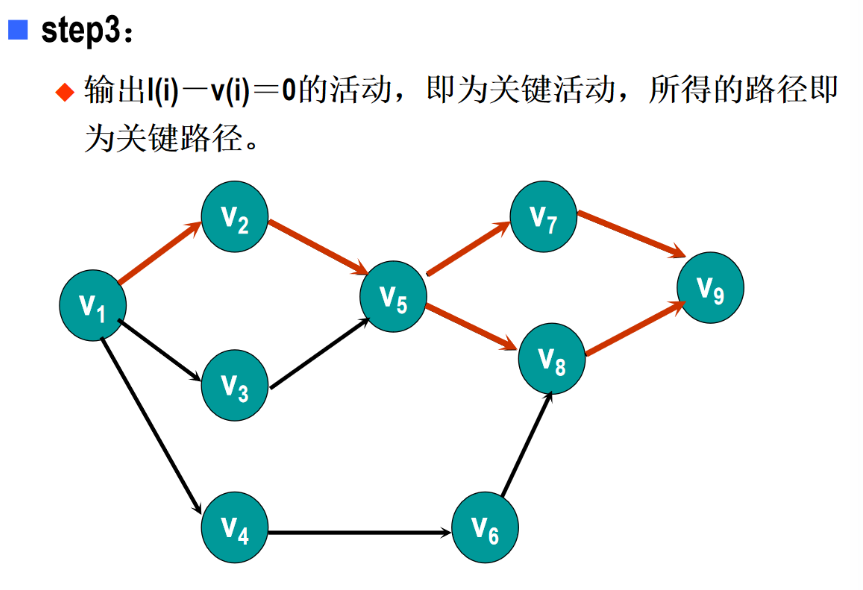

6 图习题
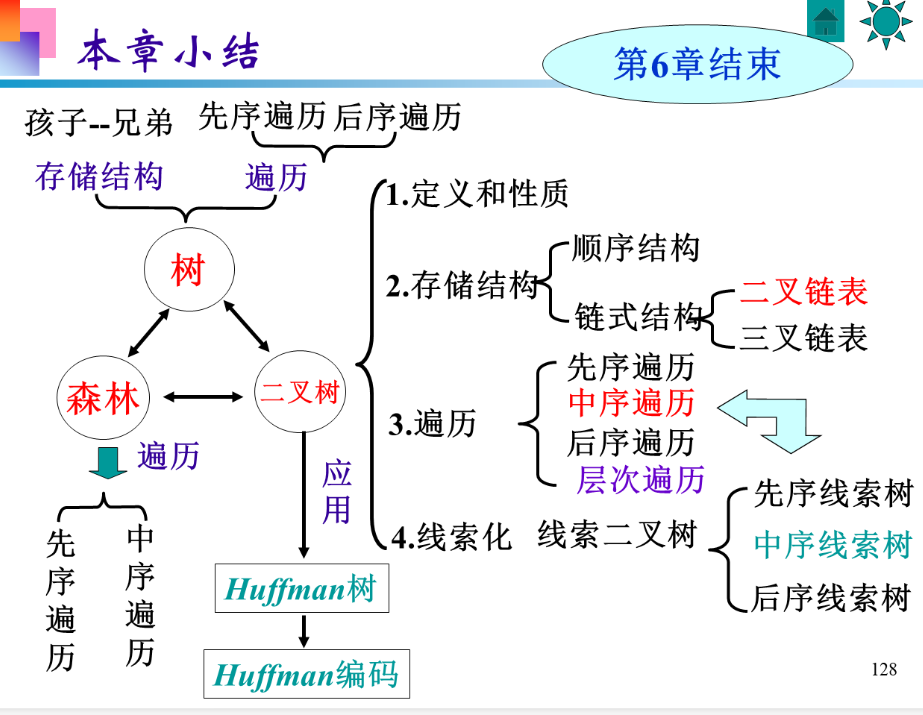
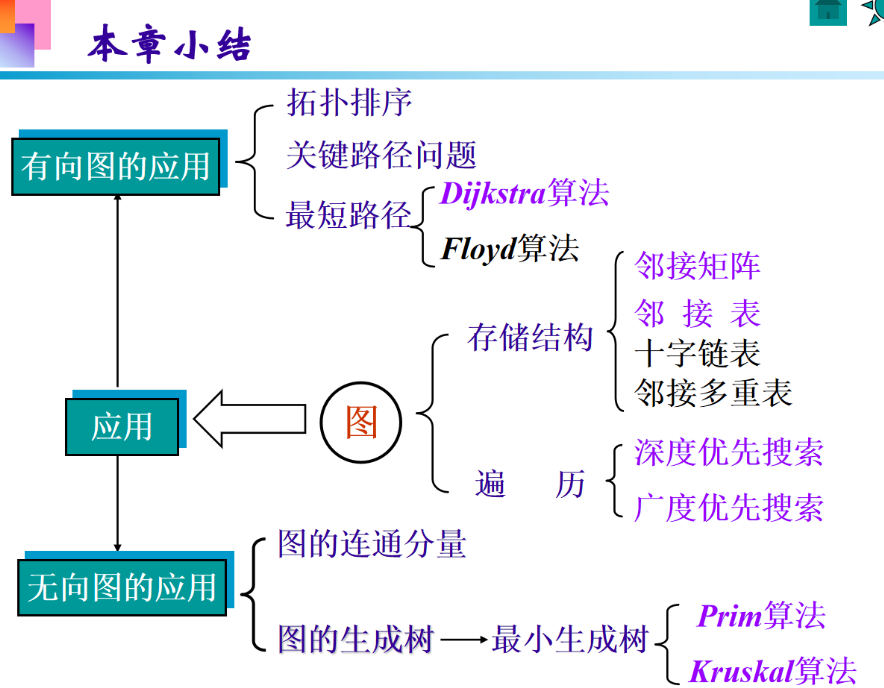
本章小结
判断题

1. 答案:正确
解析:邻接矩阵是一个n×n的二维数组(n为顶点数),无论边数多少,存储空间固定为n²(不考虑压缩),因此只与顶点数有关。
2. 答案:错误
解析:若图是非连通图 (无向图)或非强连通图(有向图),从某一顶点出发的遍历无法访问到所有顶点(只能访问所在连通分量 / 强连通分量的顶点)。
3. 答案:错误
解析:遍历序列唯一的原因是 "每个顶点的邻接顶点只有一个可选"(即每个顶点的出度≤1),但弧数不一定是n-1(例如有向图存在环且每个顶点出度为 1 时,弧数可能等于n)。
4. 答案:错误
解析:邻接表既可以存储有向图,也可以存储无向图(无向图的每条边需在两个顶点的邻接链表中各存一次);邻接矩阵确实同时适用于有向图和无向图。

5. 答案:错误
解析:AOV 网的拓扑排序结果通常不唯一。例如,若存在多个无前置依赖的顶点,选择不同顶点的顺序会得到不同的拓扑序列。
6. 答案:正确
解析:拓扑排序的前提是图为 "有向无环图(DAG)",若图存在回路,无法找到满足 "所有前驱顶点先于后继顶点" 的线性序列,因此不能进行拓扑排序。
7. 答案:正确
解析:无向图的邻接矩阵满足A[i][j] = A[j][i](对称矩阵),因此只需存储上三角或下三角部分(含对角线),即可节省一半存储空间。
8. 答案:错误
解析:AOE 网中可能存在多条关键路径(即路径长度等于工程最短完成时间的路径),例如当多个路径的权值和均为最大值时,这些路径都是关键路径。
9. 答案:正确
解析:最小生成树的边数固定为n-1(n为顶点数)。若最小生成树不唯一,说明存在多条权值最小的边,且图的总边数多于n-1(否则无法替换边得到不同的最小生成树)。
10. 答案:错误
解析:"最小代价生成树" 的定义就是代价(所有边权值和)最小的生成树,因此其代价必然小于等于其他任意生成树的代价。