补充(一)中的VideoChat-R1和VideoAuto-R1
一、VideoChat-R1
1、概述
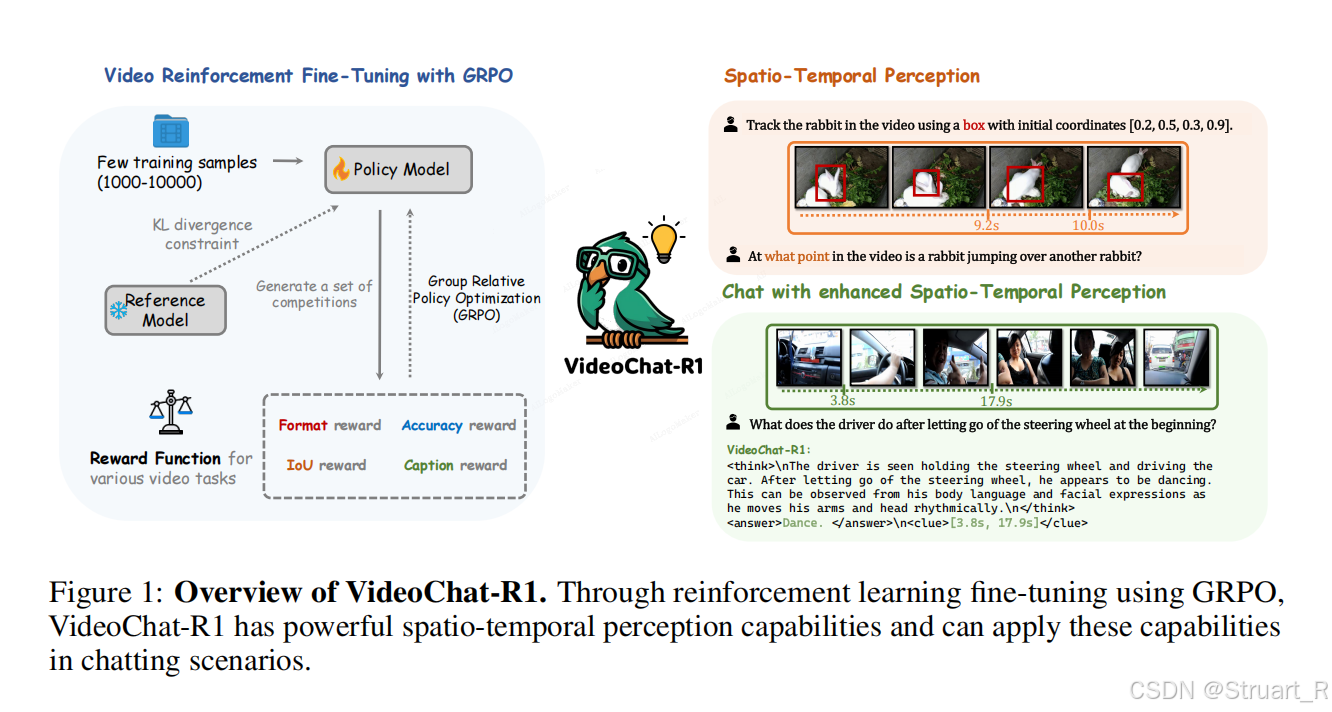
motivation:在RL+MLLM基础上扩展更泛化的任务,比如时序定位,目标跟踪,并通过不同的奖励来强化。
contribution:
(1)针对时空感知任务的多奖励函数,实现少量数据的高效训练。
(2)多任务协同训练
(3)时序线索驱动推理--用于长视频时序定位,视频中的细粒度问答
感觉这个论文像是Time-R1(时序定位)+DeepVideo-R1(时序线索驱动推理)+多了个奖励函数的版本,应该是碰巧撞了idea。
2、方法
首先,VideoChat-R1考虑了五种视频相关tasks,包括时间定位、目标跟踪、视频问答、字幕生成和质量评估。而VideoChat-R1的基座与其他方法相近,即Video LLM+RL,RL同样采用GRPO。
解决办法则是添加更多的奖励函数,在格式化奖励基础上:
添加时空交并比(就是时间上的IoU,没有Time-R1的优化)
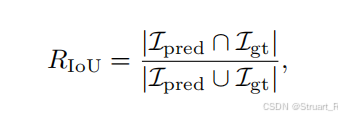
添加分类任务准确率奖励(多选题和分类任务必须完全一致赋1):
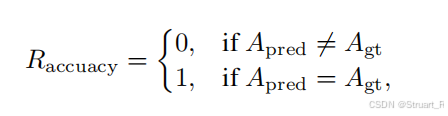
视频字幕召回奖励(将预测caption和真实caption用Qwen2.5分解为两个set集合,并计算蕴含关系作为召回奖励):
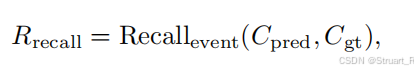
在不同任务时,我们采用不同的奖励组合,比如时序标注和目标跟踪问题用format+IoU的组合,多选题带时序的问答(问时间段节点)则使用format+IoU+Acc的组合,视频字幕问题则使用format+recall的组合,多选题和视频质量评估问题用format+recall。
线索驱动推理:用于处理长视频的方法,二阶段推理。
(1)先处理低分辨率 或低帧率的压缩视频,生成初始答案(A1),同时生成一个时序clue,比如兔子的出现在1.2s,2.5s,这种相关时间段,可以看作是模型thinking后给出的证据所在位置。
(2)对关键片段进行高分辨率、高帧率超采样,并再次输入模型,生成最终答案(A2)
3、实验
基模:Qwen2.5-VL-7B
数据集使用:
|----------------------|---------------|
| Temporal Grounding任务 | Charade - STA |
| Object Tracking任务 | GoT - 10k |
| QA和Grounding QA任务 | NExTGQA |
| Video Caption任务 | Fiber-1k |
| 视频质量评估任务 | VidTAB |
训练方法:不通过SFT二次训练Video datasets,直接在基模上应用GRPO,并多任务协同训练。
TVG任务效果如下:

二、VideoAuto-R1
1、概述
motivation:视频理解上依赖视觉感知,而非符号推理,所以冗长的CoT可能存在过度思考,同时浪费成本。
contribution:
(1)系统性研究直接回答与CoT模式下的性能对比
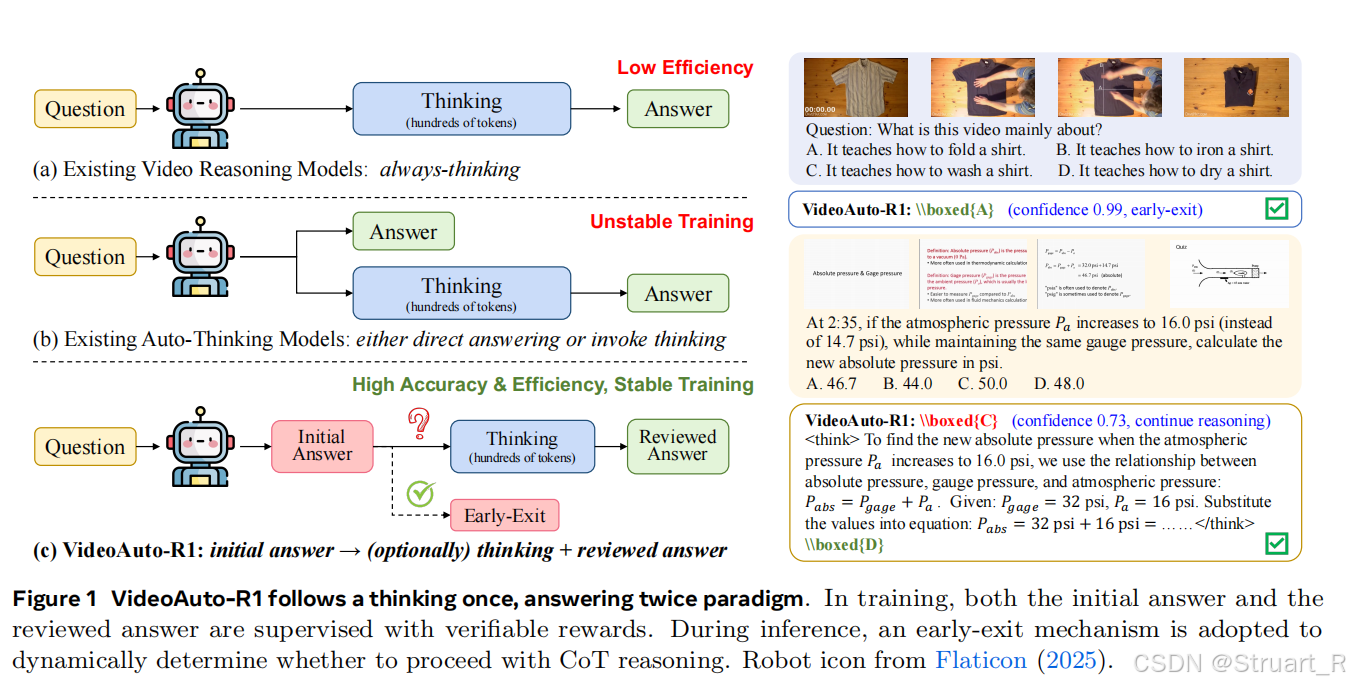
(2)VideoAuto-R1框架,"思考一次,回答两次"框架
2、相关工作
处理视频理解问题的推理方式:直接回答(a),链式思维推理(b),自适应推理(c)
直接回答:对纯感知问题回答准确,效率高,tokens少,但数学推理,复杂推理等缺失显式推理过程的会导致错误。
链式思维推理:必须一步步推理,最终输出答案,但无论难易问题,都要生成数百个tokens的推理过程,造成巨大计算资源浪费,简单问题也会出现过度思考。
自适应推理:本文的,先生成一个初始答案,根据答案置信度动态决定是否进行后续的CoT推理生成复审答案。并且两次答案都要受到奖励信号监督。
3、方法
3.1系统级对比CoT的意义
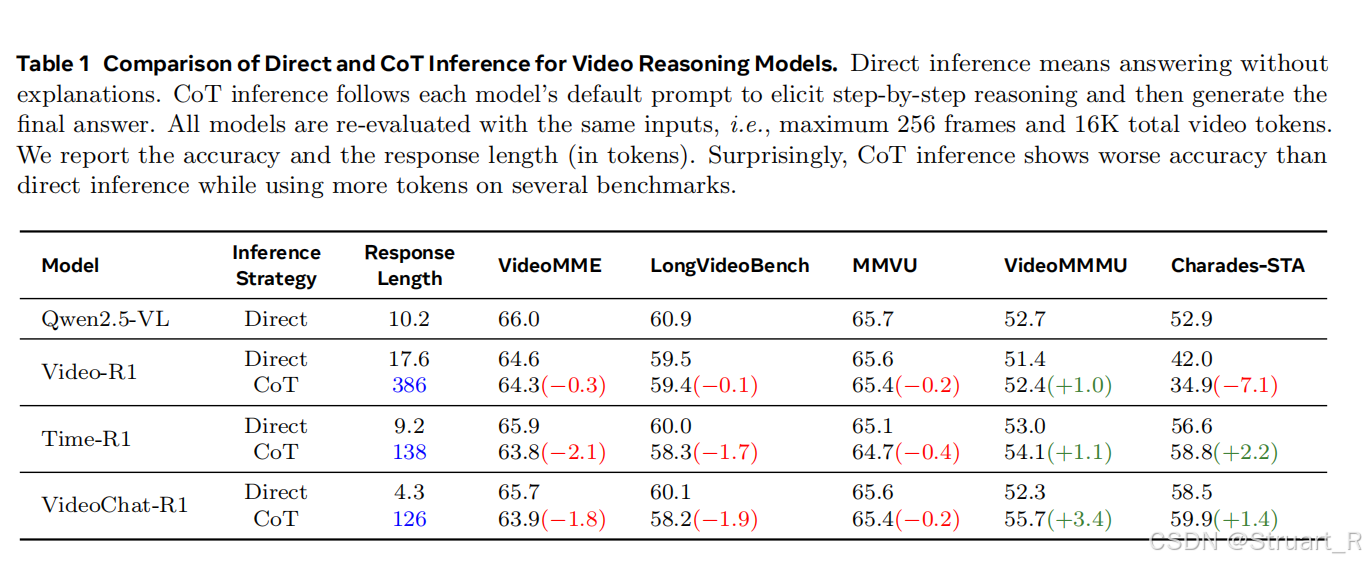
视频理解上CoT真的有意义吗?针对Video-R1,Time-R1,VideoChat-R1在长视频理解,视频问答等benchmark下对比两种推理策略。但惊人发现CoT的情况下,大多数benchmark,score甚至会下降。这也证明了CoT在特定任务上有效(多步推理的VideoMMMU),过度思考会影响简单的感知问题,多数情况下CoT都是收效甚微。
3.2VideoAuto-R1
"思考一次,回答两次":
初始答案 (A1):模型被要求首先不假思索地给出一个简短答案。如果问题过于复杂无法直接回答,它被允许输出一个特定的回退字符串(如"Let's analyze the problem step by step")。
推理过程:在 think标签内,模型进行自由的、逐步的链式思考(CoT)。
复审答案 (A2):在思考之后,模型再次输出答案。如果认为A1正确,可以重复它;如果发现错误,则修正它。
在VideoAuto-R1中的解决方法:
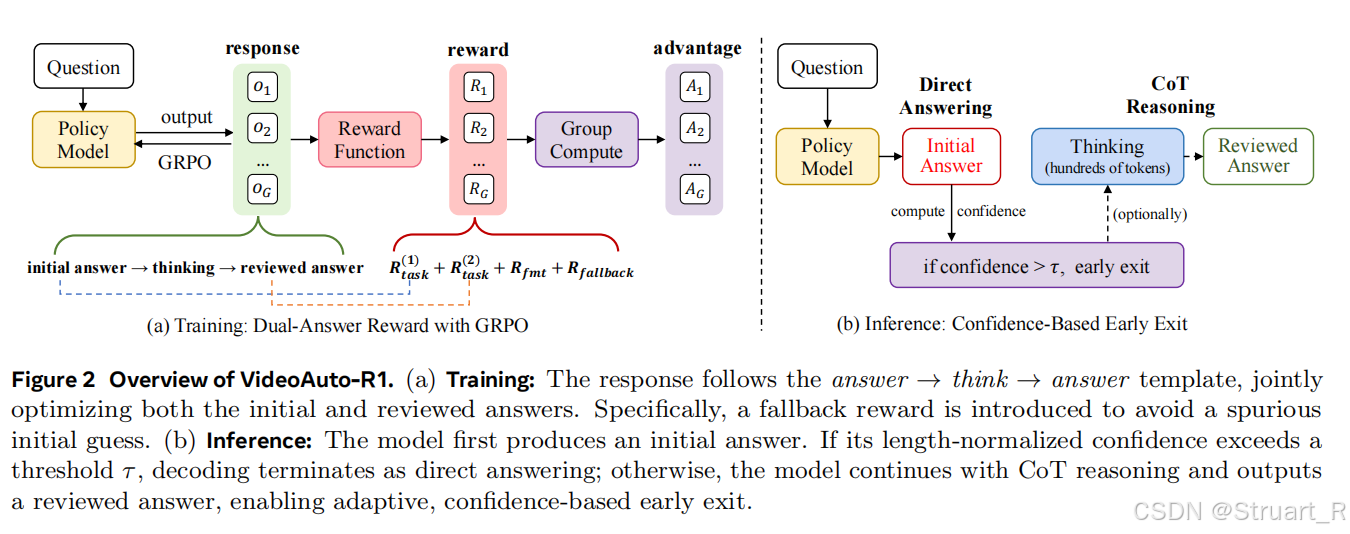
**训练阶段:**不区分"Think/No-Think"样本。对于每一个训练样本,模型都被要求遵循"回答→思考→回答"的模板。它必须练习生成一个初始答案(A1),然后进行推理,最后生成一个复审答案(A2)。训练的目标是让A1和A2都尽可能正确。
基于GRPO的双答案奖励优化函数。总奖励为双答案任务奖励,格式奖励,回退奖励。
其中,任务奖励的权重设定,即最终输出的复审答案A2更为重要,鼓励模型在需要时利用思考过程来修正A1,而不是盲目坚持一个可能是猜错的答案。
格式奖励,确保模型的输出严格遵循A1+think+A2的模版。
回退奖励,当A1是回退字符串时且A2正确时,给予额外奖励,这可以鼓励模型在真正棘手的问题上诚实地承认无法直接回答,从而提高初始答案A1的置信度可靠性。
通过这种奖励设计,模型训练中学会了快速给出准确初始答案的能力 和通过推理进行自我修正的能力。
训练模版如下:

**推理阶段:**早期退出策略。先生成初始答案A1,并计算A1中所有token长度归一化平均对数概率作为置信度,如果A1是回退字符串,则强制设定为置信度负无穷。如果
,也就是初始答案A1有高置信度时,立即终止解码,输出A1为最终答案。反之则将继续生成think中的推理内容和复审答案A2。
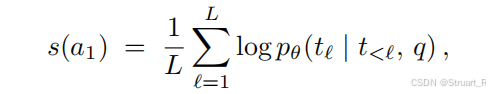
4、实验
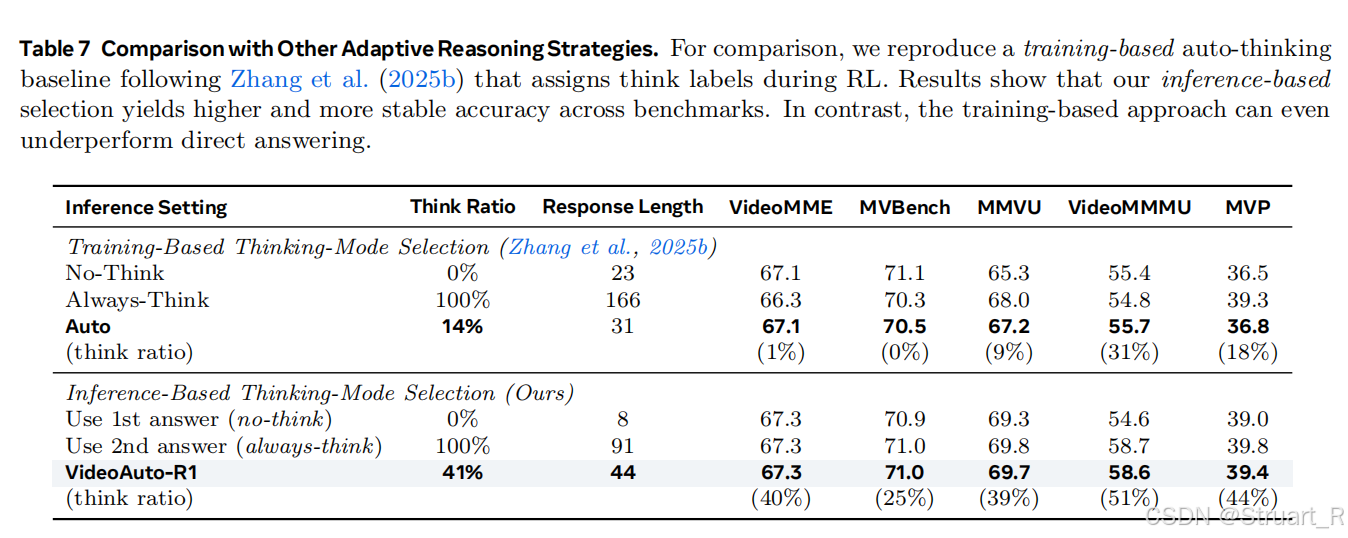
对比两种策略,基于训练的thinking selection和基于推理的thinking selection。
(1)基于训练的thinking selection:
-No-Think:以往直接回答的训练方法
-Always-Think:以往完全过Think的方法**(本文用的)**
-Auto:以往根据数据集给定的Think或No-Think,来判定是否对该样本采用Think或No-Think的方法
(2)基于推理的thinking selection:
Use 1st answer:一步推理,以往所有的模型都是一步推理
Use 2nd answer:完全二步推理
VideoAuto-R1:本论文中提到的,基于置信度的早期退出的推理模式。(本文)
MVP是一个评估视频推理能力(反事实推理或细微差别感知能力的数据集),比如相似的视频中,相同的问题,产生不同的答案。在这个数据集上,过度思考是有意义的。
参考论文: