摘要:在生成式人工智能(AIGC)浪潮席卷全球的今天,大语言模型(LLM)已不再是科技巨头的专属玩具。然而,数据隐私泄露的隐忧、云端 API 高昂的调用成本以及网络延迟的不可控性,正成为阻碍企业深度应用 AI 的"三座大山"。本文基于"智聊机器人"项目的核心架构,深入剖析从大模型理论基础到本地私有化部署的全链路实践。我们将摒弃对云端服务的依赖,利用 Ollama 推理引擎与 Streamlit 前端框架,在消费级硬件上构建一个安全、可控、低成本的智能对话系统。这不仅是一次技术环境的搭建,更是一场关于"数据主权"与"AI 民主化"的深度探索。
文章目录
-
- [🌐 第一章:觉醒时刻------为何我们需要"私有化"大模型?](#🌐 第一章:觉醒时刻——为何我们需要“私有化”大模型?)
-
- [1.1 大模型时代的机遇与隐痛](#1.1 大模型时代的机遇与隐痛)
- [1.2 破局之道:开源模型与本地部署的崛起](#1.2 破局之道:开源模型与本地部署的崛起)
- [1.3 主流开源模型家族巡礼](#1.3 主流开源模型家族巡礼)
- [🛠️ 第二章:筑基工程------本地私有化部署环境全解析](#🛠️ 第二章:筑基工程——本地私有化部署环境全解析)
-
- [2.1 核心技术栈选型](#2.1 核心技术栈选型)
-
- [🔹 Ollama:大模型领域的"Docker"](#🔹 Ollama:大模型领域的“Docker”)
- [🔹 Streamlit:极速构建 AI 交互界面](#🔹 Streamlit:极速构建 AI 交互界面)
- [🔹 硬件基石:NVIDIA CUDA 生态](#🔹 硬件基石:NVIDIA CUDA 生态)
- [2.2 实战演练:从零搭建 Ollama 推理服务](#2.2 实战演练:从零搭建 Ollama 推理服务)
-
- [步骤一:安装 Ollama 运行时](#步骤一:安装 Ollama 运行时)
- 步骤二:拉取并运行智能模型
- [步骤三:验证 API 接口连通性](#步骤三:验证 API 接口连通性)
- [2.3 智聊机器人系统架构全景图](#2.3 智聊机器人系统架构全景图)
- [💡 第三章:深水区导航------关键挑战与优化策略](#💡 第三章:深水区导航——关键挑战与优化策略)
-
- [3.1 显存焦虑与量化技术的权衡](#3.1 显存焦虑与量化技术的权衡)
- [3.2 中文语境下的"水土不服"](#3.2 中文语境下的“水土不服”)
- [3.3 推理延迟与并发瓶颈](#3.3 推理延迟与并发瓶颈)
- [🔮 第四章:展望与过渡------从"能跑"到"好用"的进化之路](#🔮 第四章:展望与过渡——从“能跑”到“好用”的进化之路)
🌐 第一章:觉醒时刻------为何我们需要"私有化"大模型?
1.1 大模型时代的机遇与隐痛
过去两年,以 Transformer 为架构核心的大语言模型彻底改变了人机交互的范式。从自动编写代码到辅助医疗诊断,从智能客服到创意写作,LLM 展现出了惊人的通用智能。然而,当我们试图将这些能力引入企业内部或敏感场景时,现实却给了我们当头一棒。
痛点一:数据隐私的"达摩克利斯之剑"
在使用公有云大模型(如 ChatGPT、Claude 等)时,用户必须将提示词(Prompt)和上下文数据上传至厂商服务器。对于金融、法律、医疗或拥有核心知识产权的企业而言,这意味着核心数据可能面临泄露风险,甚至被用于训练对方的下一代模型。合规性(如 GDPR、数据安全法)成为了悬在头顶的利剑。
痛点二:难以预测的成本黑洞
云端 API 通常按 Token(字数)计费。对于高频调用的业务场景(如全天候客服、批量文档分析),每月的账单可能高达数万甚至数十万元。这种"租用算力"的模式在长期运营中缺乏成本优势。
痛点三:网络延迟与稳定性
依赖公网访问意味着受限于网络波动。在高并发或弱网环境下,API 的响应延迟可能导致用户体验急剧下降,甚至服务中断。
1.2 破局之道:开源模型与本地部署的崛起
面对上述挑战,"私有化部署 "(On-Premise Deployment)成为了最佳解决方案。其核心理念是:将模型"搬"回家。
通过下载开源权重文件(如 Llama 3, Qwen 2.5, ChatGLM 等),利用本地 GPU 进行推理,我们可以实现:
- 数据完全闭环:所有交互数据不出内网,彻底杜绝泄露风险。
- 成本可控:一次性投入硬件成本后,后续运行边际成本趋近于零(仅需电费)。
- 深度定制:可以自由修改模型架构、进行微调(Fine-tuning)或挂载私有知识库(RAG),打造专属的"行业专家"。
- 离线可用:即使在无外网环境下,智能服务依然稳定运行。
在"智聊机器人"项目中,我们正是基于这一理念,选择了一条自主可控的技术路线。
1.3 主流开源模型家族巡礼
在开始部署前,我们需要了解手中的"武器库"。当前开源社区百花齐放,以下是几款适合本地部署的明星模型:
| 模型系列 | 开发机构 | 核心优势 | 适用场景 |
|---|---|---|---|
| **Qwen **(通义千问) | 阿里巴巴 | 中文理解能力顶尖,长上下文支持好,逻辑推理强 | 中文客服、文档分析、复杂问答 |
| Llama 3 | Meta (Facebook) | 全球生态最丰富,指令遵循能力强,多语言支持好 | 通用对话、代码生成、国际化应用 |
| ChatGLM3/4 | 智谱 AI | 针对中文优化,显存占用极低,推理速度快 | 低配显卡部署、轻量级助手 |
| **Yi **(零一万物) | 零一万物 | 在数学推理和代码能力上表现卓越 | 科研辅助、编程助手 |
在智聊机器人的构建中,我们将根据硬件配置灵活切换这些模型,以实现性能与资源的最佳平衡。
🛠️ 第二章:筑基工程------本地私有化部署环境全解析
理论的价值在于指导实践。本章将详细拆解如何在一台普通的 Windows/Mac/Linux 电脑上,搭建起支撑"智聊机器人"运行的坚实底座。我们的目标是打造一个**"开箱即用、极简运维"**的开发环境。
2.1 核心技术栈选型
为了降低大模型部署的门槛,我们精心挑选了以下工具链,它们构成了智聊机器人的"骨架":
🔹 Ollama:大模型领域的"Docker"
Ollama 是本项目的核心推理引擎。它将复杂的模型加载、显存管理、量化加速等技术细节封装在黑盒中,对外提供简洁的命令行工具和 RESTful API。
- 核心价值:它让运行大模型像运行 Docker 容器一样简单。只需一条命令,即可自动下载并运行经过优化的模型版本。
- 功能特性:支持 Modelfile 自定义模型参数、自动 GPU 加速、多模型并发管理。
🔹 Streamlit:极速构建 AI 交互界面
Streamlit 是一个纯 Python 编写的 Web 应用框架,专为数据科学和机器学习项目设计。
- 核心价值:开发者无需掌握 HTML、CSS 或 JavaScript,仅用几十行 Python 代码即可构建出具有聊天窗口、文件上传、侧边栏配置等功能的专业级 Web 界面。
- 在项目中角色:作为"智聊机器人"的用户入口,负责接收用户输入并展示模型回复。
🔹 硬件基石:NVIDIA CUDA 生态
本地部署的性能瓶颈通常在于 GPU。NVIDIA 的 CUDA 并行计算架构是加速大模型推理的关键。
- 显存法则 :
- 6GB - 8GB 显存:可流畅运行 7B 参数量模型的 4-bit 量化版本。
- 12GB - 16GB 显存:可尝试 13B 模型或更高精度的 7B 模型。
- 24GB+ 显存:可运行 30B-70B 参数量的大模型,或进行多卡并行。
2.2 实战演练:从零搭建 Ollama 推理服务
以下步骤将引导你完成 Ollama 的安装与模型初始化,这是智聊机器人能够"思考"的前提。
步骤一:安装 Ollama 运行时
访问 Ollama 官方网站下载对应操作系统的安装包。安装过程极其简化,基本只需点击"Next"即可完成。安装结束后,Ollama 会自动在后台启动一个本地服务,默认监听端口为 11434。
我们可以通过终端命令验证安装是否成功:
bash
# 检查 Ollama 版本号,确认安装成功
ollama --version步骤二:拉取并运行智能模型
Ollama 内置了庞大的模型库(Library)。针对中文场景优化的需求,我们选择 qwen2.5(通义千问最新版)作为智聊机器人的默认大脑。为了适应大多数消费级显卡,我们特意选择 7b-instruct-q4_K_M 版本,这是一个经过 4-bit 量化处理的指令微调模型。
bash
# 拉取模型
# 说明:首次执行时会自动下载约 4.5GB 的模型文件,后续运行无需重复下载
# qwen2.5:7b-instruct-q4_K_M 表示:通义千问2.5代,70亿参数,指令微调版,4bit量化
ollama pull qwen2.5:7b-instruct-q4_K_M
# 运行模型并进入交互式对话
# 说明:此命令会加载模型到显存,并开启一个命令行聊天窗口
ollama run qwen2.5:7b-instruct-q4_K_M技术洞察 :为什么要用量化版(Quantized)?
原始的大模型权重通常是 16-bit 浮点数(FP16),7B 模型需要约 14GB 显存。通过量化技术将其压缩至 4-bit(Int4),显存占用可降低至 5-6GB,而精度损失通常小于 2%。这使得在普通游戏显卡上运行大模型成为可能。
步骤三:验证 API 接口连通性
Ollama 不仅仅是一个命令行工具,它本质上是一个 HTTP 服务器。智聊机器人的后端将通过 API 与其通信。我们可以使用 curl 命令模拟发送请求,测试服务是否正常。
bash
# 向 Ollama API 发送生成请求
# -d 参数指定 POST 请求的数据体(JSON 格式)
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b-instruct-q4_K_M", # 指定刚才下载的模型名称
"prompt": "你好,请简要介绍一下什么是私有化大模型?", # 用户输入的提示词
"stream": false # 设置为 false 表示一次性返回完整结果,便于测试
}'如果终端返回了一段包含 response 字段的 JSON 数据,且内容准确回答了问题,说明我们的推理引擎已经就绪,随时可以接受智聊机器人的调用。
2.3 智聊机器人系统架构全景图
基于上述组件,我们设计了智聊机器人的基础技术架构。这是一个典型的前后端分离结构,但所有组件均运行在本地局域网内。
架构设计亮点解析:
- 松耦合设计:前端(Streamlit)不直接依赖具体的模型文件,而是通过标准 API 与 Ollama 通信。这意味着如果我们想从 Qwen 切换到 Llama 3,只需修改后端配置中的模型名称,无需重构整个应用。
- 安全沙箱:所有数据流转(用户输入 -> 后端 -> Ollama -> 模型 -> 返回)均在本地内存或内网中进行,物理上隔绝了外部网络的窥探。
- 流式响应支持 :虽然测试时使用了
stream: false,但在实际智聊机器人应用中,我们将开启流式传输(Streaming),让用户看到文字逐字生成的效果,极大提升交互体验。
💡 第三章:深水区导航------关键挑战与优化策略
在实际的私有化部署过程中,初学者往往会遇到各种"坑"。基于项目经验,我们总结了以下三大挑战及其应对方案。
3.1 显存焦虑与量化技术的权衡
挑战 :许多开发者满怀热情地下载了 70B 参数的超大模型,结果发现显存瞬间爆满,程序崩溃。
深度解析 :
显存占用 = 模型参数量 × 精度字节数 + 上下文缓存(KV Cache)。
对于 7B 模型:
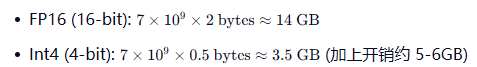
优化策略:
- 首选量化模型 :在生产环境中,除非有科研级的高精度需求,否则强烈推荐
q4_K_M或q5_K_M版本的模型。它们在性能和资源之间取得了最佳平衡。 - GPU 卸载(Offloading):Ollama 支持将部分模型层卸载到系统内存(RAM)。虽然速度会变慢(从 50 tokens/s 降至 5 tokens/s),但至少能让程序跑起来,避免直接报错。
3.2 中文语境下的"水土不服"
挑战 :直接使用原版 Llama 3 等国际模型时,可能会出现中文回答生硬、夹杂英文或无法理解中国特有文化梗的情况。
优化策略:
-
模型选型本土化:优先选用 Qwen(通义千问)、ChatGLM(智谱)、Yi(零一万物)等国产开源模型。它们在万亿级中文语料上进行了专项训练,更懂中文语境。
-
System Prompt (系统提示词):在发送给模型的请求中,预设系统指令。例如:
pythonsystem_instruction = "你是一个名为'智聊'的智能助手,由本地私有化部署驱动。请用专业、流畅且友好的中文回答用户问题,避免使用翻译腔。"这能显著引导模型的输出风格,使其更符合预期。
3.3 推理延迟与并发瓶颈
挑战 :当多个用户同时访问智聊机器人时,单张显卡的处理能力可能成为瓶颈,导致响应变慢。
优化策略:
- 批处理(Batching):Ollama 内部已实现了请求批处理机制,会自动将短时间内的多个请求合并计算,提高 GPU 利用率。
- 大小模型协同:设计路由机制,简单问题(如问候、查天气)由 1.8B 或 3B 的小模型快速回答;复杂问题(如代码生成、逻辑推理)再路由给 7B 或 13B 的大模型。
- 上下文窗口管理:限制单次对话的历史记录长度(如只保留最近 10 轮),减少 KV Cache 的显存占用,从而提升推理速度。
🔮 第四章:展望与过渡------从"能跑"到"好用"的进化之路
至此,我们已经完成了智聊机器人项目的第一阶段里程碑:成功在本地搭建了一个可运行、可交互的大模型环境。
回顾这段历程,我们从对大模型的宏观认知出发,经历了工具选型的纠结、环境配置的调试,最终看到了终端里跳动的字符。这不仅仅是一次技术的落地,更是一次思维的转变------我们不再是被动的 API 调用者,而是自己 AI 基础设施的构建者。
当前的成果:
- ✅ 理解了私有化部署的核心价值与安全优势。
- ✅ 掌握了 Ollama 工具的安装、模型拉取与 API 调用方法。
- ✅ 构建了基于 Streamlit + Ollama 的基础系统架构。
- ✅ 解决了显存优化与中文适配的关键问题。
但这只是起点。目前的智聊机器人还只是一个"裸机"状态:
- 它还没有一个美观、功能丰富的聊天界面(目前仅靠命令行或简易网页)。
- 它还没有记忆能力,无法记住上一轮对话的上下文(除了基础的多轮对话)。
- 我们还没有系统地测试它的 API 性能,不知道它在高负载下的表现如何。
- 它还没有连接任何外部工具或知识库,知识局限于训练数据截止日之前。
下一阶段的旅程 :
在接下来的第二篇智聊机器人博客中,我们将深入项目的核心内容,带领智聊机器人完成从"原型"到"产品"的蜕变:
- 接口调试与规范化 :引入 Apifox 工具,对 Ollama 的 API 进行全方位的测试、文档化管理和自动化校验,确保后端接口的稳健性。
- 交互体验升级 :集成 Chatbox 桌面客户端或深度定制 Streamlit 界面,实现Markdown 渲染、代码高亮、历史会话管理、文件上传等高级功能,让机器人真正"像人一样"交流。
- 全流程联调:将前端、后端、模型引擎无缝串联,打造一个真正的企业级"智聊机器人"应用。
私有化 AI 的大门已经打开,精彩的实战才刚刚开始。请保持期待,我们将在下一篇博文中继续携手前行,见证智聊机器人的完全体诞生!
写在最后 :
界面,实现Markdown 渲染、代码高亮、历史会话管理、文件上传等高级功能,让机器人真正"像人一样"交流。