NeurIPS 2024 Spotlight 3DGS经典Backbone工作3DGS-MCMC论文及代码解读
- [一、论文简介 🌟](#一、论文简介 🌟)
-
- [1.1 基本信息](#1.1 基本信息)
- [1.2 论文主要贡献](#1.2 论文主要贡献)
- [二、方法论 🍀](#二、方法论 🍀)
-
- [2.1 3D高斯泼溅简要回顾(Brief review of 3D Gaussian Splatting)](#2.1 3D高斯泼溅简要回顾(Brief review of 3D Gaussian Splatting))
- [2.2 将3D高斯泼溅视为马尔可夫链蒙特卡洛(3D Gaussian Splatting as Markov Chain Monte Carlo (MCMC))](#2.2 将3D高斯泼溅视为马尔可夫链蒙特卡洛(3D Gaussian Splatting as Markov Chain Monte Carlo (MCMC)))
- [2.3 使用随机梯度朗之万动力学进行更新(Updating with Stochastic Gradient Langevin Dynamics)](#2.3 使用随机梯度朗之万动力学进行更新(Updating with Stochastic Gradient Langevin Dynamics))
- [2.4 通过重定位将启发式方法视为状态转移(Heuristics as state transitions via relocation)](#2.4 通过重定位将启发式方法视为状态转移(Heuristics as state transitions via relocation))
- [2.5 鼓励更少的高斯体(Encouraging fewer Gaussians)](#2.5 鼓励更少的高斯体(Encouraging fewer Gaussians))
- [2.6 更多实现细节(More implementation details)](#2.6 更多实现细节(More implementation details))
- [2.7 结论(Conclusion)](#2.7 结论(Conclusion))
- [三、论文实验部分 🧪](#三、论文实验部分 🧪)
-
- [3.1 对比实验](#3.1 对比实验)
- [3.2 消融实验(Ablation Study)](#3.2 消融实验(Ablation Study))
- [四、论文代码解读 💻](#四、论文代码解读 💻)
- 写在最后
写在前面:如果想了解更多关于3DGS的加速压缩新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
一、论文简介 🌟
1.1 基本信息
- 📖 题目:3D Gaussian Splatting as Markov Chain Monte Carlo
- 🏫 单位:University of British Columbia;Google Research;Google DeepMind;Simon Fraser University;University of Toronto
- 🌍 主页:https://ubc-vision.github.io/3dgs-mcmc
- 🀄️ 论文摘要:虽然 3D 高斯泼溅(3DGS)最近在神经渲染中变得流行,但当前的方法依赖于精心设计的克隆和分裂策略来放置高斯体,这可能导致渲染质量不佳,并依赖于良好的初始化 。在本研究中,论文将 3D 高斯体集合重新构思为从描述场景物理表示的底层概率分布中抽取的随机样本------换句话说,即马尔可夫链蒙特卡洛(MCMC)样本 。在此视角下,论文证明通过简单地引入噪声,3D 高斯更新可以转换为随机梯度朗之万动力学(SGLD)更新 。随后,论文将 3D 高斯泼溅中的加密和剪枝策略重写为简单的 MCMC 样本确定性状态转移,从而从框架中移除了这些启发式方法 。为此,论文将高斯体的"克隆"修正为一种近似保持样本概率的重定位方案 。为了鼓励高效利用高斯体,论文引入了一个正则化项,以促进移除未使用的高斯体。在各种标准评估场景中,论文证明该方法提供了改进的渲染质量、对高斯体数量的简便控制以及对初始化的鲁棒性。
1.2 论文主要贡献
神经辐射场(NeRF)一直处于这些进展的前沿,通过神经网络进行隐式建模提供了令人印象深刻的结果,随着 3D 高斯泼溅(3DGS)的引入,3D 高斯泼溅因其速度和效率而变得非常受欢迎------它可以在 NeRF 所需时间的一小部分内渲染高质量图像。不出所料,针对 3D 高斯泼溅提出了各种扩展,例如将 3D 高斯体扩展到动态场景、使其对混叠效应具有鲁棒性以及生成式 3D 内容创作。
然而,尽管有各种扩展,这些方法的一个共同缺点是它们大多依赖相同的初始化和加密策略来放置高斯体:要么是最初建议的方法,要么是最近提出的其他变体 。具体来说,它们依赖精心设计的克隆和分裂启发式方法来放置高斯体 。根据每个高斯体的状态,它们被克隆、分裂或剪枝,这是控制 3DGS 表示中高斯体数量的主要方式 。此外,高斯体通过将它们的不透明度设置为较小值来定期"重置",以移除表示中的漂浮物 。这种基于启发式的方法需要仔细调整多个超参数,并且正如论文稍后将展示的那样,在某些场景中可能会失败。
这些启发式方法进一步导致了各种问题。它导致该方法严重依赖良好的初始点云才能发挥良好作用,尤其是在应用于现实世界场景时。也很难仅从超参数估计给定场景将使用多少 3D 高斯体,这使得难以在不影响推理过程中重建质量的情况下提前控制计算和内存预算。同时期的工作专注于拥有更好的初始化来解决前者,或研究后者的问题。然而,即使是这些最近的同期解决方案仍然依赖启发式方法,并且它们并不总是能很好地泛化 。在某些情况下,这会导致高斯体的次优放置,从而导致渲染质量差并浪费计算资源。
为了解决这个问题,论文退后一步,将 3D 高斯体集合重新构思为随机样本------更具体地说是马尔可夫链蒙特卡洛(MCMC)样本------这些样本是从与这些高斯体忠实重建场景程度成正比的底层概率分布中抽取的 。考虑到这一点,论文展示了传统的 3D 高斯泼溅更新规则与随机梯度朗之万动力学(SGLD)更新非常相似,其中唯一缺失的项是促进样本探索的噪声项 。因此,论文将 3D 高斯泼溅重新表述为一个 SGLD 框架,这是一种 MCMC 算法,它自然地探索场景景观,并采样能够有效忠实再现场景的高斯体 。重要的是要注意,虽然论文假设了一个底层分布,但这个分布不需要显式建模,因为高斯体本身已经代表了它。
基于这种视角,涉及高斯体加密和剪枝以及重置其不透明度的启发式方法不再是必要的 。3D 高斯体只是用于 MCMC 的样本,因此探索它们的样本位置通过 SGLD 更新自然处理 。对高斯体集合的任何修改,包括增加或减少其基数,都可以重新表述为确定性的状态转移------即高斯体的重定位,论文将样本(高斯体集合)移动到另一个样本(具有不同配置的另一个高斯体集合)。重要的是,为了最小程度地扰动 MCMC 采样链,论文确保移动前后的两个状态具有相似的概率。这意味着当论文改变组合属性(如表示中的高斯体数量)时,训练损失值不会改变,从而防止训练过程变得不稳定 。在 MCMC 框架下,这种简单的策略足以提供高质量的渲染,超越了传统启发式方法所能提供的效果。
更具体地说,论文建议使用一种"克隆"策略来重定位高斯体,即将"死亡"的高斯体(低不透明度)移动到其他"存活"的高斯体存在的地方,但这种方式对渲染的影响最小,因此对高斯体的概率分布影响也最小 。换句话说,论文设置克隆高斯体的组成,使其渲染出的图像与克隆前相同 。虽然最近有研究建议对克隆进行修改以确保在高斯中心处的渲染相等,但论文证明这还不够,必须考虑整个高斯体。如果没有论文精心设计的策略,MCMC 采样会提供次优的训练。最后,为了鼓励高效使用高斯体,论文应用了 L 1 L_1 L1 正则化 。由于高斯体的范围由不透明度和尺度共同定义,论文将正则化同时应用于两者 。这有效地鼓励它们在不必要时"消失"。
论文在标准场景上评估了该方法,包括 NeRF Synthetic、MipNeRF 360、Tank & Temples 和 Deep Blending,以及展示了大型场景背景的 OMMO 数据集 。使用论文的方法,不需要仔细初始化高斯体。无论高斯体是随机初始化还是从运动复原(SfM)点初始化的,论文的方法都能提供高质量的渲染。
论文的主要贡献如下:
- 论文为3DGS引入3D平滑滤波器,有效正则化3D高斯基元的最大频率,解决了先前方法在超出训练分布渲染时的伪影问题。
- 论文将二维膨胀滤波器替换为二维Mip滤波器,以处理混叠和膨胀伪影。
- 在benchmark上的实验验证了论文在修改采样率情况下的有效性。
综上所述,论文的贡献是:
- 论文揭示了 3DGS 与 MCMC 采样之间的联系,从而实现了更简单的优化;
- 论文用原则性的重定位策略取代了 3D 高斯泼溅中的启发式方法;
- 论文引入了正则化项以鼓励精简地使用高斯体;
- 论文提高了对初始化的鲁棒性;
- 论文提供了更高的渲染质量。
二、方法论 🍀
论文首先将高斯泼溅重新表述为马尔可夫链蒙特卡洛(MCMC)采样。随后,论文在带有随机梯度朗之万动力学(SGLD)的 MCMC 框架下引入新的更新方程。接着,论文讨论了如何将 3D 高斯泼溅中的启发式方法整合到一个新型重定位方案中 。最后,论文讨论了用于鼓励高效利用高斯体的 L 1 L_1 L1 正则化以及实现细节。
2.1 3D高斯泼溅简要回顾(Brief review of 3D Gaussian Splatting)
在重新表述之前,为了完整性,论文首先简要回顾了 3D 高斯泼溅 。3D 高斯泼溅将场景表示为一组 3D 高斯体,随后通过 α \alpha α-混合将其光栅化到所需的视图中。这可以被视为执行类似 NeRF 中体积渲染的一种高效方式。具体而言,对于相机姿态 θ \theta θ,为了渲染像素 x x x,论文通过按距离相机增加的顺序对 N N N 个高斯体进行排序,并写作:
C ( x ) = ∑ i = 1 N c i α i ( x ) ∏ j = 1 i − 1 ( 1 − α j ( x ) ) ( 1 ) C(x)=\sum_{i=1}^{N}c_{i}\alpha_{i}(x)\\prod_{j=1}\^{i-1}(1-\\alpha_{j}(x)) \quad(1) C(x)=i=1∑Nciαi(x)j=1∏i−1(1−αj(x))(1)
其中 c i c_{i} ci 是每个高斯体的颜色,以球谐函数形式存储,并根据姿态 θ \theta θ 转换为颜色;如果论文将其不透明度表示为 o o o,中心表示为 μ \mu μ,协方差表示为 Σ \Sigma Σ ,则有:
α i ( x ) = o i e x p ( − 1 2 ( x − R ( μ i ; θ ) ) T R θ ( Σ i ) − 1 ( x − R ( μ i ; θ ) ) ) ( 2 ) \alpha_{i}(x)=o_{i}exp(-\frac{1}{2}(x-\mathcal{R}(\mu_{i};\theta))^{T}\mathcal{R}{\theta}(\Sigma{i})^{-1}(x-\mathcal{R}(\mu_{i};\theta))) \quad(2) αi(x)=oiexp(−21(x−R(μi;θ))TRθ(Σi)−1(x−R(μi;θ)))(2)
其中 R \mathcal{R} R 是相机投影操作 。随后,利用每个像素的颜色值,训练高斯体以最小化损失:
L o r i g = ( 1 − λ D − S S I M ) ⋅ L 1 + λ D ⋅ S S I M ⋅ L D ⋅ S S I M ( 3 ) \mathcal{L}{orig}=(1-\lambda{D-SSIM})\cdot\mathcal{L}{1}+\lambda{D\cdot SSIM}\cdot\mathcal{L}_{D\cdot SSIM}\quad(3) Lorig=(1−λD−SSIM)⋅L1+λD⋅SSIM⋅LD⋅SSIM(3)
其中 L 1 \mathcal{L}{1} L1 是 C ( x ) C(x) C(x) 与真实颜色 C g t ( x ) C{gt}(x) Cgt(x) 之间的平均 L 1 L_1 L1 误差,而 L D ⋅ S S I M \mathcal{L}{D\cdot SSIM} LD⋅SSIM 是渲染图像与真实图像之间的结构相似性指数(SSIM) 。其中 λ D ⋅ S S I M = 0.2 \lambda{D\cdot SSIM}=0.2 λD⋅SSIM=0.2,如原研究所建议。
2.2 将3D高斯泼溅视为马尔可夫链蒙特卡洛(3D Gaussian Splatting as Markov Chain Monte Carlo (MCMC))
与现有的 3D 高斯泼溅方法不同,论文建议将放置和优化高斯体的训练过程解释为一个采样过程 。论文没有定义损失函数并简单地向局部最小值迈进,而是定义了一个分布 G \mathcal{G} G,该分布为忠实重建训练图像的高斯体集合分配高概率。这种选择允许论文利用 MCMC 框架的力量从该分布中抽取样本,其方式在数学上是良好的,即使在参数空间中进行离散更改时也是如此 。因此,论文可以设计类似于高斯泼溅原始分裂和剪枝启发式方法的离散操作,而不会破坏作为典型基于梯度优化基础的连续性假设。为了实现这一点,论文从随机梯度朗之万动力学(SGLD)方法开始,这是一种 MCMC 框架,最近也已应用于新视角合成应用 。这一特定选择非常方便,因为 SGLD 已经类似于常用的随机梯度下降(SGD)更新规则,但增加了随机噪声 。具体来说,如果论文考虑 3DGS 中单个高斯体 g g g 的更新,并暂时忽略其分裂/合并启发式方法:
g ← g − λ l r ⋅ ∇ g E I ∼ I L t o t a l ( g ; I ) ( 4 ) g\leftarrow g-\lambda_{lr}\cdot\nabla_{g}\mathbb{E}_{I\sim\mathcal{I}}\\mathcal{L}_{total}(g;I) \quad (4) g←g−λlr⋅∇gEI∼ILtotal(g;I)(4)
其中 λ l r \lambda_{lr} λlr 是学习率, I I I 是从训练图像集 I \mathcal{I} I 中采样的图像 。现在让论文将前者与典型的 SGLD 更新进行比较:
g ← g + a ⋅ ∇ g l o g P ( g ) + b ⋅ ϵ ( 5 ) g\leftarrow g+a\cdot\nabla_{g}log\mathcal{P}(g)+b\cdot\epsilon \quad(5) g←g+a⋅∇glogP(g)+b⋅ϵ(5)
其中 P \mathcal{P} P 是希望从中采样的分布的数据相关概率密度函数,而 ϵ \epsilon ϵ 是用于探索的噪声分布 。超参数 a a a 和 b b b 共同控制收敛速度与探索之间的权衡 。论文注意到 (4) 和 (5) 之间显著的相似性 。换句话说,通过将损失作为基础分布的负对数似然:
G = P ∝ e x p ( − L t o t a l ) ( 6 ) \mathcal{G}=\mathcal{P}\propto exp(-\mathcal{L}_{total}) \quad(6) G=P∝exp(−Ltotal)(6)
如果 λ l r = − a \lambda_{lr}=-a λlr=−a 且 b = 0 b=0 b=0,方程将变得完全一致 。因此,标准高斯泼溅优化可以被理解为高斯体是从与渲染质量相关的似然分布中采样的。论文进一步指出,这种在优化中加入噪声的做法与传统的注入噪声的优化方法或执行扰动梯度下降的方法高度相关。在此,论文将其表述为 MCMC,这有利于它在 (6) 中提供的概率关系,以及它所实现的启发式方法的移除,这将在第 2.4 节中讨论 。
在典型的 SGLD 形式中, b b b 通常表示为 a a a 和另一个超参数的函数,但论文遵循文献 20,在不失一般性的情况下将其改写为这种形式。
2.3 使用随机梯度朗之万动力学进行更新(Updating with Stochastic Gradient Langevin Dynamics)
在揭示了 SGLD 与传统 3DGS 优化之间的联系后,论文将 (4) 改写为:
g ← g − λ l r ⋅ ∇ g E I ∼ I L t o t a l ( g ; I ) + λ n o i s e ⋅ ϵ ( 7 ) g\leftarrow g-\lambda_{lr}\cdot\nabla_{g}\mathbb{E}{I\sim\mathcal{I}}\\mathcal{L}_{total}(g;I)+\lambda{noise}\cdot\epsilon \quad (7) g←g−λlr⋅∇gEI∼ILtotal(g;I)+λnoise⋅ϵ(7)
其中 λ l r \lambda_{lr} λlr 和 λ n o i s e \lambda_{noise} λnoise 是控制学习率和 SGLD 强制执行的探索量的超参数。 在实践中,论文使用带有默认 β 1 \beta_{1} β1 和 β 2 \beta_{2} β2 参数的 Adam 优化器,而不是原始梯度 ∇ g E I ∼ I L t o t a l ( g ; I ) \nabla_{g}\mathbb{E}_{I\sim\mathcal{I}}\\mathcal{L}_{total}(g;I) ∇gEI∼ILtotal(g;I)。
在方程 (7) 中,精心设计噪声项 ϵ \epsilon ϵ 至关重要。 噪声项 ϵ \epsilon ϵ 需要以能够被梯度项 ∇ g L t o t a l \nabla_{g}\mathcal{L}_{total} ∇gLtotal "平衡"的方式添加,否则 (7) 就会退化为随机更新。 例如,在重建场景以表示线条和边缘时,高斯体通常很窄。 如果添加的噪声迫使高斯体移动到先前支持区域之外的位置,这种随机游走将是不可恢复的,从而破坏 MCMC 采样链。
论文进一步注意到,探索对于不透明度、尺度和颜色并不重要,论文不对这些参数添加噪声。 事实上,论文通过实验发现,对它们添加噪声会略微损害性能。 相反,已有研究表明,当空间区域未被探索时(例如由于初始化中缺少点),3DGS 重建会受到显著损害。 这表明基于噪声的探索有可能改善随机初始化以及受几何缺失影响的 SfM 衍生初始化的结果。
最后,由于论文关注的是"收敛"质量而不仅仅是探索,论文在模型表现良好时减少噪声量,即当高斯体的不透明度足够高,足以被梯度良好引导时。 因此,论文仅在模型的位置上设计噪声项,使其取决于它们的协方差、不透明度以及学习率:
ϵ μ = λ l r ⋅ σ ( − k ( t − o ) ) ⋅ Σ η , w h e r e ϵ = ϵ μ , 0 ( 8 ) \epsilon_{\mu}=\lambda_{lr}\cdot\sigma(-k(t-o))\cdot\Sigma\eta, \space where \space \epsilon=\\epsilon_{\\mu},0 \quad (8) ϵμ=λlr⋅σ(−k(t−o))⋅Ση, where ϵ=ϵμ,0(8)
其中 η ∼ N ( 0 , I ) \eta\sim\mathcal{N}(0,I) η∼N(0,I), σ \sigma σ 是 sigmoid 函数, k k k 和 t t t 是控制 sigmoid 锐度的超参数,论文将其设置为 k = 100 k=100 k=100 和 t = 0.005 t=0.005 t=0.005,以创建一个从零到一的尖锐过渡函数,该函数以 3D 高斯泼溅中高斯体不透明度值的默认剪枝阈值为中心。 简单来说,(8) 用具有相同各向异性分布的各向异性噪声扰动高斯体,而 sigmoid 项则减少了噪声对不透明高斯体的影响。
2.4 通过重定位将启发式方法视为状态转移(Heuristics as state transitions via relocation)
受 MCMC 中的跳跃和重采样移动启发 ,论文现在讨论如何将 3D 高斯泼溅中的启发式方法重写为简单的状态转移。在 3D 高斯泼溅中,启发式方法被用于"移动"、"分裂"、"克隆"、"剪枝"和"添加"高斯体,以鼓励产生更多"存活"的高斯体 ( o i > 0.005 o_{i}>0.005 oi>0.005) 。论文将所有这些修改解释为从一个样本状态 g o l d g^{old} gold 转移到另一个样本状态 g n e w g^{new} gnew 。这也适用于高斯体数量发生变化的情况,因为人们可以将高斯体数量较少的状态简单地视为具有更多高斯体的等效状态,只是那些多出的高斯体具有零不透明度,即死亡高斯体 。重要的是,为了将这些确定性移动整合到 MCMC 框架中,必须确保它们不会导致 MCMC 采样崩溃 。具体来说,论文的目标是保持移动前后样本状态的概率,即 P ( g n e w ) = P ( g o l d ) \mathcal{P}(g^{new})=\mathcal{P}(g^{old}) P(gnew)=P(gold),使得该移动可以被视为简单地跳向另一个具有相等概率的样本 。
论文现在详细说明如何实现这一点 。虽然可以有多种方式,但论文选择了一种简单的策略,即将"死亡"高斯体 ( o i < 0.005 o_{i}<0.005 oi<0.005) 移动到"存活"高斯体的位置 。在此过程中,论文设置高斯体的参数,以最小化 g n e w g^{new} gnew 和 g o l d g^{old} gold 提供的渲染影响之间的差异 。论文在附录 A 中提供了确切的推导,此处给出更新方程 。在不失一般性的情况下,考虑将 N − 1 N-1 N−1 个高斯体 g 1 , . . . , N − 1 g_{1,...,N-1} g1,...,N−1 移动到 g N g_{N} gN 。然后,用上标 o l d old old 表示旧的高斯体参数,用 n e w new new 表示新的参数,论文写作:
μ 1 , . . . , N n e w = μ N o l d , o 1 , . . . , N n e w = 1 − 1 − o N o l d N , Σ 1 , . . . , N n e w = ( o N o l d ) 2 ( ∑ i = 1 N ∑ k = 0 i − 1 ( ( i − 1 k ) ( − 1 ) k ( o N n e w ) k + 1 k + 1 ) ) − 2 Σ N o l d ( 9 ) \mu_{1,...,N}^{new}=\mu_{N}^{old}, o_{1,...,N}^{new}=1-\sqrtN{1-o_{N}^{old}}, \\ \Sigma_{1,...,N}^{new}=(o_{N}^{old})^{2}(\sum_{i=1}^{N}\sum_{k=0}^{i-1}(\binom{i-1}{k}\frac{(-1)^{k}(o_{N}^{new})^{k+1}}{\sqrt{k+1}}))^{-2}\Sigma_{N}^{old} \quad (9) μ1,...,Nnew=μNold,o1,...,Nnew=1−N1−oNold ,Σ1,...,Nnew=(oNold)2(i=1∑Nk=0∑i−1((ki−1)k+1 (−1)k(oNnew)k+1))−2ΣNold(9)
虽然乍一看,论文选择的策略可能与 3D 高斯泼溅中的"克隆"相似,但 (9) 带来的差异至关重要。在图 1 中,论文展示了一个简化的一维示例,当 o N o l d = 0.95 o_{N}^{old}=0.95 oNold=0.95 时的情况 。如图所示,传统的克隆方法以及最近提出的"中心修正"版本都导致在执行克隆时光栅化高斯体产生显著差异 。这是因为在 (1) 中,合成的不透明度是多个高斯形状及其负值的乘积 。现有的两种策略都会导致所选高斯体的范围扩大,从而在这些状态的相似性方面产生显著差异,即 P ( g n e w ) ≠ P ( g o l d ) \mathcal{P}(g^{new})\ne\mathcal{P}(g^{old}) P(gnew)=P(gold) 。事实上,这会导致训练效果不佳。
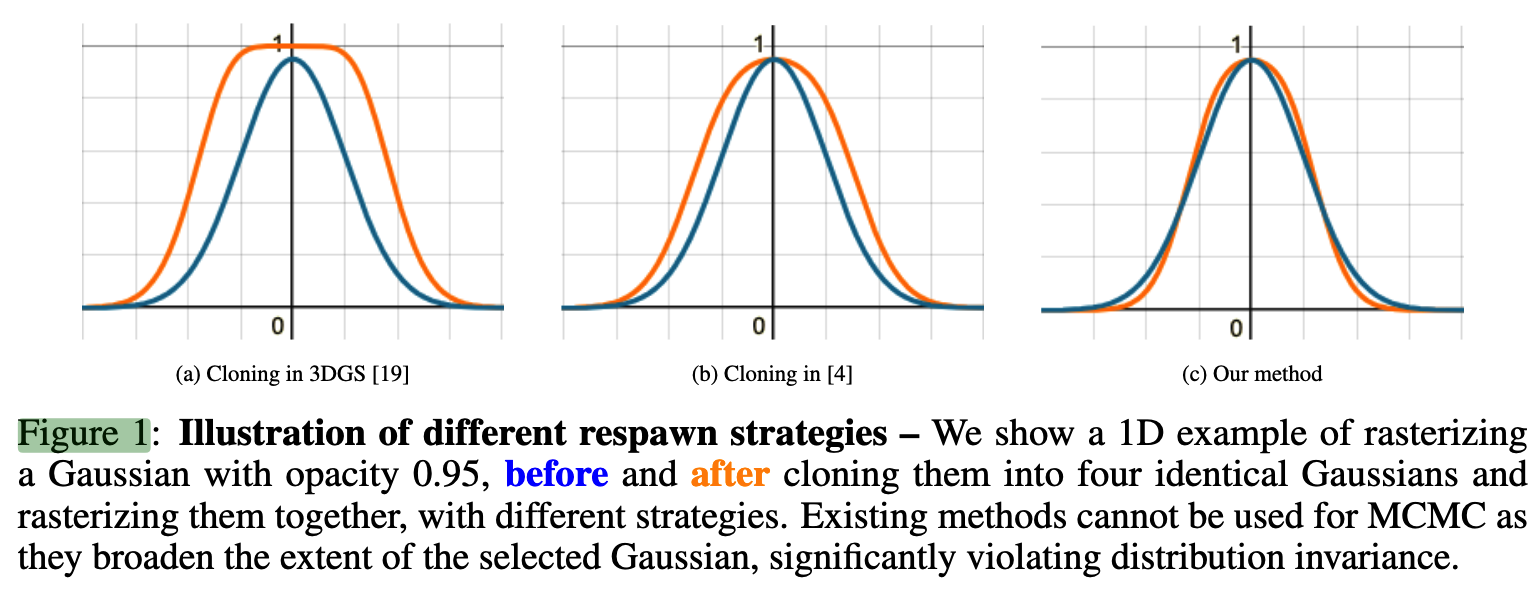
实现(Implementation) 。虽然论文的方法实现了 P ( g n e w ) ≈ P ( g o l d ) \mathcal{P}(g^{new})\approx\mathcal{P}(g^{old}) P(gnew)≈P(gold),但这并不精确。因此,论文每 100 次迭代执行一次此移动,以避免干扰训练过程。为了选择移动到何处,对于每个死亡高斯体,论文首先通过对存活高斯体进行多项式采样来选择目标高斯体进行移动/传送,采样概率与它们的不透明度值成正比。请注意,只有在做出所有移动决策后,论文才会应用 (9) 。最后,由于论文依赖 Adam 优化器,动量统计量也应进行调整 。论文重置目标高斯体(即被克隆的原始高斯体)的动量统计量,使其倾向于保持静止;而对于新的高斯体(源),论文保留动量统计量以鼓励探索 。这是因为"死亡"(源)高斯体受 (7) 中的噪声项支配,因此动量统计量适合促进探索。
2.5 鼓励更少的高斯体(Encouraging fewer Gaussians)
为了在提高性能的同时有效利用内存和计算资源,论文鼓励高斯体在无用位置消失并在其他地方"重生" 。由于高斯体的存在实际上由其不透明度 o o o 和协方差 Σ \Sigma Σ 决定,论文对这两者都应用了正则化。论文的完整训练损失为:
L t o t a l = ( 1 − λ D ⋅ S S I M ) ⋅ L 1 + λ D ⋅ S S I M ⋅ L D ⋅ S S I M + λ o ⋅ ∑ i ∣ o i ∣ 1 + λ Σ ⋅ ∑ i j ∣ e i g j ( Σ i ) ∣ 1 ( 10 ) \mathcal{L}{total}=(1-\lambda{D\cdot SSIM})\cdot\mathcal{L}{1}+\lambda{D\cdot SSIM}\cdot\mathcal{L}{D\cdot SSIM}+\lambda{o}\cdot\sum_{i}|o_{i}|{1}+\lambda{\Sigma}\cdot\sum_{ij}|\sqrt{eig_{j}(\Sigma_{i})}|_{1} \quad (10) Ltotal=(1−λD⋅SSIM)⋅L1+λD⋅SSIM⋅LD⋅SSIM+λo⋅i∑∣oi∣1+λΣ⋅ij∑∣eigj(Σi) ∣1(10)
其中 e i g j ( : ) eig_{j}(:) eigj(:) 表示协方差矩阵的第 j j j 个特征值(即沿协方差矩阵主轴的方差),而 λ o \lambda_{o} λo 和 λ Σ \lambda_{\Sigma} λΣ 是超参数 。
2.6 更多实现细节(More implementation details)
论文在 3DGS框架的基础上,使用 PyTorch 实现了该方法 。
高斯体数量的逐渐增加(Gradual increase in the number of Gaussians):与其它研究一样,论文允许高斯体的数量逐渐增长,以便将高斯体放置在有用的位置 。论文通过最初从选定数量的高斯体开始,然后通过之前在第 2.4 节中详述的重定位策略,允许更多的"死亡"高斯体变为"存活"状态来实现这一点 。具体而言,论文将存活高斯体的数量逐渐增加 5%,直到达到所需的高斯体最大数量。
初始化与训练(Initialization and training) :论文要么随机初始化样本,要么从点云初始化样本,通常像 3DGS 那样使用运动复原(SfM)点云 。对于随机初始化,论文遵循 3DGS,在相机边界框范围的三倍内均匀随机采样 10 万个高斯体 。论文还使用了相同的学习率和学习率调度器以便进行比较。对于高斯体的位置,论文从 1.6 e − 4 1.6e^{-4} 1.6e−4 的学习率开始,并将其指数衰减至 1.6 e − 6 1.6e^{-6} 1.6e−6 。对于所有实验,除非另有说明,论文使用 λ n o i s e = 5 × 10 5 \lambda_{noise}=5\times10^{5} λnoise=5×105、 λ Σ = 0.01 \lambda_{\Sigma}=0.01 λΣ=0.01 和 λ o = 0.01 \lambda_{o}=0.01 λo=0.01 。对于 Deep Blending,论文使用 λ o = 0.001 \lambda_{o}=0.001 λo=0.001 。遵循 3DGS,论文从 500 次预热迭代开始,在此期间不执行第 2.4 节中的重定位,也不增加高斯体的数量 。
2.7 结论(Conclusion)
在本文中,论文将 3D 高斯泼溅训练重新表述为马尔可夫链蒙特卡洛(MCMC),并通过随机梯度朗之万动力学(SGLD)进行实现 。通过这种方式,论文证明了可以消除对点云初始化的需求,并避免了基于启发式的加密、剪枝和重置 。论文不仅证明了该策略在各种场景中具有良好的泛化能力,优于原始的 3D 高斯泼溅,而且论文首次证明了这使得 3DGS 实现在挑战性的 MipNeRF 360数据集上击败了 NeRF 骨干网络。
三、论文实验部分 🧪
3.1 对比实验
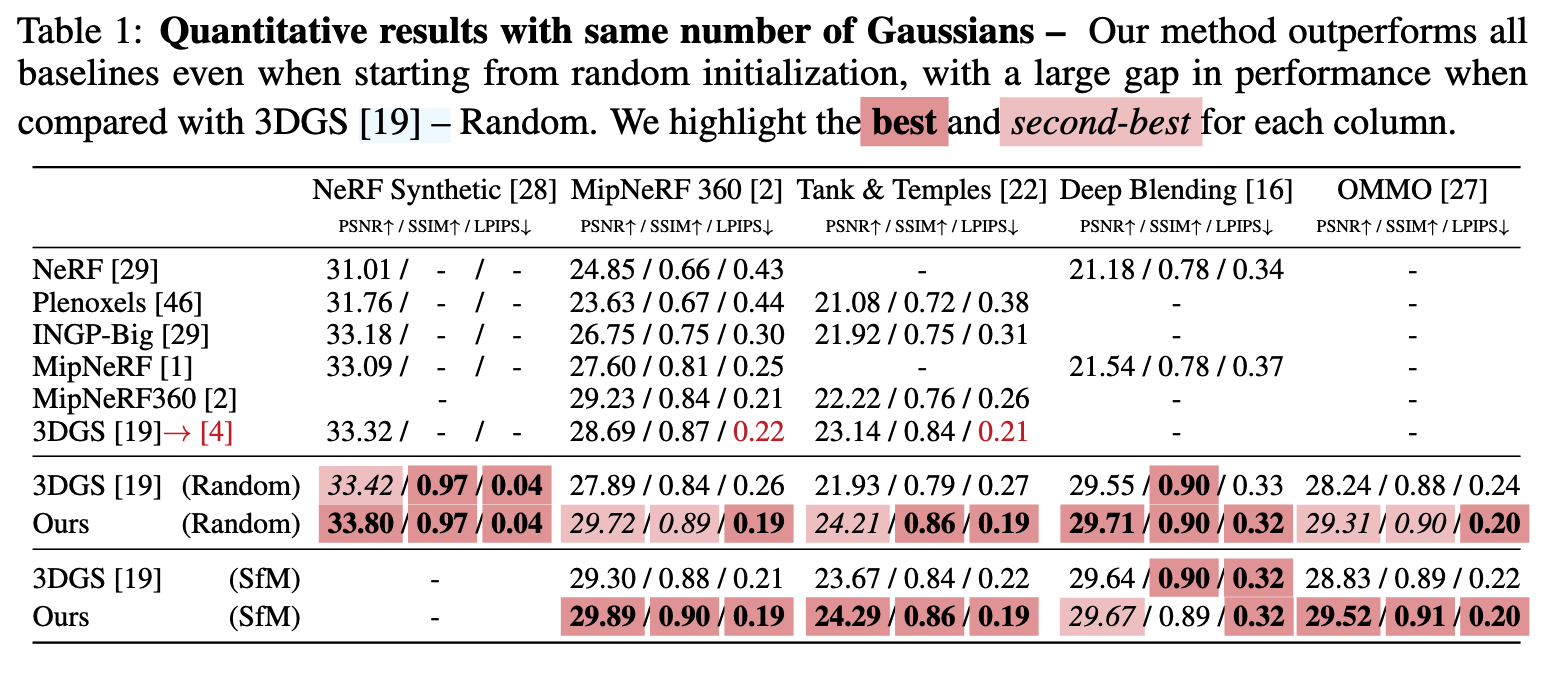

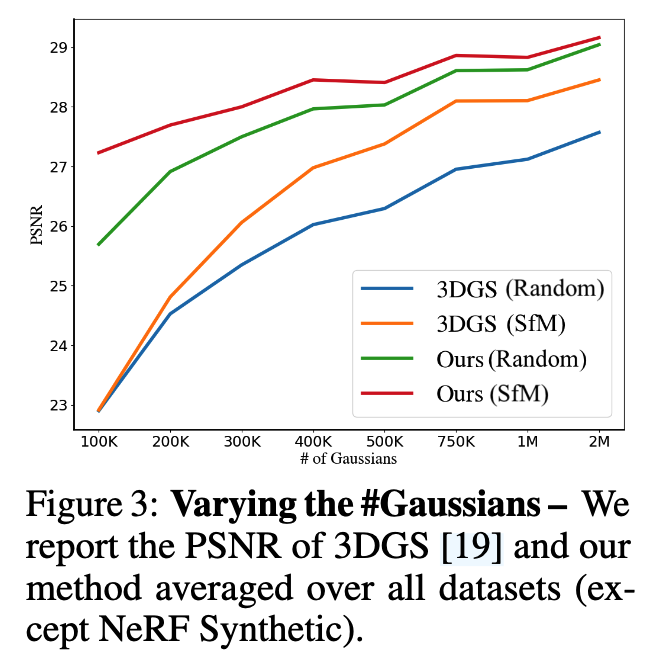
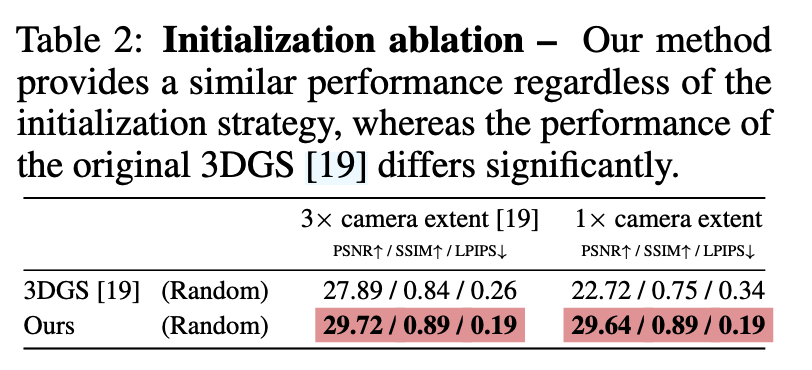
3.2 消融实验(Ablation Study)


四、论文代码解读 💻
待补充。
写在最后
由于笔者🖊️精力有限且本文更多的目的是通过📒博客记录学习过程并分享更多知识,因此文中部分描述不太具体,如有不太理解💫的地方可在评论区👀留言。非特殊赶deadline⏰或假期⛱️期间,笔者会经常上线回复💬。如有不便之处,请海涵~
如果想了解更多关于3DGS的加速⏰压缩⚡️新工作,可以关注笔者的Github仓库:Awesome-3DGS-Compress-Accelerate。
另外,创造不易,转载请注明出处💗💗💗~