文章目录
- [【1】 发现问题与解决问题](#【1】 发现问题与解决问题)
-
- [1.1 面临的问题](#1.1 面临的问题)
- [1.2 本文的贡献](#1.2 本文的贡献)
- [【2】 数据集](#【2】 数据集)
-
- [2.1 OuluVS2 数据库](#2.1 OuluVS2 数据库)
- [2.2 AVIC 语料库 (Audio-Visual Interest Corpus)](#2.2 AVIC 语料库 (Audio-Visual Interest Corpus))
- [2.3 AVIC 的 ROI 提取流程](#2.3 AVIC 的 ROI 提取流程)
- [【3】 本文的模型架构](#【3】 本文的模型架构)
-
- [3.1 编码阶段](#3.1 编码阶段)
- [3.2 时序建模与融合](#3.2 时序建模与融合)
- [3.3 分类决策(关键差异点)](#3.3 分类决策(关键差异点))
- [【4】 实验设置与核心训练策略](#【4】 实验设置与核心训练策略)
-
- [4.1 数据预处理](#4.1 数据预处理)
- [4.2 训练策略](#4.2 训练策略)
- [【5】 实验结果分析与核心发现](#【5】 实验结果分析与核心发现)
-
- [5.1 AVIC 数据集:非语言发声识别](#5.1 AVIC 数据集:非语言发声识别)
-
- [1. 评价指标的选择](#1. 评价指标的选择)
- [2. 核心结论:SOTA 的突破](#2. 核心结论:SOTA 的突破)
- [5.2 OuluVS2 数据集:视听语音识别](#5.2 OuluVS2 数据集:视听语音识别)
-
- [1. 干净环境下的"天花板效应"](#1. 干净环境下的“天花板效应”)
- [2. 噪声环境下的"鲁棒性"](#2. 噪声环境下的“鲁棒性”)
- [3. 多视角分析](#3. 多视角分析)
原文标题 :End-to-End Audiovisual Fusion with LSTMs
发表年份 :2017
核心思想 :本文是《End-to-end visual speech recognition with LSTMs》的进阶篇。它将基于 LSTM 的端到端架构从**视觉(Visual)扩展到了视听(Audiovisual)**领域,并将任务从单纯的"说话内容识别"扩展到"语音识别和非语言发声分类"。
【1】 发现问题与解决问题
1.1 面临的问题
在本文发表之前,视听融合领域存在两个主要痛点:
- 联合学习的缺失 :关于同时提取音频和视觉特征并进行联合分类的研究非常有限。
- 非端到端的主流 :大多数工作仍遵循"特征提取器(提取特征)+ 分类器(特征分类)"的分步范式,这并不是真正的端到端模型。
- 注:在 2017 年之前,《Lip Reading Sentences in the Wild》是唯一一篇尝试端到端视听训练的工作,但它依然依赖于手工提取的 MFCC 特征,而非原始数据。
1.2 本文的贡献
在这项工作中,作者提出了一种基于 双向长短期记忆(BLSTM) 网络的端到端视听模型。
- 首创性 :这是第一个直接从**原始嘴部 ROI(像素)和频谱图(原始音频特征)**执行视听融合的端到端模型。
- 能力:它能够同时学习特征提取与分类,适用于语音识别和非语言发声分类任务。
【2】 数据集
本研究使用了两个具有显著差异的数据集,分别用于验证不同场景下的模型性能。
2.1 OuluVS2 数据库
- 任务类型:视听语音识别。
- 数据规模:包含 52 位说话者。每人朗读 10 个日常短语(如 "Excuse me", "Goodbye"),每个短语重复 3 次 。
- 数据集划分:采用 35 人训练,5 人验证,12 人测试的划分标准。
- 关键特性 :多视角 。这是 2017 年前唯一公开的包含 5 个不同嘴部视角的数据集,涵盖从正面到侧面 ( 0 ∘ , 3 0 ∘ , 4 5 ∘ , 6 0 ∘ , 9 0 ∘ 0^{\circ}, 30^{\circ}, 45^{\circ}, 60^{\circ}, 90^{\circ} 0∘,30∘,45∘,60∘,90∘) 。
- 技术细节 :
- 格式:视频帧率 30 fps,音频采样率 48 kHz。
- 预处理:数据集直接提供了嘴部 ROI,本研究仅根据原始纵横比进行了缩放。
2.2 AVIC 语料库 (Audio-Visual Interest Corpus)
- 任务类型:非语言发声分类。
- 数据规模:包含 21 名受试者(11 男 10 女),多数为非英语母语者。
- 数据集划分:7 人训练,7 人验证,7 人测试 。
- 场景描述 :这是一个基于商业推销情景的二元自然互动数据集。实验者扮演推销员,受试者根据兴趣做出真实的自然反应 。
- 关键特性 :类别不平衡 。共识别 4 类发声:
- 笑声:247 个样本
- 犹豫:1136 个样本(大类)
- 同意:308 个样本
- 垃圾类:582 个样本(包含其他噪音)
- 技术细节 :
- 格式:视频帧率 25 fps,音频采样率 44.1 kHz。
- 数据清洗 :剔除了时长 ≤ 120 m s \le 120ms ≤120ms 的过短样本。
2.3 AVIC 的 ROI 提取流程
由于 AVIC 是自然场景视频,不提供现成的 ROI,论文设计了以下提取流水线:
- 追踪 (Tracking):使用追踪器检测 68 个面部关键点。
- 对齐 (Alignment):基于 5 个稳定点(双眼眼角 + 鼻尖),利用仿射变换校正人脸旋转和大小。
- 裁剪 (Cropping) :定位嘴部中心,裁剪出 85 × 129 85 \times 129 85×129 像素的边界框。
- 缩放 (Downscaling) :最终输入网络的嘴部 ROI 大小调整为 30 × 45 30 \times 45 30×45 像素。
思考:为什么要缩放得这么小?
深度学习模型(尤其是 LSTM/BLSTM)对输入维度非常敏感。较小的输入尺寸能显著减少参数量和训练时间。虽然图片变模糊了,但嘴巴的完整性得以保留。模型依然能看清"嘴巴是张开还是闭合",这对于识别发声任务来说已经足够了。
【3】 本文的模型架构
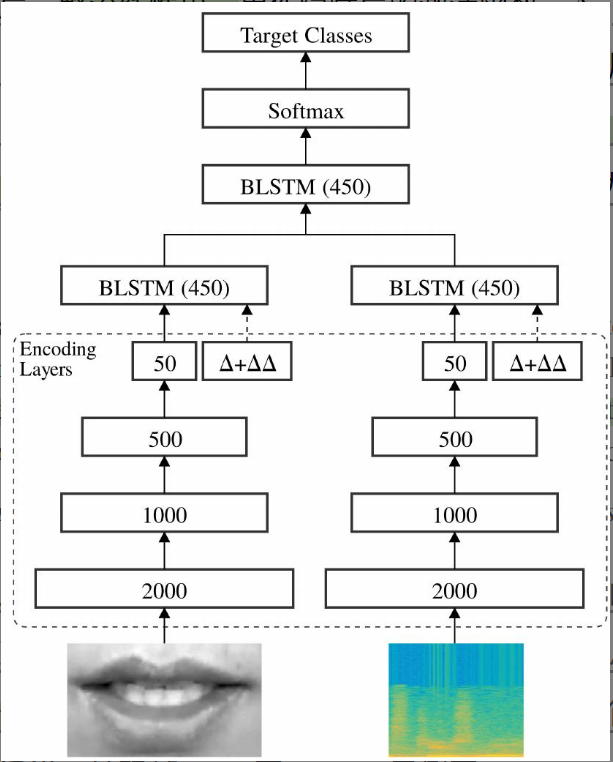
总体架构 :模型由两个相同的流组成,分别处理视觉和音频。每个流包含两部分:编码器 和 BLSTM。
3.1 编码阶段
- 结构 :编码器遵循瓶颈架构,旨在将高维输入压缩为低维表示。包含 3 个隐藏层(2000 → \to → 1000 → \to → 500),最后是一个线性瓶颈层。
- 激活函数:隐藏层使用 ReLU。
- 动态特征 :基于瓶颈特征计算 Δ \Delta Δ(一阶导数)和 Δ Δ \Delta\Delta ΔΔ(二阶导数)特征,并将它们拼接回瓶颈层,增强动态捕捉能力。
举例:数学视角看编码过程
1. 输入特征
假设原始特征向量(维度 4)为:
X = 10 , − 5 , 20 , − 8 X = 10, -5, 20, -8 X=10,−5,20,−82. 隐藏层变换
这一步的核心公式是 Z = W ⋅ X + b Z = W \cdot X + b Z=W⋅X+b(权重矩阵乘输入 + 偏置)。它是实现维度压缩( 4 维 → 3 维 4\text{维} \to 3\text{维} 4维→3维)的关键。
假设网络学习到的权重矩阵 W W W ( 3 × 4 3 \times 4 3×4) 和偏置向量 b b b 如下:
W = 0.1 1.0 0 0 0.5 0 0.1 0 0 0 0 0.25 , b = 1 0 0 W = \begin{bmatrix} 0.1 & 1.0 & 0 & 0 \\ 0.5 & 0 & 0.1 & 0 \\ 0 & 0 & 0 & 0.25 \end{bmatrix}, \quad b = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix} W= 0.10.501.00000.10000.25 ,b= 100具体计算过程(点积运算):
- 神经元 1 : ( 0.1 × 10 ) + ( 1.0 × − 5 ) + ( 0 × 20 ) + ( 0 × − 8 ) + 1 = 1 − 5 + 1 = − 3 (0.1 \times 10) + (1.0 \times -5) + (0 \times 20) + (0 \times -8) + 1 = 1 - 5 + 1 = \mathbf{-3} (0.1×10)+(1.0×−5)+(0×20)+(0×−8)+1=1−5+1=−3
- 神经元 2 : ( 0.5 × 10 ) + ( 0 × − 5 ) + ( 0.1 × 20 ) + ( 0 × − 8 ) + 0 = 5 + 2 = 7 (0.5 \times 10) + (0 \times -5) + (0.1 \times 20) + (0 \times -8) + 0 = 5 + 2 = \mathbf{7} (0.5×10)+(0×−5)+(0.1×20)+(0×−8)+0=5+2=7
- 神经元 3 : ( 0 × 10 ) + ( 0 × − 5 ) + ( 0 × 20 ) + ( 0.25 × − 8 ) + 0 = − 2 (0 \times 10) + (0 \times -5) + (0 \times 20) + (0.25 \times -8) + 0 = \mathbf{-2} (0×10)+(0×−5)+(0×20)+(0.25×−8)+0=−2
结果 :得到线性变换后的中间向量 − 3 , 7 , − 2 -3, 7, -2 −3,7,−2。
3. ReLU 激活
- 输入 : − 3 , 7 , − 2 -3, 7, -2 −3,7,−2
- 操作 :负数归零 ( x < 0 → 0 x < 0 \to 0 x<0→0)
- 结果 : 0 , 7 , 0 0, 7, 0 0,7,0(实现稀疏化)
4. 线性瓶颈层
- 压缩至 2 维核心特征 :假设计算得到 B t = 5.5 , − 3.2 B_t = 5.5, -3.2 Bt=5.5,−3.2
- 关键点 :这是线性层 ,负数 − 3.2 -3.2 −3.2 被完整保留,以承载更多信息(不进行 ReLU 截断)。
5. 动态特征拼接 (Dynamic Features)
计算速度 ( Δ \Delta Δ, 一阶导数) :
假设下一帧特征 B t + 1 = 6.5 , − 3.0 B_{t+1} = 6.5, -3.0 Bt+1=6.5,−3.0。
Δ t ≈ B t + 1 − B t = 6.5 − 5.5 , − 3.0 − ( − 3.2 ) = 1.0 , 0.2 \Delta_t \approx B_{t+1} - B_t = 6.5 - 5.5, -3.0 - (-3.2) = \mathbf{1.0, 0.2} Δt≈Bt+1−Bt=6.5−5.5,−3.0−(−3.2)=1.0,0.2计算加速度 ( Δ Δ \Delta\Delta ΔΔ, 二阶导数) :
表示"速度变化的快慢"。假设再下一刻的速度变为 Δ t + 1 = 0.8 , 0.5 \Delta_{t+1} = 0.8, 0.5 Δt+1=0.8,0.5。
Δ Δ t ≈ Δ t + 1 − Δ t = 0.8 − 1.0 , 0.5 − 0.2 = − 0.2 , 0.3 \Delta\Delta_t \approx \Delta_{t+1} - \Delta_t = 0.8 - 1.0, 0.5 - 0.2 = \mathbf{-0.2, 0.3} ΔΔt≈Δt+1−Δt=0.8−1.0,0.5−0.2=−0.2,0.3最终向量 (拼接送入 LSTM):
模型将特征本身 、变化速度 、变化加速度打包在一起:
Input LSTM = 5.5 , − 3.2 ⏟ 瓶颈特征 , 1.0 , 0.2 ⏟ Δ ( 速度 ) , − 0.2 , 0.3 ⏟ Δ Δ ( 加速度 ) \text{Input}_{\text{LSTM}} = \\underbrace{5.5, -3.2}_{\\text{瓶颈特征}}, \\underbrace{1.0, 0.2}_{\\Delta (\\text{速度})}, \\underbrace{-0.2, 0.3}_{\\Delta\\Delta (\\text{加速度})} InputLSTM=瓶颈特征 5.5,−3.2,Δ(速度) 1.0,0.2,ΔΔ(加速度) −0.2,0.3
3.2 时序建模与融合
- 单流时序建模:在编码层之上,音频流和视频流各连接一个 BLSTM,独立学习各自模态的时间动态。
- 融合机制 :将两个流的 BLSTM 输出在特征维度拼接,喂给另一个 BLSTM 进行多模态融合。
3.3 分类决策(关键差异点)
与前作《End-to-end visual speech recognition with LSTMs》不同,本作在决策机制上做了调整:
- 输出层 :Softmax 为每一帧都提供一个预测标签。
- 最终决策 :采用 "多数投票机制"。即统计整个话语中所有帧的预测结果,出现次数最多的标签即为该话语的最终类别。
【4】 实验设置与核心训练策略
4.1 数据预处理
为了消除干扰并对齐多模态数据,实施了三步标准流程:
-
去受试者特征
- 目的 :消除肤色、脸型等静态特征,迫使模型只关注动作变化。
- 方法:计算整个话语的"平均图像",从每一帧中减去该均值。
-
视听同步
- 目的:音频采样率高(100Hz),视频帧率低(25fps),时间轴不对齐。
- 方法 :使用线性插值对视觉特征进行上采样,提升至 100fps。
知识点:什么是"线性插值"?
这是一种基础的数学估算方法,假设两点间变化是均匀线性的。
本文操作:视频从 25fps 变 100fps(扩大 4 倍)。算法在 0ms 和 40ms 的真实值之间连线,均匀插入 10ms、20ms、30ms 的数值,实现在两帧间补全 3 个新点。
-
数据标准化
- 目的:满足 RBM 训练线性输入单元的数值分布要求,防止不收敛。
- 方法:使图像和频谱图均值为 0,标准差为 1。
4.2 训练策略
针对深度网络难以训练的问题,本研究采用**"先独立预训练,后联合微调"的两阶段**策略。
第一阶段:单流独立初始化
在视听融合之前,先对音频流和视频流分别进行训练,为后续融合打好基础。
1. 编码层预训练
- 方法:对音频流和视频流分别进行独立训练。
- 核心手段 :采用受限玻尔兹曼机 (RBM) 以贪婪的逐层方式进行预训练。
- 模型选择 :由于输入数据(像素或频谱图)是连续的实数值,且隐藏层包含线性单元,普通的伯努利RBM(处理 0/1 二值数据)不再适用,因此选用了高斯 RBM (Gaussian RBM)。
Tip:RBM 到底是干什么的?
在 2017 年左右,直接训练很深的网络非常困难。RBM 在这里充当了**"网络初始化助手"**的角色。
- 它的任务 :它是一种无监督学习方法。不用标签,仅仅通过观察输入数据,试着学会"重构"这些数据。
- 它的效果:通过这一步,网络权值不再是杂乱无章的随机数,而是已经学会了如何提取边缘、纹理等基础特征。
2. 关键技术细节 (RBM 训练避坑指南)
在此阶段(训练 20 轮,批量大小 100,L2 正则化系数 0.0002),有两个必须要掌握的机制:
- 优化算法:对比散度 (CD)
- 目的:直接计算 RBM 对数似然梯度的计算量呈指数级,数学上难以实现。
- 方法 :CD 算法通过运行短期的吉布斯采样 (Gibbs Sampling) 来模拟数据分布,从而近似计算出梯度的更新方向,高效地更新权重。
- 稳定性控制:低学习率与线性单元
- 目的 :线性单元(即激活函数为线性或输入为无界实数值)的输出没有边界。如果使用常规的较高学习率(如 0.1),在反向传播时极易导致权重更新幅度过大,瞬间引发**"梯度爆炸"**。
- 方法 :将学习率强制固定为较低的 0.001,以确保训练的稳定性。
第二阶段:视听联合微调
在单流网络初始化完成后,模型进入最终的联合训练阶段,这是实现多模态特征互补的关键步骤。
- 融合机制 :将训练好的单流网络作为初始状态,在顶部添加一个 BLSTM 层,用于融合两个流的输出。
- 优化器 :转为使用 Adam 算法进行全局优化。
- 超参数设置 :
- 批量大小 :设为 10 个话语。
- 学习率 :降低至 0.0001。
- 防过拟合策略:继续沿用早停法和梯度裁剪。
思考:为什么要降低学习率?
在第二阶段,由于单流网络已经通过前一阶段初始化到了一个比较好的状态,此时使用更小的学习率(0.0001)是为了进行精细的微调,避免步长过大破坏已学到的特征分布。
【5】 实验结果分析与核心发现
5.1 AVIC 数据集:非语言发声识别
背景:自然互动数据,类别严重不平衡(犹豫类 >> 笑声)。
1. 评价指标的选择
单纯看"准确率"在不平衡数据集中具有欺骗性(例如:全部预测为大类,准确率也会很高)。本实验重点关注 F1 分数 和 未加权平均召回率 (UAR)。
核心指标定义
- 精确率 (Precision):预测为正类的样本中,真正为正类的比例。(查准)
- 召回率 (Recall):实际为正类的样本中,被正确预测出来的比例。(查全)
- F1 分数:精确率和召回率的调和平均数。综合反映模型性能,比准确率更客观。
- 未加权平均召回率 (UAR) :分别计算每个类别的召回率求平均。它不考虑样本数量权重,确保小类样本(如"笑声")不被大类淹没。
2. 核心结论:SOTA 的突破
- 对比前人:相比基于手工特征的 SOTA 方法,纯音频模型 F1 提升 19%,融合模型 F1 提升 9.8%。
- 对比模态 :
- 音频主导:Audio-only 远好于 Video-only(笑声主要靠听)。
- 视觉补充 :融合模型比纯音频提升了 2% 。这说明视觉信息起到了互补作用(例如捕捉"犹豫"时的微表情)。
5.2 OuluVS2 数据集:视听语音识别
背景 :受控读稿实验。重点考察**"抗噪性"和"多视角"**。
1. 干净环境下的"天花板效应"
- 现象:无噪声时,Audio-only 准确率高达 98.5%。加入视频后,性能无提升甚至持平。
- 结论 :音频足够完美时,视觉信息是"锦上添花"甚至"画蛇添足"。在安静环境下,多模态融合收益微乎其微。
2. 噪声环境下的"鲁棒性"
作者人为加入噪声,信噪比 (SNR) 从 0dB 到 20dB。
- 现象:随着噪声变大,Audio-only 性能断崖式下跌(0dB 时仅剩 28.4%)。
- 转折 :视听融合模型展现出巨大优势。在所有噪声等级下,融合模型均显著优于纯音频模型。
- Insight :视觉模态不受声学噪声影响。当耳朵听不清时,模型学会了"读唇",这就是视听融合最大的价值------鲁棒性。
3. 多视角分析
- 纯视频 :正面 ( 0 ∘ 0^{\circ} 0∘) 和侧面效果最好, 6 0 ∘ 60^{\circ} 60∘ 最差。
- 融合 :强噪声 (0dB) 下,音频 + 正面视角 依然是最强组合。
思考:一个反直觉的"短板效应"
在 5.2 节末尾,作者提出了一个极具启发性的发现:
- 现象 :在极高噪声(0dB)下,虽然融合模型(57.5%)比纯音频(28.4%)强,但它竟然远不如纯视频模型(纯视频正面视角准确率为 91.8%)。
- 原因分析 :
- 训练偏差:模型使用干净音频训练,建立了"太信任音频"的倾向。
- 测试困境:测试时音频全为噪声,模型依然习惯性依赖音频流,导致被噪声带偏,反而忽略了清晰的视觉信息。
- 启示 :这揭示了现有融合机制(简单的拼接+BLSTM)的缺陷------无法在某模态完全失效时灵活切断权重。