目录
源码获取方式在文章末尾
一******、******项目背景细化
随着游戏产业的快速发展,用户生成的评论数据呈现爆炸式增长,如何高效处理和分析这些海量数据成为游戏开发商和运营团队的重要挑战。传统的单机数据处理工具难以应对TB级甚至PB级的评论数据,而基于Spark+Hadoop的分布式计算框架能够有效解决这一问题。Spark凭借其内存计算优势和丰富的API生态,结合Hadoop的分布式存储能力,为游戏评论数据的实时分析与可视化提供了强大的技术支持。本项目以真实的游戏评论数据集为基础,构建了一套完整的分析系统,涵盖数据清洗、情感分析、热点话题挖掘等核心功能,并通过可视化大屏直观展示分析结果,帮助运营团队快速掌握用户反馈趋势,优化游戏体验。
******二、******研究目的细化
本项目在通过Spark+Hadoop技术栈实现游戏评论数据的高效处理与深度挖掘,具体目标包括:设计可扩展的分布式数据处理流程,解决传统方法在性能与容量上的瓶颈;开发情感分析模型,自动识别用户评论中的正向、负向及中性情绪;基于关键词提取和聚类算法挖掘玩家讨论的热点话题;构建交互式可视化大屏,支持多维度的数据动态展示。通过技术实现,最终为游戏运营提供数据驱动的决策支持,例如版本更新方向、客服响应优先级等。系统还注重易用性,提供完整的部署教程和虚拟机环境,降低技术团队的学习成本。
******三、******创新点技术实现
创新性体现在三方面:一是采用Spark MLlib实现情感分析模型的分布式训练,结合自定义词典提升中文评论的识别准确率;二是利用HBase存储非结构化的评论原始数据,通过RowKey设计优化热点查询效率;三是通过D3.js与ECharts混合渲染技术,实现可视化大屏的动态加载与高性能展示。技术实现上,系统通过Kafka接入实时评论流,Spark Streaming完成窗口聚合分析,HDFS存储中间结果,形成端到端的低延迟流水线。此外,项目提供了细粒度的资源调度配置,允许根据集群规模调整Executor内存与并行度,平衡计算速度与稳定性。
四******、******技术介绍
Spark
分布式计算框架,支持内存计算,适用于大规模数据处理与分析,提供高效批处理和流处理能力。
Hadoop
开源分布式存储与计算生态系统,包含HDFS(分布式文件系统)和MapReduce(计算模型),适合海量数据离线处理。
Hive
基于Hadoop的数据仓库工具,通过类SQL语法(HQL)实现结构化数据查询与分析,支持数据ETL和OLAP场景。
MySQL
关系型数据库,轻量高效,支持事务处理与复杂查询,常用于在线业务数据存储和中小规模数据分析。
Python
通用编程语言,拥有丰富的数据处理库(如Pandas、PySpark),适合数据清洗、分析及与上述技术栈的集成开发。
五、项目展示
登录注册 大屏展示
大屏展示 游戏跳转
游戏跳转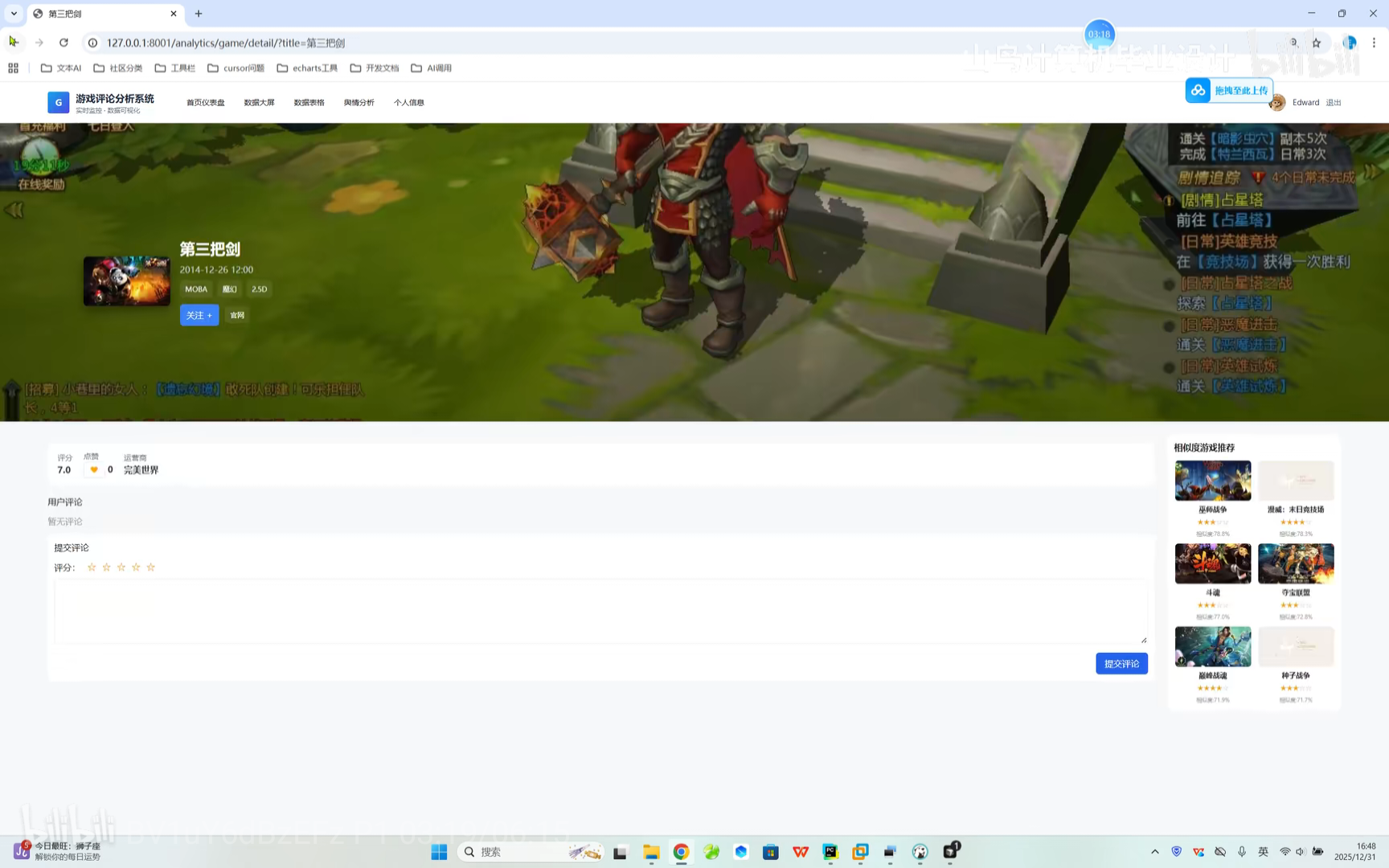
系统首页仪表盘
 游戏资讯跳转
游戏资讯跳转 系统搜索
系统搜索 评论舆情分析
评论舆情分析

 编辑个人信息
编辑个人信息
六、B站权威教学视频 
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。